作者 | 奕艾
雷火藝術中心 原畫師
AI繪畫現在已經進化到什麼程度了?
前段時間剛剛發生的新聞,美國科羅拉多州的一個博覽會,有人用下面這幅名為《空間歌劇院》的作品拿到了博覽會數字繪畫的金獎。結果後來他表示:《空間歌劇院》是用AI生成的,他不僅沒有動過筆,甚至自己連一點繪畫的基礎都沒有!這讓其他參賽者非常不滿,他們從小辛辛苦苦練習繪畫,為了這次比賽也準備了很長時間,結果竟然被一個不會畫畫的人打敗了?

再來看看下面這三張圖,你們覺得哪一張是AI畫的呢?

答案是1。是不是已經有點傻傻分不清楚了?
AI繪畫無疑是這段時間業內最火的話題之一。而圍繞著它,大家的態度也基本分為了兩派:一派非常支持用AI進行創作;而另一派則會覺得它擾亂了這個行業,會影響很多從業者的工作。
今天,我就將帶大家瞭解目前比較火的一些AI繪畫平臺,並著重對其中我個人比較喜歡的Midjourney進行深入的操作心得講解;然後我就會聊一聊,我作為一個遊戲行業的美術工作者,在體驗了AI繪畫之後,對這項技術的一些看法,以及給大家的一些建議。
現在哪家AI最好用?
現在的AI繪畫平臺,正呈現出一種百花齊放的態勢。各個廠商都推出了自己的產品,有不少都是值得你去體驗的。
但你可能不知道的是,其實很早之前,谷歌就曾推出過自己的AI繪畫產品,在當時也有很多人嘗試。但是,谷歌AI生成圖片的時間過長,效果也不是特別好。而且,它在生成的過程中還不能讓電腦息屏,否則就會立即停止工作,必須重頭開始。它在當時沒能引起廣泛的討論,想必你也能知道是為什麼了。
至於現在的AI繪畫就不一樣了,它們方便、快捷、生成的圖片又快又好。在體驗AI繪畫的過程中,你甚至會覺得自己在玩一款很爽快的遊戲,因為它會不停地給你正反饋,讓你充滿驚喜和滿足,然後當你回過神來的時候才發現——自己已經把充值的額度給用完了。
在這裡,我主要向大家介紹3個平臺,它們應該算是我目前體驗下來的“AI三巨頭”:一個是我最喜歡的Midjourney,它在8月份的時候結束了內測,現在不需要邀請碼,每個人都可以去使用;一個是Stable Diffusion,目前也非常火;還有一個是Dall-E2,出品自OpenAI這家人工智能領域的巨頭公司。

嗯……本文在撰寫的時候Novel AI還沒有那麼火,現在感覺熱度已經趕上來了
因為後面我會著重去講Midjourney這個平臺,所以在這裡先簡單跟大家介紹一下Stable Diffusion和Dall-E2。
Stable Diffusion這個平臺挺神秘的,因為他們的技術很好,很多投資人想去投資,結果都被老闆給一一回絕了,說我們不差錢。有多不差錢呢,據說他們有4000張DGX A100頂級顯卡用於AI計算——以防你不知道,一塊A100大概需要20萬美元!難怪他們生成圖片的速度能這麼快。

此外,Stable Diffusion目前也已經開源了,所以現在很多公司都在根據他們的代碼,來開發自己的AI繪畫產品。他們的口號是“AI by the people, for the people”,意思就是“AI取之於民,用之於民”,也算是很直白地說出了AI繪畫的工作原理。
如果說Stable Diffusion是“低調神秘的慈善家”的話,那麼Dall-E2的稱號應該就是“甲方終結者”了,因為它生成的圖片更有3D感,對於平面類或者設計類的需求非常在行。繪畫感則稍差一些,所以可能不是那麼適合原畫師。
Stable Diffusion和Dall-E2還在其他方面有一些區別:比方說Dall-E2會有關鍵詞的屏蔽,不能出現一些血腥、暴力、政治相關的內容,例如某德國元首就不會出現在它生成的圖片裡,哪怕你已經很明確地把他的名字輸入給了AI;而Stable Diffusion的話就沒有這些限制,你可以讓AI給你生成一個二次元風格的元首,或者是波普風格的,隨心所欲。
Dall-E2還有個特點是,不管你的關鍵詞寫的有多奇葩,它都能把你描述的詞給放進圖裡。你們猜下面這張圖的關鍵詞是什麼?是“鍵盤俠在閱兵”,黑色的地方實際上是鍵盤。

而Stable Diffusion就只能給你畫出一個閱兵的場面,沒辦法識別出更多的意思。它是有選擇性的,並不是任何稀奇古怪的關鍵詞都給你考慮進去。

Dall-E2因為是大公司出品,我雖然不敢保證未來會發展成什麼樣,但投入給它的資源應該不會少。不過就目前而言,我個人體驗下來還是Midjourney和Stable Diffusion更加推薦一些。不過需要注意的是,如果用Stable Diffusion的話,你的花費可能會大一點,而且就算花了錢,也會有張數的限制;而Midjourney只要付30美元就不會有張數的限制了,雖然可能需要你排排隊。
除了上述提到的“三巨頭”之外,其實百度最近也推出了自己的AI繪畫產品“文心”。它最大的特點是比較能貼合我們中國自己的文化。比方說它能知道孫悟空長什麼樣,而國外的產品可能連他是個猴子都不知道。包括一些國內流行的梗,比如“雞你太美”什麼的,它也知道你在說什麼。

