讓一隻猴子在打字機上隨機地按鍵,當它有無限的時間時,它就必然能夠打出任何給定的文字,從莎士比亞的全套著作到仍未出世的偉大作品。
這個無限猴子打字機的故事相信大家都不陌生,經常被引出來形容人工智能產出作品的潛力。而近期出現了一個可以基於句子作畫的AI軟件更是讓人不禁想問:難道這個猴子不只是隨意敲打鍵盤,甚至都可以自主創作了嗎?如果真是如此,那不免也讓人會悲觀地認為:既然機器可以通過算法產出我們認為美的作品,那我們是不是會被取代?
因此我想用這篇文章給大家稍微梳理一下AI作畫的信息,不僅為《AI會改變遊戲美術嗎?》這期節目做補充,也希望能帶給大家一些啟發。
1.AI作畫軟件是怎麼運作的?
這段主要參考VOX的一期解釋AI藝術的視頻,以及這篇文章。
首先,我們可以來了解一下AI作畫軟件到底是如何運作的。簡單概括一下,可以分為這幾部分:
- 訓練數據
取互聯網上的圖片和相應的配字作為訓練AI的真實樣本。
- 深度學習
通過深度學習訓練AI更好地將圖片的像素數據和文字進行匹配,並創造出一個潛在空間(Latent Space)。
- 潛在空間
