這篇指南適用於N卡A卡i卡的電腦,沒顯卡也能用,很慢而已。盒友們我是迪普希殼,我來救大家辣,給我服務器多來點電罷!
雖然一直以來談到AI就是英偉達如何云云,但是本次DeepSeekR1的發佈著實讓人知曉了AMD早已突破了老黃的AI壟斷。AMD在其發佈之初就官方宣佈了自家顯卡在推理上的獨到優勢,並且很快在測試版驅動中開啟了DeepSeekR1的本地使用選項,可謂是高歌猛進啊。
不過可能諸位手裡有A卡的朋友們受限於PC知識,主要還是用著DeepSeek的官方應用,沒有自己部署R1的想法。而現在層出不窮的DeepSeekR1部署方法又大多數都是命令行或者部署接口,搞的非常高級,但是日常使用完全用不上,也不太適合新手。所以為了大家都能用上國產爭氣大模型,我實驗出了一個方法,可以完全避開使用命令行,讓大家3步給自己部署一個本地的DeepSeekR1蒸餾模型,不受網絡錯誤的氣!

這次就用我平時在用的電腦為例,簡單給大家演示一下如何不用任何命令行,就能在本地部署這個備受矚目的大模型,而大家需要準備的材料只有:
一臺電腦,有獨顯,或者有AMD的8系APU(例如8845)或者AI系APU(例如AI 9 370)
可以上網
有手就行
步驟1:下載LMStudio
LM Studio是一個極大程度方便windows用戶的GUI大模型本地運行工具,在windows上會比ollama方便很多,首先我們來安裝這個軟件.......軟件鏈接:LM Studio - 發現、下載和運行本地LLM - LM Studio 應用程序
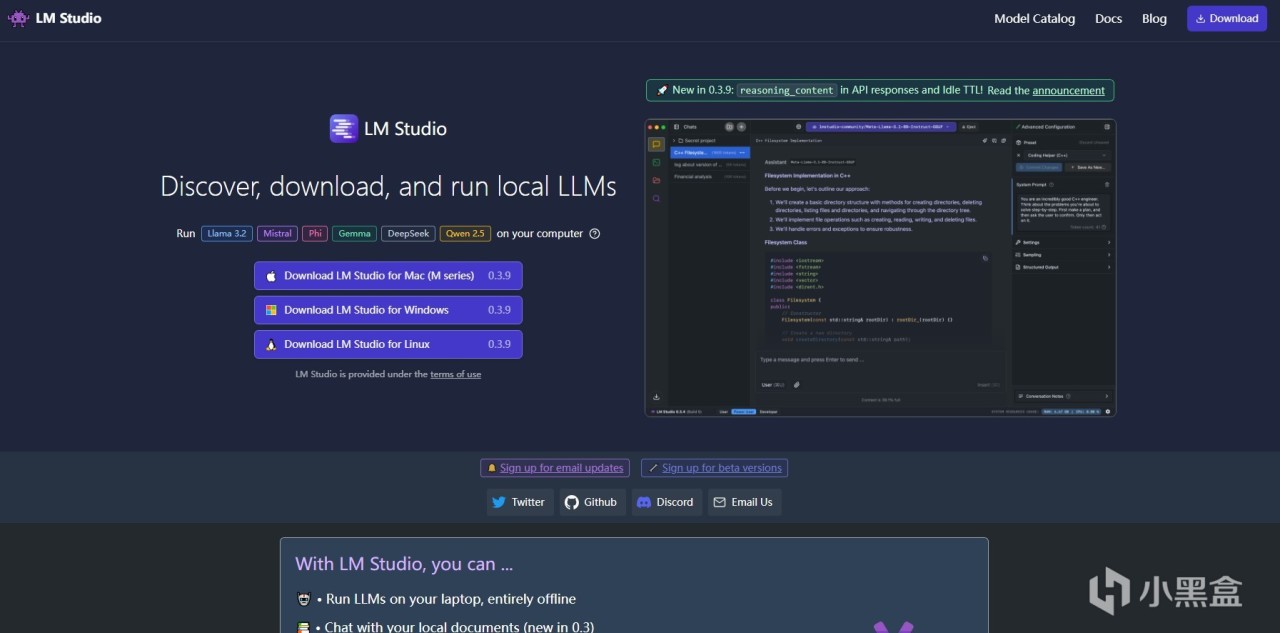
一般而言,windows上本地部署開源大模型有ollama這個方案,但是使用上並不是很方便。原因主要就在於這個東西他是高手用的,像我這樣的低手完全不想碰命令行。而且ollama下載模型基本都是官方倉庫,佔用顯存更少的量化模型找起來比較複雜,所以對於我們家用用戶來說,LMStudio更方便