更經典的例子是中國菜:什麼過橋米線、獅子頭,文心理解起來毫無壓力;而國外的產品,估計真的能給你畫成一座橋,再加一個獅子的頭。
此外,它還有個優勢是擅長生成古風和二次元類的繪畫,據說有些圖的質量甚至到了可交付的程度,感興趣的同學也可以去試一試。
“最強AI”Midjourney操作指南
這一部分我們會詳細地來聊一聊Midjourney這個平臺。先說說它背後的公司:它是由大衛·霍爾茲創辦的,在做這家公司之前,他主做物體追蹤領域,當時他們的物體追蹤技術比Xbox的Kinect都要先進上好多倍。後來這家公司被收購,他就去創辦了Midjourney這個平臺。
打開Midjourney的主頁,如果你之前沒有註冊過的話,應該看到的就是下面的這張圖。Midjourney有個好處是,它是個全平臺的產品:你可以用網頁、也可以用電腦客戶端、手機上也有APP——因為等下你就會知道,它本質上其實就是個“聊天軟件”,所以多端使用對它來說不是問題。
如果你想要開始創作,可以點擊第一個“Join the beta”按鈕,就會進入到Midjourney的官方discord頻道——沒錯,我們會在這個頻道里,開始我們的創作之旅。
點開之後,你會發現下面這樣一個頁面。最左邊是好友欄,旁邊是頻道——大家可以理解為是房間,你可以到對應的房間操作一些指令;然後中間的部分則是對話框。
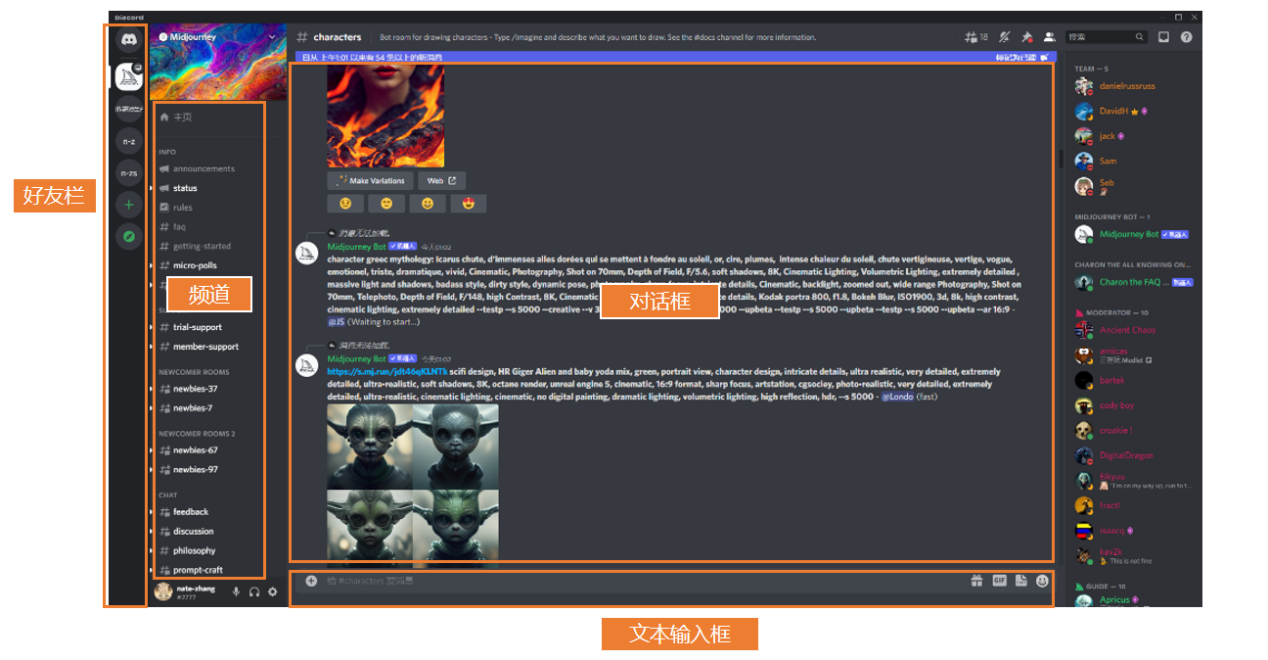
至於如何去創作?你只需要在下面的文本框裡輸入一些關鍵詞,系統就會在對話框裡發送根據關鍵詞生成的圖,快的時候可能連一分鐘都不要——沒錯,就是這麼簡單。整個的操作流程,其實都是通過discord這個聊天軟件完成的,是不是沒想到?
下面是一些基礎的指令,那些沒有接觸過AI繪畫的同學可以來參考一下:

如果大家想要生成圖片,基本上用第一個指令“/imagine”加上一些關鍵詞就好了。而“/info”,其實就是能顯示你目前賬戶狀態的一個指令。如果你沒有訂閱的話,就會顯示你還剩多少張圖可以生成。訂閱之後,會顯示你是標準版、基礎版還是企業版等等。
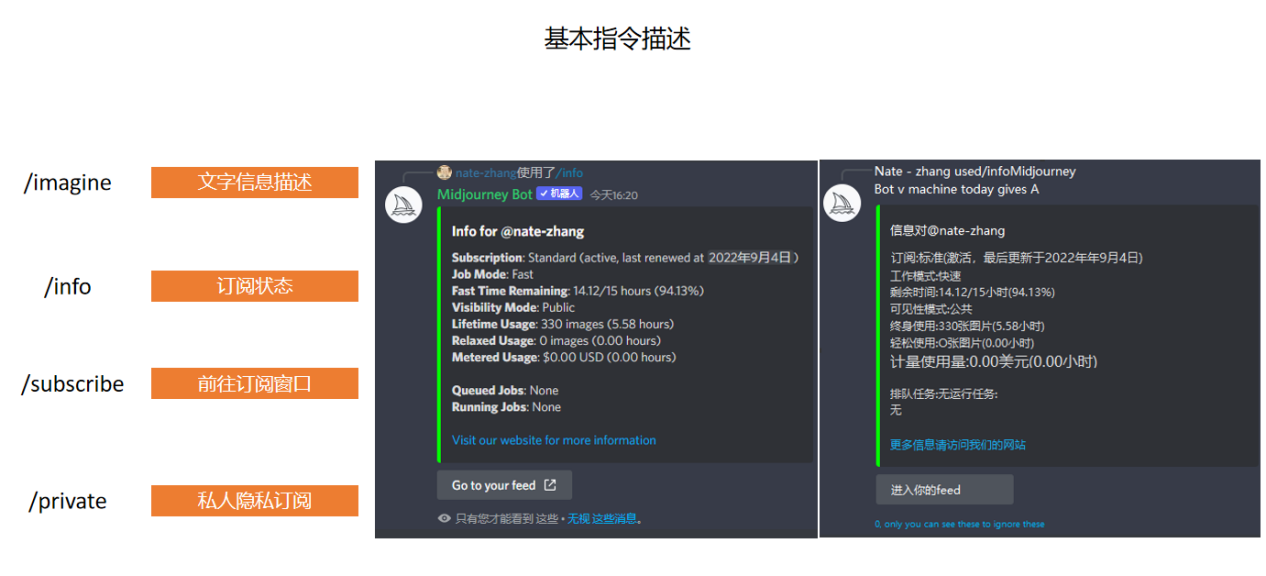
值得注意的是這個/private私人隱私訂閱。Midjourney裡的頻道,其實就相當於是一個公共的聊天室,所有人打上去的字,包括系統生成的圖,大家全都能看到。但有了隱私訂閱之後,你在頻道里輸入的東西就只對你一個人可見了。目前有不少國內的博主會選擇這個訂閱,因為他們不希望自己的關鍵詞被公開——畢竟如果別人也用了這些關鍵詞,那麼很容易就能做出類似的圖片了。
沒錯,對於目前的AI繪畫來說,關鍵詞的調教可以說是重中之重。生成的圖好不好,是不是自己想要的效果,全靠它。下面我們也會重點來說一說這個模塊。
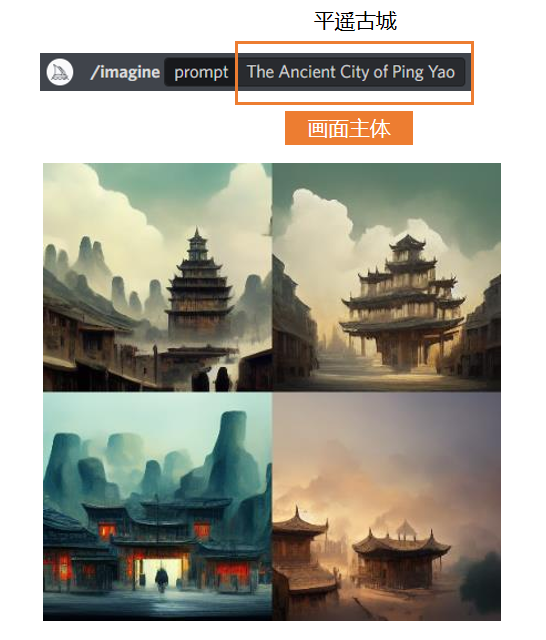
首先,你需要輸入一個你想要的主題。比如,我想要AI畫一個平遙古城,那麼我就輸入平遙古城的英文——記得,不能打拼音。你也可以直接用中文,也能識別,但是效果不保證,所以我建議大家還是去維基百科上查詢官方的英文譯名比較好。
輸入好關鍵詞,然後點擊生成。因為你沒有規定它的畫幅比例,所以它默認生成出來的圖就是1X1的,每次都會給你生成4張,效果如下:
如果想在這個基礎上增加更多想要的效果,那麼可以在主題描述不變的情況下,在後面加入一些新的關鍵詞。比如我想要晚上的平遙古城,那就加一個Night就可以。不同的關鍵詞之間可以用逗號去隔開,也可以用加號,那樣就會把兩個關鍵詞融合在一起,偶爾會出現不倫不類的情況,所以我大多數情況下還是用逗號連接。
