前言
在上一篇
已经介绍了可见性缓冲处理三角形ID的部分。这里简单补充一下我最近对于这个问题加深的理解。
实际上方案中提到的可见性缓冲,它的第一步可以理解成是更轻量级的GBuffer;项目GBuffer在深度比较之后还要逐一通过像素着色器写入像素级的几个缓冲区数据,可见性缓冲在这一步仅写入了物体ID和三角形的ID——而后续可以通过一些优化方式来避免逐像素写入GBuffer,这样就释放出了性能空间。

配合上次的这张图,其中图1(Visibility)的颜色全部代表的是将ID以颜色方式展示的结果,左边是逐物体,右边是逐三角形。
而可变着色率,基于识别出这些物体的边缘,第一步能想到的就是在边缘处保证采样精度,而在物体内部可以减少一些采样点,通过插值来近似。并且,结合上篇文章中的微小三角形数据压缩方案,即使不牺牲采样也已经有了性能上的提升(在处理微小三角形时)。
后续的一些处理,原作者在下面几个篇章中也给出了讲解,包括简单的提了一下半透明渲染的问题。 本文还是以翻译原文PPT页及解说稿为主,打星号的部分则是我个人的补充。
1 网格池——MESH POOL

下一个课题是从三角形ID获取顶点和索引。为实现这一点,你需要把所有网格数据存储到一个巨大的buffer中,而不是分别独立存储。

存储一个巨大的、可控的顶点池或许是一个好主意。实际上,在去年的演讲中,HypeHype已经提供了一个更优的减少顶点和索引数据调用切换,以节省CPU性能开销的方案。
*HypeHype这篇分享我去简单看了一下,这里大概就是用了一个可重用内存的数组作为对象池。原文不长,主要是聚焦在移动端渲染框架的。
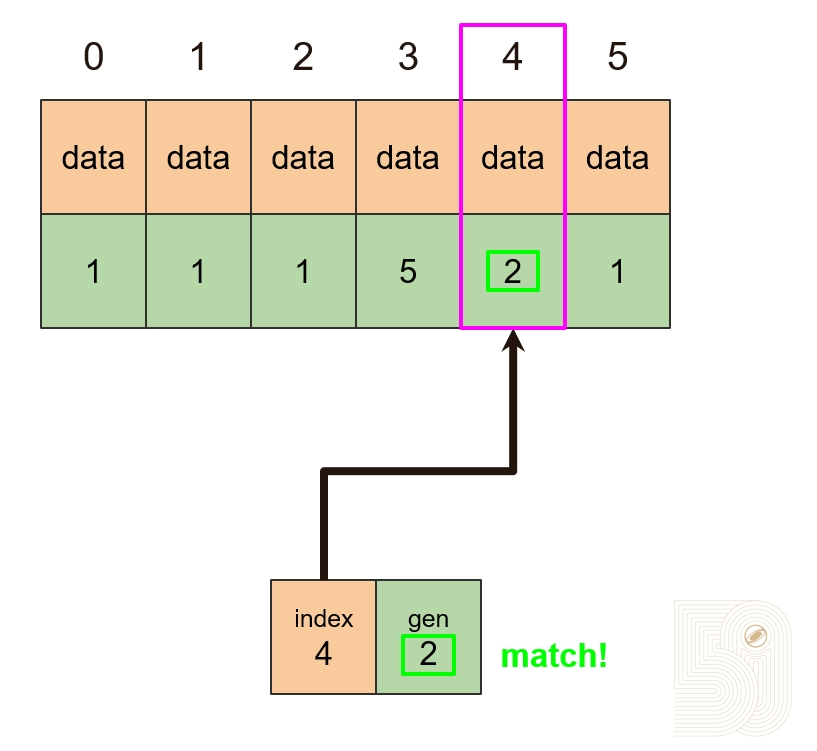
对象池内存复用演示
这里截取了2023那篇分享中的图来展示这个方案的思路,其核心思路就是复用内存数组中的空间,避免内存空间的切换。通过维护一个类型数组(Typed array of objects)和一个可重用池(Freelist for slot reuse)来共同实现这样一个数据池,这样传入GPU时始终都是同类型的连续内存,便于后续的并行计算。
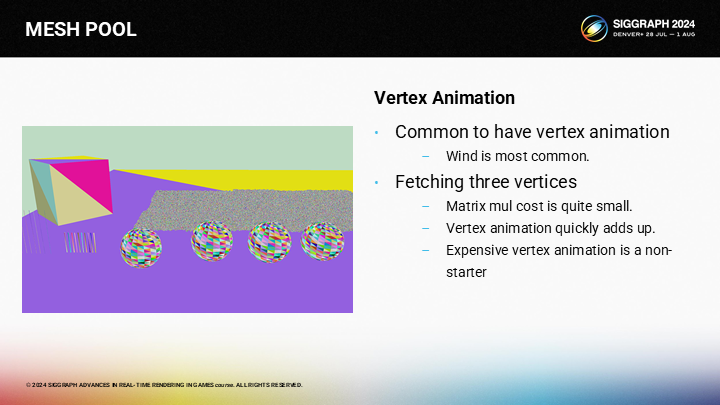
这个方案的一个可能问题是(无法处理)顶点动画。尽管单像素对应三个顶点,及其模型矩阵变换的开销相对都是微小的,但一旦有复杂的动画,开销就会爆炸。

