
在之前的技术文章中我们已经详细介绍过,锐龙7040配备了AMD第一代NPU,而锐龙8040系列则搭载了第二代NPU,它们都基于XDNA架构,而到了Ryzen AI 300系列,AMD正式为它配备了基于XDNA 2架构的NPU,使其算力暴增到50TOPS,远远超过了微软Copilot PC+的40TOPS性能需求和一众竞品。那么XDNA 2架构到底强在哪儿?为什么它能提供远超常规处理器的AI计算性能?在前不久AMD于美国洛杉矶举行的 2024 Tech Day大会上,AMD高级副总裁、人工智能负责人Vamsi Boppana为大家进行了详细的讲解。
专业的事交给专业的U:XDNA打造的NPU更适合高效AI计算
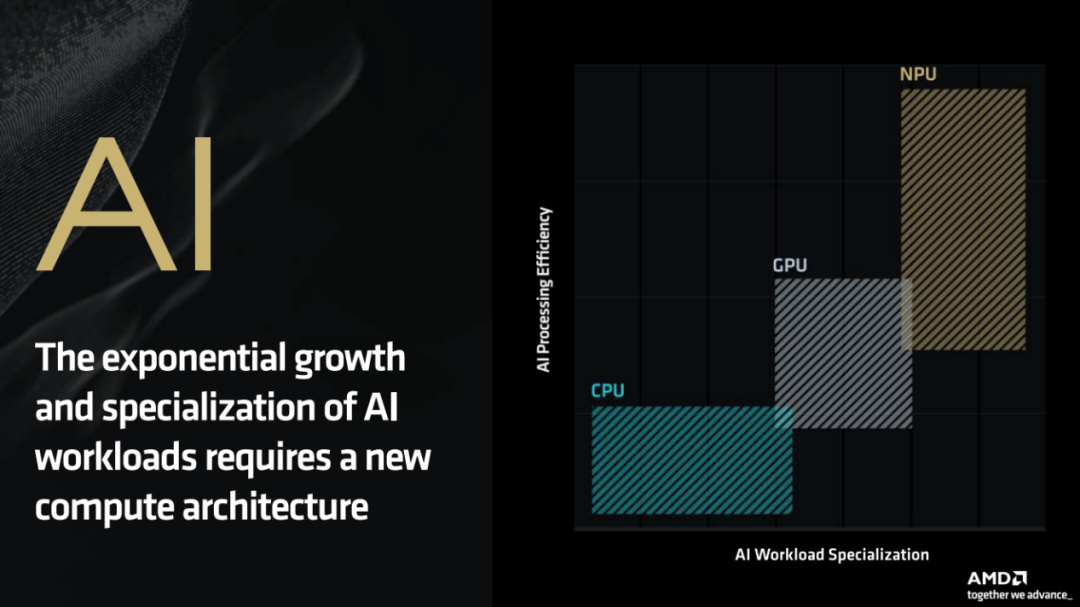
在AI PC时代,AI应用的特定性决定了它更需要一种专用的全新架构来提供更高能效的计算。
从图中可以看到,随着AI应用负载越来越特殊化,CPU和GPU在计算能效比方面已经捉襟见肘,而NPU这种专为AI计算而生的处理器明显在这方面优势很大。

那么为什么NPU是AI PC时代处理器必备的功能呢?
从图中我们可以看到,AI应用方面,模型的规模和多样性都在不断地增长,越来越成为操作系统不可或缺的一部分,因此提升AI计算的效率就比以往任何时候都显得更重要。
从AI模型每瓦性能对比可以看到,相对CPU来讲,核显可以提供大约8倍的能效,而NPU则可以提供高达35倍的能效,毫无疑问在 AI计算方面,NPU是能效表现最高的存在。
AMD Ryzen AI 300系列移动处理器作为新一代全能AI处理器,可以同时提供全新CPU、NPU和GPU架构,带来全新的AI PC使用体验。
到2024年,第三代AMD Ryzen AI已经拥有超过150个AI助力的ISV,AI生态圈的发展非常迅猛。
Ryzen AI使用的XDNA架构之所以最适合AI计算,最大的原因就是它采用了灵活的计算结构与更具适应性的内存层次结构,相对传统的多核心处理器架构来讲,它不会出现数据堵塞的情况。同时,它通过软件管理内存,不会出现缓存未命中,因此拥有稳定而准确的性能表现。此外,它的可编程互联设计可以有效降低内存带宽消耗并实现资源阻隔。上面这两点让它还可以实现计算单元的灵活分区,就像图上所示,它可以用8个AIE来完成实时视频、8个AIE来完成实时音频,16个AIE来完成内容创作,空间的可重构、高效的多任务性能保证了AI计算的实时性能。锐龙7040/8040上采用的NPU就采用了XDNA架构,从实际表现来看也达到了预期的高能效AI计算效果。
大幅升级!XDNA 2再次在架构上领先业界
在Ryzen AI 300移动处理器上,我们迎来了XDNA 2架构。XDNA 2在XDNA的基础上将AIE(AI引擎)单元从20个提升到了32个,每TIE提供双倍的MACs,片上内存增加60%,外加增强的非线性支持与独有的Block Floating Point模式支持。和锐龙7040的第一代NPU相比,采用XDNA 2架构的第三代NPU最高支持8个空间并发流,大幅增强多任务能力,提供了5倍的计算性能。同时,由于XDNA 2还采用了基于列的电源门控,因此也可以提供更长的续航能力,所以第三代NPU拥有了两倍于初代NPU的能效表现。
接下来介绍的Block Floating Point模式可以算是XDNA 2的终极奥义了。我们知道,目前的AI应用有两种常见的数据精度,大多数AI应用使用了16bit的精度,也就是FP16(16bit浮点)模式,而移动平台为了更高的效率一般会采用8位精度,也就是INT8(8位整数)模式。很显然,FP16拥有更高的精度,而INT8则拥有更高的效率,那么有没有办法两者兼得呢?AMD为XDNA 2配备的,就是兼具两者性能与精度优点的Block FP16模式。
