前言
這周讀一篇短篇,看看2024年騰訊的技術大牛Shun Cao
在SIG上分享的一篇移動端NanoMesh管線方案。
自虛幻5引擎的Nanite網格技術框架工業化,以及被越來越多的商業化產品試錯並驗證,最新的引擎技術總歸離不開如何處理海量多邊形來渲染大世界的問題——最近的就有《魔物獵人 荒野》的RE引擎。
整體的大思路肯定是網格集群化,以及自動、動態的LOD系統;而細節的部分,讓我們跟隨作者的分享,來看看各個步驟都是如何設計以及實現的。另外,原文並沒有章節劃分,這裡我是大概劃分了幾個部分,並突出其中管線實現的部分。
本文還是以翻譯原文PPT頁及解說稿為主,打星號的部分則是我個人的補充。
一、平臺現狀

讓我們以圖中的例子作為演示:其中的場景包含了八千萬多邊形,並實現了在移動端渲染。我們僅在開發過程使用高精度資源,但在渲染時,我們控制了三角形集群的顆粒度(granularity)——基於屏幕投影面積以及到攝像機的距離來渲染集群的級別,確保在不同的GPU上都有合適的效果。
*類似Nanite,這裡說的三角形數都是指原始數量,不是實際運行時的三角形數。實際運行最多也不會超過屏幕像素的規模,而且往往會以低一些的分辨率來渲染。

主機與移動端管線對比
然而,對比桌面端、主機端和移動端,主流的移動端設備缺乏很多硬件和軟件上必要的要實現無縫渲染的特性——例如渲染管線的限制,mesh shader的支持以及無綁定的特性(bindless features 之前也介紹過無綁定的一些好處);帶寬和IO在性能方面也有很大影響;另外,移動端也有其自身特色的基於tiled的GPU架構(屏幕分塊並行)。
*tiled base GPU architecture之前介紹過,是一種把屏幕分塊來利用多核渲染的架構。
二、管線框架細節

因此,如何在這些限制下進行無縫集群渲染呢?我們集中在簡化和效率方面,儘量降低對於硬件的依賴和帶寬的需要。
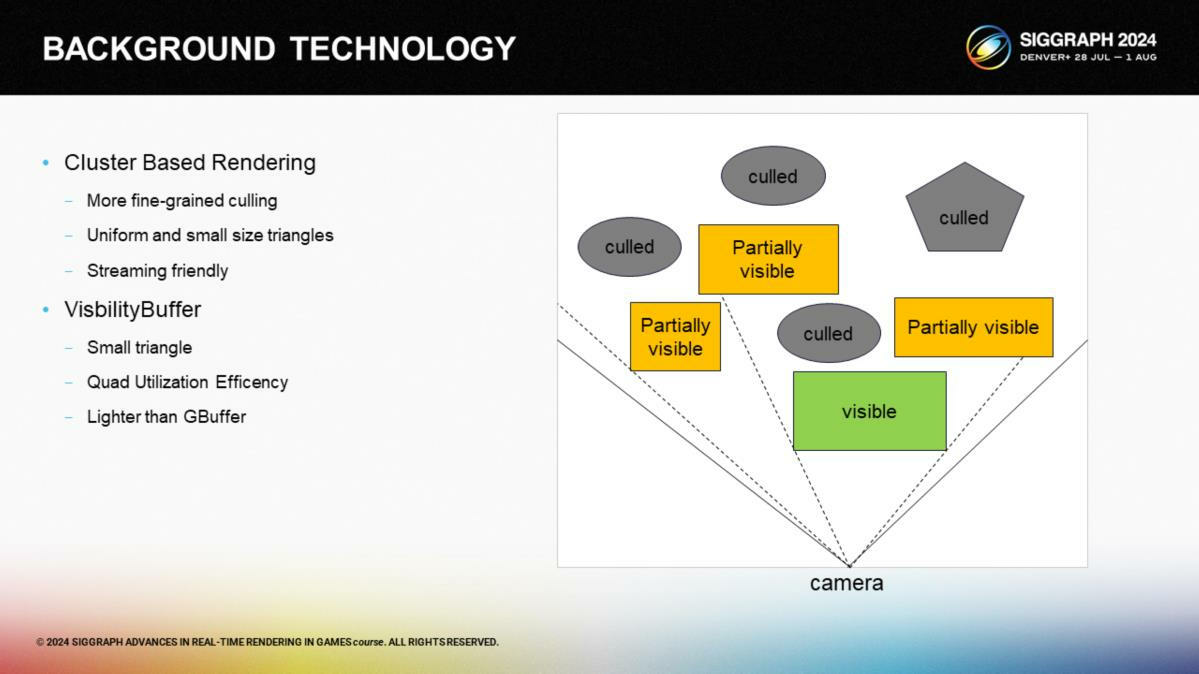
在拆分技術細節之前,讓我們迅速回顧一下背景知識。
首先,基於集群的渲染與遮擋剔除(Cluster-based Rendering: Occlusion culling)在現代的遊戲中很常見了,通過直接做多邊形的剔除來解決過渡繪製的問題。但巨大的物體即使局部可見也往往被全部渲染了。
通過將原始網格劃分到小的集群,並按集群作為剔除的單位,GPU可以略過大量無效三角形;對於集群內的少量三角形,我們可以降低頂點索引的精度,例如使用8bits;我們也可以根據包圍盒來按需加載集群,進一步提升GPU顯存的利用率。
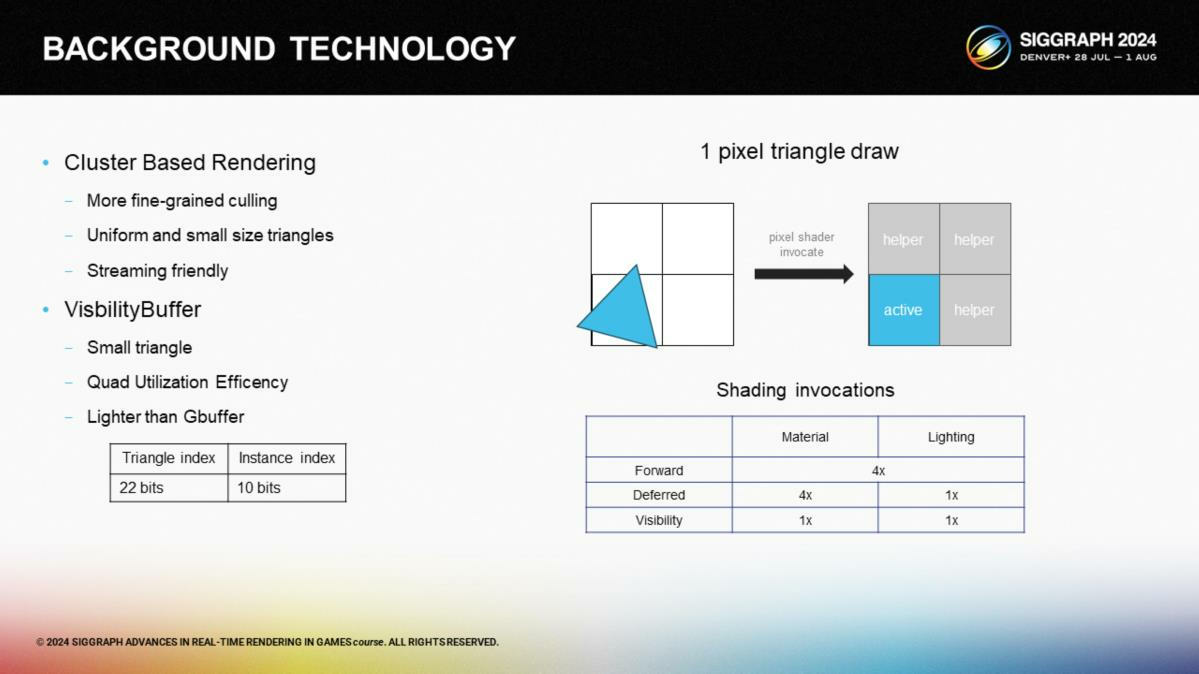
第二項相關的技術是可見性緩衝(Visbuffer)。當渲染三角形時,可見性緩衝方式提供了比前向渲染或延遲渲染更好的Quad效用,僅需要消耗32 bits的額外開銷。John Hable也會在這次的講座中提到可見性緩衝的話題。
*這裡可以聯動上次讀的系列文章。如果沒有看過的話,簡單說一下這裡Quad是指GPU一次處理4個矩形像素的一種架構,對於大三角形是有利的,對於微小三角形是不利的。

