前言
Tribulation这个词其实直译是苦难、磨难,是一个比“挑战”程度更高的概念。
考虑到AI正在深度改变我们的生活,学习和理解AI对于大部分计算机技术和应用相关的职业来说都是无法回避的——而要了解的东西又如此多,并且商业化产品高速迭代(泡沫也很重),确实对所有人来说学习和使用AI(乃至被AI挤下岗)都是一场磨难。
不过在接受这一前提后,可能慢慢的才能与之共存、从中获益。这篇GDC分享对应的肯定不是AI技术的最前沿,但对于还没有在日常和工作中大量使用AI的人(比如我)来说确实是一个不错的出发点。
我个人对于AI学习的目标大概会定在工具性和理论性的理解上,正如这篇分享中的内容一样,以力求解决实际问题为出发点——如果有分析得不对的地方,也欢迎指正。读这篇分享会以翻译原文稿的PPT页内容为主,信息过少的部分会从视频版总结一些概要;打星号的部分是我个人的补充说明。重要的概念我会从别处摘录一些合适的说明或文献。
1 概述

帝国时代4的AI团队
*前面有两页介绍了几位微软的AI开发人员,有些也参与了这个项目,这里省略了。

问题空间
(游戏包含)8个文明,380以上的单位和建筑,130项科技升级。

问题空间
城堡与城墙,攻城器械,每个时代两个奇迹,4个时代,3种胜利方式。

海战,两种地形,4种关键资源。(*这里有一段视频演示,PPT里不包含,感兴趣可以去看视频版)

机器学习
这里展示了两种深度神经网络(后续缩写DNN)的例子,有着不同的监督训练方式:
- 使用标签数据的战斗预判
- 使用增强学习的寻路与战斗
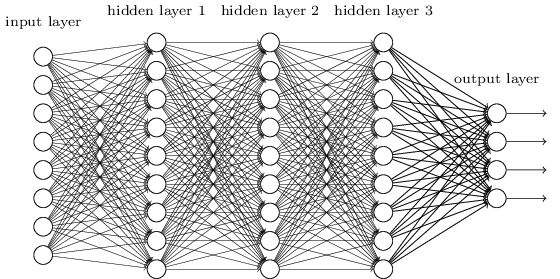
*这里补一张(早期的)深度神经网络的示例图,其中的一个节点可被称为一个感知机。如图中所示,DNN内部的神经网络层可以分为三类——输入层、隐藏层和输出层。实际前沿在采用的各种DNN结构远比这要复杂,节点间可能有卷积、池、连接等各种组织方式。
*监督学习(Supervised Learning)是指使用标注好的样本数据来训练模型,从而使模型能够预测新的未标注样本的输出。

DNN的目标
模块化(目标化)的方案——以少量的机器和较少的计算量来训练:
- 目标1:确定何种问题是好的DNN/DRL问题。(*问题可以理解为输入以及模型设计)
- 目标2:确定如何在游戏开发过程中训练模型或策略。
- 目标3:在运行时性能表现良好(以推论的方式)。
- 目标4:不产生不类似人类的行为。
2 监督学习——战斗系统预判

战斗预判——议程
- 问题空间
- 为什么使用监督学习
- 原型开发
- 观察与实现
- 结果和经验
*fitness直译的一个意思是“合适的程度”,后文我还是都翻译成“(开战是否合适的)预判”。

战斗预判——定义
- 给定两组部队,计算应该战斗还是逃跑。
- 启发式的探索许多决策。
- 通常需要补充(决策)。
*返回值是一个0-1之间的值,例如PPT页中写了0.5等于平局。

战斗预判——用例
- 单位是否应发起战斗:是否应开始战斗?合适后退或撤离?需要引入多少增援?
- 单位制造的效用计算。
- 应购买哪项升级。

战斗预判——经典路径
通过显性公式来模拟伤害模型。
需要数据“反思”。(*这里应该是指结果数据回馈到DNN的过程)
需要考虑的事项:
- 单位生命值和(部队)尺寸
- 武器属性(范围、AOE等)
- 护甲类型
- 科技升级
- 随机数

战斗预判——挑战
- 需要经常调用,因而需要能快速执行。
- 难以测试,难以维护。
- 可能需要在运行时“反思”大量数据。
- 数据可能不能明显反映一个单位的效率。
- 组合的可能性爆炸:8个文明、380多个单位和建筑、130项科技升级。
*难以测试和维护——这里是AI类功能的一个要面对的深层问题。

为什么使用监督学习
- 我们有一个老师(游戏本身)。
- 不需要(人工)处理战斗中的复杂度。
- DNN模型是离线训练的,并且可以被自动化。
- 运行时的推测功能是高性能的。
- 之前也有人开发过类似的功能。
*PPT页列出的是Michael Robbins的使用神经网络做威胁反馈的案例,文末会给出下载地址。

雏形(原型)
- 设置一个测试场景来生成战斗数据:随机单位类型和数量;记录初始和最终生命值。
- 通过不同的输入特性来进行实验。(*这里应该是指玩家操作的方式,但文中没有确认)
- 它归纳得如何呢?

