2月25日,DeepSeek開源周第三天,正式發佈了代碼庫DeepGEMM,專為簡潔高效的 FP8 通用矩陣乘法(GEMM)設計,核心代碼僅300行,為DeepSeek-V3/R1訓練和推理提供支持,DeepGEMM也是迄今為止最受期待、含金量最高的代碼庫,今天接著連續第三天為大家帶來DS最新的開源項目通俗解讀。

01 DeepGEMM有多強?
簡單來說,DeepGEMM是一個超級厲害的“計算加速器”,特別為MoE專家混合模型的訓練和推理量身打造,尤其是支持DeepSeek自家的V3和R1模型,你可以把它想象成一個高效的數學“大廚”,專門處理AI計算中超大量的矩陣乘法任務(GEMM就是“通用矩陣乘法”的縮寫)。

在DeepSeek官方的測試中,DeepGEMM在英偉達的Hopper GPU上,能達到1350+ TFLOPS的FP8計算能力,處理數據的速度快得驚人,比以前的工具強好幾倍,不僅支持普通的矩陣計算,還能處理混合專家模型(MoE)的計算需求,代碼庫的核心邏輯只有大約300行代碼,上手即用。

DeepGEMM安裝時不用費勁編譯,而是通過JIT即時編譯輕鬆搞定。對於廣大開發者來說,DeepGEMM就是送給大家的超級大禮包,展示DS如何用最簡單的方法解決最複雜的問題,更加難為可貴的是,DeepGEMM已經在他們的V3和R1模型中經過實戰檢驗,現在拿出來分享,含金量絕對頂級,DeepGEMM也是DS創始人梁文鋒一貫的理念,在有限計算資源的情況下,提高AI大模型訓練和推理的效率,接下來我們就抽絲剝繭對一個個術語進行解釋。
02 什麼是通用矩陣乘法GEMM
DeepGEMM是專為簡潔高效的 FP8 通用矩陣乘法(GEMM)設計,GEMM全稱是General Matrix Multiplication,也就是“通用矩陣乘法”,GEMM本質是一種數學操作,核心就是把兩個矩陣“乘”在一起,得到一個新的矩陣。矩陣乘法是線性代數里的基本操作,學過大學線性代數的會很熟悉,GEMM這個名之所以字聽起來比較高大上,主要是因為被廣泛用於AI領域,大家很難對AI相關的技術祛魅。
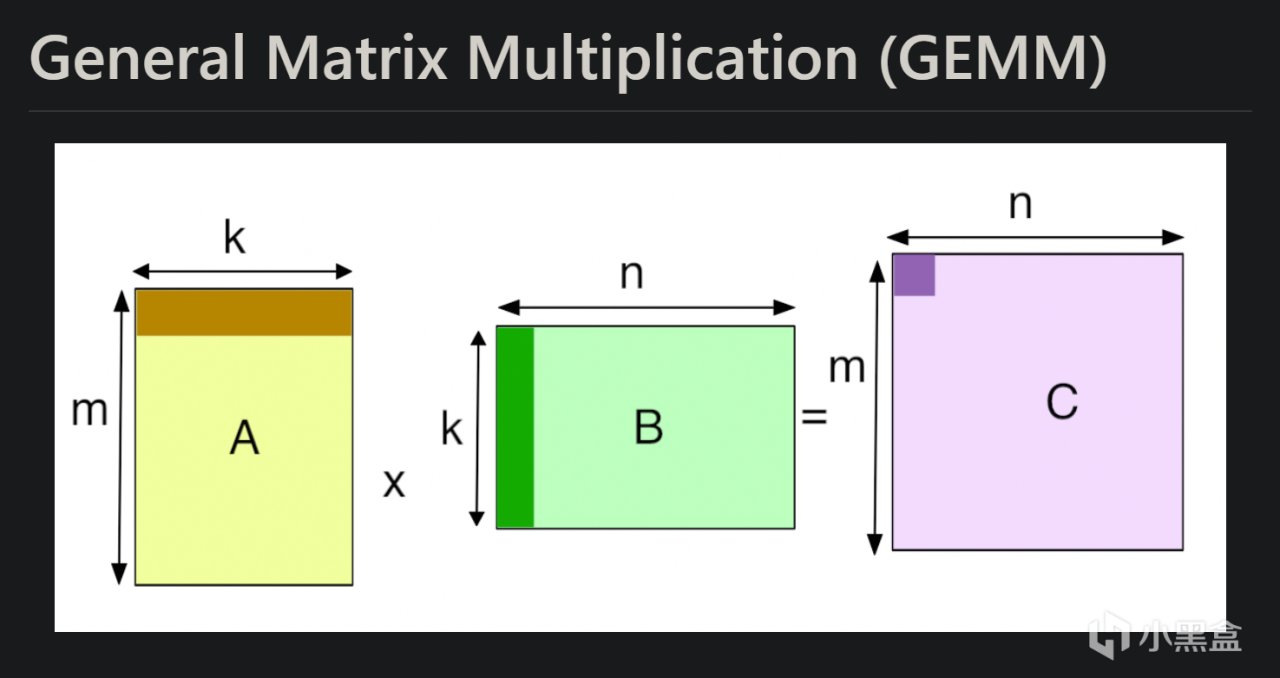
