前言
Tribulation這個詞其實直譯是苦難、磨難,是一個比“挑戰”程度更高的概念。
考慮到AI正在深度改變我們的生活,學習和理解AI對於大部分計算機技術和應用相關的職業來說都是無法迴避的——而要了解的東西又如此多,並且商業化產品高速迭代(泡沫也很重),確實對所有人來說學習和使用AI(乃至被AI擠下崗)都是一場磨難。
不過在接受這一前提後,可能慢慢的才能與之共存、從中獲益。這篇GDC分享對應的肯定不是AI技術的最前沿,但對於還沒有在日常和工作中大量使用AI的人(比如我)來說確實是一個不錯的出發點。
我個人對於AI學習的目標大概會定在工具性和理論性的理解上,正如這篇分享中的內容一樣,以力求解決實際問題為出發點——如果有分析得不對的地方,也歡迎指正。讀這篇分享會以翻譯原文稿的PPT頁內容為主,信息過少的部分會從視頻版總結一些概要;打星號的部分是我個人的補充說明。重要的概念我會從別處摘錄一些合適的說明或文獻。
1 概述

帝國時代4的AI團隊
*前面有兩頁介紹了幾位微軟的AI開發人員,有些也參與了這個項目,這裡省略了。

問題空間
(遊戲包含)8個文明,380以上的單位和建築,130項科技升級。

問題空間
城堡與城牆,攻城器械,每個時代兩個奇蹟,4個時代,3種勝利方式。

海戰,兩種地形,4種關鍵資源。(*這裡有一段視頻演示,PPT裡不包含,感興趣可以去看視頻版)

機器學習
這裡展示了兩種深度神經網絡(後續縮寫DNN)的例子,有著不同的監督訓練方式:
- 使用標籤數據的戰鬥預判
- 使用增強學習的尋路與戰鬥
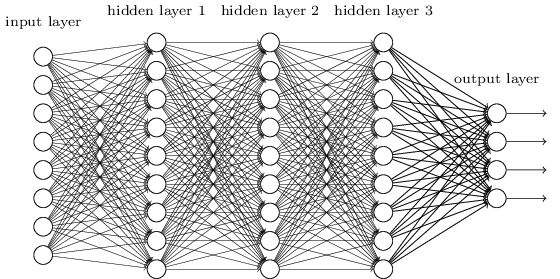
*這裡補一張(早期的)深度神經網絡的示例圖,其中的一個節點可被稱為一個感知機。如圖中所示,DNN內部的神經網絡層可以分為三類——輸入層、隱藏層和輸出層。實際前沿在採用的各種DNN結構遠比這要複雜,節點間可能有卷積、池、連接等各種組織方式。
*監督學習(Supervised Learning)是指使用標註好的樣本數據來訓練模型,從而使模型能夠預測新的未標註樣本的輸出。

DNN的目標
模塊化(目標化)的方案——以少量的機器和較少的計算量來訓練:
- 目標1:確定何種問題是好的DNN/DRL問題。(*問題可以理解為輸入以及模型設計)
- 目標2:確定如何在遊戲開發過程中訓練模型或策略。
- 目標3:在運行時性能表現良好(以推論的方式)。
- 目標4:不產生不類似人類的行為。
2 監督學習——戰鬥系統預判

戰鬥預判——議程
- 問題空間
- 為什麼使用監督學習
- 原型開發
- 觀察與實現
- 結果和經驗
*fitness直譯的一個意思是“合適的程度”,後文我還是都翻譯成“(開戰是否合適的)預判”。

戰鬥預判——定義
- 給定兩組部隊,計算應該戰鬥還是逃跑。
- 啟發式的探索許多決策。
- 通常需要補充(決策)。
*返回值是一個0-1之間的值,例如PPT頁中寫了0.5等於平局。

戰鬥預判——用例
- 單位是否應發起戰鬥:是否應開始戰鬥?合適後退或撤離?需要引入多少增援?
- 單位制造的效用計算。
- 應購買哪項升級。

戰鬥預判——經典路徑
通過顯性公式來模擬傷害模型。
需要數據“反思”。(*這裡應該是指結果數據回饋到DNN的過程)
需要考慮的事項:
- 單位生命值和(部隊)尺寸
- 武器屬性(範圍、AOE等)
- 護甲類型
- 科技升級
- 隨機數

戰鬥預判——挑戰
- 需要經常調用,因而需要能快速執行。
- 難以測試,難以維護。
- 可能需要在運行時“反思”大量數據。
- 數據可能不能明顯反映一個單位的效率。
- 組合的可能性爆炸:8個文明、380多個單位和建築、130項科技升級。
*難以測試和維護——這裡是AI類功能的一個要面對的深層問題。

為什麼使用監督學習
- 我們有一個老師(遊戲本身)。
- 不需要(人工)處理戰鬥中的複雜度。
- DNN模型是離線訓練的,並且可以被自動化。
- 運行時的推測功能是高性能的。
- 之前也有人開發過類似的功能。
*PPT頁列出的是Michael Robbins的使用神經網絡做威脅反饋的案例,文末會給出下載地址。

雛形(原型)
- 設置一個測試場景來生成戰鬥數據:隨機單位類型和數量;記錄初始和最終生命值。
- 通過不同的輸入特性來進行實驗。(*這裡應該是指玩家操作的方式,但文中沒有確認)
- 它歸納得如何呢?