*這裡列出了作者的一些參考資料。最早能追溯2017年左右《刺客教條 大革命》提出網格集群方案的時候。
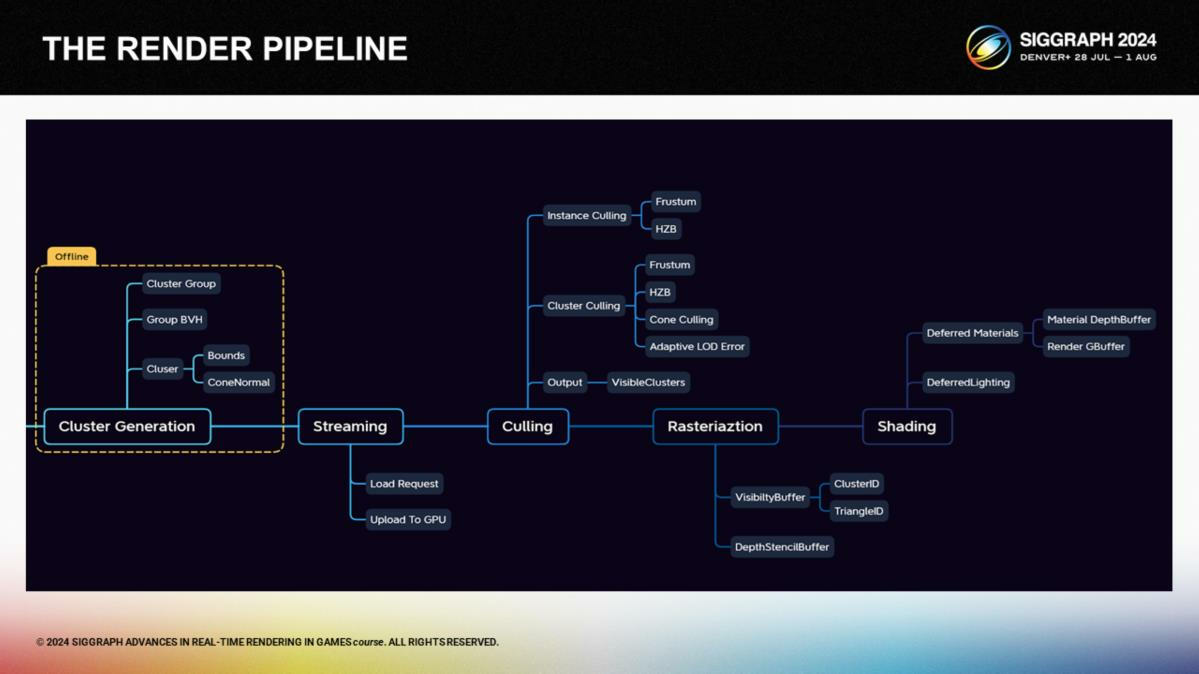
在介紹了背景技術知識後,讓我們看看渲染管線的架構。管線包括兩個部分:離線處理和運行時。
離線階段導入並生成自定義的集群數據,而運行時包含streaming、剔除、光柵化和著色。
*基本思路和Nanite是一致的,後續主要看移動端實現。

