近年來,國內外大模型技術飛速發展,以OpenAI的GPT-3.5為起點,大模型在自然語言理解、邏輯推理和自動化生成等領域展現出強大潛力。特別是DeepSeek-R1等開源模型的推出,加速了大模型技術在各行業的滲透。
在數據資產建設實踐中,傳統方案長期受限於人工經驗驅動模式,面臨效率瓶頸、成本攀升、標準模糊等核心痛點。構建"大模型可理解的數據資產"體系,已成為企業釋放數據要素價值的關鍵突破口。
本文將基於數據團隊建設遊戲數據資產的實踐經驗,系統性解析傳統建設範式的侷限性,並深入探討如何通過大模型技術重構資產標準和建設路徑,最終實現智能化躍遷與降本增效。
傳統數據資產的困境
傳統數據資產建設核心圍繞「標準化、建模、運營、自助化」四個環節展開,旨在通過規範化流程提升數據質量和複用效率。
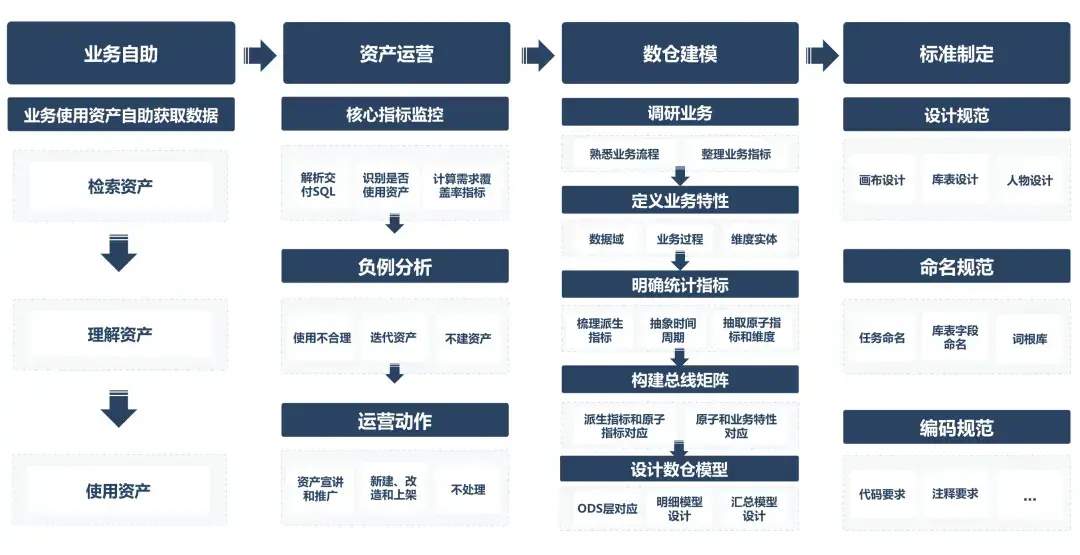
儘管傳統方案在規範化和複用性上有所效果,然而,隨著業務持續發展和複雜度增長,該體系逐漸暴露三大核心矛盾:
1、非結構化標準缺失
- 需求描述語義模糊:業務方提出的“週迴流用戶”指標,可能被不同開發人員解讀為“近7天有過活躍的用戶”或“間隔7天再次活躍的用戶”。