初始模型
- 这里摘录了英国步兵单位的参数。
- 数据集需要几个小时来生成。
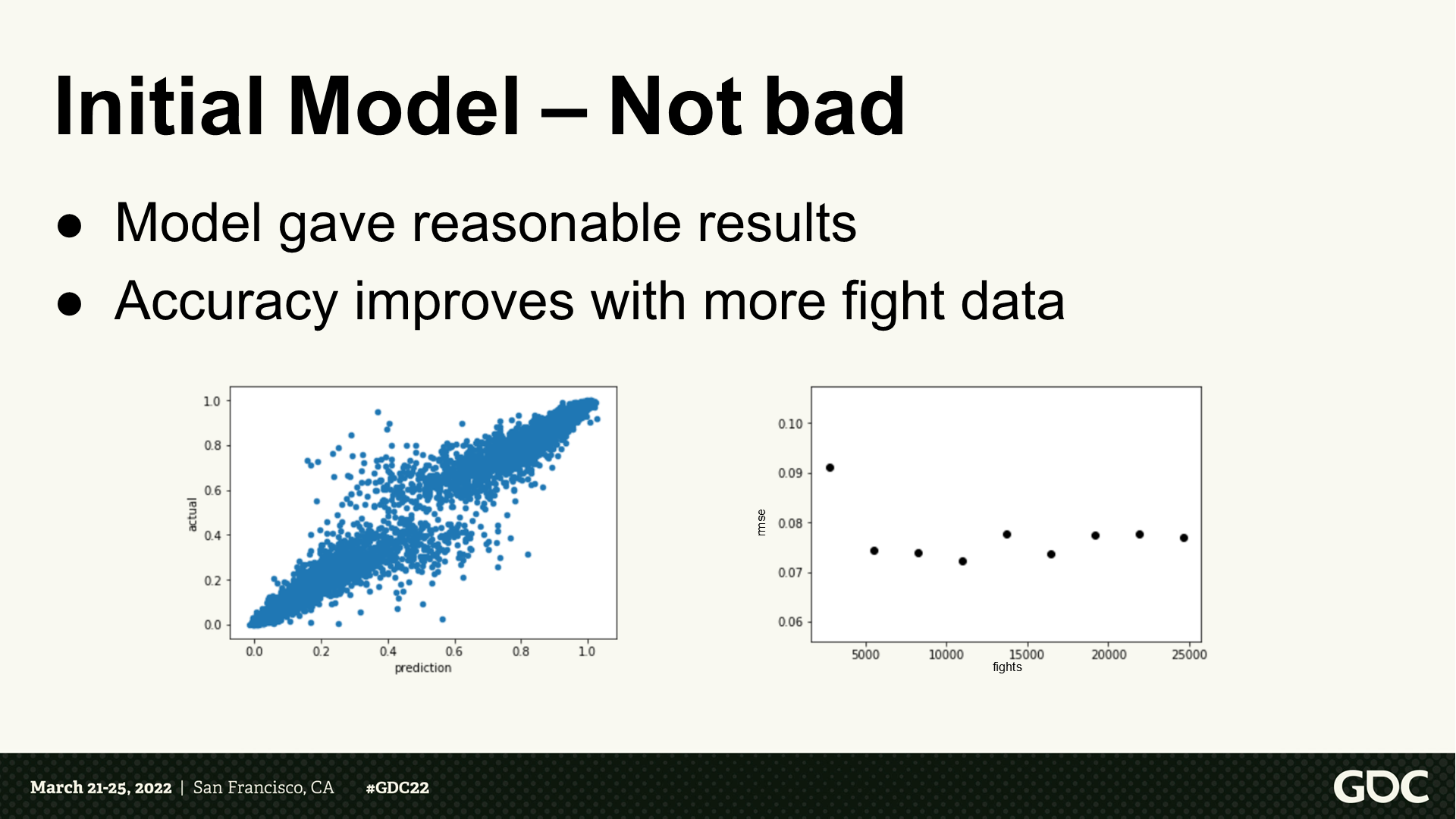
初始模型——还不错
- 模型能生成合理的结果。
- 随着战斗次数变多精度逐步提升。

初始模型——局限
- 考虑更多的单位类型需要更大量的工作。
- 输入特性的选择也比较棘手。

原始单位的组合
(使用单位的组合作为输入)很简单,也能描述所有战斗类型。
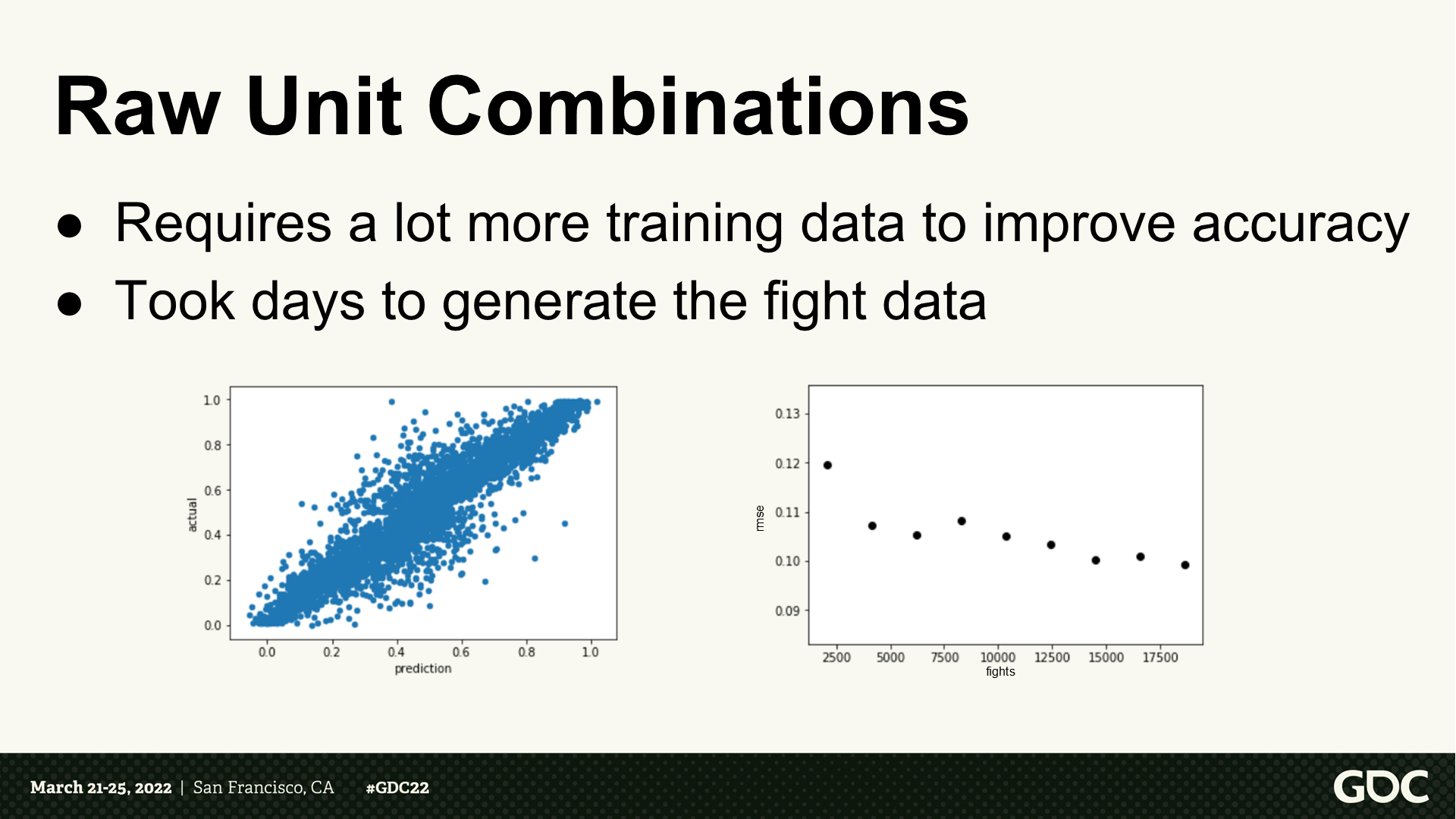
原始单位的组合
- 需要更多训练数据来提升准确度。
- 需要几天来生成战斗数据。

