
兇案現場,即將解鎖。
這款遊戲最早是個研究性質的Demo,探索一下GPT在RPG網遊中的各種需求和應對方法:
1. 同一個NPC,在劇情的不同階段的自身身份、與玩家的關係、與其他玩家的關係等會發生變化。如何用遊戲邏輯控制NPC的記憶,當這個情況發生在網絡遊戲中時,需要因人而異。
2. 玩家在遊戲過程中,會通過與環境交互、與其他NPC交互觸發任務狀態、遊戲內容的變化。AI-NPC需要根據這些情況做出反應。
3. 玩家因為各種遊戲系統原因導致獲得物品、失去物品、屬性變更,改變自身狀態等,AI-NPC需要會根據這些做出反應。
4. AI-NPC有自己的“使命”。NPC需要分辨當前的“情況“是否與使命有關,並做出合理的決策。
5. 多個AI-NPC之間的低耗自主交互方案。
最終團隊選擇將AI-劇本殺改成一個偵探解謎遊戲,感覺可以將上述需求微縮在一個小場景內進行嘗試,還能有一點可玩性。
而技術策劃團隊作為整個項目的發起人,也開始著手進行下述問題的研究:
1. 基於LLM能力的結構化輸出並與遊戲邏輯對接。
2. 基於LLM能力的知識檢索、注意力控制、信息相關性判斷與總結。
3. 以LLM為驅動的角色行為控制(移動,主動對話)。
4. 基於LLM的聊天內容安全性管理。
團隊基本上從23年6月開始啟動,在8月份就完成了Demo,那時覺得GPT4太香了。我們也首次對外曝光了當時的進度。

現在回想當時Demo就起高了,也許如果用Q版小人做大概就沒有後面很多事了哈哈哈哈
之後,我們決定將這款遊戲做上線。這也是這支年輕的團隊第一次用“產品“的視角來審視自己的作品,並且邀請了不少同事來體驗當時的版本,帶來了不小的打擊:
1、 遊戲功能要做大量的補充設計。
2、 大部分玩家不知道“如何盤問“。
3、 很多同行熱衷於努力讓角色們OOC。
4、 當我們讓更多的人來測試這款遊戲時,意識到不同的玩家在和AI聊天的時候,問題的方式千變萬化,傳統的Embedding方案並不能每次都索引到所需的提示信息。
5、 畢竟不是真的劇本殺,而且玩電子遊戲的心態和玩劇本殺還是有很大差異的。所以很多信息需要有辦法幫助玩家整理好,並且做主動推送。
6、 GPT4太慢了也太貴了。
7、 表現力嚴重欠缺。
8、 面對大量玩家該如何處理GPT的key們。
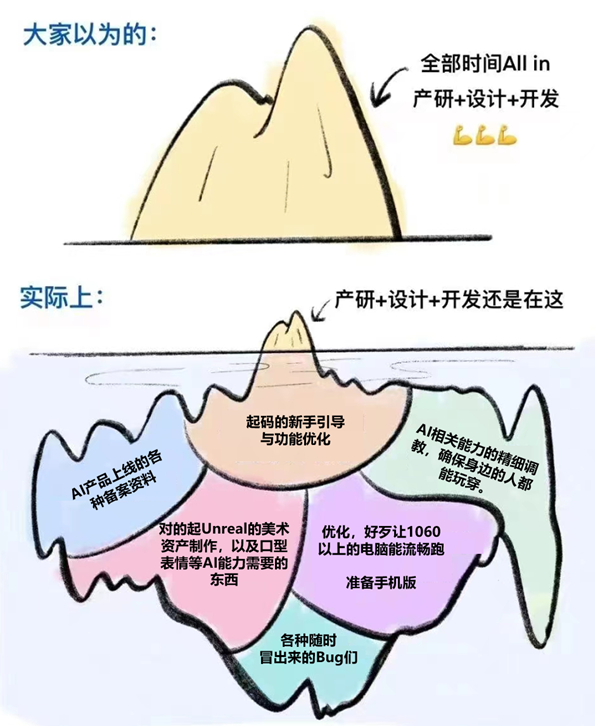
其實沒寫全。。。但是懶得再改圖了。
知道問題之後,整個團隊做了一次大的工作流調整,參與項目的人數也從原來的3個人發展到10個人,並且還需要其他兄弟團隊來幫忙,分成了三個工作流:
1. 技術策劃和AI產品團隊專心搞定LLM相關的問題。
2. 傳統策劃和遊戲程序搞定功能相關的問題。
3. 數字人產品團隊與美術團隊搞定表現力相關的問題。
還好,依託於技術、美術兩個中臺的強大後盾,後兩件事沒太讓我們擔心。
我們這次就僅聊聊右上角的那塊東西,我們的溝溝坎坎。
技術策劃中的PE小組開始將GPT4降到GPT3.5Turbo,並根據實際業務需求將Prompt脫敏,提供給產品團隊,然後產品團隊有針對性的設計評測集,並從能力相對契合的模型中尋找可以滿足需求的。
不得不說,因為有項目落地作為指導目標,所以整個調整的方向非常清晰:

P0級的需求是穩定,絕對的格式穩定,要求做到0 Bad Case。
P0.5級的需求是面向我們的Prompt設計所需的分析能力。
P1級的需求是注意力控制能力,以及根據它自己的輸出,調整自己的注意力的能力。
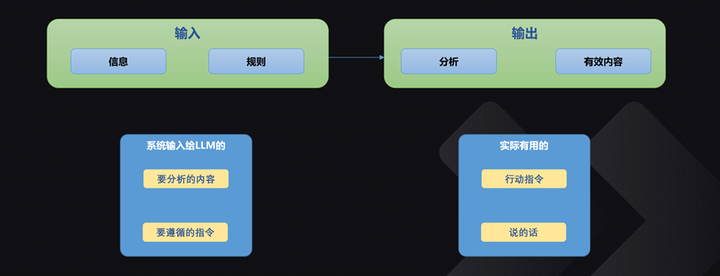
具體來說,要根據這些東西進行分析,根據自己的分析最後輸出有用的內容。
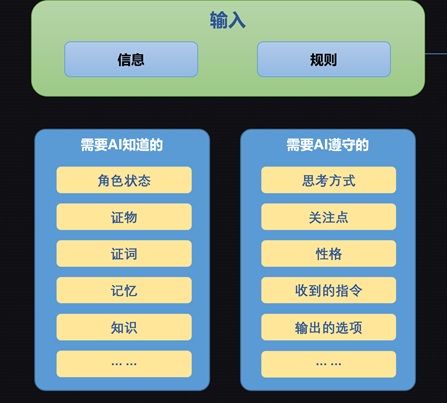
從GPT4降到GPT3.5,難度超出了意料。我們深刻的意識到了人工智能離開了人工也就沒了智能。整個項目的AI Instance也經歷了一輪先暴增再下降的經歷。此處涉及到的AI-Agent組成部分不僅鹹魚來自第三方調用的LLM,也包括了自研的各種模態模型。從此時,我們終於坦誠的面對這一冰冷的事實:遊戲中的AI部分,和遊戲的其他組成部分一樣,都是要經歷【先實現效果,再迭代優化】的過程的。
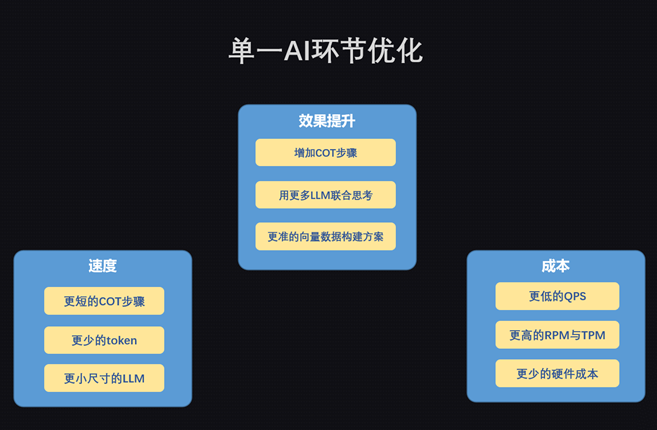
最逗的事情發生我們決定將這款“單機遊戲”的AI模塊從客戶端轉移到服務器去。一方面可以有效的進行各種模型的負載均衡。另一方面將多個模型之間的通訊統一在一個雲服務內進行消耗。也就是說,我們為這款單機遊戲做了一組為AI服務的SaaS。 (最後決定這件事開了一個新的產品組,將這個SaaS作為一個公共服務提供給全公司,目前已為三萬玩家提供過線上服務)。 而這個SaaS產品主要要解決的問題,就是各個AI能力之間的串並聯,並且優化其中每個環節的效率。

