前言
在高质量写实渲染方面,UE引擎无疑是比Unity有着大幅领先的——这种领先主要在于渲染管线、全局光照、GPU集群渲染等方面,而我认为更重要的是在工具化实现高清渲染方面(即它是对于艺术家更友好的一款引擎)。最终这种开发和渲染特性传达给玩家的感觉,就有例如“建模”更精细,整体光感更好更“真”,特效更亮更炫等。
但是反过来,大家可能也有一种感觉,就是现有的玩家硬件其实还不够迎接这种技术升级。因为概括来说这种技术提供的是“不人工优化模型网格”的一种特权,它带来的优势更多是高清大型项目中的,对GPU有一定的算力要求,这从出发点上就一定程度上放弃了下沉到中低端设备的可能性。而且从文章中我们可以看出,其实不人工优化网格不等于不生成LOD,只是他们的LOD自动化构建有一套搭配他们新渲染方案的定制化的方案。
由于我不是从事UE方面开发的工作,因此虽然之前大概了解过UE5中实现巨量多边形的大概思路,不过如果不过写文章我可能不会进行逐页翻译粗读。这次还是以读分享文稿为主,由于篇幅原因就不摘录讲述者的原文了;打星号的部分还是我个人的一些补充说明。
另外,由于篇幅原因会分成两次来读,这篇文章是上篇。
1 目标

梦想——目标
- 像实现虚拟纹理一样实现虚拟化几何体(指像虚拟纹理突破尺寸和显存限制)
- 不再有性能预算——多边形数量、渲染调用次数、内存
- 直接使用电影质量的美术资源(不需要手动优化)
- 不损失质量
*看过当年UE5首次演示的应该有印象,这些就是它们的核心突破方向和宣传点。

实际情况
——比虚拟纹理难得多
- 不仅是内存管理(地址映射)问题
- 几何体的细节会直接产生渲染开销
- 几何体不具备一般可过滤的特性(不像纹理格式,可以应用各种信号学意义上的滤波方法)
2 备选方案分析与拆解
*这部分可以说探索了现代引擎渲染技术的方方面面,虽然长但是很有价值。
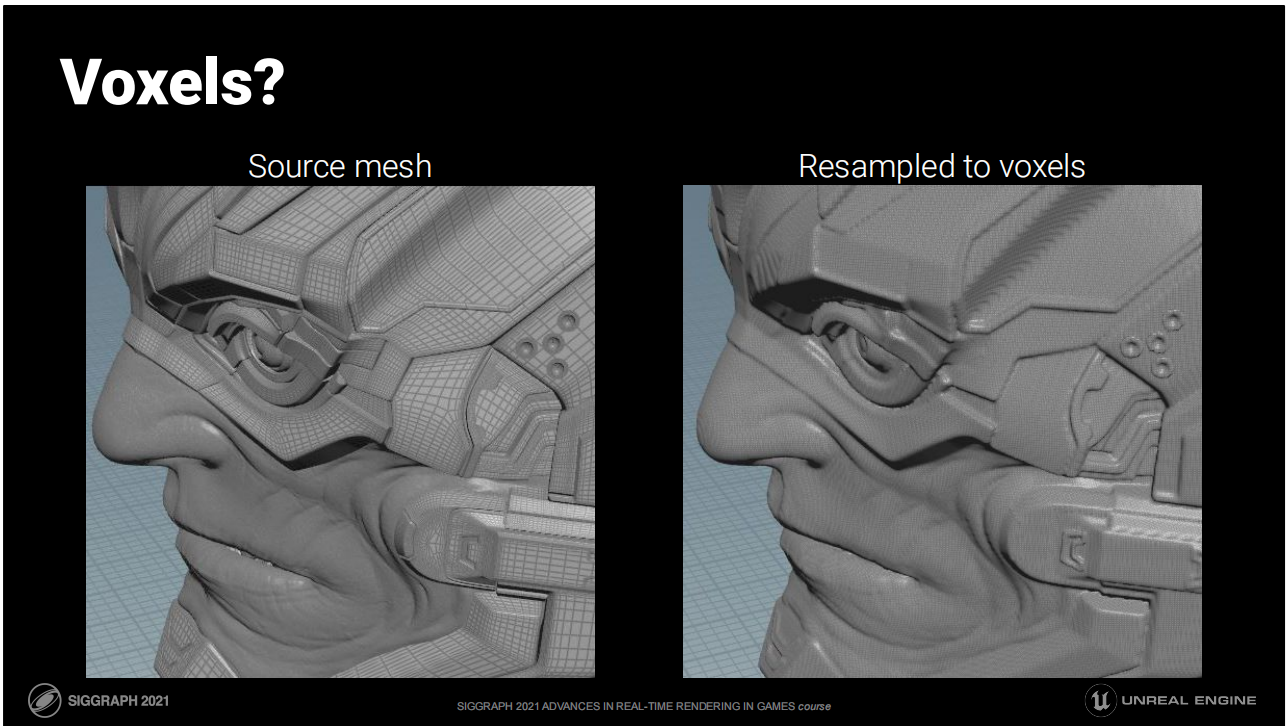
体素?
- 体素和隐式表面(通过函数定义的)通常是这类问题的有潜在优势的讨论方向。
- 图中的原网格被重采样成了右侧的基于有向距离函数的体素(13M narrow band SDF voxels)。
- 体素方案的核心问题是采样精度不好把握以及数据量相对较大(在相对无损的情况下)

