大家好。前幾天整了個小活,把Gadio從創始到23年末的2300多期電臺內容做成了可以用語意搜索的向量數據庫,所以就出現了這麼一個所謂的"Gadio高維空間定位系統",名字起的可謂是有理由中二(理由我們後文再說)。今天稍有閒時,於是起意用一篇小文來記錄一下這件事的過程裡覺得值得聊的事情,以及自己的收穫。
用這個系統大概率可以搜到一些我們記憶中的電臺片段到底出自哪一期節目,比如說後來成為了“機組曼德拉效應”的代表片段:酒館裡貓被酒毒死了到底是不是四十二說的?
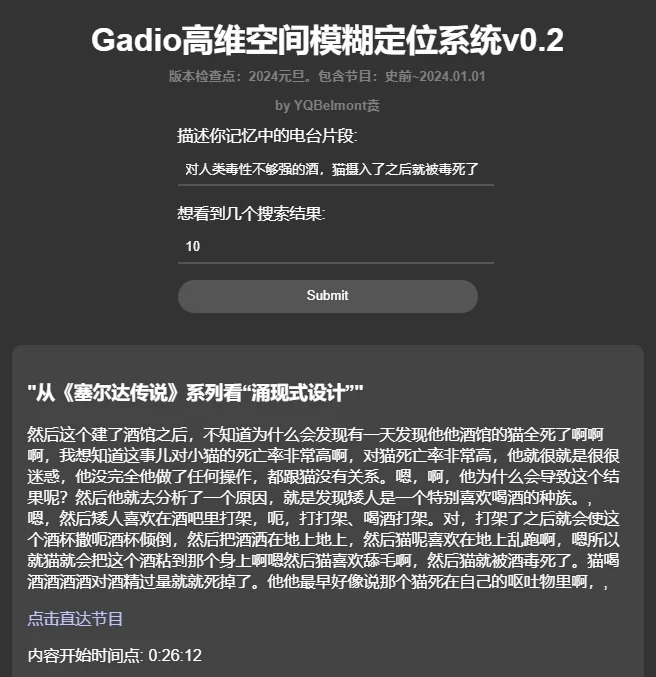
看來的確不是。。。
是這期節目,還真就不是四十二,居然他都沒參加
再比如下面的這麼幾個自己曾經想找卻沒找到的片段↓也都秒速找到了出處。(看來我就是對中元夜話記得特別多……)
- 穿過小洞看到對面,後來發現地上有兩個圓柱形的印記,很像芭蕾舞鞋的痕跡
- 當時在宿舍裡打牌,最後少一張,怎麼找都找不到,最後宿舍老大回來,讓我們全都出去,對著屋裡說了幾句,再開門就找到了那張牌。
- 磚頭下壓著100塊錢
現在這個系統已經上線了,感謝@alizoed 老哥提供部署。如果您馬上就想要測試一下,請直接拉到文末找到鏈接與使用指南。因為這個純語意搜索系統和傳統的關鍵詞搜索用法不太一樣,所以推薦您一定先看一眼使用說明。
好,那麼就開始我們今天的正文了。以下幾件事情:
- 簡陋科普:基於語意的搜索是怎麼做到的??
- 項目簡介:本項目的技術棧和大概構架
- 使用說明和注意事項
一、如何讓電腦理解“恐懼”和“害怕”這兩個詞具有相似性?
這是個非常有意思的問題,“恐懼”和“害怕”這兩個詞,除了都是由兩個字組成之外,從字形和讀音上判斷,幾乎是毫無相似之處,但你說他倆完全等效嗎?也肯定不是。那麼是不是有一種方法,可以讓電腦能夠處理這種微妙的相似和不同呢?人類這麼聰明肯定能想出辦法來,而且這個辦法確實很精彩。
請在腦海中想象一個失重的空間,這個空間裡漂浮著漢語裡所有的詞彙,圍繞著你,非常紛繁複雜,但所有的詞的位置,都是固定不動的。此時,你稍作觀察,找到了“恐懼”和“害怕”這兩個詞,發現他倆都處於你左前方的那個角落裡,而且貼的很近很近。然後你飛過去仔細觀察,發現這兩個詞附近的空間你還能找到“驚悚”“嚇人”這種近意詞,稍微再拓寬一點點視野,你會找到如“夢魘”“魔鬼”這種雖然意思不一樣,但是含義上也會有微妙重合的詞。顯然,這個空間裡漂浮的詞,他們是根據相似的含義聚集在一起的,越是相似的詞,就聚攏得越近。那麼……
此時你福至心靈,回望自己出發的原點,朝著相反的方向望去,果然,你在那裡找到了“幸福”“開心”這種詞。
這個空間,我們可以暫時叫它“語意空間”,每個詞在裡面都有一個點。通過點的座標,我們也可以非常容易地計算出兩個點之間的距離遠近。至此,這種難以捉摸的微妙相似性被轉化為了純粹的數學問題。
二、那具體要怎麼找到每個詞的座標位置呢?
