让一只猴子在打字机上随机地按键,当它有无限的时间时,它就必然能够打出任何给定的文字,从莎士比亚的全套著作到仍未出世的伟大作品。
这个无限猴子打字机的故事相信大家都不陌生,经常被引出来形容人工智能产出作品的潜力。而近期出现了一个可以基于句子作画的AI软件更是让人不禁想问:难道这个猴子不只是随意敲打键盘,甚至都可以自主创作了吗?如果真是如此,那不免也让人会悲观地认为:既然机器可以通过算法产出我们认为美的作品,那我们是不是会被取代?
因此我想用这篇文章给大家稍微梳理一下AI作画的信息,不仅为《AI会改变游戏美术吗?》这期节目做补充,也希望能带给大家一些启发。
1.AI作画软件是怎么运作的?
这段主要参考VOX的一期解释AI艺术的视频,以及这篇文章。
首先,我们可以来了解一下AI作画软件到底是如何运作的。简单概括一下,可以分为这几部分:
- 训练数据
取互联网上的图片和相应的配字作为训练AI的真实样本。
- 深度学习
通过深度学习训练AI更好地将图片的像素数据和文字进行匹配,并创造出一个潜在空间(Latent Space)。
- 潜在空间
这可以说说是AI作画中最重要的部分了。在这里,AI将图片编码成一组虚拟空间中的坐标。而这个坐标的每个维度都可以视作一个“特征”。
比如说下图中,在训练数据只有香蕉和气球的时候,香蕉的坐标是(黄1,圆0),红色气球的坐标是(黄0,圆1),而黄色气球的坐标是(黄1,圆1)。这时我们可以说:在“圆1”这个坐标附近,总会找到一堆气球。
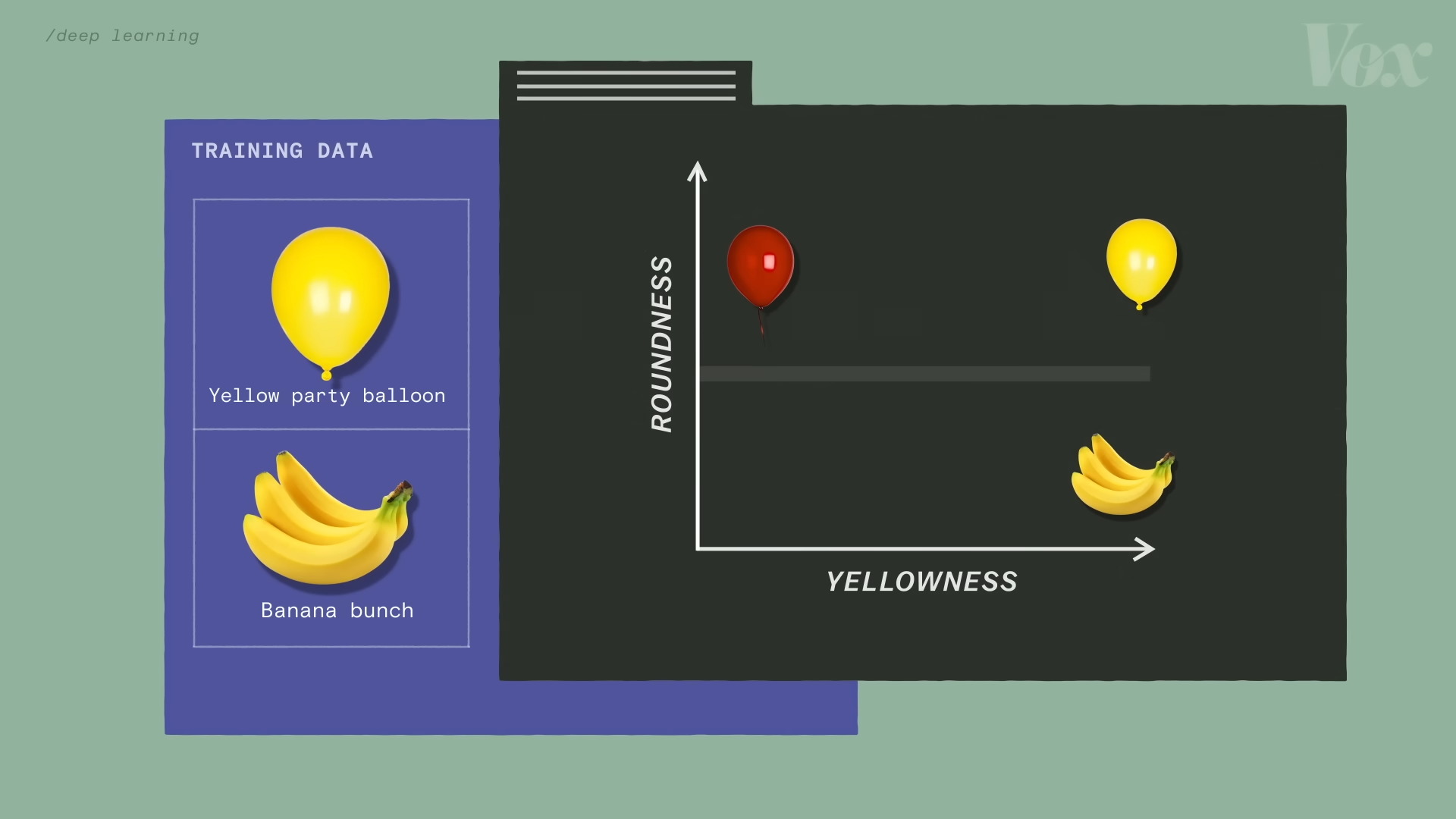
然而当训练数据的样本量扩大时,这就不再成立了。因为存在非圆形的气球,也存在圆形的香蕉切片。这时,我们就可以引入一个新的特征维度:光泽程度。因为大部分气球都是有光泽的而香蕉不是,我们现在又可以说:在“光泽1”这个坐标附近,总会找到一堆气球。同时我们可以通过调整“黄”和“圆”这两个维度的数值来控制我们在这一堆气球里找到气球的具体特性。
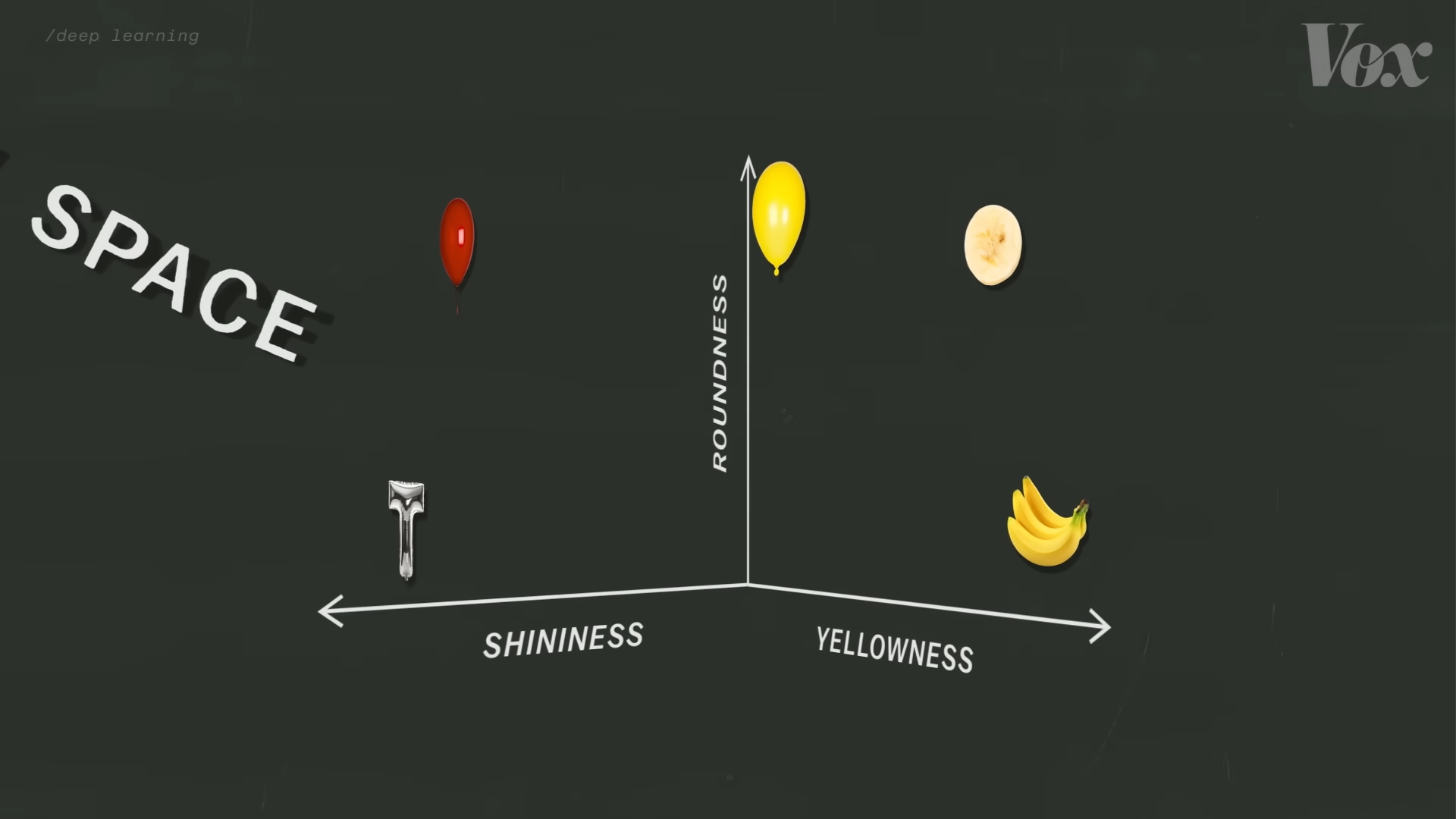
辨别更大的样本量也就需要更多的特征维度。比如Midjourney就是一个由超过500个特征维度组成的潜在空间,在这里,更相近的坐标代表更相似的图片。

由潜在空间产出的图片,可以看到不同特征维度之间的融合。
