大家好。前几天整了个小活,把Gadio从创始到23年末的2300多期电台内容做成了可以用语意搜索的向量数据库,所以就出现了这么一个所谓的"Gadio高维空间定位系统",名字起的可谓是有理由中二(理由我们后文再说)。今天稍有闲时,于是起意用一篇小文来记录一下这件事的过程里觉得值得聊的事情,以及自己的收获。
用这个系统大概率可以搜到一些我们记忆中的电台片段到底出自哪一期节目,比如说后来成为了“机组曼德拉效应”的代表片段:酒馆里猫被酒毒死了到底是不是四十二说的?
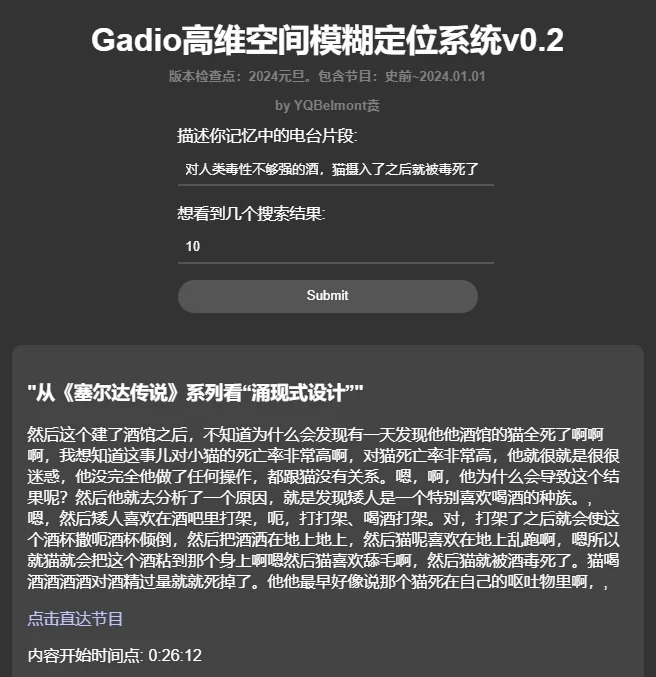
看来的确不是。。。
是这期节目,还真就不是四十二,居然他都没参加
再比如下面的这么几个自己曾经想找却没找到的片段↓也都秒速找到了出处。(看来我就是对中元夜话记得特别多……)
- 穿过小洞看到对面,后来发现地上有两个圆柱形的印记,很像芭蕾舞鞋的痕迹
- 当时在宿舍里打牌,最后少一张,怎么找都找不到,最后宿舍老大回来,让我们全都出去,对着屋里说了几句,再开门就找到了那张牌。
- 砖头下压着100块钱
现在这个系统已经上线了,感谢@alizoed 老哥提供部署。如果您马上就想要测试一下,请直接拉到文末找到链接与使用指南。因为这个纯语意搜索系统和传统的关键词搜索用法不太一样,所以推荐您一定先看一眼使用说明。
好,那么就开始我们今天的正文了。以下几件事情:
- 简陋科普:基于语意的搜索是怎么做到的??
- 项目简介:本项目的技术栈和大概构架
- 使用说明和注意事项
一、如何让电脑理解“恐惧”和“害怕”这两个词具有相似性?
这是个非常有意思的问题,“恐惧”和“害怕”这两个词,除了都是由两个字组成之外,从字形和读音上判断,几乎是毫无相似之处,但你说他俩完全等效吗?也肯定不是。那么是不是有一种方法,可以让电脑能够处理这种微妙的相似和不同呢?人类这么聪明肯定能想出办法来,而且这个办法确实很精彩。
请在脑海中想象一个失重的空间,这个空间里漂浮着汉语里所有的词汇,围绕着你,非常纷繁复杂,但所有的词的位置,都是固定不动的。此时,你稍作观察,找到了“恐惧”和“害怕”这两个词,发现他俩都处于你左前方的那个角落里,而且贴的很近很近。然后你飞过去仔细观察,发现这两个词附近的空间你还能找到“惊悚”“吓人”这种近意词,稍微再拓宽一点点视野,你会找到如“梦魇”“魔鬼”这种虽然意思不一样,但是含义上也会有微妙重合的词。显然,这个空间里漂浮的词,他们是根据相似的含义聚集在一起的,越是相似的词,就聚拢得越近。那么……
此时你福至心灵,回望自己出发的原点,朝着相反的方向望去,果然,你在那里找到了“幸福”“开心”这种词。
这个空间,我们可以暂时叫它“语意空间”,每个词在里面都有一个点。通过点的坐标,我们也可以非常容易地计算出两个点之间的距离远近。至此,这种难以捉摸的微妙相似性被转化为了纯粹的数学问题。
二、那具体要怎么找到每个词的坐标位置呢?
