
在之前的技術文章中我們已經詳細介紹過,銳龍7040配備了AMD第一代NPU,而銳龍8040系列則搭載了第二代NPU,它們都基於XDNA架構,而到了Ryzen AI 300系列,AMD正式為它配備了基於XDNA 2架構的NPU,使其算力暴增到50TOPS,遠遠超過了微軟Copilot PC+的40TOPS性能需求和一眾競品。那麼XDNA 2架構到底強在哪兒?為什麼它能提供遠超常規處理器的AI計算性能?在前不久AMD於美國洛杉磯舉行的 2024 Tech Day大會上,AMD高級副總裁、人工智能負責人Vamsi Boppana為大家進行了詳細的講解。
專業的事交給專業的U:XDNA打造的NPU更適合高效AI計算
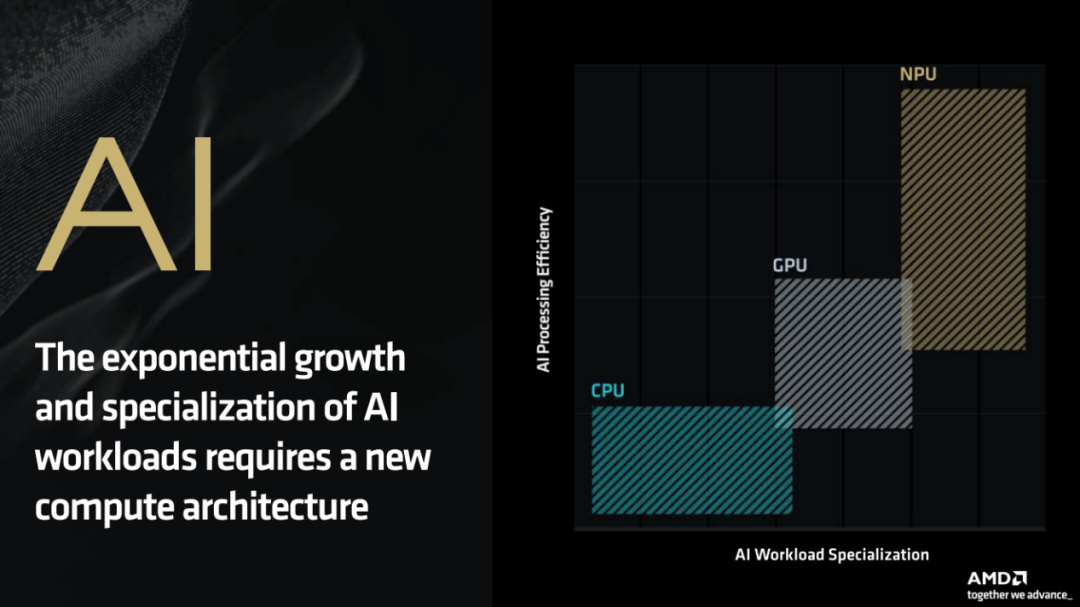
在AI PC時代,AI應用的特定性決定了它更需要一種專用的全新架構來提供更高能效的計算。
從圖中可以看到,隨著AI應用負載越來越特殊化,CPU和GPU在計算能效比方面已經捉襟見肘,而NPU這種專為AI計算而生的處理器明顯在這方面優勢很大。

那麼為什麼NPU是AI PC時代處理器必備的功能呢?
從圖中我們可以看到,AI應用方面,模型的規模和多樣性都在不斷地增長,越來越成為操作系統不可或缺的一部分,因此提升AI計算的效率就比以往任何時候都顯得更重要。
從AI模型每瓦性能對比可以看到,相對CPU來講,核顯可以提供大約8倍的能效,而NPU則可以提供高達35倍的能效,毫無疑問在 AI計算方面,NPU是能效表現最高的存在。
AMD Ryzen AI 300系列移動處理器作為新一代全能AI處理器,可以同時提供全新CPU、NPU和GPU架構,帶來全新的AI PC使用體驗。
到2024年,第三代AMD Ryzen AI已經擁有超過150個AI助力的ISV,AI生態圈的發展非常迅猛。
Ryzen AI使用的XDNA架構之所以最適合AI計算,最大的原因就是它採用了靈活的計算結構與更具適應性的內存層次結構,相對傳統的多核心處理器架構來講,它不會出現數據堵塞的情況。同時,它通過軟件管理內存,不會出現緩存未命中,因此擁有穩定而準確的性能表現。此外,它的可編程互聯設計可以有效降低內存帶寬消耗並實現資源阻隔。上面這兩點讓它還可以實現計算單元的靈活分區,就像圖上所示,它可以用8個AIE來完成實時視頻、8個AIE來完成實時音頻,16個AIE來完成內容創作,空間的可重構、高效的多任務性能保證了AI計算的實時性能。銳龍7040/8040上採用的NPU就採用了XDNA架構,從實際表現來看也達到了預期的高能效AI計算效果。
大幅升級!XDNA 2再次在架構上領先業界
在Ryzen AI 300移動處理器上,我們迎來了XDNA 2架構。XDNA 2在XDNA的基礎上將AIE(AI引擎)單元從20個提升到了32個,每TIE提供雙倍的MACs,片上內存增加60%,外加增強的非線性支持與獨有的Block Floating Point模式支持。和銳龍7040的第一代NPU相比,採用XDNA 2架構的第三代NPU最高支持8個空間併發流,大幅增強多任務能力,提供了5倍的計算性能。同時,由於XDNA 2還採用了基於列的電源門控,因此也可以提供更長的續航能力,所以第三代NPU擁有了兩倍於初代NPU的能效表現。
接下來介紹的Block Floating Point模式可以算是XDNA 2的終極奧義了。我們知道,目前的AI應用有兩種常見的數據精度,大多數AI應用使用了16bit的精度,也就是FP16(16bit浮點)模式,而移動平臺為了更高的效率一般會採用8位精度,也就是INT8(8位整數)模式。很顯然,FP16擁有更高的精度,而INT8則擁有更高的效率,那麼有沒有辦法兩者兼得呢?AMD為XDNA 2配備的,就是兼具兩者性能與精度優點的Block FP16模式。
