2月25日,DeepSeek开源周第三天,正式发布了代码库DeepGEMM,专为简洁高效的 FP8 通用矩阵乘法(GEMM)设计,核心代码仅300行,为DeepSeek-V3/R1训练和推理提供支持,DeepGEMM也是迄今为止最受期待、含金量最高的代码库,今天接着连续第三天为大家带来DS最新的开源项目通俗解读。

01 DeepGEMM有多强?
简单来说,DeepGEMM是一个超级厉害的“计算加速器”,特别为MoE专家混合模型的训练和推理量身打造,尤其是支持DeepSeek自家的V3和R1模型,你可以把它想象成一个高效的数学“大厨”,专门处理AI计算中超大量的矩阵乘法任务(GEMM就是“通用矩阵乘法”的缩写)。

在DeepSeek官方的测试中,DeepGEMM在英伟达的Hopper GPU上,能达到1350+ TFLOPS的FP8计算能力,处理数据的速度快得惊人,比以前的工具强好几倍,不仅支持普通的矩阵计算,还能处理混合专家模型(MoE)的计算需求,代码库的核心逻辑只有大约300行代码,上手即用。

DeepGEMM安装时不用费劲编译,而是通过JIT即时编译轻松搞定。对于广大开发者来说,DeepGEMM就是送给大家的超级大礼包,展示DS如何用最简单的方法解决最复杂的问题,更加难为可贵的是,DeepGEMM已经在他们的V3和R1模型中经过实战检验,现在拿出来分享,含金量绝对顶级,DeepGEMM也是DS创始人梁文锋一贯的理念,在有限计算资源的情况下,提高AI大模型训练和推理的效率,接下来我们就抽丝剥茧对一个个术语进行解释。
02 什么是通用矩阵乘法GEMM
DeepGEMM是专为简洁高效的 FP8 通用矩阵乘法(GEMM)设计,GEMM全称是General Matrix Multiplication,也就是“通用矩阵乘法”,GEMM本质是一种数学操作,核心就是把两个矩阵“乘”在一起,得到一个新的矩阵。矩阵乘法是线性代数里的基本操作,学过大学线性代数的会很熟悉,GEMM这个名之所以字听起来比较高大上,主要是因为被广泛用于AI领域,大家很难对AI相关的技术祛魅。
相比矩阵乘法,GEMM前面冠上了“通用”二字,这里“通用”体现在GEMM不局限于特定的矩阵大小,而是能处理各种尺寸和类型的矩阵乘法,还能加上一些额外的操作(比如加个偏移量),所以特别灵活,GEMM其实也是深度学习中的基石核心运算。在游戏社区,大家非常关心英伟达的显卡性能,每年老黄在GTC大会上都会公开各个消费级显卡的算力FLOPS,而GEMM就是评估计算硬件算力的标准技术。
在AI和机器学习里,尤其是深度学习,矩阵乘法是核心中的核心,比如在最早的神经网络训练LeNet中,每一层的神经网络都在做大量的矩阵乘法,把输入数据和权重“乘”在一起算出结果,这些计算量非常大,动辄几千行几千列的矩阵相乘,早期的矩阵乘法的计算复杂度很高,普通方法是O(n³)(n是矩阵大小),计算量随着矩阵变大呈立方级增长,所以怎么让GEMM跑得又快又省资源,就成了大家思考最多的问题之一。
1979年,科学家推出了BLAS(Basic Linear Algebra Subprograms),这是一个标准化的线性代数库,其中Level 3的BLAS就包括了GEMM。GEMM被定义为一个通用操作:C = αAB + βC,其中A、B是输入矩阵,C是输出,α和β是标量,能灵活调整计算,那时候的程序员会针对特定硬件(比如CPU)手动调整代码,利用缓存、分块计算让GEMM跑得更快;到了90年代,多核CPU出现,GEMM开始用并行计算。比如OpenMP这样的工具,能把矩阵乘法任务分给多个CPU核心同时干活,而真正改变历史的还是老黄的英伟达。
进入21世纪,与此同时发展起来的还有机器学习,像很多科学计算任务如天气预报、物理仿真和早期的机器学习,都是极度依赖GEMM;2006年,英伟达正式推出了CUDA(Compute Unified Device Architecture),让GPU从单纯的图形处理器变成通用计算神器,GPU有成千上万个核心,非常适合并行任务,而GEMM恰好是那种可以“拆开干活”的计算,于是CUDA核心数逐渐成为我们衡量显卡算力最重要的标准。
英伟达在CUDA的基础上推出了cuBLAS库,专门优化GEMM等线性代数操作,对比CPU,GPU将GEMM速度提升了几十倍甚至上百倍,英伟达的工程师们进一步通过分块(tiling)、内存管理(用共享内存减少读写延迟)等操作让GEMM能够在GPU上如鱼得水。到了AI深度学习元年,也就是2012年,Hinton教授和学生Alex、Ilya的AlexNet在ImageNet大赛上夺冠,神经网络从此成为AI时代最重要的基石,而神经网络的每一层都都离不开GEMM。

