前言
在上一篇
已經介紹了可見性緩衝處理三角形ID的部分。這裡簡單補充一下我最近對於這個問題加深的理解。
實際上方案中提到的可見性緩衝,它的第一步可以理解成是更輕量級的GBuffer;項目GBuffer在深度比較之後還要逐一通過像素著色器寫入像素級的幾個緩衝區數據,可見性緩衝在這一步僅寫入了物體ID和三角形的ID——而後續可以通過一些優化方式來避免逐像素寫入GBuffer,這樣就釋放出了性能空間。

配合上次的這張圖,其中圖1(Visibility)的顏色全部代表的是將ID以顏色方式展示的結果,左邊是逐物體,右邊是逐三角形。
而可變著色率,基於識別出這些物體的邊緣,第一步能想到的就是在邊緣處保證採樣精度,而在物體內部可以減少一些採樣點,通過插值來近似。並且,結合上篇文章中的微小三角形數據壓縮方案,即使不犧牲採樣也已經有了性能上的提升(在處理微小三角形時)。
後續的一些處理,原作者在下面幾個篇章中也給出了講解,包括簡單的提了一下半透明渲染的問題。 本文還是以翻譯原文PPT頁及解說稿為主,打星號的部分則是我個人的補充。
1 網格池——MESH POOL

下一個課題是從三角形ID獲取頂點和索引。為實現這一點,你需要把所有網格數據存儲到一個巨大的buffer中,而不是分別獨立存儲。

存儲一個巨大的、可控的頂點池或許是一個好主意。實際上,在去年的演講中,HypeHype已經提供了一個更優的減少頂點和索引數據調用切換,以節省CPU性能開銷的方案。
*HypeHype這篇分享我去簡單看了一下,這裡大概就是用了一個可重用內存的數組作為對象池。原文不長,主要是聚焦在移動端渲染框架的。
對象池內存複用演示
這裡截取了2023那篇分享中的圖來展示這個方案的思路,其核心思路就是複用內存數組中的空間,避免內存空間的切換。通過維護一個類型數組(Typed array of objects)和一個可重用池(Freelist for slot reuse)來共同實現這樣一個數據池,這樣傳入GPU時始終都是同類型的連續內存,便於後續的並行計算。
這個方案的一個可能問題是(無法處理)頂點動畫。儘管單像素對應三個頂點,及其模型矩陣變換的開銷相對都是微小的,但一旦有複雜的動畫,開銷就會爆炸。

(對於頂點動畫)你可以需要運行一個pre-pass來存儲計算出的頂點位置。基於你的渲染方式,內存的開銷可能會非常讓人痛苦。不過要麼你要付出內存開銷,要麼就要犧牲性能,兩者只能選其一。
*因為固定的頂點只需要緩存一次之後就可以反覆快速查詢,在很多buffer裡是不用更新的;但可變的頂點就必須一直更新,作者的方案是分配單獨的計算pass和單獨的存儲空間。
*我個人理解,這個方案主要也是處理靜態物體,動態物體可以單獨通過一個pass來執行。
2 導數——DERIVATIVES
*導數是微積分上的概念,用來描述函數在某一點的變化趨勢,也被稱為微商。但不是所有函數都能求導。
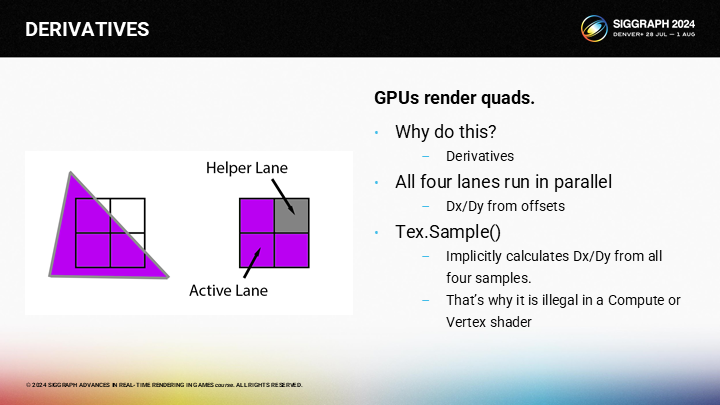
In the earlier discussion, you might have wondered why GPUs are restricted to 2x2 quads, and the reason is derivatives. Any time that you perform a texture sample, the GPU is approximating the partial derivative of the UV by using the 4 samples. That’s why they are called “helper” lanes…they help the active lanes compute partial derivatives.
在之前的論述中,你可能會好奇為什麼GPU要有2X2的quad的限制——其中的原因是要計算導數。每當你進行一次紋理採樣,GPU是基於4個採樣點來估計UV上局部的變化率。這是為什麼它們被稱為“輔助”通道的原因——輔助的其實是局部的導數計算。
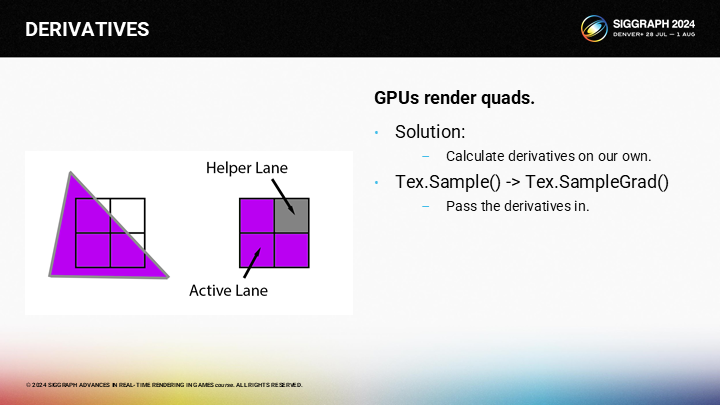
我們將自己計算這些導數,並使用SampleGrad()函數來替代Sample()。

