这篇指南适用于N卡A卡i卡的电脑,没显卡也能用,很慢而已。盒友们我是迪普希壳,我来救大家辣,给我服务器多来点电罢!
虽然一直以来谈到AI就是英伟达如何云云,但是本次DeepSeekR1的发布着实让人知晓了AMD早已突破了老黄的AI垄断。AMD在其发布之初就官方宣布了自家显卡在推理上的独到优势,并且很快在测试版驱动中开启了DeepSeekR1的本地使用选项,可谓是高歌猛进啊。
不过可能诸位手里有A卡的朋友们受限于PC知识,主要还是用着DeepSeek的官方应用,没有自己部署R1的想法。而现在层出不穷的DeepSeekR1部署方法又大多数都是命令行或者部署接口,搞的非常高级,但是日常使用完全用不上,也不太适合新手。所以为了大家都能用上国产争气大模型,我实验出了一个方法,可以完全避开使用命令行,让大家3步给自己部署一个本地的DeepSeekR1蒸馏模型,不受网络错误的气!

这次就用我平时在用的电脑为例,简单给大家演示一下如何不用任何命令行,就能在本地部署这个备受瞩目的大模型,而大家需要准备的材料只有:
一台电脑,有独显,或者有AMD的8系APU(例如8845)或者AI系APU(例如AI 9 370)
可以上网
有手就行
步骤1:下载LMStudio
LM Studio是一个极大程度方便windows用户的GUI大模型本地运行工具,在windows上会比ollama方便很多,首先我们来安装这个软件.......软件链接:LM Studio - 发现、下载和运行本地LLM - LM Studio 应用程序
一般而言,windows上本地部署开源大模型有ollama这个方案,但是使用上并不是很方便。原因主要就在于这个东西他是高手用的,像我这样的低手完全不想碰命令行。而且ollama下载模型基本都是官方仓库,占用显存更少的量化模型找起来比较复杂,所以对于我们家用用户来说,LMStudio更方便