- 設計註釋信息不明:以記錄玩家連續活躍狀的態的“actv_status”字段為例,該字段採用100位0和1編碼,首次使用的開發人員需要反覆確認“當日活躍狀態,是對應從左至右第100位還是從右至左第100位”。
2、改造治理成本高
- 資產頻繁改造的困境:遊戲新增角色粒度對局表時,需要人工評估歷史資產可用性,如果不可用則會進行邏輯改造,耗時且易出錯。
- 人工驗證的效率瓶頸:資產改造後往往需要人工校驗數據一致性,難以應對快速迭代需求。
3、運營目標存在衝突
- 效率與複用的矛盾:業務方追求快速響應,架構師強調資產複用,開發團隊夾在中間難以平衡。例如,如果追求資產複用,新建資產需經歷設計、評審、培訓等冗長流程,導致需求響應週期延長。
重構數據資產體系
為突破傳統範式侷限,我們提出通過利用大模型語義和代碼理解的核心優勢能力,構建模型可理解的新型數據資產體系。
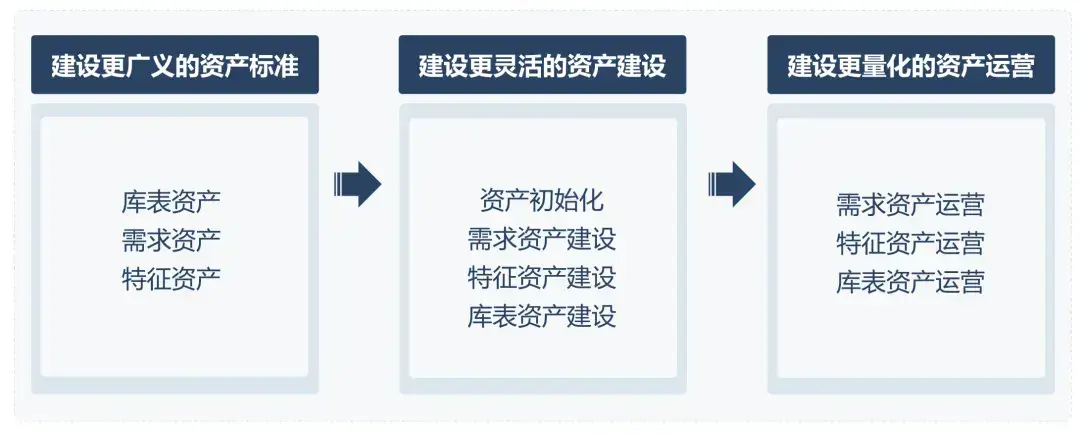
1、建設更廣義的資產標準
在結構化庫表資產基礎上,擴展定義需求資產(規範化業務需求表達)和特徵資產(標準化核心業務邏輯代碼)兩類非結構化資產,構建人與大模型協同的資產標準體系,提升大模型解析效率並降低人工依賴。
2、建設更智能的資產建設
基於大模型技術實現資產全生命週期管理:初始化階段自動解析歷史SQL沉澱特徵/庫表資產;開發階段實時將需求轉化為標準化資產,結合湖倉技術自動生成表結構設計推薦,形成“開發即沉澱“的建設閉環。
