參與測試的AI有ChatGPT,Kimi,Gemini,Copilot(開啟GPT4)
測試不限時,測試項目有:智能思維、英語作文、數學題目、常識題目、詩歌創作
考卷:
一、智能思維題目(每道20分)
1.—只熊從P點出發,向正南走一英里,然後改變方向向正東走1英里,然後再向左轉,往正北走一英里,此時它正好到達它出發的P點。
這隻熊是什麼顏色的?
2. 鮑勃(Bob)想要一塊完全平坦的土地,它有四條邊界線,其中兩條為正南北走向,另兩條為正東西走向,而其中每一條邊界線的長度恰好為100英尺。鮑勃能在美國買到這樣的一塊土地嗎?
3.鮑勃有10個口袋和44枚銀幣。他想把這些銀幣分配到這些口袋中去,使每個口袋中的銀幣數都不相同。他能做到嗎?
4.為了給一本厚書標上頁碼,印刷工人用了2989 個數字。這本書總共有多少頁?
5.在祖父的文件中發現了一張賬單:
72只火雞 $_67.9_
那個顯然表示這些家禽總價的數的第一位和最後一位數碼已經褪色了,難以辨認,因此這裡用下劃線代替。
這兩個褪色的數碼是什麼?每隻火雞的價格是多少?
二、英語作文題目(每道50分)


三、數學題目(80分)
求和
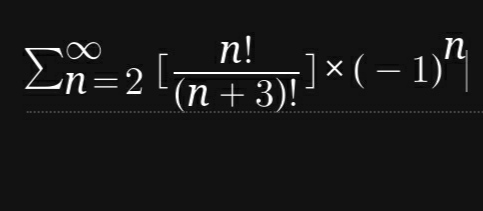
四、常識題目(每道10分)
1.魯迅和周樹人是什麼關係?
2.在數值上9.11和9.8哪個大?
五、詩歌創作題目(每道25分)
1.以藝術為主題,仿照郭沫若的文筆寫一首二十行左右的詩歌
2.以藝術為主題,仿照徐志摩的文筆寫一首二十行左右的詩歌
以上為全部考題
題目設置背景與緣由:
智能思維題目是波利亞《怎樣解題》中的五道題目,挑選的是靠前的比較簡單的題目,我認為《怎樣解題》中的題目有一定的思維性,能夠較好地測出AI的思維能力。
英語作文摘自我們老師昨天佈置的作業,實際上,我之前已經用Gemini幫我寫了很多次英語作文了。
數學題目我挑選了一個有一定技巧性的題目 ,這些技巧對AI的考驗很大,為了拉開AI間的差距,我沒有挑選更具技巧性的題目。
常識題目是一些對AI常用的題目,魯迅與周樹人之前常用於分辨GPT3.5和GPT4,9.8與9.11常用於消遣AI。
詩歌創作採用了去年某作文大賽的主題,只不過題材改為僅限詩歌,便於測試。
測試結果:
測試過程和判分依據:英語作文和詩歌是我主觀判分的,但是我本身英語和語文並不很好,所以成績僅供參考。數學題目只有ChatGPT在我引導下(我並未告知答案)做出來了,其他的AI在我告知答案是1/24依舊無法做出題目,給出錯誤答案,其中Kimi甚至說1/24才是錯的,最後我都酌情給了10分。常識題目Kimi和Copilot答錯的都是9.8比9.11那道題。最令我吃驚的是Gemini沒有一道智能思維題目是完全正確的,實際上我只應該給它10分(第3問對了一半)最終酌情給加了10分
最後,我搞這個測試是因為有位同學不久前跟我說Kimi是他見過最聰明的AI(他沒有翻牆經歷)而我本人最近到處碰見Kimi打廣告也比較煩,我就整理了一些測試題目來看看Kimi實際上怎麼樣,結果看來,Kimi只有詩歌創作方面有優勢(得益於中文本土模型?喝油們可以測測ChatGLM怎麼樣)在其他方面就表現的比較中庸。不過大家應該注意到了這次測試更側重數學與邏輯,而一些語言模型又恰好不太擅長這些,所以這次測試並不能代表語言模型的全部性能,希望喝油們以自己的實際體驗為準