2025年3月6日消息,素有計算機屆諾獎之稱的圖靈獎,在今天正式公開了2024年的獲獎名單,獲獎者是強化學習之父 Richard Sutton 和他的博士導師 Andrew Barto,圖靈獎表彰他們在強化學習上取得的成就!上世紀80年代,師徒二人對強化學習(RL)的理論重構與算法創新,徹底改變了AI領域的發展軌跡,給AlphaGo、ChatGPT這些突破性技術奠定基礎,機器人技術、芯片設計等尖端領域同樣受益於Sutton的強化學習成果!

01 ACM圖靈獎
在計算機科學的世界裡,圖靈獎是至高無上的“殿堂”,由美國計算機協會(ACM)設立,旨在表彰對計算機科學有重大且持久貢獻的個人,獎項以著名的科學家艾倫·圖靈(Alan Turing)命名,圖靈本人是理論計算機科學和人工智能的奠基人!

計算機科學是一門新興學科,自從1966年設立圖靈以來,獲獎者涵蓋了算法、數據庫、人工智能、計算機體系結構等多個領域,截至 2024 年,已有 77 人獲獎,其中科學家姚期智,成為首位華裔圖靈獎得主。2024年圖靈獎頒給了Barto和Sutton師徒,也是自2018年深度學習三巨頭獲獎後,AI領域再次摘得“計算機界諾貝爾獎”。

02 強化學習之父
Richard Sutton(理查德·薩頓)是近年來全球最知名的科學家之一,被譽為“強化學習之父”,Sutton於1978年在斯坦福大學獲得心理學學士學位,隨在馬薩諸塞大學阿默斯特分校攻讀計算機與信息科學碩士及博士學位,師從Andrew Barto教授。

師傅Barto現年76歲,畢業於密歇根大學數學系,一開始主要研究船舶建築與工程,80年代,他與學生Sutton開始探索人類的神經元,轉向用計算機和數學來模擬人類的大腦,Sutton的博士論文《Temporal Credit Assignment in Reinforcement Learning》(強化學習中的時間學分分配),一共有210頁,提出了評價器結構和"時間信用分配"概念,將強化學習從理念轉化為以數學為基礎的理論框架。
03 AI入門聖經
接下來的90年代,Barto師徒圍繞著Sutton博士論文中的強化學習繼續延伸,以馬爾可夫決策過程(MDP)為核心構建了完整的強化學習模型,傳統的模式識別主要依靠靜態數據,而Sutton的強化學習過程借鑑了心理學中動物試錯學習調整行為機制,將心理學中的“延遲滿足”概念數學化。
Sutton提出用最大化長期累積獎勵取代即時回報的策略,來優化任務目標,1998年,師徒二人合著了《強化學習導論》,整合了MDP、探索-利用權衡等理論,並通過各種通俗易懂的例子進行算法實現,降低學習門檻,教材被引用超8萬次,成為全球研究者的“AI入門聖經”!

04 AlphaGo的誕生
在大模型爆發前,人們對AI最火的印象就是AlphaGo,當時AlphaGo直接擊敗了世界冠軍李世石和柯潔,而Sutton的強化學習直接啟發了AlphaGo的誕生。圍棋極為複雜,DeepMind公司用蒙特卡洛樹對圍棋龐大的龐大搜索空間進行高效決策,深度神經網絡DNN用來評估棋局狀態,同時預測下一步的最佳走法。

強化學習則是AlphaGo最強的武功秘籍,可以通過自我對弈不斷優化策略,讓狗在沒有人類指導的情況下也能變得更強,這種延遲獎勵機制的優化目標與強化學習中“最大化長期累積獎勵”的目標一致,DeepMind團隊哈薩比斯也曾明確表示他們的工作主要就是受到Sutton的影響。