初始模型
- 這裡摘錄了英國步兵單位的參數。
- 數據集需要幾個小時來生成。
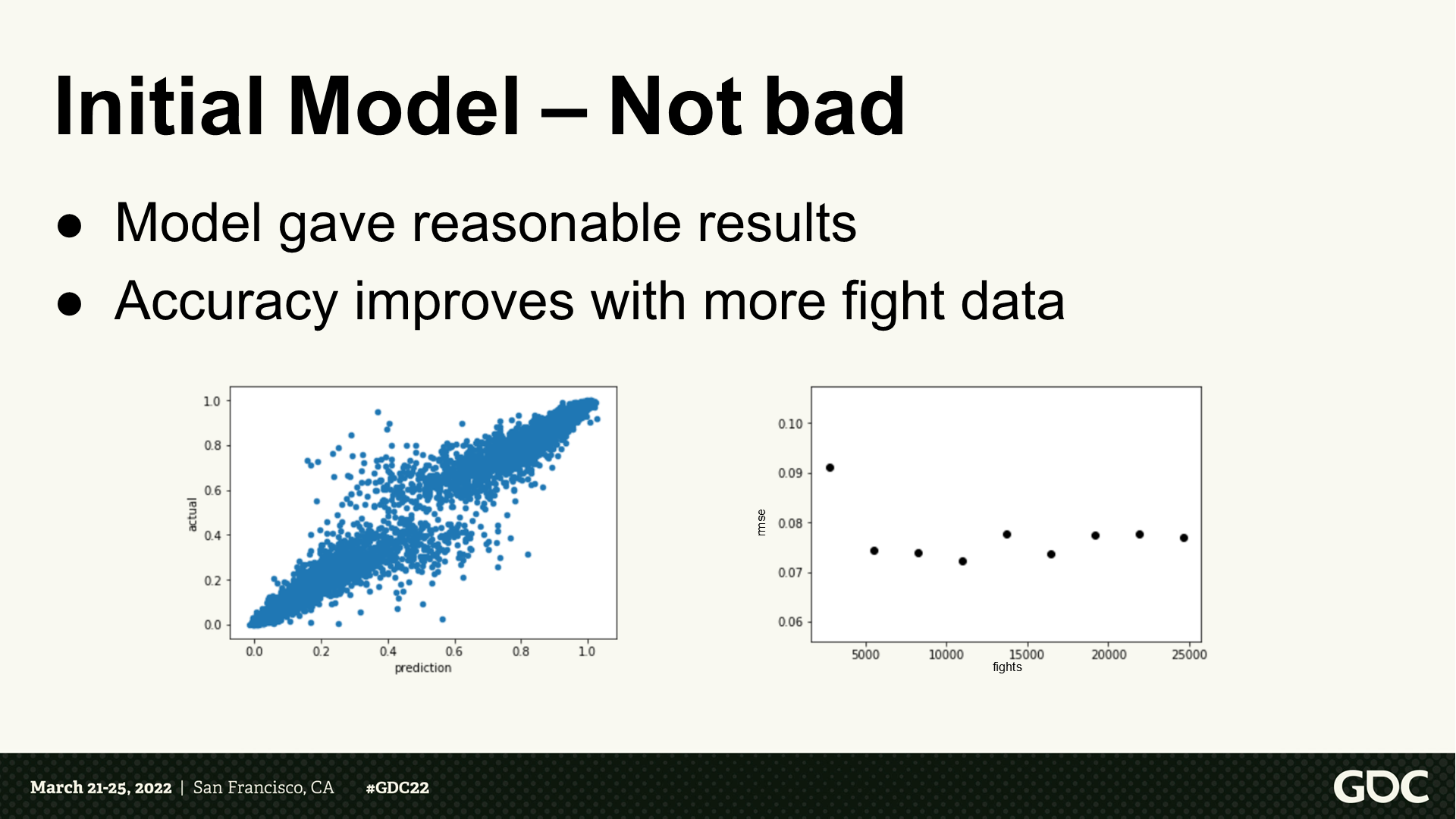
初始模型——還不錯
- 模型能生成合理的結果。
- 隨著戰鬥次數變多精度逐步提升。

初始模型——侷限
- 考慮更多的單位類型需要更大量的工作。
- 輸入特性的選擇也比較棘手。

原始單位的組合
(使用單位的組合作為輸入)很簡單,也能描述所有戰鬥類型。
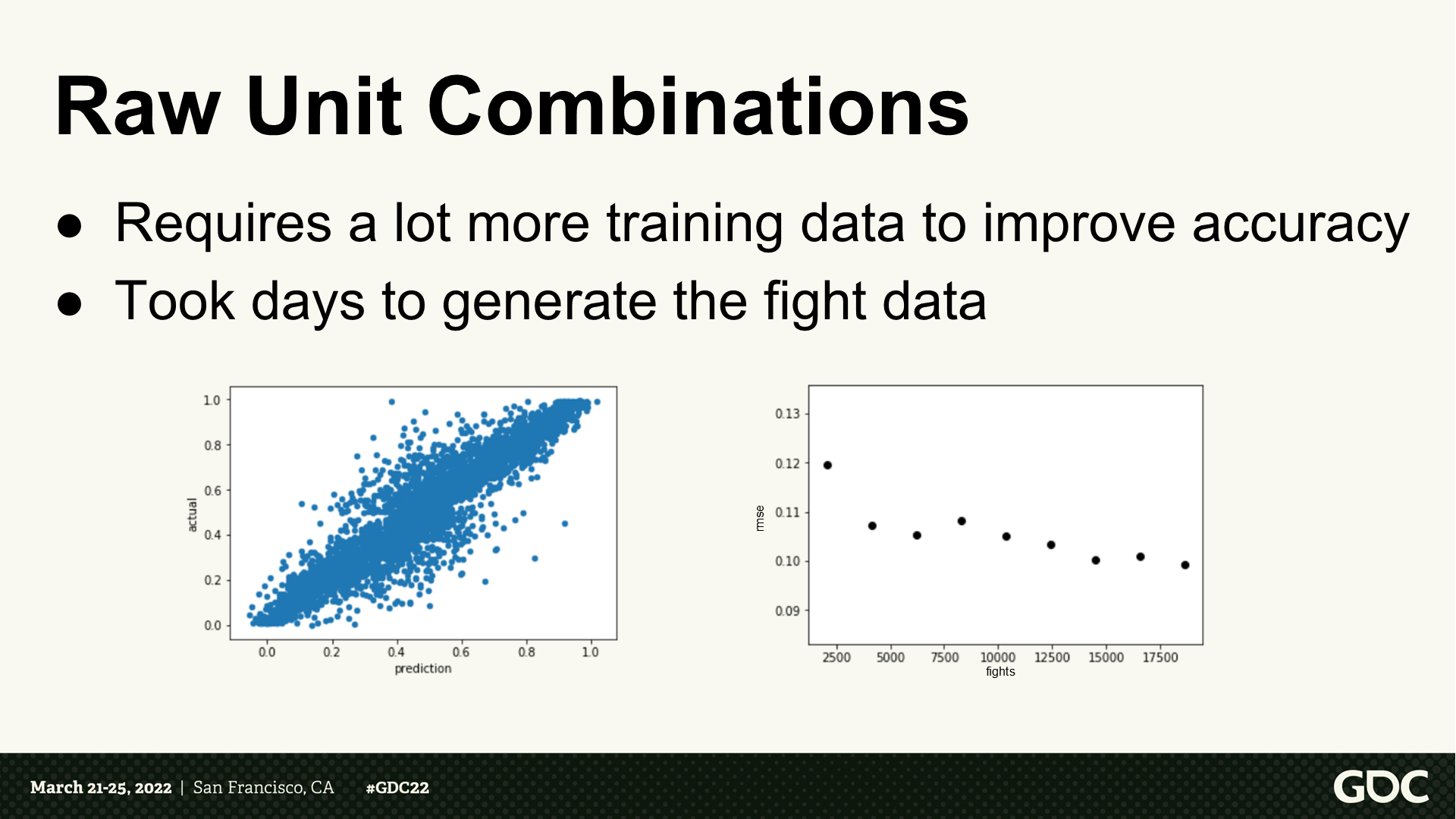
原始單位的組合
- 需要更多訓練數據來提升準確度。
- 需要幾天來生成戰鬥數據。