安装过程全默认即可,打开之后就能看到很简洁的界面,过程并不需要装额外的依赖内容,也不需要下载额外资源,而且LM Studio在0.2版本就已经支持了ROCm,所以默认使用AMD显卡也是可以跑满速的
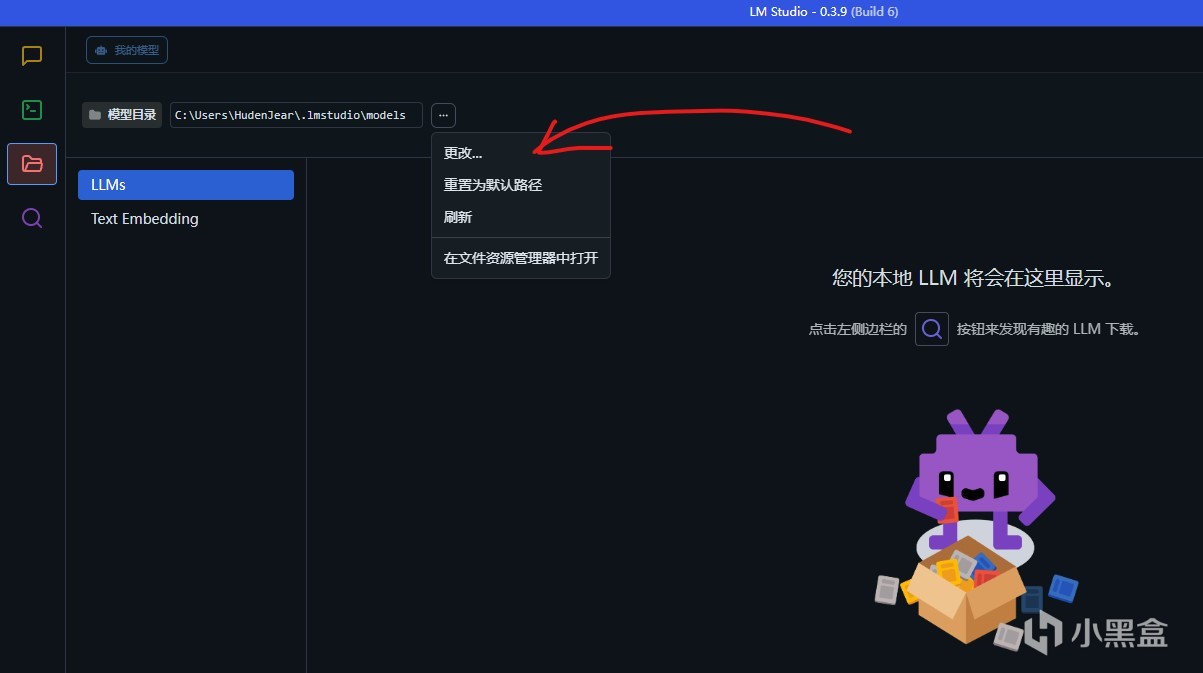
点击文件夹图标可以看到本地的模型,但是目前本地没有模型,联网也找不到模型。这个问题是因为huggingface.io在部分地区无法访问,所以我们需要绕过这个
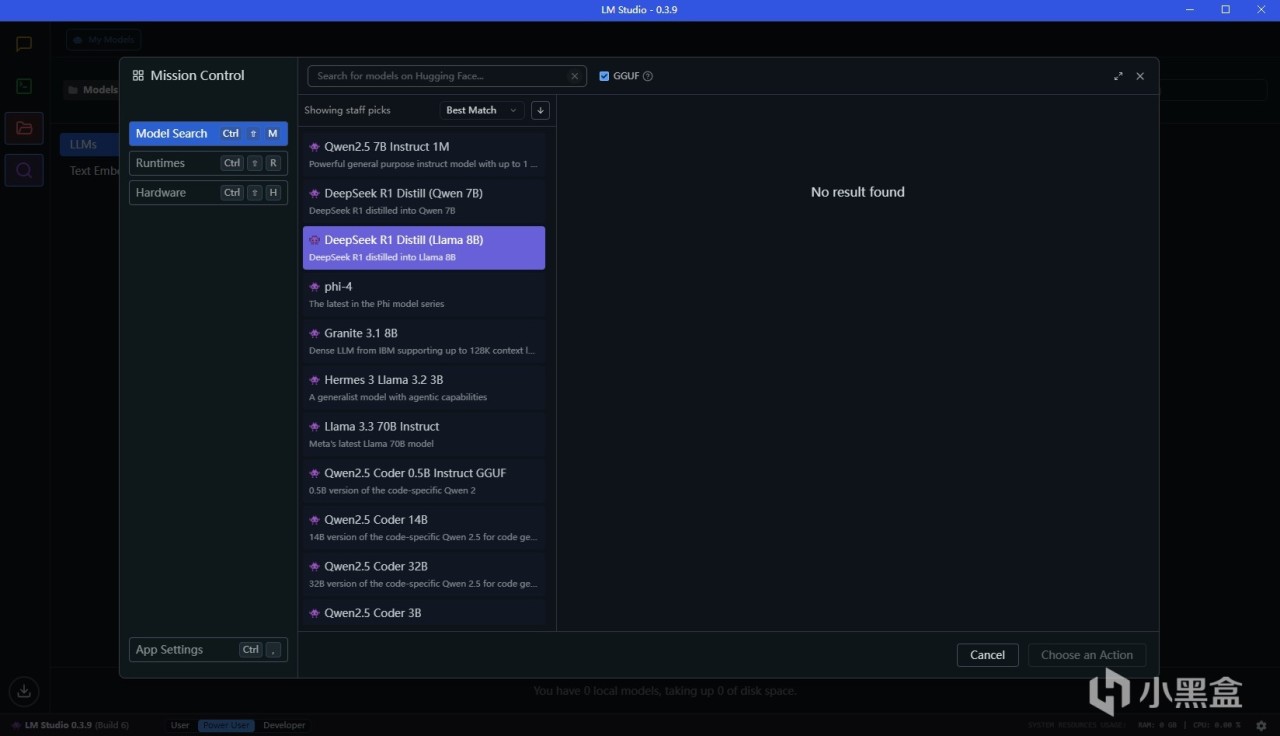
步骤2:下载模型
绕过huggingface.io下载模型的方法也很简单,国内有hf的镜像网站,内容很齐全,版本也很新:HF-Mirror
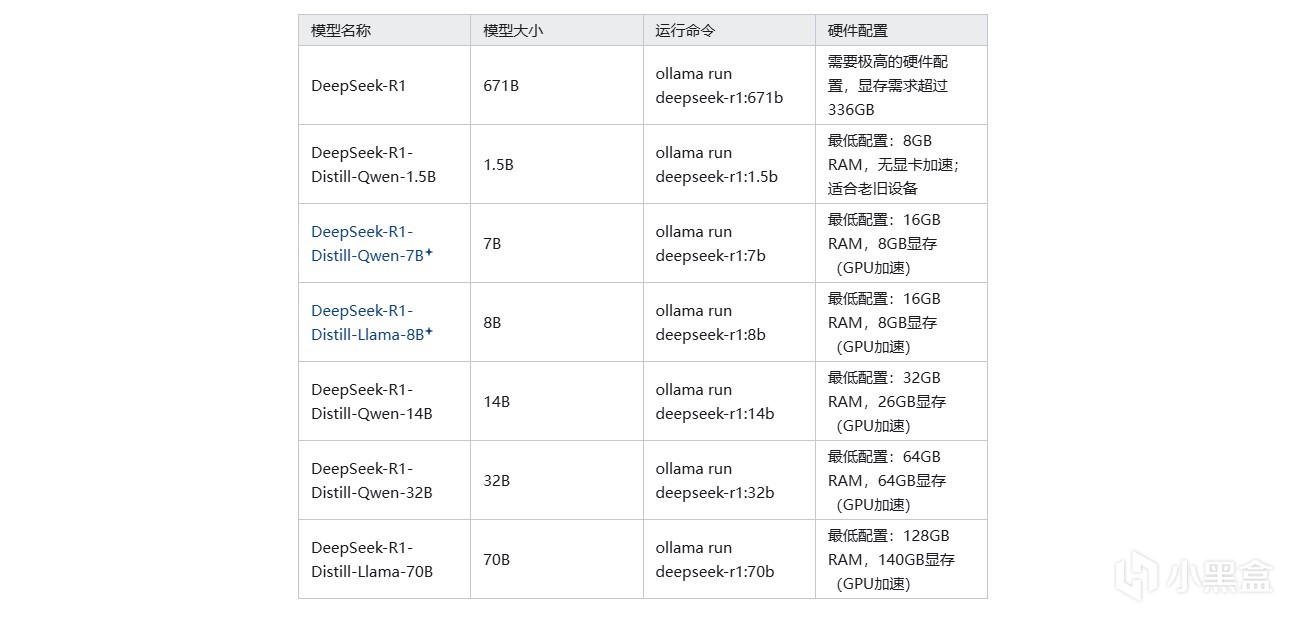
比如我们搜索DeepSeek-R1-Distill-Qwen-1.5B-GGUF,然后打开页面,就能看到已经被量化打包好的模型。点开fileandversion这一栏,就能下载模型了。一般我们只需要下载一个模型,这里面比较推荐使用Q8模型,当显存不足的时候可以考虑Q2以及Q4