——(网格体素化)并不是要完全改变全部CG工作流
- 支持把任何地方制作的网格体进行导入
- 仍有UV和细节纹理
- 只替代了网格,而不是纹理、材质和相关工具
——但尽管如此也带来了更多难解的问题
- 体素如何与UV进行映射?
- 小于体素采样精度的尺度下,无法表现细节和动画
*基于这些现状,体素目前无法称为既有网格结构的替代方案。

细分表面?
- 细分表面既可以作为平滑增加细节的方案,也可以作为合并减面的方案。
- 采用自动化的网格细分并不会减少网格方面的限制,并且往往会为艺术家引入一些额外的限制,否则往往表现不如传统的手工低面数网格模型。

替代(移位)纹理?
- 在某些情况下可以用低网格模型结合雕刻出的替代纹理数据,以类似法线贴图的方式来提高精度
- 但对于右侧的铁链,是无法通过替代纹理来取一个低网格模型然后提高精度的,因为位移操作不能改变物体的“属”(Genus 拓扑结构的概念,可以简单理解成洞的数量)——就好比无法通过位移操作把圆球变成圆环
- 因此它不能作为一个常规普适的网格简化方案

基于点的渲染?
- 单个点本身渲染会很快,但整体结果会有overdraw问题,或者需要补洞
- 点之间的几何关系也没有保存下来

最终选择了三角形作为基础渲染单元
尽管其它的一些方案也能围绕其艺术风格上的特点构建一套完整的渲染系统,但Unreal需要普适的渲染方案。因此基于之前的一些对照方案,Nanite(UE引擎的一个模块)选择了三角形作为基础渲染单元。
3 管线概述

GPU驱动的管线
——渲染器的现行模式
- 跨帧进行GPU场景数据保持
- 在场景物体变化时进行稀疏的更新
- 所有顶点和索引数据保存在一个大资源文件中
——每个渲染视图中
- GPU实例剔除
- 三角形光栅化
——如果只绘制深度,整个场景可以在一个DrawIndirect(集成好的间接绘制指令)中完成
*强调是GPU驱动的意义在于减少与CPU的交互并尽量通过显存内部处理、传递和运算数据,这也是现代渲染管线的趋势。Cluster这个处理逻辑也是建立在GPU的并行计算优势之上的。

三角集群剔除
- 将三角面分组为集群——为每个集群构建包围盒数据
- 基于包围盒剔除集群——视锥体剔除、遮挡剔除

遮挡剔除
- 遮挡剔除主要针对多层深度缓冲来进行(后续缩写为HZB)
- 剔除计算时,依据包围盒对应的屏幕空间尺寸来判断合适的HZB层级
- 当屏幕尺寸小于等于4X4时,直接和最低层级的mip比较
*我之前一篇介绍遮挡剔除的文章里详细介绍过Hiz剔除是怎么计算的。