這意味著?
- 需要結合所有文明和戰鬥類型進行訓練。
- (潛在的)是一個大得不可行的問題空間,幾乎不能生成訓練數據。

減少特徵
*減少維度後,能有更快的訓練時間,在運行時也能更快地執行預測查詢。

使用原型(典型)——理念
*archetype的其中一個翻譯也是“原型”,但和prototype的意思不同。這裡理解成歸納起來的超類更合適,而prototype則是指事物比較初始的樣子。
- 將有著同類戰鬥機制的單位分組。
- 使用組內最弱的單位作為基準,並記1分。
- 確認其它單位和基準的相關強度比例。

使用原型——例子
- 10個帝國時代長矛手
- 27個黑暗時代長矛手
- 帝國時代長矛手評分=2.7
*右側依次是:黑暗時代、封建時代、城堡時代、帝國時代。

使用成員分數
*可以看到這裡整合了同類型的單位,將其轉為一個總的分數。當然這樣可能失去了實際過程中單位攻擊範圍之類的參數考慮,但大幅提升了可用性。

戰鬥預判——模型
- (戰鬥建模)包括步兵、攻城單位、海軍的原型。
- 也包括戰鬥建築和治療者。(*按PPT頁來看,380種單位提煉到了41種原型)

科技升級的層
- 科技升級如何影響戰鬥?
- 為每項升級增加新的輸入項(0或1)
- 更新戰鬥數據生成的腳本,隨機加入升級項。

科技升級——遇到的問題
- 部分科技升級對單位的提升太微小了,以至於隨機性的波動範圍覆蓋了科技的效用。
- 由於層是全連接的,模型可能會將(結果的)提升歸納於科技和無關單位的聯繫。

科技升級——解決方案
- 基於前置的知識來提供我們自定義的層。
- 從遊戲數據中我們能知道一項科技升級能影響哪些單位。
- 訓練一個單獨的模型來學習升級對於這些單位的效能影響,忽略那些不想關的。
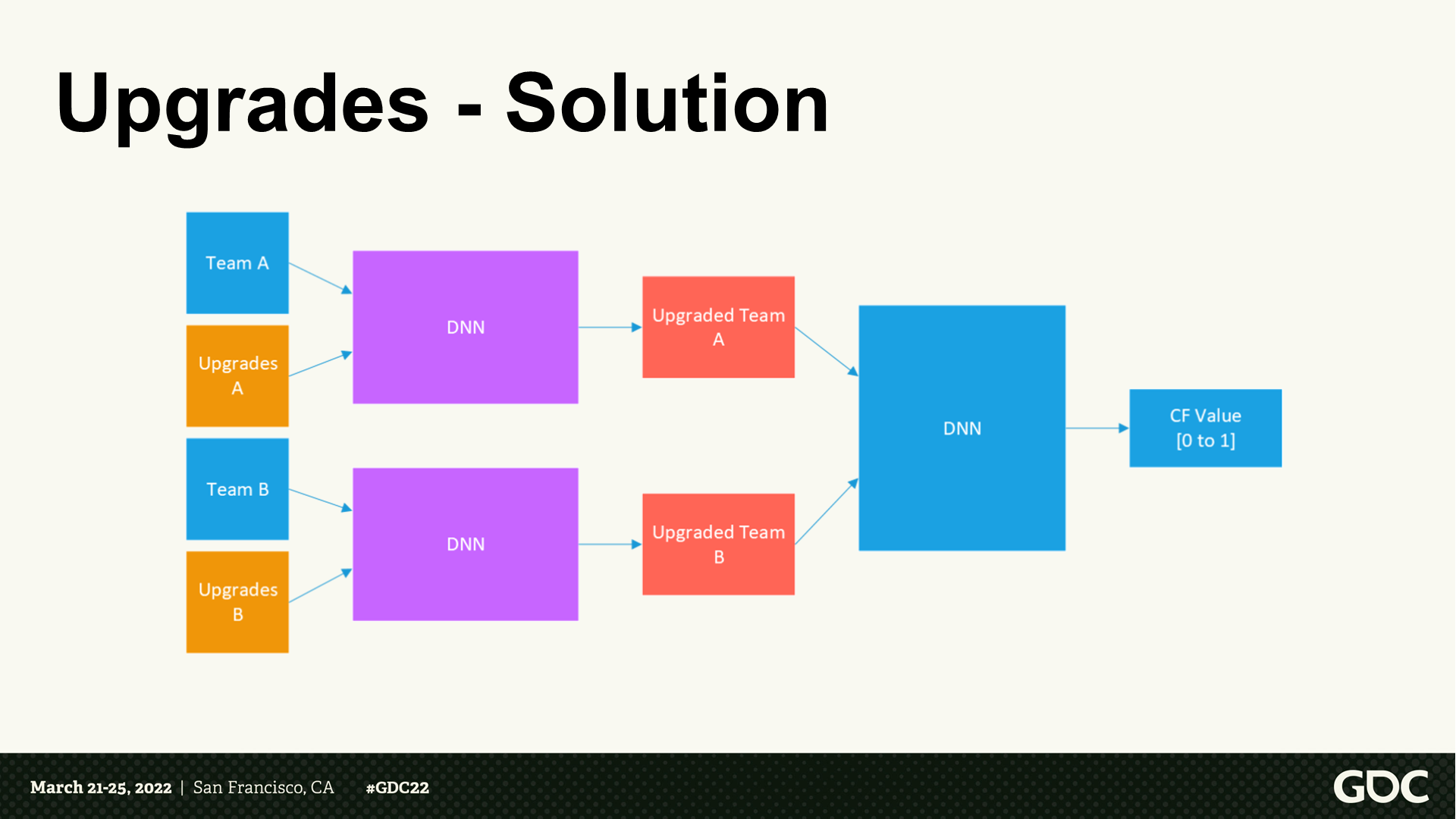
科技升級——解決方案
*調整後的DNN結構變為了圖中所示,科技升級這個事項有了單獨的DNN。
計算出勝者之後呢
現在我們有了戰鬥健壯性的解決方案,如何將它引入產品(遊戲)中呢?