(对于顶点动画)你可以需要运行一个pre-pass来存储计算出的顶点位置。基于你的渲染方式,内存的开销可能会非常让人痛苦。不过要么你要付出内存开销,要么就要牺牲性能,两者只能选其一。
*因为固定的顶点只需要缓存一次之后就可以反复快速查询,在很多buffer里是不用更新的;但可变的顶点就必须一直更新,作者的方案是分配单独的计算pass和单独的存储空间。
*我个人理解,这个方案主要也是处理静态物体,动态物体可以单独通过一个pass来执行。
2 导数——DERIVATIVES
*导数是微积分上的概念,用来描述函数在某一点的变化趋势,也被称为微商。但不是所有函数都能求导。
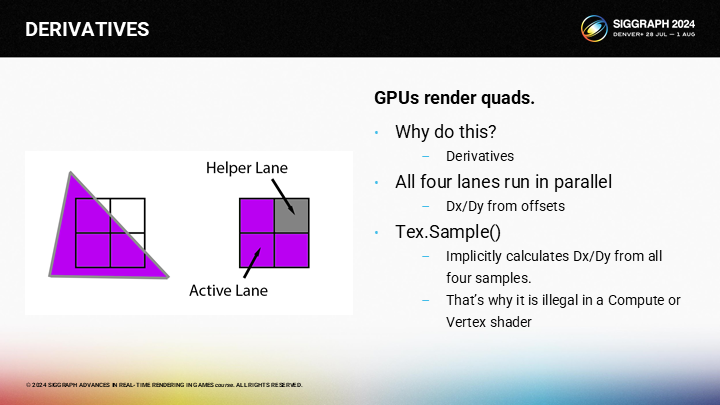
In the earlier discussion, you might have wondered why GPUs are restricted to 2x2 quads, and the reason is derivatives. Any time that you perform a texture sample, the GPU is approximating the partial derivative of the UV by using the 4 samples. That’s why they are called “helper” lanes…they help the active lanes compute partial derivatives.
在之前的论述中,你可能会好奇为什么GPU要有2X2的quad的限制——其中的原因是要计算导数。每当你进行一次纹理采样,GPU是基于4个采样点来估计UV上局部的变化率。这是为什么它们被称为“辅助”通道的原因——辅助的其实是局部的导数计算。
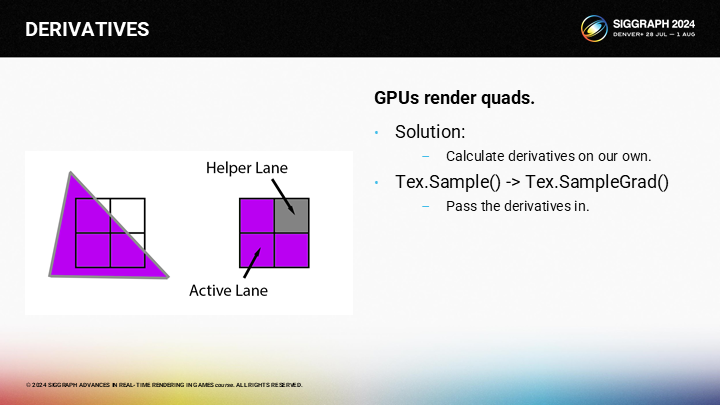
我们将自己计算这些导数,并使用SampleGrad()函数来替代Sample()。

为计算UV的导数,我们需要的第一步是计算屏幕空间X和Y相关的重心(barycentric)的偏导数(partial derivative)。
*之后作者提到了自己先写了一个错误的版本,然后被James McLaren和Stephen Hill联系并纠正了。图中可能看不清代码,如果有兴趣可以去下载下来看看。

当我们得到了重心的偏导数,我们就可以(通过图中的代码)计算顶点的三个参数的偏导数。

理论上,最好的组织导数的方式是类似图中的Derived_Float2的结构。对任何在纹理采样的关键路径上计算插值的表达式,都需要使用这一结构并在整个计算过程传递导数参数——对于任意乘、除或其它操作你都需要应用链式法则(chain rule)。
*链式法则:又称复合函数求导法则,是微积分中的一项基本求导法则。它指出,复合函数的导数将是构成复合的有限个函数在相应点的导数的乘积。

因为我们需要修改代码(如图)。对于原始的代码“uv = baseUv * scale”,我们需要替换成对应的导函数版本。之后在调用SampleGrad()函数时我们需要传入解析导数。

