測試硬件和配置
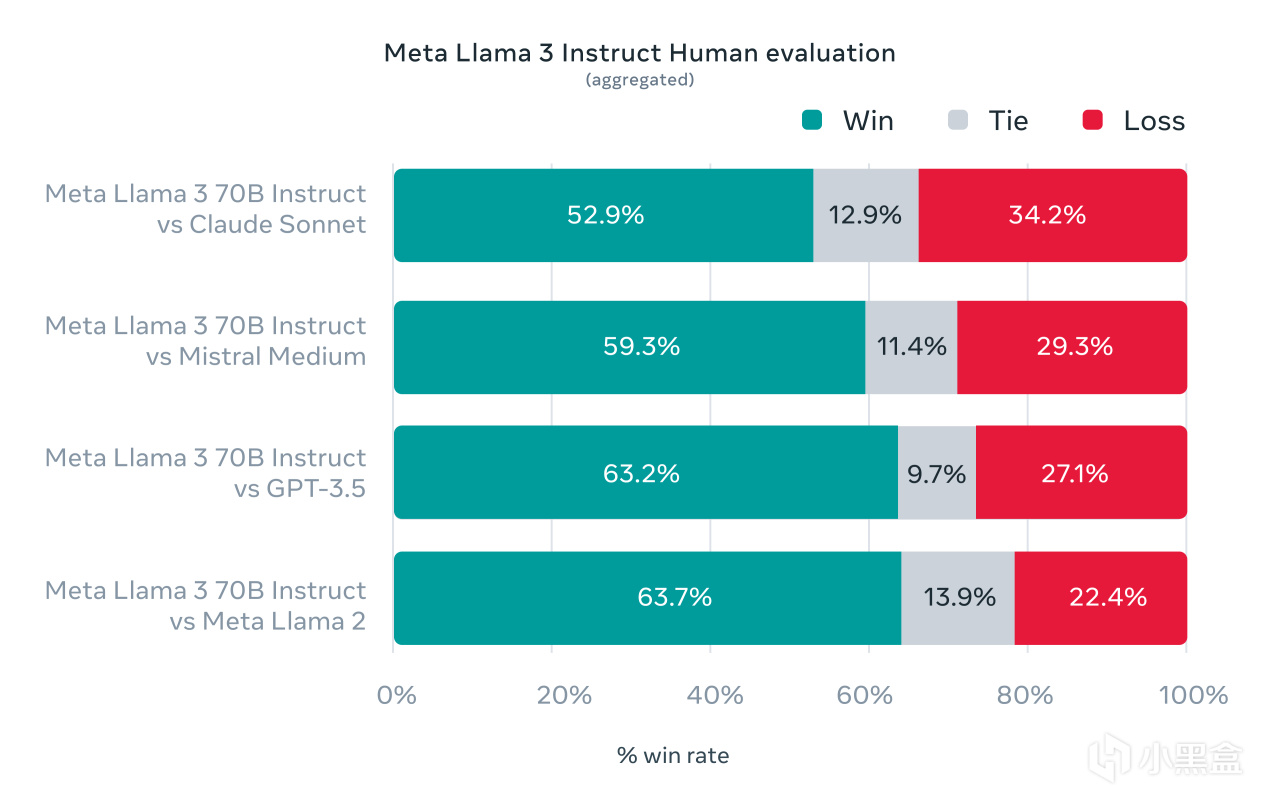
Meta前陣子發佈了號稱最強大的開源大語言模型LIama 3,根據官方說法,它在兩個定製的24K GPU集群上進行訓練,效率比LIama 2提高了約三倍,首先登場的包括LIama 3-8B和LIama 3-70B兩種版本,從官方提供的人類評估數據集可以看到,LIama 3-70B可以全方位領先於Claude Sonnet、Mistral Medium和GPT-3.5,這無疑是真·OpenAI!