從AMD官方數據來看,Block FP16吞吐量幾乎持平INT8/W8A8,大約兩倍於INT8/W8A16——很明顯INT8在處理8位權重和16位激活的數據類型時是遠不及Block FP16的。在9位存儲的模型體積方面,Block FP16只比INT8略高,遠低於FP16,這也有效節約了存儲空間。在16bit精度方面,使用LIama2-7B模型測試,Block FP16可以達到FP16大約99.9%的精度,比INT8/W8A16更高,更是高出INT8/W8A8一倍。由此可見,Block FP16結合了INT8的高性能與FP16的高精度優勢,讓XDNA 2架構打造的第三代Ryzen AI NPU能夠發揮出遙遙領先對手的AI算力。實際上,我們從圖上還可以看到,Block FP16即便是和FP32基線相比,也幾乎沒有什麼精度損失,這也就意味著Block FP16給ISV們帶來FP16/FP32或者Block FP16訓練的模型提供了一條強力的“匝道”。
從實測Float16峰值性能來看,XDNA 2架構打造的第三代Ryzen AI NPU擁有最高50TOPS的算力,遠超Apple M4 ANE、Intel Lunar Lake NPU和高通驍龍Elite X NPU。
綜合來看,XDNA 2架構在XDNA的基礎上進一步擴大規模,並提供了對Block FP16 的支持,從而讓它擁有了業界領先的AI算力,提供當下無與倫比的AI高效加速體驗。
強大生態圈助力第三代Ryzen AI起飛
在硬件方面,XDNA 2已經交出了令人滿意的答卷,那麼在配套的生態圈部分呢?
AMD與微軟多年來的深度合作已經在AI生態圈的打造方面有了巨大的進展,包括感知殼體、生成式AI和協作與溝通,目前所有的模型都已經可以工作,在基於XDNA 2架構的NPU上,可以獲得出色的Copilot+體驗。
大家最為熟悉的Stable Diffusion XL Turbo本地AI圖片生成工具也提供了對Block FP16的支持,可以在XDAN 2架構的NPU上實現超快的圖片生成操作。
LIama2大語言模型也可以利用Block FP16來同時提供高精度和高性能,從AMD官方數據來看,在基於LIama2 7B模型的AI響應速度對比中,XDNA 2架構的Ryzen AI NPU可以提供五倍於競品酷睿Ultra 7 155H內置NPU的響應速度。
在本地檢索增強生成(RAG)演示中,使用LIama2-7B模型的RAG可以在第三代Ryzen AI NPU上完美運行,當然,用戶也可以隨時給本地RAG“喂”上更新的資料,讓它在回答問題時能夠提供更加準確的結果。
對於開發者來講,可以非常輕鬆地利用Ryzen AI開發出成千上萬的模型。
Ryzen AI擁有更廣的模型支持度,支持1000+的模型,包括CNN和Transformer,支持不同的數據類型,包括INT4/8以及Block FP16、FP 16等等。
同時也優化了Halo模型,支持LIama、Mistral、Qwen大語言模型和Stable Diffusion文生圖。
在執行端,Ryzen AI也支持ONNX運行時,最終打造出運行在銳龍AI筆記本上的應用集合。
AMD的統一AI軟件棧讓Ryzen AI APU的CPU+NPU+GPU三位一體AI加速架構可以讓ISV提供更佳的AI應用體驗。
其中在AI模型與算法方面,對開源平臺的PyTorch、TensorFlow和ONNX提供了很好的支持;
在函數庫方面,為CPU(Zen5)/GPU(RDNA 3.5)/NPU(XDNA 2)都提供了運行時,支持AI工作負載分區、編譯和優化功能。
當然,硬件基礎方面也少不了強大的CPU(Zen5)+ GPU(RDNA 3.5)+ NPU(XDNA 2)三位一體AI加速架構。
寫在最後
最後簡單總結一下,Ryzen AI 300移動處理器內置的XDNA 2架構Ryzen AI NPU是當前性能最強的NPU,XDNA 2在XDNA的基礎上進一步擴展規模,大幅提升性能,這使得它擁有了高達50TOPS的峰值算力,領先業界的同時也成為Copilot+PC當下最佳選擇,堪稱世界首款“Win24 ready”的X86內置NPU。
同時,XDNA 2還帶來了獨有的Block FP16支持,可以實現接近INT8的性能與FP16的精準度,此外,它還支持高級數據類型、提供廣泛的模型支持,在統一AI軟件棧的支持下更是讓ISV能夠提供更好的AI使用體驗。
綜合來講,在AI PC時代,入手具備XDNA 2架構第三代Ryzen AI NPU的銳龍AI PC,無疑能獲得當下最佳的AI應用體驗,同時也能更好地支持未來深度綁定AI功能的Windows操作系統。