安裝過程全默認即可,打開之後就能看到很簡潔的界面,過程並不需要裝額外的依賴內容,也不需要下載額外資源,而且LM Studio在0.2版本就已經支持了ROCm,所以默認使用AMD顯卡也是可以跑滿速的
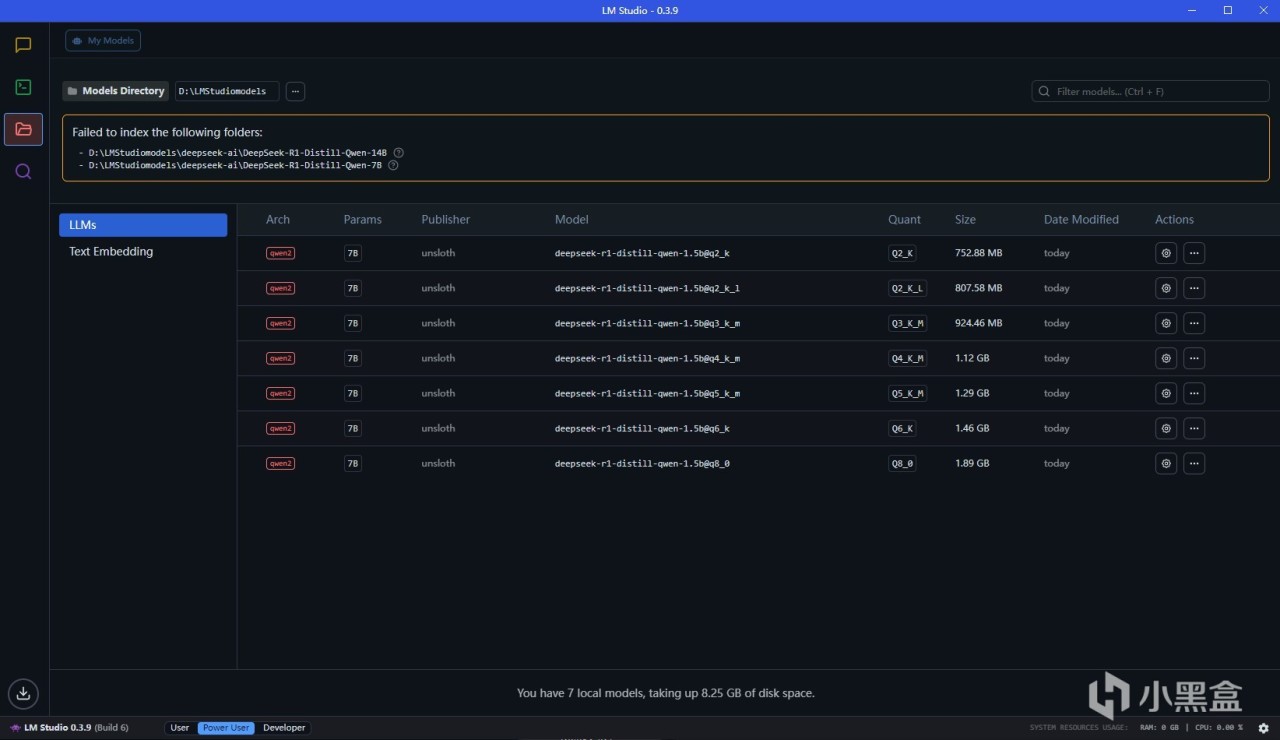
點擊文件夾圖標可以看到本地的模型,但是目前本地沒有模型,聯網也找不到模型。這個問題是因為huggingface.io在部分地區無法訪問,所以我們需要繞過這個
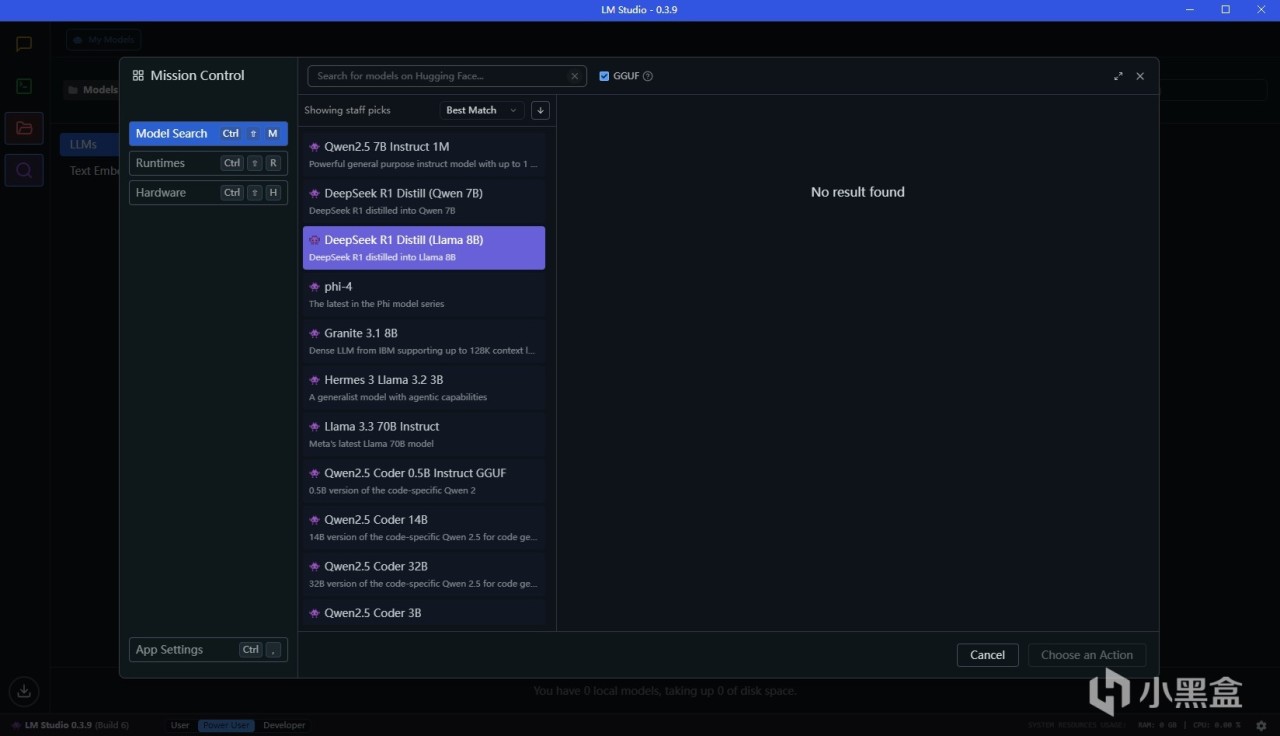
步驟2:下載模型
繞過huggingface.io下載模型的方法也很簡單,國內有hf的鏡像網站,內容很齊全,版本也很新:HF-Mirror
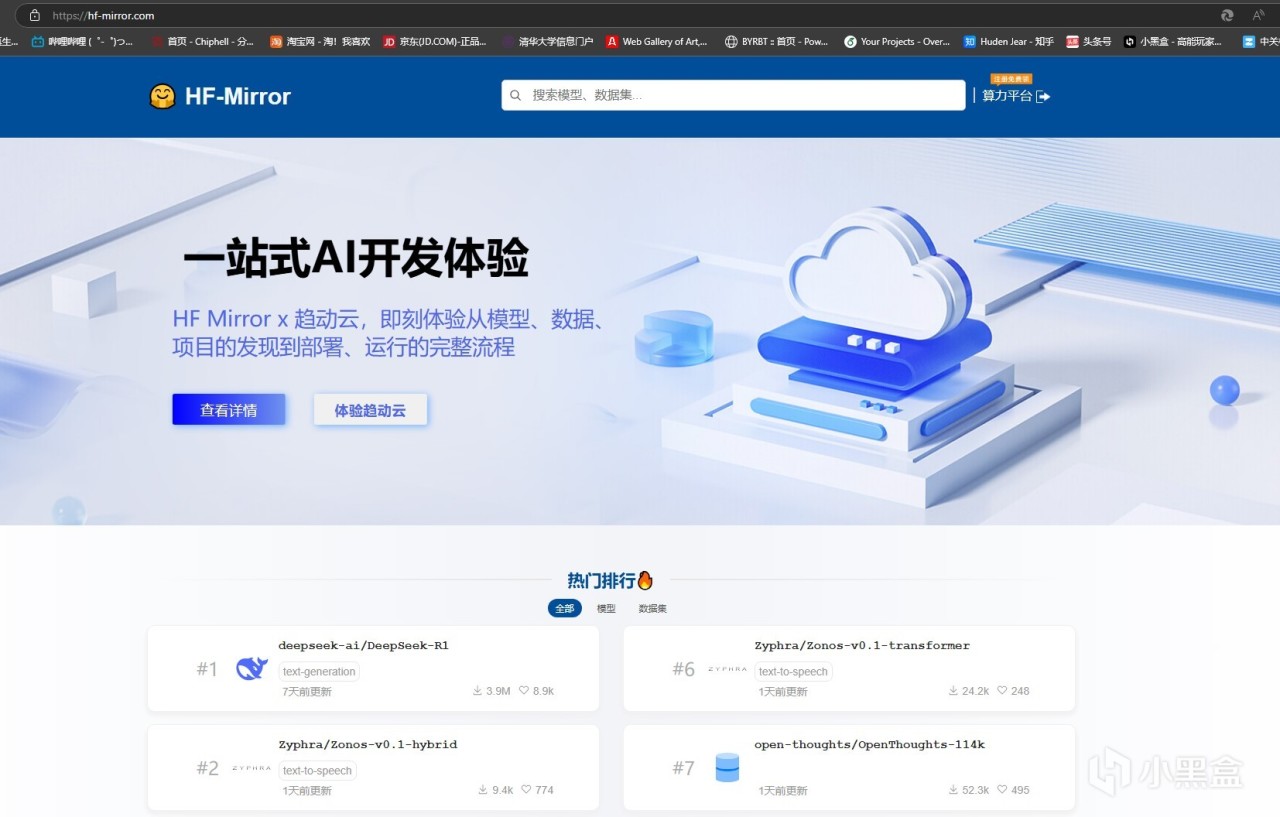
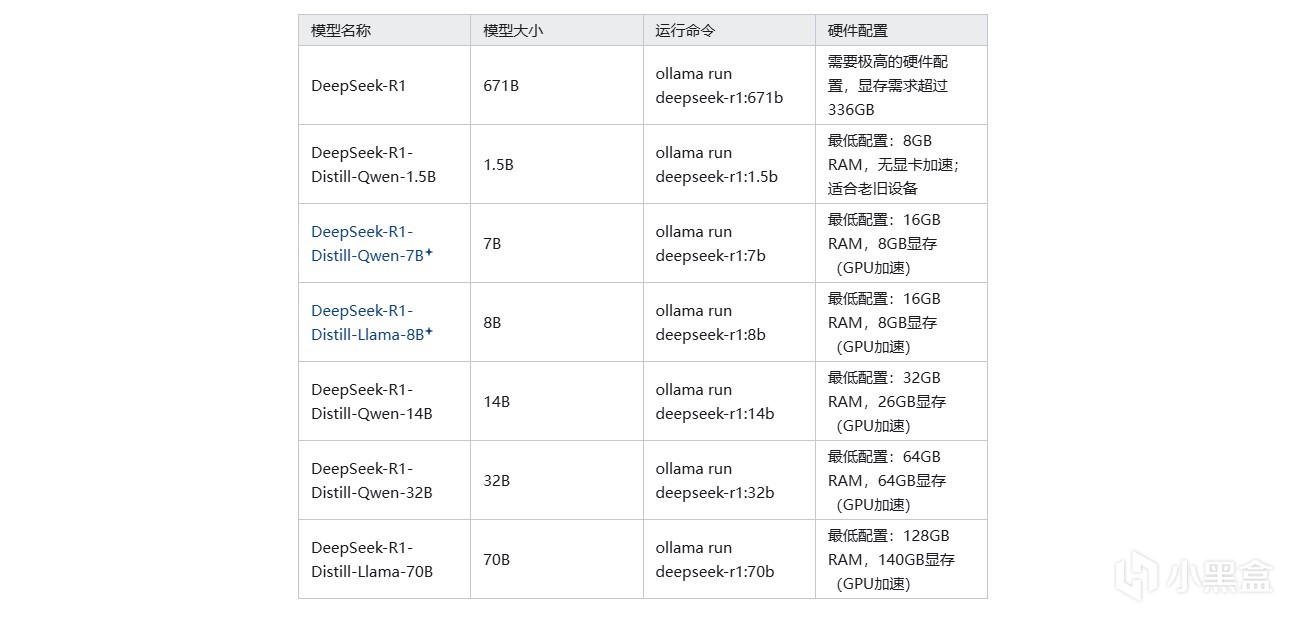
