本质是用显卡跑本地模型进行日→中的翻译。
gpt火了之后,gal界迎来了一波gpt机翻的浪潮。可惜正版gpt要国外银行卡导致国内gpt用户并不多,gal的gpt机翻更多是agito、cx2333等大佬们在为爱发电。近日,由热心网友分享的专门用于翻译gal和轻小说的本地模型Sakura-13B横空出世!只要你的显存够大,就能获得媲美gpt3.5的翻译文本!
已获得授权。大佬叫我不要提起他,不过你们去github就看得到
先上翻译成果,软件是luna翻译器,接入了本地模型的api(占用14G的显存)。

效果还是不错的
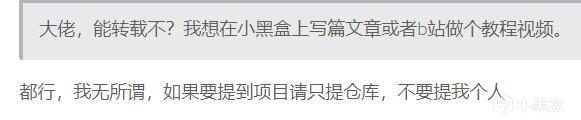
当然,没有4090也可以跑本地模型,不同的本地模型占用显存是不一样的。占用显存越小的模型,翻译速度越快同时翻译质量也越差。
笔者目前只试过Q8_0模型
教程以4090为例。其他显卡的话按照下面这个网站的教程来。
https://github.com/Sa*****LM/Sakura-13B-Galgame/wiki/llama.cpp%E4%B8%80%E9%94%AE%E5%8C%85%E9%83%A8%E7%BD%B2%E6%95%99%E7%A8%8B
所需要的资源笔者放在网盘了。
https://pan.baidu.com/s/1AUVm9nTInO34aC5IqrkCJw?pwd=tim3
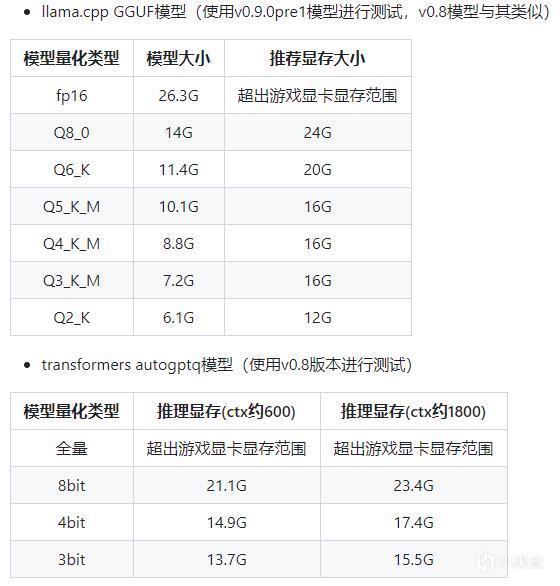
1.在全英文路径下解压sakura-launcher.v0.0.1。解压cudart-llama-bin-win-cu12.2.0-x64和llama-b1848-bin-win-cublas-cu12.2.0-x64到llama文件夹下,如图所示。
