
凶案现场,即将解锁。
这款游戏最早是个研究性质的Demo,探索一下GPT在RPG网游中的各种需求和应对方法:
1. 同一个NPC,在剧情的不同阶段的自身身份、与玩家的关系、与其他玩家的关系等会发生变化。如何用游戏逻辑控制NPC的记忆,当这个情况发生在网络游戏中时,需要因人而异。
2. 玩家在游戏过程中,会通过与环境交互、与其他NPC交互触发任务状态、游戏内容的变化。AI-NPC需要根据这些情况做出反应。
3. 玩家因为各种游戏系统原因导致获得物品、失去物品、属性变更,改变自身状态等,AI-NPC需要会根据这些做出反应。
4. AI-NPC有自己的“使命”。NPC需要分辨当前的“情况“是否与使命有关,并做出合理的决策。
5. 多个AI-NPC之间的低耗自主交互方案。
最终团队选择将AI-剧本杀改成一个侦探解谜游戏,感觉可以将上述需求微缩在一个小场景内进行尝试,还能有一点可玩性。
而技术策划团队作为整个项目的发起人,也开始着手进行下述问题的研究:
1. 基于LLM能力的结构化输出并与游戏逻辑对接。
2. 基于LLM能力的知识检索、注意力控制、信息相关性判断与总结。
3. 以LLM为驱动的角色行为控制(移动,主动对话)。
4. 基于LLM的聊天内容安全性管理。
团队基本上从23年6月开始启动,在8月份就完成了Demo,那时觉得GPT4太香了。我们也首次对外曝光了当时的进度。

现在回想当时Demo就起高了,也许如果用Q版小人做大概就没有后面很多事了哈哈哈哈
之后,我们决定将这款游戏做上线。这也是这支年轻的团队第一次用“产品“的视角来审视自己的作品,并且邀请了不少同事来体验当时的版本,带来了不小的打击:
1、 游戏功能要做大量的补充设计。
2、 大部分玩家不知道“如何盘问“。
3、 很多同行热衷于努力让角色们OOC。
4、 当我们让更多的人来测试这款游戏时,意识到不同的玩家在和AI聊天的时候,问题的方式千变万化,传统的Embedding方案并不能每次都索引到所需的提示信息。
5、 毕竟不是真的剧本杀,而且玩电子游戏的心态和玩剧本杀还是有很大差异的。所以很多信息需要有办法帮助玩家整理好,并且做主动推送。
6、 GPT4太慢了也太贵了。
7、 表现力严重欠缺。
8、 面对大量玩家该如何处理GPT的key们。
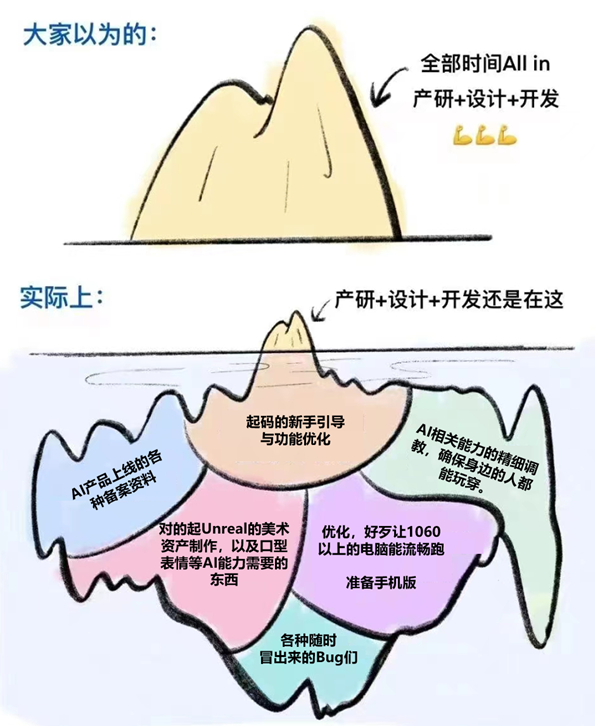
其实没写全。。。但是懒得再改图了。
知道问题之后,整个团队做了一次大的工作流调整,参与项目的人数也从原来的3个人发展到10个人,并且还需要其他兄弟团队来帮忙,分成了三个工作流:
1. 技术策划和AI产品团队专心搞定LLM相关的问题。
2. 传统策划和游戏程序搞定功能相关的问题。
3. 数字人产品团队与美术团队搞定表现力相关的问题。
还好,依托于技术、美术两个中台的强大后盾,后两件事没太让我们担心。
我们这次就仅聊聊右上角的那块东西,我们的沟沟坎坎。
技术策划中的PE小组开始将GPT4降到GPT3.5Turbo,并根据实际业务需求将Prompt脱敏,提供给产品团队,然后产品团队有针对性的设计评测集,并从能力相对契合的模型中寻找可以满足需求的。
不得不说,因为有项目落地作为指导目标,所以整个调整的方向非常清晰:

P0级的需求是稳定,绝对的格式稳定,要求做到0 Bad Case。
P0.5级的需求是面向我们的Prompt设计所需的分析能力。
P1级的需求是注意力控制能力,以及根据它自己的输出,调整自己的注意力的能力。
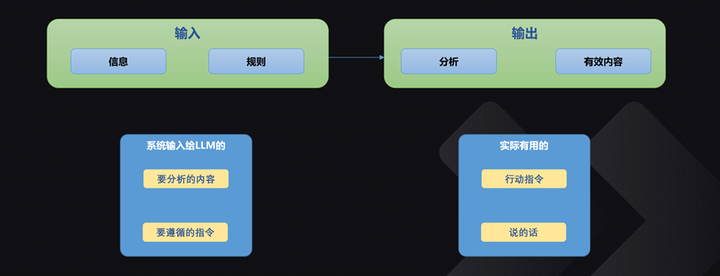
具体来说,要根据这些东西进行分析,根据自己的分析最后输出有用的内容。
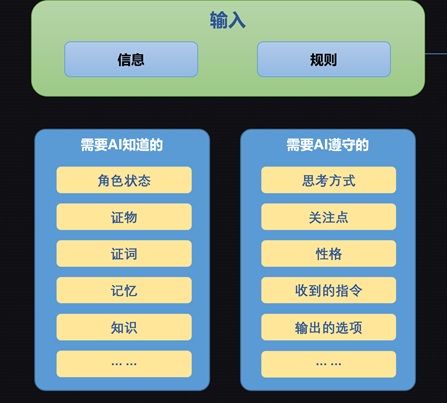
从GPT4降到GPT3.5,难度超出了意料。我们深刻的意识到了人工智能离开了人工也就没了智能。整个项目的AI Instance也经历了一轮先暴增再下降的经历。此处涉及到的AI-Agent组成部分不仅咸鱼来自第三方调用的LLM,也包括了自研的各种模态模型。从此时,我们终于坦诚的面对这一冰冷的事实:游戏中的AI部分,和游戏的其他组成部分一样,都是要经历【先实现效果,再迭代优化】的过程的。
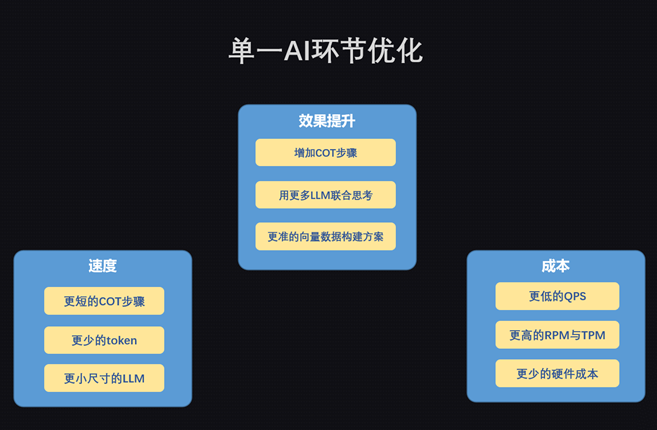
最逗的事情发生我们决定将这款“单机游戏”的AI模块从客户端转移到服务器去。一方面可以有效的进行各种模型的负载均衡。另一方面将多个模型之间的通讯统一在一个云服务内进行消耗。也就是说,我们为这款单机游戏做了一组为AI服务的SaaS。 (最后决定这件事开了一个新的产品组,将这个SaaS作为一个公共服务提供给全公司,目前已为三万玩家提供过线上服务)。 而这个SaaS产品主要要解决的问题,就是各个AI能力之间的串并联,并且优化其中每个环节的效率。