為計算UV的導數,我們需要的第一步是計算屏幕空間X和Y相關的重心(barycentric)的偏導數(partial derivative)。
*之後作者提到了自己先寫了一個錯誤的版本,然後被James McLaren和Stephen Hill聯繫並糾正了。圖中可能看不清代碼,如果有興趣可以去下載下來看看。

當我們得到了重心的偏導數,我們就可以(通過圖中的代碼)計算頂點的三個參數的偏導數。

理論上,最好的組織導數的方式是類似圖中的Derived_Float2的結構。對任何在紋理採樣的關鍵路徑上計算插值的表達式,都需要使用這一結構並在整個計算過程傳遞導數參數——對於任意乘、除或其它操作你都需要應用鏈式法則(chain rule)。
*鏈式法則:又稱複合函數求導法則,是微積分中的一項基本求導法則。它指出,複合函數的導數將是構成複合的有限個函數在相應點的導數的乘積。

因為我們需要修改代碼(如圖)。對於原始的代碼“uv = baseUv * scale”,我們需要替換成對應的導函數版本。之後在調用SampleGrad()函數時我們需要傳入解析導數。

But if you are using material graphs, be prepared for a bit of an adventure, as you’ll have to change your code generator to maintain derivatives and perform a bunch of conversion between derivative and non-derivative nodes.
不過如果你使用了一個材質圖,情況可能會比較複雜,因為你需要修改你的shader代碼生成器來考慮導數的影響,並在可導和不可導的節點之間進行一些轉換。

作為替代我們可以使用一個描述表面(surface description)的API,例如MDL或OSL。兩個表面描述語言都可以從MaterialX生成並幫助你計算導數。MDL是NVIDIA的圖形語言,而OSL來自Sony Imageworks。兩者都是可行的選項,不過對我來說打破平衡的(tie-breaker)點是MDL包含了HLSL的支持,而OSL則沒有。
*MaterialX是一個開源的圖形化材質編輯工具。
*HLSL是High Level Shader Language 的縮寫,是由微軟擁有及開發的一種著色器語言 。

因而這就是我目前採用的管線。從USD到MaterialX,到MDL,最後到HLSL。雖然聽起來中間的工作很多,但實際上比起實現一整個材質編輯器來說其實工作量不算多。MDL也包含了一些額外的好用的特性(圖中提到的)。
*這裡USD是Universal Scene Description的縮寫,是有皮克斯開發的一種通用場景描述方式,被包括NVIDIA在內的很多大廠採用。
3 重構畫面——RECONSTRUCTION
*前面一節提到的問題可能過於抽象不好理解,但這一節又回到了很多圖示的部分。

有很多方式能生成我們(可變採樣率)的初始採樣點。第一種方式是使用棋盤式的方案。

第二中方式是使用1/4的採樣率,在半精度的一個格子中採樣一個點。
*前2種幾乎就是之前主流的超採樣到4K以上的方式。

第三種方案是採用隨機分佈的方式,在需要更多細節的地方通過偏移採樣位置的方式來獲得更多采樣點。

最後一種則是逐像素採樣。

其中關鍵的一個trick就是執行精確的邊緣預測。如果你採用實例ID、深度、幾何法線,你就能得到一個很好的邊緣檢測結果。
*屏幕空間邊緣檢測其實廣泛應用於渲染中,包括不限於實現卡通渲染的勾邊效果(的其中一種方案)。