03 DeepSeek是如何创新的?
介绍完了GEMM的前世,接下来我们一起看DeepSeek是如何创新的。与第一天FlashMLA的BF16、第二天DeepEP的FP8类似,DeepSeek也在低精度计算上做文章——传统的GEMM使用FP32(32位浮点)精度,训练的计算量巨大,FP32显得太“浪费”,于是出现了FP16(半精度)、INT8(8位整数)的数据类型,英伟达在2017年推出Volta架构引入Tensor Core,专门加速GEMM,尤其是FP16和混合精度。
今年,DeepSeek直接将数据精度压缩至FP8(8位浮点),FP8相比FP16内存带宽需求降低50%,更适合大规模模型的实时推理,而英伟达真的就是DeepSeek的最强后盾,22年的Hopper架构开始支持FP8性能直接起飞,Hopper架构可以进行两级累加技术,即通过Hopper GPU的CUDA核心进行FP32中间结果累加,弥补FP8精度损失,确保关键信息不丢失。
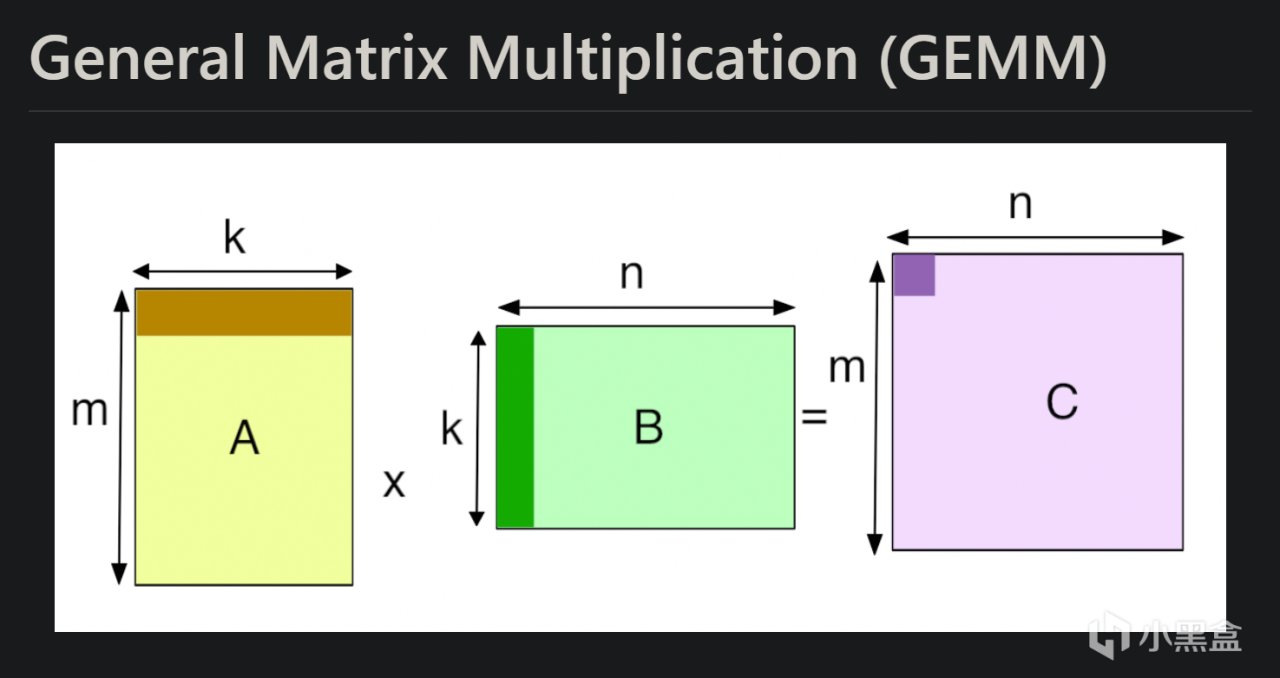
DeepGEMM同时专门为Hopper GPU架构进行深度适配,比如支持了112×128等非标准分块计算,突破了英伟达传统的分块限制,提升GPU张量核心利用率14%,利用TMA(Tensor Memory Accelerator)技术加速,内存带宽达2668 GB/s,接近理论峰值。
DeepGEMM不光搞定标准矩阵乘法,还为MoE专家架构模型也进行了专属优化,批量处理同类型专家计算(如MoE训练前向传播),减少GPU上下文切换损耗,提速1.2倍,同时动态跳过无效计算(如推理解码中的空令牌),延迟降低30%。MoE模型的特点是只激活部分专家网络,数据处理方式很“挑剔”,DeepGEMM设计的连续排列(把数据接成一块)和掩码排列(标记哪些数据要算),完美适配这种需求。
未来,MoE是大模型的趋势,这几天的代码库都是围绕MoE展开,混合专家模型计算效率一直是瓶颈,DeepGEMM就像给MoE装了个发动机,让这个模型跑起来更快更高效,同时DeepGEMM代码清晰易懂,结构简单,没有像CUTLASS那样用复杂的模板堆砌,而是用直白的CUDA代码实现,还自带Python接口(标准、连续分组、掩码分组函数),让开发者能快速上手,大大降低了技术门槛。