那既然现在我们可以准确的找到图片,我们该怎么生成新的图片呢?这时候就需要对潜在空间进行插值(interpolate)或者叫柔化(Diffusion)。
- 柔化
潜在空间是将图片编码为坐标,柔化则是将给定坐标解码成图片。在解码之前一般会加入噪点(Noise),这样就算坐标完全一样AI也会产出相近而不同的结果。
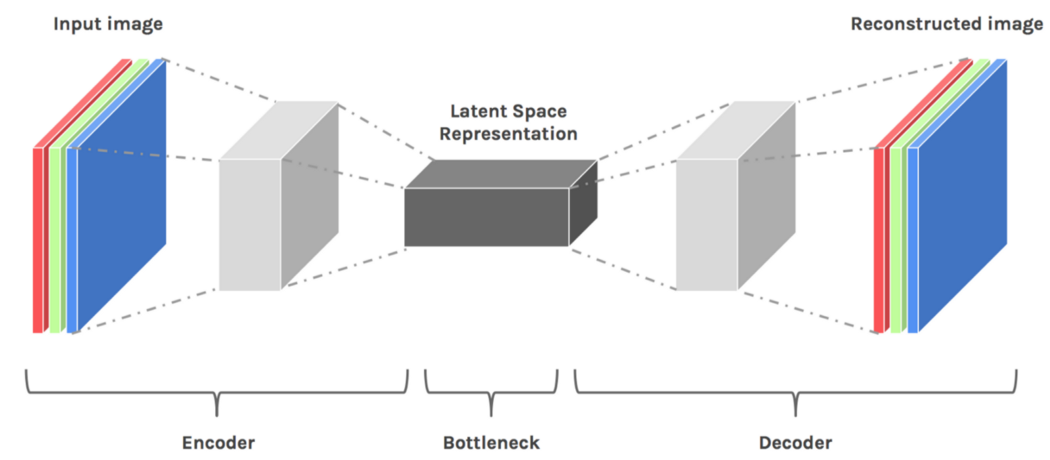
”输入图片>编码>隐藏空间>解码>重建图片“的过程
在实际使用中,用户输入的句子会被转换成对AI有意义的特征关键词,对应到潜在空间中的一个坐标。这个坐标会被柔化转换成一张图像。但如果输入的句子太复杂,那只有靠前的关键词会被实现出来。因为类似MIdjourney这样的软件会默认靠前的关键词拥有更高的权重(也可以在关键词后面加::n数字直接调整权重)。
另一种常见的技巧是在输入句子的尾部加入的“Buff”,也就是一些产出特定效果的关键词,比如说 “4k”, “8k”,“high detail”会让画面看起来更细节(不会真的改变分辨率),“cinematic”会让画面有景深和光圈模糊,等等。

成堆的关键词Buff