05 啟發ChatGPT
GPT系列模型能夠取得成功核心同樣也依賴強化學習,這裡用到了強化學習中的人類反饋強化學習(RLHF)機制,實現上非常簡單,首先是預訓練階段,GPT 模型首先在大規模文本數據上進行無監督學習,掌握語言的基本統計規律,形成一個基礎語言模型。
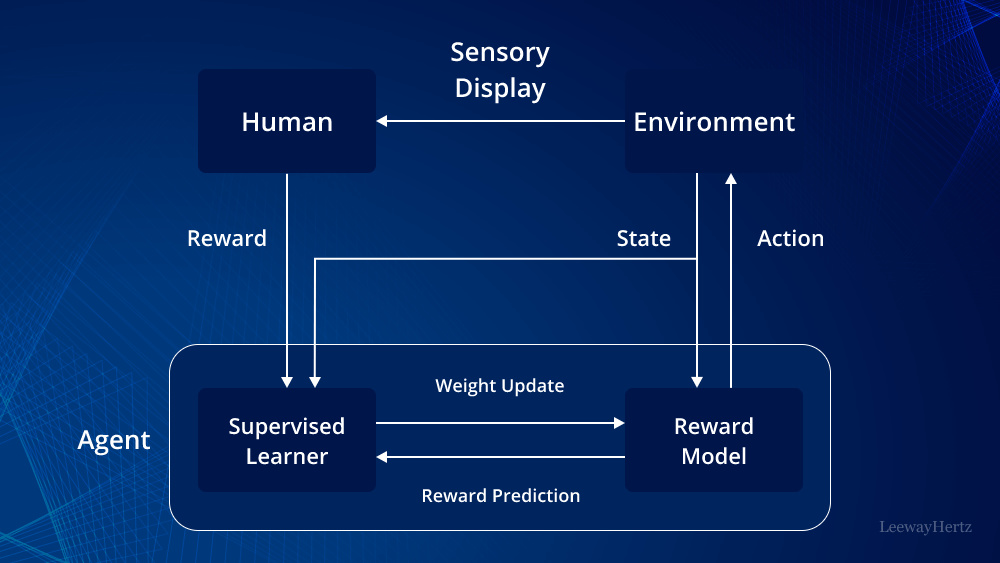
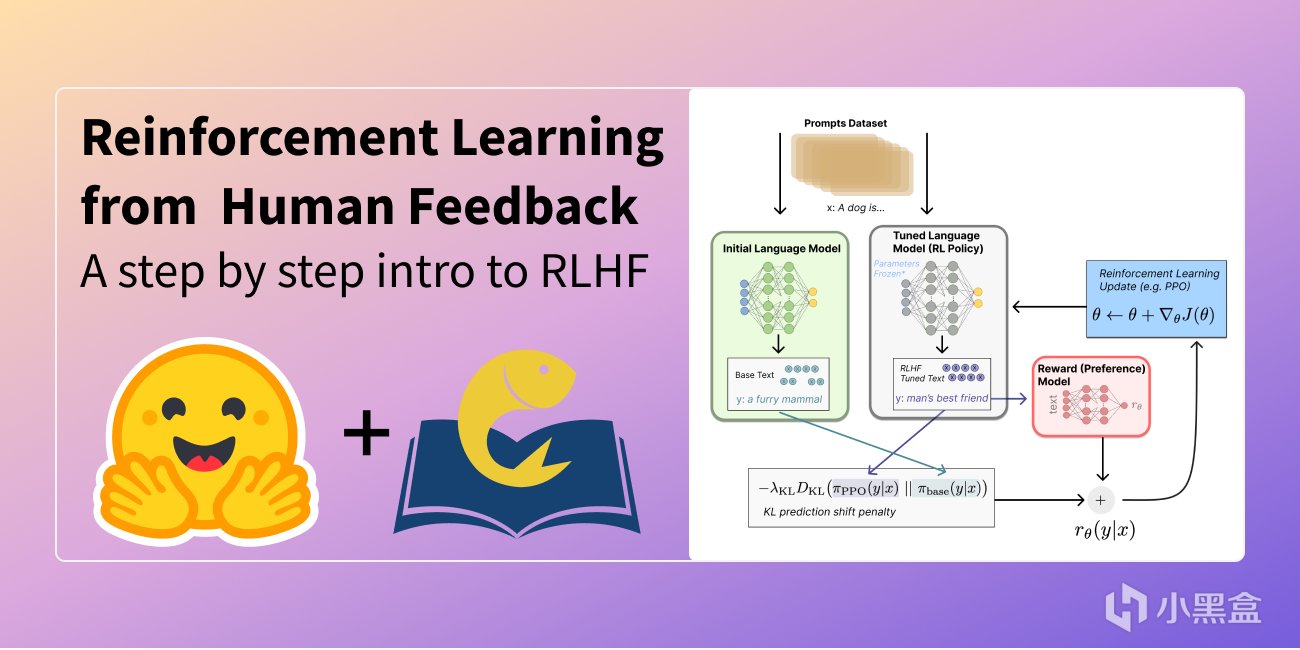
然後進行監督微調SFT,在預訓練的基礎上,將高質量問答數據模型與人類表達習慣初步對齊,讓生成的回答更貼近人類對話的風格和需求;隨後再進行獎勵模型訓練,通過人類標註的偏好數據構建獎勵函數,評估模型輸出質量,評分越高表示越符合人類偏好。
最後再利用強化學習算法優化,比如近端策略優化算法(PPO)以獎勵模型的評分作為獎勵信號,調整 GPT 模型的生成策略,模型通過不斷生成回答並接收反饋,逐步優化以最大化累積獎勵,生成更高質量的文本。大模型發展到今天,強化學習同樣功不可沒。
06 圖靈祖師爺
這次Sutton獲得圖靈獎也有說法,因為強化學習和祖師爺圖靈也有淵源,1950年,圖靈在發表的經典論文《Computing Machinery and Intelligence》中,提出了一個影響深遠的問題:“機器能思考嗎?”。這篇論文不僅引入了著名的圖靈測試(用於評估機器是否具有類似人類的智能),還探討了機器學習的可能性。