这意味着?
- 需要结合所有文明和战斗类型进行训练。
- (潜在的)是一个大得不可行的问题空间,几乎不能生成训练数据。

减少特征
*减少维度后,能有更快的训练时间,在运行时也能更快地执行预测查询。

使用原型(典型)——理念
*archetype的其中一个翻译也是“原型”,但和prototype的意思不同。这里理解成归纳起来的超类更合适,而prototype则是指事物比较初始的样子。
- 将有着同类战斗机制的单位分组。
- 使用组内最弱的单位作为基准,并记1分。
- 确认其它单位和基准的相关强度比例。

使用原型——例子
- 10个帝国时代长矛手
- 27个黑暗时代长矛手
- 帝国时代长矛手评分=2.7
*右侧依次是:黑暗时代、封建时代、城堡时代、帝国时代。

使用成员分数
*可以看到这里整合了同类型的单位,将其转为一个总的分数。当然这样可能失去了实际过程中单位攻击范围之类的参数考虑,但大幅提升了可用性。

战斗预判——模型
- (战斗建模)包括步兵、攻城单位、海军的原型。
- 也包括战斗建筑和治疗者。(*按PPT页来看,380种单位提炼到了41种原型)

科技升级的层
- 科技升级如何影响战斗?
- 为每项升级增加新的输入项(0或1)
- 更新战斗数据生成的脚本,随机加入升级项。

科技升级——遇到的问题
- 部分科技升级对单位的提升太微小了,以至于随机性的波动范围覆盖了科技的效用。
- 由于层是全连接的,模型可能会将(结果的)提升归纳于科技和无关单位的联系。

科技升级——解决方案
- 基于前置的知识来提供我们自定义的层。
- 从游戏数据中我们能知道一项科技升级能影响哪些单位。
- 训练一个单独的模型来学习升级对于这些单位的效能影响,忽略那些不想关的。
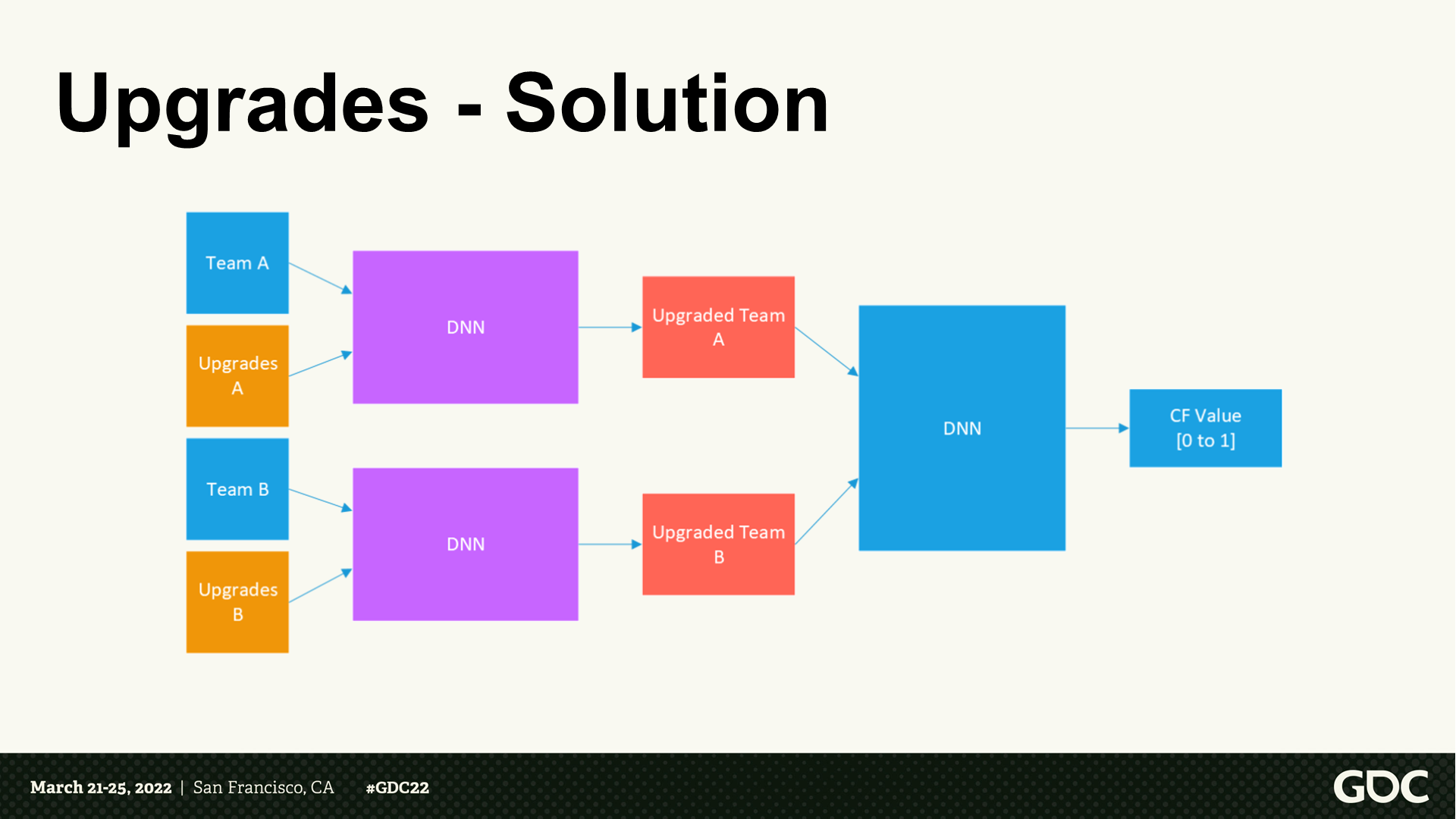
科技升级——解决方案
*调整后的DNN结构变为了图中所示,科技升级这个事项有了单独的DNN。
计算出胜者之后呢
现在我们有了战斗健壮性的解决方案,如何将它引入产品(游戏)中呢?

