2025年3月6日消息,素有计算机届诺奖之称的图灵奖,在今天正式公开了2024年的获奖名单,获奖者是强化学习之父 Richard Sutton 和他的博士导师 Andrew Barto,图灵奖表彰他们在强化学习上取得的成就!上世纪80年代,师徒二人对强化学习(RL)的理论重构与算法创新,彻底改变了AI领域的发展轨迹,给AlphaGo、ChatGPT这些突破性技术奠定基础,机器人技术、芯片设计等尖端领域同样受益于Sutton的强化学习成果!

01 ACM图灵奖
在计算机科学的世界里,图灵奖是至高无上的“殿堂”,由美国计算机协会(ACM)设立,旨在表彰对计算机科学有重大且持久贡献的个人,奖项以著名的科学家艾伦·图灵(Alan Turing)命名,图灵本人是理论计算机科学和人工智能的奠基人!

计算机科学是一门新兴学科,自从1966年设立图灵以来,获奖者涵盖了算法、数据库、人工智能、计算机体系结构等多个领域,截至 2024 年,已有 77 人获奖,其中科学家姚期智,成为首位华裔图灵奖得主。2024年图灵奖颁给了Barto和Sutton师徒,也是自2018年深度学习三巨头获奖后,AI领域再次摘得“计算机界诺贝尔奖”。

02 强化学习之父
Richard Sutton(理查德·萨顿)是近年来全球最知名的科学家之一,被誉为“强化学习之父”,Sutton于1978年在斯坦福大学获得心理学学士学位,随在马萨诸塞大学阿默斯特分校攻读计算机与信息科学硕士及博士学位,师从Andrew Barto教授。

师傅Barto现年76岁,毕业于密歇根大学数学系,一开始主要研究船舶建筑与工程,80年代,他与学生Sutton开始探索人类的神经元,转向用计算机和数学来模拟人类的大脑,Sutton的博士论文《Temporal Credit Assignment in Reinforcement Learning》(强化学习中的时间学分分配),一共有210页,提出了评价器结构和"时间信用分配"概念,将强化学习从理念转化为以数学为基础的理论框架。
03 AI入门圣经
接下来的90年代,Barto师徒围绕着Sutton博士论文中的强化学习继续延伸,以马尔可夫决策过程(MDP)为核心构建了完整的强化学习模型,传统的模式识别主要依靠静态数据,而Sutton的强化学习过程借鉴了心理学中动物试错学习调整行为机制,将心理学中的“延迟满足”概念数学化。
Sutton提出用最大化长期累积奖励取代即时回报的策略,来优化任务目标,1998年,师徒二人合著了《强化学习导论》,整合了MDP、探索-利用权衡等理论,并通过各种通俗易懂的例子进行算法实现,降低学习门槛,教材被引用超8万次,成为全球研究者的“AI入门圣经”!