這可以說說是AI作畫中最重要的部分了。在這裡,AI將圖片編碼成一組虛擬空間中的座標。而這個座標的每個維度都可以視作一個“特徵”。
比如說下圖中,在訓練數據只有香蕉和氣球的時候,香蕉的座標是(黃1,圓0),紅色氣球的座標是(黃0,圓1),而黃色氣球的座標是(黃1,圓1)。這時我們可以說:在“圓1”這個座標附近,總會找到一堆氣球。
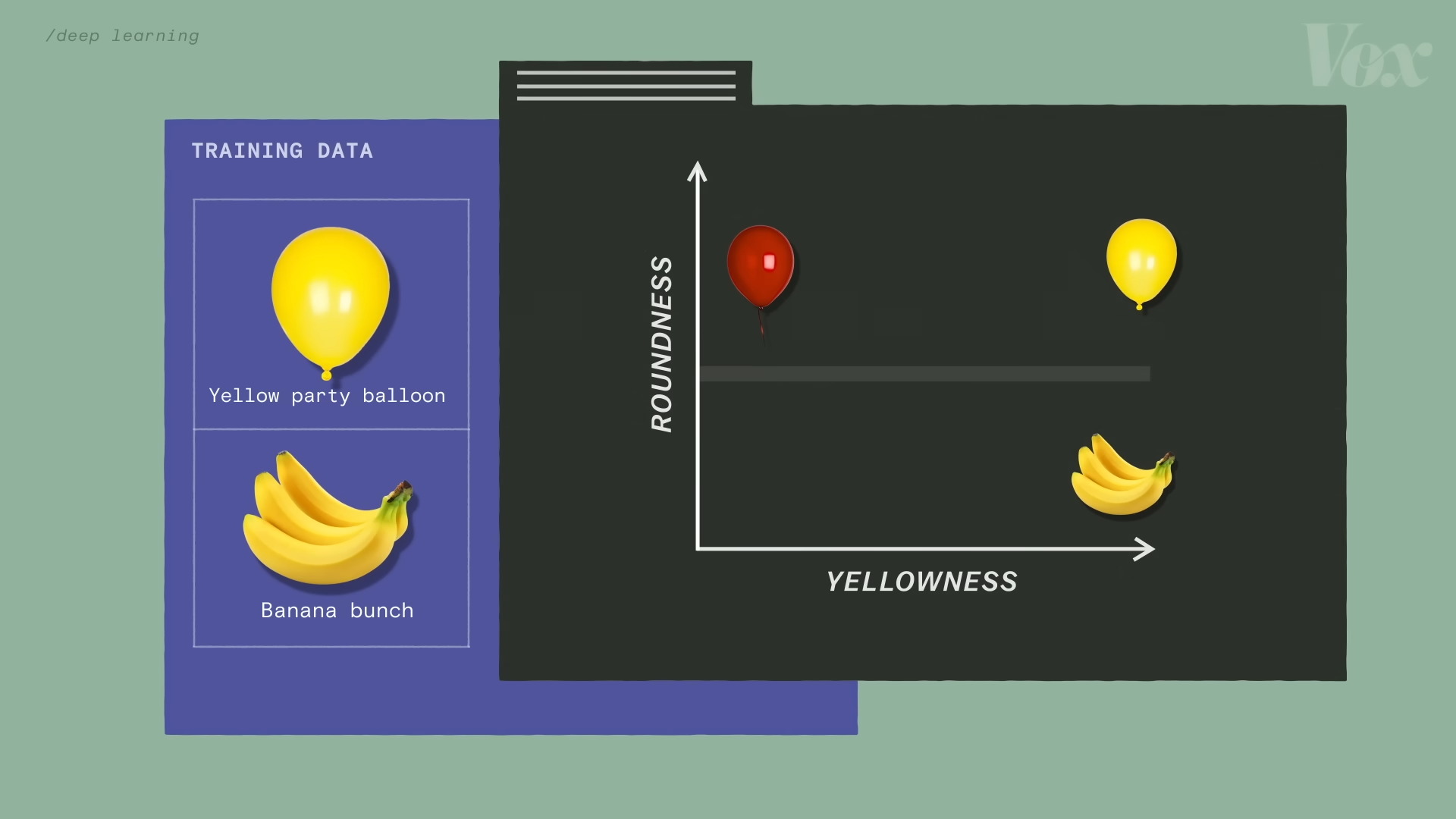
然而當訓練數據的樣本量擴大時,這就不再成立了。因為存在非圓形的氣球,也存在圓形的香蕉切片。這時,我們就可以引入一個新的特徵維度:光澤程度。因為大部分氣球都是有光澤的而香蕉不是,我們現在又可以說:在“光澤1”這個座標附近,總會找到一堆氣球。同時我們可以通過調整“黃”和“圓”這兩個維度的數值來控制我們在這一堆氣球裡找到氣球的具體特性。
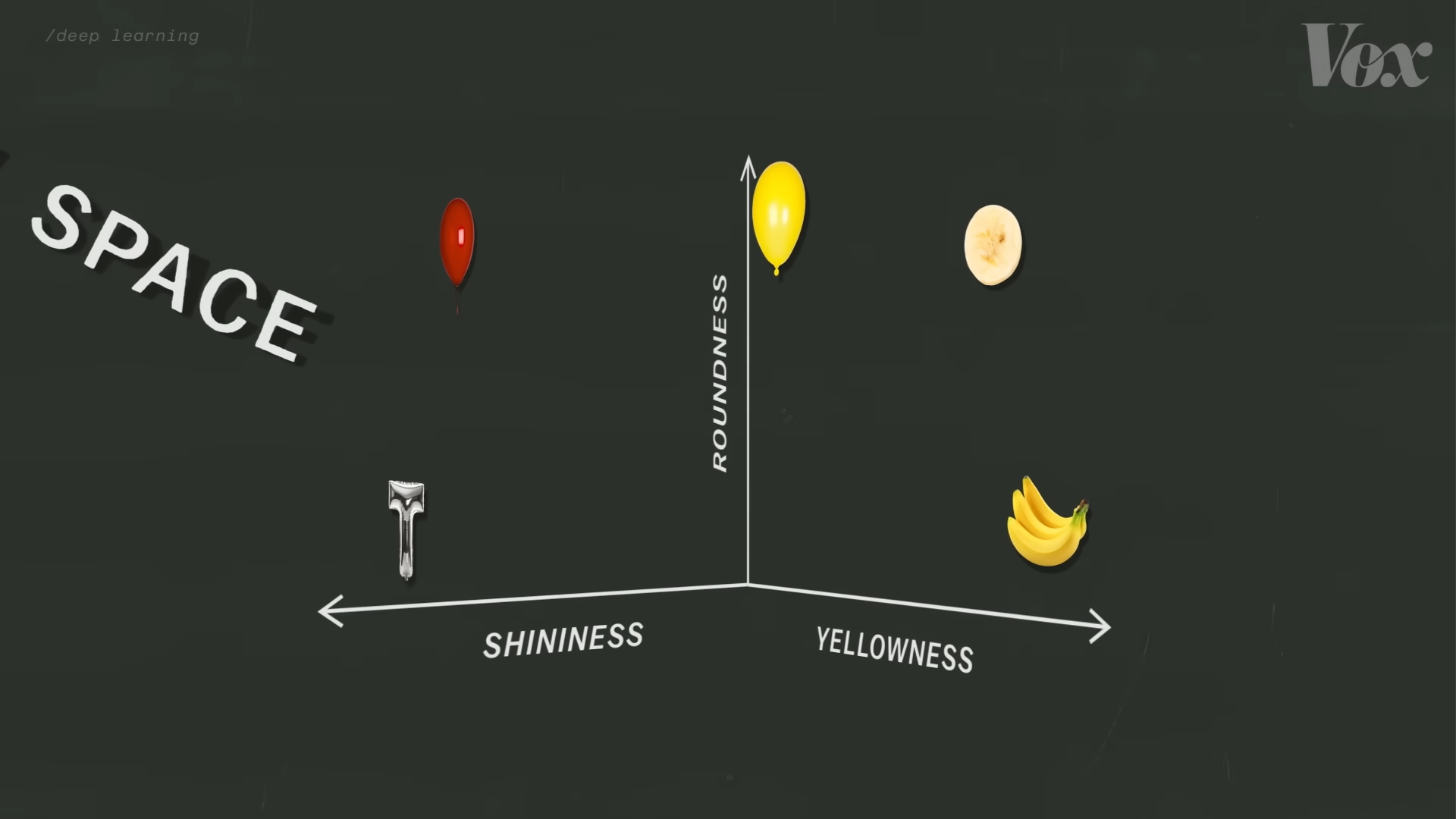
辨別更大的樣本量也就需要更多的特徵維度。比如Midjourney就是一個由超過500個特徵維度組成的潛在空間,在這裡,更相近的座標代表更相似的圖片。

由潛在空間產出的圖片,可以看到不同特徵維度之間的融合。
