近年来,国内外大模型技术飞速发展,以OpenAI的GPT-3.5为起点,大模型在自然语言理解、逻辑推理和自动化生成等领域展现出强大潜力。特别是DeepSeek-R1等开源模型的推出,加速了大模型技术在各行业的渗透。
在数据资产建设实践中,传统方案长期受限于人工经验驱动模式,面临效率瓶颈、成本攀升、标准模糊等核心痛点。构建"大模型可理解的数据资产"体系,已成为企业释放数据要素价值的关键突破口。
本文将基于数据团队建设游戏数据资产的实践经验,系统性解析传统建设范式的局限性,并深入探讨如何通过大模型技术重构资产标准和建设路径,最终实现智能化跃迁与降本增效。
传统数据资产的困境
传统数据资产建设核心围绕「标准化、建模、运营、自助化」四个环节展开,旨在通过规范化流程提升数据质量和复用效率。
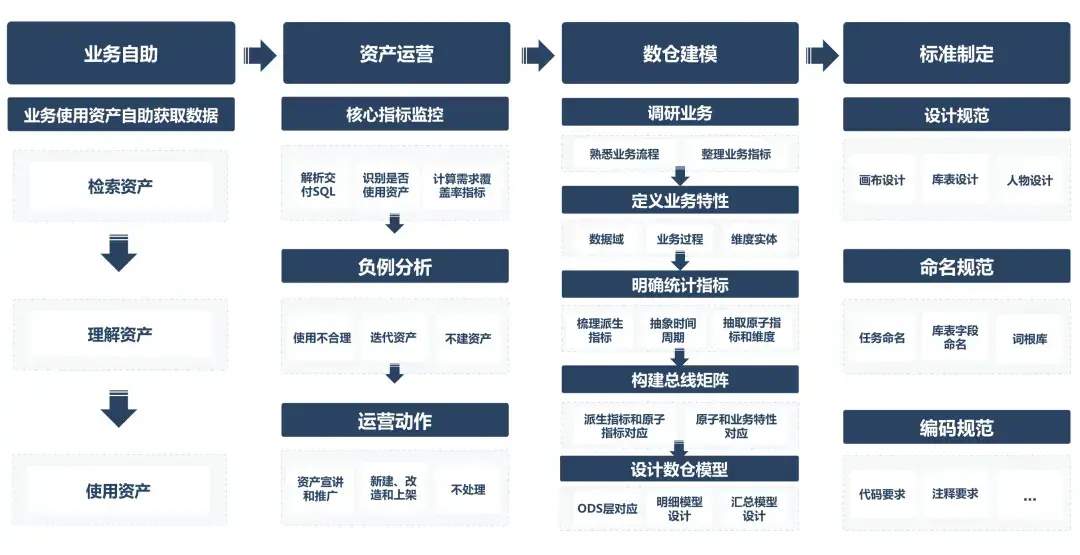
尽管传统方案在规范化和复用性上有所效果,然而,随着业务持续发展和复杂度增长,该体系逐渐暴露三大核心矛盾:
1、非结构化标准缺失
- 需求描述语义模糊:业务方提出的“周回流用户”指标,可能被不同开发人员解读为“近7天有过活跃的用户”或“间隔7天再次活跃的用户”。
- 设计注释信息不明:以记录玩家连续活跃状的态的“actv_status”字段为例,该字段采用100位0和1编码,首次使用的开发人员需要反复确认“当日活跃状态,是对应从左至右第100位还是从右至左第100位”。
2、改造治理成本高
- 资产频繁改造的困境:游戏新增角色粒度对局表时,需要人工评估历史资产可用性,如果不可用则会进行逻辑改造,耗时且易出错。