从AMD官方数据来看,Block FP16吞吐量几乎持平INT8/W8A8,大约两倍于INT8/W8A16——很明显INT8在处理8位权重和16位激活的数据类型时是远不及Block FP16的。在9位存储的模型体积方面,Block FP16只比INT8略高,远低于FP16,这也有效节约了存储空间。在16bit精度方面,使用LIama2-7B模型测试,Block FP16可以达到FP16大约99.9%的精度,比INT8/W8A16更高,更是高出INT8/W8A8一倍。由此可见,Block FP16结合了INT8的高性能与FP16的高精度优势,让XDNA 2架构打造的第三代Ryzen AI NPU能够发挥出遥遥领先对手的AI算力。实际上,我们从图上还可以看到,Block FP16即便是和FP32基线相比,也几乎没有什么精度损失,这也就意味着Block FP16给ISV们带来FP16/FP32或者Block FP16训练的模型提供了一条强力的“匝道”。
从实测Float16峰值性能来看,XDNA 2架构打造的第三代Ryzen AI NPU拥有最高50TOPS的算力,远超Apple M4 ANE、Intel Lunar Lake NPU和高通骁龙Elite X NPU。
综合来看,XDNA 2架构在XDNA的基础上进一步扩大规模,并提供了对Block FP16 的支持,从而让它拥有了业界领先的AI算力,提供当下无与伦比的AI高效加速体验。
强大生态圈助力第三代Ryzen AI起飞
在硬件方面,XDNA 2已经交出了令人满意的答卷,那么在配套的生态圈部分呢?
AMD与微软多年来的深度合作已经在AI生态圈的打造方面有了巨大的进展,包括感知壳体、生成式AI和协作与沟通,目前所有的模型都已经可以工作,在基于XDNA 2架构的NPU上,可以获得出色的Copilot+体验。
大家最为熟悉的Stable Diffusion XL Turbo本地AI图片生成工具也提供了对Block FP16的支持,可以在XDAN 2架构的NPU上实现超快的图片生成操作。
LIama2大语言模型也可以利用Block FP16来同时提供高精度和高性能,从AMD官方数据来看,在基于LIama2 7B模型的AI响应速度对比中,XDNA 2架构的Ryzen AI NPU可以提供五倍于竞品酷睿Ultra 7 155H内置NPU的响应速度。
在本地检索增强生成(RAG)演示中,使用LIama2-7B模型的RAG可以在第三代Ryzen AI NPU上完美运行,当然,用户也可以随时给本地RAG“喂”上更新的资料,让它在回答问题时能够提供更加准确的结果。
对于开发者来讲,可以非常轻松地利用Ryzen AI开发出成千上万的模型。
Ryzen AI拥有更广的模型支持度,支持1000+的模型,包括CNN和Transformer,支持不同的数据类型,包括INT4/8以及Block FP16、FP 16等等。
同时也优化了Halo模型,支持LIama、Mistral、Qwen大语言模型和Stable Diffusion文生图。
在执行端,Ryzen AI也支持ONNX运行时,最终打造出运行在锐龙AI笔记本上的应用集合。
AMD的统一AI软件栈让Ryzen AI APU的CPU+NPU+GPU三位一体AI加速架构可以让ISV提供更佳的AI应用体验。
其中在AI模型与算法方面,对开源平台的PyTorch、TensorFlow和ONNX提供了很好的支持;
在函数库方面,为CPU(Zen5)/GPU(RDNA 3.5)/NPU(XDNA 2)都提供了运行时,支持AI工作负载分区、编译和优化功能。
当然,硬件基础方面也少不了强大的CPU(Zen5)+ GPU(RDNA 3.5)+ NPU(XDNA 2)三位一体AI加速架构。
写在最后
最后简单总结一下,Ryzen AI 300移动处理器内置的XDNA 2架构Ryzen AI NPU是当前性能最强的NPU,XDNA 2在XDNA的基础上进一步扩展规模,大幅提升性能,这使得它拥有了高达50TOPS的峰值算力,领先业界的同时也成为Copilot+PC当下最佳选择,堪称世界首款“Win24 ready”的X86内置NPU。
同时,XDNA 2还带来了独有的Block FP16支持,可以实现接近INT8的性能与FP16的精准度,此外,它还支持高级数据类型、提供广泛的模型支持,在统一AI软件栈的支持下更是让ISV能够提供更好的AI使用体验。
综合来讲,在AI PC时代,入手具备XDNA 2架构第三代Ryzen AI NPU的锐龙AI PC,无疑能获得当下最佳的AI应用体验,同时也能更好地支持未来深度绑定AI功能的Windows操作系统。