3、建設更量化的資產運營
圍繞需求、特徵、庫表三大資產建立可量化指標體系(需求質量評分、特徵複用率、庫表覆蓋率等),通過數據驅動持續評估資產使用效果,形成"建設-監控-優化"的正向循環,實現資產價值迭代升級。
數據資產體系架構
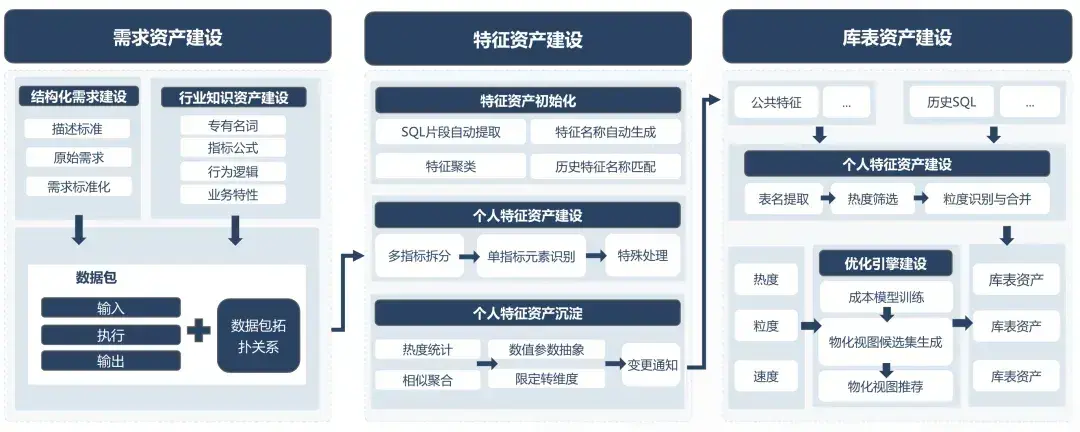
1、需求資產
作為人機協同的橋樑,需求資產由三部分組成:結構化需求、行業知識和大模型理解的需求。
- 結構化需求建設是指將業務原始需求按照標準化描述進行改寫,包括補充完整日期、增加輸出字段、完善維度枚舉,並轉換為類Excel格式;
- 行業知識資產建設涉及從業務知識文檔或原始需求中提取指標公式,積累大模型無法理解的專有名詞和行為邏輯,以及基於業務調研定義業務特性;
- 大模型理解的需求建設是指根據結構化需求和行業知識資產,通過思維鏈讓模型將需求進行分析拆解形成,建設可以被大模型準確理解的需求集合。
2、特徵資產
作為邏輯抽象層,特徵資產區別於算法領域的“特徵”,在技術實現上表現為介於表和最終需求SQL的中間狀態。既可以是表,也可以原子的業務邏輯代碼片段。