自動化的目標
- 持續的開發和設計變更以及平衡性調整會需要(定期)更新模型。
- 更新包含兩部分:原型訓練自動化、戰鬥數據生成。
- 然而,模型訓練仍然是手動的。

原型自動化設置
- 並行執行原型訓練。
- 拆分大的原型到不同小組。
- 需要幾個小時來完成。

戰鬥自動化設置
- 單位數量從1對1到40對40。
- 可以是單一單位或不同組合。
- (單位包括)陸地、海軍、建築。
- 以及是否進行了科技升級。
- 20萬場戰鬥計算需要8小時。

排查錯誤時遇到的問題
- (AI運算是)單一黑盒。
- 不容易確定當模型不準確時具體發生了什麼。
- 模型訓練仍然是手動的:抽查場景,可以對數據補丁並執行實驗;調整數據分佈(獨立單位或原型);(補充)數據盲區。
- 會執行大量在修改處的測試。

實現中的一些經驗筆記
- 使用TensorFlow和Python/Jupyter Notebook。
- 一些超參數的調節。
- 將保存的模型轉為.tflite格式。
- 運行時使用TensorFlow Lite(能提升4倍速度)。
*這裡TensorFlow是最早於2015年由谷歌提出的一套機器學習框架,具體點說是一套基於數據流編程的符號數學系統。在國內通過它訓練數據常被和一個詞聯繫在一起——“端到端”。當然它肯定也不是唯一的機器學習框架。
*Python/Jupyter Notebook是一個智能化腳本編寫工具,斜槓表示不同時期這個軟件名稱變化過一次(並不是兩個分開的概念)。

結果和經驗
- 成功將監督學習用於戰鬥預判的訓練:提升運行時表現、能適應持續的修改。
- 並不是完全自動化:遇到問題需要手動調查修改。
- 需要監測各個方面:數據生成、模型準確性。
- 只是一個啟發式功能:並不是始終準確、需要額外的補充或保護邏輯。
*到這裡的總結符合大家對目前AI化的功能的一個總體感覺,就是——大部分時候可能都還挺好,但是確實沒法保證始終穩定如預期運行,一旦出現數據沒有覆蓋到或者預判錯誤的情況,可能就整段垮掉,甚至會導致更大範圍的程序問題。
3 增強學習——幾個優化例子
*由於GDC提供的PPT文稿沒有附帶視頻,對演示視頻感興趣的可以通過文末提供的鏈接去看看視頻版。這一段海戰部分的講解幾乎都是視頻演示。
*增強學習指AI通過與環境的交互來學習。AI會嘗試不同的行動,並通過觀察結果來判斷行動的好壞,逐步學習相對最優的策略。(後面縮寫成RL)

