最近看csgo的饰品价格一个个都涨疯了,相信不少兄弟们都有跟仓赌一波的冲动。我也不例外
然而比起单纯的用自己的主观判断去加仓,我在想能不能用一些客观存在的数学规律去预测饰品价格来得到更高的利润,于是便想用lstm人工智能模型去预测csgo饰品价格的发展

价格涨疯了
由于我还未爬取第三方交易平台上饰品的资料,而饰品和股票价格同属时间序列或顺序数据,于是本篇文章将以苹果(Apple)公司股票价格预测为例例一个一看便懂的预测模型。
兄弟们只要把输入的data替换成某一饰品的价格便可得到关于这单一饰品的预测模型。使用简便,对手残党十分友好。话不多说,直接到代码部分

1. 股票数据的获取
import math
import yfinance as yf
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
首先,我们将使用yFinance来获取股票数据。yFinance 是一个开源的 Python 库,它允许我们免费从 Yahoo Finance(yfinance) 获取股票数据
stock_data = yf.download('AAPL', start='2016-01-01', end='2021-10-01')
print(stock_data.head())
### 使用yFinance下载方式获取2016年1月1日至2021年10月1日的股票数据,然后预览数据。
2.可视化股票价格历史
在准备构建 LSTM 模型之前,我们可以通过绘制折线图来了解一下 AAPL 的历史价格走势
plt.figure(figsize=(15, 8))
plt.title('Stock Prices History')
## 设置绘图图形大小和标题。
plt.plot(stock_data['Close'])
## 创建 AAPL 收盘价的折线图
plt.xlabel('Date')
plt.ylabel('Prices ($)')
## 设x轴y轴标签
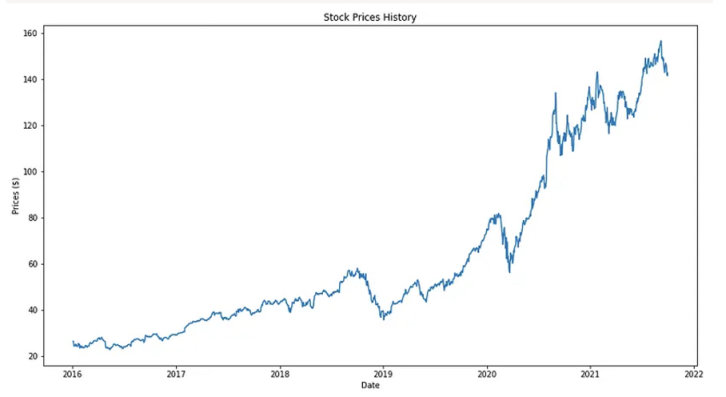
就是说五年前全部梭哈apple好像也不错wwwww
3. 数据预处理
要构建 LSTM 模型,我们需要将股票价格数据分成训练集和测试集。此外,我们还将规范化我们的数据,使所有值都在 0 到 1 之间
3.1 训练集的准备
在这里,我们只需要数据集中的收盘价来训练我们的 LSTM 模型。我们将从我们获得的股票数据中提取 80% 的收盘价作为我们的训练集
close_prices = stock_data['Close']
values = close_prices.values
training_data_len = math.ceil(len(values)* 0.8)
## 计算 80% 数据集的数据大小。math.ceil方法是为了确保数据大小向上取整。
scaler = MinMaxScaler(feature_range=(0,1))
scaled_data = scaler.fit_transform(values.reshape(-1,1))
## 使用Scikit-Learn MinMaxScaler对范围从 0 到 1 的所有股票数据进行归一化。我们还将归一化数据重塑为二维数组
train_data = scaled_data[0: training_data_len, :]
## 将前80%的股票数据分出来作为训练集
x_train = []
y_train = []
for i in range(60, len(train_data)):
x_train.append(train_data[i-60:i, 0])
y_train.append(train_data[i, 0])
## 创建一个 60 天的历史价格窗口 ( i-60 ) 作为我们的特征数据 ( x_train ),并创建接下来的 60 天窗口作为标签数据 ( y_train )。
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))
## 将特征数据 ( x_train ) 和标签数据 ( y_train ) 转换为Numpy 数组,因为它是 Tensorflow 在训练神经网络模型时接受的数据格式。作为训练 LSTM 模型要求的一部分,再次将x_train和y_train重塑为三维数组
3.2 测试集准备
test_data = scaled_data[training_data_len-60: , : ]
## 从我们的标准化数据集(数据集的最后 20%)中提取收盘价。
x_test = []
y_test = values[training_data_len:]
for i in range(60, len(test_data)):
x_test.append(test_data[i-60:i, 0])
## 从测试集中创建特征数据 ( x_test ) 和标签数据 ( y_test )
x_test = np.array(x_test)
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
3.3 建立 LSTM 网络架构
model = keras.Sequential()
## 定义一个由线性堆栈层组成的顺序模型
model.add(layers.LSTM(100, return_sequences=True, input_shape=(x_train.shape[1], 1)))
## 通过给它 100 个网络单元添加一个LSTM 层。将return_sequence设置为 true,以便该层的输出将是另一个相同长度的序列。
model.add(layers.LSTM(100, return_sequences=False))
## 添加另一个具有 100 个网络单元的 LSTM 层。但是这次我们将return_sequence设置为false以仅返回输出序列中的最后一个输出
model.add(layers.Dense(25))
## 添加一个具有 25 个网络单元的密集连接的神经网络层
model.add(layers.Dense(1))
## 最后,添加一个密集连接层,指定 1 个网络单元的输出
model.summary()
## 显示我们的 LSTM 网络架构的摘要
3.4 训练LSTM模型
在这个阶段,我们几乎准备好通过将其与训练集拟合来训练我们的 LSTM 模型。在此之前,我们必须为我们的模型设置一个优化器和一个损失函数
model.compile(optimizer='adam', loss='mean_squared_error')
## 采用“ adam ”优化器并将均方误差设置为损失函数
model.fit(x_train, y_train, batch_size= 1, epochs=3)
## 通过将模型与训练集进行拟合来训练模型。我们可以尝试将 batch_size 设置为 1 并运行 3 个 epoch 的训练
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions)