對於任意位置的圖像重構,我們可以切割相鄰的區域至4份(如圖),並從各區域選擇一個像素。(順時針執行,以距離為權重)
*下面的部分展示了從一個區域選擇目標像素格的算法。
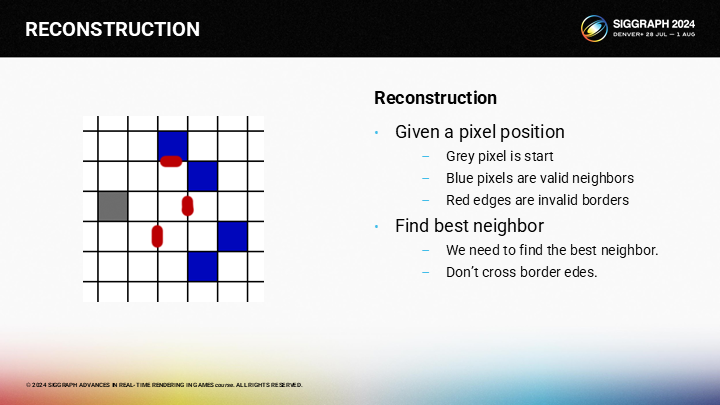
作為一個示例,假設我們想找到圖中灰色像素的相鄰區域。其中藍色的像素是有效的相鄰像素集合,而紅色則是圖像的邊緣。
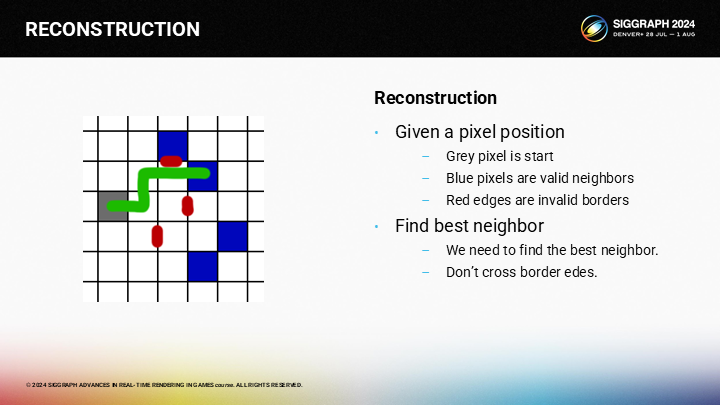
最優的相鄰像素可以被如圖的路徑所找到。
*這裡原文展示的寫法有點倒果為因,其實算法還是比較清晰的,後面馬上就會介紹到了。
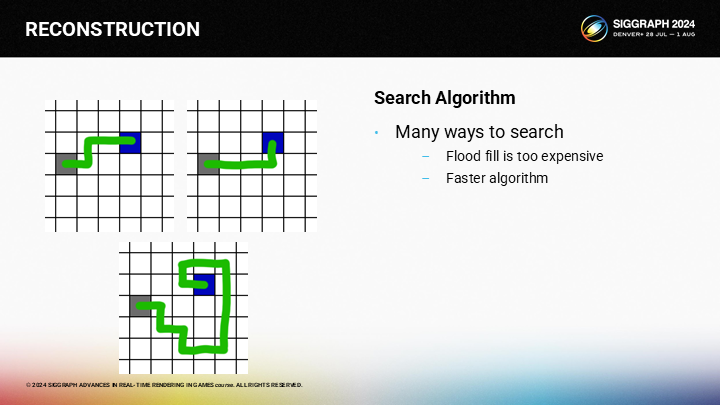
但如何更快的執行計算過程?對於給定的起止點,方法有不止一種,而用氾濫填充(flood fill)的方式會太慢。
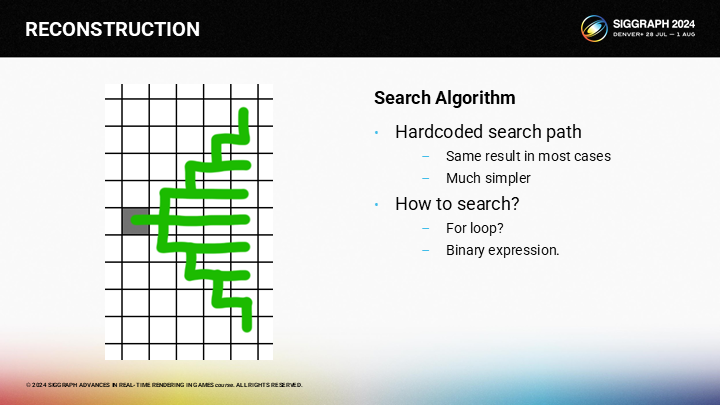
作為一種優化方案,我們可以按預設的查找路徑執行。理論上這可能會錯過一些有效像素(因為某些“繞路”方式並沒有全部覆蓋),不過如果一個像素需要90度旋轉才能到達,它大概率也不是一個好的候選(因為已經在邊緣之後了)。
由於查找的方式顯然是一重for循環,我們可以將它優化成一個二進制表達式(binary expression)。
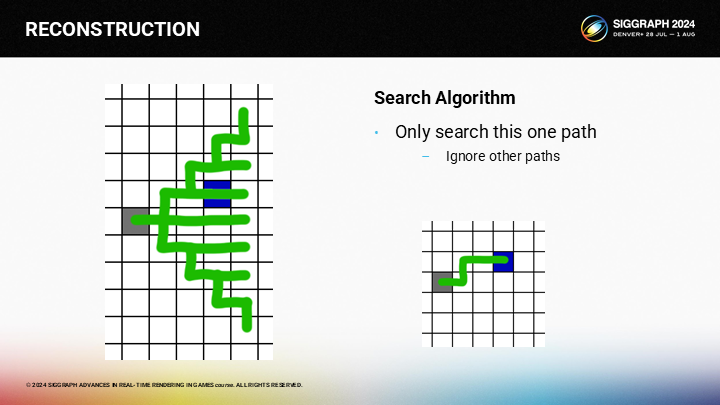
因為對於從灰色格作為給定的查找起點,我們就能得出圖中所示的唯一路徑。其中有三條規則。