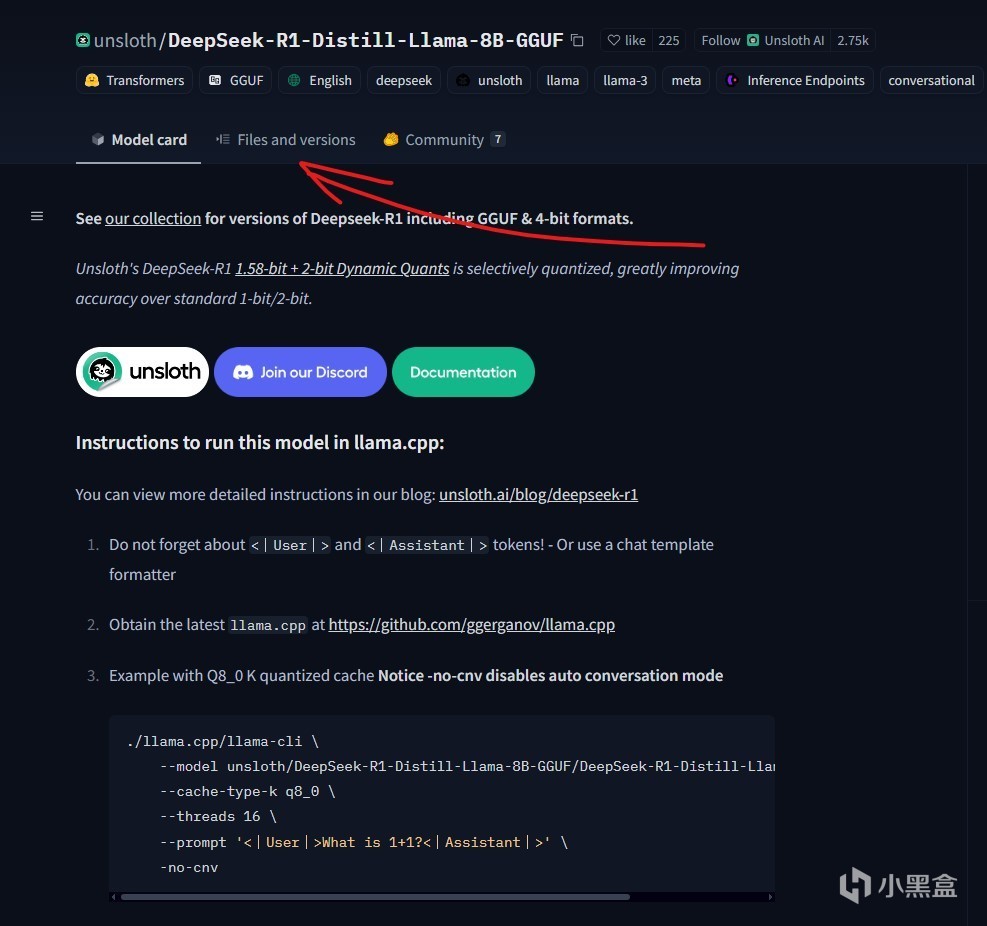
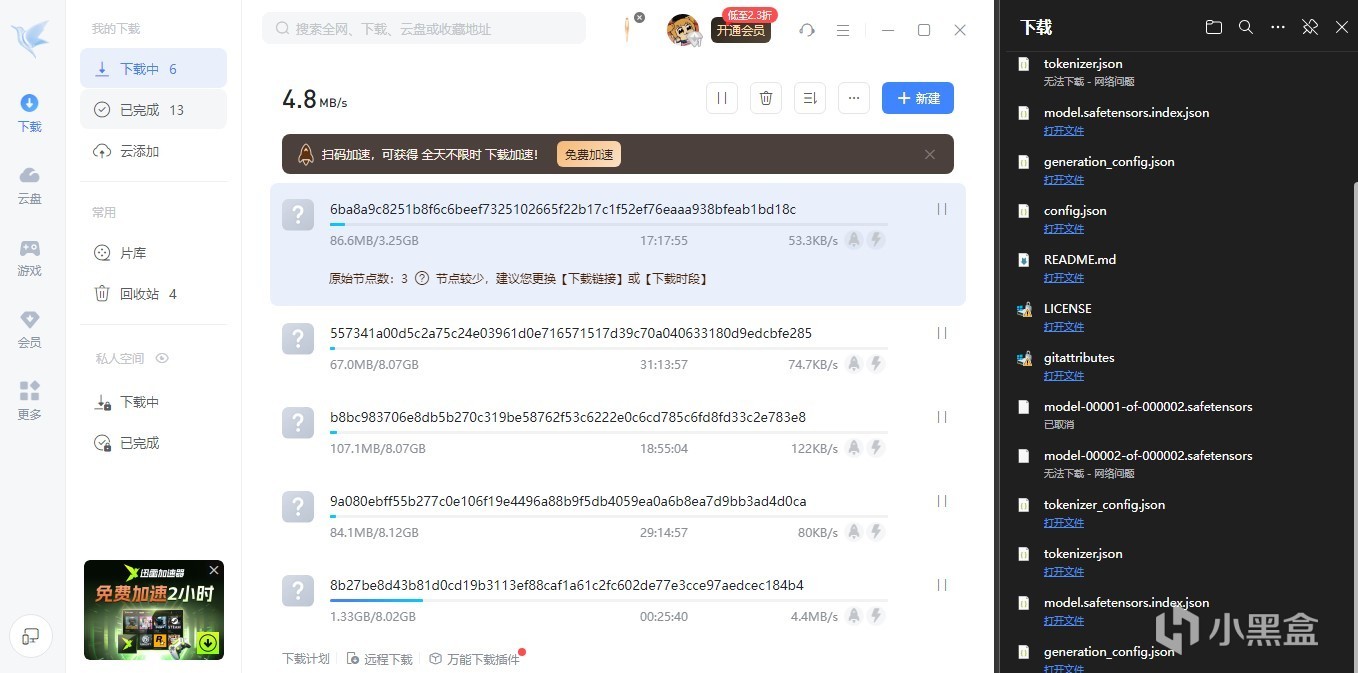
觉得慢可以用某雷p2p加速一下,会比浏览器下载快很多。下载的时候建议同时下载gitattributes这个文件,方便LMStudio读取模型信息
步骤3:准备本地模型文件
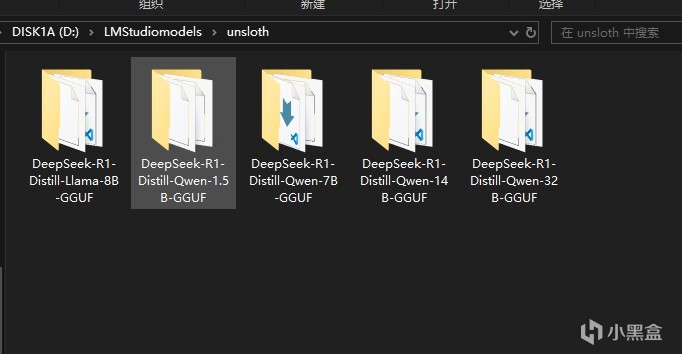
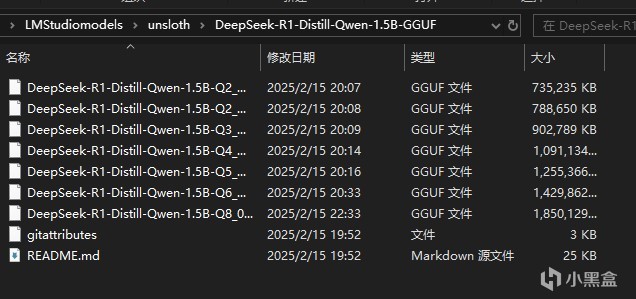
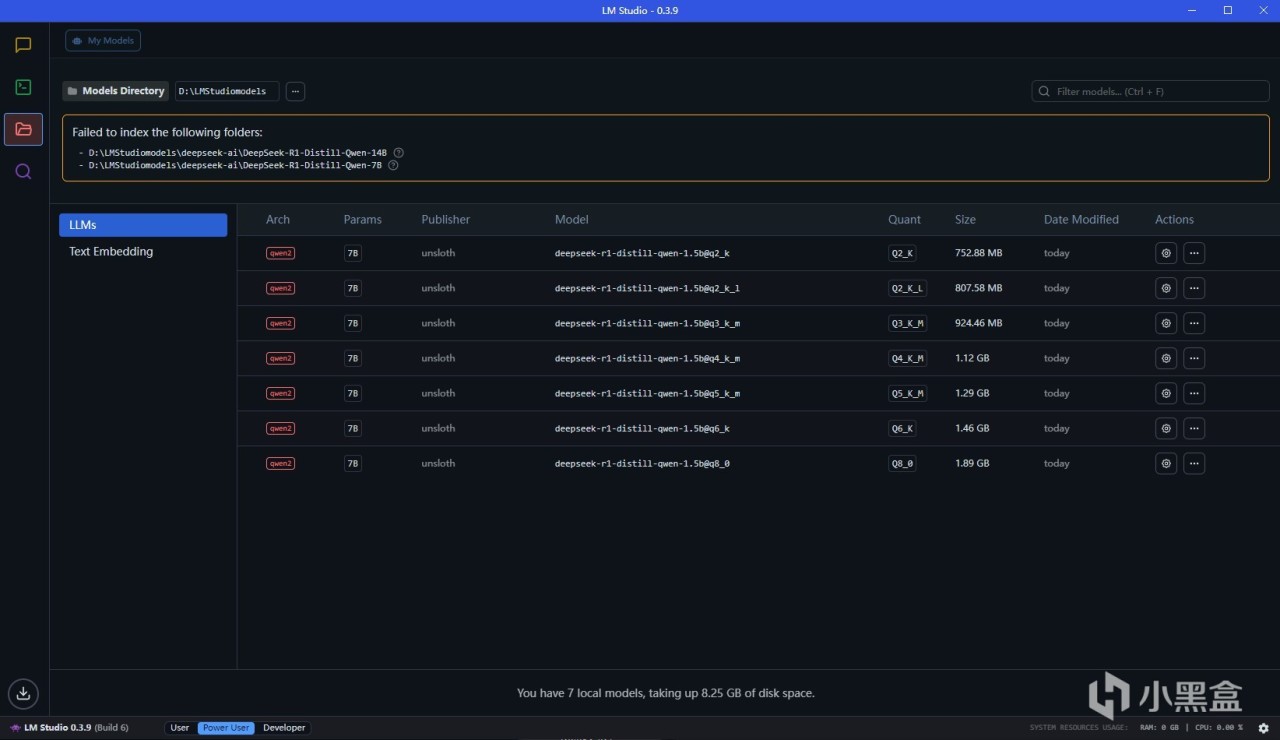
下载好上文中的模型文件之后,我们需要新建一个LMStuidioModels文件夹,这是仓库的根目录,然后新建一个unsloth文件夹,这是模型来源索引文件夹,然后再在其中根据模型名称新建文件夹,比