相比矩陣乘法,GEMM前面冠上了“通用”二字,這裡“通用”體現在GEMM不侷限於特定的矩陣大小,而是能處理各種尺寸和類型的矩陣乘法,還能加上一些額外的操作(比如加個偏移量),所以特別靈活,GEMM其實也是深度學習中的基石核心運算。在遊戲社區,大家非常關心英偉達的顯卡性能,每年老黃在GTC大會上都會公開各個消費級顯卡的算力FLOPS,而GEMM就是評估計算硬件算力的標準技術。
在AI和機器學習裡,尤其是深度學習,矩陣乘法是核心中的核心,比如在最早的神經網絡訓練LeNet中,每一層的神經網絡都在做大量的矩陣乘法,把輸入數據和權重“乘”在一起算出結果,這些計算量非常大,動輒幾千行幾千列的矩陣相乘,早期的矩陣乘法的計算複雜度很高,普通方法是O(n³)(n是矩陣大小),計算量隨著矩陣變大呈立方級增長,所以怎麼讓GEMM跑得又快又省資源,就成了大家思考最多的問題之一。
1979年,科學家推出了BLAS(Basic Linear Algebra Subprograms),這是一個標準化的線性代數庫,其中Level 3的BLAS就包括了GEMM。GEMM被定義為一個通用操作:C = αAB + βC,其中A、B是輸入矩陣,C是輸出,α和β是標量,能靈活調整計算,那時候的程序員會針對特定硬件(比如CPU)手動調整代碼,利用緩存、分塊計算讓GEMM跑得更快;到了90年代,多核CPU出現,GEMM開始用並行計算。比如OpenMP這樣的工具,能把矩陣乘法任務分給多個CPU核心同時幹活,而真正改變歷史的還是老黃的英偉達。
進入21世紀,與此同時發展起來的還有機器學習,像很多科學計算任務如天氣預報、物理仿真和早期的機器學習,都是極度依賴GEMM;2006年,英偉達正式推出了CUDA(Compute Unified Device Architecture),讓GPU從單純的圖形處理器變成通用計算神器,GPU有成千上萬個核心,非常適合並行任務,而GEMM恰好是那種可以“拆開幹活”的計算,於是CUDA核心數逐漸成為我們衡量顯卡算力最重要的標準。
英偉達在CUDA的基礎上推出了cuBLAS庫,專門優化GEMM等線性代數操作,對比CPU,GPU將GEMM速度提升了幾十倍甚至上百倍,英偉達的工程師們進一步通過分塊(tiling)、內存管理(用共享內存減少讀寫延遲)等操作讓GEMM能夠在GPU上如魚得水。到了AI深度學習元年,也就是2012年,Hinton教授和學生Alex、Ilya的AlexNet在ImageNet大賽上奪冠,神經網絡從此成為AI時代最重要的基石,而神經網絡的每一層都都離不開GEMM。