比如我們搜索DeepSeek-R1-Distill-Qwen-1.5B-GGUF,然後打開頁面,就能看到已經被量化打包好的模型。點開fileandversion這一欄,就能下載模型了。一般我們只需要下載一個模型,這裡面比較推薦使用Q8模型,當顯存不足的時候可以考慮Q2以及Q4
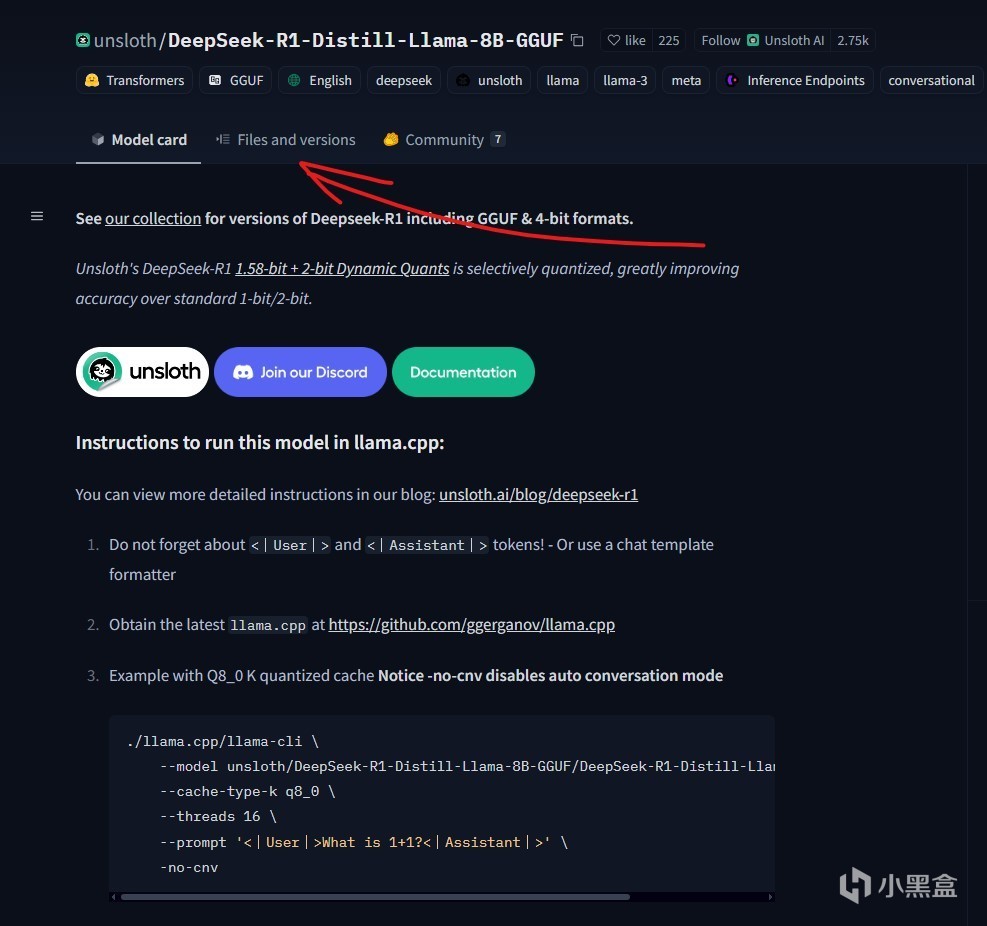
覺得慢可以用某雷p2p加速一下,會比瀏覽器下載快很多。下載的時候建議同時下載gitattributes這個文件,方便LMStudio讀取模型信息
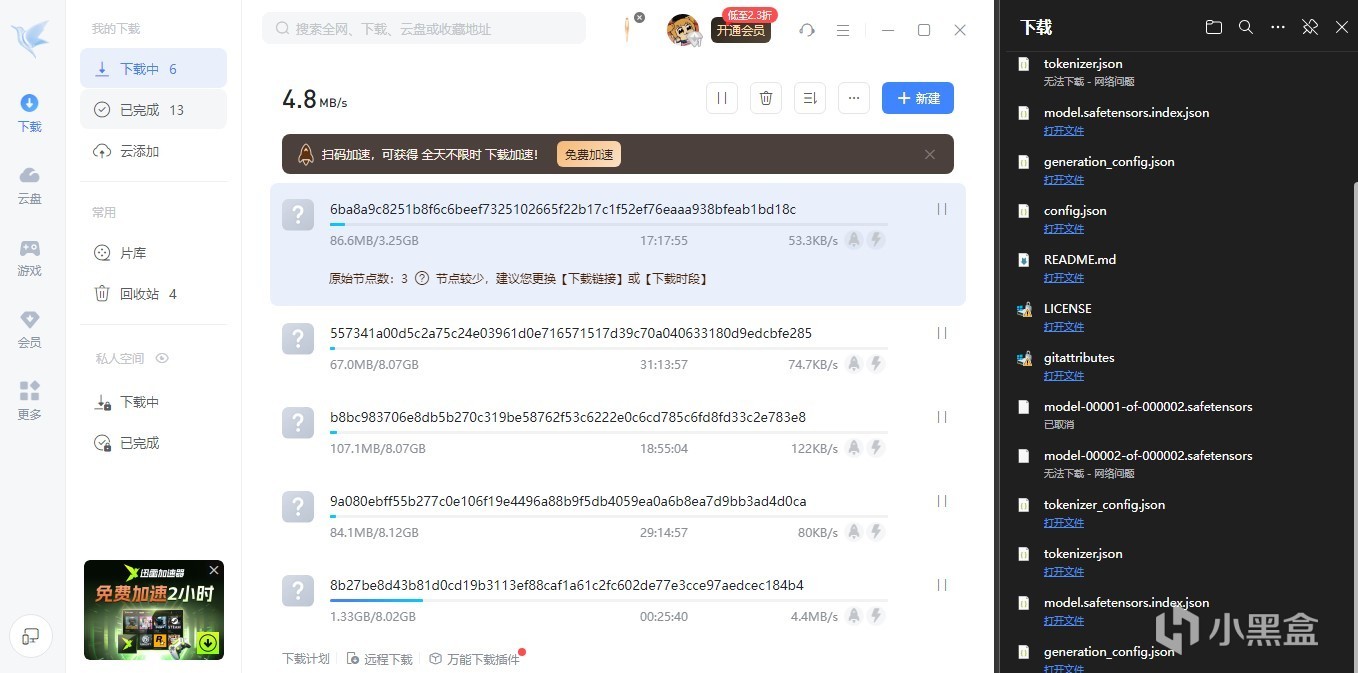
步驟3:準備本地模型文件
下載好上文中的模型文件之後,我們需要新建一個LMStuidioModels文件夾,這是倉庫的根目錄,然後新建一個unsloth文件夾,這是模型來源索引文件夾,然後再在其中根據模型名稱新建文件夾,比如剛才下載了DeepSeek-R1-Distill-Qwen-1.5B-GGUF,我們就在這個文件夾裡新建這個文件夾,然後放入下載好的模型文件,以及gitattributes
