1.前言
1.1 FLUX.1
今年前不久,Black Forest Labs團隊發佈了擁有120億參數量的FLUX.1繪畫模型,該團隊儘管是一家初創公司,但其內部有大量從Stability AI離職的前Stable Difussion開發者,可謂陣容十分豪華。
FLUX.1擁有120億參數量,是SDXL的3.5倍,SD3的1.5倍。作為一個規模如此之大的模型,其可以說做到了目前開源最強的位置,當前繪畫AI難以處理的“手”對FLUX.1來說完全不是問題,不僅如此,其開創性地做到了穩定的文字生成,你可以讓指定的文字穩定地出現在圖片之中,而不是像其他AI一樣只能生成歪歪扭扭的“蚯蚓”。

FLUX.1生成的手與文字
1.2 ComfyUI
繪畫模型WebUI的發展幾乎和繪畫模型本身是同步的,如今市面上已經出現了許多WebUI,如A1111、forge和SD.Next。
而ComfyUI開創性地將節點式工作流引入了AI繪畫當中,這使得用戶可以很方便地自定義自己的工作流,將AI自然地做為自己整個流程的一部分乃至多AI協作,而不是像之前那樣只能手動操作。
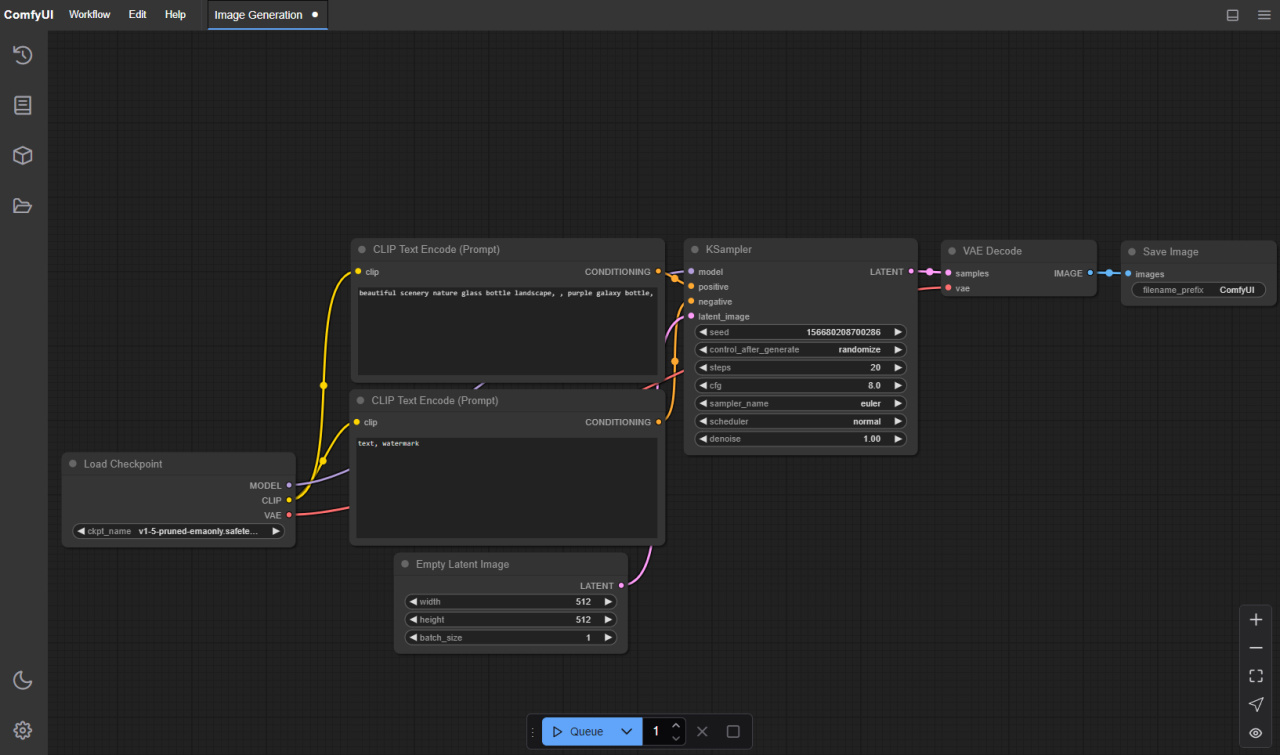
ComfyUI的節點式工作流
https://github.com/comfyanonymous/ComfyUI
1.3 秋葉整合包
b站用戶秋葉aaaki將運行AI繪畫WebUI幾乎所有的運行環境打包成了單個的整合包,該整合集成了Zluda的支持,A卡可在Windows下通過GPU直接運行,用戶需要的僅僅是安裝顯卡驅動和下載自定義模型就可以輕鬆運行AI繪畫。
秋葉大佬發佈了多個WebUI的整合,A1111的包主要適用於輕度使用,勝在方便,其也無法運行FLUX.1模型,而ComfyUI的包,如上文所述,功能強大,同時也支持FLUX.1故本文將採用此包進行示例。
https://space.bilibili.com/12566101
2.正文
2.1 簡單的基礎環境配置
首先按照我這篇教程的內容安裝HIP SDK,這屬於驅動層面的內容,即使整合包整合了包括Zluda在內的幾乎所有環境,但是HIP SDK無法整合進其中。注意,儘管這篇教程很長,但是安裝HIP SDK的部分很簡單,你無需全部閱讀。
![]()
![]() 【教程】A卡用戶Windows下AI運行完全指南-基礎環境篇
【教程】A卡用戶Windows下AI運行完全指南-基礎環境篇
之後下載秋葉大佬的ComfyUI整合包,並將其解壓到指定位置。下載鏈接在秋葉大佬的視頻下面的置頂評論裡,各位還是儘量去給一個三連。
https://www.bilibili.com/video/BV1Ew411776J
解壓後打開A繪世啟動器.exe,點擊高級選項,將生成引擎切換為ZLUDA GPU。
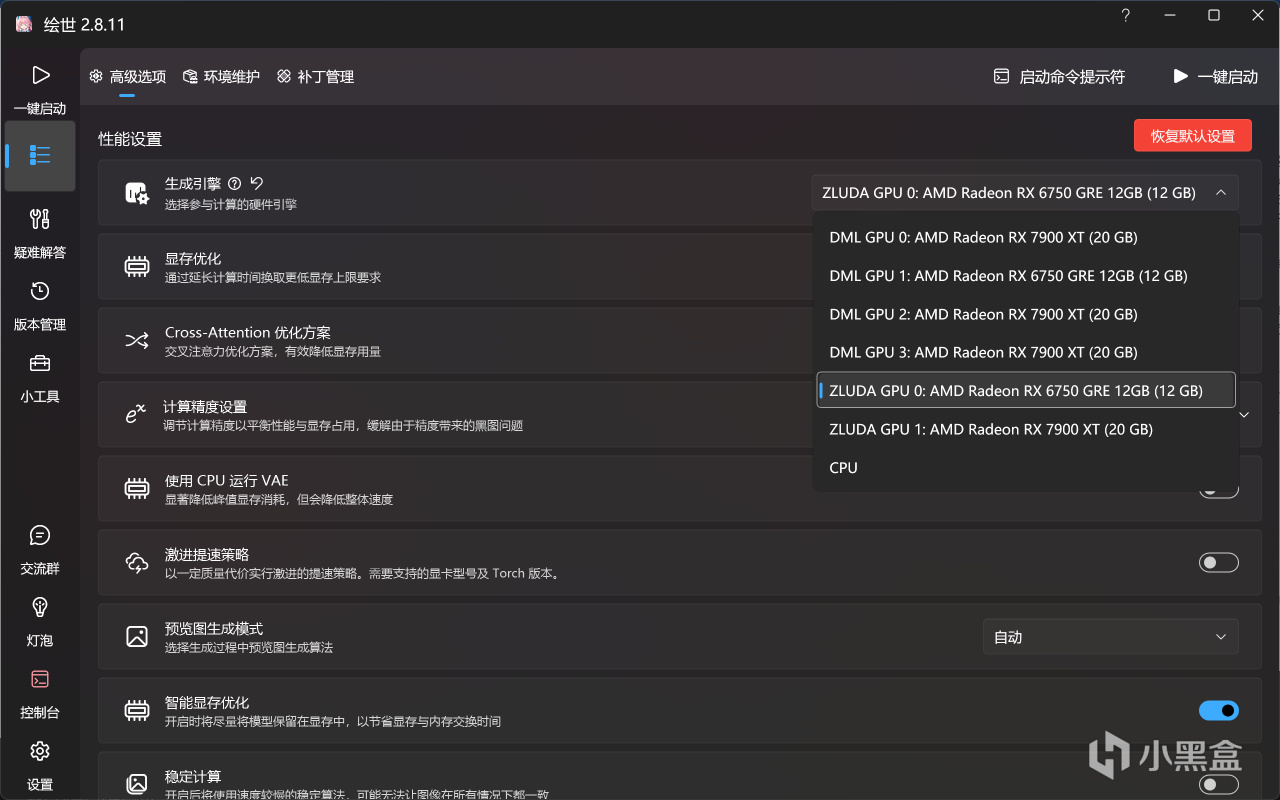
切換生成引擎
至此,你已經可以啟動後用自帶的工作流和上一代的SD1.5模型進行圖片生成了,但我們的目的不止於此。
