测试硬件和配置
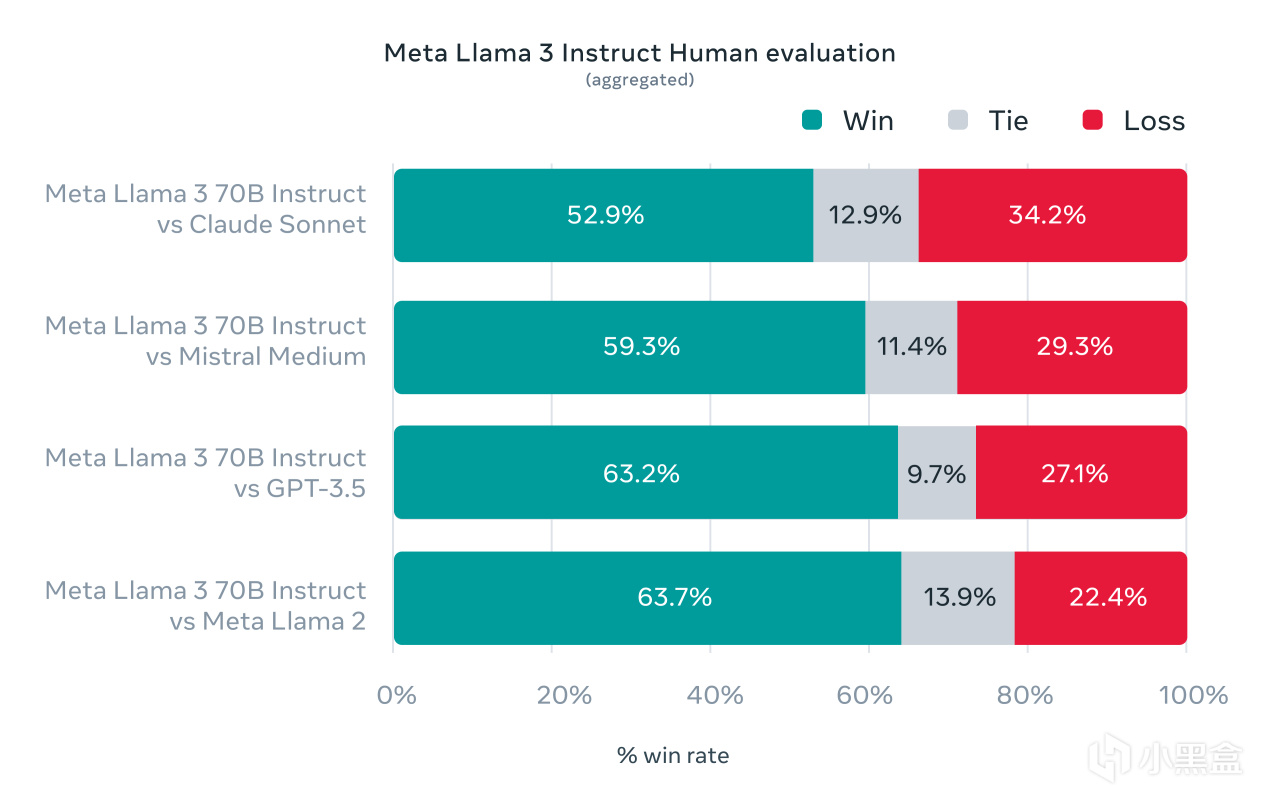
Meta前阵子发布了号称最强大的开源大语言模型LIama 3,根据官方说法,它在两个定制的24K GPU集群上进行训练,效率比LIama 2提高了约三倍,首先登场的包括LIama 3-8B和LIama 3-70B两种版本,从官方提供的人类评估数据集可以看到,LIama 3-70B可以全方位领先于Claude Sonnet、Mistral Medium和GPT-3.5,这无疑是真·OpenAI!
LIama 3既然是开源的大模型,那么自然是可以进行本地部署,用它来替代GPT-3.5岂不是最好的选择?要知道,本地部署是可以随时随地无网络就能使用,并且个人隐私也得以保护,硬核原本手上就有一台锐龙7 7800X3D+RX 7900 XT专门玩游戏的主机,这篇文章就通过LIama 3扩展一下主机的AI聊天功能吧。

测试显卡来自定位次旗舰的蓝宝石RX 7900 XT超白金OC L,外观采用银灰色金属导流罩+单侧灵动岛RGB灯条设计,拥有七根镀镍热管、全铜底座、铝镁合金框架等豪华用料,是AMD高端非公版的代表之作。

配合这次AI工具搭建的处理器是锐龙7 7800X3D,其TDP只有65W,这里就使用了微星MAG B650M MORTAR WIFI迫击炮进行搭配,它拥有绝对低调的纯黑风格外观,覆盖面积足够大、带迫击炮元素的散热马甲,还拥有12(80A)+2相强悍供电,用来带锐龙7 7800X3D就是小菜一碟。
压制锐龙7 7800X3D的CPU散热器来自微星MEG CORELIQUID S360战神,它是一款纯黑颜值兼备性能的旗舰360水冷产品,冷头上带有2.4英寸IPS显示屏,能监测并显示硬件运行状况,还内置了60mm风扇和Asetek第七代水泵,性能得以保障。
为了更好并留有余量驱动锐龙7 7800X3D和RX 7900 XT的高端配置,配备电源来自微星MPG A1000G PCIE5,它采用了全日系105℃电容,并通过80PLUS金牌认证,并提供10年售后质保非常可靠。当然,它最大的亮点是符合ATX 3.0标准并支持PCIe 5.0,拥有原生12VHPWR 16pin供电线缆,输出功率达600W且一线即连很美观。
其他硬件和配置方面,锐龙7 7800X3D直接开启PBO技术,为了给推理预留充足的内存,这里使用了四根DDR5 6000C34开启EXPO超频,总计64GB内存容量,本次测试安装的是AMD Adrenalin 24.4.1最新版本显卡驱动,操作系统是Windows 11 23H2版本,最后在BIOS中开启Resizable BAR技术提升一些显卡性能。
LM Studio安装、Mistral/LIama 3/Qwen 1.5多模型对比测试
目前本地部署LIama 3基本有三种方法,第一种是GPT4 ALL软件,更适合低配用户,相对来说操作简单,但是模型选择范围更少,也不好兼容AMD显卡。第二种是Ollama,系统支持全面,对AMD显卡友好,不过要通过WebUI界面敲代码部署环境,对于新手不友好。
这里就推荐第三种使用LM Studio软件,界面操作简单,对于AMD硬件也友好,关键支持模型也丰富,AMD显卡需要对应下载AMD ROCm版本的LM Studio(RX 6800以后的显卡均支持加速)
安装LM Studio后打开第二个搜索选项,使用魔法输入Meta LIama 3关键词后就会罗列出一大堆模型列表,右侧绿色的字体代表着当前显卡能完全符合该模型的运行要求,推荐大家优先选择这类模型运行,要是显示蓝色、灰色和红色字体就需要注意了,意味着运行效率会显著下降甚至无法运行。
在LM Studio中想要顺利下载模型,还可能需要用到Proxifier软件,它可以轻松把魔法软件的HTTP代理转换成Socks5代理,具体方法也简单,添加代理服务器,地址设置127.0.0.1,端口需要在魔法中寻找,类型选Socks5,只要运行LM Studio之前打开Proxifier,就可以实现自动转换。