- 人工验证的效率瓶颈:资产改造后往往需要人工校验数据一致性,难以应对快速迭代需求。
3、运营目标存在冲突
- 效率与复用的矛盾:业务方追求快速响应,架构师强调资产复用,开发团队夹在中间难以平衡。例如,如果追求资产复用,新建资产需经历设计、评审、培训等冗长流程,导致需求响应周期延长。
重构数据资产体系
为突破传统范式局限,我们提出通过利用大模型语义和代码理解的核心优势能力,构建模型可理解的新型数据资产体系。
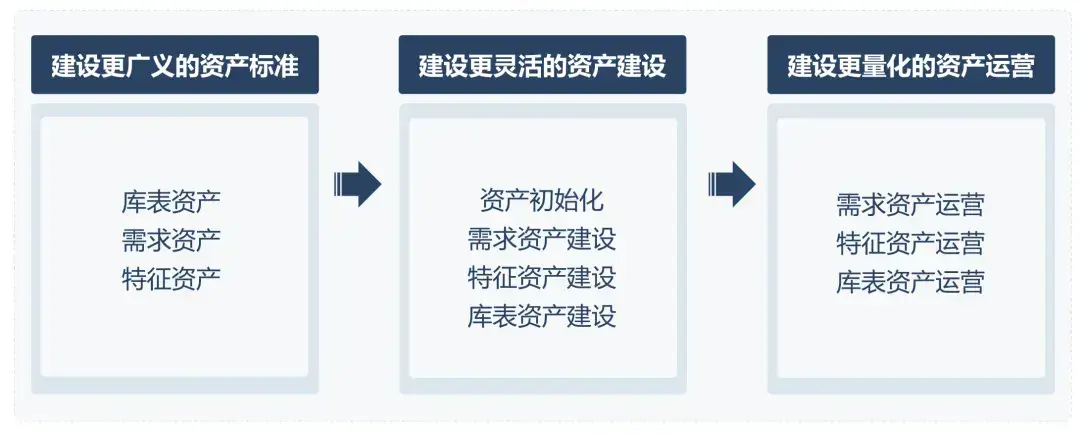
1、建设更广义的资产标准
在结构化库表资产基础上,扩展定义需求资产(规范化业务需求表达)和特征资产(标准化核心业务逻辑代码)两类非结构化资产,构建人与大模型协同的资产标准体系,提升大模型解析效率并降低人工依赖。
2、建设更智能的资产建设
基于大模型技术实现资产全生命周期管理:初始化阶段自动解析历史SQL沉淀特征/库表资产;开发阶段实时将需求转化为标准化资产,结合湖仓技术自动生成表结构设计推荐,形成“开发即沉淀“的建设闭环。
3、建设更量化的资产运营
围绕需求、特征、库表三大资产建立可量化指标体系(需求质量评分、特征复用率、库表覆盖率等),通过数据驱动持续评估资产使用效果,形成"建设-监控-优化"的正向循环,实现资产价值迭代升级。
数据资产体系架构
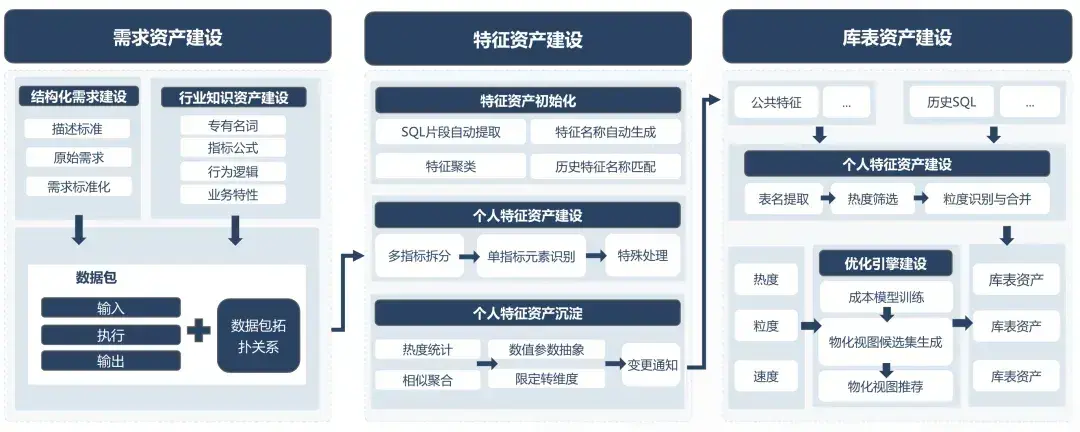
1、需求资产
作为人机协同的桥梁,需求资产由三部分组成:结构化需求、行业知识和大模型理解的需求。