But if you are using material graphs, be prepared for a bit of an adventure, as you’ll have to change your code generator to maintain derivatives and perform a bunch of conversion between derivative and non-derivative nodes.
不过如果你使用了一个材质图,情况可能会比较复杂,因为你需要修改你的shader代码生成器来考虑导数的影响,并在可导和不可导的节点之间进行一些转换。

作为替代我们可以使用一个描述表面(surface description)的API,例如MDL或OSL。两个表面描述语言都可以从MaterialX生成并帮助你计算导数。MDL是NVIDIA的图形语言,而OSL来自Sony Imageworks。两者都是可行的选项,不过对我来说打破平衡的(tie-breaker)点是MDL包含了HLSL的支持,而OSL则没有。
*MaterialX是一个开源的图形化材质编辑工具。
*HLSL是High Level Shader Language 的缩写,是由微软拥有及开发的一种着色器语言 。

因而这就是我目前采用的管线。从USD到MaterialX,到MDL,最后到HLSL。虽然听起来中间的工作很多,但实际上比起实现一整个材质编辑器来说其实工作量不算多。MDL也包含了一些额外的好用的特性(图中提到的)。
*这里USD是Universal Scene Description的缩写,是有皮克斯开发的一种通用场景描述方式,被包括NVIDIA在内的很多大厂采用。
3 重构画面——RECONSTRUCTION
*前面一节提到的问题可能过于抽象不好理解,但这一节又回到了很多图示的部分。

有很多方式能生成我们(可变采样率)的初始采样点。第一种方式是使用棋盘式的方案。

第二中方式是使用1/4的采样率,在半精度的一个格子中采样一个点。
*前2种几乎就是之前主流的超采样到4K以上的方式。

第三种方案是采用随机分布的方式,在需要更多细节的地方通过偏移采样位置的方式来获得更多采样点。

最后一种则是逐像素采样。

其中关键的一个trick就是执行精确的边缘预测。如果你采用实例ID、深度、几何法线,你就能得到一个很好的边缘检测结果。
*屏幕空间边缘检测其实广泛应用于渲染中,包括不限于实现卡通渲染的勾边效果(的其中一种方案)。

