作者 | 奕艾
雷火艺术中心 原画师
AI绘画现在已经进化到什么程度了?
前段时间刚刚发生的新闻,美国科罗拉多州的一个博览会,有人用下面这幅名为《空间歌剧院》的作品拿到了博览会数字绘画的金奖。结果后来他表示:《空间歌剧院》是用AI生成的,他不仅没有动过笔,甚至自己连一点绘画的基础都没有!这让其他参赛者非常不满,他们从小辛辛苦苦练习绘画,为了这次比赛也准备了很长时间,结果竟然被一个不会画画的人打败了?

再来看看下面这三张图,你们觉得哪一张是AI画的呢?

答案是1。是不是已经有点傻傻分不清楚了?
AI绘画无疑是这段时间业内最火的话题之一。而围绕着它,大家的态度也基本分为了两派:一派非常支持用AI进行创作;而另一派则会觉得它扰乱了这个行业,会影响很多从业者的工作。
今天,我就将带大家了解目前比较火的一些AI绘画平台,并着重对其中我个人比较喜欢的Midjourney进行深入的操作心得讲解;然后我就会聊一聊,我作为一个游戏行业的美术工作者,在体验了AI绘画之后,对这项技术的一些看法,以及给大家的一些建议。
现在哪家AI最好用?
现在的AI绘画平台,正呈现出一种百花齐放的态势。各个厂商都推出了自己的产品,有不少都是值得你去体验的。
但你可能不知道的是,其实很早之前,谷歌就曾推出过自己的AI绘画产品,在当时也有很多人尝试。但是,谷歌AI生成图片的时间过长,效果也不是特别好。而且,它在生成的过程中还不能让电脑息屏,否则就会立即停止工作,必须重头开始。它在当时没能引起广泛的讨论,想必你也能知道是为什么了。
至于现在的AI绘画就不一样了,它们方便、快捷、生成的图片又快又好。在体验AI绘画的过程中,你甚至会觉得自己在玩一款很爽快的游戏,因为它会不停地给你正反馈,让你充满惊喜和满足,然后当你回过神来的时候才发现——自己已经把充值的额度给用完了。
在这里,我主要向大家介绍3个平台,它们应该算是我目前体验下来的“AI三巨头”:一个是我最喜欢的Midjourney,它在8月份的时候结束了内测,现在不需要邀请码,每个人都可以去使用;一个是Stable Diffusion,目前也非常火;还有一个是Dall-E2,出品自OpenAI这家人工智能领域的巨头公司。

嗯……本文在撰写的时候Novel AI还没有那么火,现在感觉热度已经赶上来了
因为后面我会着重去讲Midjourney这个平台,所以在这里先简单跟大家介绍一下Stable Diffusion和Dall-E2。
Stable Diffusion这个平台挺神秘的,因为他们的技术很好,很多投资人想去投资,结果都被老板给一一回绝了,说我们不差钱。有多不差钱呢,据说他们有4000张DGX A100顶级显卡用于AI计算——以防你不知道,一块A100大概需要20万美元!难怪他们生成图片的速度能这么快。

此外,Stable Diffusion目前也已经开源了,所以现在很多公司都在根据他们的代码,来开发自己的AI绘画产品。他们的口号是“AI by the people, for the people”,意思就是“AI取之于民,用之于民”,也算是很直白地说出了AI绘画的工作原理。
如果说Stable Diffusion是“低调神秘的慈善家”的话,那么Dall-E2的称号应该就是“甲方终结者”了,因为它生成的图片更有3D感,对于平面类或者设计类的需求非常在行。绘画感则稍差一些,所以可能不是那么适合原画师。
Stable Diffusion和Dall-E2还在其他方面有一些区别:比方说Dall-E2会有关键词的屏蔽,不能出现一些血腥、暴力、政治相关的内容,例如某德国元首就不会出现在它生成的图片里,哪怕你已经很明确地把他的名字输入给了AI;而Stable Diffusion的话就没有这些限制,你可以让AI给你生成一个二次元风格的元首,或者是波普风格的,随心所欲。
Dall-E2还有个特点是,不管你的关键词写的有多奇葩,它都能把你描述的词给放进图里。你们猜下面这张图的关键词是什么?是“键盘侠在阅兵”,黑色的地方实际上是键盘。

而Stable Diffusion就只能给你画出一个阅兵的场面,没办法识别出更多的意思。它是有选择性的,并不是任何稀奇古怪的关键词都给你考虑进去。

Dall-E2因为是大公司出品,我虽然不敢保证未来会发展成什么样,但投入给它的资源应该不会少。不过就目前而言,我个人体验下来还是Midjourney和Stable Diffusion更加推荐一些。不过需要注意的是,如果用Stable Diffusion的话,你的花费可能会大一点,而且就算花了钱,也会有张数的限制;而Midjourney只要付30美元就不会有张数的限制了,虽然可能需要你排排队。
除了上述提到的“三巨头”之外,其实百度最近也推出了自己的AI绘画产品“文心”。它最大的特点是比较能贴合我们中国自己的文化。比方说它能知道孙悟空长什么样,而国外的产品可能连他是个猴子都不知道。包括一些国内流行的梗,比如“鸡你太美”什么的,它也知道你在说什么。