3.5 可视化预测价格
data = stock_data.filter(['Close'])
train = data[:training_data_len]
validation = data[training_data_len:]
validation['Predictions'] = predictions
plt.figure(figsize=(16,8))
plt.title('Model')
plt.xlabel('Date')
plt.ylabel('Close Price USD ($)')
plt.plot(train)
plt.plot(validation[['Close', 'Predictions']])
plt.legend(['Train', 'Val', 'Predictions'], loc='lower right')
plt.show()
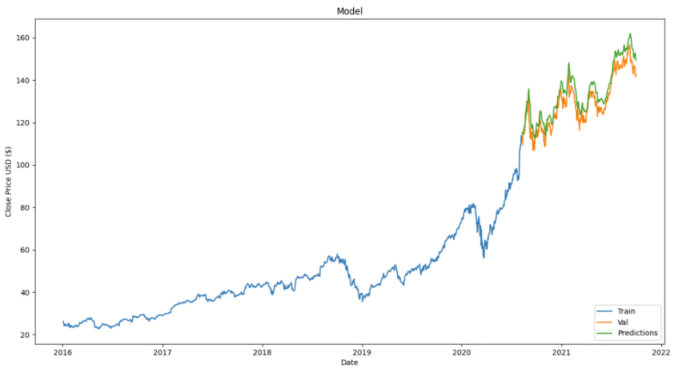
从上面的结果图表中,我们可以看到预测的股价与实际股价的走势非常接近。这显示了 LSTM 处理时间序列或顺序数据(如股票价格)的有效性。
以上就是model的训练方法,下面是训练自己的模型预测饰品价格的tips~
1. 更改训练集只需在3.1处把close_prices给替换了就行
print(close_prices)
print(type(close_prices))
close_prices的数据类型:pandas.Series
2. 请务必注意,预测仅基于历史价格走势,而历史价格走势通常不会是影响未来价格走势的唯一因素,因此模型使用仅供参考
3. 不仅是饰品预测,股价预测等,模型在数学建模比赛也能得到应用(只要是序列数据)
期待各位的好消息~
问一下大家还对编程的哪方面感兴趣呢
#ai人工智能# #steam游戏# #pc游戏#