遮挡剔除
- HZB怎么来的?在还没有渲染任何东西时是没有HZB的(尤其是第一帧时)
- 把前一帧的Z-Buffer投射到当前帧呢?往往需要额外的补洞方案,且剔除的结果总是粗略和不够保守的

双pass遮挡剔除
- 上一帧可见的物体很大程度上会是在这一帧可见的,至少是一个视为遮挡物的好的选择
- 双pass的方案:绘制前一帧可见的物体;构建HZB;绘制上一帧不可见但这一帧可见的物体
- 这几乎是一个完美的遮挡剔除方案:它是保守的(不会额外剔除),只在一些极端的可见性变化的情况会失效

从材质上解耦可见性属性
By that I mean determining visibility per pixel (which is what depth buffered rasterization does) is disconnected from the material evaluation.
(这种解耦)意味这逐像素确定可见性——就像深度缓冲光栅化中做的一样,将其和材质公式的关联性去掉。
消除:
- 光栅化过程中的shader切换(which is 有性能开销的)
- 材质评估过程中的重叠绘制
- 为避免重叠绘制而进行的前置深度pass
- 处理密集网格体时的像素多边形低效
备选项:
- REYES(Render Everything Your Eye Sees,渲染所见的一切)
- 纹理空间
- 延迟渲染可用的材质
*这部分思路以及后面围绕这个逐像素的策略进行的改装就是UE5管线的精华了。

可见性缓冲
把几何体信息写入屏幕——深度、实例ID、三角形ID
逐像素的材质shader:
- 加载VisBuffer(可见性)
- 加载实例的空间变换数据
- 加载3个顶点的索引
- 加载3个顶点的坐标
- 把坐标变换到屏幕空间
- 得到目标像素的重心坐标
- 加载和插值参数

可见性缓冲
听起来不太现实?但实际不像它看起来那么慢
- 有很多可用的缓存数据
- 没有重叠绘制或像素多边形低效问题
材质pass写入了GBuffer——可以与我们其它的延迟着色渲染模块集成
现在我们可以在1次绘制中渲染所有不透明几何体
- 完全GPU驱动
- 不仅是深度的prepass(也是几何体的绘制pass)
- 每个视图仅光栅化三角形一次
*这部分可以说就是这个方案的核心,一些方面消耗虽然变高了,但另一些方面节省了。

次线性缩放
Linear scaling in triangles is not ok. We can’t achieve our goals of “just works no matter how much you throw at it” if we scale linearly
三角形的线性缩放是不OK的,如果不管引入多少三角形我们都仅线性缩放,我们就无法达成目标。(这里scale直接理解成规模变化也没问题)
Virtualized geometry is partly about memory. But ray tracing isn’t fast enough for our target even if it fit in memory
虚拟几何体是部分关于(节省)内存的,但(对现有数据结构的)光线追踪即使在内存达标的状态下还是不够快。

次线性缩放
In terms of clusters, we want to draw the same number of clusters every frame regardless of how many objects or how dense they are.
在集群方面,我们希望绘制相同的集群数量(和像素数量相关),无论每一帧有多少物体或密度如何。
It’s impractical to be perfect there but in general the cost of rendering geometry should scale with screen resolution, not scene complexity. That means constant time in terms of scene complexity and constant time means level of detail.
虽然没有完美实践过,不过通常来说渲染几何体的开销是与屏幕分辨率正相关的,而不是场景复杂度。这意味着在(不同)场景复杂度方面的恒定时间,而恒定时间意味着采用LOD。
*这里再次突出了这个方案的重点,就是“逐像素”或者规模与像素正相关。
4 LOD的构建