在離線處理的部分,在所有步驟之前我們首先重新設計了網格存儲的結構。相比於傳統的多級LOD或簡化集群,我們把網格拆分成多個集群,並連續地把它們重組成新的更粗粒的級別的集群,以相似的方式迭代多次。
它和UE5的Nanite類似,但我們添加了一個合併係數函數來確保能對資源及手動網格LOD進行一定的人工控制。這使多級集群數據更精簡,能更好支持剔除或streaming使的數據結構需求。
對於每個集群,我們儲存了它的包圍盒和法向錐體(normal cone)以便更高效地進行遮擋和背面剔除。每個集群有最多128個三角形,因此我們可以通過8 bits來存儲索引以節省空間。對於非葉子節點(non-leaf nodes),我們記錄為合併時的誤差項。
*簡單來說就是要做得比Nanite的集群和LOD更省,以應對移動端。
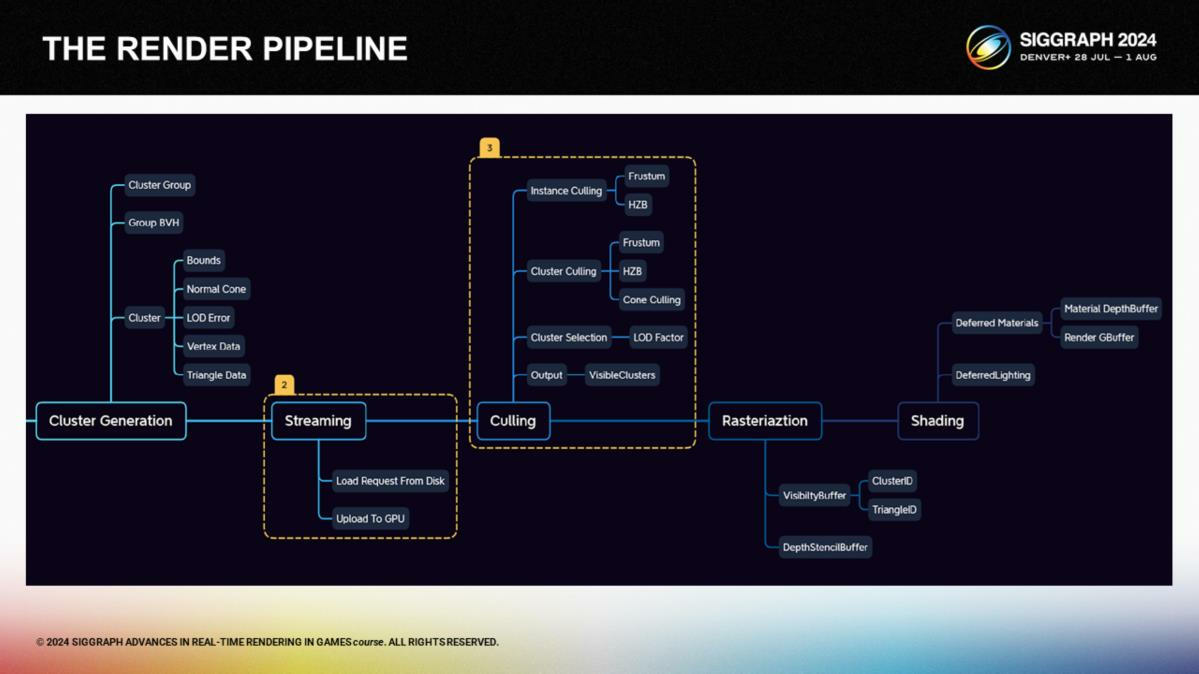
下一步是streaming和剔除階段。Streaming從最粗粒的集群實例開始,之後根據剔除pass的輸出進行按需加載。
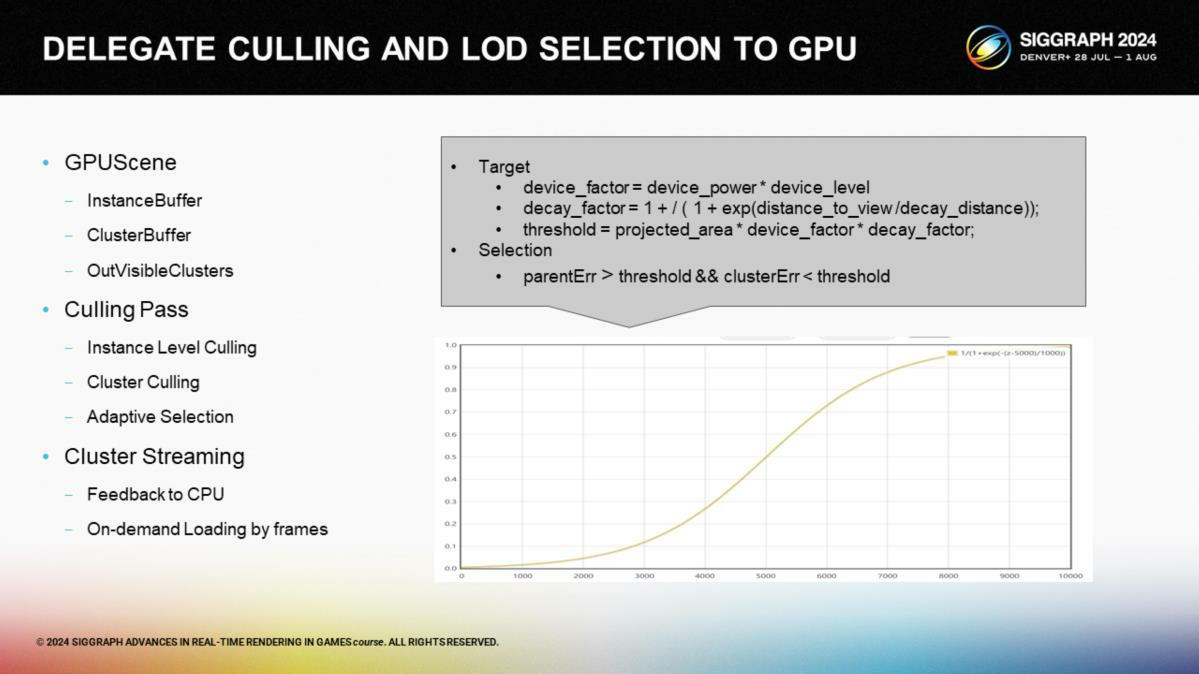
在剔除階段,我們讓GPU來處理集群控制和選擇。物體被存儲在一個實例緩存中,集群在集群緩存中,而經過剔除計算輸出的ID則寫入一個可見集群的緩存。集群緩存自動地基於GPU的選擇進行動態加載。
在剔除步驟的一開始進行一個快速的實例級別的HZB剔除(instance-level culling *Hiz方案介紹過多次了,這裡比對的是實例包圍盒與多層深度緩衝),之後應用例如視錐剔除、遮擋剔除和基於法向錐的背面剔除。我們使用了和Nanite近似的誤差方案來計算集群LOD剔除,不過我們設計了一個基於距離的曲線來作為LodFactor選擇係數,來確保近處的高精度和遠處使用粗粒三角形——模仿手動LOD控制的過程。
*這裡的culling雖然翻譯成剔除,實際負責的計算還包括LOD選擇等。
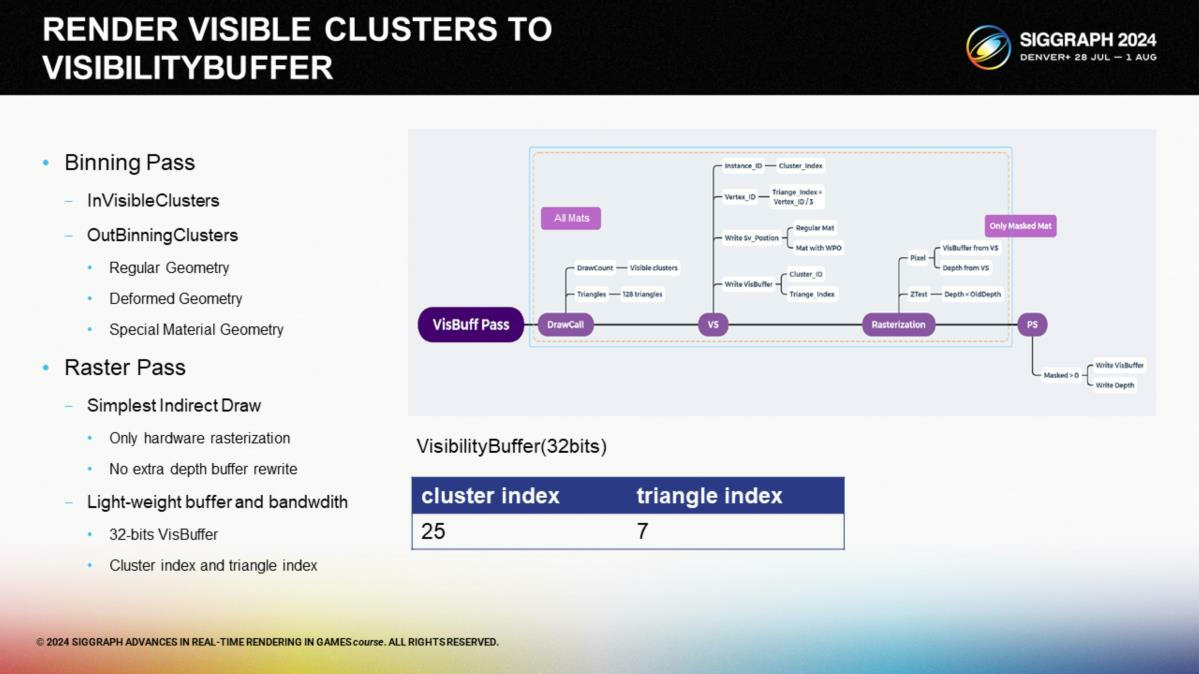
在光柵化階段,為降低電量消耗和GPU用量,我們將中間的渲染結果以32-bit的visbuffer來存儲。理想狀態下,一個draw call就可以把一個集群的所有三角形寫入visbuffer。
為利用GPU的並行特性,我們將物體歸類:類型1在頂點著色器中記錄集群和三角形ID,跳過像素著色計算;類型2,例如蒙皮網格(skinned meshe),頂點著色器中通過骨骼信息重計算頂點座標;類型3,例如有alpha遮罩的植物,過濾器的visbuffer在像素著色中基於遮罩紋理來生成。
We avoid soft rasterization due to extra scene depth passes, lack of atomic64 support, and higher bandwidth from 64-bit visbuffers.
由於額外的場景深度缺乏64位的支持和64位visbuffer的更高帶寬需要,我們避免了使用軟件光柵化。
因為我們是基於集群而不是實例進行渲染,7 bits的空間對於三角形就足夠了,以節省空間給集群的存儲。

