本文是對ECCV 2024 Oral文章Pyramid Diffusion for Fine 3D Large Scene Generation的介紹。代碼已經開源。
文章編輯 | 狗屁糖
代碼鏈接:https://github.com/yuhengliu02/pyramid-discrete-diffusion
論文鏈接:https://arxiv.org/abs/2311.12085
項目官網:https://yuheng.ink/project-page/pyramid-discrete-diffusion/

Introduction
3D場景生成旨在模擬我們現實世界環境的三維複雜性,從而能夠幫助我們更好地理解物理世界。這項技術在自動駕駛,虛擬現實,具身智能中都發揮著至關重要的作用。然而,由於3D場景本身的龐大規模以及缺乏大規模的3D場景數據集,想要生成高質量的3D場景仍然極具挑戰性。
儘管生成式擴散模型在生成2D圖像或者小型3D物體上也有不錯的效果,但是將擴散模型直接應用於3D場景的生成並非易事,特別是3D的戶外場景。一方面擴散模型會佔用大量資源,並且需要很長的訓練時間,另一方面,擴散模型需要大量的訓練數據,但目前還十分缺少高質量的3D戶外場景數據,這就導致擴散模型難以生成大規模和具備複雜細節的3D戶外場景。
為了解決這些問題,現有的工作主要都集中於有條件的擴散模型生成,藉助像場景圖,2D語義圖這樣的附加條件對生成式模型進行指導。但是這種條件指導的方式可能會限制了生成式擴散模型的泛化能力。因此,受到圖像超分辨率中廣泛使用的“粗到細”(Coarse-to-Fine)的啟發,作者引入了金字塔離散擴散模型(PDD),這個框架可以在不依賴外部指導條件的情況下逐步生成大規模且精細化的3D戶外場景。
Method
作者首先生成小規模的3D場景,並且在這個的基礎上逐步增加場景的分辨率及細節。在每個規模層次上,作者都會單獨訓練適用於當前規模的擴散模型,而這個模型會使用前一規模生成的場景作為條件(除了第一個生成的場景,第一個生成的場景使用噪聲作為模型的輸入)來生成更大規模的3D場景。這種分階段且多尺度的生成過程將一個具有困難和挑戰性的無條件場景生成任務分解為了幾個更易於管理的條件生成任務。此外,在最高分辨率的生成中,作者還採用了一種場景細分的技術,將大場景劃分為多個較小的子場景,並且使用共享擴散模型進行合成。這個技術解決了3D戶外場景體積龐大而導致的模型過大的問題。並且這種多尺度的生成框架還能夠實現跨數據集的轉移應用,即在模擬數據集(例如CarlaSC)上預訓練好的模型可以直接在現實中採集的數據集(例如SemanticKITTI)上直接進行微調,從而在減少訓練資源和時間的基礎上還實現了在新數據集上的高質量生成。最後,作者還進一步提出了一種基於PDD框架的擴展,該拓展可以用於無限3D戶外場景的生成。PDD在創新性方面主要做出了以下貢獻:
提出了一個新的適用於3D戶外場景生成的金字塔擴散模型,實現了3D戶外場景生成的粗到細的策略。
對PDD進行了廣泛的實驗,證明了在與現有方法相當的計算資源下,該方法能夠生成更高質量的3D場景,此外,還引入了新的度量標準,從多個方面評估3D戶外場景的生成質量。
展現了PDD方法更廣泛的應用:能夠從合成數據集生成到真實世界數據的場景生成;可以通過拓展PDD來支持無限場景的生成。
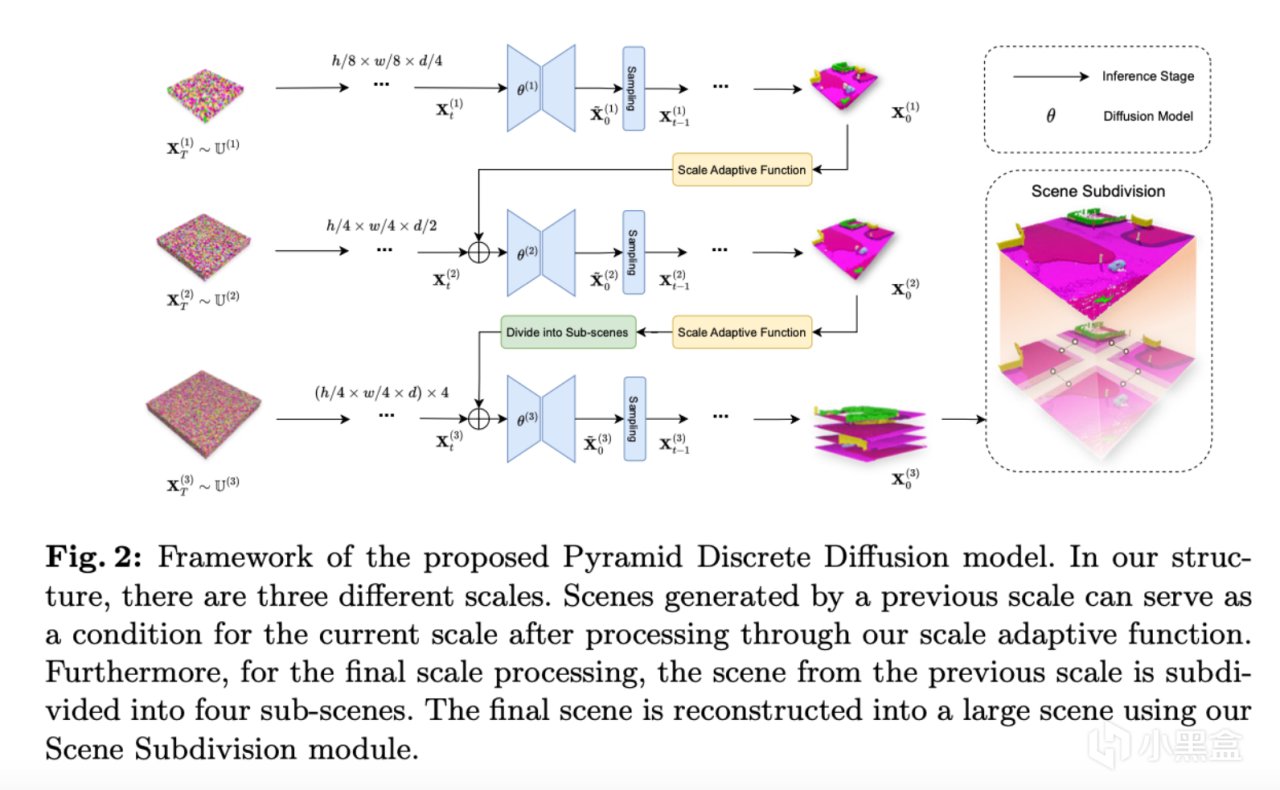
根據上圖所示,PDD主要分為兩個模塊:1. 金字塔離散擴散模型:PDD擴展了標準的離散擴散模型(Discrete Diffusion Model)以此適應3D數據;2. 場景細分:提出了場景細分方法來進一步降低內存需求。並且展示了PDD在特定場景中的兩個實際應用。
實際應用
除了作為生成模型的主要功能之外,作者還為PDD引入了兩個新的應用。首先,跨數據集遷移 旨在將一個在源數據集上訓練的模型適配到目標數據集。由於輸入尺度的靈活性,PDD可以通過在新數據集中重新訓練或微調較小尺度的模型,同時保留較大尺度的模型來實現這一目標。利用PDD的策略提高了在不同數據集之間遷移3D場景生成模型的效率。
其次,無限場景生成在自動駕駛和城市建模等需要大規模3D場景的領域中具有重要意義。PDD可以擴展其場景細分技術。通過使用先前生成場景的邊緣作為條件,它可以迭代生成更大的場景,理論上可以沒有規模限制。
Experiments
評估標準
由於用於2D生成的指標(例如FID)無法直接應用於3D戶外場景,文章中引入並實現了三種評估生成3D場景質量的指標。
首先,作者通過生成場景上的語義分割結果來評估模型在是否能夠生成語義一致的場景方面的效果。具體來說,文章實現了基於Voxel的SparseUNet和基於Points的PointNet++架構來執行分割任務。並且通過計算mIoU和MAs作為評估指標。
另外,作者提出了F3D,一種基於FID在3D中進行改進的評估指標,這個指標使用了帶有3D CNN架構的預訓練自編碼器。文章中計算了在特徵域(feature domain)中生成場景和真實場景之間的Fréchet距離。
同時,作者還使用了MMD,一種用於量化生成場景和真實場景分佈之間的差異的指標。類似於F3D方法,先通過同樣的預訓練自編碼器提取特徵,再計算生成的3D場景和真實場景之間的MMD。
主要結果

作者將文章中提出的方法與兩個基線方法進行比較。表1中的結果表明,在無條件和有條件兩組實驗設置下,文章的方法在所有指標上都有不錯的表現,並且在計算資源相當的情況下超越了現有的方法。尤其在分割任務的評估中,PDD的性能表現出了顯著的優勢,反應了其生成語義一致性場景的能力。