你也可以去手動規定生成圖片的比例,比如16:9,21:9,這些都可以。或者可以用“-w”和“-h”來規定寬和高,來輸出類似1920x1080這樣精確尺寸的圖。
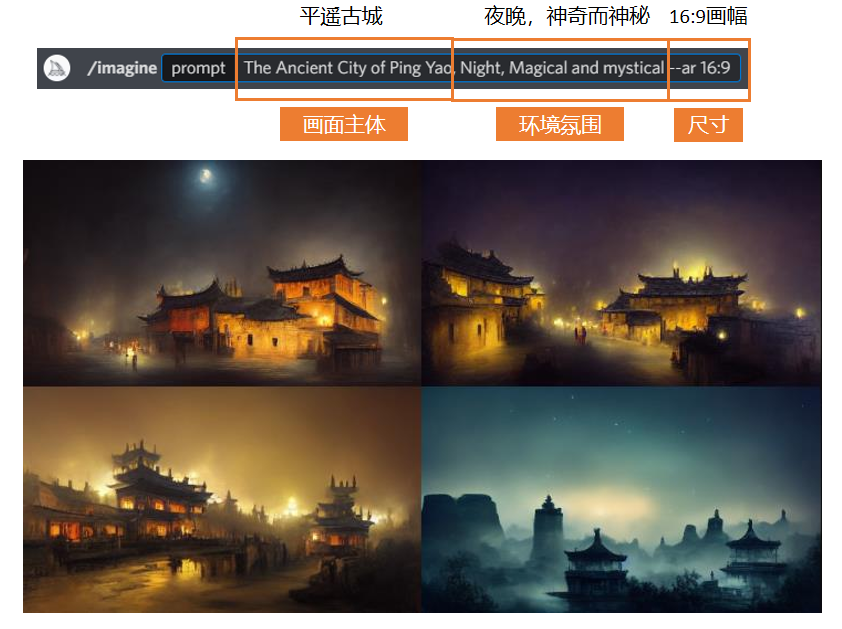
在加上Night這個關鍵詞之後,AI生成的圖片就都是晚上的平遙古城了。但因為我沒有寫明想要什麼色調,所以AI同時給出了黃色和藍色兩種色調的圖。這也是AI繪圖的一個運行邏輯:如果你沒有給AI一個明確的需求,那麼它就會對你沒有規定的部分做出一些猜測。但如果你規定了你就想要藍色的,那它就肯定不會給你生成黑色或者紅色的——它不會違揹你的命令,頂多就是有點任性。
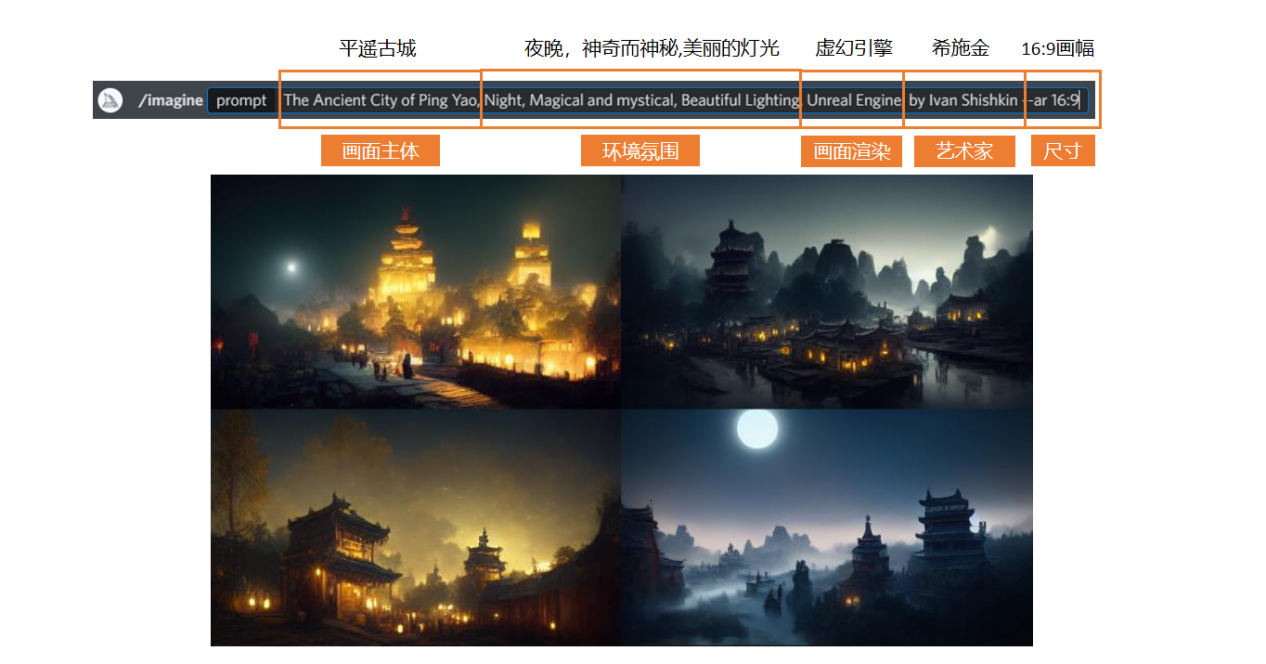
然後我們繼續去細化我們的關鍵詞。我在原有的基礎之上增加了“美麗的燈光”,然後又加了一個引擎渲染的效果,我希望它生成的圖帶有虛幻引擎的感覺——當然,如果你想要其他引擎的效果也是可以的,添加相應的關鍵詞就行。
另外,我也加了一個藝術家的名字進來,我希望畫面也能有他的風格。不過需要注意,很多時候藝術家的風格和遊戲引擎的風格是衝突的。如果藝術家本身的風格是寫實那就還好,加上虛幻引擎說不定能更加分;但如果藝術家本身是二次元風格,那還是不要強行把它們放在一起吧。
這麼調教下來的效果如下圖,個人認為還是挺令人驚喜的:
後來,我把虛幻引擎的關鍵詞去掉,然後把藝術家的名字換成了葛飾北齋,得到了下面這一組圖,效果也不錯:

不過,葛飾北齋和燈光這個關鍵詞其實是有點衝突的,如果你單純只是想要葛飾北齋的風格,那就可以把燈光這個關鍵詞給去掉,得到下面這一組圖:

另外,根據很多人的測試,好像豎畫幅的構圖更容易出片。於是我又把藝術家的名字換成了唐伯虎,再把參數裡的畫幅由橫構圖換成了豎構圖,最終得到的成品如下:

其實AI繪畫用的多了之後,你會發現AI的思維和人類的思維是很像的。譬如我們在看到一些關鍵詞的時候,其實腦海中浮現的也都是一些模糊的、整體的印象。比如提到故宮,你能想到紅色的宮牆、黃色的屋頂、大氣磅礴的中式建築這些概念,但很難想到某一個具體的圖案或者結構。AI也是類似,很多時候它就是把關鍵詞的整體感覺呈現給你,但如果你仔細觀察的話,會發現圖片在一些地方存在著雜亂的效果堆積——就跟人類在想象某個物體的時候對於細節的缺失感一樣。
不過呢,Midjourney也有對應的功能,去完善缺失的細節。下圖的“U”就是放大添加細節的功能,而“V”則是按照構圖重新計算一次,1、2、3、4則對應著四張圖片,很好理解:
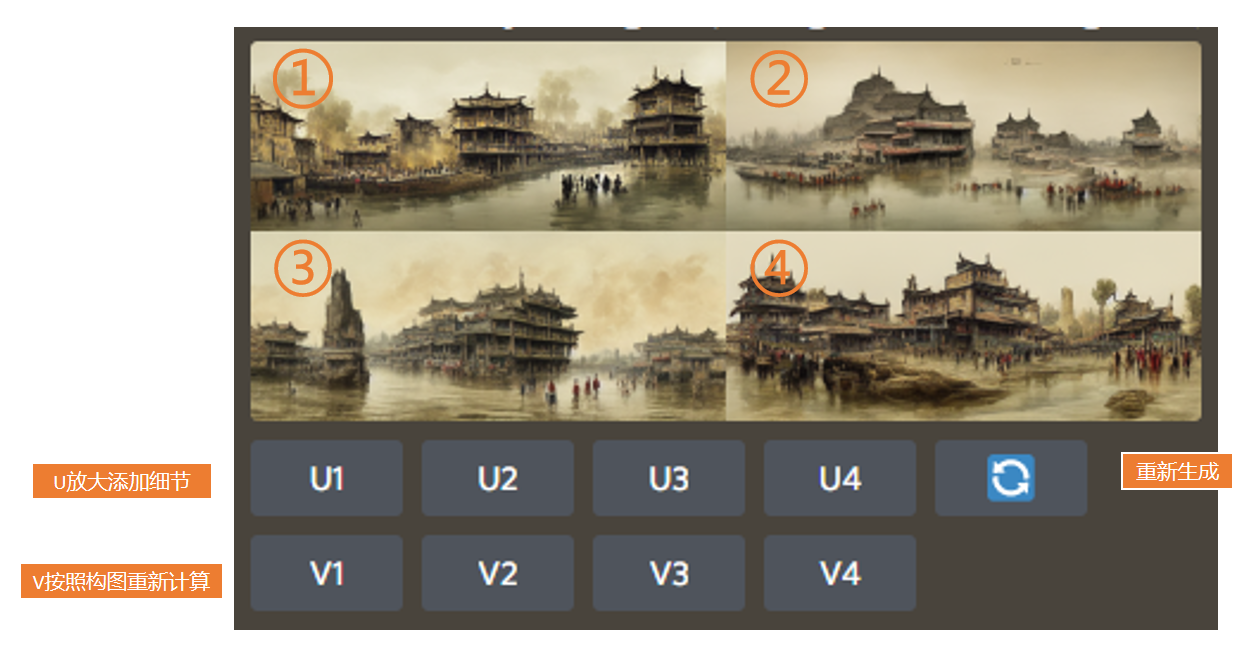
選了U放大之後,它會生成一張新的圖,同時再多給你幾個選項:第一個按鈕是重新做變化,也就是根據當前這張的構圖,它會重新生成一張差不多的圖片;第二個是細節尺寸放大,也就是在U放大之後,你可以再放大一版;第三個是降噪,所謂降噪其實就是把一些細節稍微模糊掉一點,講道理效果並不是特別好,所以我也不常用;然後是增加細節處理,你可以讓圖片裡的細節變得更多;最後就是重製了,完全地重新制作,這也是一個新推出的功能,同樣我個人覺得也不是那麼好用。
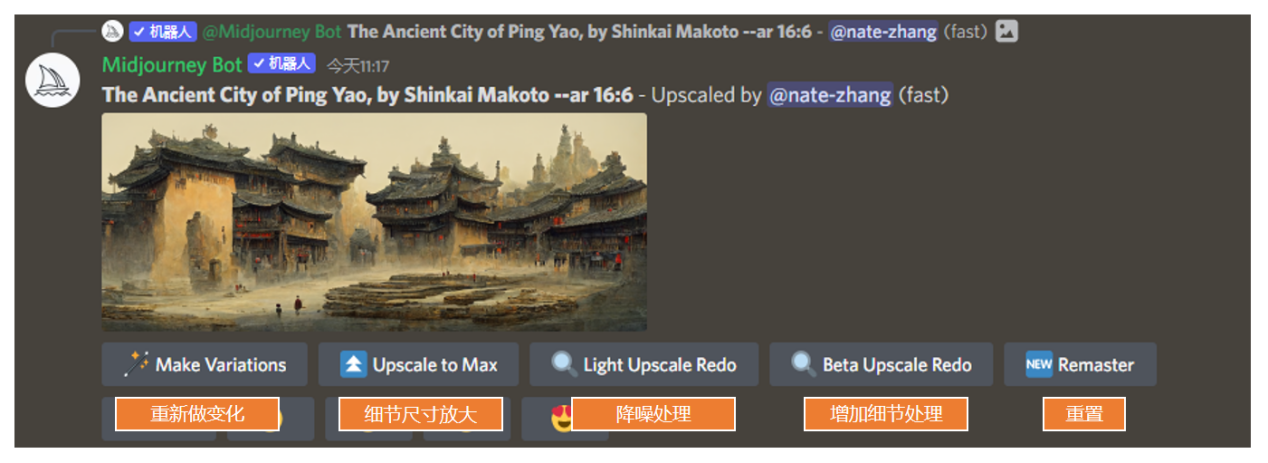
下圖是放大尺寸和增加細節過後的對比。可以看到,增加細節處理之後,整個畫面就有點過於銳化了,這不是我們想要的效果。而且,生成這些細節更多、尺寸更大的圖,耗費的時間也會更長。