由於無綁定方式(bindless)還不被移動端的設備支持,為實現材質著色,我們需要每個材質單獨用一個drawcall進行渲染。由於通常來說單個材質覆蓋整個屏幕的情況比較少,因此我們把屏幕劃分成很多小的tile,每個材質有其自身的tile列表。
通過這種方式,在渲染時我們不需要每個材質都渲染整個屏幕。在每一個tile的渲染中,我們通過visbuffer中集群信息存儲的materialID與當前著色的ID進行比較,僅當兩者匹配時才進行當前tile內該材質的著色。
*這裡主要介紹了材質渲染的tile化,而visbuffer中存儲ID上個系列中也介紹過了。

渲染可形變的網格是遊戲中不可避免的需求。以蒙皮網格為例:在動畫中,每個集群的邊緣一直在變化,使預計算的LOD邊緣或剔除都不準確了;而實時的基於頂點邊界的計算又開銷太大。
So, we need special handling for skinned meshes. The approach is dynamic bound box calculation and culling based on clusters in the main bone space.
因此我們需要針對蒙皮網格的特殊處理。這一方案是基於主要骨骼空間集群的動態包圍盒計算與剔除。
*這裡的詞組有點繞,後面馬上會展開介紹。
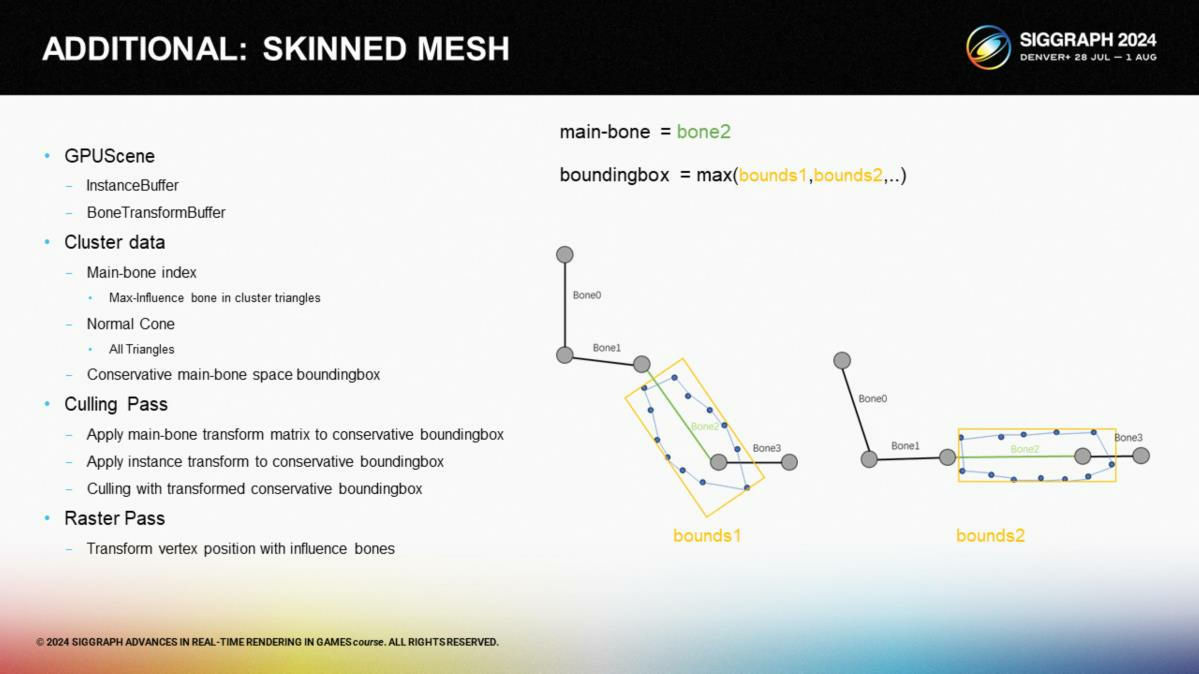
Offline, we compute each cluster's main bone, normal cone, and a conservative bounding box in the main bone space. The main bone is the one with the highest vertex weight in the cluster. The normal cone is the average normal of all cluster triangles, with a cone angle covering them all. The bound box covers the cluster's maximum range in the main bone space across all animations.
在離線時,我們計算每個集群的主要骨骼、 法向錐體以及一個主要骨骼空間的保守(conservative)包圍盒。這裡主要骨骼指有著最高的頂點權重的骨骼。法向錐體代表了集群中所有三角形的法線的平均值,以一個錐體角度來覆蓋它們。而包圍盒覆蓋了集群在主要骨骼的所有動畫中的最大包圍盒範圍。
Runtime, the CPU sends bone transform data to the GPU. During cluster culling, it reads the bone transform, transforms the conservative bound box to mesh space, then proceeds with normal cluster culling. Skinning rasterization follows normal skeletal animation calculations.
在運行時,CPU把骨骼形變數據傳遞給GPU。在集群剔除階段,從中讀取骨骼形變數據,並把保守包圍盒變換到對應的網格空間中,之後再通過常規網格集群剔除的方案執行。蒙皮的光柵化遵循普通骨骼動畫的計算方式(*指不通過visbuffer的方式)。
*這裡提出的一個經驗性的方案就是離線預計算所有動畫情況的保守包圍盒。