04 DeepGEMM未来有什么影响
还是老生常谈的话题,DeepGEMM是绕开CUDA吗?今天我给出的答案很明确,不会。DeepGEMM反而有可能加深CUDA的护城河,之前DeepSeek-V3的时候亮点就是训练成本大大降低,使用的FP8精度仍然需要配合Hopper GPU的超高性能,这次DeepSeek开源的DeepGEMM用实际行动证明了FP8低精度计算不仅可行,还能兼顾性能和效率。
未来其他开发者可能会陆续跟进DeepSeek的脚步,各家硬件厂商未来也会加速推出支持低精度的芯片,软件生态也会围绕低精度优化,形成一个正反馈循环,而这个反馈循环的核心还是CUDA。DeepGEMM的灵感本身来源于CUTLASS项目,完全依托于英伟达的CUDA框架和Hopper GPU硬件生态,DeepGEMM的300行代码之所以能这么高效,也是因为充分利用了CUDA提供的低级控制能力(比如内存管理、线程调度)和硬件加速(FP8支持),这恰恰证明了CUDA的强大。
当然,DeepSeek本身就是推动CUDA生态继续发展最重要的公司之一,这次的DeepGEMM项目完全开源,其他厂商要改进或者定制仍然有难度,无形之中也提高了竞争对手AMD的ROCm的追赶难度,想要绕开CUDA就得开发一个新框架,还要适配各种硬件,况且当前AI领域90%以上的深度学习框架(像TensorFlow、PyTorch)都是深度集成CUDA,生态已经形成。
DeepGEMM轻量化设计也吸引了大量社区贡献,目前已经有开发者提交PR优化非常规矩阵形状性能,DeepGEMM未来会让AI更快、更省、更普及,同时推动低精度计算和开源生态的发展,当前DeepSeek已经让大家对OpenAI这些闭源公司祛魅,这是开源社区的胜利,同时也感谢DeepSeek毫无保留地分享核心技术,期待剩下两天的代码库,另外也期待全新的大模型DeepSeek-R2(据知情人士,R2现在正在训练中,并且会提前开源)!