更经典的例子是中国菜:什么过桥米线、狮子头,文心理解起来毫无压力;而国外的产品,估计真的能给你画成一座桥,再加一个狮子的头。
此外,它还有个优势是擅长生成古风和二次元类的绘画,据说有些图的质量甚至到了可交付的程度,感兴趣的同学也可以去试一试。
“最强AI”Midjourney操作指南
这一部分我们会详细地来聊一聊Midjourney这个平台。先说说它背后的公司:它是由大卫·霍尔兹创办的,在做这家公司之前,他主做物体追踪领域,当时他们的物体追踪技术比Xbox的Kinect都要先进上好多倍。后来这家公司被收购,他就去创办了Midjourney这个平台。
打开Midjourney的主页,如果你之前没有注册过的话,应该看到的就是下面的这张图。Midjourney有个好处是,它是个全平台的产品:你可以用网页、也可以用电脑客户端、手机上也有APP——因为等下你就会知道,它本质上其实就是个“聊天软件”,所以多端使用对它来说不是问题。
如果你想要开始创作,可以点击第一个“Join the beta”按钮,就会进入到Midjourney的官方discord频道——没错,我们会在这个频道里,开始我们的创作之旅。
点开之后,你会发现下面这样一个页面。最左边是好友栏,旁边是频道——大家可以理解为是房间,你可以到对应的房间操作一些指令;然后中间的部分则是对话框。
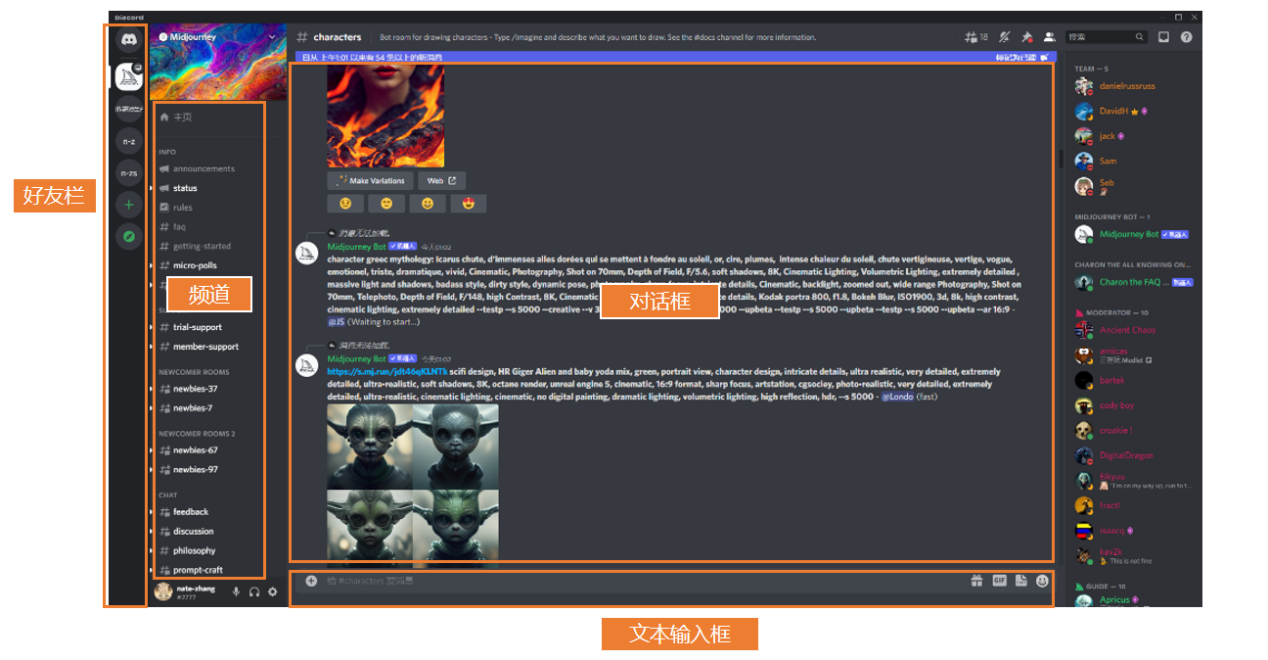
至于如何去创作?你只需要在下面的文本框里输入一些关键词,系统就会在对话框里发送根据关键词生成的图,快的时候可能连一分钟都不要——没错,就是这么简单。整个的操作流程,其实都是通过discord这个聊天软件完成的,是不是没想到?
下面是一些基础的指令,那些没有接触过AI绘画的同学可以来参考一下:

如果大家想要生成图片,基本上用第一个指令“/imagine”加上一些关键词就好了。而“/info”,其实就是能显示你目前账户状态的一个指令。如果你没有订阅的话,就会显示你还剩多少张图可以生成。订阅之后,会显示你是标准版、基础版还是企业版等等。
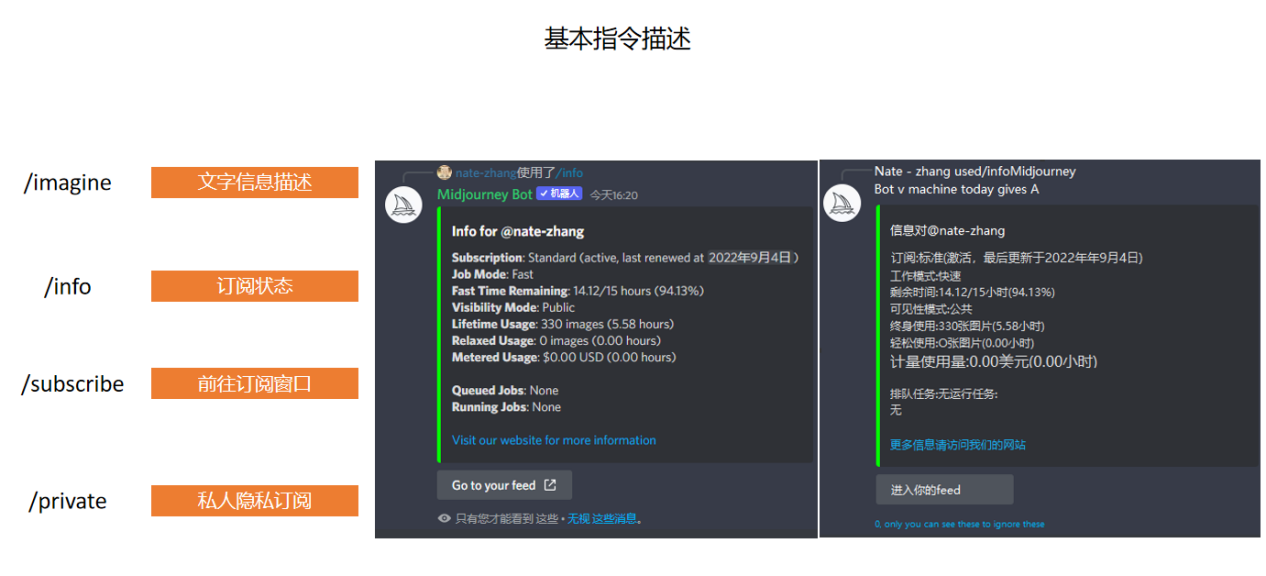
值得注意的是这个/private私人隐私订阅。Midjourney里的频道,其实就相当于是一个公共的聊天室,所有人打上去的字,包括系统生成的图,大家全都能看到。但有了隐私订阅之后,你在频道里输入的东西就只对你一个人可见了。目前有不少国内的博主会选择这个订阅,因为他们不希望自己的关键词被公开——毕竟如果别人也用了这些关键词,那么很容易就能做出类似的图片了。
没错,对于目前的AI绘画来说,关键词的调教可以说是重中之重。生成的图好不好,是不是自己想要的效果,全靠它。下面我们也会重点来说一说这个模块。
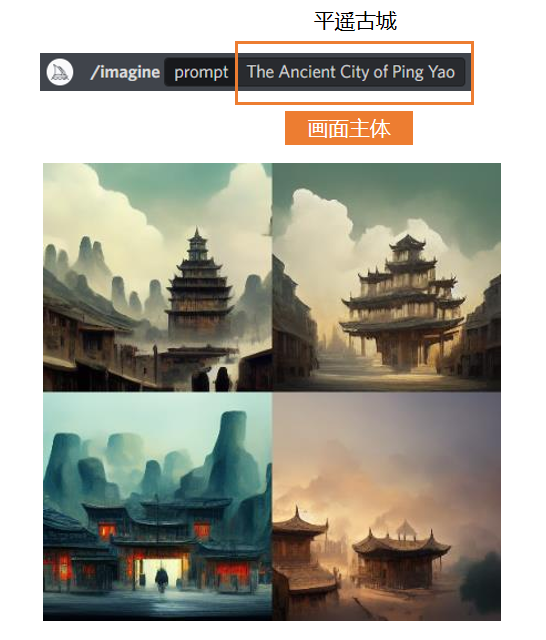
首先,你需要输入一个你想要的主题。比如,我想要AI画一个平遥古城,那么我就输入平遥古城的英文——记得,不能打拼音。你也可以直接用中文,也能识别,但是效果不保证,所以我建议大家还是去维基百科上查询官方的英文译名比较好。
输入好关键词,然后点击生成。因为你没有规定它的画幅比例,所以它默认生成出来的图就是1X1的,每次都会给你生成4张,效果如下:
如果想在这个基础上增加更多想要的效果,那么可以在主题描述不变的情况下,在后面加入一些新的关键词。比如我想要晚上的平遥古城,那就加一个Night就可以。不同的关键词之间可以用逗号去隔开,也可以用加号,那样就会把两个关键词融合在一起,偶尔会出现不伦不类的情况,所以我大多数情况下还是用逗号连接。
