近期發表的一項研究探討了大型語言模型(LLM)和多模態大型語言模型(MLLM)在概念表示方面是否能夠模擬人類大腦的功能。該研究由一個國際科學家團隊完成,他們通過分析近470萬次的三元組判斷數據,揭示了人工智能如何理解和分類自然物體。
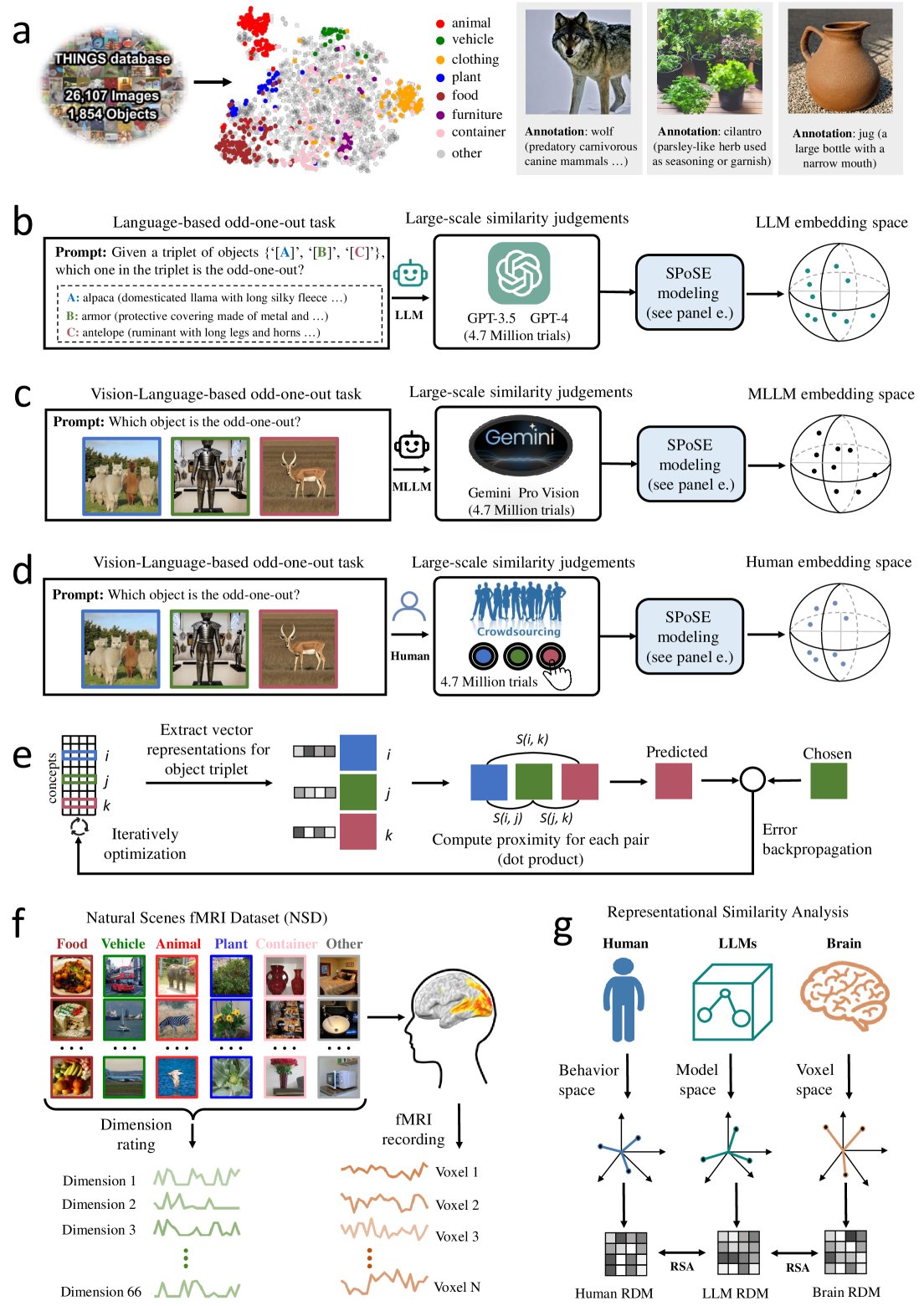
研究團隊選取了1854種自然物體,並採用一種稱為“稀疏正相似性嵌入”(SPoSE)的方法,從中提取了66個維度的概念表示。這些表示不僅穩定而且具有高度的預測能力,顯示出與人類心智模型相似的語義聚類特性。
通過與人類大腦活動模式的對比,研究人員發現,無論是LLM還是MLLM的物體表示與大腦中的多個功能區域(如EBA、PPA、RSC和FFA等)的神經活動模式都有很強的一致性。這些發現為人工智能的發展提供了新的視角,表明通過大規模語言和圖像數據的訓練,人工智能可以發展出與人類相似的概念表示能力。
此外,研究還探討了LLM和MLLM在理解物體類別方面的能力。結果顯示,這些模型能夠識別出18個高級別的物體類別,如動物、食物和工具等,其準確率遠高於隨機水平,進一步證明了它們在無需特定任務訓練的情況下也能表現出類似人類的分類能力。
這項研究的首席科學家表示,這一發現不僅增強了我們對人工智能內部運作的理解,也為未來開發更加人性化的人工智能系統提供了可能。他們希望通過進一步的研究,探索人工智能在更廣泛的自然語境中的應用潛力,例如在提供個性化助手和改善機器人系統交互方面。
研究結果已經在科學期刊上發表,並引起了學術界和技術界的廣泛關注。隨著人工智能技術的不斷進步,其在模擬和擴展人類認知能力方面的潛力正在逐漸顯現,預示著未來可能出現更多創新的人機協作模式。