當時圖靈設想了一種方法,讓機器通過類似人類或動物的學習方式,從環境中獲取知識並改進自身行為。其中,他特別提到了一種基於獎懲機制的機器學習方法。這種方法的核心在於,機器可以通過接收獎勵(正反饋)或懲罰(負反饋),調整自己的行為,以實現更好的性能,這一思想在當時是非常超前的,因為1950年的計算機科學和人工智能領域尚處於萌芽階段。

近年來,人工智能領域不斷取得重大進展,同時還憑藉一系列重要獎項得到了全球的廣泛認可,2018年深度學習三巨頭獲得圖靈獎,2024年辛頓獲得諾貝爾物理學獎、哈薩比斯獲得諾貝爾化學獎、Sutton師徒獲得圖靈獎。圖靈當年的設想,如今正通過深度學習、強化學習等技術逐步實現,在多個領域開花結果。

DeepSeek——最新論文解讀,梁文鋒大佬親自署名!
DeepSeek——創始人碩士學位論文賞析 [精讀]
深度學習入門——圖靈獎AI三巨頭
AI編年史——深度學習的發展史(收藏向)
AI編年史2——GPT是如何誕生的?
AI學術巨佬——何愷明,從遊戲中獲得論文靈感
AI領軍人物——孫劍,重劍無鋒的經典之作
AI傳奇巨佬——湯曉鷗,中國人工智能領袖人物!
AI女神李飛飛——從成都七中,到頂級AI科學家!
AI教父辛頓——一文帶你瞭解機器學習,AI教父的成長史!
山姆·奧特曼——從遊戲編程,到OpenAI之父!
張益唐——黎曼猜想,華人數學家再創重大突破!
B站大學——線代不掛科,MIT傳奇教授的最後一課!
華為——盤古大模型解讀,專注“小模型”工業落地!
英偉達——跟著老黃學AI,英偉達官方免費推出AI課!
微軟免費AI課程——18節課,初學者入門大模型!
機器學習——科學家周志華,成為中國首位AI頂會掌門人!
機器學習入門——數學基礎(積分篇)
機器學習入門——數學基礎(代數篇)
機器學習入門——數學基礎(貝葉斯篇)
#gd的ai&遊戲雜談#