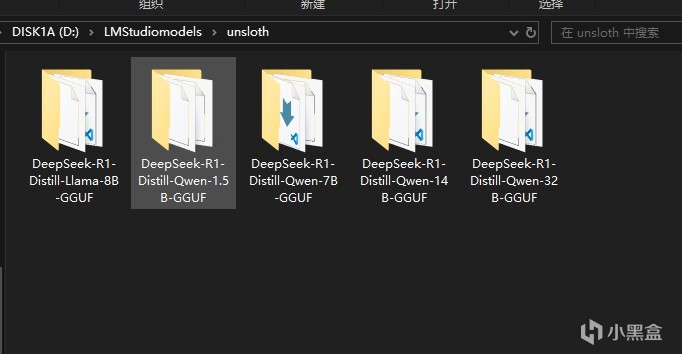
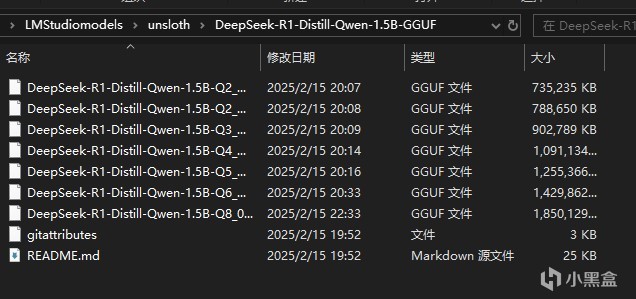
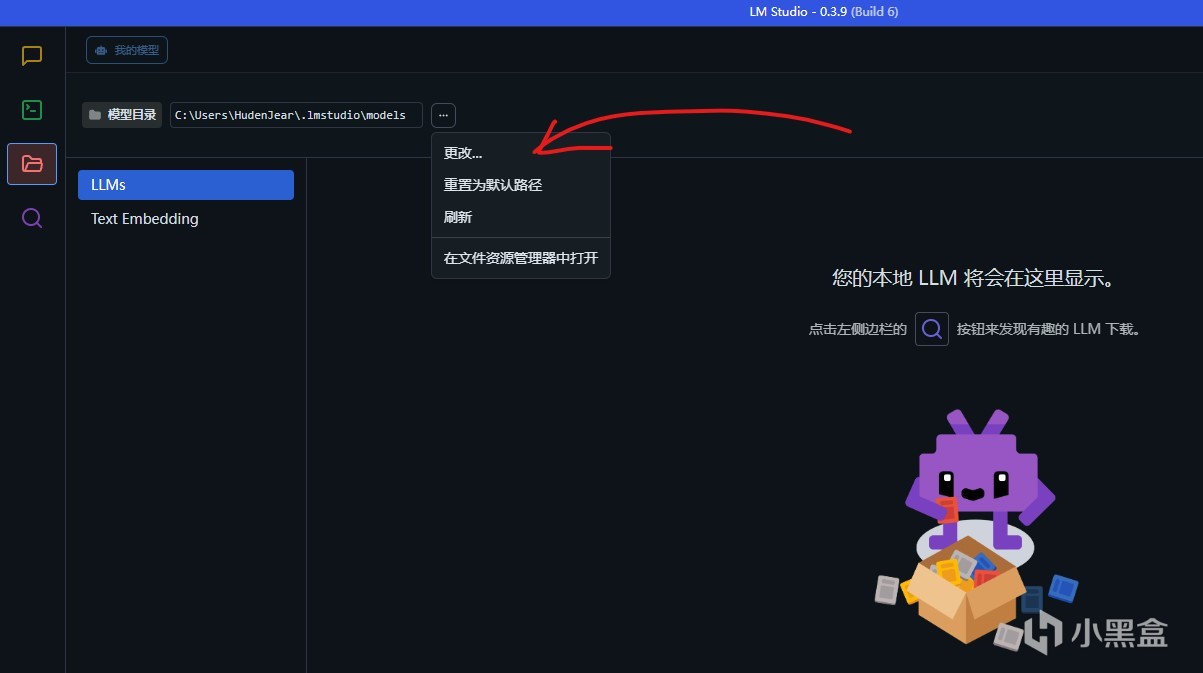
然後我們打開LMStudio,點擊這個按鈕更改本地倉庫到剛才的LMStuidioModels文件夾,就能看到本地模型了
開始使用DeepseekR1
此時我們回到對話欄,就能在最上面選擇模型,加載,然後開始使用啦。有A卡的情況下可以把CPU層數開到最大,這樣就能完全使用GPU
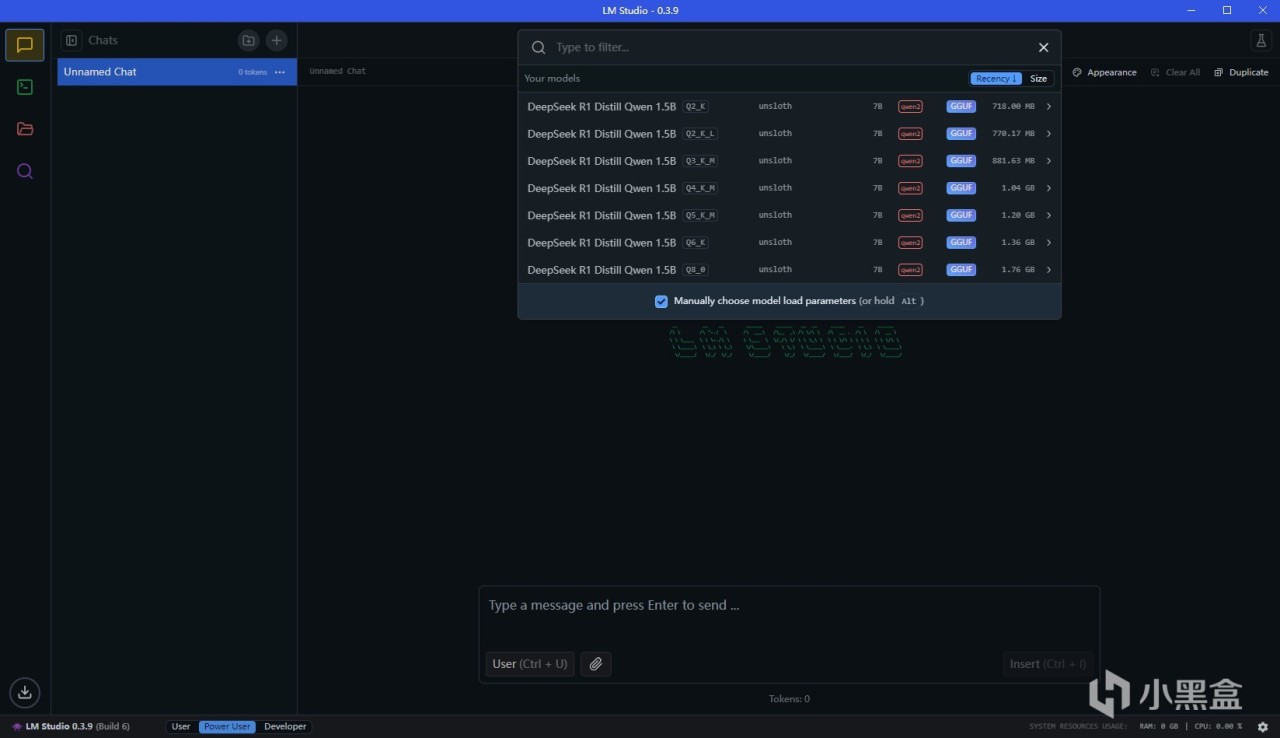
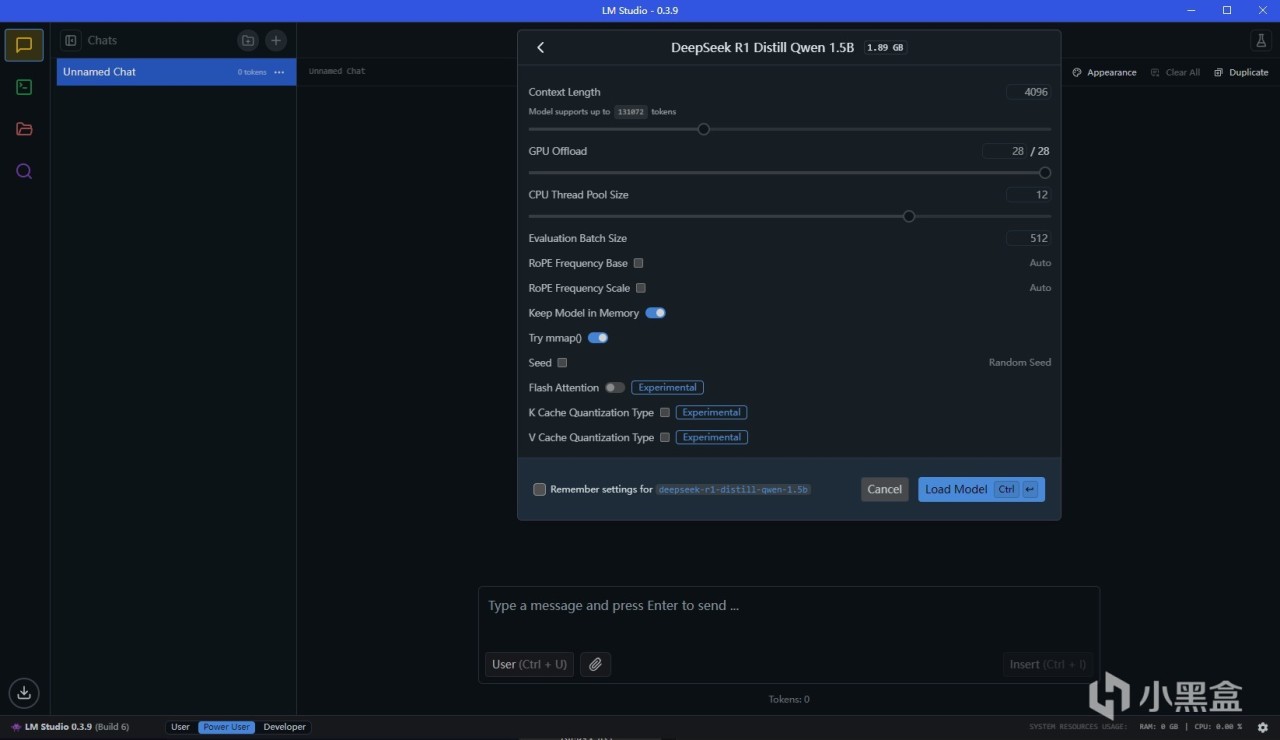
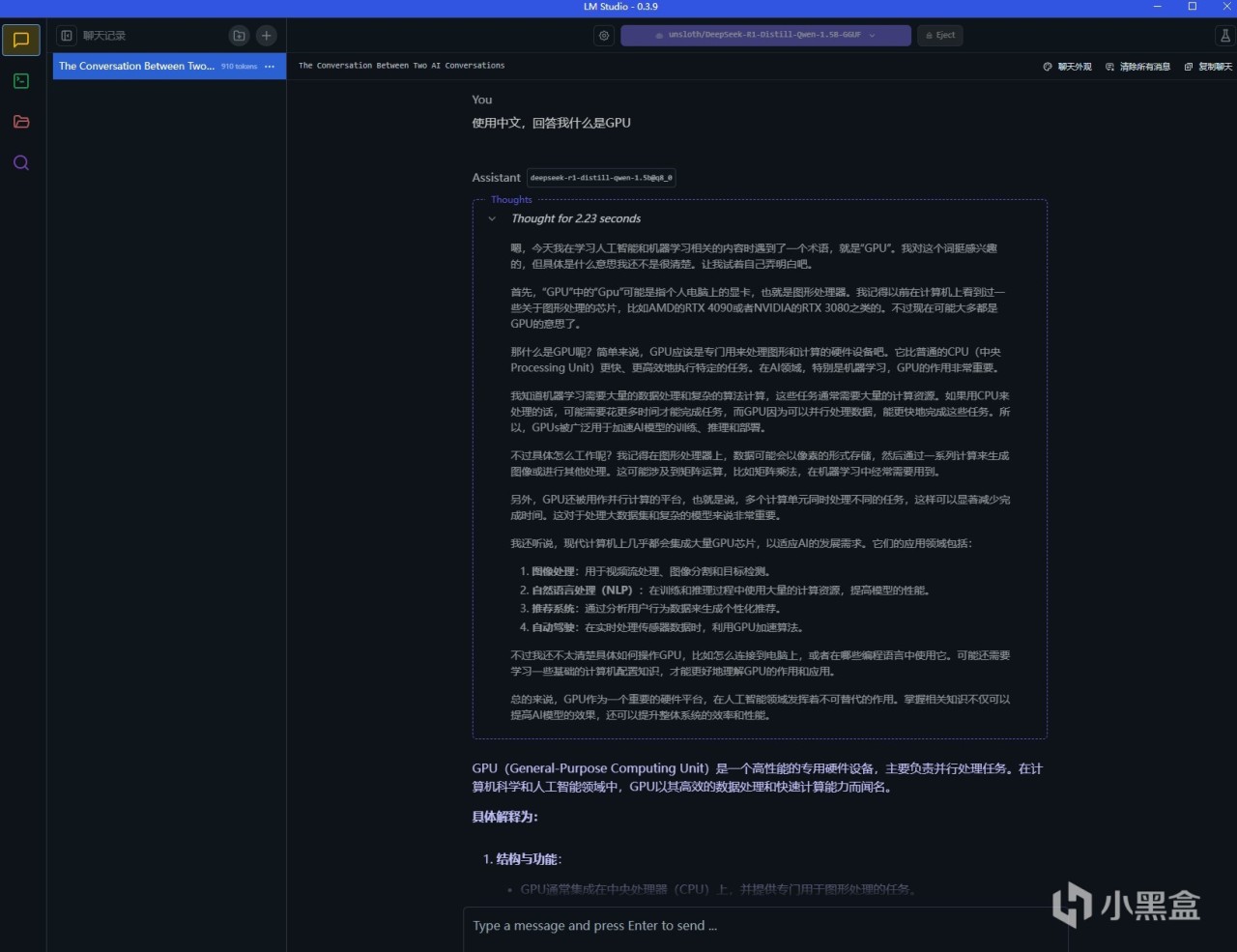