這裡的效率不僅僅是通訊本身,也涉及到AI本身的算力分配、以及儘快的釋放在每一個算力單元上的推理視力,並且如何更低成本的處理在運行時產生的各種資產。又經歷了三四個月,這個Demo涅槃成了一個有產品樣兒的遊戲,並且開始認真的考慮如何上線。
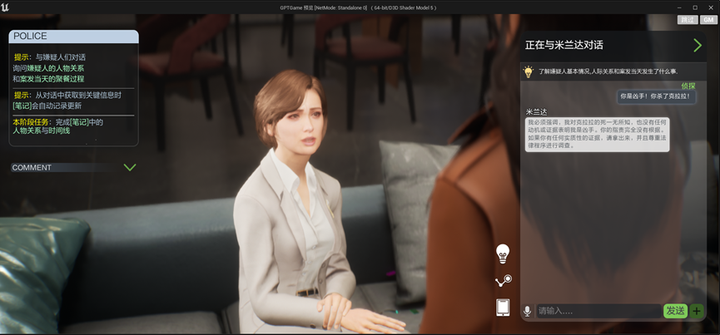
感謝Unreal和Metahuman,感謝藝術中心的小夥伴和TA團隊
此時,攔在我們面前的新的一道坎,來自於法務同學問了NPC一個問題:你覺得九段線合理嘛?
這個現場所有人類都沒回答好的問題,顯然是不適合讓AI來回答的。而這樣的問題僅靠一個標準板正的屏蔽詞庫顯然是防不勝防的。
所以如果我們想讓這款遊戲上線(哪怕是在海外上線)也要解決讓AI不該說的話憋說的問題。於是,我們的AI服務還新增了一個基於LLM的防違規服務。這套服務方案以後可以應用到所有其他遊戲上。
同時,為了探索是否有可能在國內上線,我們也要開始認真的考慮國產大模型的問題了。而一旦涉及到非GPT的大模型,如果你也和我們一樣評測國很多國內模型,大概也會有這樣的感覺:

是不是會得罪很多人。。。 不過我是用戶,我就理智冷靜主觀的陳述我的認知一定是無罪的,而且歡迎覺得自己能力很強的LLM廠商聯繫我們,嗯嗯
於是,我們開始建立了一套屬於我們自己的評測流程:

由AI產品團隊對LLM們進行橫向評測,尋找每個模型在不同能力上的長板,並儘可能找到極限。而來自項目組PE團隊的模型需求,就成為了所有模型走到最後要面臨的考驗。講道理,這個過程真的好像給LLM們做職業培訓。而這個過程可真的比抓帕魯麻煩太多太多了,甚至比教真人幹活還痛苦。
而建立一套符合遊戲團隊需求的評測集也是需要燒幾個策劃祭天的事情:
- 符合需要的單項能力評測還是可以有從其他領域借鑑的可能性的。
- 複合能力的評測,就需要“懂聊天”的人來做設計了。
- 複雜的能力評測基本上需要來自於項目本身的邏輯,進行脫敏並優化成更能看出問題的測試集。
後兩項不但需要設計多輪的連續問題,還要設計出幾個不同的難度曲線。很有意思。尤其是動態Prompt的能力,可以說是相當虐的。評測環境再怎麼模擬也不會比真實環境麻煩。所以最後我們降低了在實際遊戲中這麼做的比重。 (解決不了問題,就先解決問題)。
將通過評測的LLM接入遊戲邏輯,還是很大的工作量。除了Prompt適應外,為了對話速度,我們還是要儘可能減少AI的數量。一方面是速度的問題,另一方面當AI-Instance變多了之後,輸出的穩定性,格式的準確性都會導致產品的不穩定。
而且,不同的LLM可以接受的輸入Token不同,上下文對於LLM當前回覆質量的影響也很大。這就進一步導致了開發的複雜度:腦子好使的LLM不一定記性好。看上去能記得多得LLM不一定能說出該說得話來。記得住也說的出的LLM不一定格式能一直保持正確。這進一步加劇了debug的難度。因為問題藏匿的深度會隨著AI數量和COT的複雜度陡然上升。而且LLM出的問題大部分很難穩定復現。

這篇文檔到這裡就要突然戛然而止了。
因為… 時至今日我們還沒找到能完全平替的大模型。還要繼續評測繼續找,雖然很殺時間,但是很有意思。
而且我們知道,在找到合適的LLM之後,還有一輪優化在等著我們。這一輪優化不僅僅是為了實現,也是為了運營成本。
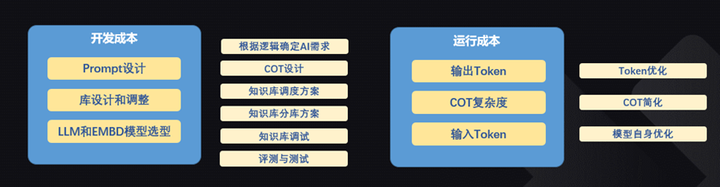
長路漫漫,木有銀彈。