增強學習探索項目——議程
- 失敗嘗試:優化農場建造
- 試煉:可信的海軍戰鬥
- 整合與工程師們的努力

核心的增強學習循環
核心循環(組成):智能體、策略、行為、環境、觀察、獎勵。
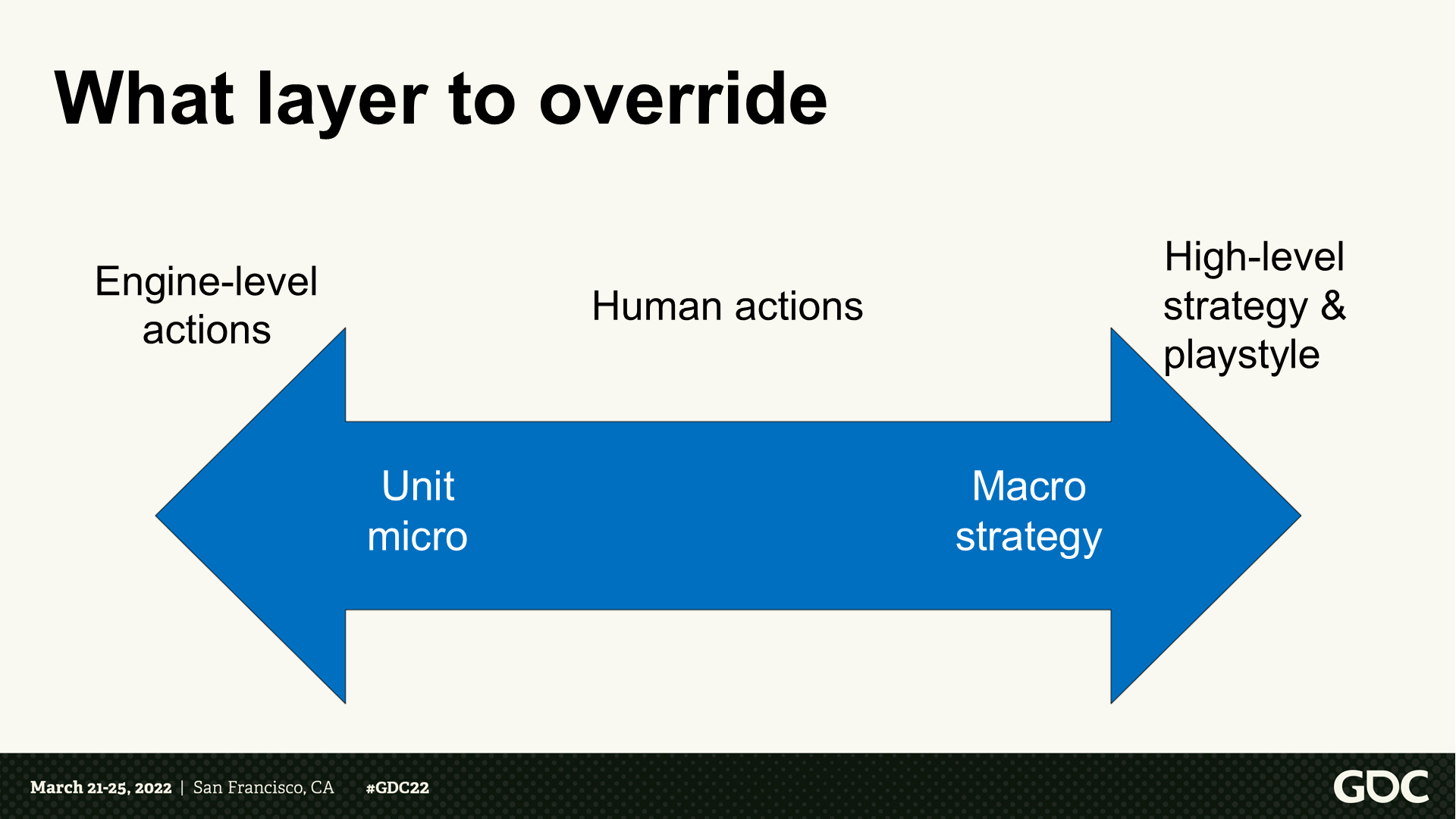
要覆蓋哪些層面的邏輯
- 左側:引擎級別的行動——單位微觀。
- 右側:高層級策略和遊玩風格——宏觀策略。

挑戰:優化農場建造
*農場是遊戲中的資源建築,這部分我會提煉視頻內容進行概述。
*這裡的課題是想找到最優的建造農場的時間間隔,以兼顧資源和運營。
*第一個面臨的問題是:農場產出帶來的“獎勵”效果是大幅滯後的(甚至10到20分鐘後)。
*第二個面臨的問題是:訓練模型的過程揭示了農場系統的設計問題,一個隨機的初級AI模型和一個深度訓練的AI模型在農場上的操作差距很小——這一點他們與設計團隊進行了反饋溝通。
*總的來說,這裡算是選擇了不適合RL的課題,因為這部分已經由遊戲的功能函數處理得比較好了

原型環境
*這裡展示了第二個課題——海軍在海上航行的示意。原視頻展示了一段RL船對戰腳本船的過程。

早期訓練設置
以簡單的設置開始:
- 全連接網絡
- 通過RLlib的近端策略優化
- 在本地機器上訓練
*RLlib是一個強化學習庫,而Proximal Policy Optimization是OpenAI在2017年提出的一種算法,它能改進策略梯度算法,使訓練結果更穩定。基於PPO這個方案會有很多不同的實現,例如大語言模型就應用了這個算法。

