最近看csgo的飾品價格一個個都漲瘋了,相信不少兄弟們都有跟倉賭一波的衝動。我也不例外
然而比起單純的用自己的主觀判斷去加倉,我在想能不能用一些客觀存在的數學規律去預測飾品價格來得到更高的利潤,於是便想用lstm人工智能模型去預測csgo飾品價格的發展

價格漲瘋了
由於我還未爬取第三方交易平臺上飾品的資料,而飾品和股票價格同屬時間序列或順序數據,於是本篇文章將以蘋果(Apple)公司股票價格預測為例例一個一看便懂的預測模型。
兄弟們只要把輸入的data替換成某一飾品的價格便可得到關於這單一飾品的預測模型。使用簡便,對手殘黨十分友好。話不多說,直接到代碼部分

1. 股票數據的獲取
import math
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
首先,我們將使用yFinance來獲取股票數據。yFinance 是一個開源的 Python 庫,它允許我們免費從 Yahoo Finance(yfinance) 獲取股票數據
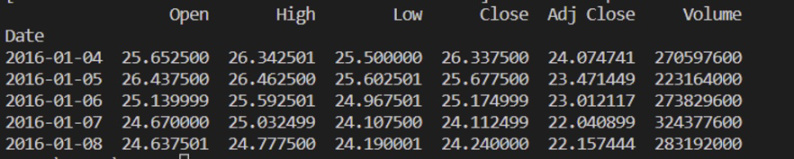
stock_data = yf.download('AAPL', start='2016-01-01', end='2021-10-01')
print(stock_data.head())
### 使用yFinance下載方式獲取2016年1月1日至2021年10月1日的股票數據,然後預覽數據。
2.可視化股票價格歷史
在準備構建 LSTM 模型之前,我們可以通過繪製折線圖來了解一下 AAPL 的歷史價格走勢
plt.figure(figsize=(15, 8))
plt.title('Stock Prices History')
## 設置繪圖圖形大小和標題。
plt.plot(stock_data['Close'])
## 創建 AAPL 收盤價的折線圖
plt.xlabel('Date')
plt.ylabel('Prices ($)')
## 設x軸y軸標籤
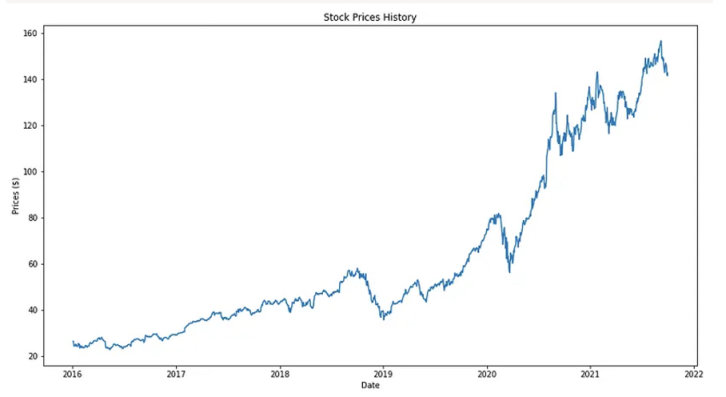
就是說五年前全部梭哈apple好像也不錯wwwww
3. 數據預處理
要構建 LSTM 模型,我們需要將股票價格數據分成訓練集和測試集。此外,我們還將規範化我們的數據,使所有值都在 0 到 1 之間
3.1 訓練集的準備
在這裡,我們只需要數據集中的收盤價來訓練我們的 LSTM 模型。我們將從我們獲得的股票數據中提取 80% 的收盤價作為我們的訓練集
close_prices = stock_data['Close']
values = close_prices.values
training_data_len = math.ceil(len(values)* 0.8)
## 計算 80% 數據集的數據大小。math.ceil方法是為了確保數據大小向上取整。
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(values.reshape(-1,1))
## 使用Scikit-Learn MinMaxScaler對範圍從 0 到 1 的所有股票數據進行歸一化。我們還將歸一化數據重塑為二維數組
train_data = scaled_data[0: training_data_len, :]
## 將前80%的股票數據分出來作為訓練集
x_train = []
y_train = []
for i in range(60, len(train_data)):
x_train.append(train_data[i-60:i, 0])
y_train.append(train_data[i, 0])
## 創建一個 60 天的歷史價格窗口 ( i-60 ) 作為我們的特徵數據 ( x_train ),並創建接下來的 60 天窗口作為標籤數據 ( y_train )。
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
## 將特徵數據 ( x_train ) 和標籤數據 ( y_train ) 轉換為Numpy 數組,因為它是 Tensorflow 在訓練神經網絡模型時接受的數據格式。作為訓練 LSTM 模型要求的一部分,再次將x_train和y_train重塑為三維數組
3.2 測試集準備
test_data = scaled_data[training_data_len-60: , : ]
## 從我們的標準化數據集(數據集的最後 20%)中提取收盤價。
x_test = []
y_test = values[training_data_len:]
for i in range(60, len(test_data)):
x_test.append(test_data[i-60:i, 0])
## 從測試集中創建特徵數據 ( x_test ) 和標籤數據 ( y_test )
x_test = np.array(x_test)
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
3.3 建立 LSTM 網絡架構
model = keras.Sequential()
## 定義一個由線性堆棧層組成的順序模型
model.add(layers.LSTM(100, return_sequences=True, input_shape=(x_train.shape[1], 1)))
## 通過給它 100 個網絡單元添加一個LSTM 層。將return_sequence設置為 true,以便該層的輸出將是另一個相同長度的序列。
model.add(layers.LSTM(100, return_sequences=False))
## 添加另一個具有 100 個網絡單元的 LSTM 層。但是這次我們將return_sequence設置為false以僅返回輸出序列中的最後一個輸出
model.add(layers.Dense(25))
## 添加一個具有 25 個網絡單元的密集連接的神經網絡層
model.add(layers.Dense(1))
## 最後,添加一個密集連接層,指定 1 個網絡單元的輸出
model.summary()
## 顯示我們的 LSTM 網絡架構的摘要
3.4 訓練LSTM模型
在這個階段,我們幾乎準備好通過將其與訓練集擬合來訓練我們的 LSTM 模型。在此之前,我們必須為我們的模型設置一個優化器和一個損失函數
model.compile(optimizer='adam', loss='mean_squared_error')
## 採用“ adam ”優化器並將均方誤差設置為損失函數
model.fit(x_train, y_train, batch_size= 1, epochs=3)
## 通過將模型與訓練集進行擬合來訓練模型。我們可以嘗試將 batch_size 設置為 1 並運行 3 個 epoch 的訓練
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions)