如图所示
2.将后缀名为gguf的模型文件放在sakura-launcher文件夹里面。
3.双击启动Sakura服务器-N卡.bat,你将看到一个黑乎乎的窗口弹出。这表示Sakura服务已成功启动,其默认地址为http://127.0.0.1:8080。这个黑乎乎的窗口不要关掉。
4.打开https://books.fishhawk.top/sakura-workspace。点击"添加点击"添加Sakura翻译器",链接输入http://127.0.0.1:8080,确保LlamaApi开关是打开的,然后点击添加。添加完成后,点击进行测试。如果一切顺利,将显示翻译的结果。
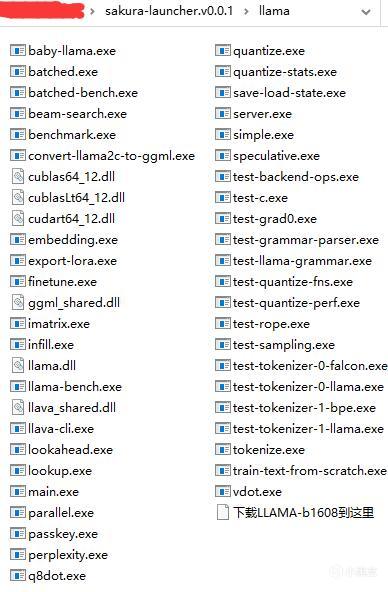
5.解压LunaTranslator。运行LunaTranslator.exe。打开设置,翻译设置,在线翻译全部打叉。
在线翻译全部打叉
离线翻译,Sakura大模型,打勾,点击粉色的齿轮图标,将http://127.0.0.1:8080复制粘贴到API接口地址。
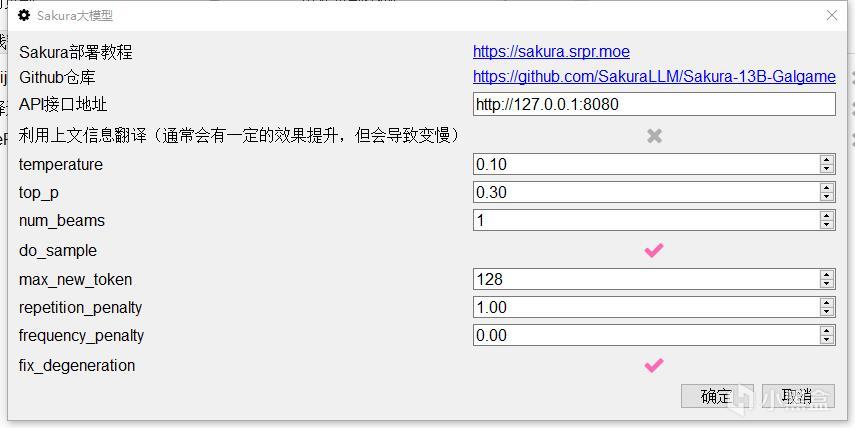
如图
关闭设置界面,选择游戏(就是锁链的图标)。选择你已经打开并且出现文本框的生肉gal,会出现“选择文本”的弹窗。

红圈中的图标就是“选择游戏”
选择一项与gal游戏里文本框对应的文本,打勾。
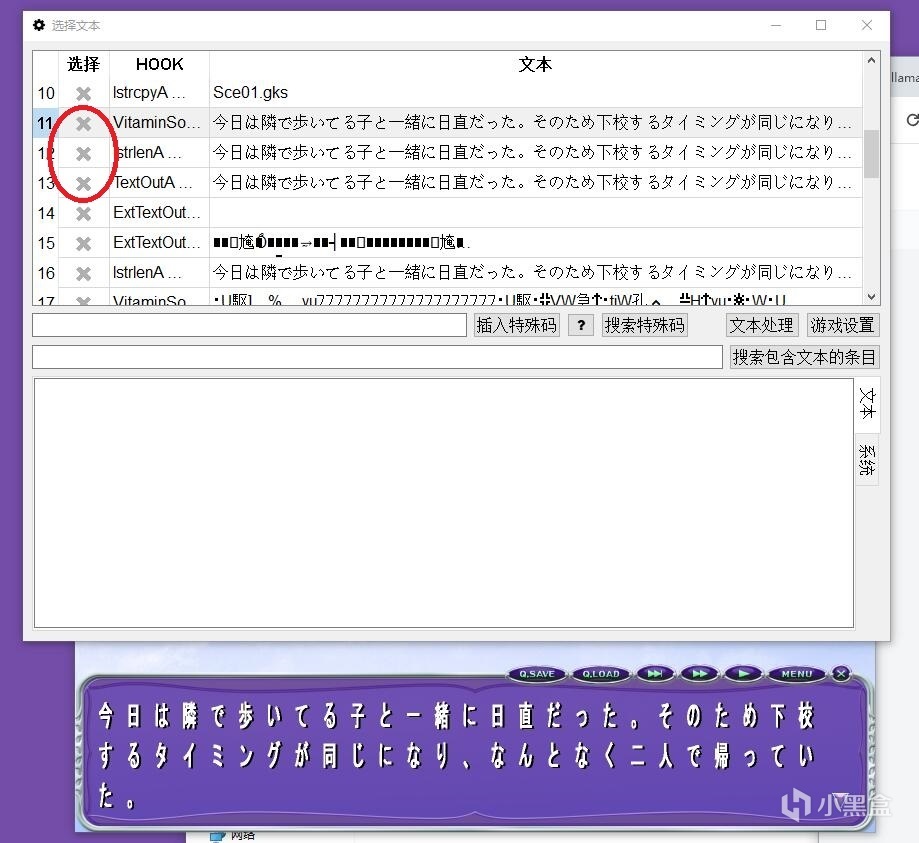
任选一项文本,出现bug的话再换成另外一项文本
正常情况下,打勾后luna翻译器里就会同时出现日文文本和翻译的中文文本。如上面的动图所示。
至于用本地模型制作13B机翻补丁啥的,涉及解包封包笔者目前也不会,遗憾没法用4090造福其他网友了。