尋路用的建模架構
- 輸入:射線檢測
- 對每艘船而言(循環):到其它船的距離、角度,自身的相對旋轉
- 輸出的是評分函數和行為策略:向前行動、左右轉。
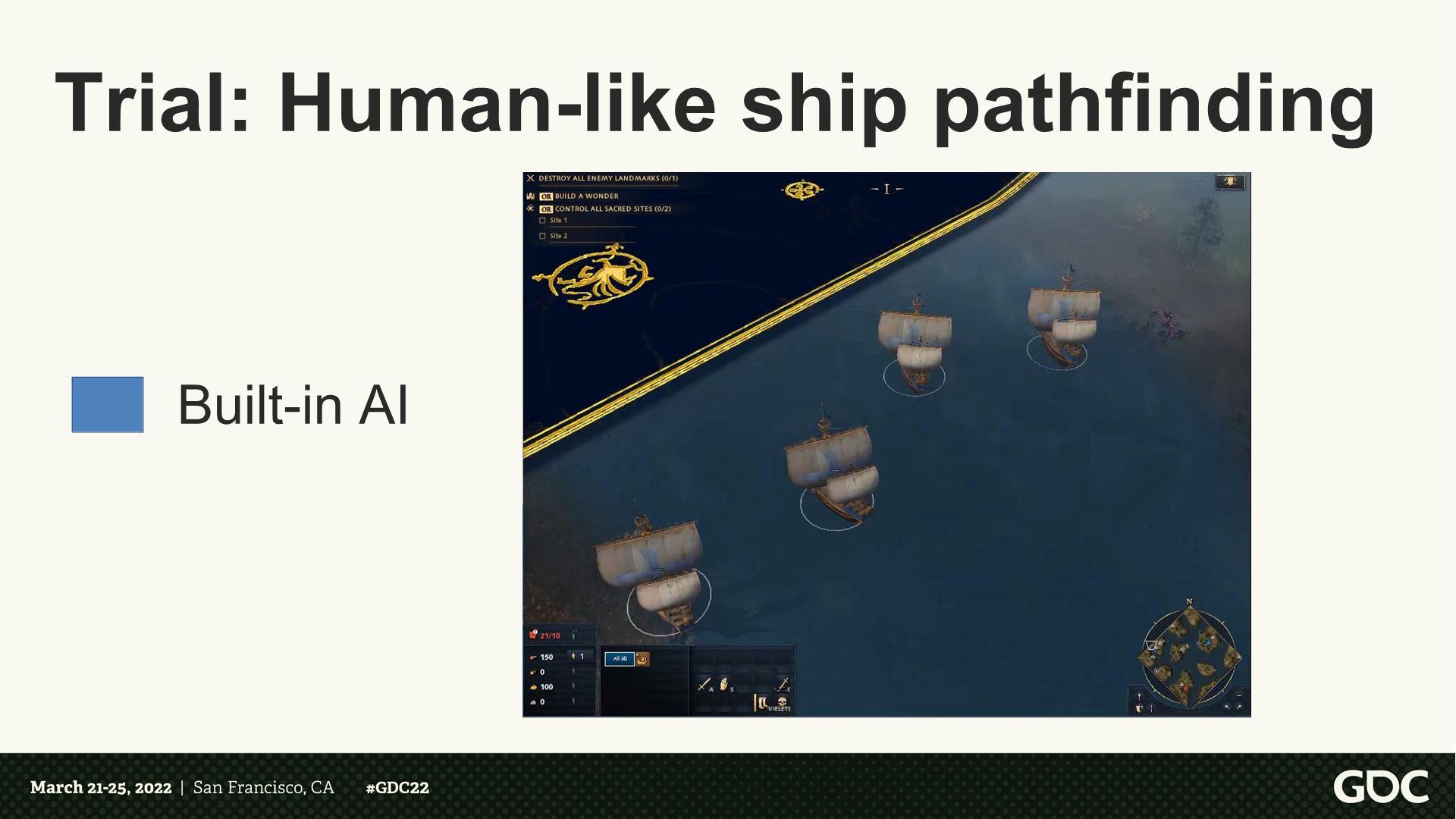
試煉:像人類行為的艦船尋路
*這裡視頻版展示了程序執行AI邏輯的船行動路線,會有撞在一起在調轉,以及擦到水體邊緣的情況。
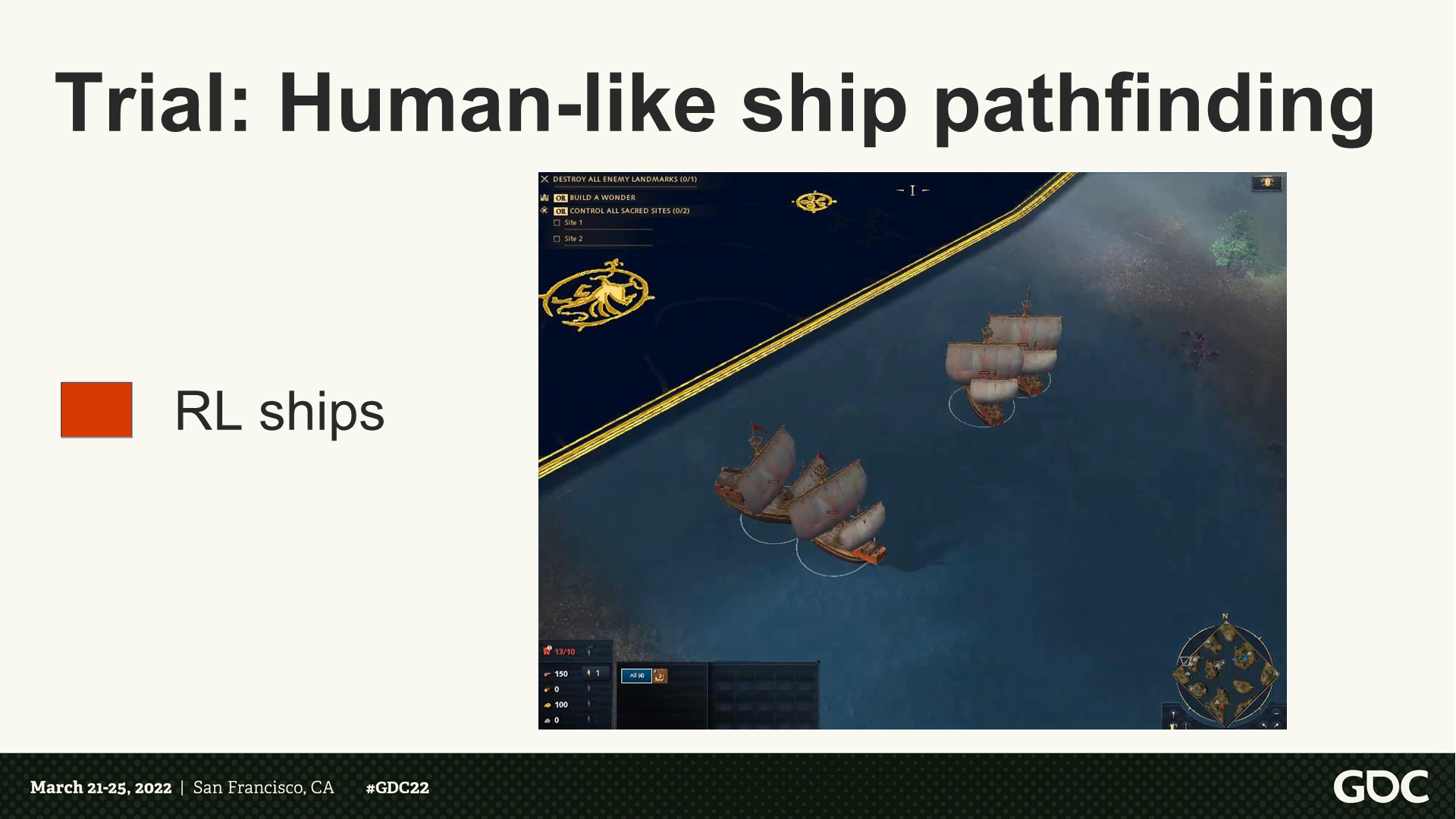
試煉:像人類行為的艦船尋路
*這裡視頻版展示了RL訓練後的路徑,能更好的分組、轉向、避開淺水區。

如何更快更高效的訓練?
將模型建立在(有著高影響的)範圍較窄的應用上。
潛在的瓶頸:
- 神經網絡訓練
- 遊戲採樣收集
*這裡主講人解釋了:由於這裡神經網絡模型比較簡單,所以主要瓶頸還是在數據收集方面。