- 结构化需求建设是指将业务原始需求按照标准化描述进行改写,包括补充完整日期、增加输出字段、完善维度枚举,并转换为类Excel格式;
- 行业知识资产建设涉及从业务知识文档或原始需求中提取指标公式,积累大模型无法理解的专有名词和行为逻辑,以及基于业务调研定义业务特性;
- 大模型理解的需求建设是指根据结构化需求和行业知识资产,通过思维链让模型将需求进行分析拆解形成,建设可以被大模型准确理解的需求集合。
2、特征资产
作为逻辑抽象层,特征资产区别于算法领域的“特征”,在技术实现上表现为介于表和最终需求SQL的中间状态。既可以是表,也可以原子的业务逻辑代码片段。
该概念的提出源于实践洞察:在大模型需求验证过程中,我们发现可以通过对思维链下游隐藏上游的复杂信息,减少不必要的注意力分散,能够有效避免幻觉。因此在上游链路抽象出提前定义好的代码片段,当下游再使用这些代码片段时,只需要让模型理解简单的字段即可。
具体特征资产建设包含初始化和建设两部分:
- 初始化是指从企业历史SQL中提取关键代码片段;
- 特征资产建设是指从大模型可理解的需求中自动沉淀个人特征,并通过对高热度和高价值的个人特征进行聚合和抽象,建设公共特征资产。
3、库表资产
作为物理存储层,库表资产建设路径包含初始化和基于优化引擎建议的人工构建:
- 初始化是指从企业历史SQL中自动萃取高价值的资产表;
- 人工构建则是基于公共特征资产及其热度、粒度、速度参数,由优化引擎推荐数仓模型设计,然后人工根据建议构建库表资产。