如果你去社交媒體上看很多人的分享,你可能會發現他們出的圖都特別精細。但其實他們一般都不是直接在Midjourney上放大的,他們會拿著AI畫的圖去其他平臺做像素放大,又實惠又快捷,效果還更好。
除了關鍵詞之外,其實你也可以添加網絡圖片的地址,或者直接上傳本地的圖片,讓AI參考圖片來繪圖。
但要注意,AI可能不會去識別這張圖的構圖和顏色,而是試圖去理解這張圖裡呈現出來的元素。比如深藍色的面積比較大,那AI可能就會識別這是一片海。如果海里面有一艘很小的船,可能它就識別不出來了,或者會把它識別成一條魚。在識別了這些元素之後,AI在後臺會把它轉化成關鍵詞,然後再去生成圖片。你需要明白這個功能的原理,否則可能做不到你想要的效果。

此外,AI也不能完全根據圖片來生成新圖,它會同時參考關鍵詞和圖片,並且有一個可調節的權重。你可以在參數裡用“--iw”來調節參考圖與關鍵詞之間的權重比例,最高好像是5,也就是1:1,圖片和文本的參考度對半分。

我在這裡也總結了一些其他常用的參數。如“--no xxx”,其實就是在你的關鍵詞可能會有歧義的時候用的。比如你想要一個熱狗,你就可以加上“不要出現真的狗”,否則說不定AI就能給你畫出來一隻著了火的狗。
長寬比就很好理解,不過你們也可以試著直接輸入“HD”,AI就會自動給你生成1920x1080的分辨率,很方便。
“-q X(1-5)”指的是精細度,q後面的數字越高,代表精細度越高,花費的時間也就越長。
風格化,這個數字越高,它的風格化越強,也就越平面;數字越低,那它就越接近真實。
然後是渲染停止,如果是stop50的話,那它渲染到一半就會停下來,直接輸出一個半成品給你。如果你有特殊需求的話,不妨去試一試這個參數。

然後我也把一些你可能用得上的關鍵詞分門別類總結了出來,供大家參考。值得一提的是,除了鏡頭的視角你可以規定之外,甚至你還可以自定義相機的品牌,比如索尼相機,或者是尼康相機等等。不同的相機品牌,它生成出來的效果也是會有細微差別的,非常好玩。
至於要添加多少關鍵詞才合適,我想說其實很多人都不會弄一長串單詞在上面,因為關鍵詞一多,相當於就多了很多侷限。雖然AI生成的圖可能會更符合你想要的效果,但就會少了很多驚喜。
Midjourney最多能識別60個左右的關鍵詞,再多它的系統就處理不過來了——當然,我想也不會有人真的放那麼多詞在上面吧?