集群层级
- 决定LOD基于一个集群基础方案
- 构建LOD层级:最简单的就是树状集群;父节点是它们子节点的简化版
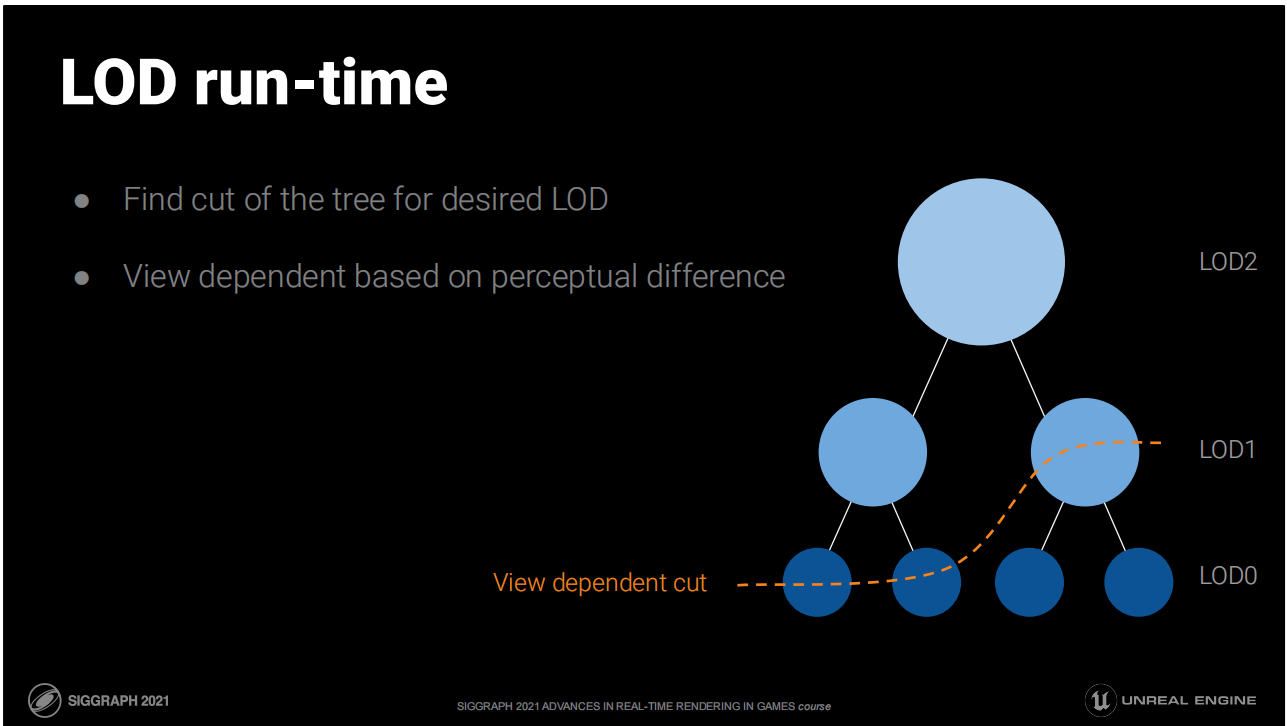
LOD运行时
- 找到树中目标LOD的切片(这意味着同一网格的不同部件可能有不同LOD)
- 基于视点通过感知差异(屏幕空间的投影容差范围)来决定切面

流式加载
- 整个树不需要同时都在内存中
- 可以标记出树的部分切面作为叶子节点,丢弃其它节点
- 在渲染时按需请求数据——像虚拟纹理一样
*这里可以说是虚拟几何体方案的核心思想之一——破除传统的一些绑定上的限制,按需加载渲染。