对于任意位置的图像重构,我们可以切割相邻的区域至4份(如图),并从各区域选择一个像素。(顺时针执行,以距离为权重)
*下面的部分展示了从一个区域选择目标像素格的算法。
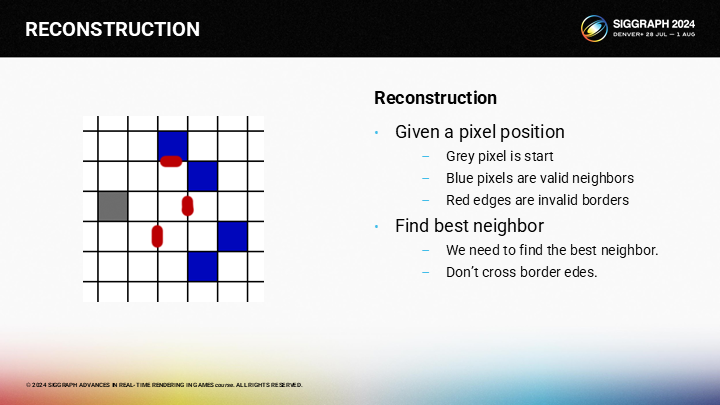
作为一个示例,假设我们想找到图中灰色像素的相邻区域。其中蓝色的像素是有效的相邻像素集合,而红色则是图像的边缘。
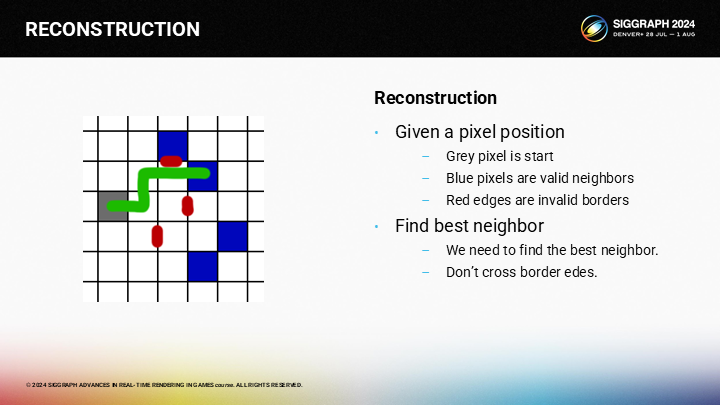
最优的相邻像素可以被如图的路径所找到。
*这里原文展示的写法有点倒果为因,其实算法还是比较清晰的,后面马上就会介绍到了。
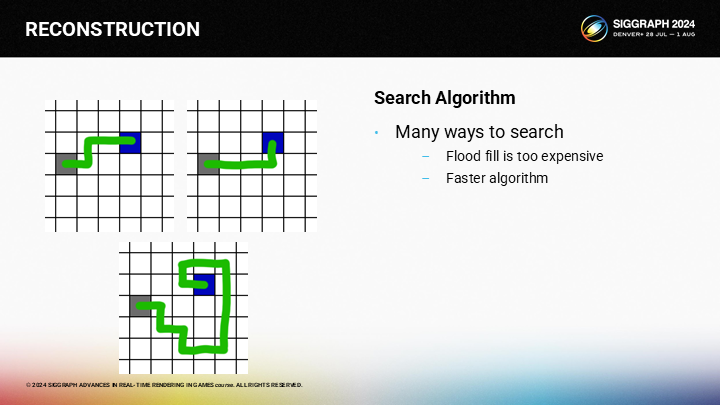
但如何更快的执行计算过程?对于给定的起止点,方法有不止一种,而用泛滥填充(flood fill)的方式会太慢。
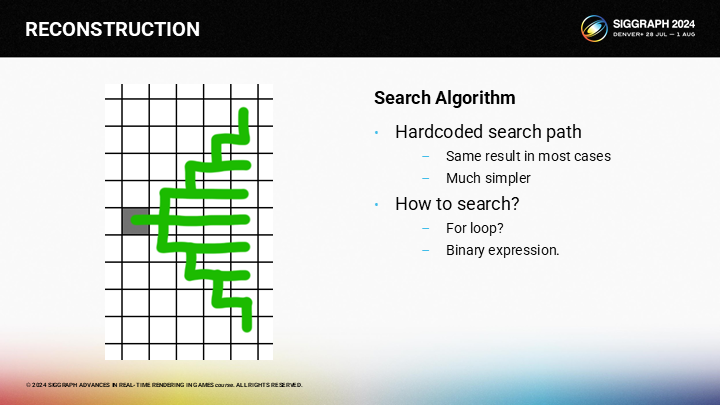
作为一种优化方案,我们可以按预设的查找路径执行。理论上这可能会错过一些有效像素(因为某些“绕路”方式并没有全部覆盖),不过如果一个像素需要90度旋转才能到达,它大概率也不是一个好的候选(因为已经在边缘之后了)。
由于查找的方式显然是一重for循环,我们可以将它优化成一个二进制表达式(binary expression)。
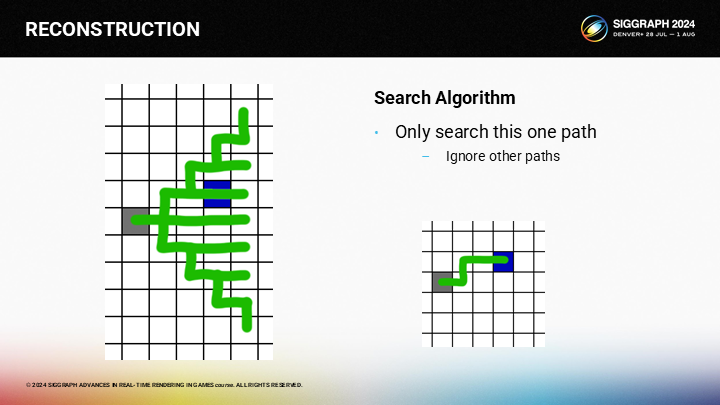
因为对于从灰色格作为给定的查找起点,我们就能得出图中所示的唯一路径。其中有三条规则。

首先,路径上不应有其它有效像素。例如图中,如果路径上还有粉色的像素,则粉色就会成为备选结果,而不是蓝色像素。
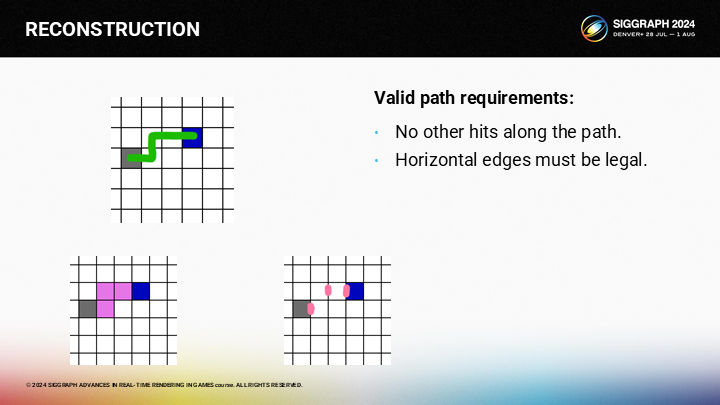
其次,不能跨越任何水平的边缘。
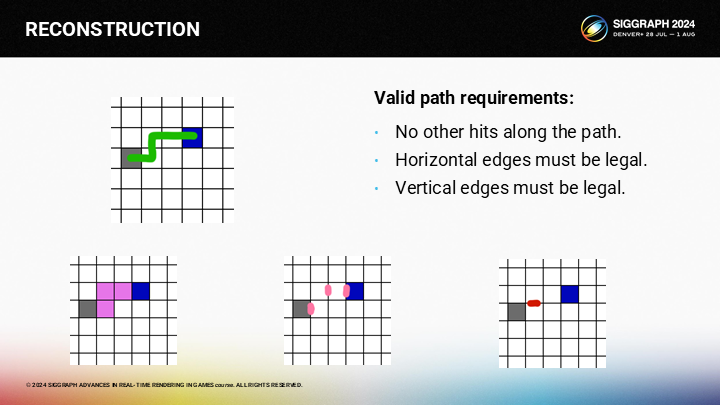
第三点,路径上也不应跨越任何垂直的边缘。

