本文是对ECCV 2024 Oral文章Pyramid Diffusion for Fine 3D Large Scene Generation的介绍。代码已经开源。
文章编辑 | 狗屁糖
代码链接:https://github.com/yuhengliu02/pyramid-discrete-diffusion
论文链接:https://arxiv.org/abs/2311.12085
项目官网:https://yuheng.ink/project-page/pyramid-discrete-diffusion/

Introduction
3D场景生成旨在模拟我们现实世界环境的三维复杂性,从而能够帮助我们更好地理解物理世界。这项技术在自动驾驶,虚拟现实,具身智能中都发挥着至关重要的作用。然而,由于3D场景本身的庞大规模以及缺乏大规模的3D场景数据集,想要生成高质量的3D场景仍然极具挑战性。
尽管生成式扩散模型在生成2D图像或者小型3D物体上也有不错的效果,但是将扩散模型直接应用于3D场景的生成并非易事,特别是3D的户外场景。一方面扩散模型会占用大量资源,并且需要很长的训练时间,另一方面,扩散模型需要大量的训练数据,但目前还十分缺少高质量的3D户外场景数据,这就导致扩散模型难以生成大规模和具备复杂细节的3D户外场景。
为了解决这些问题,现有的工作主要都集中于有条件的扩散模型生成,借助像场景图,2D语义图这样的附加条件对生成式模型进行指导。但是这种条件指导的方式可能会限制了生成式扩散模型的泛化能力。因此,受到图像超分辨率中广泛使用的“粗到细”(Coarse-to-Fine)的启发,作者引入了金字塔离散扩散模型(PDD),这个框架可以在不依赖外部指导条件的情况下逐步生成大规模且精细化的3D户外场景。
Method
作者首先生成小规模的3D场景,并且在这个的基础上逐步增加场景的分辨率及细节。在每个规模层次上,作者都会单独训练适用于当前规模的扩散模型,而这个模型会使用前一规模生成的场景作为条件(除了第一个生成的场景,第一个生成的场景使用噪声作为模型的输入)来生成更大规模的3D场景。这种分阶段且多尺度的生成过程将一个具有困难和挑战性的无条件场景生成任务分解为了几个更易于管理的条件生成任务。此外,在最高分辨率的生成中,作者还采用了一种场景细分的技术,将大场景划分为多个较小的子场景,并且使用共享扩散模型进行合成。这个技术解决了3D户外场景体积庞大而导致的模型过大的问题。并且这种多尺度的生成框架还能够实现跨数据集的转移应用,即在模拟数据集(例如CarlaSC)上预训练好的模型可以直接在现实中采集的数据集(例如SemanticKITTI)上直接进行微调,从而在减少训练资源和时间的基础上还实现了在新数据集上的高质量生成。最后,作者还进一步提出了一种基于PDD框架的扩展,该拓展可以用于无限3D户外场景的生成。PDD在创新性方面主要做出了以下贡献:
提出了一个新的适用于3D户外场景生成的金字塔扩散模型,实现了3D户外场景生成的粗到细的策略。
对PDD进行了广泛的实验,证明了在与现有方法相当的计算资源下,该方法能够生成更高质量的3D场景,此外,还引入了新的度量标准,从多个方面评估3D户外场景的生成质量。
展现了PDD方法更广泛的应用:能够从合成数据集生成到真实世界数据的场景生成;可以通过拓展PDD来支持无限场景的生成。
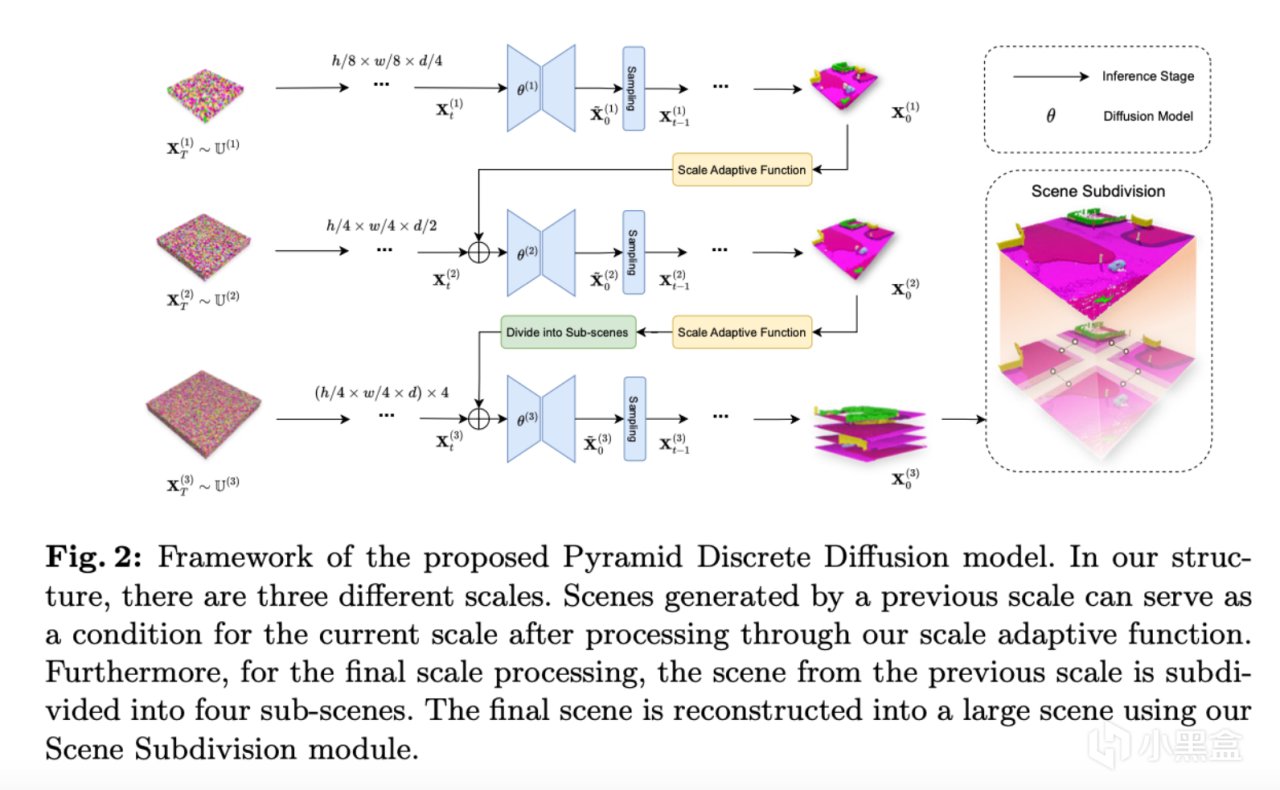
根据上图所示,PDD主要分为两个模块:1. 金字塔离散扩散模型:PDD扩展了标准的离散扩散模型(Discrete Diffusion Model)以此适应3D数据;2. 场景细分:提出了场景细分方法来进一步降低内存需求。并且展示了PDD在特定场景中的两个实际应用。
实际应用
除了作为生成模型的主要功能之外,作者还为PDD引入了两个新的应用。首先,跨数据集迁移 旨在将一个在源数据集上训练的模型适配到目标数据集。由于输入尺度的灵活性,PDD可以通过在新数据集中重新训练或微调较小尺度的模型,同时保留较大尺度的模型来实现这一目标。利用PDD的策略提高了在不同数据集之间迁移3D场景生成模型的效率。
其次,无限场景生成在自动驾驶和城市建模等需要大规模3D场景的领域中具有重要意义。PDD可以扩展其场景细分技术。通过使用先前生成场景的边缘作为条件,它可以迭代生成更大的场景,理论上可以没有规模限制。
Experiments
评估标准
由于用于2D生成的指标(例如FID)无法直接应用于3D户外场景,文章中引入并实现了三种评估生成3D场景质量的指标。
首先,作者通过生成场景上的语义分割结果来评估模型在是否能够生成语义一致的场景方面的效果。具体来说,文章实现了基于Voxel的SparseUNet和基于Points的PointNet++架构来执行分割任务。并且通过计算mIoU和MAs作为评估指标。
另外,作者提出了F3D,一种基于FID在3D中进行改进的评估指标,这个指标使用了带有3D CNN架构的预训练自编码器。文章中计算了在特征域(feature domain)中生成场景和真实场景之间的Fréchet距离。
同时,作者还使用了MMD,一种用于量化生成场景和真实场景分布之间的差异的指标。类似于F3D方法,先通过同样的预训练自编码器提取特征,再计算生成的3D场景和真实场景之间的MMD。
主要结果

作者将文章中提出的方法与两个基线方法进行比较。表1中的结果表明,在无条件和有条件两组实验设置下,文章的方法在所有指标上都有不错的表现,并且在计算资源相当的情况下超越了现有的方法。尤其在分割任务的评估中,PDD的性能表现出了显著的优势,反应了其生成语义一致性场景的能力。