你也可以去手动规定生成图片的比例,比如16:9,21:9,这些都可以。或者可以用“-w”和“-h”来规定宽和高,来输出类似1920x1080这样精确尺寸的图。
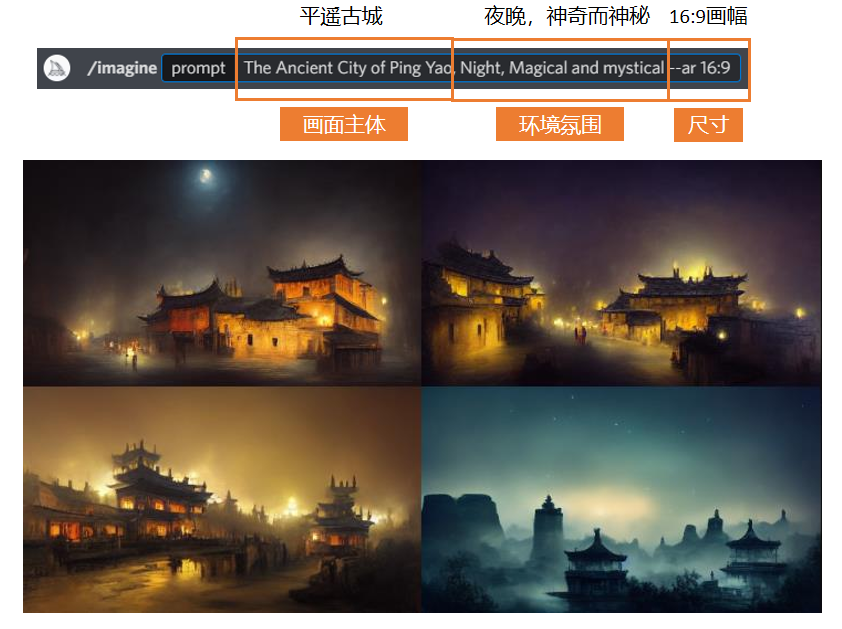
在加上Night这个关键词之后,AI生成的图片就都是晚上的平遥古城了。但因为我没有写明想要什么色调,所以AI同时给出了黄色和蓝色两种色调的图。这也是AI绘图的一个运行逻辑:如果你没有给AI一个明确的需求,那么它就会对你没有规定的部分做出一些猜测。但如果你规定了你就想要蓝色的,那它就肯定不会给你生成黑色或者红色的——它不会违背你的命令,顶多就是有点任性。
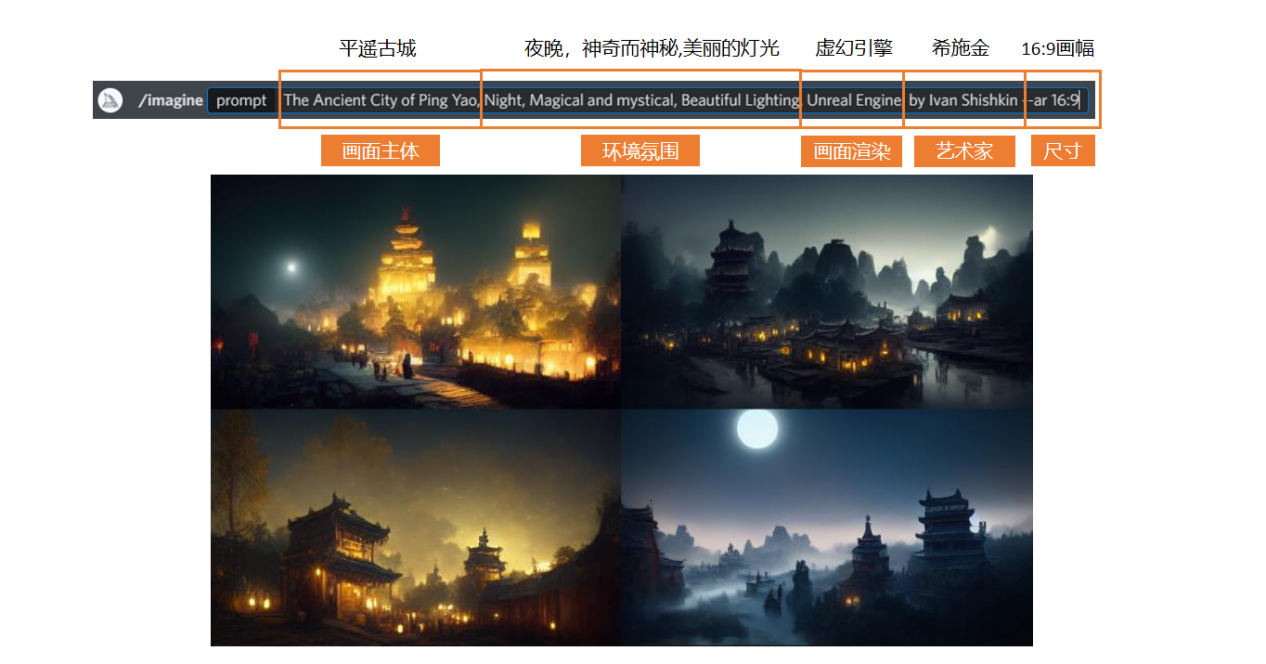
然后我们继续去细化我们的关键词。我在原有的基础之上增加了“美丽的灯光”,然后又加了一个引擎渲染的效果,我希望它生成的图带有虚幻引擎的感觉——当然,如果你想要其他引擎的效果也是可以的,添加相应的关键词就行。
另外,我也加了一个艺术家的名字进来,我希望画面也能有他的风格。不过需要注意,很多时候艺术家的风格和游戏引擎的风格是冲突的。如果艺术家本身的风格是写实那就还好,加上虚幻引擎说不定能更加分;但如果艺术家本身是二次元风格,那还是不要强行把它们放在一起吧。
这么调教下来的效果如下图,个人认为还是挺令人惊喜的:
后来,我把虚幻引擎的关键词去掉,然后把艺术家的名字换成了葛饰北斋,得到了下面这一组图,效果也不错:

不过,葛饰北斋和灯光这个关键词其实是有点冲突的,如果你单纯只是想要葛饰北斋的风格,那就可以把灯光这个关键词给去掉,得到下面这一组图:

另外,根据很多人的测试,好像竖画幅的构图更容易出片。于是我又把艺术家的名字换成了唐伯虎,再把参数里的画幅由横构图换成了竖构图,最终得到的成品如下:

其实AI绘画用的多了之后,你会发现AI的思维和人类的思维是很像的。譬如我们在看到一些关键词的时候,其实脑海中浮现的也都是一些模糊的、整体的印象。比如提到故宫,你能想到红色的宫墙、黄色的屋顶、大气磅礴的中式建筑这些概念,但很难想到某一个具体的图案或者结构。AI也是类似,很多时候它就是把关键词的整体感觉呈现给你,但如果你仔细观察的话,会发现图片在一些地方存在着杂乱的效果堆积——就跟人类在想象某个物体的时候对于细节的缺失感一样。
不过呢,Midjourney也有对应的功能,去完善缺失的细节。下图的“U”就是放大添加细节的功能,而“V”则是按照构图重新计算一次,1、2、3、4则对应着四张图片,很好理解:
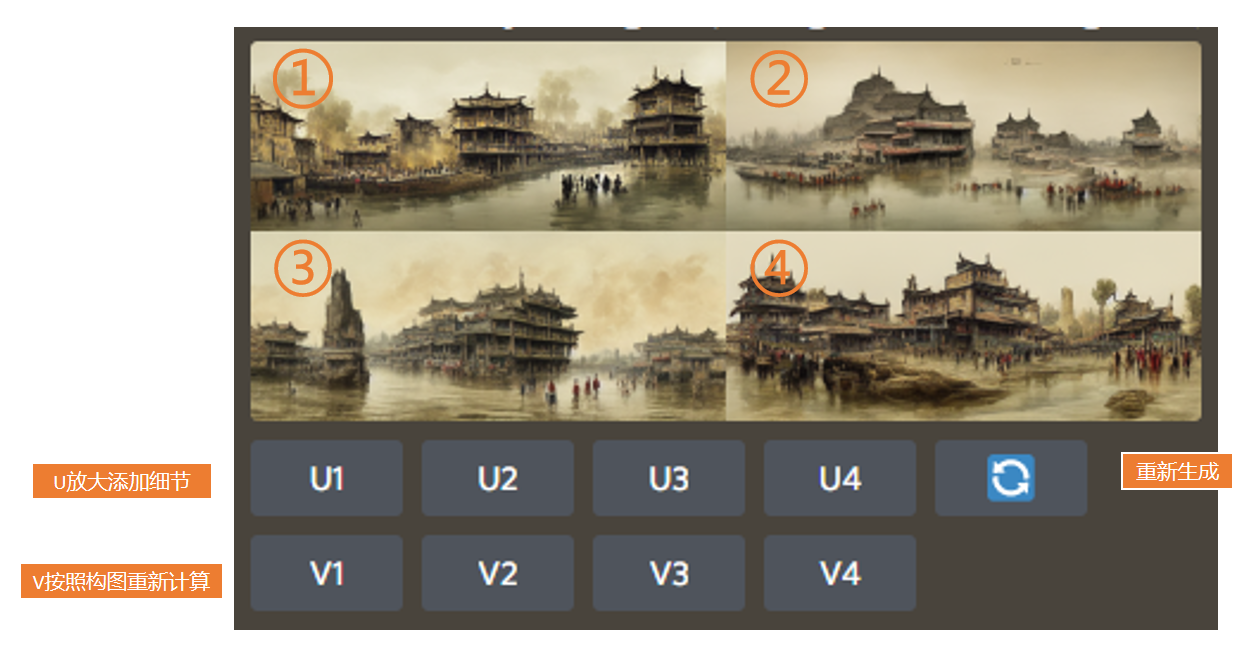
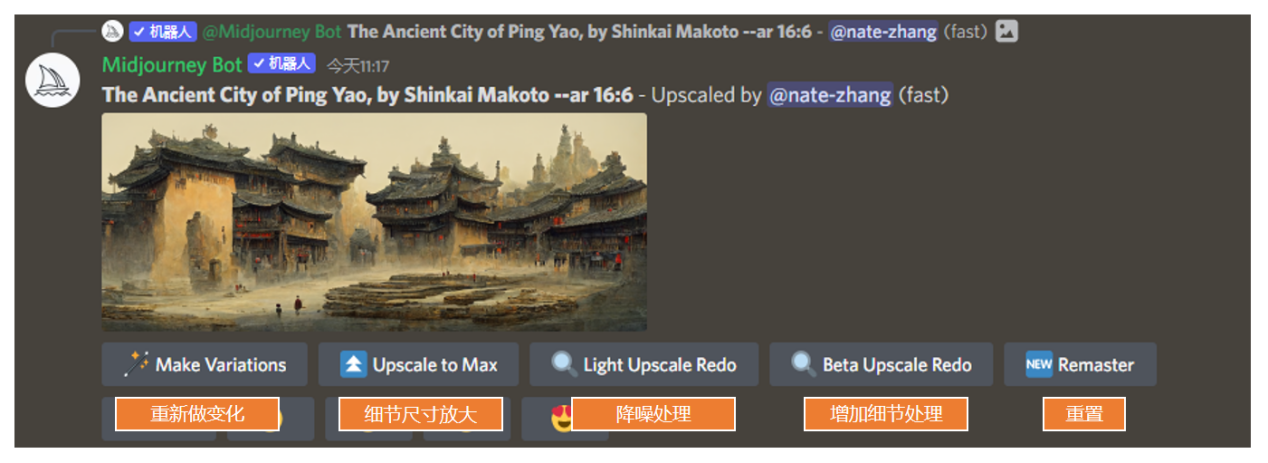
选了U放大之后,它会生成一张新的图,同时再多给你几个选项:第一个按钮是重新做变化,也就是根据当前这张的构图,它会重新生成一张差不多的图片;第二个是细节尺寸放大,也就是在U放大之后,你可以再放大一版;第三个是降噪,所谓降噪其实就是把一些细节稍微模糊掉一点,讲道理效果并不是特别好,所以我也不常用;然后是增加细节处理,你可以让图片里的细节变得更多;最后就是重制了,完全地重新制作,这也是一个新推出的功能,同样我个人觉得也不是那么好用。
下图是放大尺寸和增加细节过后的对比。可以看到,增加细节处理之后,整个画面就有点过于锐化了,这不是我们想要的效果。而且,生成这些细节更多、尺寸更大的图,耗费的时间也会更长。