如刚才下载了DeepSeek-R1-Distill-Qwen-1.5B-GGUF,我们就在这个文件夹里新建这个文件夹,然后放入下载好的模型文件,以及gitattributes
然后我们打开LMStudio,点击这个按钮更改本地仓库到刚才的LMStuidioModels文件夹,就能看到本地模型了
开始使用DeepseekR1
此时我们回到对话栏,就能在最上面选择模型,加载,然后开始使用啦。有A卡的情况下可以把CPU层数开到最大,这样就能完全使用GPU
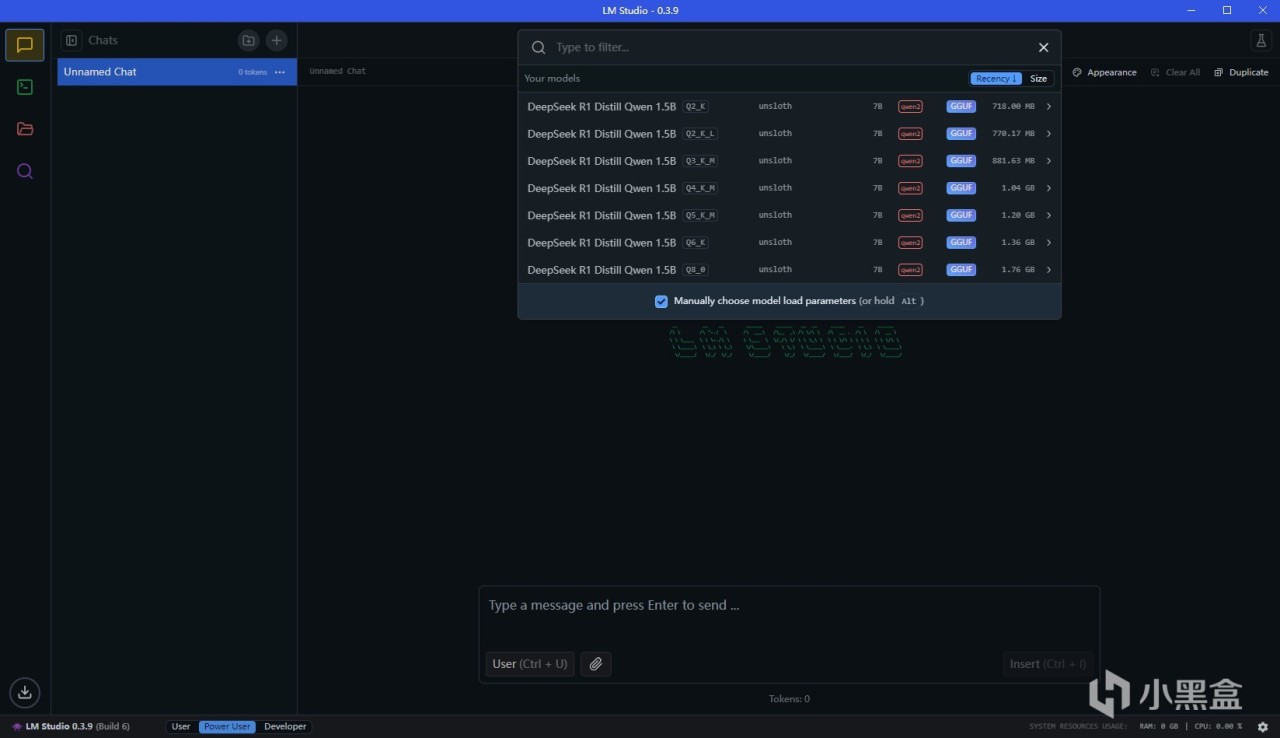
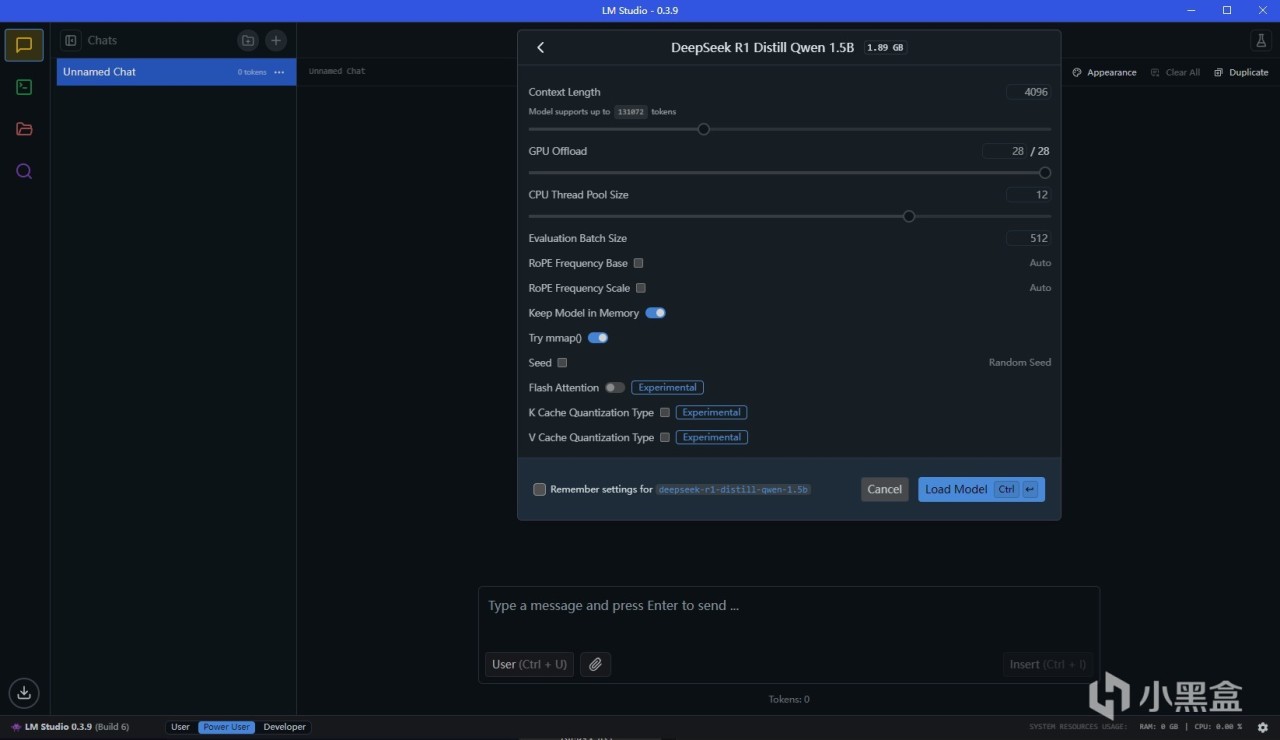
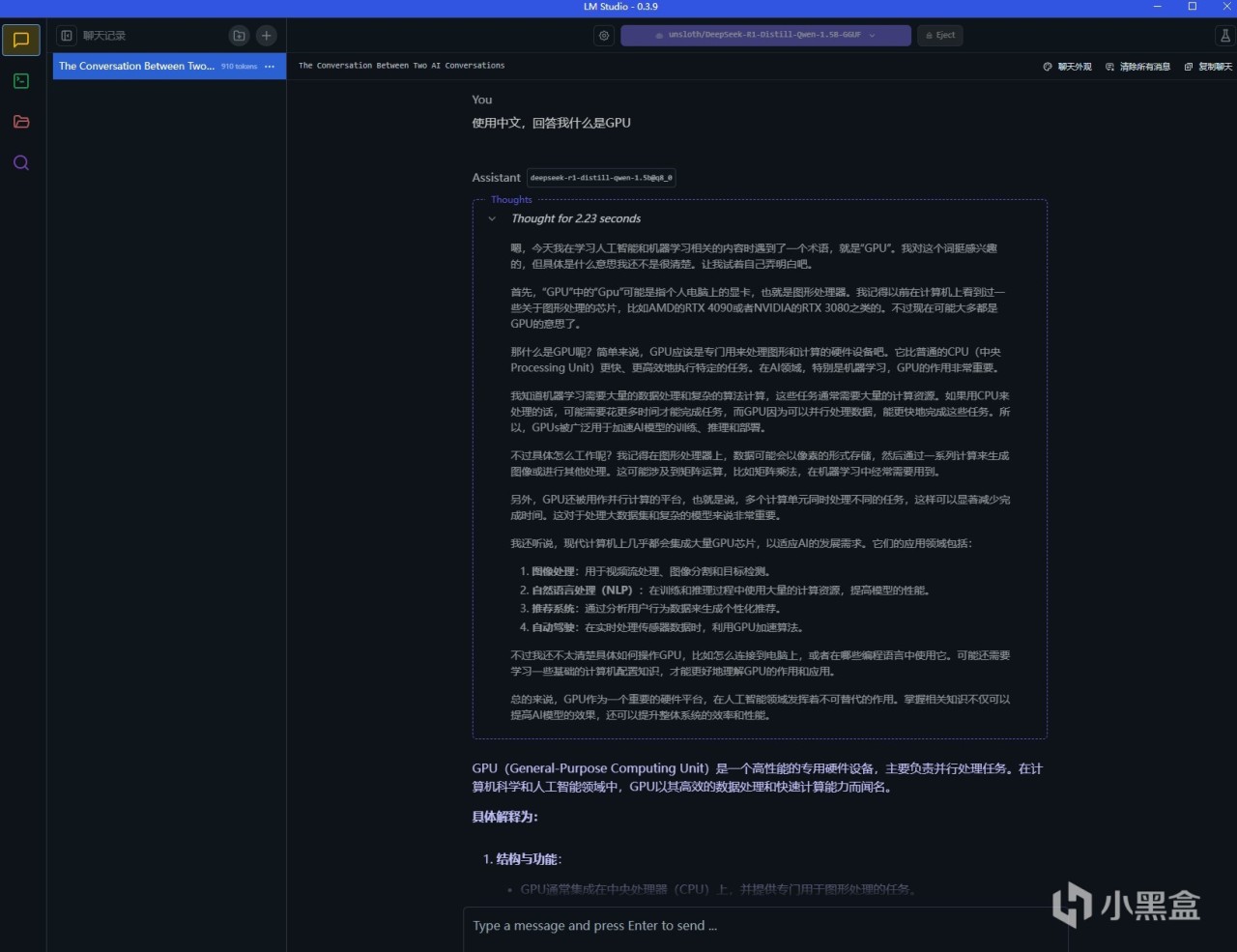
比如我们选用一个模型,这里用的是最小的1.5B模型,完成加载后如图。我们此时就能在下方的对话框里随意提问了,和一般的大模型使用并无区别