首先,路徑上不應有其它有效像素。例如圖中,如果路徑上還有粉色的像素,則粉色就會成為備選結果,而不是藍色像素。
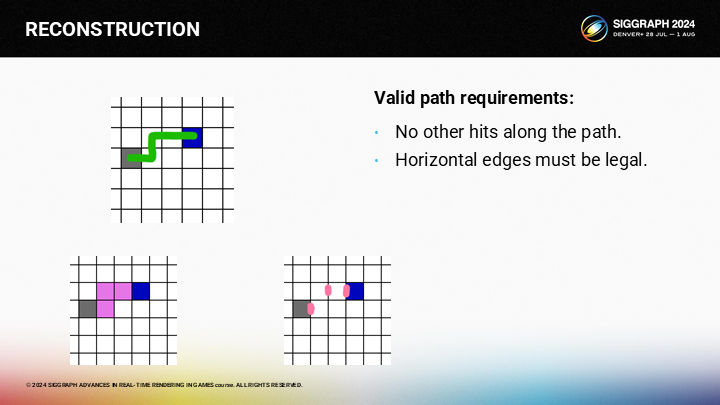
其次,不能跨越任何水平的邊緣。
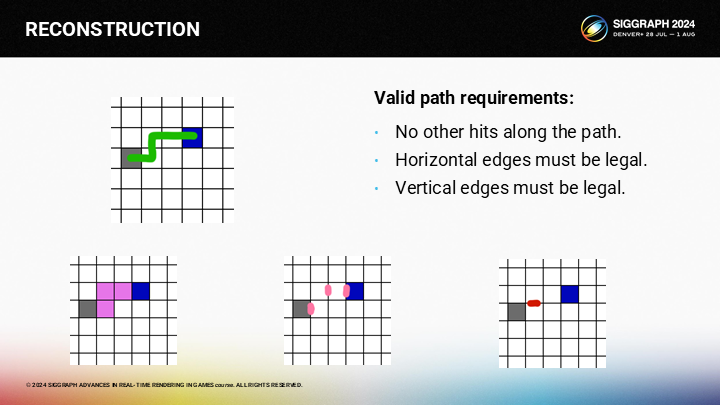
第三點,路徑上也不應跨越任何垂直的邊緣。

(由於可能性是確定的)最好的計算方式是一個布爾表達式,我們不需要for循環。

And the great thing about booleans is that we can pack them into uints. Since our search radius is only 4 pixels, we can search for 24 pixels at a time with 4 bits of pad on each side.
布爾值的一個極大優勢是可以被打包(pack 這裡是數據壓縮上的概念)進uints類型。由於我們的查找半徑是4像素,這使我們可以通過一個4字節的參數空間同時查找24個像素。

在對所有位置計算完這些巨量的布爾值表達式後,我們在每個維度上都有一個從-4到+4的結果,以及一個代表“未命中像素”的特定結果。四方向的結果可以被pack進一個32位int中。
由於比我預期的要慢一些,因此優化這個pass是我後續的目標之一。

為了完整展示這個算法過程,首先,我們選擇了一些稀疏的樣本並進行渲染。

之後我們需要檢測垂直的邊緣。(圖中綠色)

以及水平的邊緣。(圖中紅色)

此時,我們可以基於之前的最優4個相鄰像素結果來做插值,並不會跨過邊緣。有少數像素無法找到一個有效的命中結果,圖中以紅色像素標出了。(主要是邊緣很密的區域,以及右側黑色區域中的部分像素)。