如此看来,AI与其说是在“画画”,不如说是一个精细的图片搜索引擎。这个搜索引擎根据我们的输入,将它数据库里的图片以像素等级重新排列组合成一张“新”的图片。
一旦以这个全新的视角观察AI作画,我们就不难发现其中的问题。
2.AI作画的问题?
行业中对AI作画最大的批评之一就是其对有版权图片和艺术家作品进行“拼贴”和“窃取”。这点不是毫无证据的。比如有的AI模仿艺术家画风,连签名都模仿进去了。甚至更是有直接模仿了一张天空的Stock Image,水印还在上面。

天空中出现迷之水印
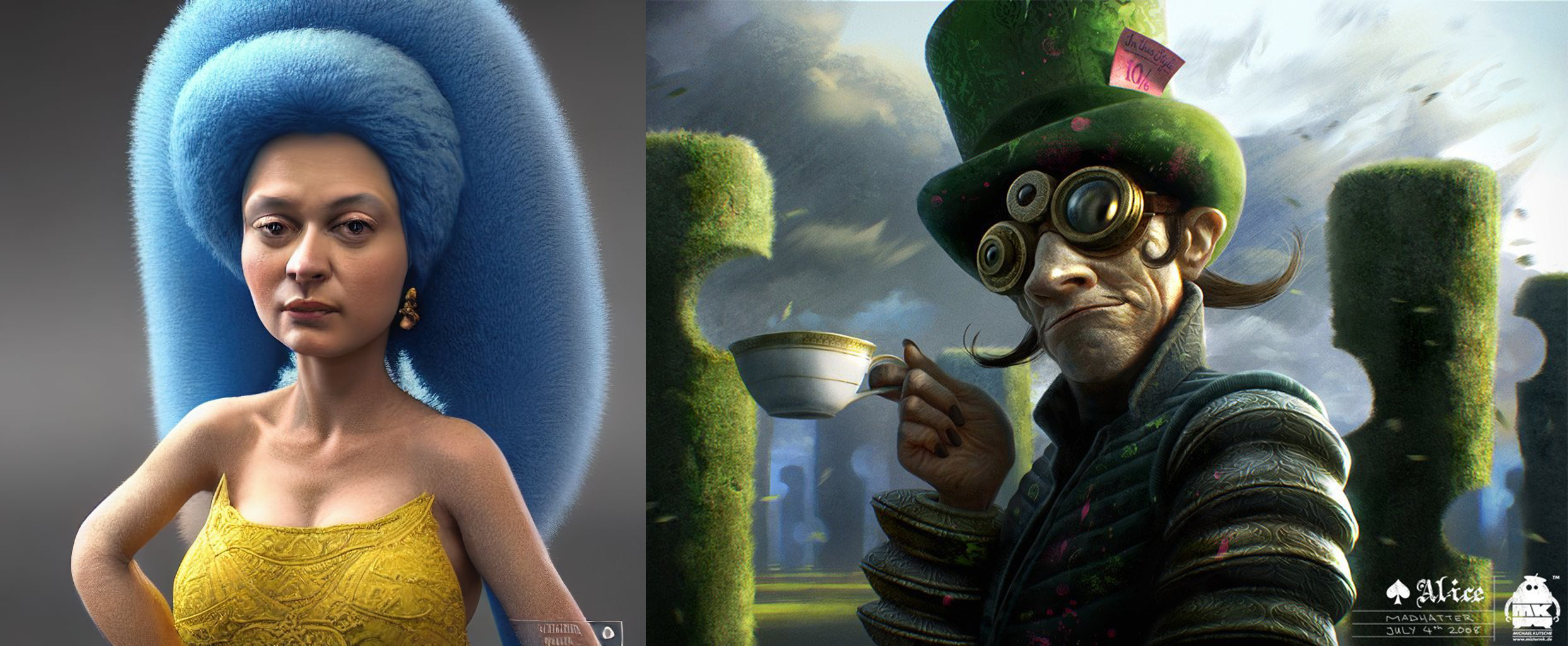
左边的AI”模仿“右边画师的签名。(来源:https://twitter.com/arvalis/status/1558623546879778816)
天空中出现迷之水印
左边的AI”模仿“右边画师的签名。(来源:https://twitter.com/arvalis/status/1558623546879778816)
天空中出现迷之水印
1 / 2
作为经常在AI作画中出现的艺术家关键词,美国插画大师James Gurney对AI报接受态度,但仍在VOX的采访中表示:
我认为只有当人们看到(AI作图)作品时能够知道输入的关键词和软件是什么的时候才公平。此外,我认为应该允许艺术家自愿选择是否将他们辛辛苦苦手工完成的作品加入这个创作其他艺术品的数据集中。
截至现在,没有任何工具可以避免AI“抄袭”。原因就是因为AI作图的训练数据是互联网上能抓取到的图片。这对内容创作者来说是具有潜在伤害性的。而对于想将AI图作为商业用途的人来说,想要排查图中是否侵权,侵谁的权,都是一件几乎不可能的事情。如果使用普通的搜索引擎,有很大可能可以找到图片来源;而一旦使用AI作画这个引擎,则断绝了这条路。
就算AI作画可以提升效率和提供全新的视角,它与以往革新的美术工具的最大区别就在于其中人的主动性很弱。相比于摄影需要使用者寻找构图,规划打光,调整光圈和快门,我们也会倾向于认为单反照出来的日落风景会比傻瓜相机的游客照更具有艺术性。
但如果我们暂时只把AI作图只当作一种旧技术的升级版,一些矛盾就会迎刃而解。我们不会直接把网上搜来的图直接商用,也不应该无许可地转载网上艺术家的作品,更不会认为搜索引擎自己可以创造艺术。
另外,现在大部分AI作图都是有很明显的特点和瑕疵的:过于鲜艳的颜色,有巨量细节,人物形象尤其是脸部不明确等等。我们能在其中看到世界观,情感,故事,人物,很大程度上是因为我们人类的脑补能力,加之我们对娱乐作品类别化语境的熟悉:我们看惯了太空中发光飞船,霓虹灯城市,城堡和骑士和龙。

近看却只是随机的形状,远看人脑却能够脑补出一对士兵。
价值判断的过程需要人参与的。就算猴子可以有无限的时间敲打打字机,它也需要一个人看遍无限篇作品来判断它打出的究竟是胡言乱语还是旷世奇作。
3.尾声
虽然上面列出了很多不足,但我其实对AI作画软件作为搜索引擎的一面很看好。
它可以给艺术家提供更直接的参考图和Mood Board。对于非商用的用途,AI也可以省去搜索的时间。比如DM可以用AI生成CG图片给玩家更强的代入感,除此之外还会有很多很多应用。
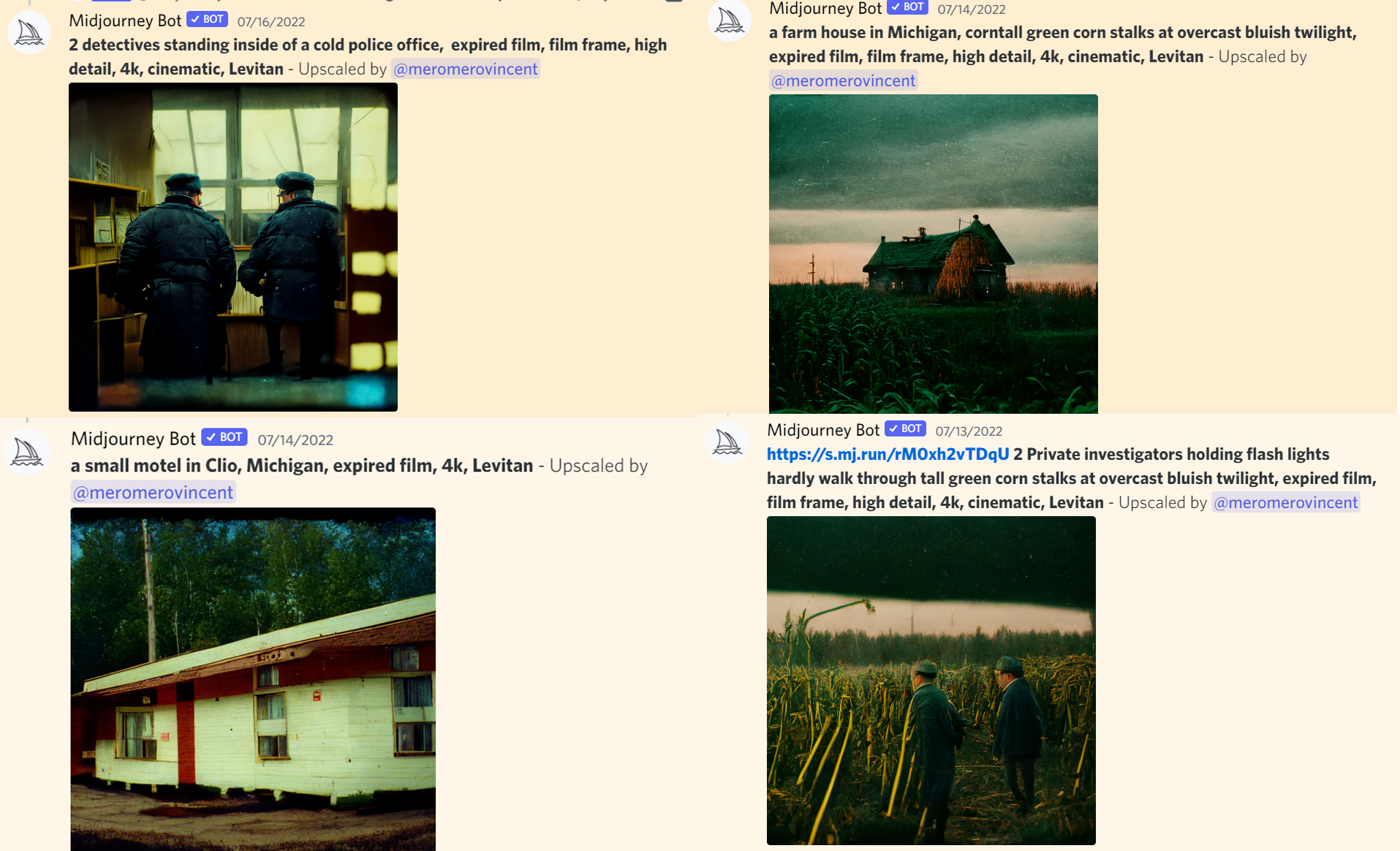
之前跑COC的时候用AI生成的过场图。
而对于AI作画软件是否会取代艺术家,我想分享一张梗图 :P
最后,因为并非我的专业,所以前面对AI作画的机制和术语难免有问题,欢迎评论斧正。也欢迎你分享关于AI作画的看法。