如果你去社交媒体上看很多人的分享,你可能会发现他们出的图都特别精细。但其实他们一般都不是直接在Midjourney上放大的,他们会拿着AI画的图去其他平台做像素放大,又实惠又快捷,效果还更好。
除了关键词之外,其实你也可以添加网络图片的地址,或者直接上传本地的图片,让AI参考图片来绘图。
但要注意,AI可能不会去识别这张图的构图和颜色,而是试图去理解这张图里呈现出来的元素。比如深蓝色的面积比较大,那AI可能就会识别这是一片海。如果海里面有一艘很小的船,可能它就识别不出来了,或者会把它识别成一条鱼。在识别了这些元素之后,AI在后台会把它转化成关键词,然后再去生成图片。你需要明白这个功能的原理,否则可能做不到你想要的效果。

此外,AI也不能完全根据图片来生成新图,它会同时参考关键词和图片,并且有一个可调节的权重。你可以在参数里用“--iw”来调节参考图与关键词之间的权重比例,最高好像是5,也就是1:1,图片和文本的参考度对半分。

我在这里也总结了一些其他常用的参数。如“--no xxx”,其实就是在你的关键词可能会有歧义的时候用的。比如你想要一个热狗,你就可以加上“不要出现真的狗”,否则说不定AI就能给你画出来一只着了火的狗。
长宽比就很好理解,不过你们也可以试着直接输入“HD”,AI就会自动给你生成1920x1080的分辨率,很方便。
“-q X(1-5)”指的是精细度,q后面的数字越高,代表精细度越高,花费的时间也就越长。
风格化,这个数字越高,它的风格化越强,也就越平面;数字越低,那它就越接近真实。
然后是渲染停止,如果是stop50的话,那它渲染到一半就会停下来,直接输出一个半成品给你。如果你有特殊需求的话,不妨去试一试这个参数。

然后我也把一些你可能用得上的关键词分门别类总结了出来,供大家参考。值得一提的是,除了镜头的视角你可以规定之外,甚至你还可以自定义相机的品牌,比如索尼相机,或者是尼康相机等等。不同的相机品牌,它生成出来的效果也是会有细微差别的,非常好玩。
至于要添加多少关键词才合适,我想说其实很多人都不会弄一长串单词在上面,因为关键词一多,相当于就多了很多局限。虽然AI生成的图可能会更符合你想要的效果,但就会少了很多惊喜。
Midjourney最多能识别60个左右的关键词,再多它的系统就处理不过来了——当然,我想也不会有人真的放那么多词在上面吧?