那既然現在我們可以準確的找到圖片,我們該怎麼生成新的圖片呢?這時候就需要對潛在空間進行插值(interpolate)或者叫柔化(Diffusion)。
- 柔化
潛在空間是將圖片編碼為座標,柔化則是將給定座標解碼成圖片。在解碼之前一般會加入噪點(Noise),這樣就算座標完全一樣AI也會產出相近而不同的結果。
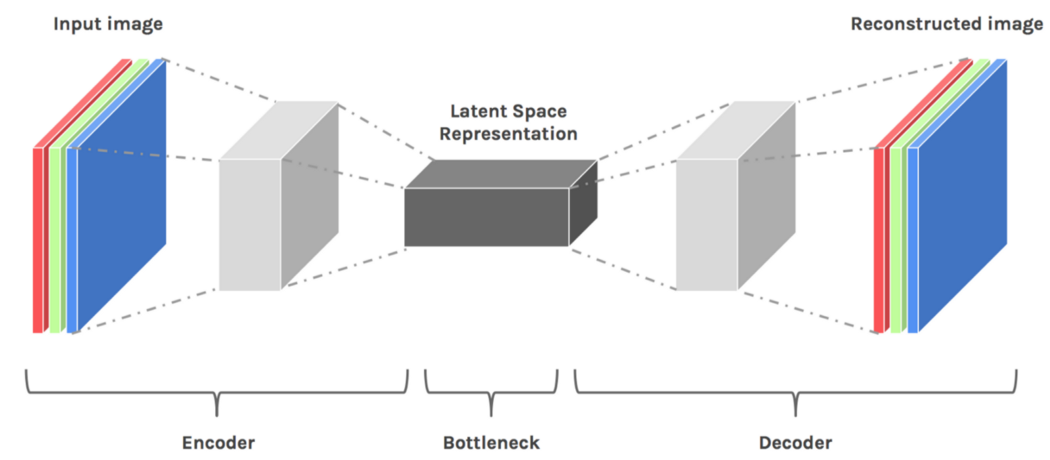
”輸入圖片>編碼>隱藏空間>解碼>重建圖片“的過程
在實際使用中,用戶輸入的句子會被轉換成對AI有意義的特徵關鍵詞,對應到潛在空間中的一個座標。這個座標會被柔化轉換成一張圖像。但如果輸入的句子太複雜,那只有靠前的關鍵詞會被實現出來。因為類似MIdjourney這樣的軟件會默認靠前的關鍵詞擁有更高的權重(也可以在關鍵詞後面加::n數字直接調整權重)。
另一種常見的技巧是在輸入句子的尾部加入的“Buff”,也就是一些產出特定效果的關鍵詞,比如說 “4k”, “8k”,“high detail”會讓畫面看起來更細節(不會真的改變分辨率),“cinematic”會讓畫面有景深和光圈模糊,等等。

成堆的關鍵詞Buff