該概念的提出源於實踐洞察:在大模型需求驗證過程中,我們發現可以通過對思維鏈下游隱藏上游的複雜信息,減少不必要的注意力分散,能夠有效避免幻覺。因此在上游鏈路抽象出提前定義好的代碼片段,當下遊再使用這些代碼片段時,只需要讓模型理解簡單的字段即可。
具體特徵資產建設包含初始化和建設兩部分:
- 初始化是指從企業歷史SQL中提取關鍵代碼片段;
- 特徵資產建設是指從大模型可理解的需求中自動沉澱個人特徵,並通過對高熱度和高價值的個人特徵進行聚合和抽象,建設公共特徵資產。
3、庫表資產
作為物理存儲層,庫表資產建設路徑包含初始化和基於優化引擎建議的人工構建:
- 初始化是指從企業歷史SQL中自動萃取高價值的資產表;
- 人工構建則是基於公共特徵資產及其熱度、粒度、速度參數,由優化引擎推薦數倉模型設計,然後人工根據建議構建庫表資產。
數據資產建設實踐
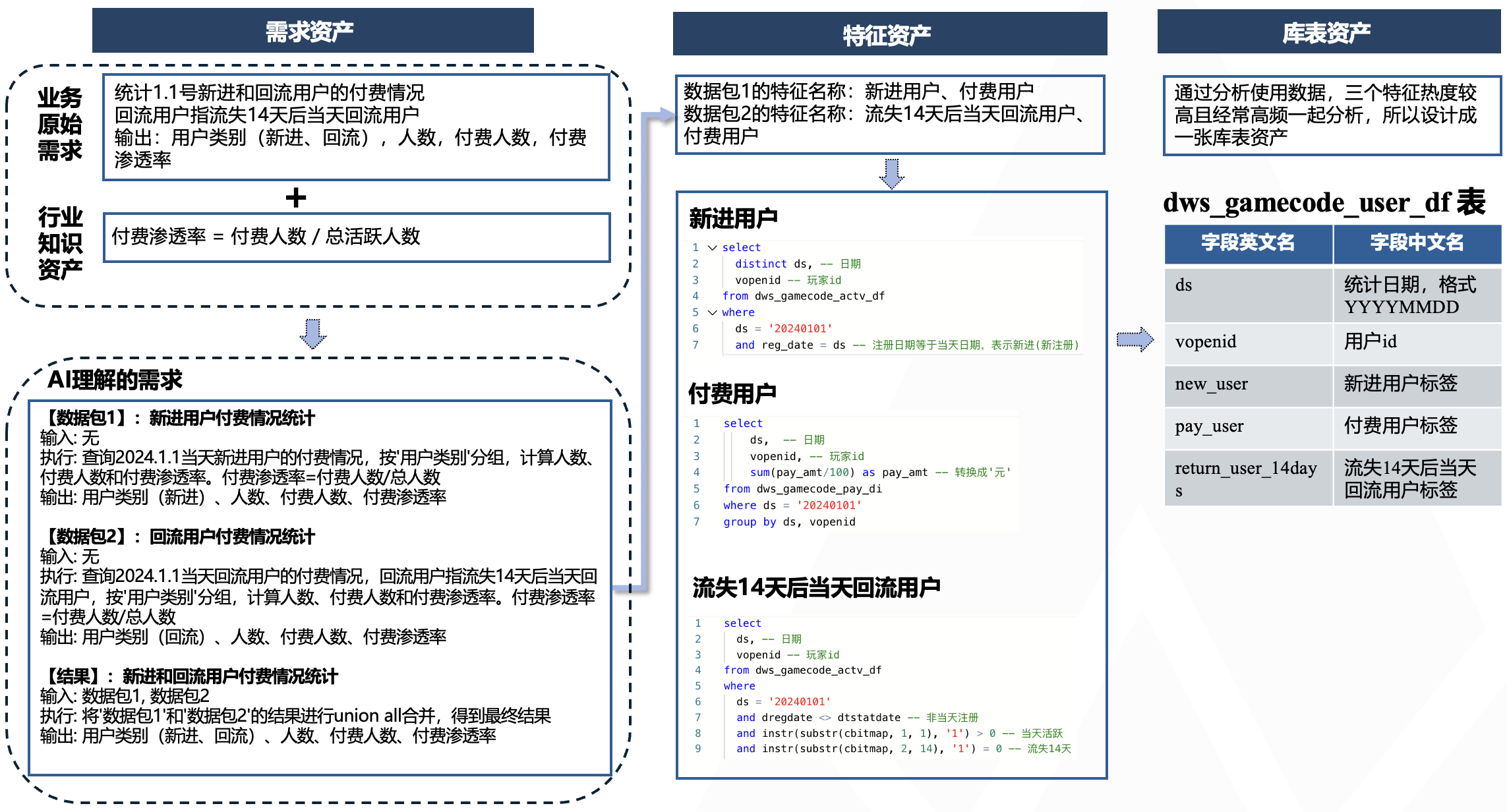
需求資產、特徵資產和庫表資產三者存在流程遞進關係。
以遊戲領域“統計不同類型用戶的付費情況”需求舉例:
- 首先,結合業務原始需求和行業知識資產,通過大模型分析構建具備思維鏈(CoT)結構的需求樣本,完成需求資產建設;
- 其次,由大模型從需求資產中提取特徵名稱並匹配對應代碼片段,形成標準化的特徵資產;
- 最後,通過優化引擎對特徵資產進行自動合併處理,構建庫表資產。