3.5 可視化預測價格
data = stock_data.filter(['Close'])
train = data[:training_data_len]
validation = data[training_data_len:]
validation['Predictions'] = predictions
plt.figure(figsize=(16,8))
plt.title('Model')
plt.xlabel('Date')
plt.ylabel('Close Price USD ($)')
plt.plot(train)
plt.plot(validation[['Close', 'Predictions']])
plt.legend(['Train', 'Val', 'Predictions'], loc='lower right')
plt.show()
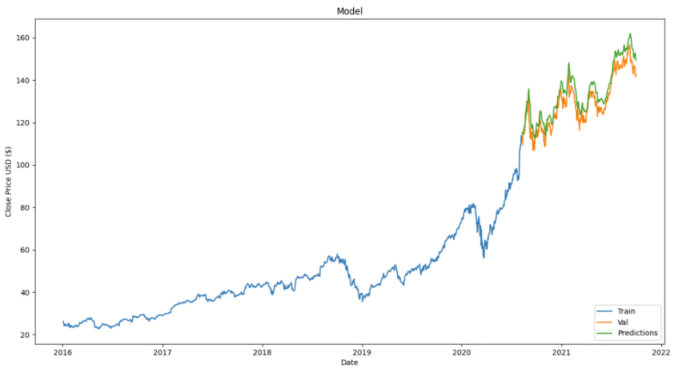
從上面的結果圖表中,我們可以看到預測的股價與實際股價的走勢非常接近。這顯示了 LSTM 處理時間序列或順序數據(如股票價格)的有效性。
以上就是model的訓練方法,下面是訓練自己的模型預測飾品價格的tips~
1. 更改訓練集只需在3.1處把close_prices給替換了就行
print(close_prices)
print(type(close_prices))
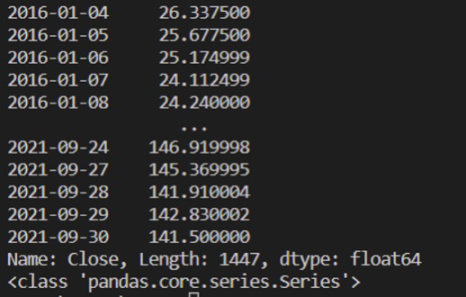
close_prices的數據類型:pandas.Series
2. 請務必注意,預測僅基於歷史價格走勢,而歷史價格走勢通常不會是影響未來價格走勢的唯一因素,因此模型使用僅供參考
3. 不僅是飾品預測,股價預測等,模型在數學建模比賽也能得到應用(只要是序列數據)
期待各位的好消息~
問一下大家還對編程的哪方面感興趣呢
#ai人工智能# #steam遊戲# #pc遊戲#