参与测试的AI有ChatGPT,Kimi,Gemini,Copilot(开启GPT4)
测试不限时,测试项目有:智能思维、英语作文、数学题目、常识题目、诗歌创作
考卷:
一、智能思维题目(每道20分)
1.—只熊从P点出发,向正南走一英里,然后改变方向向正东走1英里,然后再向左转,往正北走一英里,此时它正好到达它出发的P点。
这只熊是什么颜色的?
2. 鲍勃(Bob)想要一块完全平坦的土地,它有四条边界线,其中两条为正南北走向,另两条为正东西走向,而其中每一条边界线的长度恰好为100英尺。鲍勃能在美国买到这样的一块土地吗?
3.鲍勃有10个口袋和44枚银币。他想把这些银币分配到这些口袋中去,使每个口袋中的银币数都不相同。他能做到吗?
4.为了给一本厚书标上页码,印刷工人用了2989 个数字。这本书总共有多少页?
5.在祖父的文件中发现了一张账单:
72只火鸡 $_67.9_
那个显然表示这些家禽总价的数的第一位和最后一位数码已经褪色了,难以辨认,因此这里用下划线代替。
这两个褪色的数码是什么?每只火鸡的价格是多少?
二、英语作文题目(每道50分)


三、数学题目(80分)
求和
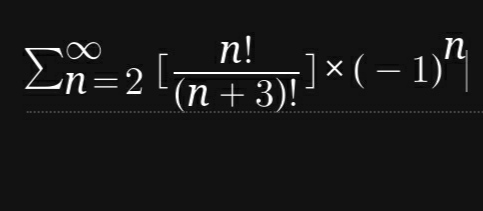
四、常识题目(每道10分)
1.鲁迅和周树人是什么关系?
2.在数值上9.11和9.8哪个大?
五、诗歌创作题目(每道25分)
1.以艺术为主题,仿照郭沫若的文笔写一首二十行左右的诗歌
2.以艺术为主题,仿照徐志摩的文笔写一首二十行左右的诗歌
以上为全部考题
题目设置背景与缘由:
智能思维题目是波利亚《怎样解题》中的五道题目,挑选的是靠前的比较简单的题目,我认为《怎样解题》中的题目有一定的思维性,能够较好地测出AI的思维能力。
英语作文摘自我们老师昨天布置的作业,实际上,我之前已经用Gemini帮我写了很多次英语作文了。
数学题目我挑选了一个有一定技巧性的题目 ,这些技巧对AI的考验很大,为了拉开AI间的差距,我没有挑选更具技巧性的题目。
常识题目是一些对AI常用的题目,鲁迅与周树人之前常用于分辨GPT3.5和GPT4,9.8与9.11常用于消遣AI。
诗歌创作采用了去年某作文大赛的主题,只不过题材改为仅限诗歌,便于测试。
测试结果:
测试过程和判分依据:英语作文和诗歌是我主观判分的,但是我本身英语和语文并不很好,所以成绩仅供参考。数学题目只有ChatGPT在我引导下(我并未告知答案)做出来了,其他的AI在我告知答案是1/24依旧无法做出题目,给出错误答案,其中Kimi甚至说1/24才是错的,最后我都酌情给了10分。常识题目Kimi和Copilot答错的都是9.8比9.11那道题。最令我吃惊的是Gemini没有一道智能思维题目是完全正确的,实际上我只应该给它10分(第3问对了一半)最终酌情给加了10分
最后,我搞这个测试是因为有位同学不久前跟我说Kimi是他见过最聪明的AI(他没有翻墙经历)而我本人最近到处碰见Kimi打广告也比较烦,我就整理了一些测试题目来看看Kimi实际上怎么样,结果看来,Kimi只有诗歌创作方面有优势(得益于中文本土模型?喝油们可以测测ChatGLM怎么样)在其他方面就表现的比较中庸。不过大家应该注意到了这次测试更侧重数学与逻辑,而一些语言模型又恰好不太擅长这些,所以这次测试并不能代表语言模型的全部性能,希望喝油们以自己的实际体验为准