数据资产建设实践
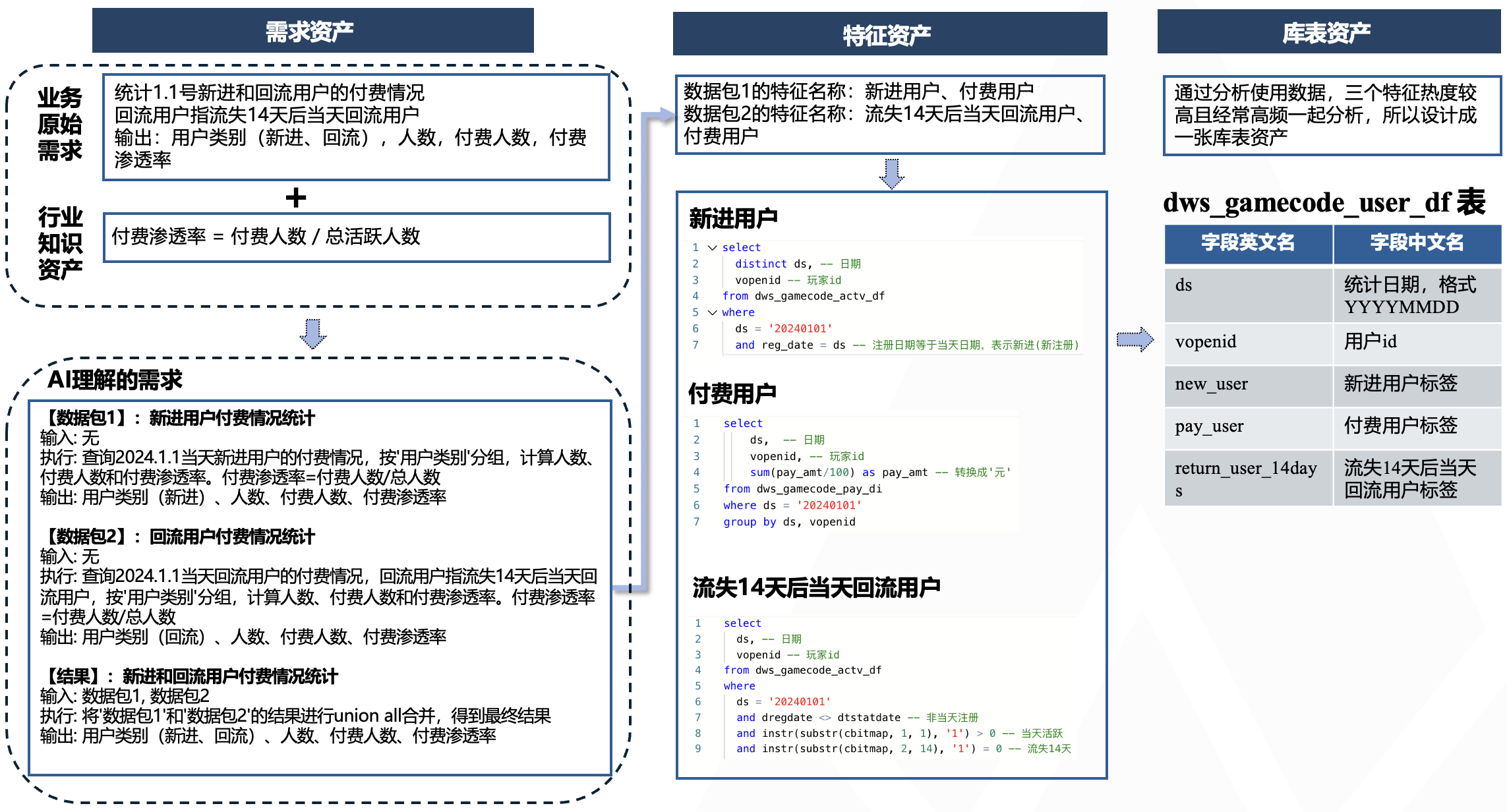
需求资产、特征资产和库表资产三者存在流程递进关系。
以游戏领域“统计不同类型用户的付费情况”需求举例:
- 首先,结合业务原始需求和行业知识资产,通过大模型分析构建具备思维链(CoT)结构的需求样本,完成需求资产建设;
- 其次,由大模型从需求资产中提取特征名称并匹配对应代码片段,形成标准化的特征资产;
- 最后,通过优化引擎对特征资产进行自动合并处理,构建库表资产。
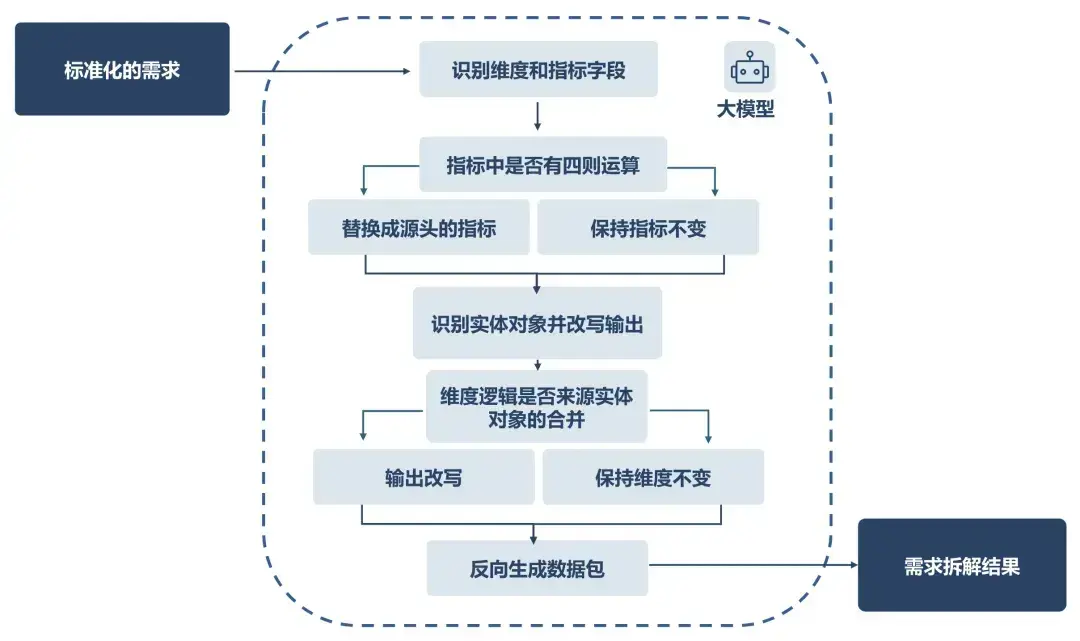
需求资产构建采用四阶流程:
- 维度和指标解析:大模型首先识别维度字段和指标字段。针对四则运算的复合指标(入“付费渗透率”),需改写为原始计算指标并保持维度不变。
- 实体对象识别:解析指标涉及的实体对象。
- 维度复杂度判定:对逻辑聚合的复杂维度,例如,“用户类型(新进、流失、留存)”需拆解为“新进用户”、“流失用户”和“留存用户”三个实体对象明细的合并。
- 拓扑结构生成:基于前述分析形成需求思维链,输出由多个数据包组成的拓扑结构,每个数据包明确输入源、执行逻辑和输出字段。
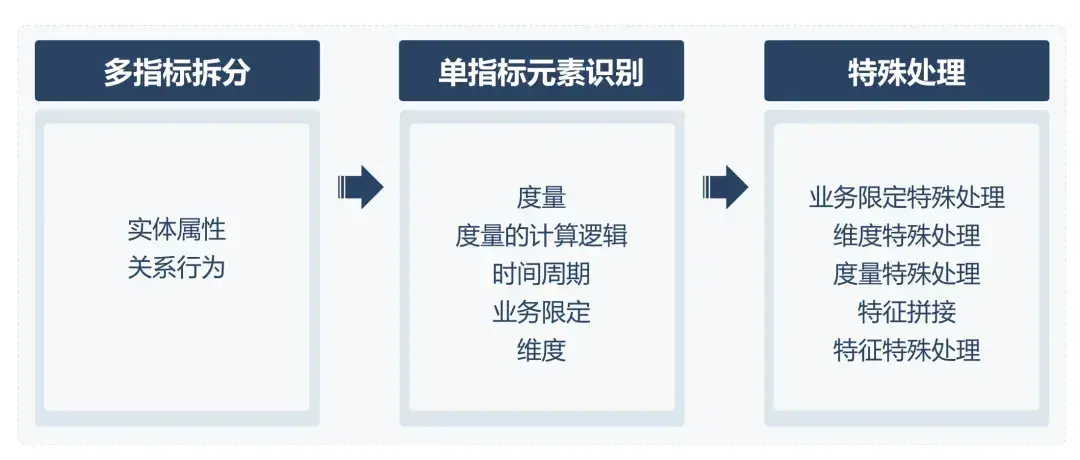
特征资产由特征名称和SQL片段构成。其中特征名称由大模型自动提取,SQL片段则通过资产库匹配或人工补充完成。以"统计特定渠道首次付费用户中的非回流用户数"需求为例,特征名称提取流程为:
- 多指标拆分:分离“付费行为”和“回流行为”两个独立指标