读到这里,显然,这设想还只是个饼,落不了地啊~最关键的一点没解决——要怎么才能有效地把词语和句子转化成有语意特征的坐标点呢?总不能有一个人在那一个个放点吧……这就是自然语言处理(NLP)领域的重要突破——词嵌入(Word Embedding) 。这个过程是通过一个训练好的神经网络模型完成的,这个模型的输入是一个词,或者一句话,甚至是一段话,输出则是一个高维向量,也就是坐标值,只不过数量上超过了xyz三个坐标数字,来到了几百上千个维度。(哎,回收封面啊,这就是为啥要叫“高维”定位的原因,合法中二。)
下一个问题,则是为何这个Embedding模型可以做到这一点?简单来说,这个模型是通过在巨量的文本里面寻找词语出现的规律,来学习词语的语意相似性。比如,在它看过的数亿个句子里,出现了好多好多次类似“令人恐惧/害怕的东西经常会出现在噩梦/梦魇中。”这种表达,有时候句子里用的是“恐惧”有时候用的是“害怕”,那么这个模型就会基于此,学到这两个词是相似的。当然,实际情况还要复杂得多,比如除了同义词,近义词,还会学到反义词,上下位词,但究其根本,是统计学意义上的规律。具体的展开各位可以搜索Embedding模型训练原理,肯定有大佬做过更有效的讲述,此处不多展开(避免露怯)
至此,我们居然做到了随便给一句话或者一段话,就能把它变成高维空间中的一个有着具体位置的点。(在Gadio这个项目里用到的是阿里的 damo/nlp_gte_sentence-embedding_chinese-base这个模型,没记错的话是768维度。也就是说你给它输入一个词或者句子,它会返回给你768个数字,代表了一个768维空间中的点,这个点的位置,就包含了输入文字的语意特征。)
三、妥了,那只要把电台文本向量化就可以了嘛。
那么剩下的就简单很多了,我们只需要把电台的所有文本都逐个喂给Embedding模型,然后把向量存起来,到时候查询的人来了,把查询的内容也转换成768维度的空间中的一个点,就好像一个灯塔,只要把它周围距离最近的几个点抓回来,也就是我们的搜索结果了。
这里面落地的过程中还有很多细碎的问题,我直接枚举到下方,也就直接交代清楚了这个项目的流程。
第一个任务:语音转文字。这个过程一开始用的是OpenAI的Whisper,后来发现非常不好用!首先很慢,其次中文的准确度和稳定性都很差,动不动就一整篇的无限复读重复,就不截图了。总之,最后用的是阿里家的 funasr 里面的 paraformer-zh 这个模型,效果拔群,经过一张4090显卡150小时的奋战,成功将2300多期电台转化为了15m大小的TXT。(没错,只有15m)
第二个任务:文字切块。这个过程基本是把一整个电台的文本切成小块,这样语意的特征会更加集中,会更容易按某一个具体的内容搜索到正确的结果。这里采用了很常规的方法,就是为了防止恰好内容被切断,每一个块都和它的前后有50%的重叠。也感谢语音识别模型稳定的发挥,得以让我们在标点符号处切割,至少不会把句子截断。这样切割后,文字量直接翻倍。
第三个任务:向量化。无需多言,一片片文本塞给Emebedding模型,然后把得到的向量一个个保存好。向量化之后数据量直接来到了5G,5个G全是数字啊朋友们,打开一看老吓人了。
第四个任务:整理元数据+灌库。以上整个过程里最好数据的标签,保证最后的每一个向量都能准确地反过去查找到“原文”、“时间戳”、“电台节目名字”、“电台网址”这几个东西,然后联合向量,变成一条条的数据灌入ChromaDB(一个最近还挺流行的免费向量数据库工具。)为啥要用数据库呐?因为快和方便~如果直接是硬搜,会导致每一次查询都和5个G的数据一条条对比,很灾难。但是向量数据库会自动把内容分簇,先找到最接近的那一簇,然后再往下面的分支里走,这样可以很快就找到结果。