比如我們選用一個模型,這裡用的是最小的1.5B模型,完成加載後如圖。我們此時就能在下方的對話框裡隨意提問了,和一般的大模型使用並無區別
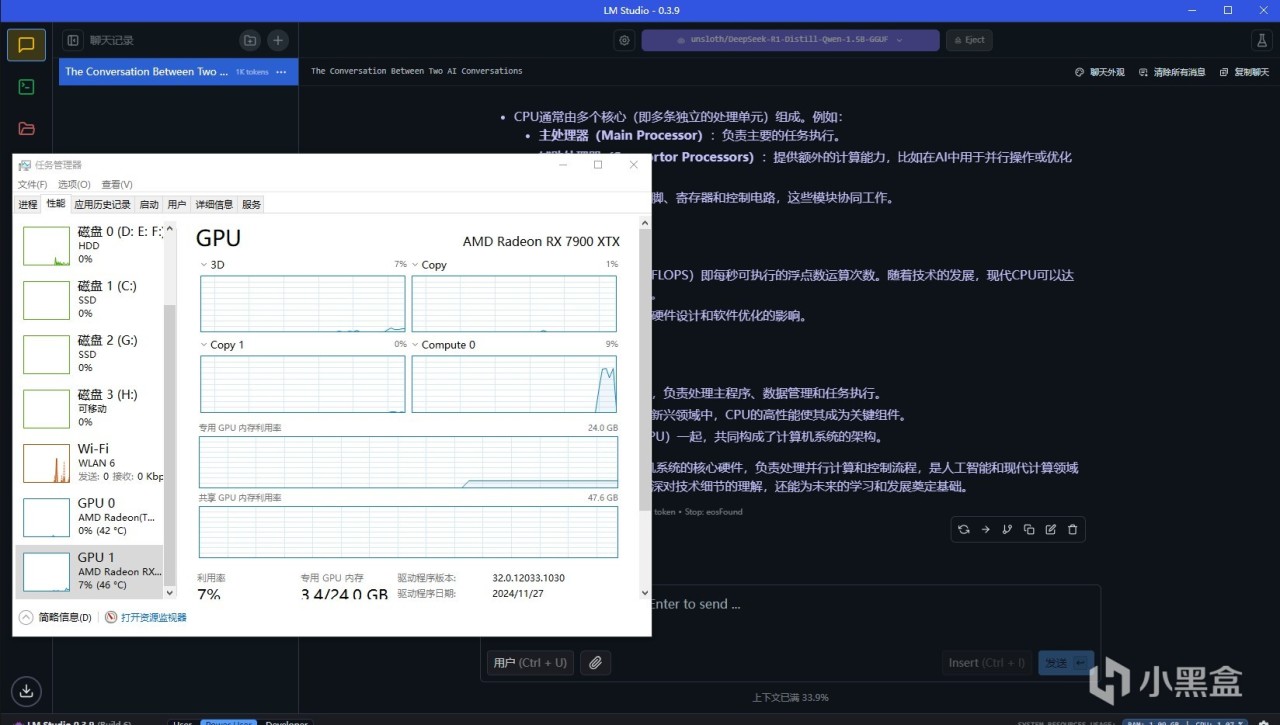
查看顯卡佔用情況,就能看到LM Studio確實調用了GPU,因為LM Studio在0.2版本就已經支持了ROCm,所以使用AMD顯卡也是可以跑滿速的
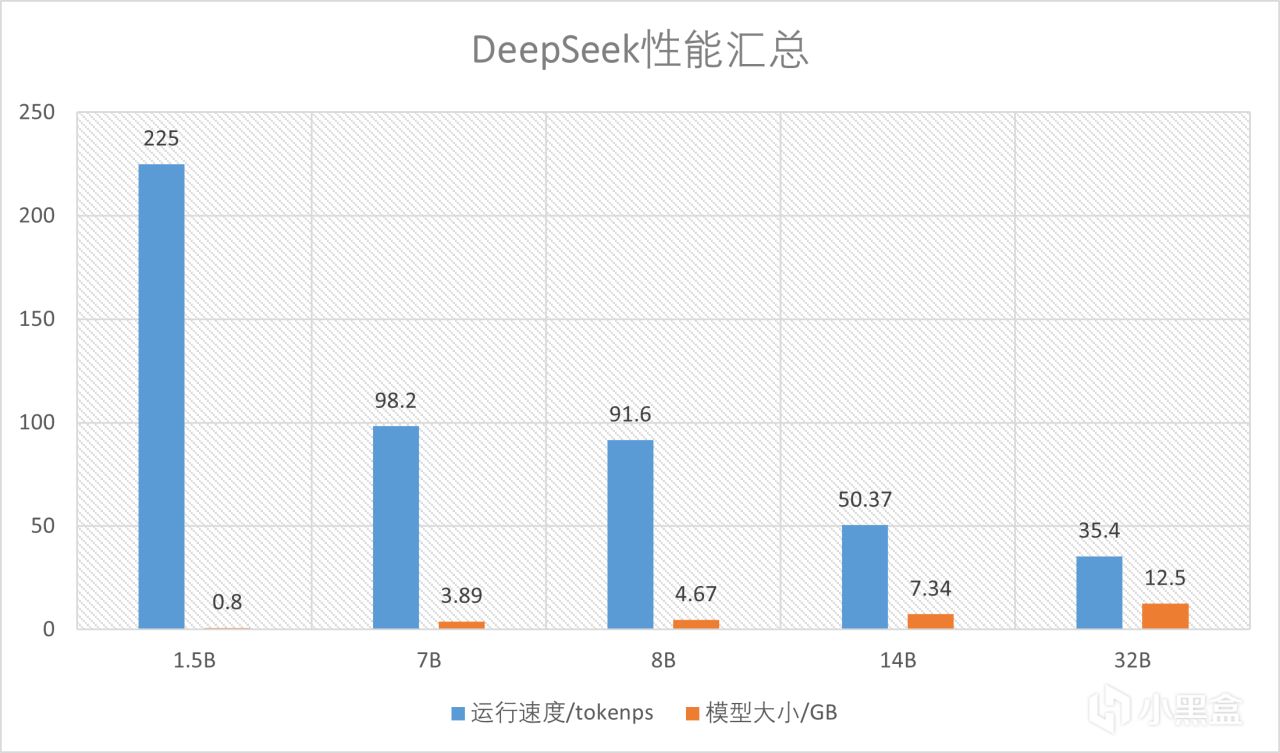
至於性能可以看圖,因為7900XTX的顯存足夠,所以能跑最大32B的量化模型。速度上,使用最小的模型可以達到225token/s,最大的模型也有35.4token/s,速度絕對是夠用的,相比於一般CPU來說快了非常多
(可選)部署內網API接口
LMStudio也支持內網API接口調用,打開開發者模式,以及接口運行,就能在本地開啟對應模型的接口。
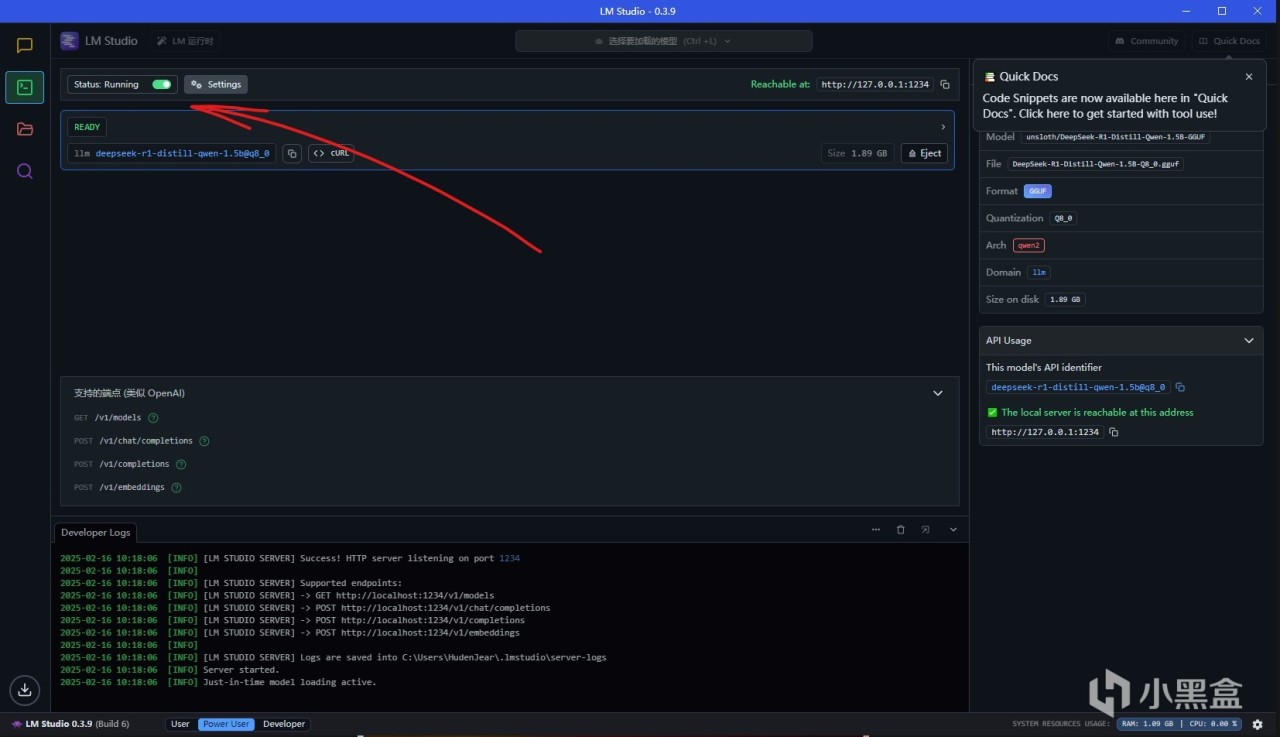