下面图3中展示了使用不同模型的可视化结果,PDD生成的场景在细节和随机性方面表现更佳。
此外,作者还对有条件的3D户外场景生成进行了比较,利用了PDD在输入尺度上的灵活性,分别在除第一阶段的模型上,以第一阶段的尺度(32 x 32 x 4)逐步恢复到第二阶段的尺度(64 x 64 x 8)和最后一个阶段的尺度(256 x 256 x 16)上。表1和下面图5中的结果展示了PDD在条件生成对比中的出色表现。
未过拟合验证
作者利用结构相似性指标(SSIM)来验证生成的场景与训练集中最邻近场景的不同之处。具体来说,作者生成了1K个场景,并使用SSIM指标找到它们在训练集中的最近匹配场景,并且计算了这1K个场景的平均SSIM的值(见表3)。
另外,作者还将相同的方法应用于验证集,以此建立一个参考的基线。表3中显示,生成的场景与基线结果相当,验证了PDD并未对训练集过拟合。为了进一步支撑这一理论,文章中还使用分布图(见图4)来验证生成场景与训练集的相似性。此外,作者在图中展示了处于不同分布段的三对场景,显示了SSIM分数较低的场景与其在训练集中最近匹配的差异更大。这些实验表明PDD有效捕捉了训练集的分布,而不是简单记忆了训练数据。
实际应用测试
跨数据集迁移 图8和图9展示了PDD在从CarlaSC迁移到SemanticKITTI数据集上执行无条件和有条件场景生成时的表现。通过在SemanticKITTI数据集上进行微调,PDD展现出更高的场景质量,如表6中的结果所示。
无限场景生成 图7可视化了使用PDD模型生成大规模无限场景的过程和结果。作者先使用小尺度模型快速生成一个粗略的无限3D场景(图7的底部层级)。然后利用更大尺度的模型逐步添加复杂细节(图7的中部和顶部层级),提升了场景的真实感。该方法使得PDD可以生成高质量、连续的城市景观,而无需额外的输入,克服了传统数据集有限场景的局限性,并且生成的场景可以支持如3D场景分割等下游任务。(更完整的生成的无限场景可以在文章开头的Demo视频查看)
Conclusion
在这个工作中,文章提出了金字塔离散扩散模型(PDD),展示了一种渐进式的生成方法,从粗略到精细且无缝过渡到高质量的3D户外场景。与其它方法相比,PDD能够在有限的资源约束下生成高质量的场景,并且不需要引入额外的数据源。文中的大量实验结果表明,PDD在无条件和有条件生成任务中均表现出色,证明其是创建真实且复杂场景的可靠的解决方案。此外,PDD在将使用合成数据训练的模型适配到现实数据集方面也具有很大的潜力,为解决当前有限现实世界数据不足提供了一种具有前景的解决方案。