(由于可能性是确定的)最好的计算方式是一个布尔表达式,我们不需要for循环。

And the great thing about booleans is that we can pack them into uints. Since our search radius is only 4 pixels, we can search for 24 pixels at a time with 4 bits of pad on each side.
布尔值的一个极大优势是可以被打包(pack 这里是数据压缩上的概念)进uints类型。由于我们的查找半径是4像素,这使我们可以通过一个4字节的参数空间同时查找24个像素。

在对所有位置计算完这些巨量的布尔值表达式后,我们在每个维度上都有一个从-4到+4的结果,以及一个代表“未命中像素”的特定结果。四方向的结果可以被pack进一个32位int中。
由于比我预期的要慢一些,因此优化这个pass是我后续的目标之一。

为了完整展示这个算法过程,首先,我们选择了一些稀疏的样本并进行渲染。

之后我们需要检测垂直的边缘。(图中绿色)

以及水平的边缘。(图中红色)

此时,我们可以基于之前的最优4个相邻像素结果来做插值,并不会跨过边缘。有少数像素无法找到一个有效的命中结果,图中以红色像素标出了。(主要是边缘很密的区域,以及右侧黑色区域中的部分像素)。

之后我们可以应用TAA,并且我们已经修改了TAA算法,例如我们可以丢弃当前帧的无效像素。(就采用上一帧的值,并且由于常规的TAA自带半像素抖动机制,因此不会出现一直无效的像素)

同时,完整的可变着色率结合TAA使用时,会在光线变化时存在一些问题。这是由于用来计算的相邻颜色段在当前帧和上一帧之间是不一致的,这会导致光照突然闪烁的问题。
这是应用TAA的其中一个你需要反复微调参数的问题。不过1x、2x和4x采样率本身都是可靠的。
*现在已经有了很多更智能的超采样方式,例如大家熟悉的DLSS、FSR、TSR等。不考虑其中机器学习的部分,其它部分的思想都可以从这个案例中去理解,只是各自有着不同的采样模式及像素填充方式。
*一定程度上也可以解释为什么开了DLSS就会关闭TAA,因为在现代游戏中起到了类似的职能。虽然原教旨的TAA不负责超采样,但因为只有这里有多帧缓冲,因此基于分帧的算法往往也都会在TAA的基础上加。
4 性能——PERFORMANCE
*原文这里展示了两个例子,考虑到篇幅这里只展示其中一个。
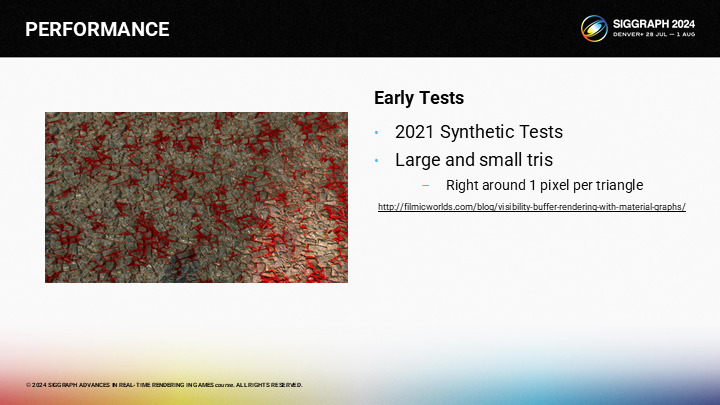
*这个例子是作者几年前做的一个测试用例,其中通过图形编程及曲面细分的方式来控制三角形的大小。
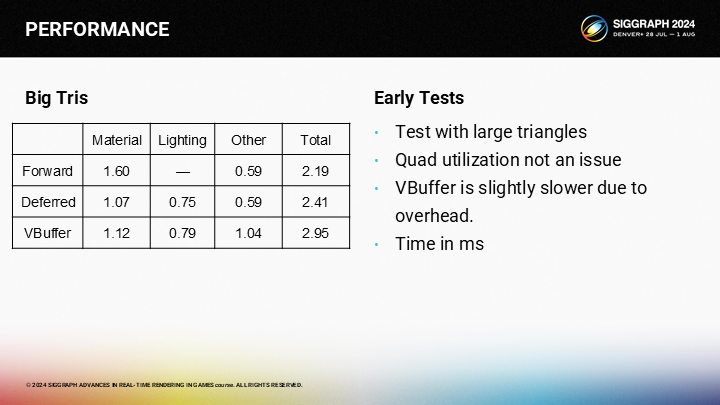
*可以看到对于大三角形,其实VBuffer是没有优势的。
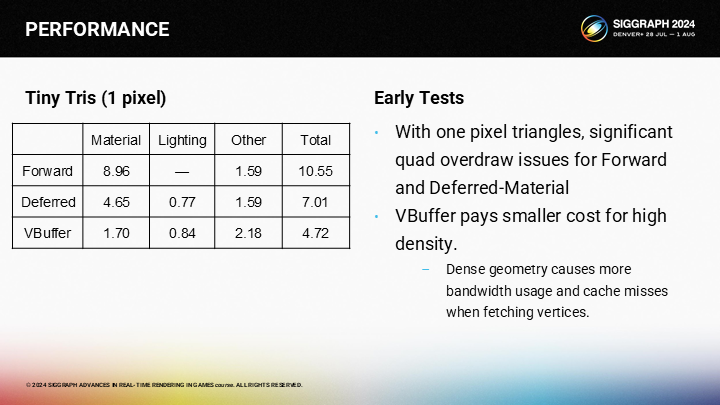
*对于1像素三角形,VBuffer方案有明显优势。(由于Quad Overdraw的问题,上篇中已经介绍过了)