03 DeepSeek是如何創新的?
介紹完了GEMM的前世,接下來我們一起看DeepSeek是如何創新的。與第一天FlashMLA的BF16、第二天DeepEP的FP8類似,DeepSeek也在低精度計算上做文章——傳統的GEMM使用FP32(32位浮點)精度,訓練的計算量巨大,FP32顯得太“浪費”,於是出現了FP16(半精度)、INT8(8位整數)的數據類型,英偉達在2017年推出Volta架構引入Tensor Core,專門加速GEMM,尤其是FP16和混合精度。
今年,DeepSeek直接將數據精度壓縮至FP8(8位浮點),FP8相比FP16內存帶寬需求降低50%,更適合大規模模型的實時推理,而英偉達真的就是DeepSeek的最強後盾,22年的Hopper架構開始支持FP8性能直接起飛,Hopper架構可以進行兩級累加技術,即通過Hopper GPU的CUDA核心進行FP32中間結果累加,彌補FP8精度損失,確保關鍵信息不丟失。
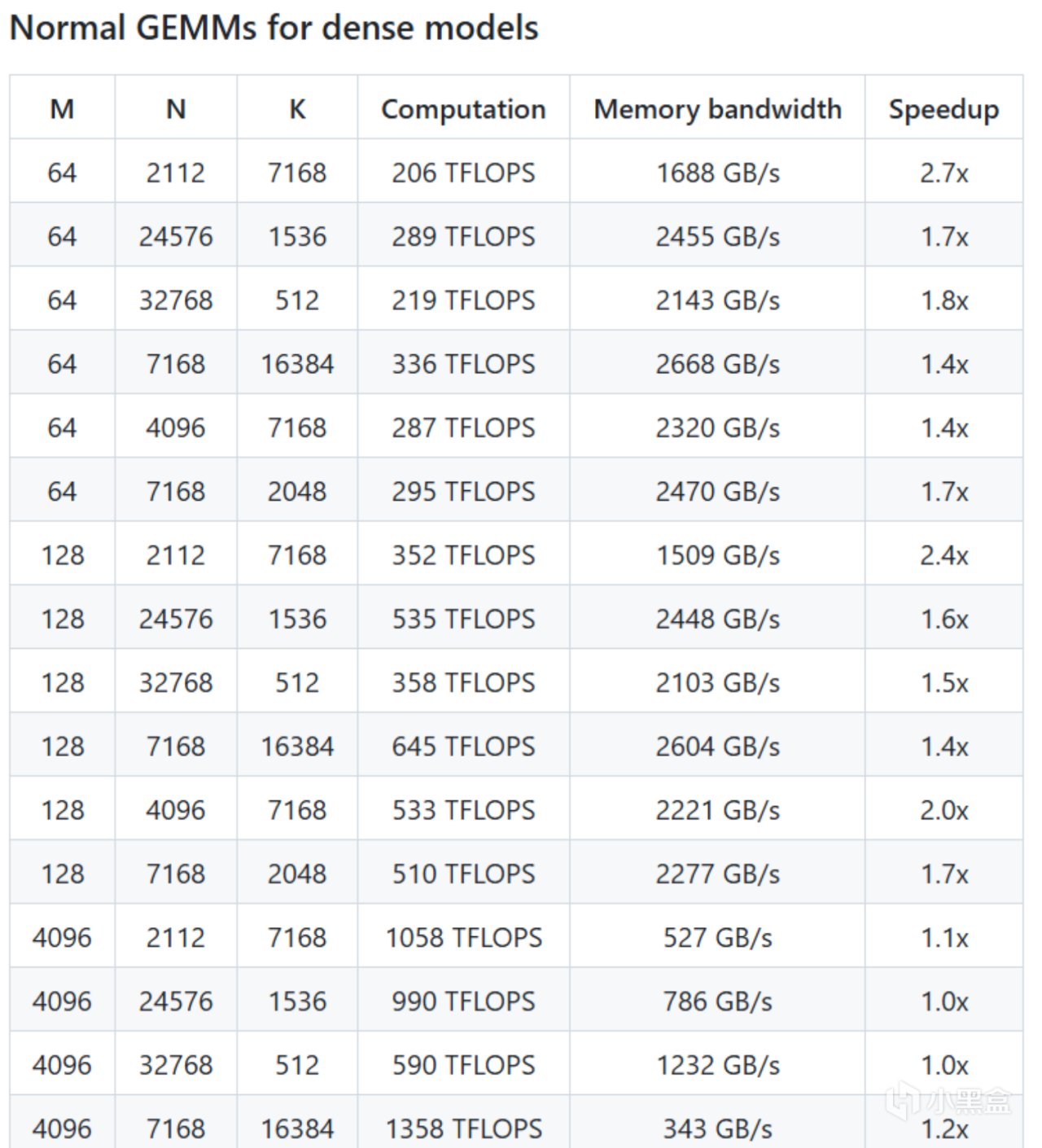
DeepGEMM同時專門為Hopper GPU架構進行深度適配,比如支持了112×128等非標準分塊計算,突破了英偉達傳統的分塊限制,提升GPU張量核心利用率14%,利用TMA(Tensor Memory Accelerator)技術加速,內存帶寬達2668 GB/s,接近理論峰值。
DeepGEMM不光搞定標準矩陣乘法,還為MoE專家架構模型也進行了專屬優化,批量處理同類型專家計算(如MoE訓練前向傳播),減少GPU上下文切換損耗,提速1.2倍,同時動態跳過無效計算(如推理解碼中的空令牌),延遲降低30%。MoE模型的特點是隻激活部分專家網絡,數據處理方式很“挑剔”,DeepGEMM設計的連續排列(把數據接成一塊)和掩碼排列(標記哪些數據要算),完美適配這種需求。
未來,MoE是大模型的趨勢,這幾天的代碼庫都是圍繞MoE展開,混合專家模型計算效率一直是瓶頸,DeepGEMM就像給MoE裝了個發動機,讓這個模型跑起來更快更高效,同時DeepGEMM代碼清晰易懂,結構簡單,沒有像CUTLASS那樣用複雜的模板堆砌,而是用直白的CUDA代碼實現,還自帶Python接口(標準、連續分組、掩碼分組函數),讓開發者能快速上手,大大降低了技術門檻。