这里还可以再展开聊一个“欧式距离”和“余弦距离”的事儿,也很有意思。这是两种不同的计算空间中两个点的距离的方法,很微妙地反应出了数学算法和抽象语意之间的关系。
简单说,余弦距离是站在坐标原点看角度,只要这两个点,从我坐标原点看过去几乎重合,哪怕他俩在空间中距离很远,我也算他俩很接近。好比我们人看到金星凌日,金星撞进太阳里了,其实人家俩距离远着呢,只是从我们的角度看很近。
乍一听是不是很不合理?哎~好玩就在这里,人们发现用这种方法去求距离的时候,可以忽略文本长度!也就是说,如果我输入的搜索文本只有10个字,但是电台里这个事儿他们花了100个字才把这事儿说完,用这个方法就可以更有效地匹配到我的输入和电台文本之间的相似关系。欧式距离呢,就是真正的两个点之间连条线,这个线的长度。毫无疑问,在我们的这个场景里,更适合用余弦距离。(我当时学会这个区别的时候简直从椅子上蹦起来。)
第五个任务:编写后端服务和前端网页。具体不展开啦!这里也比较枯燥~(我也不咋会主要是……)
四、地址和使用方法
相信如果您不是跳到这里的话,使用方法不用我来赘言了。请直接移步地址。但如果您真的是跳过来的,请参考下面这一点点说明:
注意这个不是关键词搜索系统,是语义搜索系统,所以描述长一点反而比单独一个词更容易搜到。能想起来的上下文越多越容易搜到。不用准确。也不用说“电台”字样。这里需要大家走出传统的搜索思路。
正面例(应该能搜到好结果):
- “圣经开头第46个字和结尾第46个字合起来是莎士比亚”
- “玩完那个结局我就感觉被打了一拳”
- “把这个转换成小调之后,马上感觉就不一样”
- 和女生说 我要 成为你的剑
反面例(很难搜到好结果):
- “圣经 莎士比亚 46”
- “42评论往日之影结局”
- “重轻老师讲调式那期节目”
- 成为你的剑
另外这个系统目前不认识人名或者专有名词,所以“西蒙说xxxxx”这种就直接写“xxxxx”的内容就可以了。(也可以写上,万一呢)
唯一宗旨:用节目里人的说话内容来搜,而不要用局外人的角度。因为毕竟检索的文本本体是电台内容的语音识别稿。
最后,系统在这,希望能给您带来一刻愉快~
地址
Credit:
- @YQBelmont:数据收集、转录、检索系统与网页
- @alizoed:移植、规范化与正式部署,服务器提供
PS. 如果需要项目源码和数据库内容可以私信笔者。
下期预告:还有好玩的
既然我们已经拿到了所有节目的向量,那如果把每个节目里的向量求个平均值,是不是这个平均向量就能代表这个节目的特征呢?
于是我们成功地使用自动聚类算法把2300期节目分成了n个类别。而且随着类别的增多,我们会发现各种有意思的小细节。比如"核市节目确实是非常“独树一帜”地特征鲜明,总能做到自己一类",还有“最像常规节目的新闻节目”,“最不Pro的pro节目”(冒犯)之类的。。。




1 / 4
右滑更多分类
而且随着类量的增多,可以明显看出来分类依据有从“内容范式和结构”向“具体垂直领域划分”变化的趋势。比如下图是100类的时候出现的

显然,被蛮荒之地这期节目打动的我,找到了很多也非常值得重温的节目,而这些节目里的大多数都不是“浪潮的把戏”系列里的,还算蛮惊喜~
当我们对某一个节目引起共鸣的时候,也可以通过这种方法来给自己“算法推荐”一波哈哈哈哈哈。具体下期我们再展开聊,我再探索探索还有没有别的好玩的。另外站内文章也正在做嗷。