2.2 GGUF插件安裝
GGUF插件即為小顯存運行擁有120億參數的FLUX.1大模型的核心,要以完整精度加載FLUX.1,即使有20G顯存的7900XT也無法做到。而GGUF簡而言之就是將原本16位的精度的模型量化為更低精度的版本,如8位、5位乃至2位,其原本用於大語言模型的推理,如今繪畫模型的規模也達到了一定的量級,所以也用上了GGUF,關於其更詳細的介紹可以參考我的這篇文章:
![]()
![]() A卡Windows下大模型運行(量化)與微調(原生)指南
A卡Windows下大模型運行(量化)與微調(原生)指南
對於規模足夠大的模型而言,量化損失的精度對模型輸出的影響是足夠小的。下圖是原精度模型(上)和量化精度模型(下)在同提示詞和隨機種子下生成圖像的對比。可以看到其差距非常小。[本人顯卡無法加載全精度模型,故此對比採用他人圖片,圖片來源https://www.youtube.com/watch?v=b_-zwpaNJXQ]
量化模型和原模型效果對比
ComfyUI本身不支持GGUF模型的加載,需要安裝插件,而整合包也未將其收錄,但我們可以手動進行安裝。
直接在繪世啟動器中安裝ComfyUI-GGUF插件,點擊版本管理-安裝新拓展-搜索GGUF,找到ComfyUI-GGUF點擊進行安裝。
ComfyUI-GGUF插件
2.3 模型下載
我們通過HuggingFace鏡像對模型進行下載,huggingface-cli的安裝以及鏡像站的配置請查看我這篇教程的1.4節部分:
![]()
![]() A卡Windows下大模型運行(量化)與微調(原生)指南
A卡Windows下大模型運行(量化)與微調(原生)指南
完成上述配置後,運行如下指令下載量化版本的FLUX.1模型本體:
huggingface-cli download --resume-download city96/FLUX.1-dev-gguf --include "flux1-dev-Q4_0*.gguf" --local-dir J:\改成\你自己的\下載位置\FLUX.1-dev-gguf
注意下載路徑改成你自己的,而"flux1-dev-Q4_0*.gguf"中的這個"Q4_0"指的就是量化精度,各位可以根據你的顯存容量選擇下載頁面中存在的不同的精度。
倉庫地址(國內鏡像站):https://hf-mirror.com/city96/FLUX.1-dev-gguf/tree/main
可用的精度
之後下載文本編碼器權重,首先是T5模型,我指令中選擇的依舊是Q4_K_M量化版本,各位也可根據自己的顯存選擇其他版本。
倉庫地址(國內鏡像站):https://hf-mirror.com/city96/t5-v1_1-xxl-encoder-gguf/tree/main