下面来用RX 7900 XT测试一下OpenHermes-2.5-Mistral-7B、Meta Llama 3-8B、Qwen 1.5-14B、Qwen 1.5-32B、Qwen 1.5-72B以及Meta Llama 3-70B六种不同类型、参数量的大模型,在LM Studio中使用AMD ROCm加速,看看它们之间的推理速度、推理结果有什么差别。
OpenHermes-2.5-Mistral-7B,RX 7900 XT使用AMD ROCm加速
推荐GPU负载数值MAX,推理速度为78.97 tok/s
Meta Llama 3-8B,RX 7900 XT使用AMD ROCm加速
推荐GPU负载数值MAX,推理速度为75.16 tok/s
Qwen 1.5-14B,RX 7900 XT使用AMD ROCm加速
推荐GPU负载数值MAX,推理速度为61.98 tok/s
Qwen 1.5-32B,RX 7900 XT使用AMD ROCm加速
推荐GPU负载数值MAX,推理速度为30.13 tok/s
首先我们不看两个超大参数量的70B+大模型,在以上这些模型中,Qwen 1.5-32B推理结果是最为详细和比较准确的,但是输入问题后它要停顿两秒才会进行推理,而其他模型基本上就是秒出。
其中Meta Llama 3-8B整体推理效果是最为均衡的,推理结果基本接近于比它更大参数量的Qwen 1.5-14B,推理速度自然也会比Qwen 1.5-14B更快,而最原始的OpenHermes-2.5-Mistral-7B虽然拥有最快的推理速度,但是推理结果的满意度不尽人意,都完全偏离主题了。
Qwen 1.5-72B,RX 7900 XT设置GPU负载数值MAX会提示爆显存,因为该模型需要29.16GB显存来加载。
Qwen 1.5-72B,RX 7900 XT的GPU负载数值降低到40,这时候就能正常加载了,不过加载完内存用掉了37.1GB,显存也占用达到19.1GB。
Meta Llama 3-70B,RX 7900 XT的GPU负载数值可以直接拉到MAX档,成功加载模型后占用18.6GB显存,内存仅仅使用了9.1GB。
Qwen 1.5-72B,RX 7900 XT使用AMD ROCm加速,推理过程中显卡占用率仅有11%,内存和显存均处于高容量占比,一般主流的32GB内存已经远远不够了。
Meta Llama 3-70B,RX 7900 XT使用AMD ROCm加速,推理过程中显卡占用率达到92%,内存和显存得以合理利用
对于两个70B+的大模型,它们对于硬件性能资源使用是直接拉满,尤其是Qwen 1.5-72B其实已经是超出本配置的要求了,GPU负载数值只能设置很低,否则连加载都成问题,而Meta Llama 3-70B却可以完全拉满GPU负载数值,完全用尽RX 7900 XT的资源并不影响其他系统资源,当然本次运行的模型量化值只有IQ1。
Qwen 1.5-72B,RX 7900 XT使用AMD ROCm加速
推荐GPU负载数值40,推理速度为2.92 tok/s
Meta Llama 3-70B,RX 7900 XT使用AMD ROCm加速
推荐GPU负载数值MAX,推理速度为21.57 tok/s
而Meta Llama 3-70B实际推理效果也是最让人满意,它的答案不但更符合问题本身,而且给出的答案细节更多,推理速度也还可以,提问五秒之内就能开始推理。而Qwen 1.5-72B不但推理速度极慢,而且推理结果其实和Qwen 1.5-32B基本是没有太大区别的。
结语
体验下来,RX 7900 XT在大语言模型(LLM)领域的性能表现是非常不错的,它可以很高效率运行目前比较流行的Meta Llama 3-8B,甚至因为它拥有20GB GDDR6超大显存容量,还可以胜任一些参数量更大的模型,同时,我们也能看到AMD ROCm框架在Windows系统中的加速效果十分显著,期待AMD后面可以持续优化AIGC和LLM的生态圈。如果你也想把你的AMD游戏主机扩展一下本地AI聊天功能,不妨可以参考一下本文,感谢观看!