自动化的目标
- 持续的开发和设计变更以及平衡性调整会需要(定期)更新模型。
- 更新包含两部分:原型训练自动化、战斗数据生成。
- 然而,模型训练仍然是手动的。

原型自动化设置
- 并行执行原型训练。
- 拆分大的原型到不同小组。
- 需要几个小时来完成。

战斗自动化设置
- 单位数量从1对1到40对40。
- 可以是单一单位或不同组合。
- (单位包括)陆地、海军、建筑。
- 以及是否进行了科技升级。
- 20万场战斗计算需要8小时。

排查错误时遇到的问题
- (AI运算是)单一黑盒。
- 不容易确定当模型不准确时具体发生了什么。
- 模型训练仍然是手动的:抽查场景,可以对数据补丁并执行实验;调整数据分布(独立单位或原型);(补充)数据盲区。
- 会执行大量在修改处的测试。

实现中的一些经验笔记
- 使用TensorFlow和Python/Jupyter Notebook。
- 一些超参数的调节。
- 将保存的模型转为.tflite格式。
- 运行时使用TensorFlow Lite(能提升4倍速度)。
*这里TensorFlow是最早于2015年由谷歌提出的一套机器学习框架,具体点说是一套基于数据流编程的符号数学系统。在国内通过它训练数据常被和一个词联系在一起——“端到端”。当然它肯定也不是唯一的机器学习框架。
*Python/Jupyter Notebook是一个智能化脚本编写工具,斜杠表示不同时期这个软件名称变化过一次(并不是两个分开的概念)。

结果和经验
- 成功将监督学习用于战斗预判的训练:提升运行时表现、能适应持续的修改。
- 并不是完全自动化:遇到问题需要手动调查修改。
- 需要监测各个方面:数据生成、模型准确性。
- 只是一个启发式功能:并不是始终准确、需要额外的补充或保护逻辑。
*到这里的总结符合大家对目前AI化的功能的一个总体感觉,就是——大部分时候可能都还挺好,但是确实没法保证始终稳定如预期运行,一旦出现数据没有覆盖到或者预判错误的情况,可能就整段垮掉,甚至会导致更大范围的程序问题。
3 增强学习——几个优化例子
*由于GDC提供的PPT文稿没有附带视频,对演示视频感兴趣的可以通过文末提供的链接去看看视频版。这一段海战部分的讲解几乎都是视频演示。
*增强学习指AI通过与环境的交互来学习。AI会尝试不同的行动,并通过观察结果来判断行动的好坏,逐步学习相对最优的策略。(后面缩写成RL)