LOD裂开问题
- 如果每个集群都与相邻物体无关的来决定LOD,就可能导致开裂问题
- 不成熟的方案:在网格简化的过程中锁定共享的边界;不相关的集群将始终在边界处相合
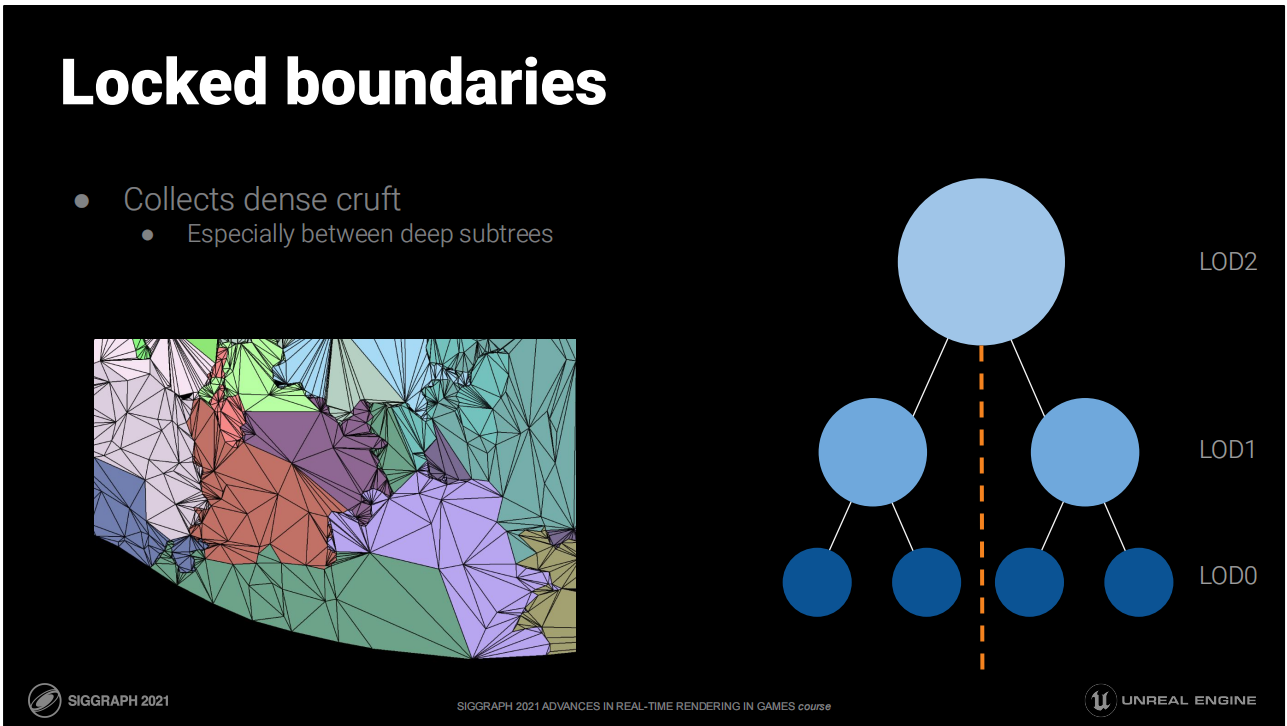
锁定的边界
*如图所示,这种限制会带来边界不整齐的问题。