然後,記得在撰寫關鍵詞的時候不要把一些前後矛盾的描述同時輸入進去。這就像是跟設計說我想要一個五彩斑斕的黑一樣,AI在接到這樣的指令的時候也會覺得懵逼的。
另外在使用關鍵詞的時候,也多去使用一些明確的定義,避免使用“不是xxx”這樣的描述。“不是xxx”,可選擇的範圍就太大了,生成出來的結果可能就和你想要的相去甚遠。
如果你是個新手,需要一些關於關鍵詞的引導,那你可以去promptomania這個網站看一看。它收集了很多關鍵詞,並且一步一步、分門別類地為你整理好了。你只需要根據網站給出的步驟,從它的關鍵詞庫裡選擇你想要的效果,然後把這串關鍵詞直接複製到Midjourney裡就好。把“填空題”變成“選擇題”,非常方便。
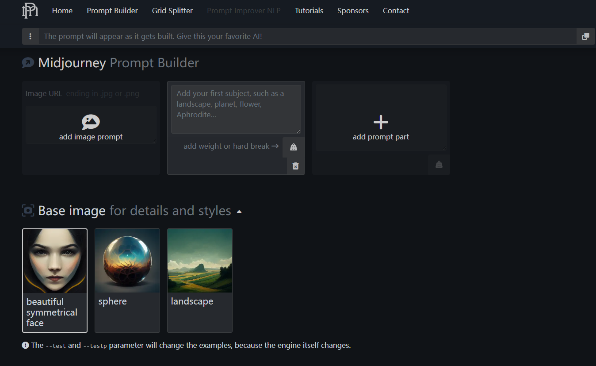
下面這個工具也和上面的類似,你可以看看哪個更適合你的操作習慣。網址:點擊跳轉
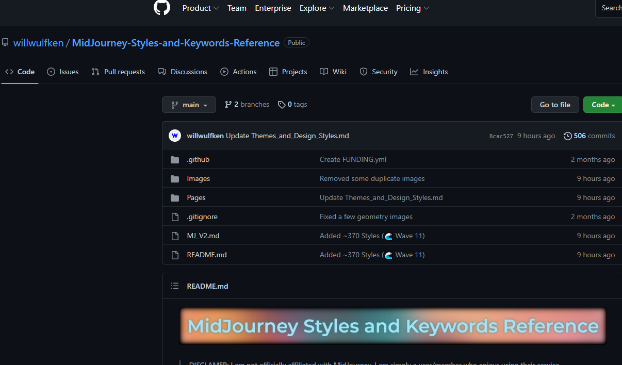
另外,如果你想把關鍵詞準確地翻譯成英文,可以試試這個網站:deepl。這個網站翻譯出來的內容,比谷歌翻譯更好一些,能夠讓AI更加準確地識別你的意思。
畢竟Midjourney是外國的平臺,它對於很多詞語的理解都是基於西方的理解之上的。比如我們想要一條中國龍,就不能簡單地告訴它想要一隻“Dragon”,而是要去描述它有蛇的身體、魚的鱗片、鱷魚的手足、鹿的角等等,這樣可能才能得到你想要的結果。
AI繪畫對我們的影響
其實AI繪畫這個東西在剛出現的時候,我並沒有特別大的感觸。因為當時AI的技術還不過關,有的時候甚至還需要自己去改代碼,出圖的質量也非常糟糕,所以也不會覺得它可以替代人類做很多事。
但我沒想到AI繪畫的發展居然可以這麼快。等到Midjourney出來了之後,忽然之間你就會覺得,這項技術好像已經非常成熟了。服裝設計、插畫、建築工藝、平面設計,當然還有我們的遊戲行業,或多或少都受到了它的影響。誠然,它現在還不能一下子完成一個可交付質量的東西——特別是像很多人調侃的那樣:“你給我生成一個帶分層的PSD文件試試啊?”但實話實說,至少對於前期的概念設計來講,目前的AI已經相當夠用了。