如此看來,AI與其說是在“畫畫”,不如說是一個精細的圖片搜索引擎。這個搜索引擎根據我們的輸入,將它數據庫裡的圖片以像素等級重新排列組合成一張“新”的圖片。
一旦以這個全新的視角觀察AI作畫,我們就不難發現其中的問題。
2.AI作畫的問題?
行業中對AI作畫最大的批評之一就是其對有版權圖片和藝術家作品進行“拼貼”和“竊取”。這點不是毫無證據的。比如有的AI模仿藝術家畫風,連簽名都模仿進去了。甚至更是有直接模仿了一張天空的Stock Image,水印還在上面。

天空中出現迷之水印
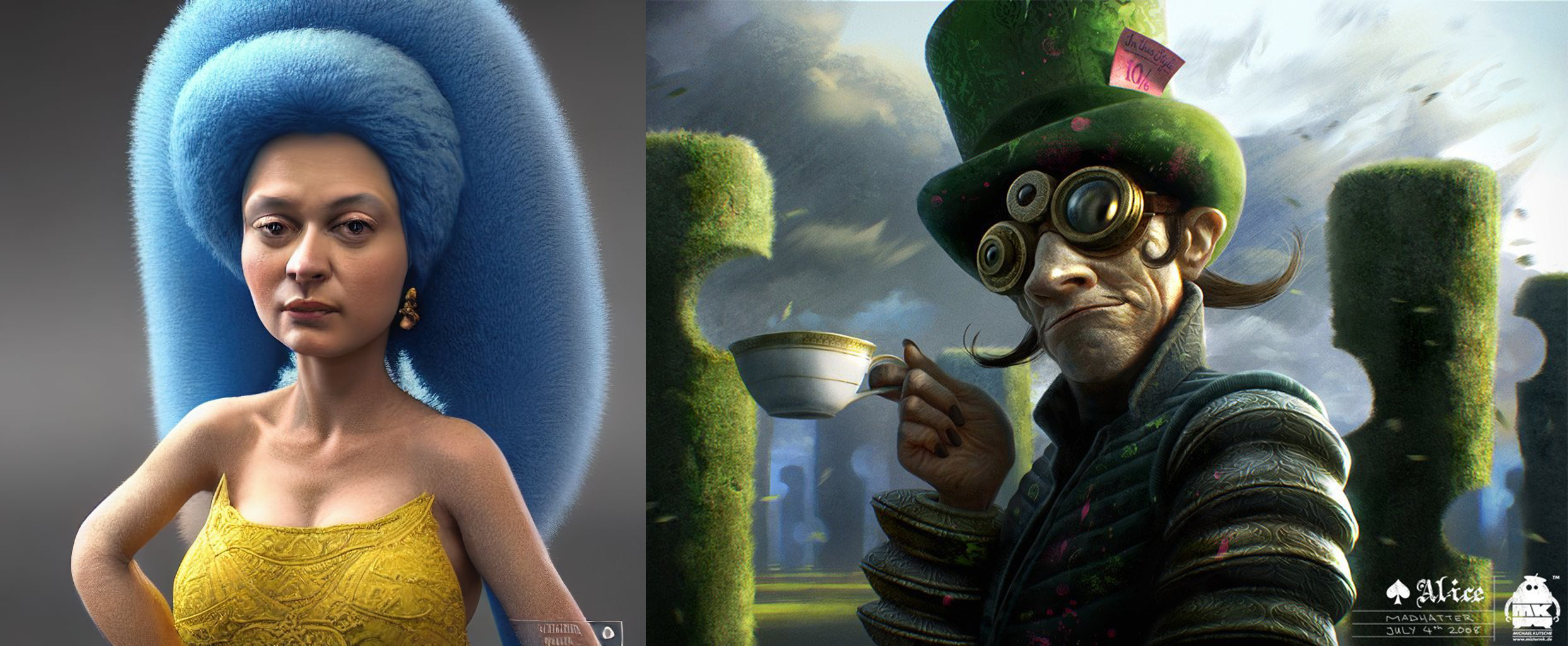
左邊的AI”模仿“右邊畫師的簽名。(來源:https://twitter.com/arvalis/status/1558623546879778816)
天空中出現迷之水印
左邊的AI”模仿“右邊畫師的簽名。(來源:https://twitter.com/arvalis/status/1558623546879778816)
天空中出現迷之水印
1 / 2
作為經常在AI作畫中出現的藝術家關鍵詞,美國插畫大師James Gurney對AI報接受態度,但仍在VOX的採訪中表示:
我認為只有當人們看到(AI作圖)作品時能夠知道輸入的關鍵詞和軟件是什麼的時候才公平。此外,我認為應該允許藝術家自願選擇是否將他們辛辛苦苦手工完成的作品加入這個創作其他藝術品的數據集中。
截至現在,沒有任何工具可以避免AI“抄襲”。原因就是因為AI作圖的訓練數據是互聯網上能抓取到的圖片。這對內容創作者來說是具有潛在傷害性的。而對於想將AI圖作為商業用途的人來說,想要排查圖中是否侵權,侵誰的權,都是一件幾乎不可能的事情。如果使用普通的搜索引擎,有很大可能可以找到圖片來源;而一旦使用AI作畫這個引擎,則斷絕了這條路。
就算AI作畫可以提升效率和提供全新的視角,它與以往革新的美術工具的最大區別就在於其中人的主動性很弱。相比於攝影需要使用者尋找構圖,規劃打光,調整光圈和快門,我們也會傾向於認為單反照出來的日落風景會比傻瓜相機的遊客照更具有藝術性。
但如果我們暫時只把AI作圖只當作一種舊技術的升級版,一些矛盾就會迎刃而解。我們不會直接把網上搜來的圖直接商用,也不應該無許可地轉載網上藝術家的作品,更不會認為搜索引擎自己可以創造藝術。
另外,現在大部分AI作圖都是有很明顯的特點和瑕疵的:過於鮮豔的顏色,有巨量細節,人物形象尤其是臉部不明確等等。我們能在其中看到世界觀,情感,故事,人物,很大程度上是因為我們人類的腦補能力,加之我們對娛樂作品類別化語境的熟悉:我們看慣了太空中發光飛船,霓虹燈城市,城堡和騎士和龍。

近看卻只是隨機的形狀,遠看人腦卻能夠腦補出一對士兵。
價值判斷的過程需要人參與的。就算猴子可以有無限的時間敲打打字機,它也需要一個人看遍無限篇作品來判斷它打出的究竟是胡言亂語還是曠世奇作。
3.尾聲
雖然上面列出了很多不足,但我其實對AI作畫軟件作為搜索引擎的一面很看好。
它可以給藝術家提供更直接的參考圖和Mood Board。對於非商用的用途,AI也可以省去搜索的時間。比如DM可以用AI生成CG圖片給玩家更強的代入感,除此之外還會有很多很多應用。
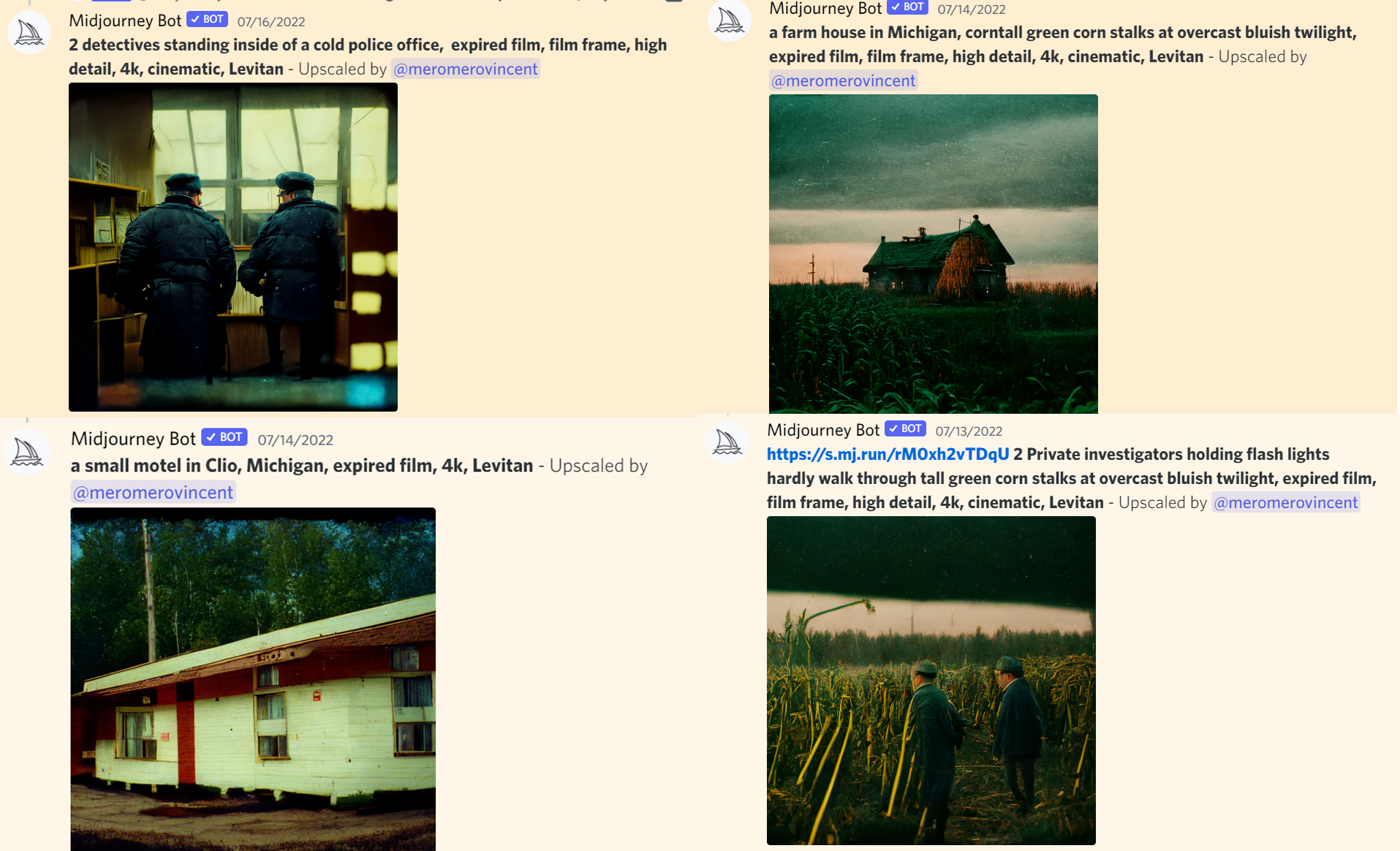
之前跑COC的時候用AI生成的過場圖。
而對於AI作畫軟件是否會取代藝術家,我想分享一張梗圖 :P
最後,因為並非我的專業,所以前面對AI作畫的機制和術語難免有問題,歡迎評論斧正。也歡迎你分享關於AI作畫的看法。