04 AlphaGo的诞生
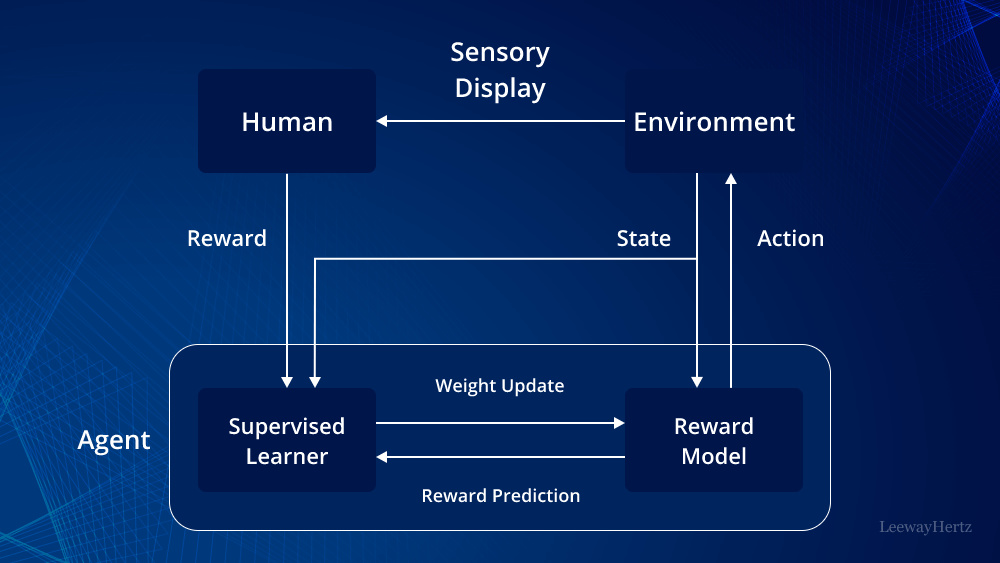
在大模型爆发前,人们对AI最火的印象就是AlphaGo,当时AlphaGo直接击败了世界冠军李世石和柯洁,而Sutton的强化学习直接启发了AlphaGo的诞生。围棋极为复杂,DeepMind公司用蒙特卡洛树对围棋庞大的庞大搜索空间进行高效决策,深度神经网络DNN用来评估棋局状态,同时预测下一步的最佳走法。

强化学习则是AlphaGo最强的武功秘籍,可以通过自我对弈不断优化策略,让狗在没有人类指导的情况下也能变得更强,这种延迟奖励机制的优化目标与强化学习中“最大化长期累积奖励”的目标一致,DeepMind团队哈萨比斯也曾明确表示他们的工作主要就是受到Sutton的影响。

05 启发ChatGPT
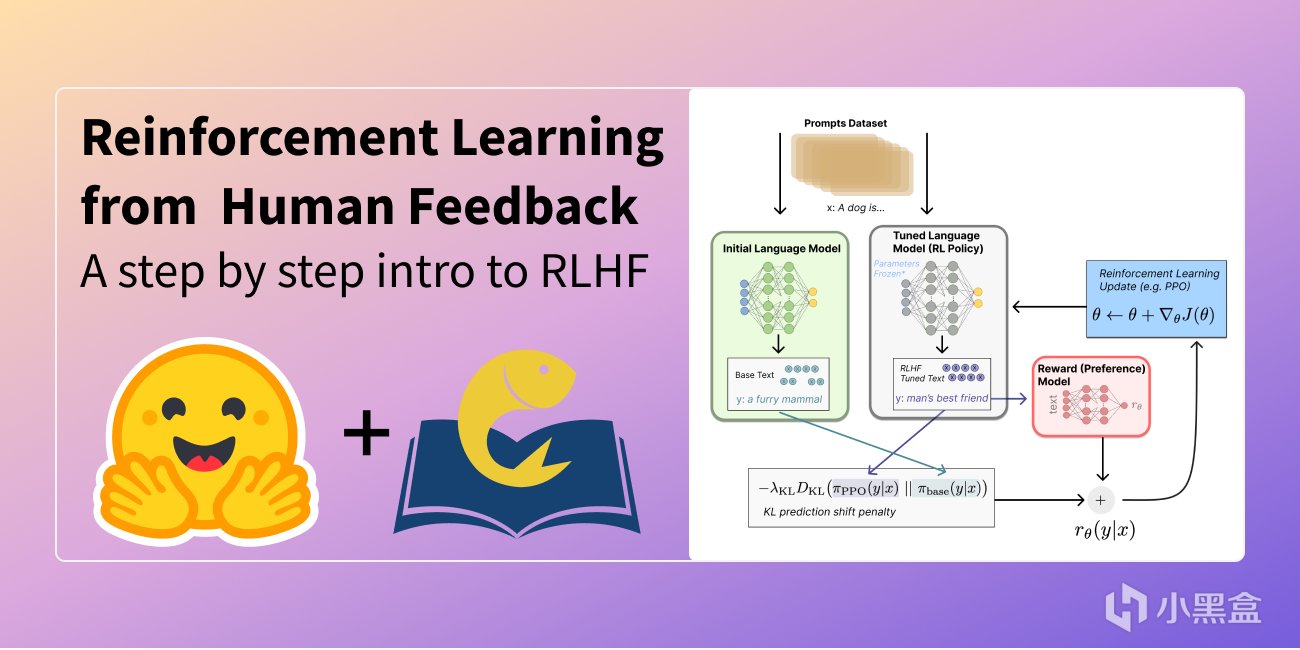
GPT系列模型能够取得成功核心同样也依赖强化学习,这里用到了强化学习中的人类反馈强化学习(RLHF)机制,实现上非常简单,首先是预训练阶段,GPT 模型首先在大规模文本数据上进行无监督学习,掌握语言的基本统计规律,形成一个基础语言模型。
然后进行监督微调SFT,在预训练的基础上,将高质量问答数据模型与人类表达习惯初步对齐,让生成的回答更贴近人类对话的风格和需求;随后再进行奖励模型训练,通过人类标注的偏好数据构建奖励函数,评估模型输出质量,评分越高表示越符合人类偏好。
最后再利用强化学习算法优化,比如近端策略优化算法(PPO)以奖励模型的评分作为奖励信号,调整 GPT 模型的生成策略,模型通过不断生成回答并接收反馈,逐步优化以最大化累积奖励,生成更高质量的文本。大模型发展到今天,强化学习同样功不可没。
06 图灵祖师爷
这次Sutton获得图灵奖也有说法,因为强化学习和祖师爷图灵也有渊源,1950年,图灵在发表的经典论文《Computing Machinery and Intelligence》中,提出了一个影响深远的问题:“机器能思考吗?”。这篇论文不仅引入了著名的图灵测试(用于评估机器是否具有类似人类的智能),还探讨了机器学习的可能性。