無縫渲染,基於它的固有特性,需要在光照計算上的特定實現與優化。例如,當計算全局光照時,我們需要考慮lightmap能否使用,以及其精度能否覆蓋像素級的三角形,這些因素都會顯著影響內存和存儲。因此,我們實現了一套全動態的GI算法。
*相比於網格技術而言,這裡的GI無疑是與lumen不同的完全面向輕量化的無縫渲染方案。
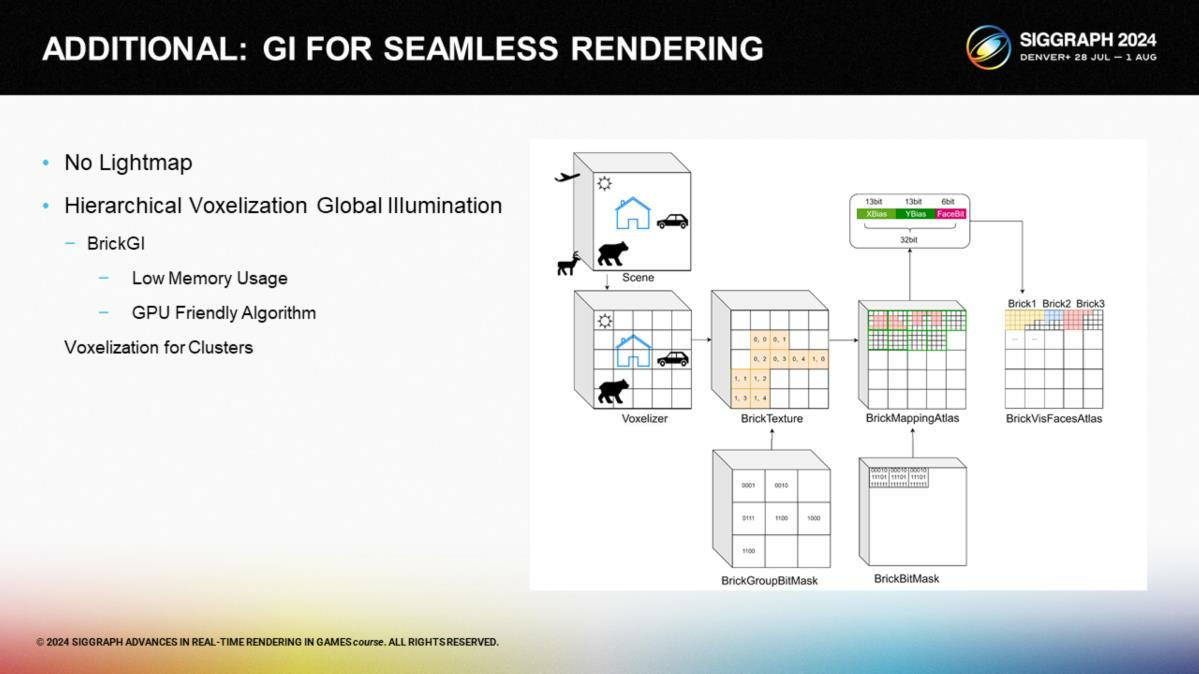
這項GI算法利用了一個多層的基於體積的方案(hierarchical voxel-based approach)。它通過把場景劃分成塊並體素化,之後利用這些塊和提煉出的體素進行快速的raymarching計算。
其中BrickTexture紋理存儲BrickData在BrickMappingAtlas中的偏移。BrickMappingAtlas存儲體素數據在VisFaceAtlas中的偏移。
*這裡設計了一種利用紋理做多層索引的形式,具體組織方式及哪些是三維的,可以從圖中看出。核心的GI思想就是體素級別的快速追蹤。

*這裡展示了默認的配置參數。

這裡展示了我們如何從塊和visfacelightingatlas中獲得光照數據的偽代碼。當進行ray tracing時(這裡追蹤的不是世界空間而是紋理空間,更接近通過數據追蹤),第一步需要通過對brickgroupbitmask的快速查詢來確定哪一個塊所在的組是有效的——這需要一個uint64的採樣操作。如果遮罩值不是0,就說明當前的塊所在的組包含了有效的塊,我們可以通過檢測哪些bits被設置過來確定有效的體素塊。
After locating the brickindex through the combination of the bitmask and the sampleposition, it is straightforward to convert this index into bricktexcoord, allowing us to query the actual bias stored for the brick in the bricktexture. Subsequently, we utilize both the brickbitmask and the sampleposition to continue with a rapid ray marching process, which identifies the valid voxelcoord within the brick. Then, in the brickmappingatlas, we locate the offset of the voxel within the visfaceatlas, and proceed to read the relevant lightingdata.
通過組合bitmask和採樣位置,可以定位到塊的索引——之後就能直接轉換成塊的紋理座標,這允許我們直接查詢實際在bricktexture存儲的塊的偏移。這之後,我們同時利用brickbitmask和採樣位置來繼續執行一次快速的ray marching過程,以確定塊的內部有效的體素紋理座標。然後,在brickmappingatlas內部,我們定位體素在visfaceatlas中的偏移值,並讀取相關的光照數據。
*這裡可能有點繞,但最終實際上就是逐層定位到一個體素的光照數據。對於光照數據的結構,後面有具體展示。