增强学习探索项目——议程
- 失败尝试:优化农场建造
- 试炼:可信的海军战斗
- 整合与工程师们的努力

核心的增强学习循环
核心循环(组成):智能体、策略、行为、环境、观察、奖励。
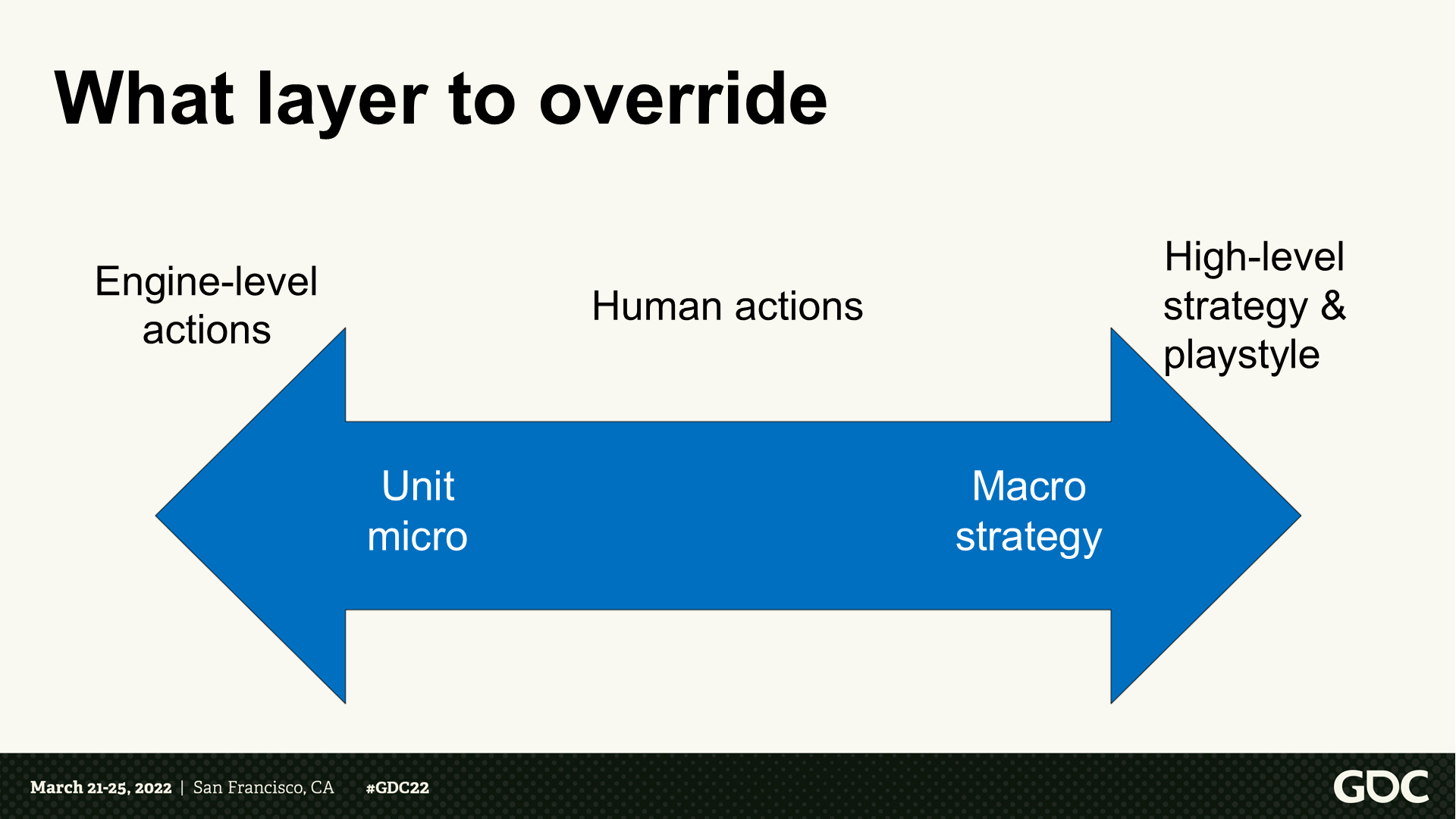
要覆盖哪些层面的逻辑
- 左侧:引擎级别的行动——单位微观。
- 右侧:高层级策略和游玩风格——宏观策略。

挑战:优化农场建造
*农场是游戏中的资源建筑,这部分我会提炼视频内容进行概述。
*这里的课题是想找到最优的建造农场的时间间隔,以兼顾资源和运营。
*第一个面临的问题是:农场产出带来的“奖励”效果是大幅滞后的(甚至10到20分钟后)。
*第二个面临的问题是:训练模型的过程揭示了农场系统的设计问题,一个随机的初级AI模型和一个深度训练的AI模型在农场上的操作差距很小——这一点他们与设计团队进行了反馈沟通。
*总的来说,这里算是选择了不适合RL的课题,因为这部分已经由游戏的功能函数处理得比较好了

原型环境
*这里展示了第二个课题——海军在海上航行的示意。原视频展示了一段RL船对战脚本船的过程。

早期训练设置
以简单的设置开始:
- 全连接网络
- 通过RLlib的近端策略优化
- 在本地机器上训练
*RLlib是一个强化学习库,而Proximal Policy Optimization是OpenAI在2017年提出的一种算法,它能改进策略梯度算法,使训练结果更稳定。基于PPO这个方案会有很多不同的实现,例如大语言模型就应用了这个算法。