下面圖3中展示了使用不同模型的可視化結果,PDD生成的場景在細節和隨機性方面表現更佳。
此外,作者還對有條件的3D戶外場景生成進行了比較,利用了PDD在輸入尺度上的靈活性,分別在除第一階段的模型上,以第一階段的尺度(32 x 32 x 4)逐步恢復到第二階段的尺度(64 x 64 x 8)和最後一個階段的尺度(256 x 256 x 16)上。表1和下面圖5中的結果展示了PDD在條件生成對比中的出色表現。
未過擬合驗證
作者利用結構相似性指標(SSIM)來驗證生成的場景與訓練集中最鄰近場景的不同之處。具體來說,作者生成了1K個場景,並使用SSIM指標找到它們在訓練集中的最近匹配場景,並且計算了這1K個場景的平均SSIM的值(見表3)。
另外,作者還將相同的方法應用於驗證集,以此建立一個參考的基線。表3中顯示,生成的場景與基線結果相當,驗證了PDD並未對訓練集過擬合。為了進一步支撐這一理論,文章中還使用分佈圖(見圖4)來驗證生成場景與訓練集的相似性。此外,作者在圖中展示了處於不同分佈段的三對場景,顯示了SSIM分數較低的場景與其在訓練集中最近匹配的差異更大。這些實驗表明PDD有效捕捉了訓練集的分佈,而不是簡單記憶了訓練數據。
實際應用測試
跨數據集遷移 圖8和圖9展示了PDD在從CarlaSC遷移到SemanticKITTI數據集上執行無條件和有條件場景生成時的表現。通過在SemanticKITTI數據集上進行微調,PDD展現出更高的場景質量,如表6中的結果所示。
無限場景生成 圖7可視化了使用PDD模型生成大規模無限場景的過程和結果。作者先使用小尺度模型快速生成一個粗略的無限3D場景(圖7的底部層級)。然後利用更大尺度的模型逐步添加複雜細節(圖7的中部和頂部層級),提升了場景的真實感。該方法使得PDD可以生成高質量、連續的城市景觀,而無需額外的輸入,克服了傳統數據集有限場景的侷限性,並且生成的場景可以支持如3D場景分割等下游任務。(更完整的生成的無限場景可以在文章開頭的Demo視頻查看)
Conclusion
在這個工作中,文章提出了金字塔離散擴散模型(PDD),展示了一種漸進式的生成方法,從粗略到精細且無縫過渡到高質量的3D戶外場景。與其它方法相比,PDD能夠在有限的資源約束下生成高質量的場景,並且不需要引入額外的數據源。文中的大量實驗結果表明,PDD在無條件和有條件生成任務中均表現出色,證明其是創建真實且複雜場景的可靠的解決方案。此外,PDD在將使用合成數據訓練的模型適配到現實數據集方面也具有很大的潛力,為解決當前有限現實世界數據不足提供了一種具有前景的解決方案。