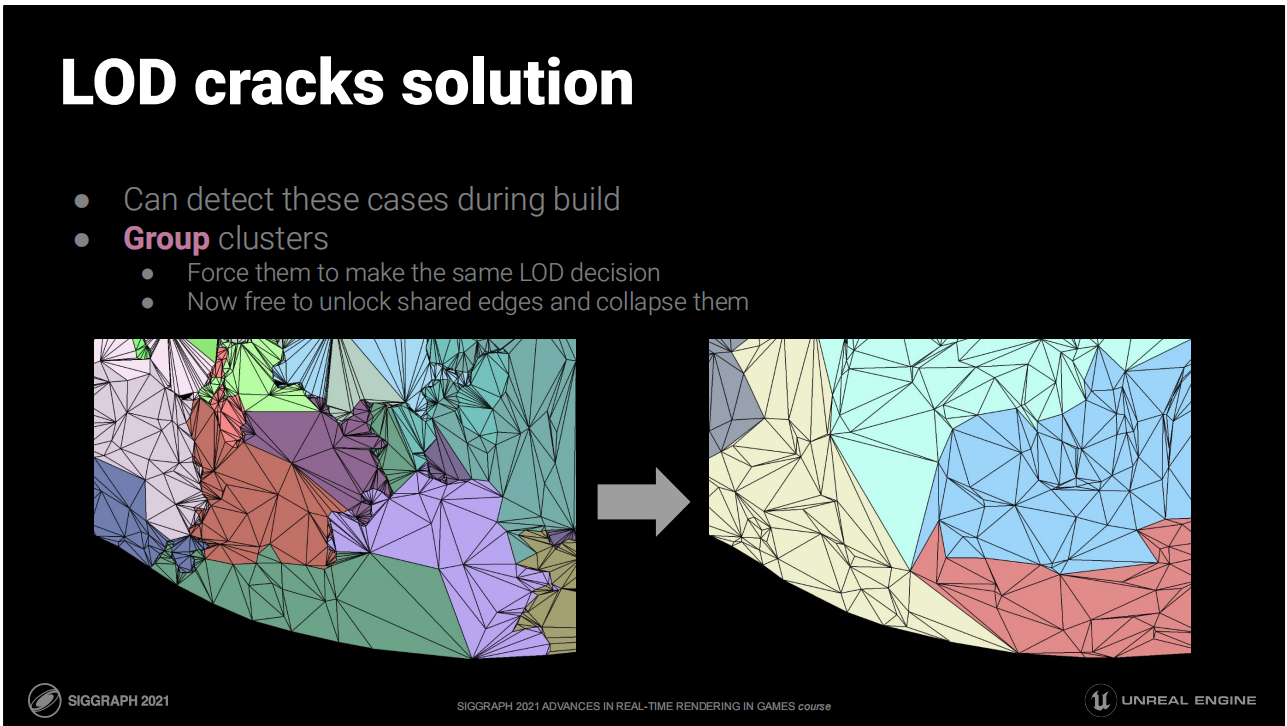
LOD裂开的解决方案
- 可以在构建时探测出这类情况
- 将集群分组:强制它们采用同样的LOD;现在就可以自由解锁共享的边缘或使之塌陷了
*原文中还以实例演示了这一方案的基本思路,并对比了其它潜在的解决LOD裂开的方案。篇幅原因这里不展开了,有兴趣可以去看文末链接。
5 资源构建过程