寻路用的建模架构
- 输入:射线检测
- 对每艘船而言(循环):到其它船的距离、角度,自身的相对旋转
- 输出的是评分函数和行为策略:向前行动、左右转。
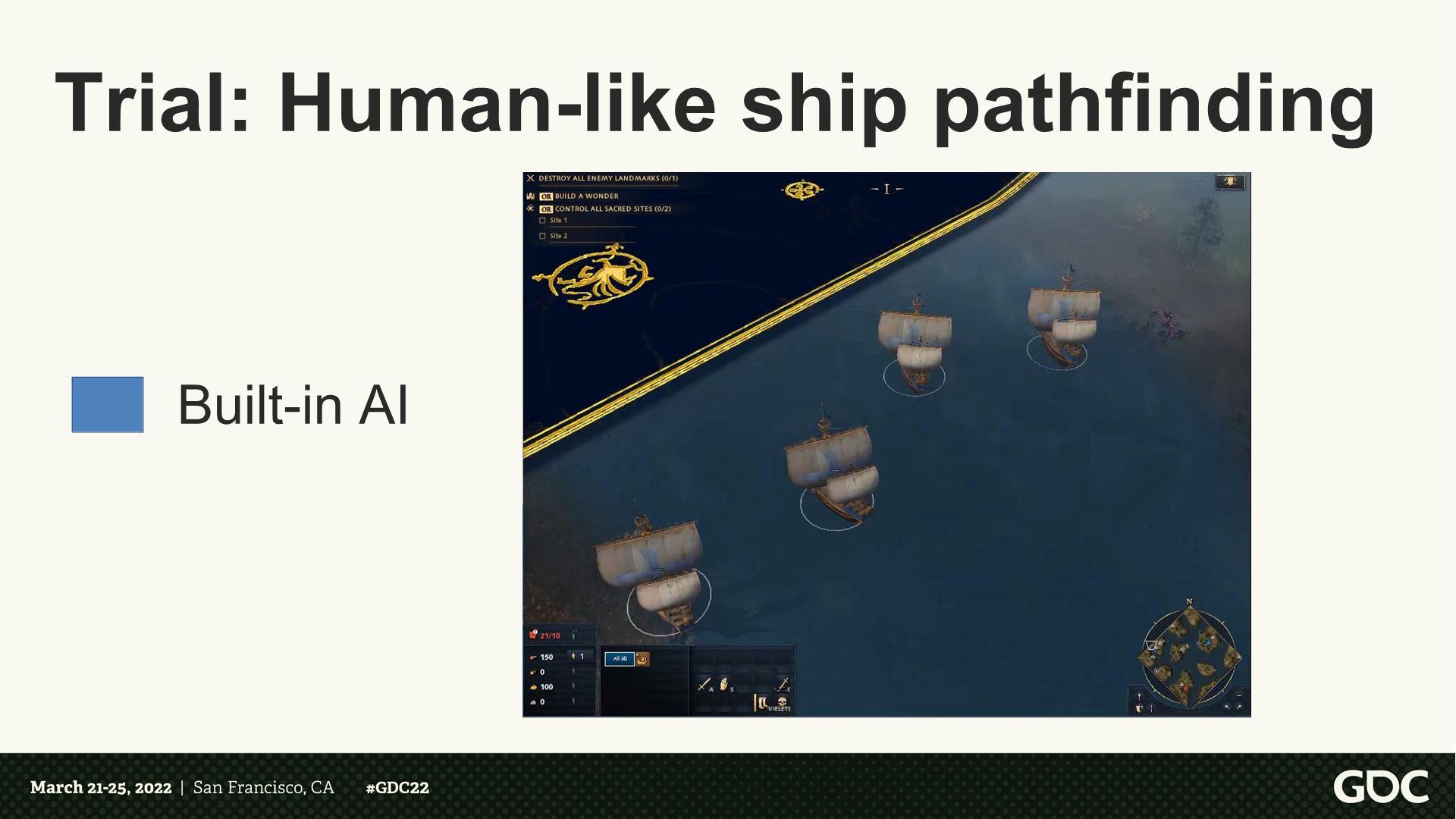
试炼:像人类行为的舰船寻路
*这里视频版展示了程序执行AI逻辑的船行动路线,会有撞在一起在调转,以及擦到水体边缘的情况。
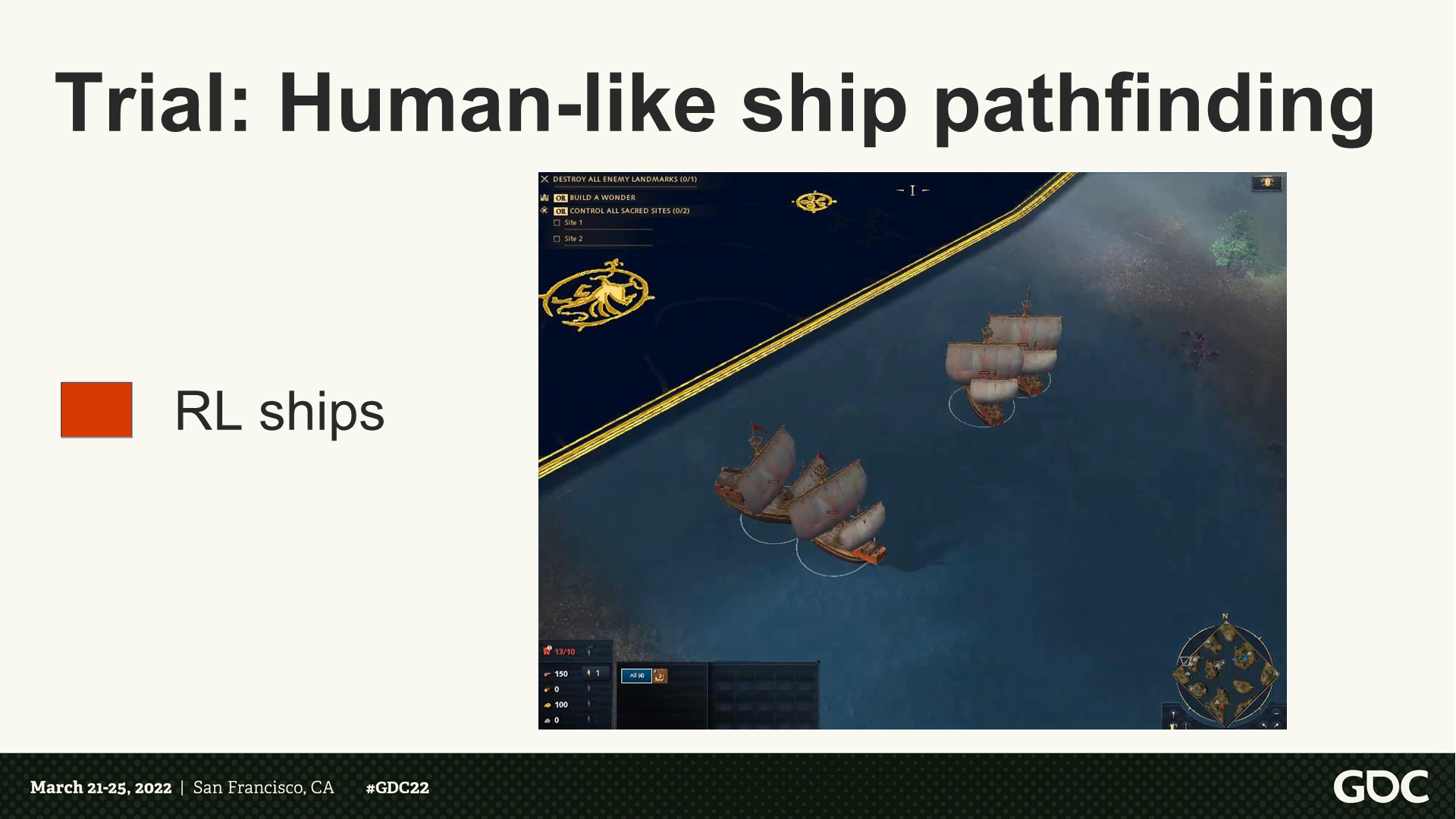
试炼:像人类行为的舰船寻路
*这里视频版展示了RL训练后的路径,能更好的分组、转向、避开浅水区。

如何更快更高效的训练?
将模型建立在(有着高影响的)范围较窄的应用上。
潜在的瓶颈:
- 神经网络训练
- 游戏采样收集
*这里主讲人解释了:由于这里神经网络模型比较简单,所以主要瓶颈还是在数据收集方面。