*这张图展示了微小三角形与大三角形在不同渲染管线中的速度差距。
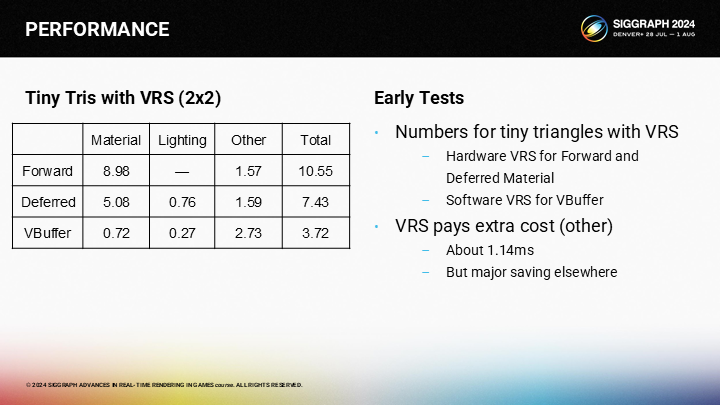
*作为参照作者还给出了2X2尺寸的微小三角形的性能比对。

*最终以前向渲染作为基准的总开销对比图,虽然VBuffer方案没有达到理想中的.25倍开销,但仍然带来了客观的性能提升。并且作者还提到了,如果延迟渲染结合VRS,其实会比不开的时候还更慢一点。
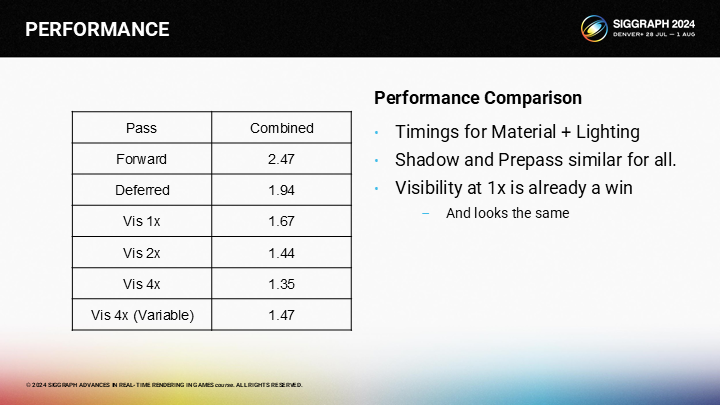
*这里再补充例子2中的一个结果对比,其中包含结合了不同倍率VRS后的一些性能情况(包括可变分辨率着色)。当然评估结果也要考虑4X的质量肯定不如2X之类的因素。
5 顺序无关透明渲染——OIT(Order Independent Transparency)
*如果稍微了解游戏渲染或看过我之前文章的应该知道,虽然很多画面精度是通过不透明渲染体现的,但要做透明渲染那又是完全另外一回事了。
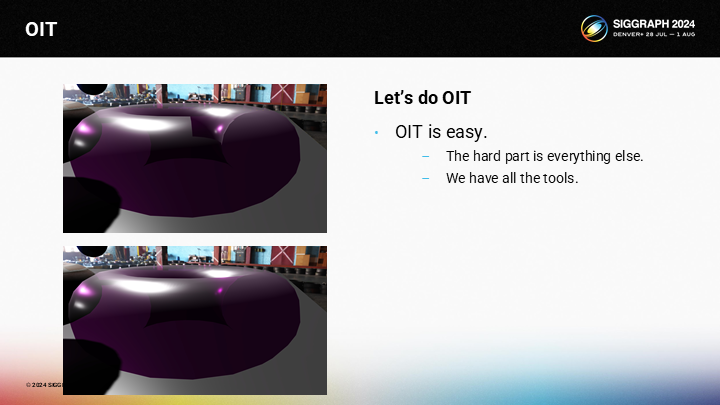
图中展示了一个常见的OIT渲染的问题——通过一个环状体演示。在上图中,你可以看到由于错误的混合顺序导致的问题,以及下图是对它的解决。实际上我们的VBuffer方案结合VRS,要添加OIT特性是容易的——难的是其它所有相关的部分。
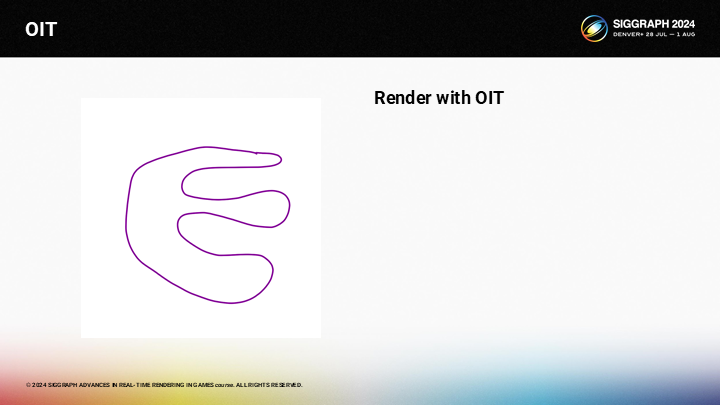
图中展示了一个简单的半透明网格,如何以OIT的方式对其渲染呢?