构建操作
将原始的三角形集群化。当集群数大于1时:
- 将集群分组以清除它们组内的共享边界
- 将同组的三角形融合到共享列表中
- 简化至一半三角形数量
- 将简化后的三角形拆分并归入新集群(128个三角形一组)
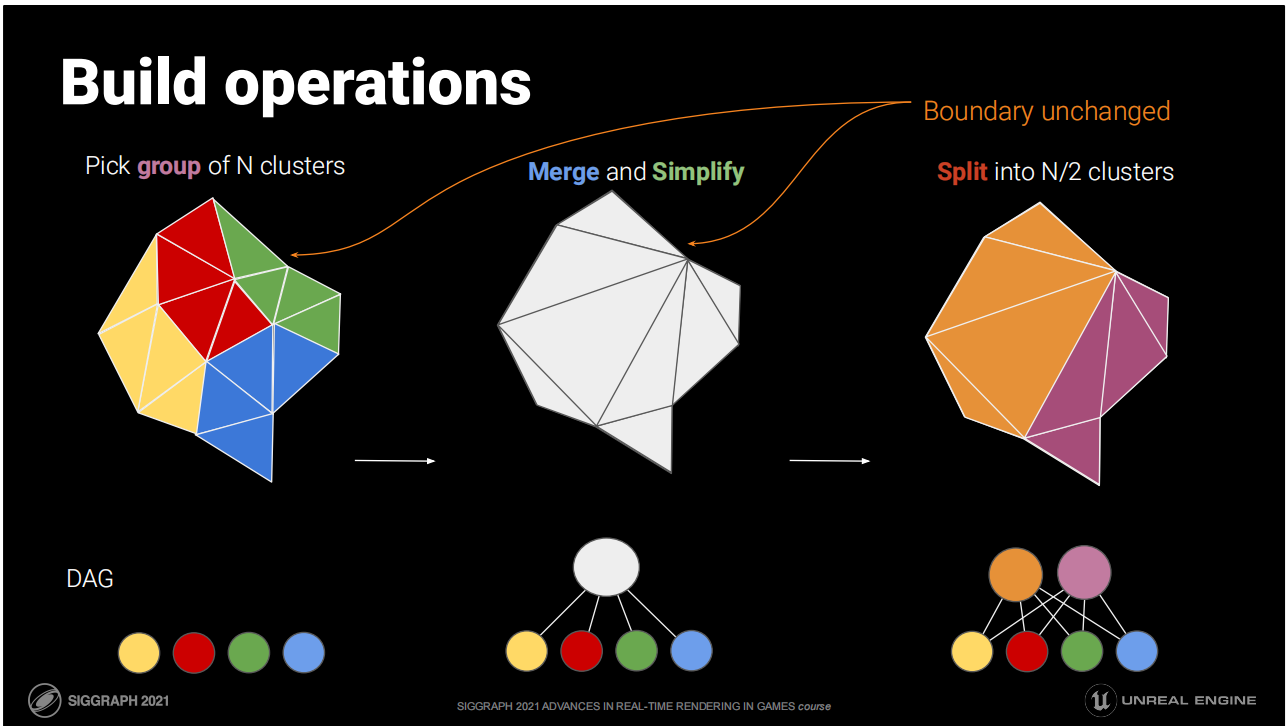
构建操作
*图中演示了这一构建归纳的步骤,最终的得到的数据结构是一个DAG(Directed Acyclic Graph 有向无环图,这里的“图”是一种数据结构)。
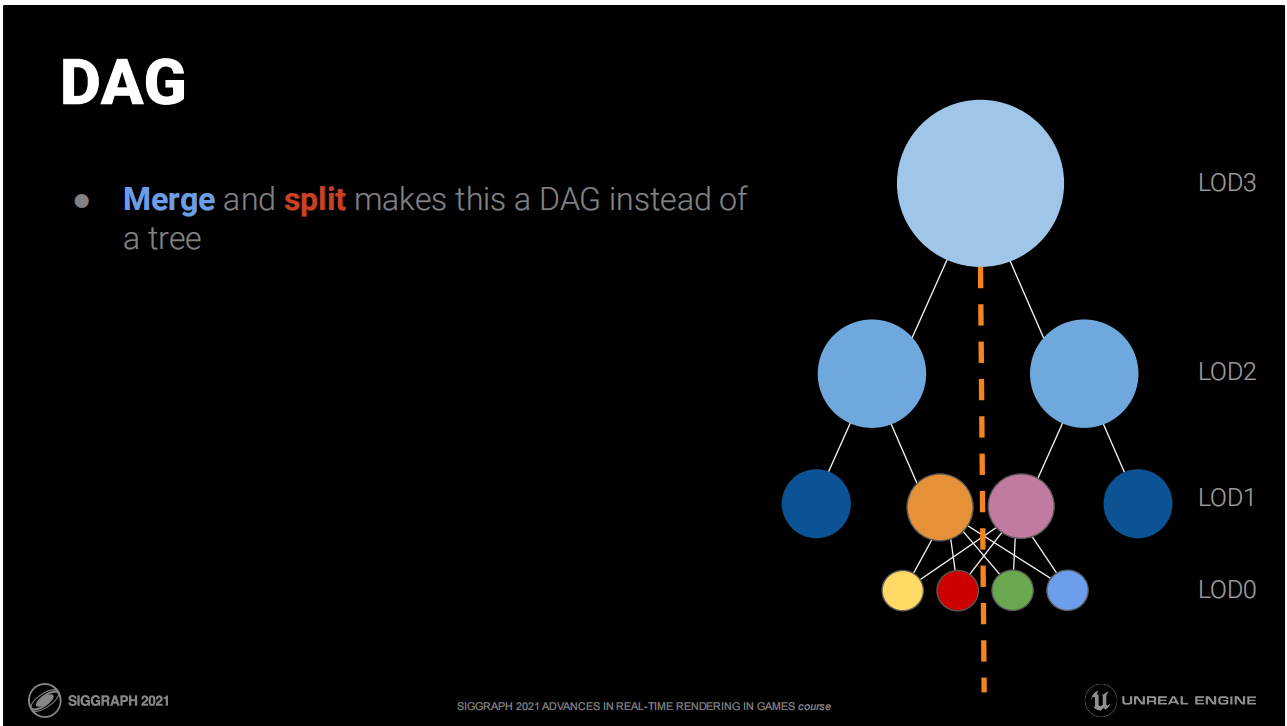
融合和拆分操作使这个结构是一个DAG而不是树。