*這裡展示瞭如何從brickmask得到有效的塊的偽代碼。核心思路就是按位計算索引。

讓我們比較brickgi和lightmap方案在移動端的性能。在這個測試中,我們添加了超過100個物體,每個包含一個1024x1024精度的lightmap,在一個512x512米的大場景中。實驗結果表明lightmap需要至少160MB的內存開銷,而brickgi只需要30MB。
另外,brickgi的GPU時間輕微的高於lightmap方案,3ms在大部分移動設備上仍被視為一個可接受的指標。

圖表展示了30MB內存具體是如何分配以覆蓋512米的場景的。此外,高精度的三角形集群不需要體素化計算,這使整體的體素化開銷較低。
*可以看到具體的體素存了Albedo、Normal、Lighting、Emissive這4個通道的光照用數據。另外,“高精度的三角形集群不需要體素化計算”這個結論不那麼容易得出,雖然我也有一些自己的猜想,不過還是感覺作者缺少了相應的鋪墊。

低精度的集群在光柵化過程中則能更容易地體素化。

對於直接光照計算,我們的測試過程表明在生成陰影深度時高精度集群是非必須的。使用粗粒度的估計對視覺質量的影響較小,但卻能顯著提升性能。
*右側圖片展示了陰影繪製時使用LOD0和2之間的drawcall差距。

上方的圖片展示了200個drawcall時的陰影紋理,而下方則是100個drawcall的。它們的區別是微乎其微的。另外,使用shadow caching也是最高效的的方法之一。
*shadow caching是一種shadowmap的分幀緩存複用方案。現代引擎的shadowmap一定程度上都會做緩存。