讀到這裡,顯然,這設想還只是個餅,落不了地啊~最關鍵的一點沒解決——要怎麼才能有效地把詞語和句子轉化成有語意特徵的座標點呢?總不能有一個人在那一個個放點吧……這就是自然語言處理(NLP)領域的重要突破——詞嵌入(Word Embedding) 。這個過程是通過一個訓練好的神經網絡模型完成的,這個模型的輸入是一個詞,或者一句話,甚至是一段話,輸出則是一個高維向量,也就是座標值,只不過數量上超過了xyz三個座標數字,來到了幾百上千個維度。(哎,回收封面啊,這就是為啥要叫“高維”定位的原因,合法中二。)
下一個問題,則是為何這個Embedding模型可以做到這一點?簡單來說,這個模型是通過在巨量的文本里面尋找詞語出現的規律,來學習詞語的語意相似性。比如,在它看過的數億個句子裡,出現了好多好多次類似“令人恐懼/害怕的東西經常會出現在噩夢/夢魘中。”這種表達,有時候句子裡用的是“恐懼”有時候用的是“害怕”,那麼這個模型就會基於此,學到這兩個詞是相似的。當然,實際情況還要複雜得多,比如除了同義詞,近義詞,還會學到反義詞,上下位詞,但究其根本,是統計學意義上的規律。具體的展開各位可以搜索Embedding模型訓練原理,肯定有大佬做過更有效的講述,此處不多展開(避免露怯)
至此,我們居然做到了隨便給一句話或者一段話,就能把它變成高維空間中的一個有著具體位置的點。(在Gadio這個項目裡用到的是阿里的 damo/nlp_gte_sentence-embedding_chinese-base這個模型,沒記錯的話是768維度。也就是說你給它輸入一個詞或者句子,它會返回給你768個數字,代表了一個768維空間中的點,這個點的位置,就包含了輸入文字的語意特徵。)
三、妥了,那隻要把電臺文本向量化就可以了嘛。
那麼剩下的就簡單很多了,我們只需要把電臺的所有文本都逐個餵給Embedding模型,然後把向量存起來,到時候查詢的人來了,把查詢的內容也轉換成768維度的空間中的一個點,就好像一個燈塔,只要把它周圍距離最近的幾個點抓回來,也就是我們的搜索結果了。
這裡面落地的過程中還有很多細碎的問題,我直接枚舉到下方,也就直接交代清楚了這個項目的流程。
第一個任務:語音轉文字。這個過程一開始用的是OpenAI的Whisper,後來發現非常不好用!首先很慢,其次中文的準確度和穩定性都很差,動不動就一整篇的無限復讀重複,就不截圖了。總之,最後用的是阿里家的 funasr 裡面的 paraformer-zh 這個模型,效果拔群,經過一張4090顯卡150小時的奮戰,成功將2300多期電臺轉化為了15m大小的TXT。(沒錯,只有15m)
第二個任務:文字切塊。這個過程基本是把一整個電臺的文本切成小塊,這樣語意的特徵會更加集中,會更容易按某一個具體的內容搜索到正確的結果。這裡採用了很常規的方法,就是為了防止恰好內容被切斷,每一個塊都和它的前後有50%的重疊。也感謝語音識別模型穩定的發揮,得以讓我們在標點符號處切割,至少不會把句子截斷。這樣切割後,文字量直接翻倍。
第三個任務:向量化。無需多言,一片片文本塞給Emebedding模型,然後把得到的向量一個個保存好。向量化之後數據量直接來到了5G,5個G全是數字啊朋友們,打開一看老嚇人了。
第四個任務:整理元數據+灌庫。以上整個過程裡最好數據的標籤,保證最後的每一個向量都能準確地反過去查找到“原文”、“時間戳”、“電臺節目名字”、“電臺網址”這幾個東西,然後聯合向量,變成一條條的數據灌入ChromaDB(一個最近還挺流行的免費向量數據庫工具。)為啥要用數據庫吶?因為快和方便~如果直接是硬搜,會導致每一次查詢都和5個G的數據一條條對比,很災難。但是向量數據庫會自動把內容分簇,先找到最接近的那一簇,然後再往下面的分支裡走,這樣可以很快就找到結果。
這裡還可以再展開聊一個“歐式距離”和“餘弦距離”的事兒,也很有意思。這是兩種不同的計算空間中兩個點的距離的方法,很微妙地反應出了數學算法和抽象語意之間的關係。
簡單說,餘弦距離是站在座標原點看角度,只要這兩個點,從我座標原點看過去幾乎重合,哪怕他倆在空間中距離很遠,我也算他倆很接近。好比我們人看到金星凌日,金星撞進太陽裡了,其實人家倆距離遠著呢,只是從我們的角度看很近。
乍一聽是不是很不合理?哎~好玩就在這裡,人們發現用這種方法去求距離的時候,可以忽略文本長度!也就是說,如果我輸入的搜索文本只有10個字,但是電臺裡這個事兒他們花了100個字才把這事兒說完,用這個方法就可以更有效地匹配到我的輸入和電臺文本之間的相似關係。歐式距離呢,就是真正的兩個點之間連條線,這個線的長度。毫無疑問,在我們的這個場景裡,更適合用餘弦距離。(我當時學會這個區別的時候簡直從椅子上蹦起來。)
第五個任務:編寫後端服務和前端網頁。具體不展開啦!這裡也比較枯燥~(我也不咋會主要是……)
四、地址和使用方法
相信如果您不是跳到這裡的話,使用方法不用我來贅言了。請直接移步地址。但如果您真的是跳過來的,請參考下面這一點點說明:
注意這個不是關鍵詞搜索系統,是語義搜索系統,所以描述長一點反而比單獨一個詞更容易搜到。能想起來的上下文越多越容易搜到。不用準確。也不用說“電臺”字樣。這裡需要大家走出傳統的搜索思路。
正面例(應該能搜到好結果):
- “聖經開頭第46個字和結尾第46個字合起來是莎士比亞”
- “玩完那個結局我就感覺被打了一拳”
- “把這個轉換成小調之後,馬上感覺就不一樣”
- 和女生說 我要 成為你的劍
反面例(很難搜到好結果):
- “聖經 莎士比亞 46”
- “42評論往日之影結局”
- “重輕老師講調式那期節目”
- 成為你的劍
另外這個系統目前不認識人名或者專有名詞,所以“西蒙說xxxxx”這種就直接寫“xxxxx”的內容就可以了。(也可以寫上,萬一呢)
唯一宗旨:用節目里人的說話內容來搜,而不要用局外人的角度。因為畢竟檢索的文本本體是電臺內容的語音識別稿。
最後,系統在這,希望能給您帶來一刻愉快~
地址
Credit:
- @YQBelmont:數據收集、轉錄、檢索系統與網頁
- @alizoed:移植、規範化與正式部署,服務器提供
PS. 如果需要項目源碼和數據庫內容可以私信筆者。
下期預告:還有好玩的
既然我們已經拿到了所有節目的向量,那如果把每個節目裡的向量求個平均值,是不是這個平均向量就能代表這個節目的特徵呢?
於是我們成功地使用自動聚類算法把2300期節目分成了n個類別。而且隨著類別的增多,我們會發現各種有意思的小細節。比如"核市節目確實是非常“獨樹一幟”地特徵鮮明,總能做到自己一類",還有“最像常規節目的新聞節目”,“最不Pro的pro節目”(冒犯)之類的。。。




1 / 4
右滑更多分類
而且隨著類量的增多,可以明顯看出來分類依據有從“內容範式和結構”向“具體垂直領域劃分”變化的趨勢。比如下圖是100類的時候出現的

顯然,被蠻荒之地這期節目打動的我,找到了很多也非常值得重溫的節目,而這些節目裡的大多數都不是“浪潮的把戲”系列裡的,還算蠻驚喜~
當我們對某一個節目引起共鳴的時候,也可以通過這種方法來給自己“算法推薦”一波哈哈哈哈哈。具體下期我們再展開聊,我再探索探索還有沒有別的好玩的。另外站內文章也正在做嗷。