DAG:哪些集群分为一组
将有着最多共享边缘的集群分为一组——更少边缘等于更少锁定边缘。
这类问题被称为图分割问题。图分割可以用来最小化边缘切割的消耗:
- 图节点=集群
- 图边缘=通过直接相连的三角形连接集群
- 图边缘权重=共享三角形边缘的数量
- 对于空间上闭合的集群需要额外的图边缘——为“孤岛”添加空间信息
最小化图边缘切割等于锁定最少边缘。可以使用METIS库来辅助(METIS是一款高效数据分割与图划分工具)。

初始的集群
需要优化很多变量:
- 为了剔除的效果,需要尽量少扩张集群的包围盒
- 集群中三角形的数量需要尽量接近,但不超过128个以符合光栅化过程
- 基于原始shader的限制,顶点的数量还是不能超限
- 最小化集群的外界边数,以减少对网格简化过程的限制
*这部分直接翻译自解说稿,因为比页内的内容更清楚一些。

图分割
- 由于不可能优化所有方面,因此选择了两个相关的维度进行优化,并期待其它方面最终能有效:优化集群边缘边的数量及每个集群三角形的数量。
- 这和之前集群分组面临的是一样的问题——图是网格的对偶。
- 对于划分的上限需要严格限制:图分割算法并不能保证这一点,因此需要通过适当的放松条件和替代方案等强制其生效。

*最终发现初始化三角形集群和拆分三角形集群是在做同一件事。

网格简化
- 边缘塌陷(指维度上合并折叠)
- 选择误差最小的边缘开始
- 误差估计采用被称为QEM(Quadric Error Metric)的方法
- 在优化新顶点的位置使尽量引入最小误差
- 整体方案是高度精炼和改进的
- 需要返回误差估计——否则后续在投射到屏幕空间时就会导致像素误差,而这是最困难的部分
*后面分享者还提到了一些具体的困难,例如尽管可以用启发式分析算法来分析像素误差,有时候对于具体的法线、材质、顶点颜色等是无法抛开其应用场合(或重要程度)来保证结果的,但这些在网格简化的过程中并不全部知道。
*后面还有几页介绍了误差分析的一些细节问题,以及在预过滤方面暂时不支持(未来想引入)的一些课题。篇幅原因也不展开了,有兴趣的可以去看原文。
结语
之前读的《漫威蜘蛛侠2》的GDC分享中,Insomiac对于自动化的处理两层建筑LOD都已经用尽了各种复杂的组合方案;而这里UE5要提供的是一套普适的应对高清3D美术资产的方案,显然是更复杂维度更多的方案,里面引用的大量前人的技术积累让人看起来头晕目眩。
总结来说,UE5的多边形魔法主要来自全新的GPU驱动管线、渲染后期步骤的逐像素流程以及定制化的网格LOD结构——这部分主要涉及了他们整套管线设计方案的方方面面,很细致也很有革新性。尤其是LOD整体方案,确实如他们所说是一个“不断精进”的过程。
直到今年开始,一些后立项的高清渲染游戏例如《影之刃:零》才开始逐步放出消息,回头算算估计也是和UE5推出几乎同步开始开发的;以后这类只面向更高画质的大型3A游戏可能会逐渐多起来,但这需要UE5的这套新技术框架经得住更多商业的考验。
最容易想到的两个问题,一个是这套机制它要能自己稳定运行,即减少引入BUG和无法人工补救的问题;另一个方面就是它有相对更高的硬件性能要求,因为它的设计初衷就是面向高质量3A项目的,实际上从玩家的角度看来,这个时代的硬件设备可能还没有准备好迎接它。
下一篇文章中会覆盖他们提到的运行时的一些细节,看看有了这些框架和数据结构后运行时又有哪些新课题。
最后是一些资料链接:
Nanite A Deep Dive 原文地址
之前的数据结构方案 Quick-VDR 介绍
之前的数据结构方案Batched Multi-triangulation的论文页