- 要素解析:提取时间周期、度量、度量的计算逻辑、维度和业务限定
- 特征合成:生成"不同渠道的首次付费用户"与"游戏当前回流用户"两个特征实体

实践表明,通过构建标准化公共特征资产可覆盖80%以上的游戏业务场景需求。配套开发的优化引擎基于公共特征的代码逻辑和参数指标,实现库表资产规范化建设。
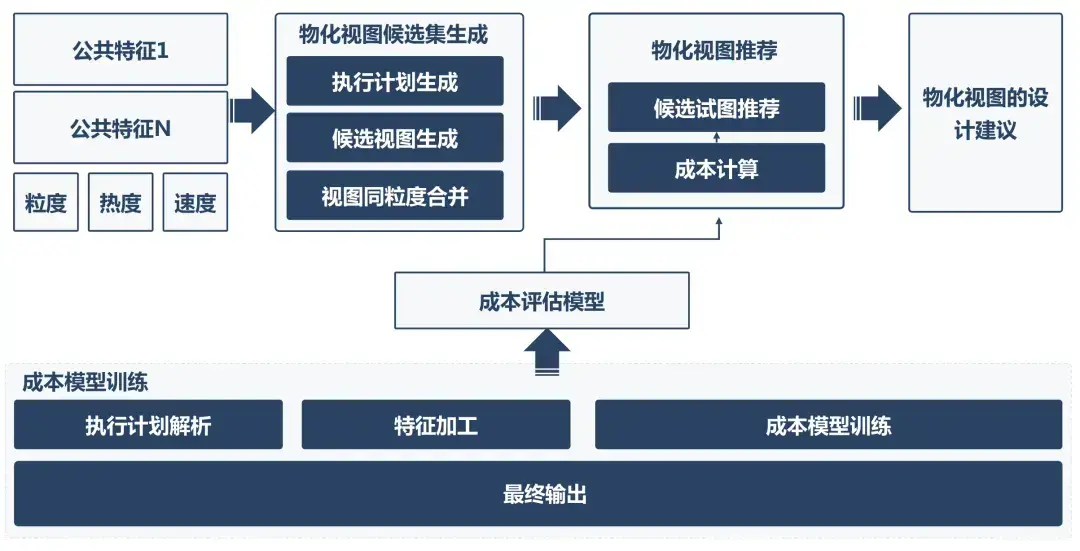
值得特别说明的是,当前业界对StarRocks物化视图的认知主要集中在查询性能加速层面。事实上,我们认为其更本质的核心价值在于让业务逻辑和技术元数据解耦有了可能。当业务方基于ODS层的表提需求时,开发团队可以依托物化视图,专注于业务逻辑实现,显著减少数仓架构设计、任务逻辑配置、任务调度配置、数据补录等事务工作。当前该技术方案仍处于工程化落地初级阶段,需持续开展技术攻关与实践验证。
总结
数据资产正经历从"传统人工经验"到"模型认知"的范式转移。游戏数据资产实践经验表明,构建大模型可理解的资产体系,不仅能突破传统方案的效率天花板,更能让数据资产成为驱动业务持续增长的智能原料,实现真正的数据价值释放。
写在最后
最近团队发布了一本《大模型工程化:大模型驱动下的数据体系》技术书籍,系统阐述了如何利用大模型技术打造高效的数据资产体系,为大模型时代的企业新基建和智能化转型提供参考。
如果有想要的同学可以私信我,会免费送大家100书(请备注姓名、电话、地址、需要多少本,送完为止)。当然也推荐大家自行去人民邮电出版社京东官方店下单。