所以,我覺得AI繪畫對一部分的插畫設計從業者,衝擊會比較大。因為插畫這個行業,有相當一部分的甲方沒有太多的審美要求,他們可能只是需要插圖整體的一個效果,不需要太多細節,只要能讓受眾get到意思就行了。所以,有了AI繪畫之後,很多工作甲方自己就可以完成,對乙方的需求量就會大大減少。
此外,我覺得AI繪畫對電影行業的衝擊可能也會不小。因為電影所需求的一些繪畫內容,大多都集中在前期的概念階段。這些概念圖的關注點都在情緒的表達和氛圍上,本身就不需要多少細節。這些工作也是可以用AI去替代的。
而對於我們遊戲行業來說,因為我們對美術的要求是非常高的,所以AI繪畫的衝擊相對來說就不會那麼大。相反,它的出現,對我們還有很多好處。
比如,它可以充當我們前期的創意工具。AI的運行原理,就是把整個互聯網當做是自己的數據庫,從中尋找參考,然後生成一張的新的圖。而我們在做設計的時候,其實也是這樣,先去搜索一些參考的素材,然後再根據自己的想法做一些概念上的融合,畢竟設計是沒辦法憑空產生的。因此你會發現,AI的創作思路,和我們人類的思路是相通的,那麼在前期尋找創意的階段,就可以讓AI來代勞,它的效率更高,往往也能給到你驚喜。
甚至於,策劃也可以利用AI來提升效率。以往策劃同學和我們溝通,通常也是要自己先找幾張參考圖,然後告訴我們想要的感覺——但是這樣畢竟不直觀。現在有了AI之後,其實他就可以自己生成一些他想要的概念圖直接給到我們,省去了大量的溝通成本和理解成本。後續,我們也可以直接在概念圖的基礎上進行修改——但要注意的是,一般來講場景改的會比較快,但是角色類的圖改起來會比較麻煩。因為如果你要動五官或者透視的話,基本相當於是重畫一張圖了。
AI繪畫還有個好處是降低了美術的門檻,這樣可以讓更多的創意加入進來。因為有很多同學,其實他們有非常好的點子,但就是因為他們不會畫畫,所以只能通過文字來表達,或者乾脆不去表達。那其實這些人就可以通過AI繪畫讓自己腦海裡的東西具象化,大大地擴充了我們的創意來源。
當然,AI繪畫目前也有一些缺點,比如目前AI生成的圖片依然很隨機,可能它不會一下子給到你最想要的那種感覺。當然,如果你只是想要一些創意,想讓AI給自己來一點驚喜,那這算是個好處;但如果你想把AI繪畫當生產力工具,融入自己的工作流當中,那出圖靠運氣這種事情就會很煩人了。有的時候你的關鍵詞已經寫得足夠精確了,但AI就是做不出你想要的那個樣子。
其次,它的藝術加成邏輯性非常差。如果你仔細觀察的話,你會發現AI生成的一些結構,或者是它畫面元素的一些組合其實是沒有什麼邏輯性的。但在我們的工作中,無論是畫場景還是畫角色,我們都要考慮到合理性,不是光好看就行了。
還有一個問題是,由於現在相同的關鍵詞過於氾濫,這會導致生成的圖片同質化非常嚴重。因為除了那些多花了20美元開通了隱私模式的“土豪”,所有其他在頻道里輸入的內容,大家都能看到。然後大家看到有些關鍵詞的效果好,就一窩蜂地都在用這些關鍵詞,這就讓作品變得越來越沒有新意了。
不過就像我之前說的,雖然AI繪畫還有很多缺點,但它進化的速度特別快。下面是我早些時候利用Midjourney生成的,給出的關鍵詞是《海賊王》和《火影忍者》角色的融合。可以看到效果並沒有那麼好,角色都顯得比較畸形,有點恐怖。

但短短几個星期過去,你就很少能看到這樣畸形的角色了:

而且非常強大的是,如果你就想要那種畸形、抽象的感覺,你也可以通過相關參數讓AI變回去,很有意思。
所以,現在AI的缺點,也許在未來很快就會被它克服。畢竟全世界每天這麼多人都在拿現成的圖“喂”它,它的成長速度可能會超過我們的想象。
AI繪畫的未來
前段時間有一個新聞,是關於谷歌的一個智能語音助理項目的,叫LaMDA2。有一次,一個谷歌倫理部門的工程師在跟LaMDA2對話的時候,發現這個AI似乎有了自己的意識。它覺得自己是有形態的,你問它在哪裡,它還會說自己無法描述,它正處於一種虛無的狀態,就好像是一個靈魂那樣。這個工程師後來把他們的對話給公佈了出來,前段時間也是鬧得沸沸揚揚。

之所以提這個新聞,我是想說,不管你喜不喜歡,很多公司已經在研究這些我們以為未來才會出現的高智能AI了。像是《銀翼殺手》裡的仿生人,還有《我,機器人》裡帶有智慧和意識的機器人,也許在不遠的將來,它們就將成為現實。別以為聽上去很誇張,要知道50年前的人類,他們也無法想象一臺巨大且昂貴的電腦可以被塞進一個屏幕裡。而現在,我們習慣稱這臺電腦為iPad,而且它能便宜到很多學生都在使用。
我的意思是,科技的發展是一條不可逆的道路。大家只能去適應和學習這些新的技術,然後為自己所用,讓自己更具競爭力。畢竟,不管你喜不喜歡,總是會有很多新技術正在被研究出來。
對於我們原畫師來說,現在網上很流行一段話:AI不會替代原畫師,但是可能會替代不會AI工具的原畫師。你會AI之後,你的競爭力也會更強。就像blender剛出來的時候一樣,這項新技術讓很多同學的作品質量突飛猛進。
不過這也警醒了我們:還是要多關注自己的創造力。在技術工具氾濫的情況下,創造力、想象力、基本功的積累會變得更加重要。舉個例子,如果你沒有基本功的話,你就算拿著AI出的圖給到甲方,甲方覺得有一些地方需要修改,你也是沒法改的。所以不管怎麼樣,這些基礎的能力都是不可或缺的。
還有的就是審美。AI創作出來的圖,我們也要根據自己的審美能力去提煉、去判斷。並不是每一張AI出的圖效果都好,那它不好在哪裡,好的圖又是什麼樣的,這就依賴於你的審美能力了。否則就算AI生成了高質量的圖,可能你也會拿著質量不怎麼樣的那一張去交差——這就會貽笑大方了。
積極地擁抱這些新事物,為自己所用,並且關注自己的獨特價值與不可替代性,我覺得這是我們看待AI繪畫,乃至未來所有新技術時應該有的一種態度。
歡迎關注:
