1.前言
1.1 FLUX.1
今年前不久,Black Forest Labs团队发布了拥有120亿参数量的FLUX.1绘画模型,该团队尽管是一家初创公司,但其内部有大量从Stability AI离职的前Stable Difussion开发者,可谓阵容十分豪华。
FLUX.1拥有120亿参数量,是SDXL的3.5倍,SD3的1.5倍。作为一个规模如此之大的模型,其可以说做到了目前开源最强的位置,当前绘画AI难以处理的“手”对FLUX.1来说完全不是问题,不仅如此,其开创性地做到了稳定的文字生成,你可以让指定的文字稳定地出现在图片之中,而不是像其他AI一样只能生成歪歪扭扭的“蚯蚓”。

FLUX.1生成的手与文字
1.2 ComfyUI
绘画模型WebUI的发展几乎和绘画模型本身是同步的,如今市面上已经出现了许多WebUI,如A1111、forge和SD.Next。
而ComfyUI开创性地将节点式工作流引入了AI绘画当中,这使得用户可以很方便地自定义自己的工作流,将AI自然地做为自己整个流程的一部分乃至多AI协作,而不是像之前那样只能手动操作。
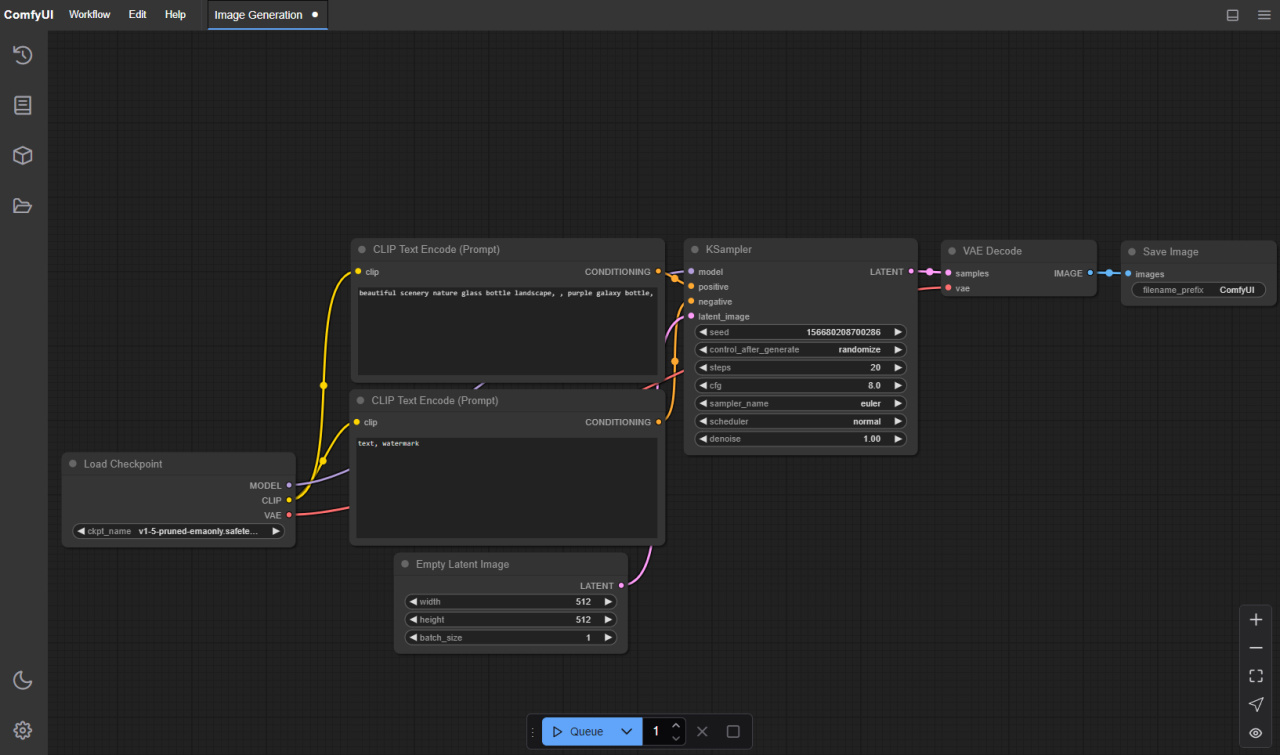
ComfyUI的节点式工作流
https://github.com/comfyanonymous/ComfyUI
1.3 秋叶整合包
b站用户秋葉aaaki将运行AI绘画WebUI几乎所有的运行环境打包成了单个的整合包,该整合集成了Zluda的支持,A卡可在Windows下通过GPU直接运行,用户需要的仅仅是安装显卡驱动和下载自定义模型就可以轻松运行AI绘画。
秋叶大佬发布了多个WebUI的整合,A1111的包主要适用于轻度使用,胜在方便,其也无法运行FLUX.1模型,而ComfyUI的包,如上文所述,功能强大,同时也支持FLUX.1故本文将采用此包进行示例。
https://space.bilibili.com/12566101
2.正文
2.1 简单的基础环境配置
首先按照我这篇教程的内容安装HIP SDK,这属于驱动层面的内容,即使整合包整合了包括Zluda在内的几乎所有环境,但是HIP SDK无法整合进其中。注意,尽管这篇教程很长,但是安装HIP SDK的部分很简单,你无需全部阅读。
![]()
![]() 【教程】A卡用户Windows下AI运行完全指南-基础环境篇
【教程】A卡用户Windows下AI运行完全指南-基础环境篇
之后下载秋叶大佬的ComfyUI整合包,并将其解压到指定位置。下载链接在秋叶大佬的视频下面的置顶评论里,各位还是尽量去给一个三连。
https://www.bilibili.com/video/BV1Ew411776J
解压后打开A绘世启动器.exe,点击高级选项,将生成引擎切换为ZLUDA GPU。
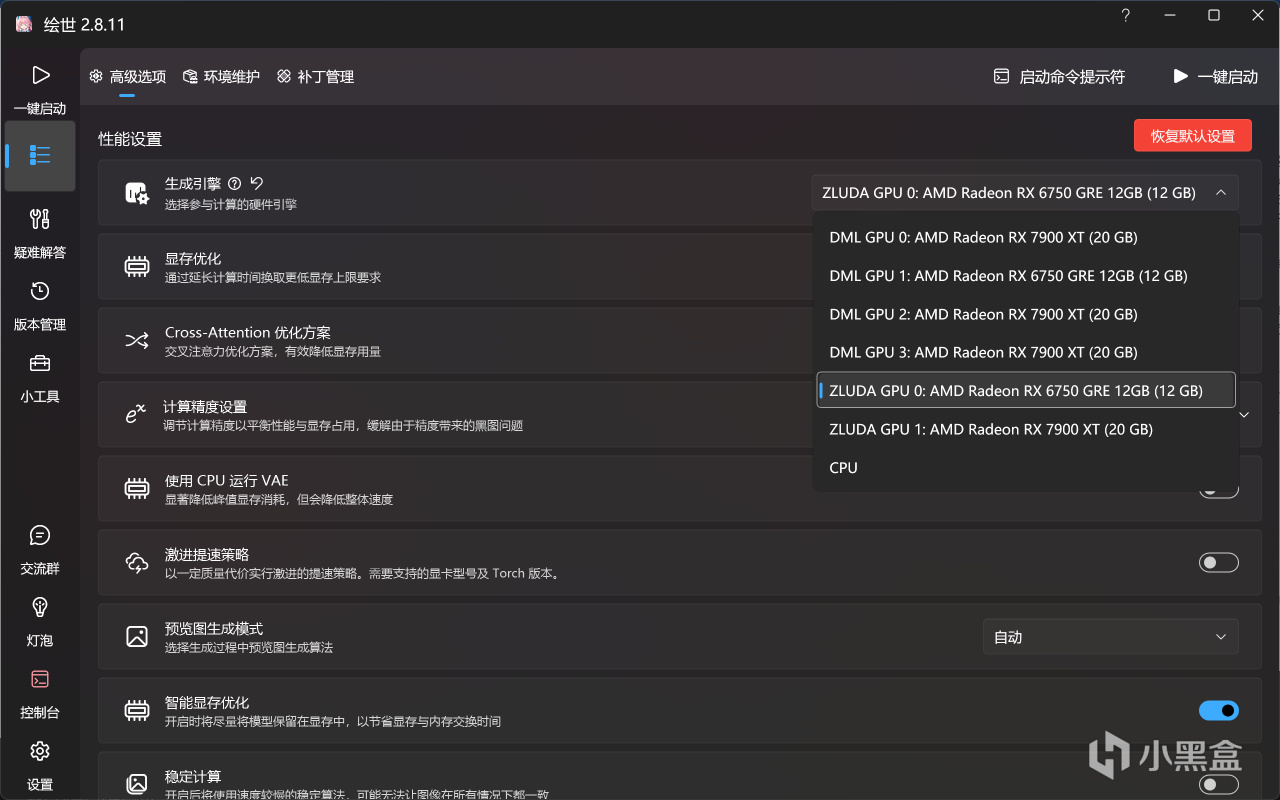
切换生成引擎
至此,你已经可以启动后用自带的工作流和上一代的SD1.5模型进行图片生成了,但我们的目的不止于此。
2.2 GGUF插件安装
GGUF插件即为小显存运行拥有120亿参数的FLUX.1大模型的核心,要以完整精度加载FLUX.1,即使有20G显存的7900XT也无法做到。而GGUF简而言之就是将原本16位的精度的模型量化为更低精度的版本,如8位、5位乃至2位,其原本用于大语言模型的推理,如今绘画模型的规模也达到了一定的量级,所以也用上了GGUF,关于其更详细的介绍可以参考我的这篇文章:
![]()
![]() A卡Windows下大模型运行(量化)与微调(原生)指南
A卡Windows下大模型运行(量化)与微调(原生)指南
对于规模足够大的模型而言,量化损失的精度对模型输出的影响是足够小的。下图是原精度模型(上)和量化精度模型(下)在同提示词和随机种子下生成图像的对比。可以看到其差距非常小。[本人显卡无法加载全精度模型,故此对比采用他人图片,图片来源https://www.youtube.com/watch?v=b_-zwpaNJXQ]
量化模型和原模型效果对比
ComfyUI本身不支持GGUF模型的加载,需要安装插件,而整合包也未将其收录,但我们可以手动进行安装。
直接在绘世启动器中安装ComfyUI-GGUF插件,点击版本管理-安装新拓展-搜索GGUF,找到ComfyUI-GGUF点击进行安装。
ComfyUI-GGUF插件
2.3 模型下载
我们通过HuggingFace镜像对模型进行下载,huggingface-cli的安装以及镜像站的配置请查看我这篇教程的1.4节部分:
![]()
![]() A卡Windows下大模型运行(量化)与微调(原生)指南
A卡Windows下大模型运行(量化)与微调(原生)指南
完成上述配置后,运行如下指令下载量化版本的FLUX.1模型本体:
huggingface-cli download --resume-download city96/FLUX.1-dev-gguf --include "flux1-dev-Q4_0*.gguf" --local-dir J:\改成\你自己的\下载位置\FLUX.1-dev-gguf
注意下载路径改成你自己的,而"flux1-dev-Q4_0*.gguf"中的这个"Q4_0"指的就是量化精度,各位可以根据你的显存容量选择下载页面中存在的不同的精度。
仓库地址(国内镜像站):https://hf-mirror.com/city96/FLUX.1-dev-gguf/tree/main
可用的精度
之后下载文本编码器权重,首先是T5模型,我指令中选择的依旧是Q4_K_M量化版本,各位也可根据自己的显存选择其他版本。
仓库地址(国内镜像站):https://hf-mirror.com/city96/t5-v1_1-xxl-encoder-gguf/tree/main
huggingface-cli download --resume-download city96/t5-v1_1-xxl-encoder-gguf --include "t5-v1_1-xxl-encoder-Q4_K_M.gguf" --local-dir J:\改成\你自己的\下载位置\t5-v1_1-xxl-encoder-gguf
接着使用如下指令下载clip_l.safetensors,这个权重规模很小,没必要量化。
huggingface-cli download --resume-download comfyanonymous/flux_text_encoders --include "clip_l.safetensors" --local-dir J:\改成\你自己的\下载位置\flux_text_encoders
之后下载VAE权重,由于black forest labs的限制,你需要认证后才能进行下载,在这里我分享一下网盘链接:
百度网盘:https://pan.baidu.com/s/1ZDwEA7k9s0KXJ18a_UbwSw?pwd=sma5
夸克网盘:https://pan.quark.cn/s/02d2adcca269
即使如此,我还是推荐你按照官方的过程进行下载,因为在之后你可能还会下载很多这样的模型。这个过程非常简单,首先注册一个HuggingFace账号,验证完邮箱后来到模型的发布页面,点击同意信息共享协议即可:
仓库地址:https://huggingface.co/black-forest-labs/FLUX.1-dev
同意协议以访问此仓库
之后进入此页面生成一个访问token以供huggingface-cli使用:
https://huggingface.co/settings/tokens
点击Create new token:
Create New Token
名字和访问范围随便,但是必须勾上"Read access to contents of all public gated repos you can access":
允许访问公开仓库
最后划到最下面点击Create token:
Create token
在弹出的窗口点击Copy复制好你的token,然后点击Done即可。
复制Token
有了token后,即可用以下指令下载vae模型:
huggingface-cli download --token 你自己的token --resume-download black-forest-labs/FLUX.1-dev --include "vae/diffusion_pytorch_model.safetensors" --local-dir J:\改成\你自己的\下载位置\FLUX.1-dev
分别下载完成模型本体、2个文本编码模型、VAE模型之后,将它们放到如下的位置:
模型本体:整合包位置\models\unet
模型本体位置
2个文本编码模型:整合包位置\models\clip
文本编码模型位置
VAE模型:整合包位置\vae
VAE模型位置
2.4 重装对应版本PyTorch
此时点击启动后提示PyTorch版本(cu121)与Zluda不匹配,点击前往高级选项安装PyTorch即可。
版本不匹配
选择一个cu118的PyTorch版本后点击安装。
安装CUDA11.8版本的PyTorch
2.5 正式运行
此时再点击一键启动就能成功运行ComfyUI了。
一键启动
如果界面不是中文,点击Switch Locale即可切换为中文:
切换语言
之后下载此工作流,这是一个FLUX.1的基础工作流,可以使其成功运行起来:
百度网盘:https://pan.baidu.com/s/1OXPZt1gBN6Y_wbHMByOHKw?pwd=pkar
夸克网盘:https://pan.quark.cn/s/c948790a88db
将其复制到如下路径:整合包位置\my_workflows
工作流位置
之后在浏览器点击左上角的文件夹图标切换配置文件:
切换配置文件
选择刚刚下载的配置文件:
选择配置文件
之后做如下检查:
DualCLIPLoader (GGUF)中的两个文本编码器是否为上面你下载的两个编码器;
Unet Loader (GGUF)中的模型是否为你刚才下载的FLUX.1模型;
VAE加载器是否为你刚才下载的VAE。
之后,你可以在文本编辑器中修改你自己的提示词,也可先用我默认的查看效果,需要注意的是,提示词内容不必像我这样用逗号隔开单个短语,也可以直接使用自然语言描述完整的一段话,但是需要是英语。一切均无误后,点击“添加提示词队列”开始生成图片。
确认模型并开始运行
首次运行需要转译PTX模块,这个过程需要花费30分钟到60分钟不等,期间无论是控制台还是网页端均不会有任何输出,请耐心等待,之后再运行则无需此过程。
转译PTX模块
Q4量化的模型最终使用了约8GB的显存,6750GRE可以正常运行此模型,速度约5.3秒每步,各位的显存如果依旧不足的话,可以选择比Q4更低量化精度的版本。
6750GRE运行中
7900XT的速度则要更快,约1.4秒每步。
7900XT运行中
从结果来看,FLUX模型还是比较“听话”的,很好地根据要求生成了绿幕背景的图片。而在这之后如果你想使用这些图片进行进一步的处理,绿幕背景就能极大地方便你的后续工作。已生成的图像通过保存节点保存在了{整合包位置\output}中。
生成结果
3.结语
至此,本篇教程完全结束,你已经可以用你的A卡在Windows下轻松地运行AI绘画。同时,本文仅仅做为基础流程的教程,你在通过本文认识了ComfyUI和FLUX.1后,可以自行搭建功能更为强大的工作流,如多视角角色设计。至此,你手中A卡的作用不再局限于玩游戏,Windows下运行AI也不再是N卡独属的功能,你可以用你的A卡运行当下几乎任何的开源AI程序,使其成为你能使用起来的强大工具。
多视角角色骨骼图
另附上本人的A卡进行大模型推理以及微调的教程:
![]()
![]() A卡Windows下大模型运行(量化)与微调(原生)指南
A卡Windows下大模型运行(量化)与微调(原生)指南