这里的效率不仅仅是通讯本身,也涉及到AI本身的算力分配、以及尽快的释放在每一个算力单元上的推理视力,并且如何更低成本的处理在运行时产生的各种资产。又经历了三四个月,这个Demo涅槃成了一个有产品样儿的游戏,并且开始认真的考虑如何上线。
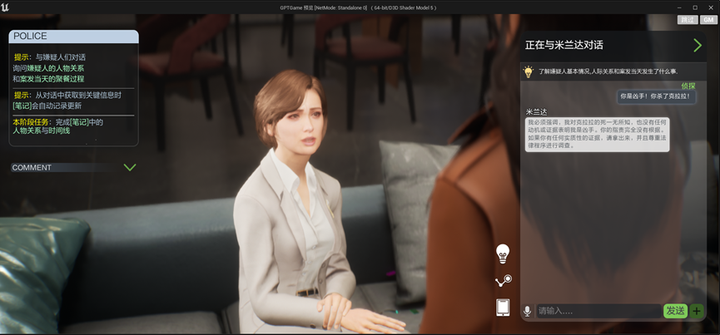
感谢Unreal和Metahuman,感谢艺术中心的小伙伴和TA团队
此时,拦在我们面前的新的一道坎,来自于法务同学问了NPC一个问题:你觉得九段线合理嘛?
这个现场所有人类都没回答好的问题,显然是不适合让AI来回答的。而这样的问题仅靠一个标准板正的屏蔽词库显然是防不胜防的。
所以如果我们想让这款游戏上线(哪怕是在海外上线)也要解决让AI不该说的话憋说的问题。于是,我们的AI服务还新增了一个基于LLM的防违规服务。这套服务方案以后可以应用到所有其他游戏上。
同时,为了探索是否有可能在国内上线,我们也要开始认真的考虑国产大模型的问题了。而一旦涉及到非GPT的大模型,如果你也和我们一样评测国很多国内模型,大概也会有这样的感觉:

是不是会得罪很多人。。。 不过我是用户,我就理智冷静主观的陈述我的认知一定是无罪的,而且欢迎觉得自己能力很强的LLM厂商联系我们,嗯嗯
于是,我们开始建立了一套属于我们自己的评测流程:

由AI产品团队对LLM们进行横向评测,寻找每个模型在不同能力上的长板,并尽可能找到极限。而来自项目组PE团队的模型需求,就成为了所有模型走到最后要面临的考验。讲道理,这个过程真的好像给LLM们做职业培训。而这个过程可真的比抓帕鲁麻烦太多太多了,甚至比教真人干活还痛苦。
而建立一套符合游戏团队需求的评测集也是需要烧几个策划祭天的事情:
- 符合需要的单项能力评测还是可以有从其他领域借鉴的可能性的。
- 复合能力的评测,就需要“懂聊天”的人来做设计了。
- 复杂的能力评测基本上需要来自于项目本身的逻辑,进行脱敏并优化成更能看出问题的测试集。
后两项不但需要设计多轮的连续问题,还要设计出几个不同的难度曲线。很有意思。尤其是动态Prompt的能力,可以说是相当虐的。评测环境再怎么模拟也不会比真实环境麻烦。所以最后我们降低了在实际游戏中这么做的比重。 (解决不了问题,就先解决问题)。
将通过评测的LLM接入游戏逻辑,还是很大的工作量。除了Prompt适应外,为了对话速度,我们还是要尽可能减少AI的数量。一方面是速度的问题,另一方面当AI-Instance变多了之后,输出的稳定性,格式的准确性都会导致产品的不稳定。
而且,不同的LLM可以接受的输入Token不同,上下文对于LLM当前回复质量的影响也很大。这就进一步导致了开发的复杂度:脑子好使的LLM不一定记性好。看上去能记得多得LLM不一定能说出该说得话来。记得住也说的出的LLM不一定格式能一直保持正确。这进一步加剧了debug的难度。因为问题藏匿的深度会随着AI数量和COT的复杂度陡然上升。而且LLM出的问题大部分很难稳定复现。

这篇文档到这里就要突然戛然而止了。
因为… 时至今日我们还没找到能完全平替的大模型。还要继续评测继续找,虽然很杀时间,但是很有意思。
而且我们知道,在找到合适的LLM之后,还有一轮优化在等着我们。这一轮优化不仅仅是为了实现,也是为了运营成本。
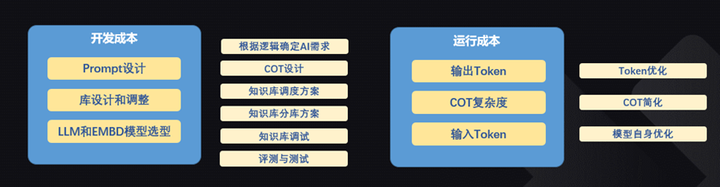
长路漫漫,木有银弹。