*作者未來的優化方向與特性開發方向。可以看到截至發分享的時候,針對高端設備例如PC的管線開發還沒有(軟件VRS、光追、MeshShader、Bindless之類)。
三、優勢與性能表現
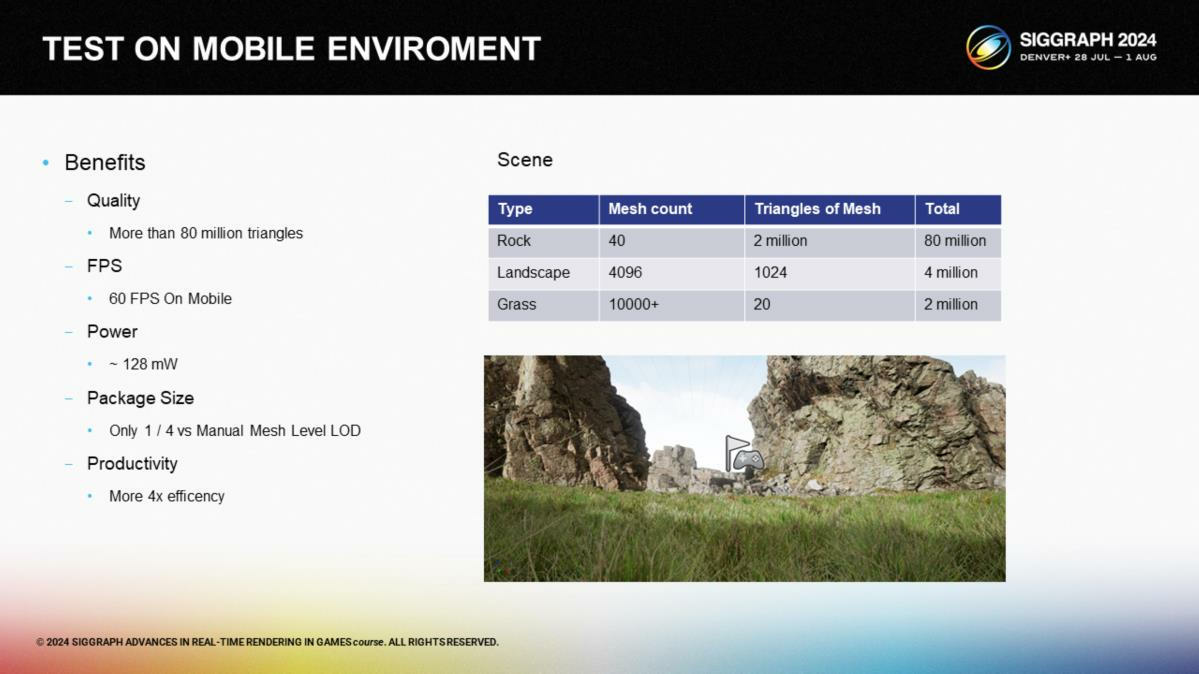
*圖中展示了一些性能上的優勢,例如比起手動LOD方案只佔用1/4的存儲空間,以及比起不定製的傳統管線有極大性能提升。
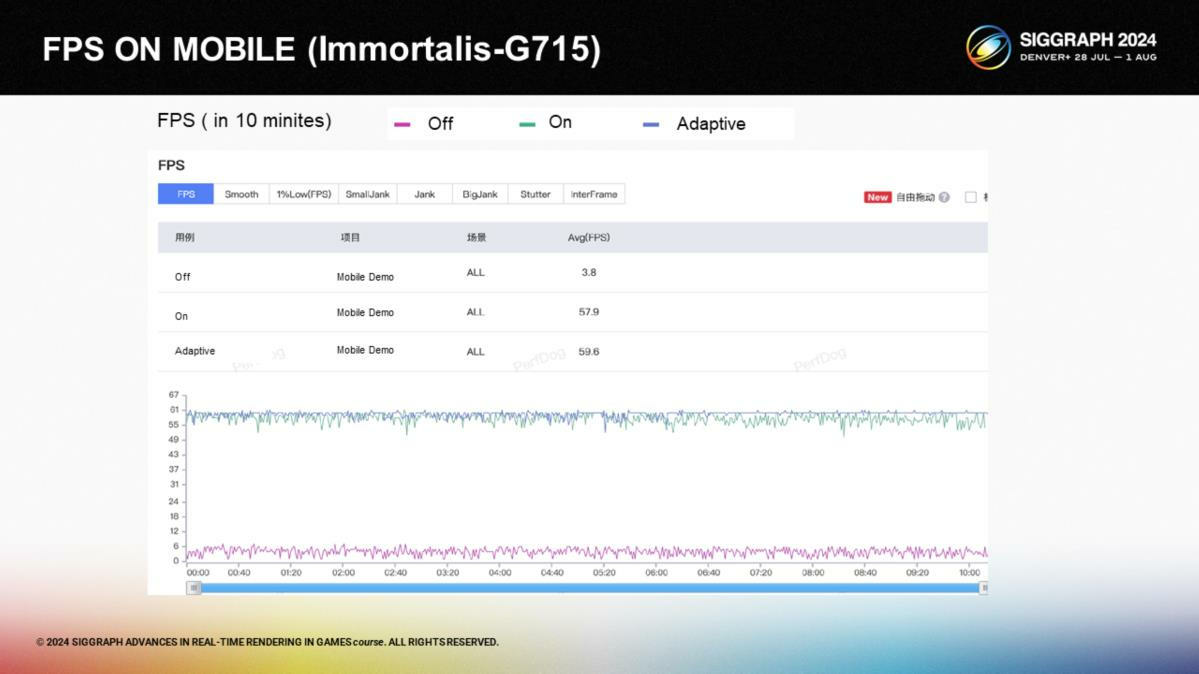
*圖中展示了用固有管線和改裝後管線的幀率對比。
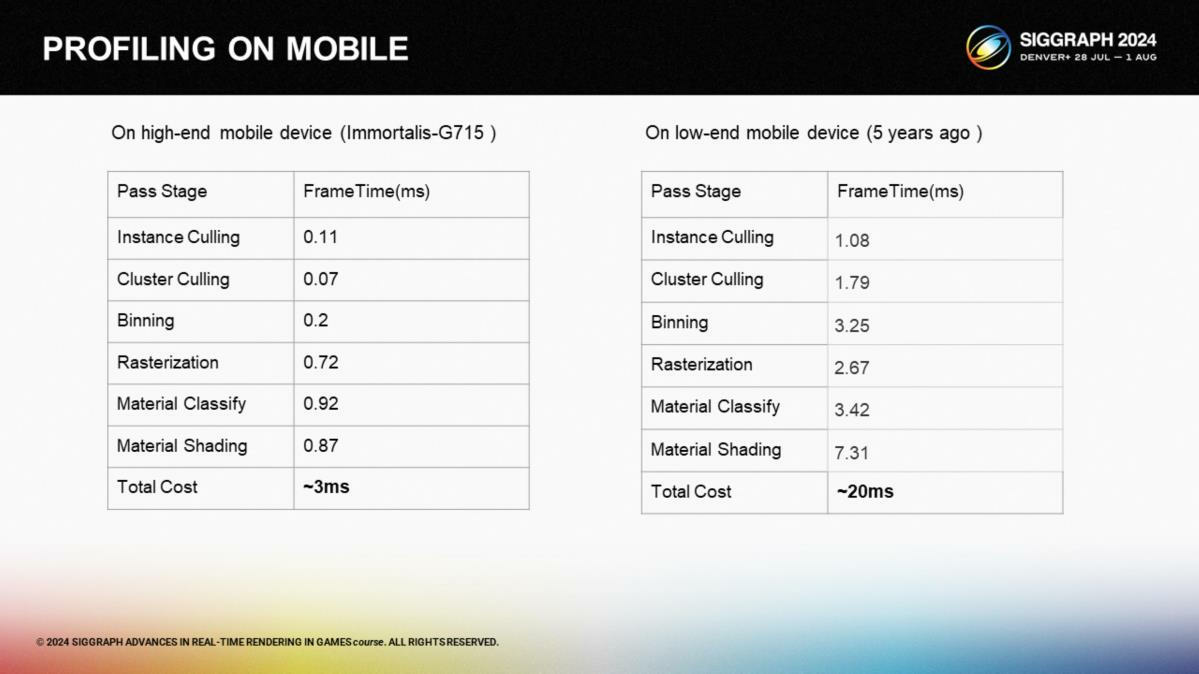
*幀時間對比,主流機型3ms,5年前的機型20ms。
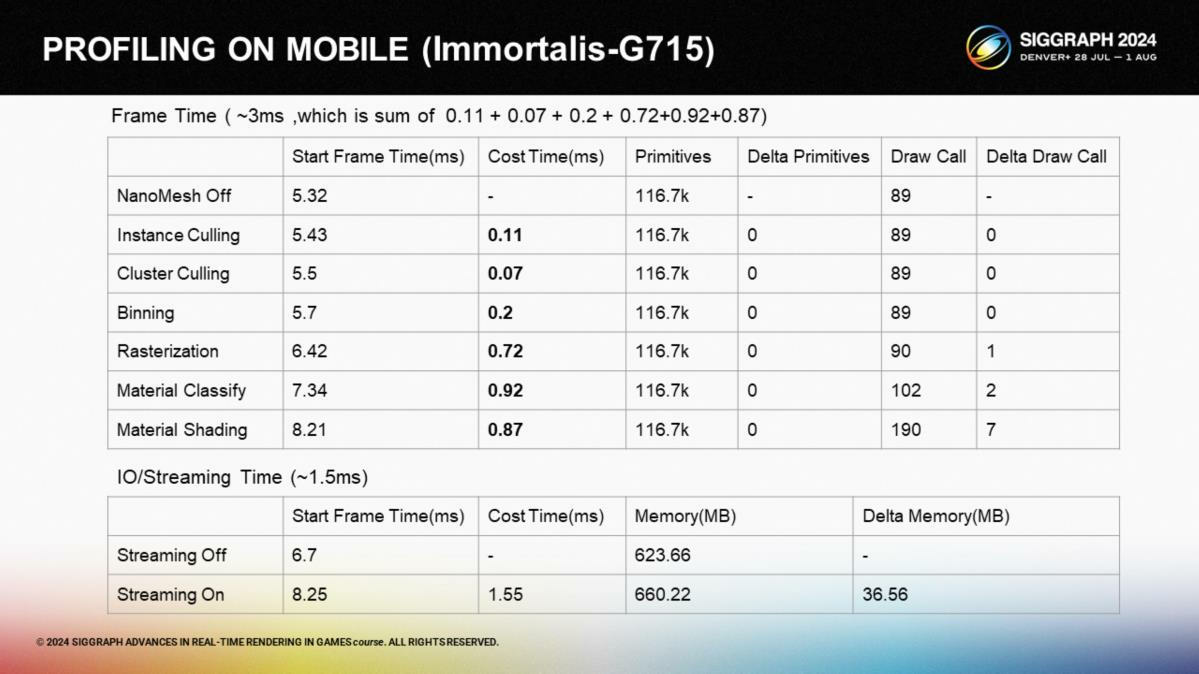
*主流機型上的性能開銷階段拆分。其中光柵化和材質著色相對耗時更多。
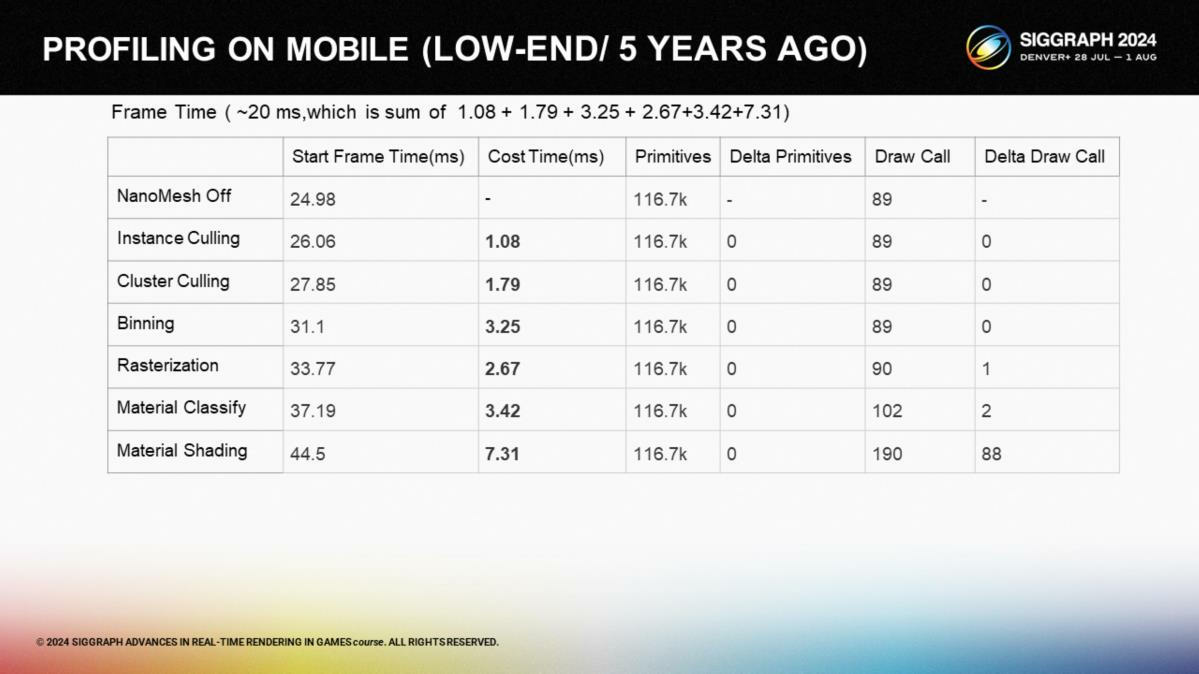
*舊機型上的性能開銷階段拆分。其中材質著色顯著耗時更長。
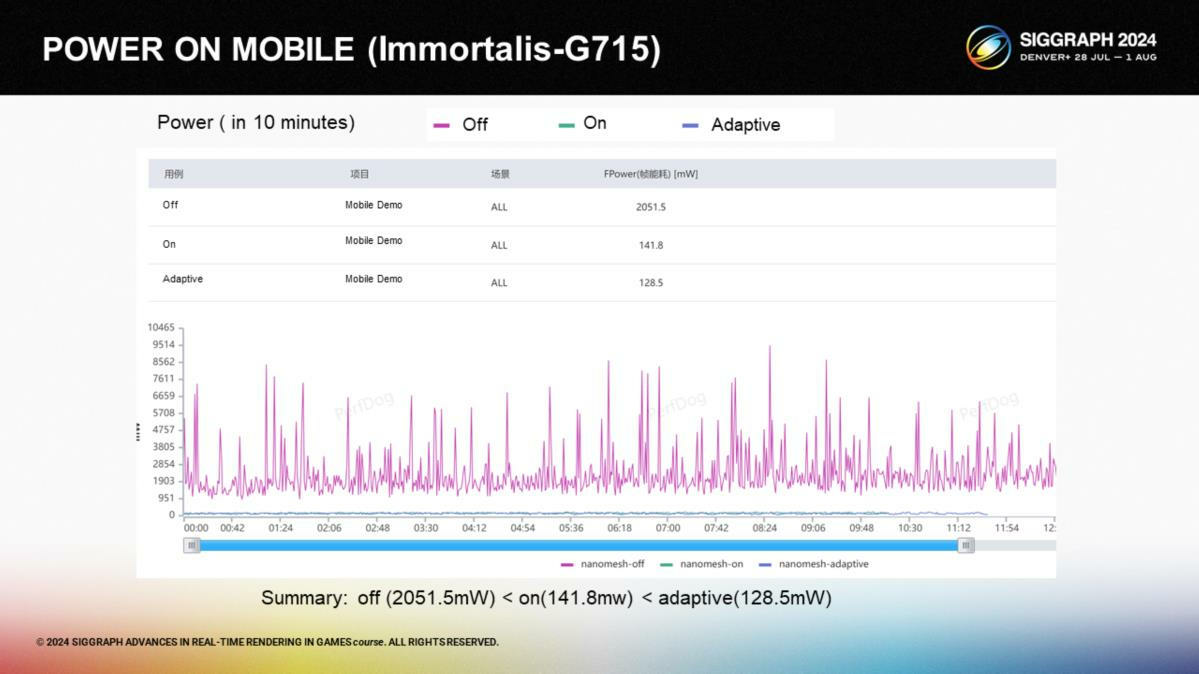
*10分鐘耗電量統計。按作者的說法這套管線會比傳統的網格渲染方式略微省電一些。
結語