04 DeepGEMM未來有什麼影響
還是老生常談的話題,DeepGEMM是繞開CUDA嗎?今天我給出的答案很明確,不會。DeepGEMM反而有可能加深CUDA的護城河,之前DeepSeek-V3的時候亮點就是訓練成本大大降低,使用的FP8精度仍然需要配合Hopper GPU的超高性能,這次DeepSeek開源的DeepGEMM用實際行動證明了FP8低精度計算不僅可行,還能兼顧性能和效率。
未來其他開發者可能會陸續跟進DeepSeek的腳步,各家硬件廠商未來也會加速推出支持低精度的芯片,軟件生態也會圍繞低精度優化,形成一個正反饋循環,而這個反饋循環的核心還是CUDA。DeepGEMM的靈感本身來源於CUTLASS項目,完全依託於英偉達的CUDA框架和Hopper GPU硬件生態,DeepGEMM的300行代碼之所以能這麼高效,也是因為充分利用了CUDA提供的低級控制能力(比如內存管理、線程調度)和硬件加速(FP8支持),這恰恰證明了CUDA的強大。
當然,DeepSeek本身就是推動CUDA生態繼續發展最重要的公司之一,這次的DeepGEMM項目完全開源,其他廠商要改進或者定製仍然有難度,無形之中也提高了競爭對手AMD的ROCm的追趕難度,想要繞開CUDA就得開發一個新框架,還要適配各種硬件,況且當前AI領域90%以上的深度學習框架(像TensorFlow、PyTorch)都是深度集成CUDA,生態已經形成。
DeepGEMM輕量化設計也吸引了大量社區貢獻,目前已經有開發者提交PR優化非常規矩陣形狀性能,DeepGEMM未來會讓AI更快、更省、更普及,同時推動低精度計算和開源生態的發展,當前DeepSeek已經讓大家對OpenAI這些閉源公司祛魅,這是開源社區的勝利,同時也感謝DeepSeek毫無保留地分享核心技術,期待剩下兩天的代碼庫,另外也期待全新的大模型DeepSeek-R2(據知情人士,R2現在正在訓練中,並且會提前開源)!