LIama 3既然是開源的大模型,那麼自然是可以進行本地部署,用它來替代GPT-3.5豈不是最好的選擇?要知道,本地部署是可以隨時隨地無網絡就能使用,並且個人隱私也得以保護,硬核原本手上就有一臺銳龍7 7800X3D+RX 7900 XT專門玩遊戲的主機,這篇文章就通過LIama 3擴展一下主機的AI聊天功能吧。

測試顯卡來自定位次旗艦的藍寶石RX 7900 XT超白金OC L,外觀採用銀灰色金屬導流罩+單側靈動島RGB燈條設計,擁有七根鍍鎳熱管、全銅底座、鋁鎂合金框架等豪華用料,是AMD高端非公版的代表之作。

配合這次AI工具搭建的處理器是銳龍7 7800X3D,其TDP只有65W,這裡就使用了微星MAG B650M MORTAR WIFI迫擊炮進行搭配,它擁有絕對低調的純黑風格外觀,覆蓋面積足夠大、帶迫擊炮元素的散熱馬甲,還擁有12(80A)+2相強悍供電,用來帶銳龍7 7800X3D就是小菜一碟。
壓制銳龍7 7800X3D的CPU散熱器來自微星MEG CORELIQUID S360戰神,它是一款純黑顏值兼備性能的旗艦360水冷產品,冷頭上帶有2.4英寸IPS顯示屏,能監測並顯示硬件運行狀況,還內置了60mm風扇和Asetek第七代水泵,性能得以保障。
為了更好並留有餘量驅動銳龍7 7800X3D和RX 7900 XT的高端配置,配備電源來自微星MPG A1000G PCIE5,它採用了全日系105℃電容,並通過80PLUS金牌認證,並提供10年售後質保非常可靠。當然,它最大的亮點是符合ATX 3.0標準並支持PCIe 5.0,擁有原生12VHPWR 16pin供電線纜,輸出功率達600W且一線即連很美觀。
其他硬件和配置方面,銳龍7 7800X3D直接開啟PBO技術,為了給推理預留充足的內存,這裡使用了四根DDR5 6000C34開啟EXPO超頻,總計64GB內存容量,本次測試安裝的是AMD Adrenalin 24.4.1最新版本顯卡驅動,操作系統是Windows 11 23H2版本,最後在BIOS中開啟Resizable BAR技術提升一些顯卡性能。
LM Studio安裝、Mistral/LIama 3/Qwen 1.5多模型對比測試
目前本地部署LIama 3基本有三種方法,第一種是GPT4 ALL軟件,更適合低配用戶,相對來說操作簡單,但是模型選擇範圍更少,也不好兼容AMD顯卡。第二種是Ollama,系統支持全面,對AMD顯卡友好,不過要通過WebUI界面敲代碼部署環境,對於新手不友好。
這裡就推薦第三種使用LM Studio軟件,界面操作簡單,對於AMD硬件也友好,關鍵支持模型也豐富,AMD顯卡需要對應下載AMD ROCm版本的LM Studio(RX 6800以後的顯卡均支持加速)
安裝LM Studio後打開第二個搜索選項,使用魔法輸入Meta LIama 3關鍵詞後就會羅列出一大堆模型列表,右側綠色的字體代表著當前顯卡能完全符合該模型的運行要求,推薦大家優先選擇這類模型運行,要是顯示藍色、灰色和紅色字體就需要注意了,意味著運行效率會顯著下降甚至無法運行。
在LM Studio中想要順利下載模型,還可能需要用到Proxifier軟件,它可以輕鬆把魔法軟件的HTTP代理轉換成Socks5代理,具體方法也簡單,添加代理服務器,地址設置127.0.0.1,端口需要在魔法中尋找,類型選Socks5,只要運行LM Studio之前打開Proxifier,就可以實現自動轉換。
下面來用RX 7900 XT測試一下OpenHermes-2.5-Mistral-7B、Meta Llama 3-8B、Qwen 1.5-14B、Qwen 1.5-32B、Qwen 1.5-72B以及Meta Llama 3-70B六種不同類型、參數量的大模型,在LM Studio中使用AMD ROCm加速,看看它們之間的推理速度、推理結果有什麼差別。