之後我們可以應用TAA,並且我們已經修改了TAA算法,例如我們可以丟棄當前幀的無效像素。(就採用上一幀的值,並且由於常規的TAA自帶半像素抖動機制,因此不會出現一直無效的像素)

同時,完整的可變著色率結合TAA使用時,會在光線變化時存在一些問題。這是由於用來計算的相鄰顏色段在當前幀和上一幀之間是不一致的,這會導致光照突然閃爍的問題。
這是應用TAA的其中一個你需要反覆微調參數的問題。不過1x、2x和4x採樣率本身都是可靠的。
*現在已經有了很多更智能的超採樣方式,例如大家熟悉的DLSS、FSR、TSR等。不考慮其中機器學習的部分,其它部分的思想都可以從這個案例中去理解,只是各自有著不同的採樣模式及像素填充方式。
*一定程度上也可以解釋為什麼開了DLSS就會關閉TAA,因為在現代遊戲中起到了類似的職能。雖然原教旨的TAA不負責超採樣,但因為只有這裡有多幀緩衝,因此基於分幀的算法往往也都會在TAA的基礎上加。
4 性能——PERFORMANCE
*原文這裡展示了兩個例子,考慮到篇幅這裡只展示其中一個。
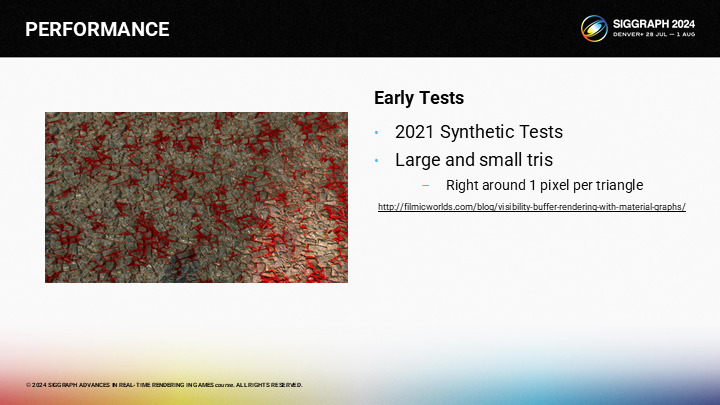
*這個例子是作者幾年前做的一個測試用例,其中通過圖形編程及曲面細分的方式來控制三角形的大小。
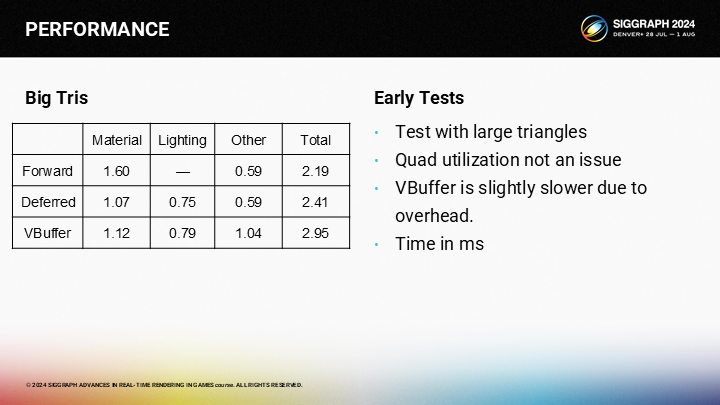
*可以看到對於大三角形,其實VBuffer是沒有優勢的。
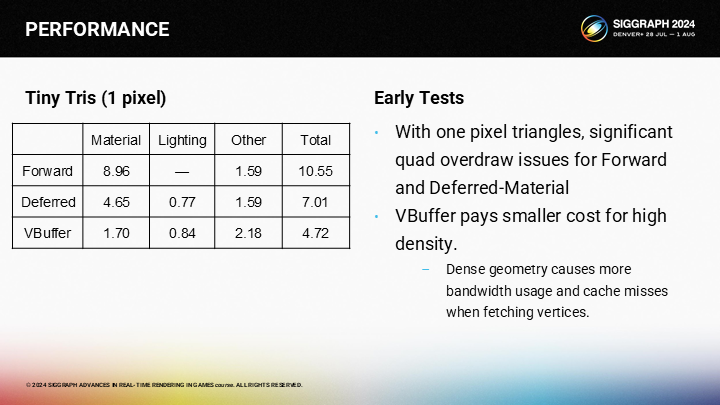
*對於1像素三角形,VBuffer方案有明顯優勢。(由於Quad Overdraw的問題,上篇中已經介紹過了)