加速游戏采样收集
调整虚拟机的规模来并行执行游戏实例。
加速游戏执行的过程:
- 使用无显示模式(不需要渲染)。
- 加速重启的任务过程(*通过python脚本)。
*这里Headless Mode是一种计算机运行模式,指在没有显示器、键盘或鼠标的情况下运行。这里分享人在视频中解释了是通过python脚本与虚拟机通信来执行一些操作,并开发了快速重置战斗环境的脚本。

战斗的建模架构
输入增加了:上次攻击的间隔、生命值。
输出增加了:攻击左侧或右侧。

多单位训练并行化
*这部分我配合视频中的讲解概述一下。
*主讲人主要介绍了应该选择那种多单位策略,是共享一个神经网络agent还是每个单位各有一个。如果是共享一个,在单位数量上升时复杂度就会上升。
*这里他们选择的是右侧的方案——每个单位一个agent。

*在这个基础上,他们要确认是每个单位独立计算权重(各自决策),还是共享权重与数据(集体决策)。这里他们选择的是右侧的方案——共享权重。

*由于是多单位共享网络,因此在训练后就有一个权重固化的过程。

*这里展示了一段4V4舰船战斗,RL的舰船学会了集火一个目标,而程序AI舰船没有编写这一策略。
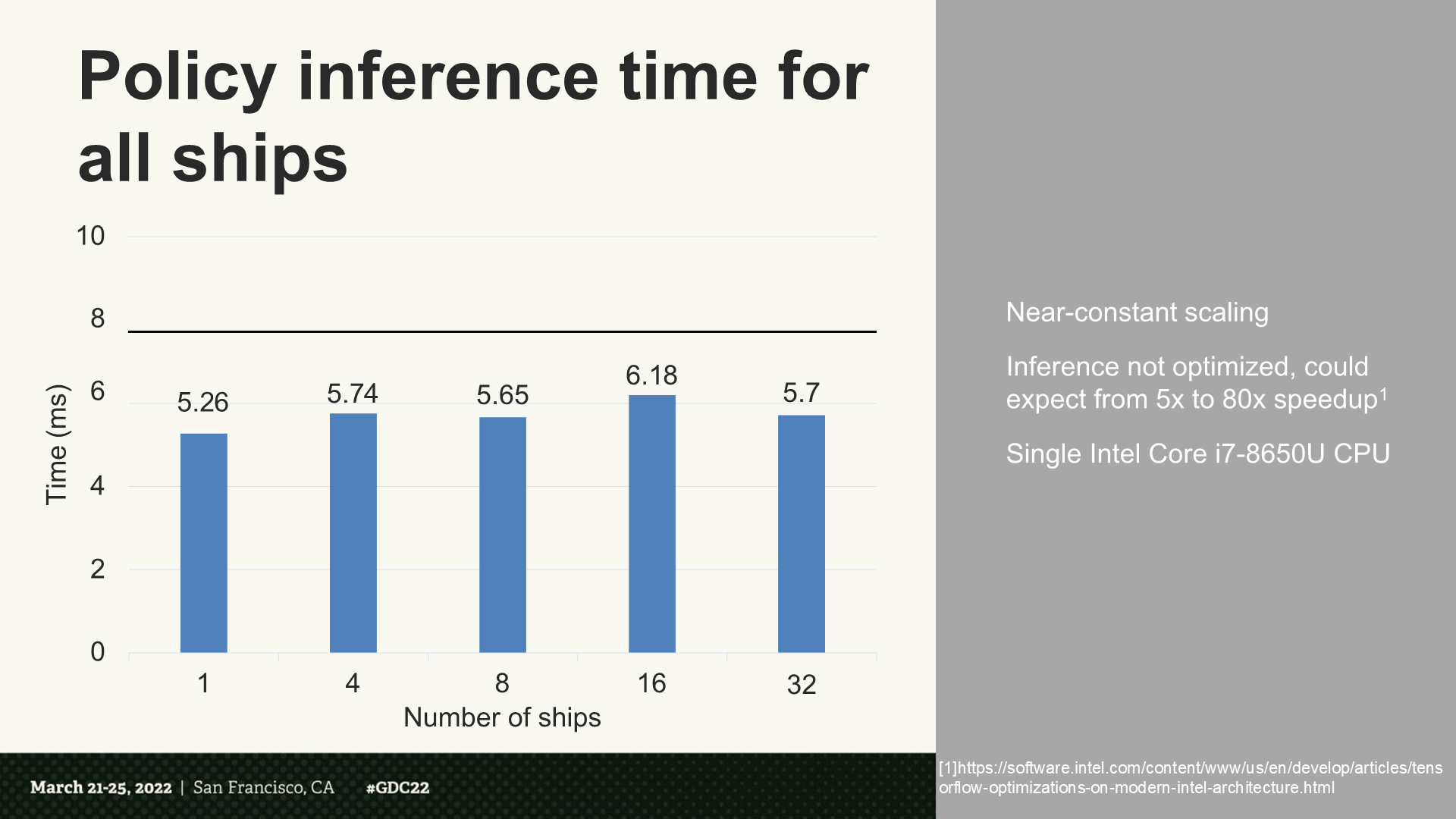
所有舰船的策略推理时间
*可以看到耗时几乎是固定规模(32比1没有明显增加)。同时分享人还指出,如果经过优化后能增加额外5倍到80倍速度。
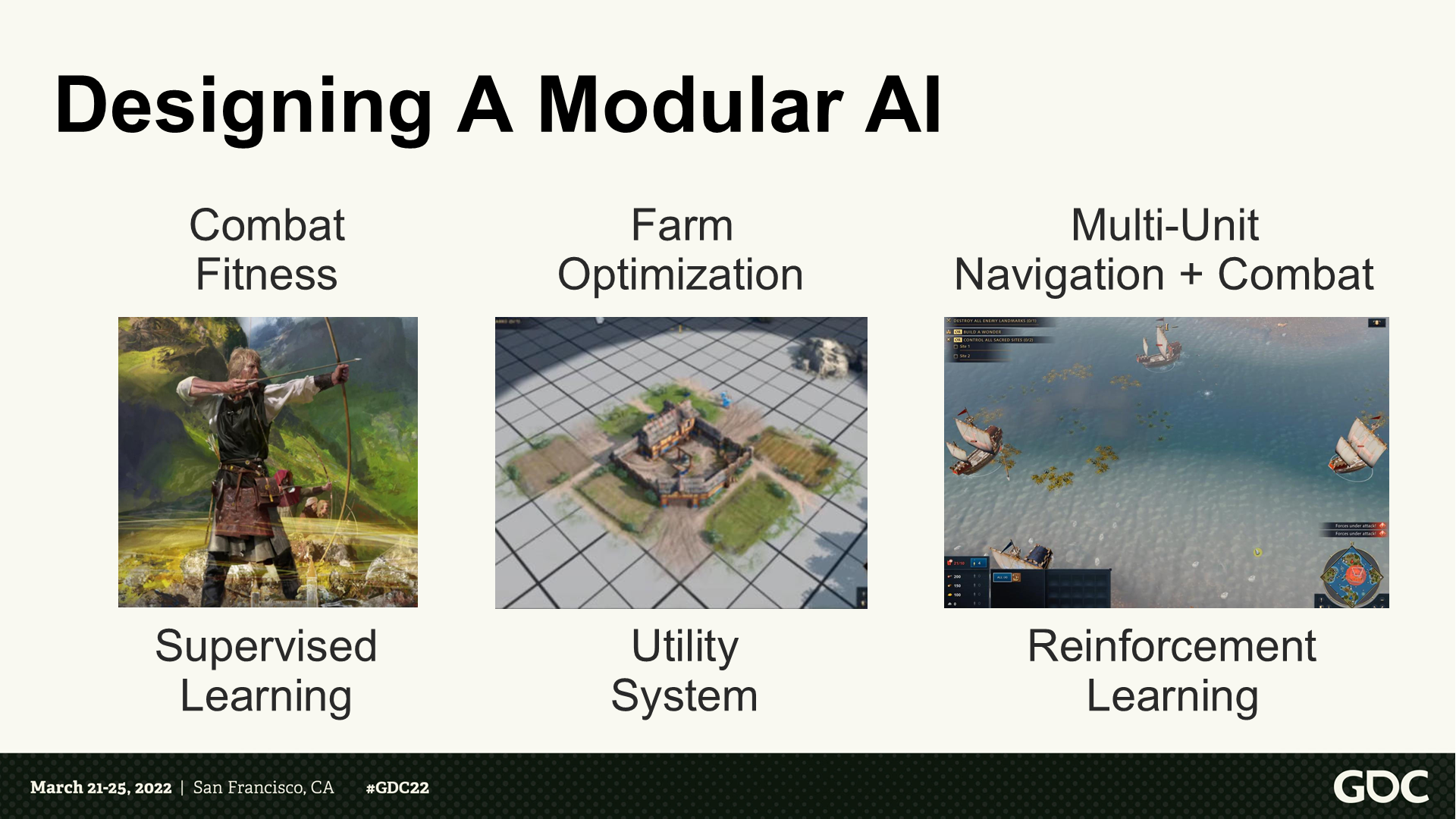
设计一个模块化的AI
*这部分主讲人对设计AI模型的一些心得进行了总结。(主要就是汇总了前面提到的一些点)