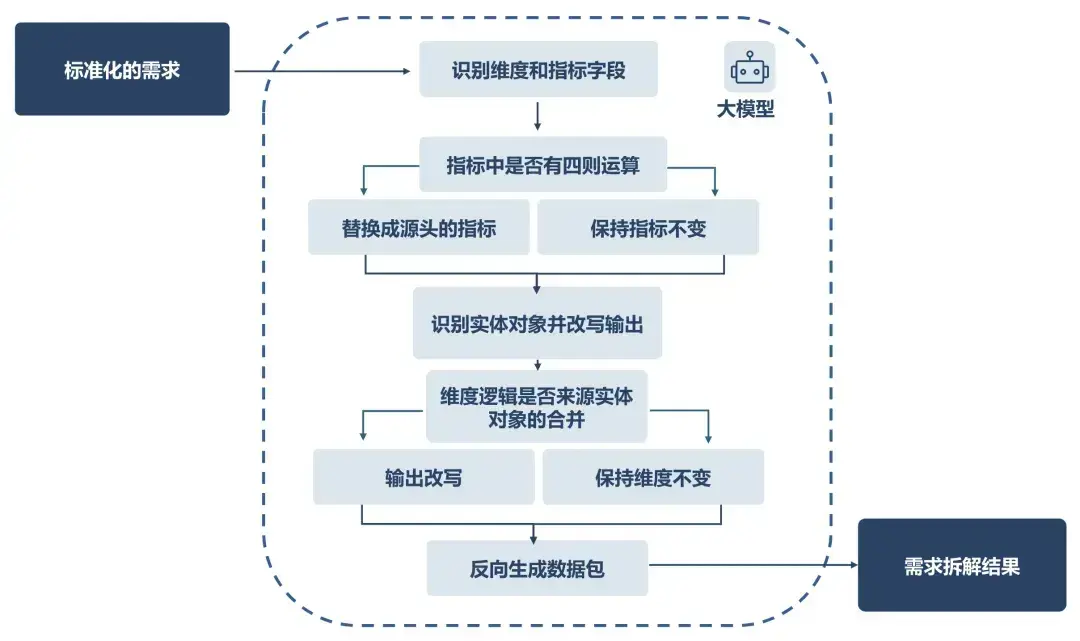
需求資產構建採用四階流程:
- 維度和指標解析:大模型首先識別維度字段和指標字段。針對四則運算的複合指標(入“付費滲透率”),需改寫為原始計算指標並保持維度不變。
- 實體對象識別:解析指標涉及的實體對象。
- 維度複雜度判定:對邏輯聚合的複雜維度,例如,“用戶類型(新進、流失、留存)”需拆解為“新進用戶”、“流失用戶”和“留存用戶”三個實體對象明細的合併。
- 拓撲結構生成:基於前述分析形成需求思維鏈,輸出由多個數據包組成的拓撲結構,每個數據包明確輸入源、執行邏輯和輸出字段。
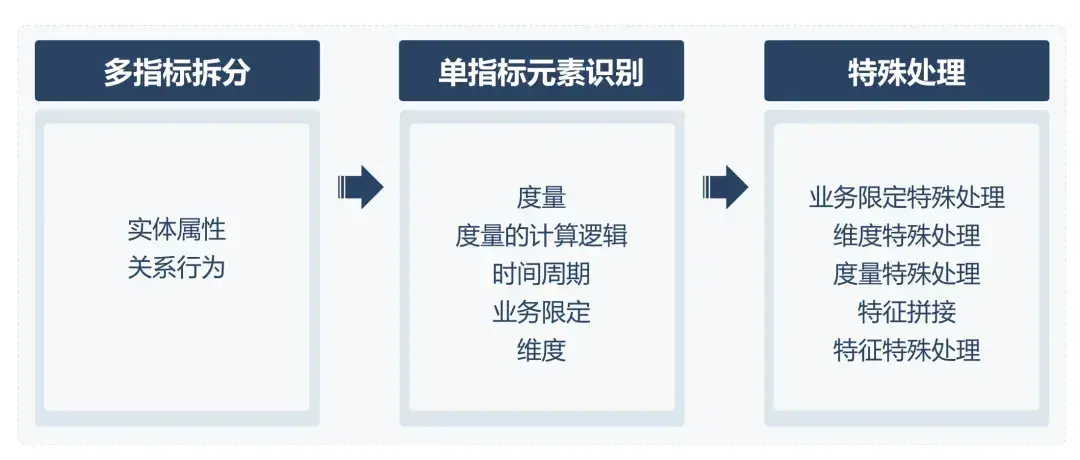
特徵資產由特徵名稱和SQL片段構成。其中特徵名稱由大模型自動提取,SQL片段則通過資產庫匹配或人工補充完成。以"統計特定渠道首次付費用戶中的非迴流用戶數"需求為例,特徵名稱提取流程為:
- 多指標拆分:分離“付費行為”和“迴流行為”兩個獨立指標
- 要素解析:提取時間週期、度量、度量的計算邏輯、維度和業務限定
- 特徵合成:生成"不同渠道的首次付費用戶"與"遊戲當前迴流用戶"兩個特徵實體