*這張圖展示了微小三角形與大三角形在不同渲染管線中的速度差距。
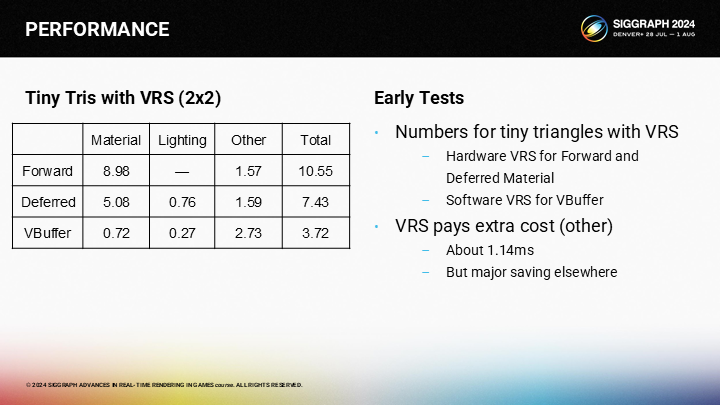
*作為參照作者還給出了2X2尺寸的微小三角形的性能比對。

*最終以前向渲染作為基準的總開銷對比圖,雖然VBuffer方案沒有達到理想中的.25倍開銷,但仍然帶來了客觀的性能提升。並且作者還提到了,如果延遲渲染結合VRS,其實會比不開的時候還更慢一點。
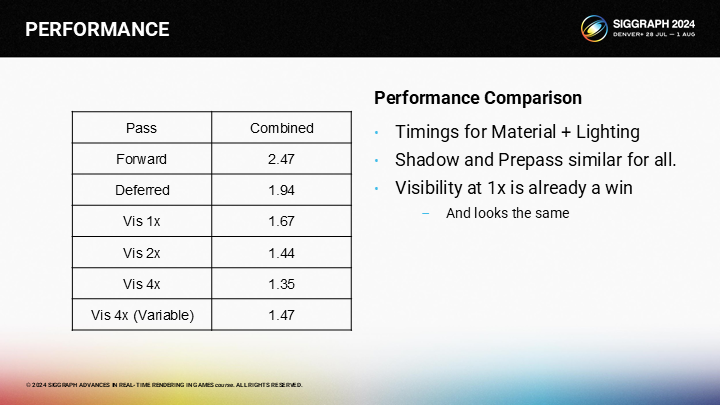
*這裡再補充例子2中的一個結果對比,其中包含結合了不同倍率VRS後的一些性能情況(包括可變分辨率著色)。當然評估結果也要考慮4X的質量肯定不如2X之類的因素。
5 順序無關透明渲染——OIT(Order Independent Transparency)
*如果稍微瞭解遊戲渲染或看過我之前文章的應該知道,雖然很多畫面精度是通過不透明渲染體現的,但要做透明渲染那又是完全另外一回事了。
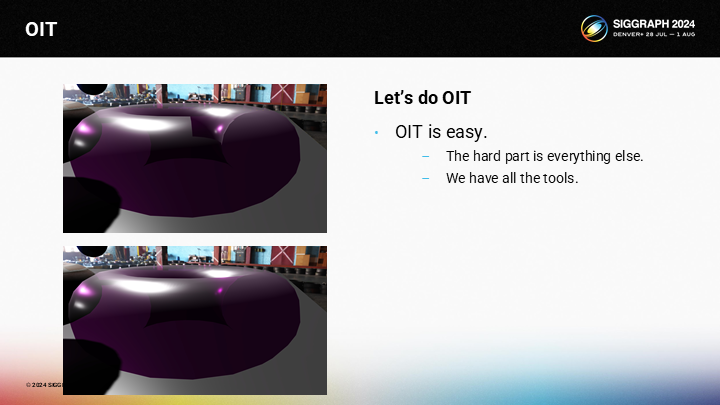
圖中展示了一個常見的OIT渲染的問題——通過一個環狀體演示。在上圖中,你可以看到由於錯誤的混合順序導致的問題,以及下圖是對它的解決。實際上我們的VBuffer方案結合VRS,要添加OIT特性是容易的——難的是其它所有相關的部分。
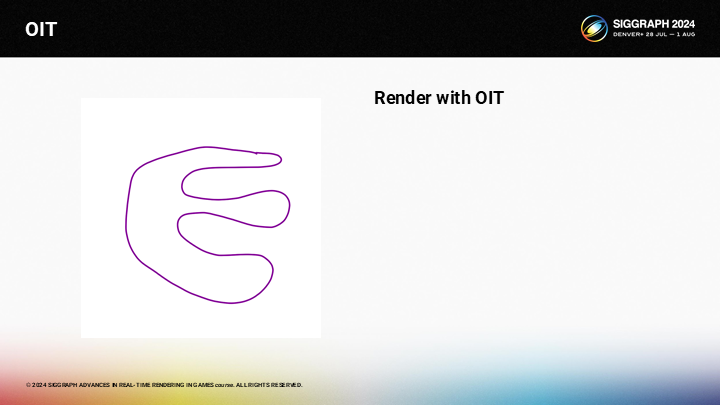
圖中展示了一個簡單的半透明網格,如何以OIT的方式對其渲染呢?

