自從1.20日DeepSeek官宣發佈並開源他們的R1以來,大模型二年來頗受制約的應用成本問題,在R1展現出卓越的性價比面前,讓全世界看到了新一種可能。
很多小夥伴因為設備或者硬件或者技術原因無法本地部署AI大模型,或者部署了也是因為設備硬件限制而不能滿血使用,那麼api就是一個最好的方法。
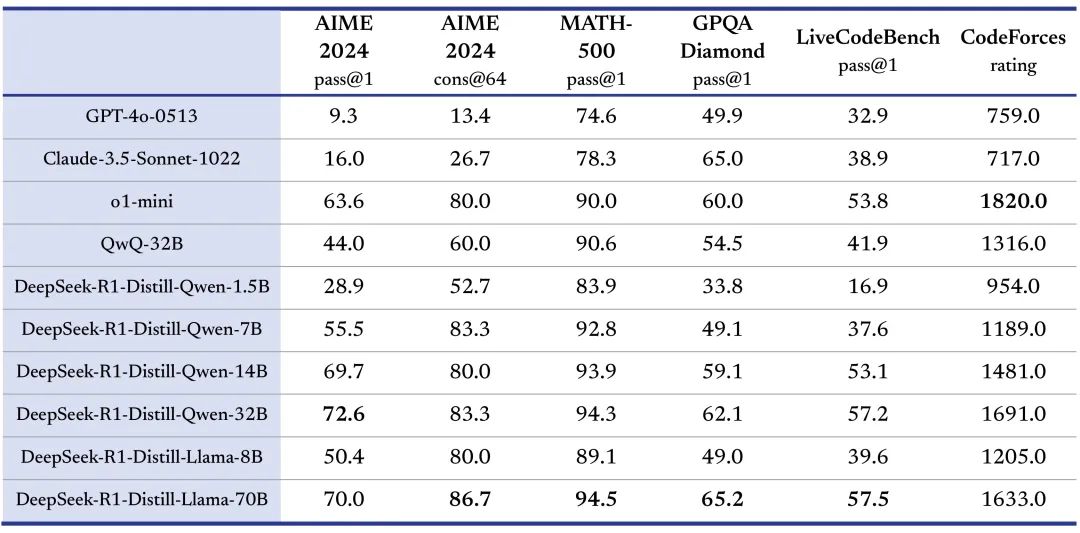
DeepSeek同步發佈了6個蒸餾小模型,通過 DeepSeek-R1 的輸出,蒸餾了 6 個小模型開源給社區,其中 32B 和 70B 模型在多項能力上實現了對標 OpenAI o1-mini 的效果,而最小的基於Qwen2.5的1.5B小模型無需GPU,用CPU就可以實現流暢的生成輸出:
於是這幾天看到很多本地部署DeepSeek小模型的攻略文章、視頻。得益於這兩年大模型開源社區的發展,ollama這種推理框架,基本上可以無坑地用一行命令就同時完成模型下載與運行,幾個G的模型數據也就是十來分鐘能下完(下載網速能到十幾M/S):

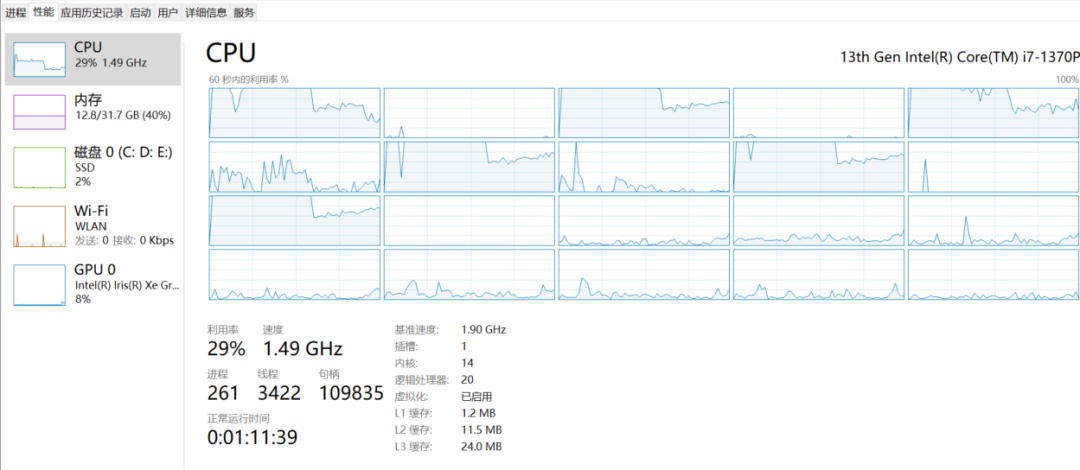
這次DeepSeek蒸餾出來最小的1.5B、7B的模型用ollama跑起來,純用cpu(i7 20個邏輯核,利用率40%以下,內存佔用與模型文件差不多大小),輸出速度與官網應用差不多:
但是,如果要本地安裝對標 OpenAI o1-mini 的效果32B、70B的模型,對機器資源就大大增加了,更重要的是這兩個基礎模型 Qwen2.5 32B和Llama3.3 70B,雖然是當下企業私有化部署開源大模型的主流,但正常使用他們的運行成本之高不是一般能接受的(人均萬元)。所以一般入坑大模型應用開發,建議直接使用線上的API,除了有免費的模型,收費的也就是幾塊錢/幾十塊錢,而且這些平臺的API基本上與OpenAI保持兼容:
平臺名稱
DeepSeek https://platform.deepseek.com/usage
智譜AI https://www.zhipuai.cn/
百度千帆https://qianfan.cloud.baidu.com/
阿里靈積https://dashscope.console.aliyun.com/usage_dashboard火山方舟https://www.volcengine.com/product/ark
騰訊混元https://hunyuan.tencent.com/
零一萬物大模型開放平臺https://platform.lingyiwanwu.com/
360智腦-API開放平臺https://ai.360.com/platform/accountMiniMaxhttps://api.minimax.chat/
訊飛開放https://console.xfyun.cn/app/myappMoonshot AIhttps://platform.moonshot.cn/docs
階躍星辰https://www.stepfun.com/
百川大模型https://platform.baichuan-ai.com/homePage
商湯萬象https://www.sensecore.cn/
紫東太初https://ai-maas.wair.ac.cn/
以上平臺大部分只是提供自家大模型的API訪問,但象百度千帆、火山方舟、阿里靈積,是所謂的MaaS平臺,提供開源或其他廠商的大模型服務。
如果想要訪問世界頂級大模型的API(官網一般封禁中國IP訪問),可以使用OpenRouter之類的AI雲平臺。