實踐表明,通過構建標準化公共特徵資產可覆蓋80%以上的遊戲業務場景需求。配套開發的優化引擎基於公共特徵的代碼邏輯和參數指標,實現庫表資產規範化建設。
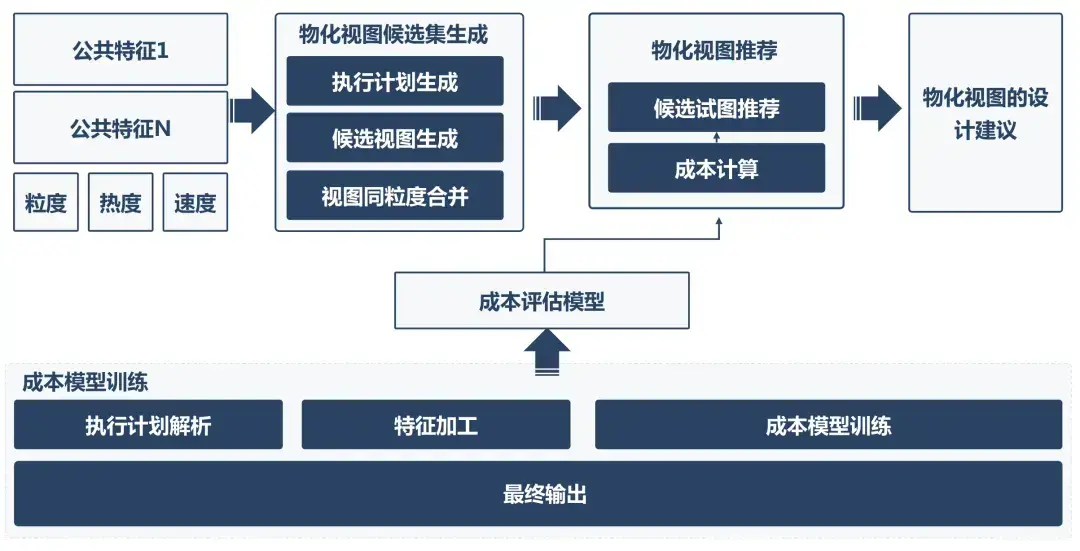
值得特別說明的是,當前業界對StarRocks物化視圖的認知主要集中在查詢性能加速層面。事實上,我們認為其更本質的核心價值在於讓業務邏輯和技術元數據解耦有了可能。當業務方基於ODS層的表提需求時,開發團隊可以依託物化視圖,專注於業務邏輯實現,顯著減少數倉架構設計、任務邏輯配置、任務調度配置、數據補錄等事務工作。當前該技術方案仍處於工程化落地初級階段,需持續開展技術攻關與實踐驗證。
總結
數據資產正經歷從"傳統人工經驗"到"模型認知"的範式轉移。遊戲數據資產實踐經驗表明,構建大模型可理解的資產體系,不僅能突破傳統方案的效率天花板,更能讓數據資產成為驅動業務持續增長的智能原料,實現真正的數據價值釋放。
寫在最後
最近團隊發佈了一本《大模型工程化:大模型驅動下的數據體系》技術書籍,系統闡述瞭如何利用大模型技術打造高效的數據資產體系,為大模型時代的企業新基建和智能化轉型提供參考。
如果有想要的同學可以私信我,會免費送大家100書(請備註姓名、電話、地址、需要多少本,送完為止)。當然也推薦大家自行去人民郵電出版社京東官方店下單。