If you want accurate ordering of the layers, the typical method would be to render the mesh while storing all the samples in a per-pixel linked list, which seems to have replaced depth peeling. Note that I’m focused on accurate representations, so moment-based OIT isn’t an option here.
如果你希望對其精確地分層,傳統的方式是渲染網格的同時將所有的採樣存儲到一個逐像素的鏈表中,作為深度剝離方案的一種替代。需要注意這裡我聚焦在精確的表達上,因此基於矩(概率論中的一個概念)的OIT就不是一個可選項。

不幸的是,採樣數可能是無限的。因此在某些相機角度你可能得到無限的採樣數,這意味著不可控的內存佔用與性能開銷。

通常,我們會硬性設置採樣數的上限。相比於存儲所有層的像素信息,我們會存儲所有層的儘可能多的像素。對於其它像素,我們基於相鄰像素做插值。
這一方案以犧牲一些質量為代價,能獲得可控的內存和性能表現。

然而,假設我們在左側的一層有另一個有效像素,但由於它只能從上下2個採樣點中插值,它就會和後續從6個採樣點來插值的點看起來很不同。
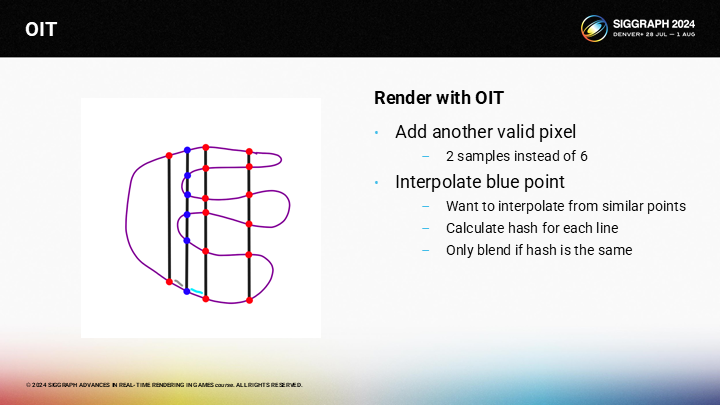
這在我們想要插值計算圖中藍色部分的像素時會時一個問題,因為右側有6個採樣點,而左側只有2個採樣點。我們採用的trick是對每一個像素計算一個哈希值,並只從有相同哈希的相鄰像素進行插值計算。(*左側沒有就只對右側計算插值,基於像素距離等信息)
*這裡哈希值的含義就是結構體中的一“行”。
*圖中展示了很多半透明的猴子雕像混合的結果。

我們可以賦予每個Mesh一個唯一的ID,並對(跨了多個Mesh)同像素採樣的哈希值做遞增。

Here is the actual shader code. You can look at it later. Every mesh has a 16 bit id. For every sample we add the value of 1 plus the hash shifted 8 bits to the left. The bottom 8 bits store the count, the middle 16 bits will store a unique hash, and the top 8 bits are to prevent overflow.
圖中展示了shader代碼。每一個Mesh有一個16bit的ID。對每一次採樣我們都將ID的哈希值中左移8位的部分增加1,再加到之前同像素的OitCount上(從代碼可以看出)。數據基數的8bit部分存儲數量,而中段的16bit存儲唯一的哈希值,高位的8bit用來防止數據溢出。
*計算哈希值時,同網格算出來的值是一樣的,但通過這一算法在不同採樣深度增加了。這裡雖然命名是count,實際應該就是前面提到的用來比對的哈希結果。

從渲染後的哈希(像素)中,我們在硬性的數量限制範圍內選擇儘量多的採樣數。隨著層的數量增加,像素會變得越來越稀疏。

一旦確認了待繪製的像素,我們通過碰撞分配(bump allocate)的方式來為所有像素分配可見性採樣數據。
*Bump allocate是一種特定的內存分配方式,在分配定長內存時是高效的。

The actual passes for OIT are very similar to the passed for opaque geometry. We sort the samples by material, and perform an execute indirect for each material which stores the GBuffer data. Then we have a lighting pass, just like the opaque pass. For edges detection, we can use the hash instead of the depth, normal, and instance id. And the reconstruction chooses the a neighbor from each of the 4 regions.
OIT的實際繪製pass很類似不透明幾何體的pass。我們基於材質對樣本排序,並對每個材質執行間接渲染以得到GBuffer數據。之後我們執行光照pass,就像不透明的pass一樣。對於邊緣檢測,我們可以使用上述的哈希值來替代深度、法線和示例ID。之後仍然從相鄰4個區域中來重構需要插值的像素。