總結一下,整個技術方案的動態網格技術屬於Nanite技術棧的衍生版,而全動態的GI則是基於體素追蹤,在材質著色上則設計了一套方案以利用GPU的tile架構。
整個技術方案還有不少指標處於研究階段和實際商品化遊戲的臨界值上——例如真實的遊戲還會有更多角色、UI、特效和複雜邏輯。不過在世界範圍內,把主機級的渲染技術逐步下沉到移動端,這個可以說是我國遊戲行業彎道超車世界的一個方向了。
無論是騰訊、網易還是其它大廠,其在移動端的開發能力無疑是領先世界的,其合作方的很多手遊項目也都是聯合開發完成的——大一點的例如《決勝時刻 手遊版》《暗黑破壞神 不朽》等。
人們通常會詬病這些產品中的一些商業化配套設計——雖然我也認為目前手遊的商業模式已經到了比較危險的邊緣,但單從技術實現角度來看,這些大IP的移動端作品確實是最大限度還原了所屬IP遊戲的視覺要素。而且其實稍微主流的移動端設備其實是有著不輸於NS的性能的,很多時候沒法比較的其實是屏幕大小、遊玩場合、操作模式、耗電量等等外在的要素。
無論如何,騰訊的大世界項目明年就要出來了,人們到底是否需要在移動端有那麼高的畫質,以及之後多端的大型網遊中的移動端到底是利好還是拖累,我覺得後面一年的一些項目就是一個分水嶺——讓我們拭目以待。
最後是資料鏈接:
Seamless Rendering on Mobile: The Magic of Adaptive LOD Pipeline的PDF