什么是一个好的监督学习问题?
*概括一下,这里主讲人主要提出了标签化(labeled)这么一个思路。

什么是一个好的增强学习问题?
*这里左侧的消砖块游戏,分享人认为能很好的符合RL的范式,因此能有很好的训练效果;而右侧的《蒙特祖马的复仇》这个游戏中,由于是长流程关卡型游戏,RL训练的效果就相对不好。
结语
2024年AI大模型相关的应用已经传递到了电动汽车中控系统、3D建模及动画、视频生成等各个方面,比起2023年以图片生成和文字处理为主的热点来说发展更加迅猛。
在近一年的时间里,AI在游戏行业的应用已经逐步降低门槛,以至于能够丝滑不出戏地应用于游戏的功能中。常见的比如图像识别“捏脸”,AI对话的NPC角色等。
近期《暗影火炬城》的开发商公布了新作《代号:动物朋克》的AI向技术演示【链接】,感兴趣的可以去看看——其中应用的内容包含语音识别、生成对话、辅助生成贴图资源等,整个运行过程是实时运算无延迟的。比起电动汽车行业“端到端”那种为了噱头而AI化的应用来说,至少这个展示里的NPC对话部分还是比较有建设性的(可能游戏就是有这点好,比较初级的实现能拿出来图一乐,不至于出现智能驾驶那种大是大非的问题)。而比较初级的自动对话和3D模型生成,似乎国内大厂的一些网游产品中已经作为兴趣点接入了。
以我个人的预测,(不限于这个游戏)解析式AI的识别盲区,以及生成式AI的难以连续固化这类问题也会伴随存在,或许到时候新的BUG类型很多会是AI导致的(难重现、难维护)。而玩家是否真的需要游戏中这么重度的使用AI技术,也需要产品来验证——既可能让一个世界栩栩如生,也可能让内容充斥赛博垃圾,这或许就是这个硬币的正反面了。
推荐收听了机核会员节目的可以反复听听《原型》系列中人工智能这一期,尤其是后面麦教授和赵老师对谈的部分,或许更能加深对AI(以及技术生活现状)的理解。
考虑到马上春节了,我个人在一年里大部分时间保持了周更的文章会暂停两周左右(鸽了),之后继续更新的同时应该会增加AI类知识学习的比例。最后祝大家都能从游戏中获得快乐!
最后是资料链接:
AI Summit: 'Age of Empires IV': Machine Learning Trials and Tribulations 视频版
AI Summit: 'Age of Empires IV': Machine Learning Trials and Tribulations 文稿版
Using Neural Networks to Control Agent Threat Response论文下载地址
知乎上DNN阶段发展历史的一篇不错的介绍
TensorFlow的官网