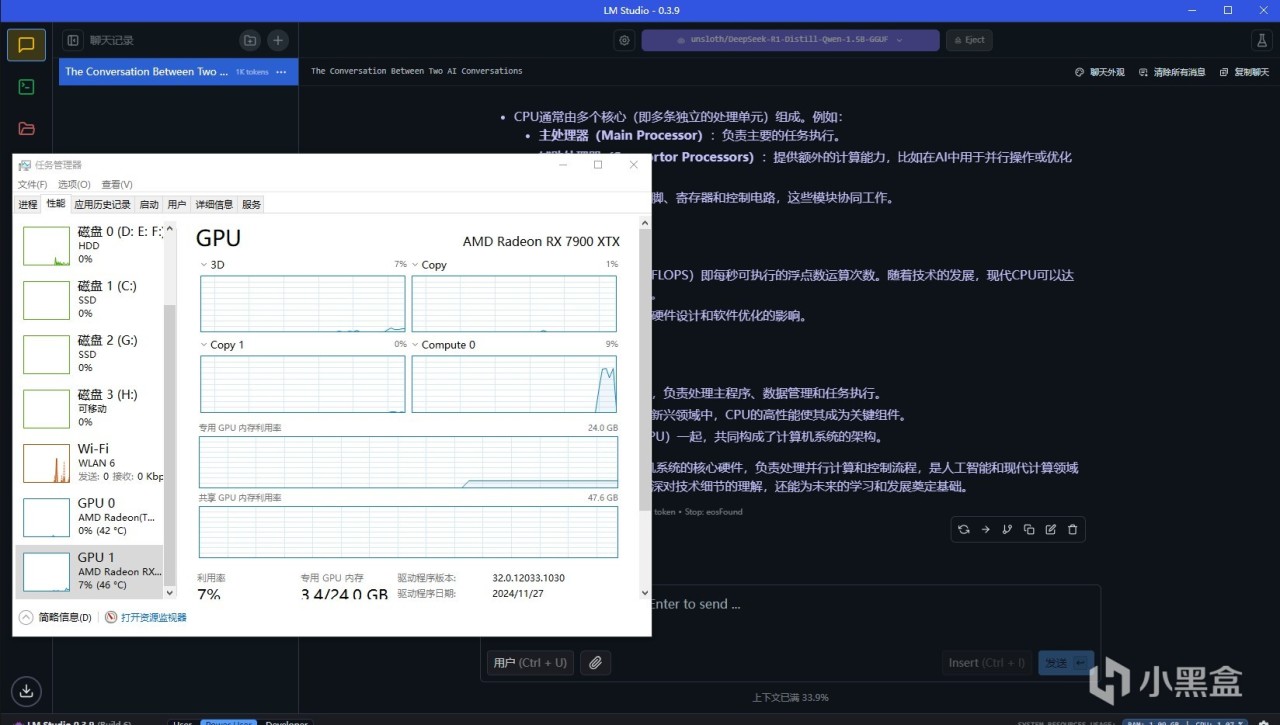
查看显卡占用情况,就能看到LM Studio确实调用了GPU,因为LM Studio在0.2版本就已经支持了ROCm,所以使用AMD显卡也是可以跑满速的
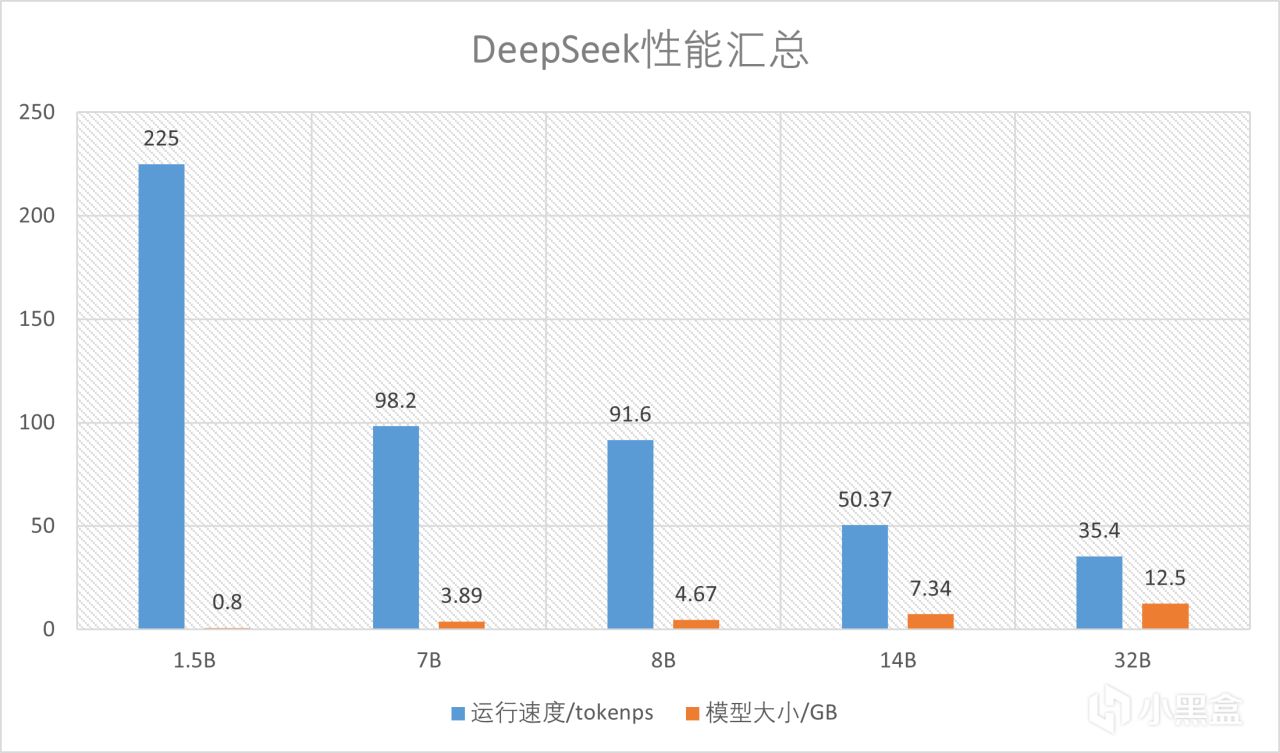
至于性能可以看图,因为7900XTX的显存足够,所以能跑最大32B的量化模型。速度上,使用最小的模型可以达到225token/s,最大的模型也有35.4token/s,速度绝对是够用的,相比于一般CPU来说快了非常多
(可选)部署内网API接口
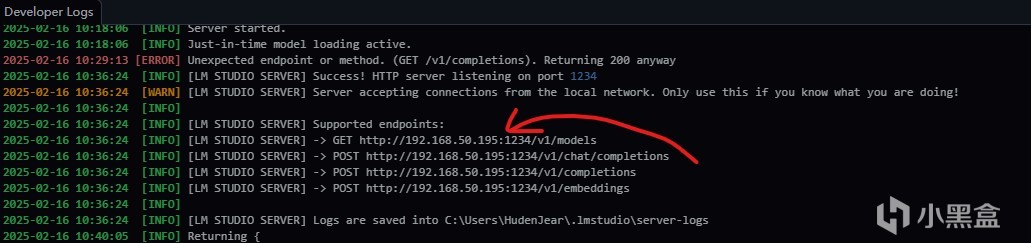
LMStudio也支持内网API接口调用,打开开发者模式,以及接口运行,就能在本地开启对应模型的接口。
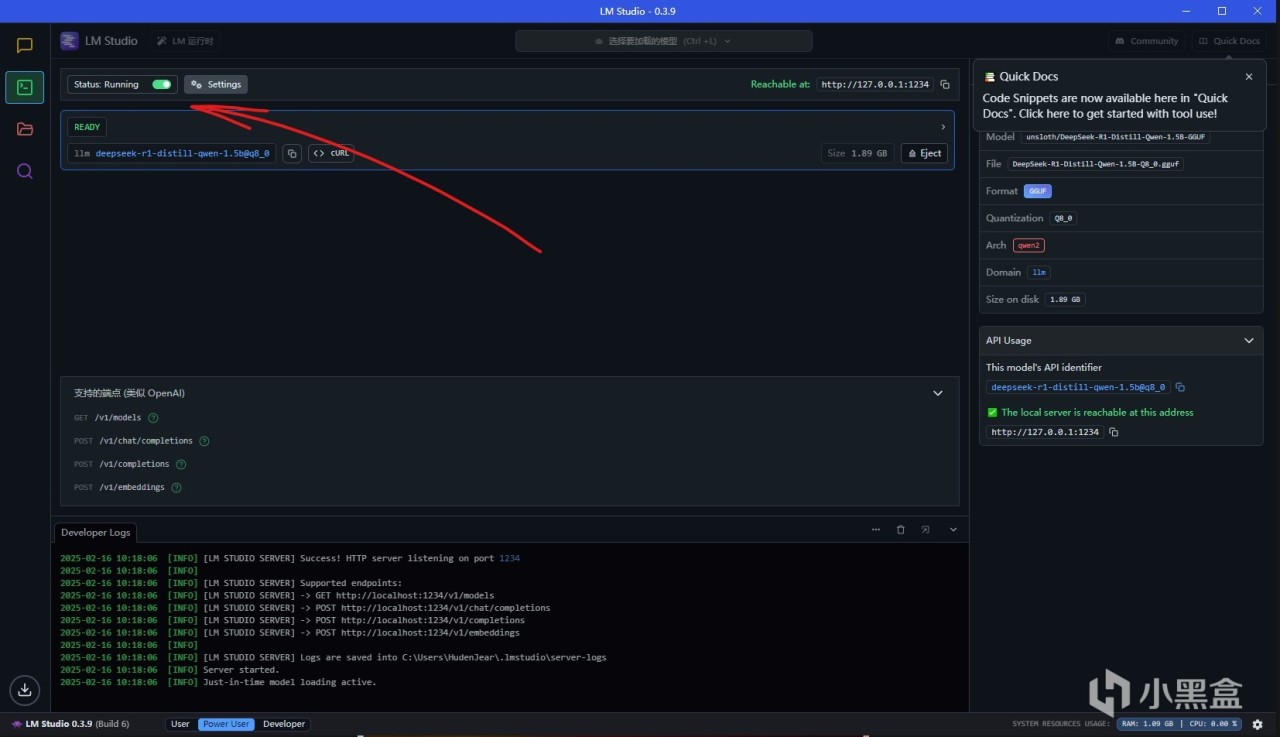