OpenHermes-2.5-Mistral-7B,RX 7900 XT使用AMD ROCm加速
推薦GPU負載數值MAX,推理速度為78.97 tok/s
Meta Llama 3-8B,RX 7900 XT使用AMD ROCm加速
推薦GPU負載數值MAX,推理速度為75.16 tok/s
Qwen 1.5-14B,RX 7900 XT使用AMD ROCm加速
推薦GPU負載數值MAX,推理速度為61.98 tok/s
Qwen 1.5-32B,RX 7900 XT使用AMD ROCm加速
推薦GPU負載數值MAX,推理速度為30.13 tok/s
首先我們不看兩個超大參數量的70B+大模型,在以上這些模型中,Qwen 1.5-32B推理結果是最為詳細和比較準確的,但是輸入問題後它要停頓兩秒才會進行推理,而其他模型基本上就是秒出。
其中Meta Llama 3-8B整體推理效果是最為均衡的,推理結果基本接近於比它更大參數量的Qwen 1.5-14B,推理速度自然也會比Qwen 1.5-14B更快,而最原始的OpenHermes-2.5-Mistral-7B雖然擁有最快的推理速度,但是推理結果的滿意度不盡人意,都完全偏離主題了。
Qwen 1.5-72B,RX 7900 XT設置GPU負載數值MAX會提示爆顯存,因為該模型需要29.16GB顯存來加載。
Qwen 1.5-72B,RX 7900 XT的GPU負載數值降低到40,這時候就能正常加載了,不過加載完內存用掉了37.1GB,顯存也佔用達到19.1GB。
Meta Llama 3-70B,RX 7900 XT的GPU負載數值可以直接拉到MAX檔,成功加載模型後佔用18.6GB顯存,內存僅僅使用了9.1GB。
Qwen 1.5-72B,RX 7900 XT使用AMD ROCm加速,推理過程中顯卡佔用率僅有11%,內存和顯存均處於高容量佔比,一般主流的32GB內存已經遠遠不夠了。
Meta Llama 3-70B,RX 7900 XT使用AMD ROCm加速,推理過程中顯卡佔用率達到92%,內存和顯存得以合理利用
對於兩個70B+的大模型,它們對於硬件性能資源使用是直接拉滿,尤其是Qwen 1.5-72B其實已經是超出本配置的要求了,GPU負載數值只能設置很低,否則連加載都成問題,而Meta Llama 3-70B卻可以完全拉滿GPU負載數值,完全用盡RX 7900 XT的資源並不影響其他系統資源,當然本次運行的模型量化值只有IQ1。
Qwen 1.5-72B,RX 7900 XT使用AMD ROCm加速
推薦GPU負載數值40,推理速度為2.92 tok/s
Meta Llama 3-70B,RX 7900 XT使用AMD ROCm加速
推薦GPU負載數值MAX,推理速度為21.57 tok/s
而Meta Llama 3-70B實際推理效果也是最讓人滿意,它的答案不但更符合問題本身,而且給出的答案細節更多,推理速度也還可以,提問五秒之內就能開始推理。而Qwen 1.5-72B不但推理速度極慢,而且推理結果其實和Qwen 1.5-32B基本是沒有太大區別的。
結語
體驗下來,RX 7900 XT在大語言模型(LLM)領域的性能表現是非常不錯的,它可以很高效率運行目前比較流行的Meta Llama 3-8B,甚至因為它擁有20GB GDDR6超大顯存容量,還可以勝任一些參數量更大的模型,同時,我們也能看到AMD ROCm框架在Windows系統中的加速效果十分顯著,期待AMD後面可以持續優化AIGC和LLM的生態圈。如果你也想把你的AMD遊戲主機擴展一下本地AI聊天功能,不妨可以參考一下本文,感謝觀看!