比如這裡使用models的api可以查看目前可用的模型名稱,也可以使用curl命令進行嘗試,直接按下這個按鈕就能複製curl命令。打開內網API之後可以看到對應接口的端口,比如這裡打開了這個端口之後,就能在其他應用裡面進行調用
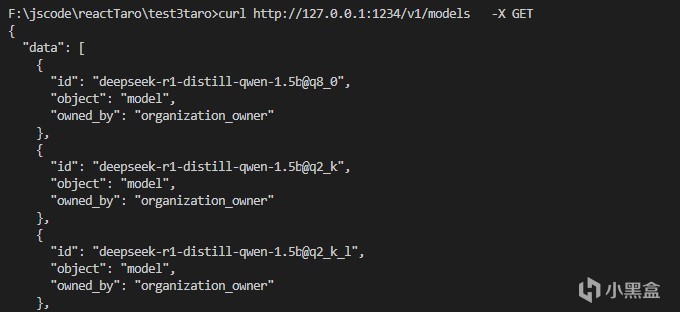
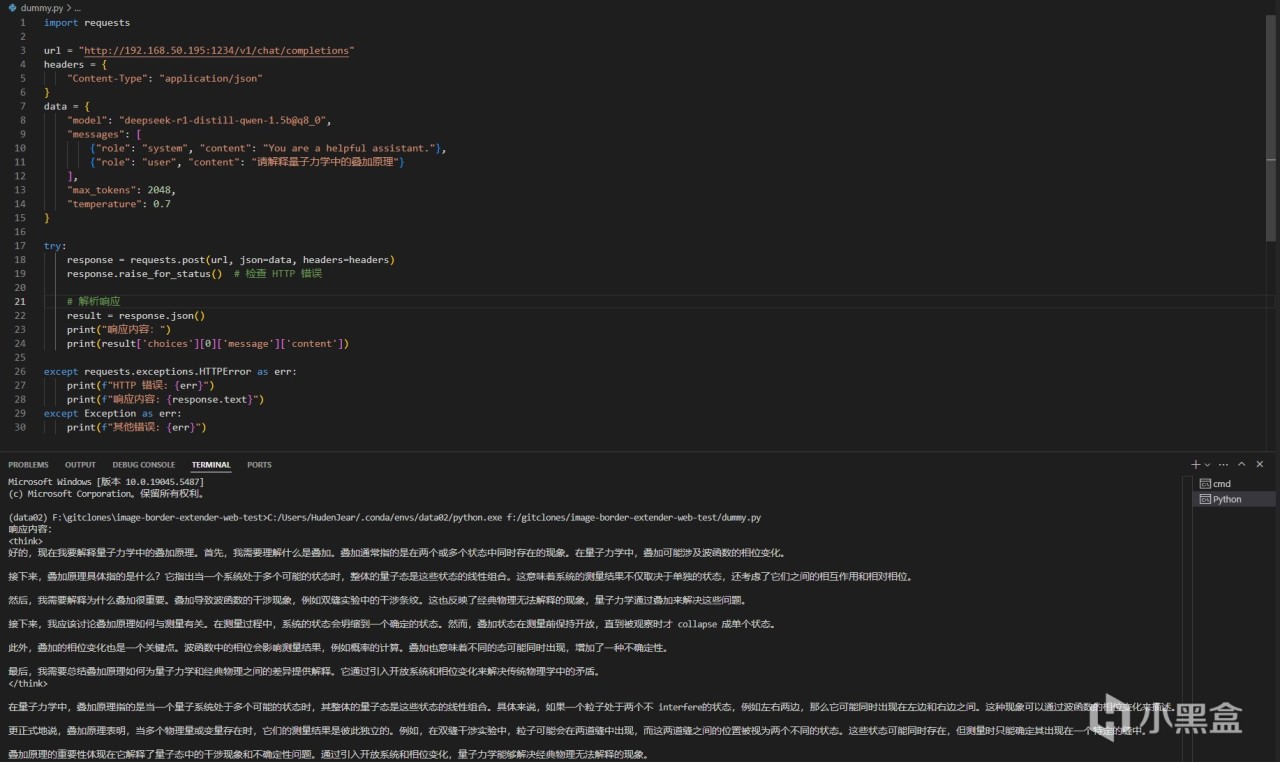
最簡單的例子就是使用python做開發,可以直接通過request包來,調用這個API,如果有耐心還可以自己封裝一些應用
總結
雖然很想讓DeepSeek幫我總結了,但是還是認真講一下吧。LMStudio作為大語言模型入門的應用來說非常方便,但是默認接入抱抱臉是一個痛點,不過使用迅雷和國內鏡像網站就能迴避,總的來說比較方便。而大語言模型也是非常實用的一個工具,我平時做開發也會用大語言模型來寫代碼,DeepSeek爆發之後也是讓我如虎添翼,所以我很推薦有條件的朋友都搞一個來玩玩。
至於部署需要的硬件成本,我覺得不高,你需要的是:一張12G以上顯存的顯卡用來部署14B的模型,16G以上的顯卡部署32B的量化模型,或者AMD最新的8系或者AI系APU,比如8845或者AI 9 370之類內置NPU,用上內存也能跑32B的模型,使用上基本能媲美獨顯。而平時應用也非常方便,不僅是寫文檔寫代碼,有一些知識相關的可以用大模型來學,比如想學一下外語(正經),大語言模型是一個非常不錯的老師。
AMD在AI領域內的不斷追趕也讓我這個小Afan更有信心了,本身AMD的顯卡精度閹割就沒那麼狠,底子很不錯。在AI這個方向上,先是開源的ROCm,接著又是計算卡MI系列,現在又在頂級大語言模型上有比同級N卡更強的推理能力。我已經開始期待奸商老黃被AMD的方案不斷吃掉份額,然後被迫賣掉皮衣補貼公司的場景了(做夢中)為了助力這個夢想,大家都快把手裡的A卡AU用起來啊,本地部署個DeepSeekR1給自己享受一把最新的科技進步!
最後送上一張圖,感謝大家圍觀
