自从1.20日DeepSeek官宣发布并开源他们的R1以来,大模型二年来颇受制约的应用成本问题,在R1展现出卓越的性价比面前,让全世界看到了新一种可能。
很多小伙伴因为设备或者硬件或者技术原因无法本地部署AI大模型,或者部署了也是因为设备硬件限制而不能满血使用,那么api就是一个最好的方法。
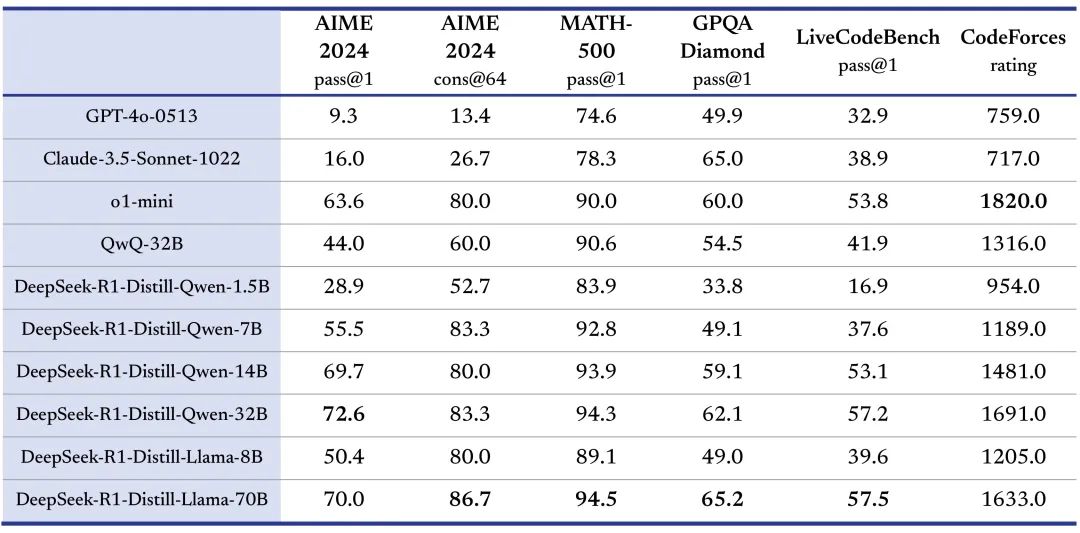
DeepSeek同步发布了6个蒸馏小模型,通过 DeepSeek-R1 的输出,蒸馏了 6 个小模型开源给社区,其中 32B 和 70B 模型在多项能力上实现了对标 OpenAI o1-mini 的效果,而最小的基于Qwen2.5的1.5B小模型无需GPU,用CPU就可以实现流畅的生成输出:
于是这几天看到很多本地部署DeepSeek小模型的攻略文章、视频。得益于这两年大模型开源社区的发展,ollama这种推理框架,基本上可以无坑地用一行命令就同时完成模型下载与运行,几个G的模型数据也就是十来分钟能下完(下载网速能到十几M/S):

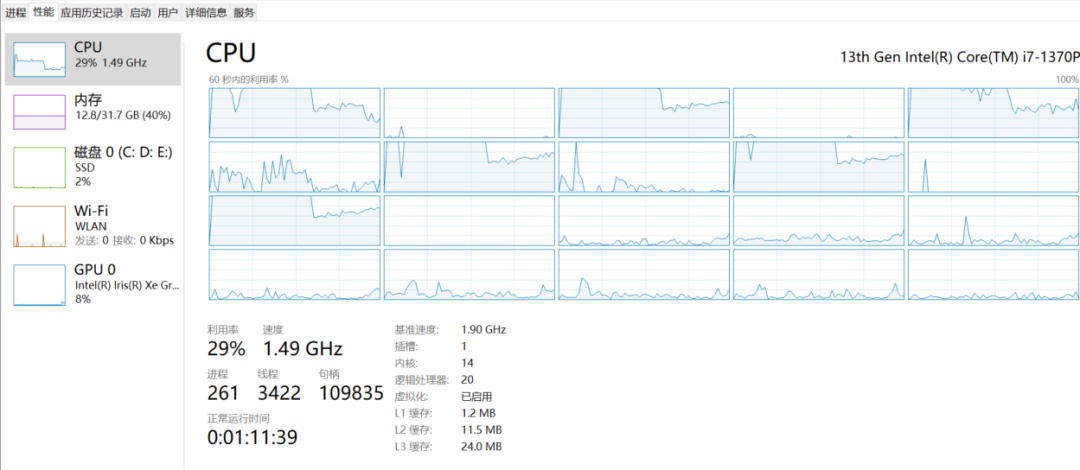
这次DeepSeek蒸馏出来最小的1.5B、7B的模型用ollama跑起来,纯用cpu(i7 20个逻辑核,利用率40%以下,内存占用与模型文件差不多大小),输出速度与官网应用差不多:
但是,如果要本地安装对标 OpenAI o1-mini 的效果32B、70B的模型,对机器资源就大大增加了,更重要的是这两个基础模型 Qwen2.5 32B和Llama3.3 70B,虽然是当下企业私有化部署开源大模型的主流,但正常使用他们的运行成本之高不是一般能接受的(人均万元)。所以一般入坑大模型应用开发,建议直接使用线上的API,除了有免费的模型,收费的也就是几块钱/几十块钱,而且这些平台的API基本上与OpenAI保持兼容:
平台名称
DeepSeek https://platform.deepseek.com/usage
智谱AI https://www.zhipuai.cn/
百度千帆https://qianfan.cloud.baidu.com/
阿里灵积https://dashscope.console.aliyun.com/usage_dashboard火山方舟https://www.volcengine.com/product/ark
腾讯混元https://hunyuan.tencent.com/
零一万物大模型开放平台https://platform.lingyiwanwu.com/
360智脑-API开放平台https://ai.360.com/platform/accountMiniMaxhttps://api.minimax.chat/
讯飞开放https://console.xfyun.cn/app/myappMoonshot AIhttps://platform.moonshot.cn/docs
阶跃星辰https://www.stepfun.com/
百川大模型https://platform.baichuan-ai.com/homePage
商汤万象https://www.sensecore.cn/
紫东太初https://ai-maas.wair.ac.cn/
以上平台大部分只是提供自家大模型的API访问,但象百度千帆、火山方舟、阿里灵积,是所谓的MaaS平台,提供开源或其他厂商的大模型服务。
如果想要访问世界顶级大模型的API(官网一般封禁中国IP访问),可以使用OpenRouter之类的AI云平台。