加速遊戲採樣收集
調整虛擬機的規模來並行執行遊戲實例。
加速遊戲執行的過程:
- 使用無顯示模式(不需要渲染)。
- 加速重啟的任務過程(*通過python腳本)。
*這裡Headless Mode是一種計算機運行模式,指在沒有顯示器、鍵盤或鼠標的情況下運行。這裡分享人在視頻中解釋了是通過python腳本與虛擬機通信來執行一些操作,並開發了快速重置戰鬥環境的腳本。

戰鬥的建模架構
輸入增加了:上次攻擊的間隔、生命值。
輸出增加了:攻擊左側或右側。

多單位訓練並行化
*這部分我配合視頻中的講解概述一下。
*主講人主要介紹了應該選擇那種多單位策略,是共享一個神經網絡agent還是每個單位各有一個。如果是共享一個,在單位數量上升時複雜度就會上升。
*這裡他們選擇的是右側的方案——每個單位一個agent。

*在這個基礎上,他們要確認是每個單位獨立計算權重(各自決策),還是共享權重與數據(集體決策)。這裡他們選擇的是右側的方案——共享權重。

*由於是多單位共享網絡,因此在訓練後就有一個權重固化的過程。

*這裡展示了一段4V4艦船戰鬥,RL的艦船學會了集火一個目標,而程序AI艦船沒有編寫這一策略。
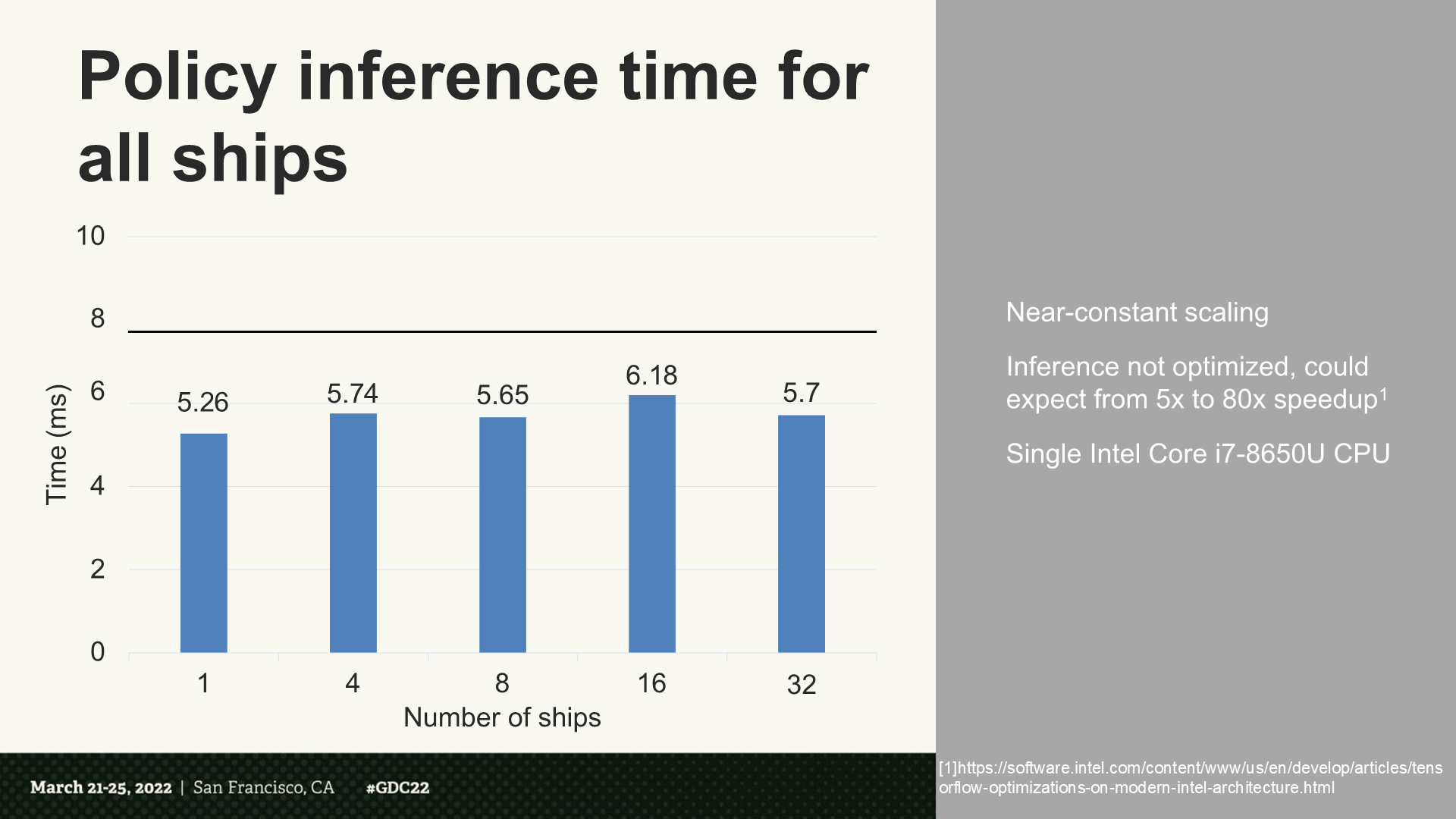
所有艦船的策略推理時間
*可以看到耗時幾乎是固定規模(32比1沒有明顯增加)。同時分享人還指出,如果經過優化後能增加額外5倍到80倍速度。
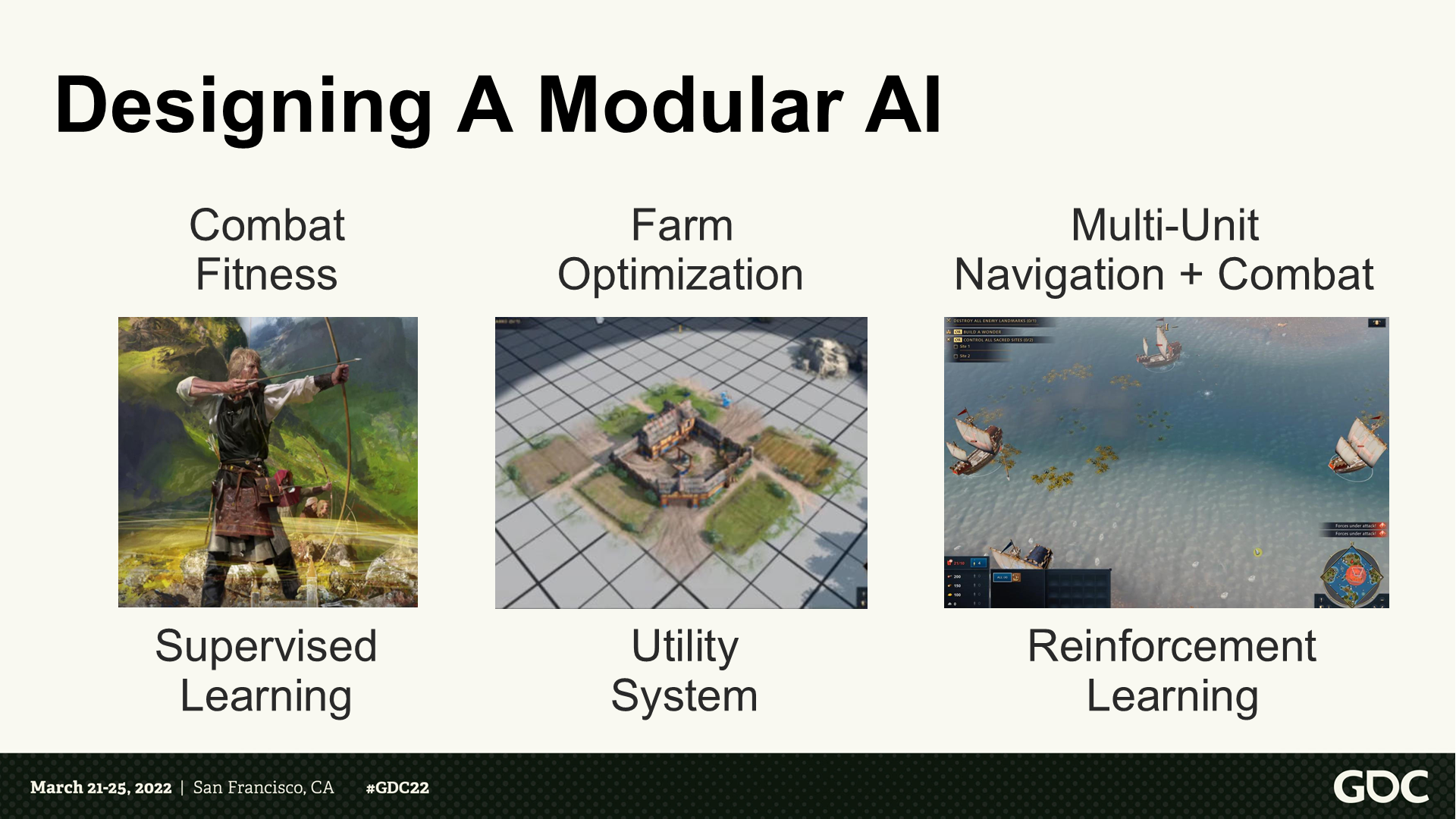
設計一個模塊化的AI
*這部分主講人對設計AI模型的一些心得進行了總結。(主要就是彙總了前面提到的一些點)

什麼是一個好的監督學習問題?
*概括一下,這裡主講人主要提出了標籤化(labeled)這麼一個思路。

什麼是一個好的增強學習問題?
*這裡左側的消磚塊遊戲,分享人認為能很好的符合RL的範式,因此能有很好的訓練效果;而右側的《蒙特祖馬的復仇》這個遊戲中,由於是長流程關卡型遊戲,RL訓練的效果就相對不好。
結語
2024年AI大模型相關的應用已經傳遞到了電動汽車中控系統、3D建模及動畫、視頻生成等各個方面,比起2023年以圖片生成和文字處理為主的熱點來說發展更加迅猛。
在近一年的時間裡,AI在遊戲行業的應用已經逐步降低門檻,以至於能夠絲滑不出戲地應用於遊戲的功能中。常見的比如圖像識別“捏臉”,AI對話的NPC角色等。
近期《暗影火炬城》的開發商公佈了新作《代號:動物朋克》的AI向技術演示【鏈接】,感興趣的可以去看看——其中應用的內容包含語音識別、生成對話、輔助生成貼圖資源等,整個運行過程是實時運算無延遲的。比起電動汽車行業“端到端”那種為了噱頭而AI化的應用來說,至少這個展示裡的NPC對話部分還是比較有建設性的(可能遊戲就是有這點好,比較初級的實現能拿出來圖一樂,不至於出現智能駕駛那種大是大非的問題)。而比較初級的自動對話和3D模型生成,似乎國內大廠的一些網遊產品中已經作為興趣點接入了。
以我個人的預測,(不限於這個遊戲)解析式AI的識別盲區,以及生成式AI的難以連續固化這類問題也會伴隨存在,或許到時候新的BUG類型很多會是AI導致的(難重現、難維護)。而玩家是否真的需要遊戲中這麼重度的使用AI技術,也需要產品來驗證——既可能讓一個世界栩栩如生,也可能讓內容充斥賽博垃圾,這或許就是這個硬幣的正反面了。
推薦收聽了機核會員節目的可以反覆聽聽《原型》系列中人工智能這一期,尤其是後面麥教授和趙老師對談的部分,或許更能加深對AI(以及技術生活現狀)的理解。
考慮到馬上春節了,我個人在一年裡大部分時間保持了周更的文章會暫停兩週左右(鴿了),之後繼續更新的同時應該會增加AI類知識學習的比例。最後祝大家都能從遊戲中獲得快樂!
最後是資料鏈接:
AI Summit: 'Age of Empires IV': Machine Learning Trials and Tribulations 視頻版
AI Summit: 'Age of Empires IV': Machine Learning Trials and Tribulations 文稿版
Using Neural Networks to Control Agent Threat Response論文下載地址
知乎上DNN階段發展歷史的一篇不錯的介紹
TensorFlow的官網