huggingface-cli download --resume-download city96/t5-v1_1-xxl-encoder-gguf --include "t5-v1_1-xxl-encoder-Q4_K_M.gguf" --local-dir J:\改成\你自己的\下載位置\t5-v1_1-xxl-encoder-gguf
接著使用如下指令下載clip_l.safetensors,這個權重規模很小,沒必要量化。
huggingface-cli download --resume-download comfyanonymous/flux_text_encoders --include "clip_l.safetensors" --local-dir J:\改成\你自己的\下載位置\flux_text_encoders
之後下載VAE權重,由於black forest labs的限制,你需要認證後才能進行下載,在這裡我分享一下網盤鏈接:
百度網盤:https://pan.baidu.com/s/1ZDwEA7k9s0KXJ18a_UbwSw?pwd=sma5
夸克網盤:https://pan.quark.cn/s/02d2adcca269
即使如此,我還是推薦你按照官方的過程進行下載,因為在之後你可能還會下載很多這樣的模型。這個過程非常簡單,首先註冊一個HuggingFace賬號,驗證完郵箱後來到模型的發佈頁面,點擊同意信息共享協議即可:
倉庫地址:https://huggingface.co/black-forest-labs/FLUX.1-dev
同意協議以訪問此倉庫
之後進入此頁面生成一個訪問token以供huggingface-cli使用:
https://huggingface.co/settings/tokens
點擊Create new token:
Create New Token
名字和訪問範圍隨便,但是必須勾上"Read access to contents of all public gated repos you can access":
允許訪問公開倉庫
最後劃到最下面點擊Create token:
Create token
在彈出的窗口點擊Copy複製好你的token,然後點擊Done即可。
複製Token
有了token後,即可用以下指令下載vae模型:
huggingface-cli download --token 你自己的token --resume-download black-forest-labs/FLUX.1-dev --include "vae/diffusion_pytorch_model.safetensors" --local-dir J:\改成\你自己的\下載位置\FLUX.1-dev
分別下載完成模型本體、2個文本編碼模型、VAE模型之後,將它們放到如下的位置:
模型本體:整合包位置\models\unet
模型本體位置
2個文本編碼模型:整合包位置\models\clip
文本編碼模型位置
VAE模型:整合包位置\vae
VAE模型位置
2.4 重裝對應版本PyTorch