If you want accurate ordering of the layers, the typical method would be to render the mesh while storing all the samples in a per-pixel linked list, which seems to have replaced depth peeling. Note that I’m focused on accurate representations, so moment-based OIT isn’t an option here.
如果你希望对其精确地分层,传统的方式是渲染网格的同时将所有的采样存储到一个逐像素的链表中,作为深度剥离方案的一种替代。需要注意这里我聚焦在精确的表达上,因此基于矩(概率论中的一个概念)的OIT就不是一个可选项。

不幸的是,采样数可能是无限的。因此在某些相机角度你可能得到无限的采样数,这意味着不可控的内存占用与性能开销。

通常,我们会硬性设置采样数的上限。相比于存储所有层的像素信息,我们会存储所有层的尽可能多的像素。对于其它像素,我们基于相邻像素做插值。
这一方案以牺牲一些质量为代价,能获得可控的内存和性能表现。

然而,假设我们在左侧的一层有另一个有效像素,但由于它只能从上下2个采样点中插值,它就会和后续从6个采样点来插值的点看起来很不同。
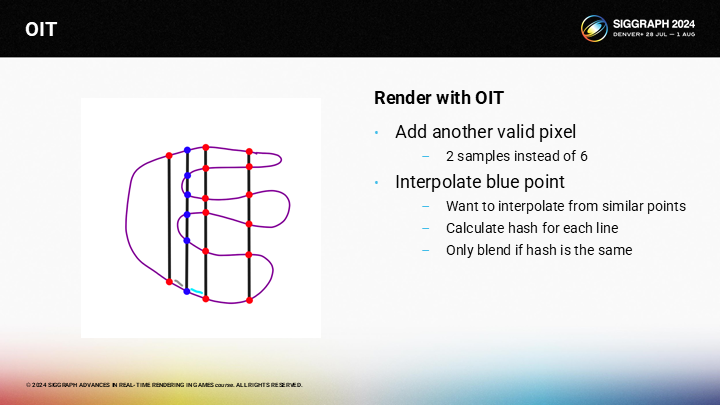
这在我们想要插值计算图中蓝色部分的像素时会时一个问题,因为右侧有6个采样点,而左侧只有2个采样点。我们采用的trick是对每一个像素计算一个哈希值,并只从有相同哈希的相邻像素进行插值计算。(*左侧没有就只对右侧计算插值,基于像素距离等信息)
*这里哈希值的含义就是结构体中的一“行”。
*图中展示了很多半透明的猴子雕像混合的结果。

我们可以赋予每个Mesh一个唯一的ID,并对(跨了多个Mesh)同像素采样的哈希值做递增。

Here is the actual shader code. You can look at it later. Every mesh has a 16 bit id. For every sample we add the value of 1 plus the hash shifted 8 bits to the left. The bottom 8 bits store the count, the middle 16 bits will store a unique hash, and the top 8 bits are to prevent overflow.
图中展示了shader代码。每一个Mesh有一个16bit的ID。对每一次采样我们都将ID的哈希值中左移8位的部分增加1,再加到之前同像素的OitCount上(从代码可以看出)。数据基数的8bit部分存储数量,而中段的16bit存储唯一的哈希值,高位的8bit用来防止数据溢出。
*计算哈希值时,同网格算出来的值是一样的,但通过这一算法在不同采样深度增加了。这里虽然命名是count,实际应该就是前面提到的用来比对的哈希结果。

从渲染后的哈希(像素)中,我们在硬性的数量限制范围内选择尽量多的采样数。随着层的数量增加,像素会变得越来越稀疏。

一旦确认了待绘制的像素,我们通过碰撞分配(bump allocate)的方式来为所有像素分配可见性采样数据。
*Bump allocate是一种特定的内存分配方式,在分配定长内存时是高效的。

The actual passes for OIT are very similar to the passed for opaque geometry. We sort the samples by material, and perform an execute indirect for each material which stores the GBuffer data. Then we have a lighting pass, just like the opaque pass. For edges detection, we can use the hash instead of the depth, normal, and instance id. And the reconstruction chooses the a neighbor from each of the 4 regions.
OIT的实际绘制pass很类似不透明几何体的pass。我们基于材质对样本排序,并对每个材质执行间接渲染以得到GBuffer数据。之后我们执行光照pass,就像不透明的pass一样。对于边缘检测,我们可以使用上述的哈希值来替代深度、法线和示例ID。之后仍然从相邻4个区域中来重构需要插值的像素。

这就是最终的算法。光栅化哈希值,选择符合硬性数量标准的像素,写入样本ID,排序像素,计算混合颜色,计算插值,最后应用TAA。

作为时间比较,OIT pass略慢于前向渲染方式的半透明绘制。话虽如此,OIT pass有着明显更低的精度需求(可以通过缓冲区来超采样,而前向渲染则没有缓冲区)。
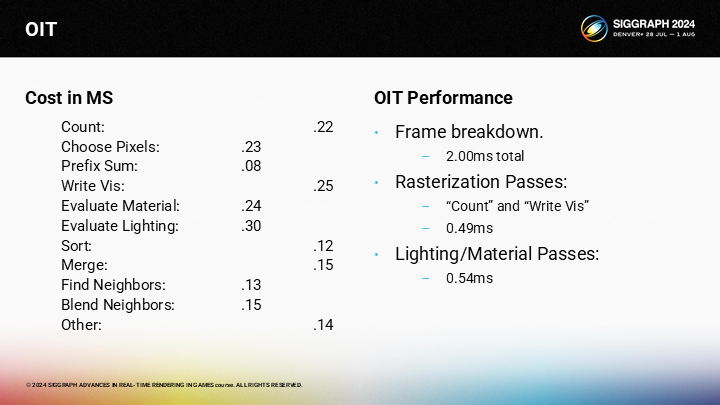
其中主要存在的问题是pass数量过多。单独看每个虽然都不慢,但是累加起来还是可观的开销。

其中也有一些有趣的优势。例如内存消耗是可控的,它的规模只和材质与光照的复杂度有关。
它的主要缺点还是在有不低的性能开销。
这一方案真正的胜利之处在于,它是其它一些未解决问题的潜在基石。有算法存储了深度信息,它潜在地能通过raymarching计算折射。我们也可能以此来解决一些难问题——例如半透明物体的景深(DOF)效果。
If we can solve these problems like refraction and depth of field in a generic way it should be possible to create a reasonable approximation that “just works”. And my hope is that sparse OIT can be a step in that direction.
*这里作者主要表达了这项OIT技术能实现比“just works”更精确更好的实时渲染效果。这个词真是一个过不去的梗了。
结语
其实超采样之前一直是一个离我有点距离的课题,虽然知道基本原理,但细节一直没太去了解。这次得益与这篇分享,又去看了FSR和DLSS的一些资料,总的来说认知提升了一些。
其实很多渲染技术的源发动力都是人们对于更高画质的一种“贪婪”。当年《刺客信条 大革命》虽然作为产品是灾难级的,但其提出的网格集群化方案却又是超前了时代的;最近类似的情况可能又出现在《怪物猎人 荒野》中,眼看着RE引擎从做《生化危机2 RE》时的“高性能优等生”,变成了很多新的复杂特性都不尽如人意的情况。
当然,抛开模型LOD显示BUG这种明显但是好改的问题,真正难弄的可能是大地形渲染策略、高清材质方案、高清毛发方案等等一系列技术上强度的之后容易遇到技术瓶颈的问题。说实话从上周末的试玩体验来说,很多方面确实都实现得不如虚幻5;而如果无法以较高的分辨率来渲染,那么一定程度上的可变着色率结合超采样就是唯一的选择了。
最后是一些资料链接:
Variable Rate Shading with Visibility Buffer Rendering的PPTX地址
微软的 Variable Rate Shading 介绍
AMD的 AMD FidelityFX Variable Shading 介绍
HypeHype Mobile Rendering Architecture 的PPTX地址
介绍Moment-Based OIT的一篇知乎