当时图灵设想了一种方法,让机器通过类似人类或动物的学习方式,从环境中获取知识并改进自身行为。其中,他特别提到了一种基于奖惩机制的机器学习方法。这种方法的核心在于,机器可以通过接收奖励(正反馈)或惩罚(负反馈),调整自己的行为,以实现更好的性能,这一思想在当时是非常超前的,因为1950年的计算机科学和人工智能领域尚处于萌芽阶段。

近年来,人工智能领域不断取得重大进展,同时还凭借一系列重要奖项得到了全球的广泛认可,2018年深度学习三巨头获得图灵奖,2024年辛顿获得诺贝尔物理学奖、哈萨比斯获得诺贝尔化学奖、Sutton师徒获得图灵奖。图灵当年的设想,如今正通过深度学习、强化学习等技术逐步实现,在多个领域开花结果。

DeepSeek——最新论文解读,梁文锋大佬亲自署名!
DeepSeek——创始人硕士学位论文赏析 [精读]
深度学习入门——图灵奖AI三巨头
AI编年史——深度学习的发展史(收藏向)
AI编年史2——GPT是如何诞生的?
AI学术巨佬——何恺明,从游戏中获得论文灵感
AI领军人物——孙剑,重剑无锋的经典之作
AI传奇巨佬——汤晓鸥,中国人工智能领袖人物!
AI女神李飞飞——从成都七中,到顶级AI科学家!
AI教父辛顿——一文带你了解机器学习,AI教父的成长史!
山姆·奥特曼——从游戏编程,到OpenAI之父!
张益唐——黎曼猜想,华人数学家再创重大突破!
B站大学——线代不挂科,MIT传奇教授的最后一课!
华为——盘古大模型解读,专注“小模型”工业落地!
英伟达——跟着老黄学AI,英伟达官方免费推出AI课!
微软免费AI课程——18节课,初学者入门大模型!
机器学习——科学家周志华,成为中国首位AI顶会掌门人!
机器学习入门——数学基础(积分篇)
机器学习入门——数学基础(代数篇)
机器学习入门——数学基础(贝叶斯篇)
#gd的ai&游戏杂谈#