這就是最終的算法。光柵化哈希值,選擇符合硬性數量標準的像素,寫入樣本ID,排序像素,計算混合顏色,計算插值,最後應用TAA。

作為時間比較,OIT pass略慢於前向渲染方式的半透明繪製。話雖如此,OIT pass有著明顯更低的精度需求(可以通過緩衝區來超採樣,而前向渲染則沒有緩衝區)。
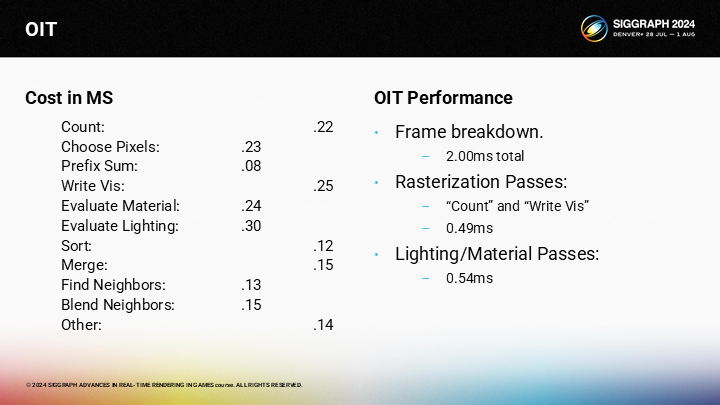
其中主要存在的問題是pass數量過多。單獨看每個雖然都不慢,但是累加起來還是可觀的開銷。

其中也有一些有趣的優勢。例如內存消耗是可控的,它的規模只和材質與光照的複雜度有關。
它的主要缺點還是在有不低的性能開銷。
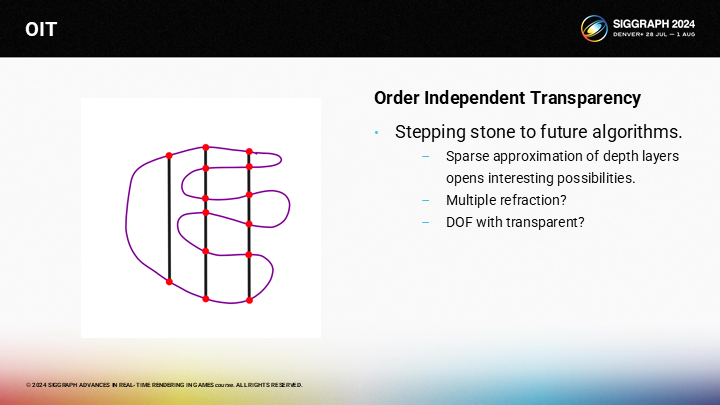
這一方案真正的勝利之處在於,它是其它一些未解決問題的潛在基石。有算法存儲了深度信息,它潛在地能通過raymarching計算折射。我們也可能以此來解決一些難問題——例如半透明物體的景深(DOF)效果。
If we can solve these problems like refraction and depth of field in a generic way it should be possible to create a reasonable approximation that “just works”. And my hope is that sparse OIT can be a step in that direction.
*這裡作者主要表達了這項OIT技術能實現比“just works”更精確更好的實時渲染效果。這個詞真是一個過不去的梗了。
結語
其實超採樣之前一直是一個離我有點距離的課題,雖然知道基本原理,但細節一直沒太去了解。這次得益與這篇分享,又去看了FSR和DLSS的一些資料,總的來說認知提升了一些。
其實很多渲染技術的源發動力都是人們對於更高畫質的一種“貪婪”。當年《刺客教條 大革命》雖然作為產品是災難級的,但其提出的網格集群化方案卻又是超前了時代的;最近類似的情況可能又出現在《魔物獵人 荒野》中,眼看著RE引擎從做《生化危機2 RE》時的“高性能優等生”,變成了很多新的複雜特性都不盡如人意的情況。
當然,拋開模型LOD顯示BUG這種明顯但是好改的問題,真正難弄的可能是大地形渲染策略、高清材質方案、高清毛髮方案等等一系列技術上強度的之後容易遇到技術瓶頸的問題。說實話從上週末的試玩體驗來說,很多方面確實都實現得不如虛幻5;而如果無法以較高的分辨率來渲染,那麼一定程度上的可變著色率結合超採樣就是唯一的選擇了。
最後是一些資料鏈接:
Variable Rate Shading with Visibility Buffer Rendering的PPTX地址
微軟的 Variable Rate Shading 介紹
AMD的 AMD FidelityFX Variable Shading 介紹
HypeHype Mobile Rendering Architecture 的PPTX地址
介紹Moment-Based OIT的一篇知乎