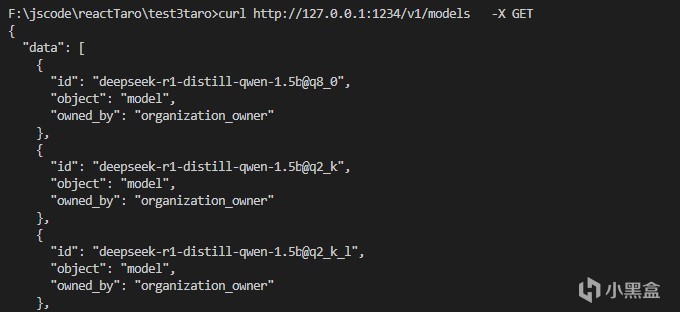
比如这里使用models的api可以查看目前可用的模型名称,也可以使用curl命令进行尝试,直接按下这个按钮就能复制curl命令。打开内网API之后可以看到对应接口的端口,比如这里打开了这个端口之后,就能在其他应用里面进行调用
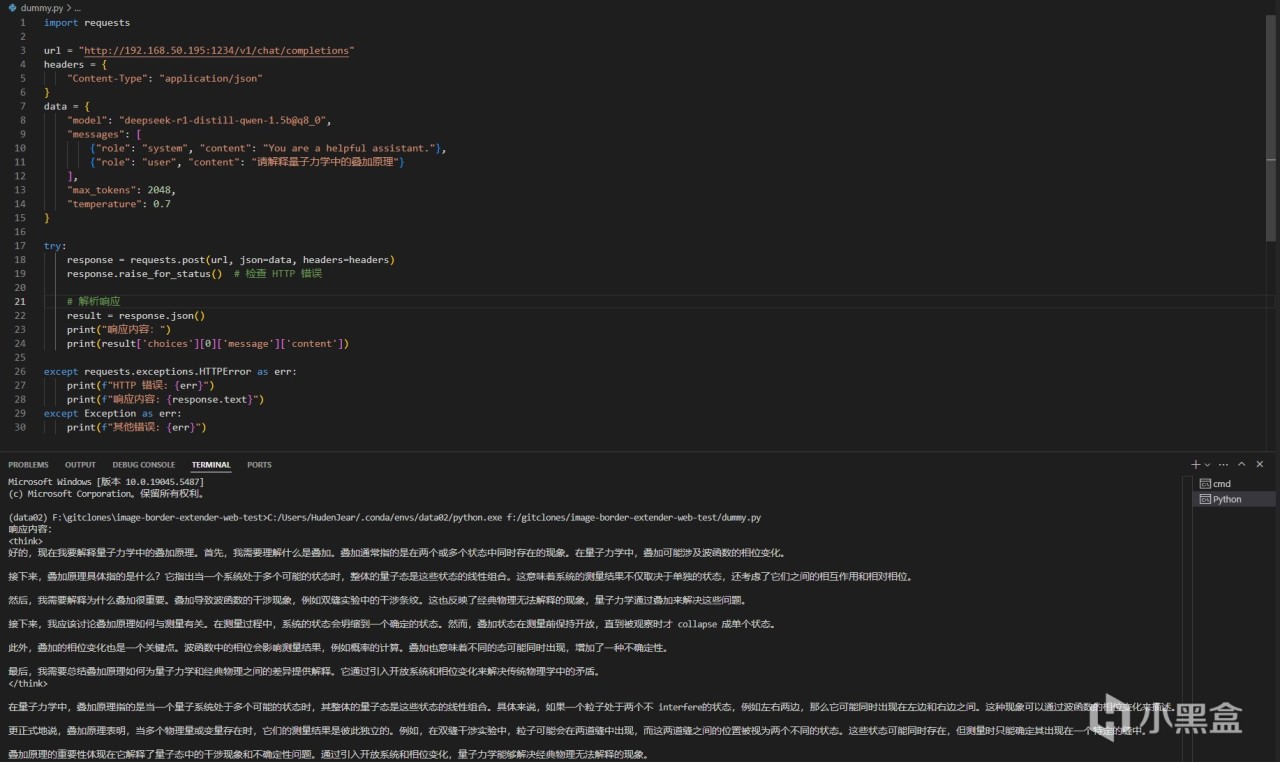
最简单的例子就是使用python做开发,可以直接通过request包来,调用这个API,如果有耐心还可以自己封装一些应用
总结
虽然很想让DeepSeek帮我总结了,但是还是认真讲一下吧。LMStudio作为大语言模型入门的应用来说非常方便,但是默认接入抱抱脸是一个痛点,不过使用迅雷和国内镜像网站就能回避,总的来说比较方便。而大语言模型也是非常实用的一个工具,我平时做开发也会用大语言模型来写代码,DeepSeek爆发之后也是让我如虎添翼,所以我很推荐有条件的朋友都搞一个来玩玩。
至于部署需要的硬件成本,我觉得不高,你需要的是:一张12G以上显存的显卡用来部署14B的模型,16G以上的显卡部署32B的量化模型,或者AMD最新的8系或者AI系APU,比如8845或者AI 9 370之类内置NPU,用上内存也能跑32B的模型,使用上基本能媲美独显。而平时应用也非常方便,不仅是写文档写代码,有一些知识相关的可以用大模型来学,比如想学一下外语(正经),大语言模型是一个非常不错的老师。
AMD在AI领域内的不断追赶也让我这个小Afan更有信心了,本身AMD的显卡精度阉割就没那么狠,底子很不错。在AI这个方向上,先是开源的ROCm,接着又是计算卡MI系列,现在又在顶级大语言模型上有比同级N卡更强的推理能力。我已经开始期待奸商老黄被AMD的方案不断吃掉份额,然后被迫卖掉皮衣补贴公司的场景了(做梦中)为了助力这个梦想,大家都快把手里的A卡AU用起来啊,本地部署个DeepSeekR1给自己享受一把最新的科技进步!
最后送上一张图,感谢大家围观