然后,记得在撰写关键词的时候不要把一些前后矛盾的描述同时输入进去。这就像是跟设计说我想要一个五彩斑斓的黑一样,AI在接到这样的指令的时候也会觉得懵逼的。
另外在使用关键词的时候,也多去使用一些明确的定义,避免使用“不是xxx”这样的描述。“不是xxx”,可选择的范围就太大了,生成出来的结果可能就和你想要的相去甚远。
如果你是个新手,需要一些关于关键词的引导,那你可以去promptomania这个网站看一看。它收集了很多关键词,并且一步一步、分门别类地为你整理好了。你只需要根据网站给出的步骤,从它的关键词库里选择你想要的效果,然后把这串关键词直接复制到Midjourney里就好。把“填空题”变成“选择题”,非常方便。
下面这个工具也和上面的类似,你可以看看哪个更适合你的操作习惯。网址:点击跳转
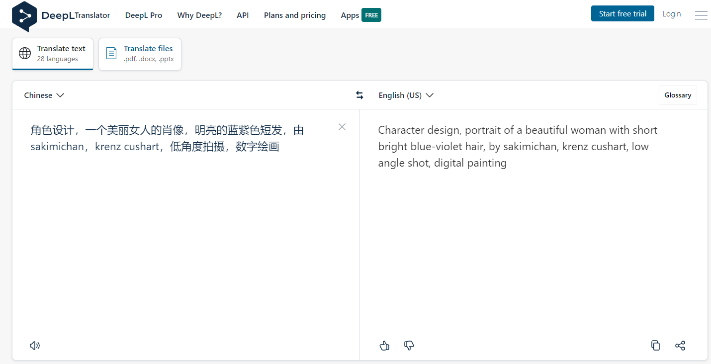
另外,如果你想把关键词准确地翻译成英文,可以试试这个网站:deepl。这个网站翻译出来的内容,比谷歌翻译更好一些,能够让AI更加准确地识别你的意思。
毕竟Midjourney是外国的平台,它对于很多词语的理解都是基于西方的理解之上的。比如我们想要一条中国龙,就不能简单地告诉它想要一只“Dragon”,而是要去描述它有蛇的身体、鱼的鳞片、鳄鱼的手足、鹿的角等等,这样可能才能得到你想要的结果。
AI绘画对我们的影响
其实AI绘画这个东西在刚出现的时候,我并没有特别大的感触。因为当时AI的技术还不过关,有的时候甚至还需要自己去改代码,出图的质量也非常糟糕,所以也不会觉得它可以替代人类做很多事。
但我没想到AI绘画的发展居然可以这么快。等到Midjourney出来了之后,忽然之间你就会觉得,这项技术好像已经非常成熟了。服装设计、插画、建筑工艺、平面设计,当然还有我们的游戏行业,或多或少都受到了它的影响。诚然,它现在还不能一下子完成一个可交付质量的东西——特别是像很多人调侃的那样:“你给我生成一个带分层的PSD文件试试啊?”但实话实说,至少对于前期的概念设计来讲,目前的AI已经相当够用了。