此時點擊啟動後提示PyTorch版本(cu121)與Zluda不匹配,點擊前往高級選項安裝PyTorch即可。
版本不匹配
選擇一個cu118的PyTorch版本後點擊安裝。
安裝CUDA11.8版本的PyTorch
2.5 正式運行
此時再點擊一鍵啟動就能成功運行ComfyUI了。
一鍵啟動
如果界面不是中文,點擊Switch Locale即可切換為中文:
切換語言
之後下載此工作流,這是一個FLUX.1的基礎工作流,可以使其成功運行起來:
百度網盤:https://pan.baidu.com/s/1OXPZt1gBN6Y_wbHMByOHKw?pwd=pkar
夸克網盤:https://pan.quark.cn/s/c948790a88db
將其複製到如下路徑:整合包位置\my_workflows
工作流位置
之後在瀏覽器點擊左上角的文件夾圖標切換配置文件:
切換配置文件
選擇剛剛下載的配置文件:
選擇配置文件
之後做如下檢查:
DualCLIPLoader (GGUF)中的兩個文本編碼器是否為上面你下載的兩個編碼器;
Unet Loader (GGUF)中的模型是否為你剛才下載的FLUX.1模型;
VAE加載器是否為你剛才下載的VAE。
之後,你可以在文本編輯器中修改你自己的提示詞,也可先用我默認的查看效果,需要注意的是,提示詞內容不必像我這樣用逗號隔開單個短語,也可以直接使用自然語言描述完整的一段話,但是需要是英語。一切均無誤後,點擊“添加提示詞隊列”開始生成圖片。
確認模型並開始運行
首次運行需要轉譯PTX模塊,這個過程需要花費30分鐘到60分鐘不等,期間無論是控制檯還是網頁端均不會有任何輸出,請耐心等待,之後再運行則無需此過程。
轉譯PTX模塊
Q4量化的模型最終使用了約8GB的顯存,6750GRE可以正常運行此模型,速度約5.3秒每步,各位的顯存如果依舊不足的話,可以選擇比Q4更低量化精度的版本。
6750GRE運行中
7900XT的速度則要更快,約1.4秒每步。
7900XT運行中
從結果來看,FLUX模型還是比較“聽話”的,很好地根據要求生成了綠幕背景的圖片。而在這之後如果你想使用這些圖片進行進一步的處理,綠幕背景就能極大地方便你的後續工作。已生成的圖像通過保存節點保存在了{整合包位置\output}中。
生成結果
3.結語
至此,本篇教程完全結束,你已經可以用你的A卡在Windows下輕鬆地運行AI繪畫。同時,本文僅僅做為基礎流程的教程,你在通過本文認識了ComfyUI和FLUX.1後,可以自行搭建功能更為強大的工作流,如多視角角色設計。至此,你手中A卡的作用不再侷限於玩遊戲,Windows下運行AI也不再是N卡獨屬的功能,你可以用你的A卡運行當下幾乎任何的開源AI程序,使其成為你能使用起來的強大工具。
多視角角色骨骼圖
另附上本人的A卡進行大模型推理以及微調的教程:
![]()
![]() A卡Windows下大模型運行(量化)與微調(原生)指南
A卡Windows下大模型運行(量化)與微調(原生)指南