所以,我觉得AI绘画对一部分的插画设计从业者,冲击会比较大。因为插画这个行业,有相当一部分的甲方没有太多的审美要求,他们可能只是需要插图整体的一个效果,不需要太多细节,只要能让受众get到意思就行了。所以,有了AI绘画之后,很多工作甲方自己就可以完成,对乙方的需求量就会大大减少。
此外,我觉得AI绘画对电影行业的冲击可能也会不小。因为电影所需求的一些绘画内容,大多都集中在前期的概念阶段。这些概念图的关注点都在情绪的表达和氛围上,本身就不需要多少细节。这些工作也是可以用AI去替代的。
而对于我们游戏行业来说,因为我们对美术的要求是非常高的,所以AI绘画的冲击相对来说就不会那么大。相反,它的出现,对我们还有很多好处。
比如,它可以充当我们前期的创意工具。AI的运行原理,就是把整个互联网当做是自己的数据库,从中寻找参考,然后生成一张的新的图。而我们在做设计的时候,其实也是这样,先去搜索一些参考的素材,然后再根据自己的想法做一些概念上的融合,毕竟设计是没办法凭空产生的。因此你会发现,AI的创作思路,和我们人类的思路是相通的,那么在前期寻找创意的阶段,就可以让AI来代劳,它的效率更高,往往也能给到你惊喜。
甚至于,策划也可以利用AI来提升效率。以往策划同学和我们沟通,通常也是要自己先找几张参考图,然后告诉我们想要的感觉——但是这样毕竟不直观。现在有了AI之后,其实他就可以自己生成一些他想要的概念图直接给到我们,省去了大量的沟通成本和理解成本。后续,我们也可以直接在概念图的基础上进行修改——但要注意的是,一般来讲场景改的会比较快,但是角色类的图改起来会比较麻烦。因为如果你要动五官或者透视的话,基本相当于是重画一张图了。
AI绘画还有个好处是降低了美术的门槛,这样可以让更多的创意加入进来。因为有很多同学,其实他们有非常好的点子,但就是因为他们不会画画,所以只能通过文字来表达,或者干脆不去表达。那其实这些人就可以通过AI绘画让自己脑海里的东西具象化,大大地扩充了我们的创意来源。
当然,AI绘画目前也有一些缺点,比如目前AI生成的图片依然很随机,可能它不会一下子给到你最想要的那种感觉。当然,如果你只是想要一些创意,想让AI给自己来一点惊喜,那这算是个好处;但如果你想把AI绘画当生产力工具,融入自己的工作流当中,那出图靠运气这种事情就会很烦人了。有的时候你的关键词已经写得足够精确了,但AI就是做不出你想要的那个样子。
其次,它的艺术加成逻辑性非常差。如果你仔细观察的话,你会发现AI生成的一些结构,或者是它画面元素的一些组合其实是没有什么逻辑性的。但在我们的工作中,无论是画场景还是画角色,我们都要考虑到合理性,不是光好看就行了。
还有一个问题是,由于现在相同的关键词过于泛滥,这会导致生成的图片同质化非常严重。因为除了那些多花了20美元开通了隐私模式的“土豪”,所有其他在频道里输入的内容,大家都能看到。然后大家看到有些关键词的效果好,就一窝蜂地都在用这些关键词,这就让作品变得越来越没有新意了。
不过就像我之前说的,虽然AI绘画还有很多缺点,但它进化的速度特别快。下面是我早些时候利用Midjourney生成的,给出的关键词是《海贼王》和《火影忍者》角色的融合。可以看到效果并没有那么好,角色都显得比较畸形,有点恐怖。

但短短几个星期过去,你就很少能看到这样畸形的角色了:

而且非常强大的是,如果你就想要那种畸形、抽象的感觉,你也可以通过相关参数让AI变回去,很有意思。
所以,现在AI的缺点,也许在未来很快就会被它克服。毕竟全世界每天这么多人都在拿现成的图“喂”它,它的成长速度可能会超过我们的想象。
AI绘画的未来
前段时间有一个新闻,是关于谷歌的一个智能语音助理项目的,叫LaMDA2。有一次,一个谷歌伦理部门的工程师在跟LaMDA2对话的时候,发现这个AI似乎有了自己的意识。它觉得自己是有形态的,你问它在哪里,它还会说自己无法描述,它正处于一种虚无的状态,就好像是一个灵魂那样。这个工程师后来把他们的对话给公布了出来,前段时间也是闹得沸沸扬扬。

之所以提这个新闻,我是想说,不管你喜不喜欢,很多公司已经在研究这些我们以为未来才会出现的高智能AI了。像是《银翼杀手》里的仿生人,还有《我,机器人》里带有智慧和意识的机器人,也许在不远的将来,它们就将成为现实。别以为听上去很夸张,要知道50年前的人类,他们也无法想象一台巨大且昂贵的电脑可以被塞进一个屏幕里。而现在,我们习惯称这台电脑为iPad,而且它能便宜到很多学生都在使用。
我的意思是,科技的发展是一条不可逆的道路。大家只能去适应和学习这些新的技术,然后为自己所用,让自己更具竞争力。毕竟,不管你喜不喜欢,总是会有很多新技术正在被研究出来。
对于我们原画师来说,现在网上很流行一段话:AI不会替代原画师,但是可能会替代不会AI工具的原画师。你会AI之后,你的竞争力也会更强。就像blender刚出来的时候一样,这项新技术让很多同学的作品质量突飞猛进。
不过这也警醒了我们:还是要多关注自己的创造力。在技术工具泛滥的情况下,创造力、想象力、基本功的积累会变得更加重要。举个例子,如果你没有基本功的话,你就算拿着AI出的图给到甲方,甲方觉得有一些地方需要修改,你也是没法改的。所以不管怎么样,这些基础的能力都是不可或缺的。
还有的就是审美。AI创作出来的图,我们也要根据自己的审美能力去提炼、去判断。并不是每一张AI出的图效果都好,那它不好在哪里,好的图又是什么样的,这就依赖于你的审美能力了。否则就算AI生成了高质量的图,可能你也会拿着质量不怎么样的那一张去交差——这就会贻笑大方了。
积极地拥抱这些新事物,为自己所用,并且关注自己的独特价值与不可替代性,我觉得这是我们看待AI绘画,乃至未来所有新技术时应该有的一种态度。
欢迎关注:
