前言
这周读一篇短篇,看看2024年腾讯的技术大牛Shun Cao
在SIG上分享的一篇移动端NanoMesh管线方案。
自虚幻5引擎的Nanite网格技术框架工业化,以及被越来越多的商业化产品试错并验证,最新的引擎技术总归离不开如何处理海量多边形来渲染大世界的问题——最近的就有《怪物猎人 荒野》的RE引擎。
整体的大思路肯定是网格集群化,以及自动、动态的LOD系统;而细节的部分,让我们跟随作者的分享,来看看各个步骤都是如何设计以及实现的。另外,原文并没有章节划分,这里我是大概划分了几个部分,并突出其中管线实现的部分。
本文还是以翻译原文PPT页及解说稿为主,打星号的部分则是我个人的补充。
一、平台现状

让我们以图中的例子作为演示:其中的场景包含了八千万多边形,并实现了在移动端渲染。我们仅在开发过程使用高精度资源,但在渲染时,我们控制了三角形集群的颗粒度(granularity)——基于屏幕投影面积以及到摄像机的距离来渲染集群的级别,确保在不同的GPU上都有合适的效果。
*类似Nanite,这里说的三角形数都是指原始数量,不是实际运行时的三角形数。实际运行最多也不会超过屏幕像素的规模,而且往往会以低一些的分辨率来渲染。

主机与移动端管线对比
然而,对比桌面端、主机端和移动端,主流的移动端设备缺乏很多硬件和软件上必要的要实现无缝渲染的特性——例如渲染管线的限制,mesh shader的支持以及无绑定的特性(bindless features 之前也介绍过无绑定的一些好处);带宽和IO在性能方面也有很大影响;另外,移动端也有其自身特色的基于tiled的GPU架构(屏幕分块并行)。
*tiled base GPU architecture之前介绍过,是一种把屏幕分块来利用多核渲染的架构。
二、管线框架细节

因此,如何在这些限制下进行无缝集群渲染呢?我们集中在简化和效率方面,尽量降低对于硬件的依赖和带宽的需要。
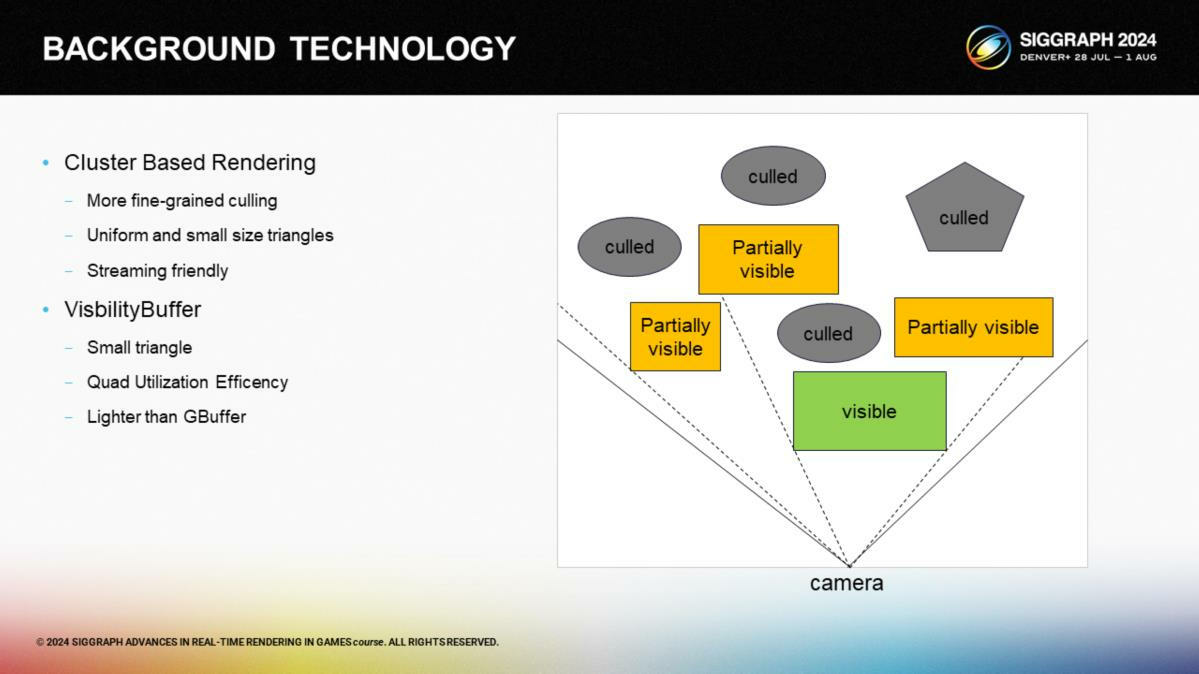
在拆分技术细节之前,让我们迅速回顾一下背景知识。
首先,基于集群的渲染与遮挡剔除(Cluster-based Rendering: Occlusion culling)在现代的游戏中很常见了,通过直接做多边形的剔除来解决过渡绘制的问题。但巨大的物体即使局部可见也往往被全部渲染了。
通过将原始网格划分到小的集群,并按集群作为剔除的单位,GPU可以略过大量无效三角形;对于集群内的少量三角形,我们可以降低顶点索引的精度,例如使用8bits;我们也可以根据包围盒来按需加载集群,进一步提升GPU显存的利用率。
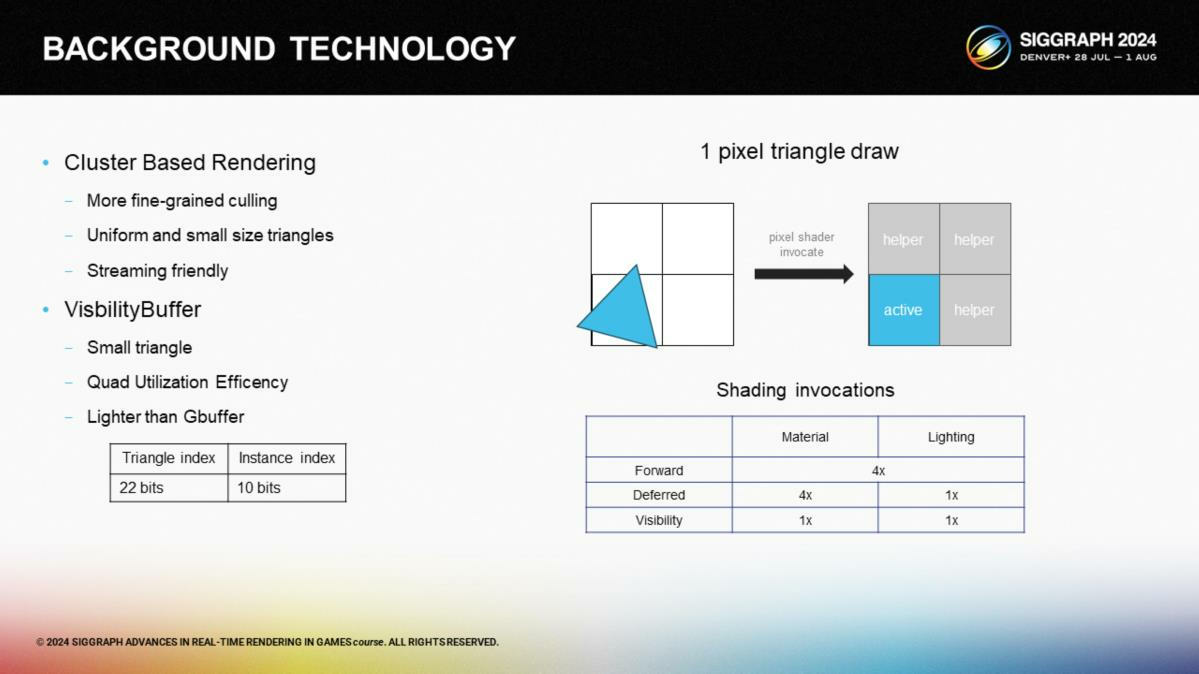
第二项相关的技术是可见性缓冲(Visbuffer)。当渲染三角形时,可见性缓冲方式提供了比前向渲染或延迟渲染更好的Quad效用,仅需要消耗32 bits的额外开销。John Hable也会在这次的讲座中提到可见性缓冲的话题。
*这里可以联动上次读的系列文章。如果没有看过的话,简单说一下这里Quad是指GPU一次处理4个矩形像素的一种架构,对于大三角形是有利的,对于微小三角形是不利的。

*这里列出了作者的一些参考资料。最早能追溯2017年左右《刺客信条 大革命》提出网格集群方案的时候。
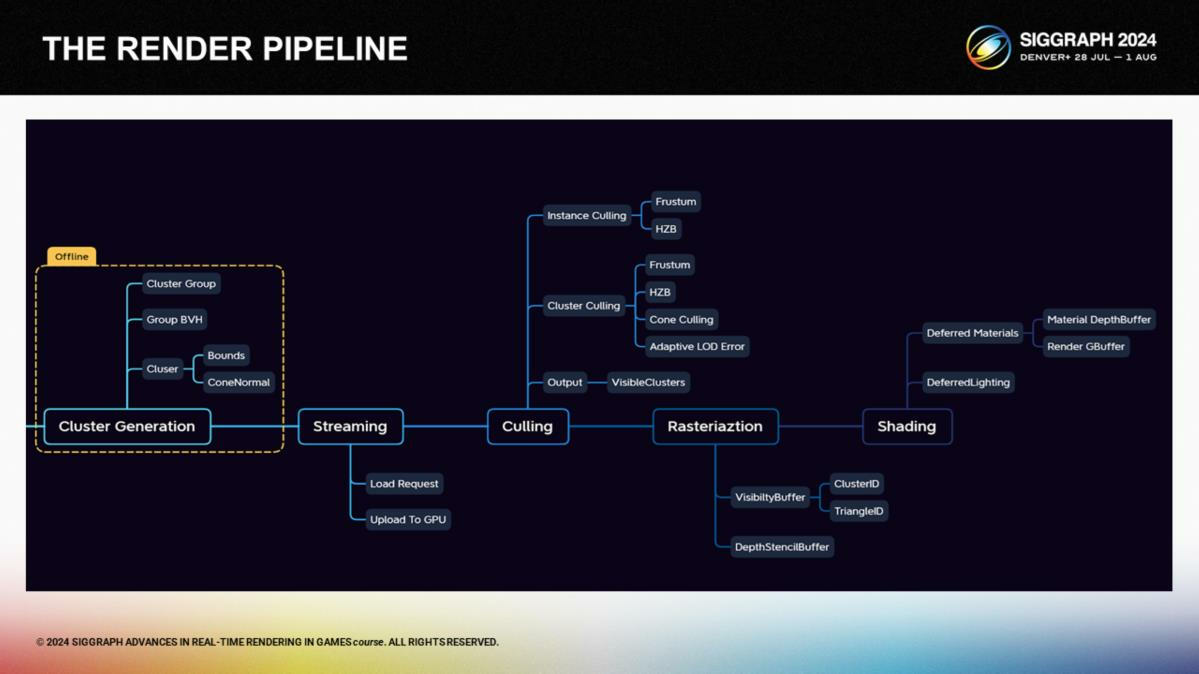
在介绍了背景技术知识后,让我们看看渲染管线的架构。管线包括两个部分:离线处理和运行时。
离线阶段导入并生成自定义的集群数据,而运行时包含streaming、剔除、光栅化和着色。
*基本思路和Nanite是一致的,后续主要看移动端实现。

在离线处理的部分,在所有步骤之前我们首先重新设计了网格存储的结构。相比于传统的多级LOD或简化集群,我们把网格拆分成多个集群,并连续地把它们重组成新的更粗粒的级别的集群,以相似的方式迭代多次。
它和UE5的Nanite类似,但我们添加了一个合并系数函数来确保能对资源及手动网格LOD进行一定的人工控制。这使多级集群数据更精简,能更好支持剔除或streaming使的数据结构需求。
对于每个集群,我们储存了它的包围盒和法向锥体(normal cone)以便更高效地进行遮挡和背面剔除。每个集群有最多128个三角形,因此我们可以通过8 bits来存储索引以节省空间。对于非叶子节点(non-leaf nodes),我们记录为合并时的误差项。
*简单来说就是要做得比Nanite的集群和LOD更省,以应对移动端。
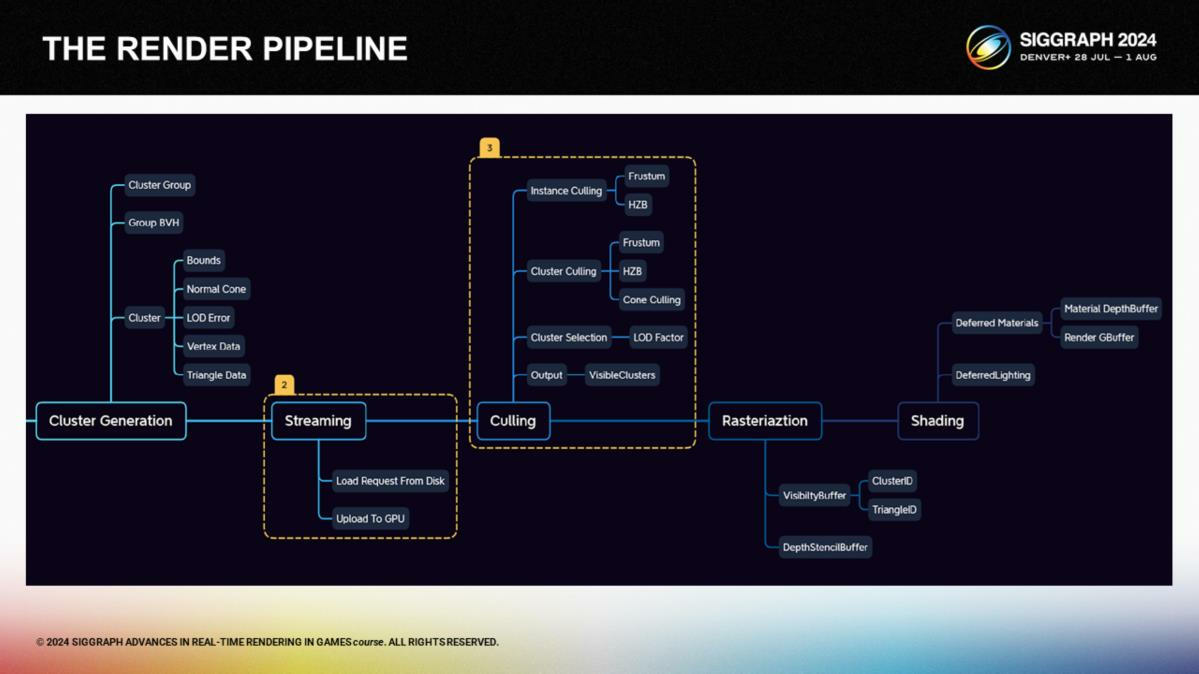
下一步是streaming和剔除阶段。Streaming从最粗粒的集群实例开始,之后根据剔除pass的输出进行按需加载。
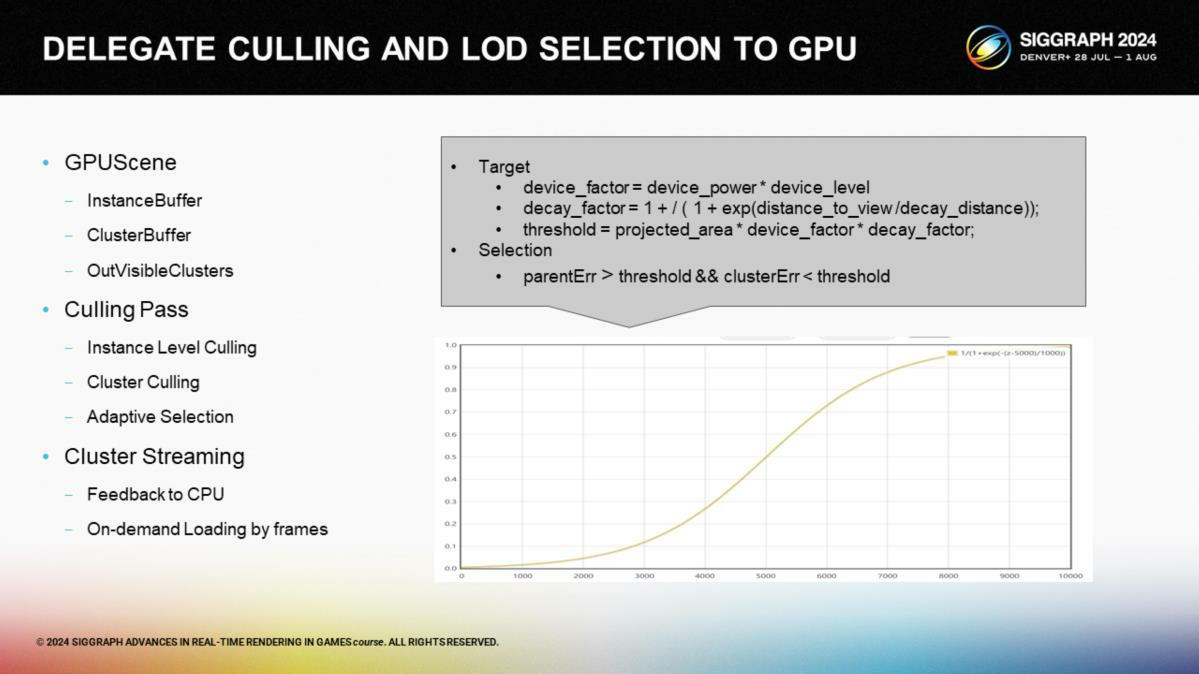
在剔除阶段,我们让GPU来处理集群控制和选择。物体被存储在一个实例缓存中,集群在集群缓存中,而经过剔除计算输出的ID则写入一个可见集群的缓存。集群缓存自动地基于GPU的选择进行动态加载。
在剔除步骤的一开始进行一个快速的实例级别的HZB剔除(instance-level culling *Hiz方案介绍过多次了,这里比对的是实例包围盒与多层深度缓冲),之后应用例如视锥剔除、遮挡剔除和基于法向锥的背面剔除。我们使用了和Nanite近似的误差方案来计算集群LOD剔除,不过我们设计了一个基于距离的曲线来作为LodFactor选择系数,来确保近处的高精度和远处使用粗粒三角形——模仿手动LOD控制的过程。
*这里的culling虽然翻译成剔除,实际负责的计算还包括LOD选择等。
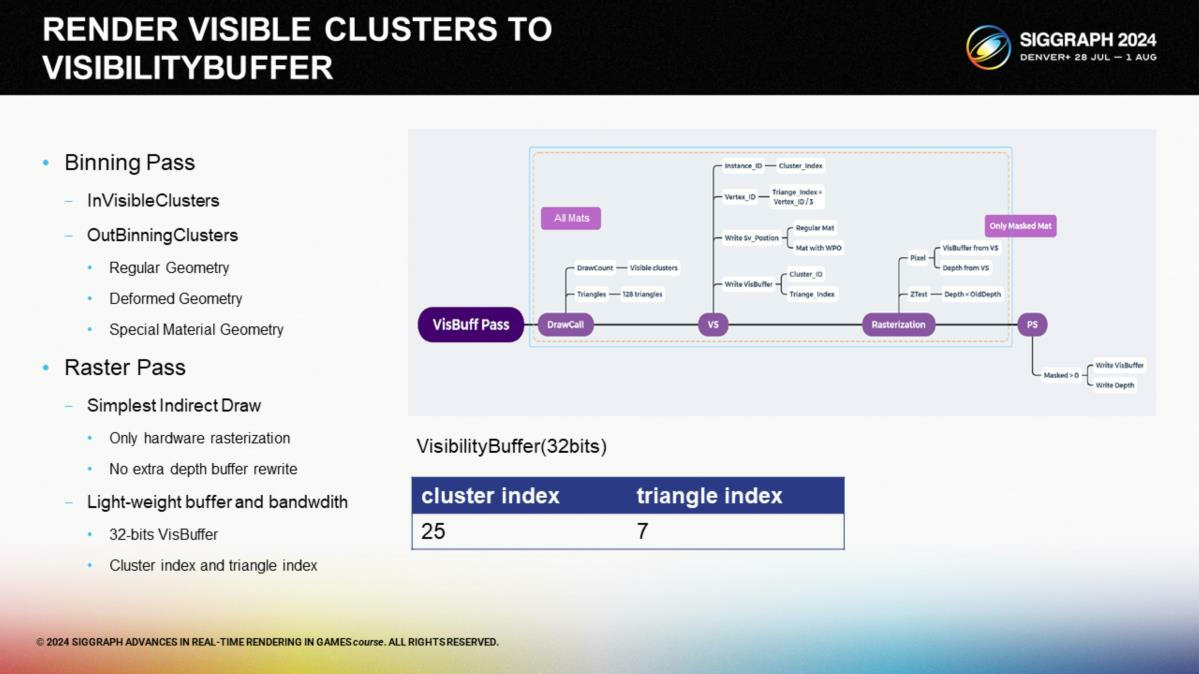
在光栅化阶段,为降低电量消耗和GPU用量,我们将中间的渲染结果以32-bit的visbuffer来存储。理想状态下,一个draw call就可以把一个集群的所有三角形写入visbuffer。
为利用GPU的并行特性,我们将物体归类:类型1在顶点着色器中记录集群和三角形ID,跳过像素着色计算;类型2,例如蒙皮网格(skinned meshe),顶点着色器中通过骨骼信息重计算顶点坐标;类型3,例如有alpha遮罩的植物,过滤器的visbuffer在像素着色中基于遮罩纹理来生成。
We avoid soft rasterization due to extra scene depth passes, lack of atomic64 support, and higher bandwidth from 64-bit visbuffers.
由于额外的场景深度缺乏64位的支持和64位visbuffer的更高带宽需要,我们避免了使用软件光栅化。
因为我们是基于集群而不是实例进行渲染,7 bits的空间对于三角形就足够了,以节省空间给集群的存储。

由于无绑定方式(bindless)还不被移动端的设备支持,为实现材质着色,我们需要每个材质单独用一个drawcall进行渲染。由于通常来说单个材质覆盖整个屏幕的情况比较少,因此我们把屏幕划分成很多小的tile,每个材质有其自身的tile列表。
通过这种方式,在渲染时我们不需要每个材质都渲染整个屏幕。在每一个tile的渲染中,我们通过visbuffer中集群信息存储的materialID与当前着色的ID进行比较,仅当两者匹配时才进行当前tile内该材质的着色。
*这里主要介绍了材质渲染的tile化,而visbuffer中存储ID上个系列中也介绍过了。

渲染可形变的网格是游戏中不可避免的需求。以蒙皮网格为例:在动画中,每个集群的边缘一直在变化,使预计算的LOD边缘或剔除都不准确了;而实时的基于顶点边界的计算又开销太大。
So, we need special handling for skinned meshes. The approach is dynamic bound box calculation and culling based on clusters in the main bone space.
因此我们需要针对蒙皮网格的特殊处理。这一方案是基于主要骨骼空间集群的动态包围盒计算与剔除。
*这里的词组有点绕,后面马上会展开介绍。
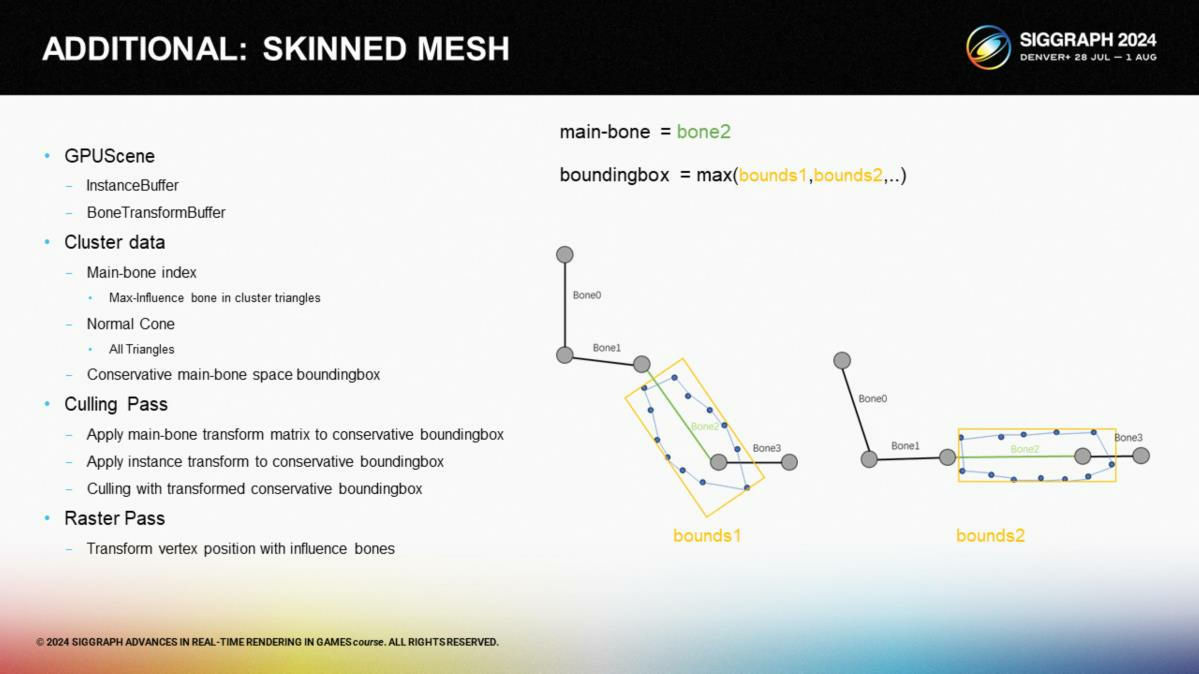
Offline, we compute each cluster's main bone, normal cone, and a conservative bounding box in the main bone space. The main bone is the one with the highest vertex weight in the cluster. The normal cone is the average normal of all cluster triangles, with a cone angle covering them all. The bound box covers the cluster's maximum range in the main bone space across all animations.
在离线时,我们计算每个集群的主要骨骼、 法向锥体以及一个主要骨骼空间的保守(conservative)包围盒。这里主要骨骼指有着最高的顶点权重的骨骼。法向锥体代表了集群中所有三角形的法线的平均值,以一个锥体角度来覆盖它们。而包围盒覆盖了集群在主要骨骼的所有动画中的最大包围盒范围。
Runtime, the CPU sends bone transform data to the GPU. During cluster culling, it reads the bone transform, transforms the conservative bound box to mesh space, then proceeds with normal cluster culling. Skinning rasterization follows normal skeletal animation calculations.
在运行时,CPU把骨骼形变数据传递给GPU。在集群剔除阶段,从中读取骨骼形变数据,并把保守包围盒变换到对应的网格空间中,之后再通过常规网格集群剔除的方案执行。蒙皮的光栅化遵循普通骨骼动画的计算方式(*指不通过visbuffer的方式)。
*这里提出的一个经验性的方案就是离线预计算所有动画情况的保守包围盒。

无缝渲染,基于它的固有特性,需要在光照计算上的特定实现与优化。例如,当计算全局光照时,我们需要考虑lightmap能否使用,以及其精度能否覆盖像素级的三角形,这些因素都会显著影响内存和存储。因此,我们实现了一套全动态的GI算法。
*相比于网格技术而言,这里的GI无疑是与lumen不同的完全面向轻量化的无缝渲染方案。
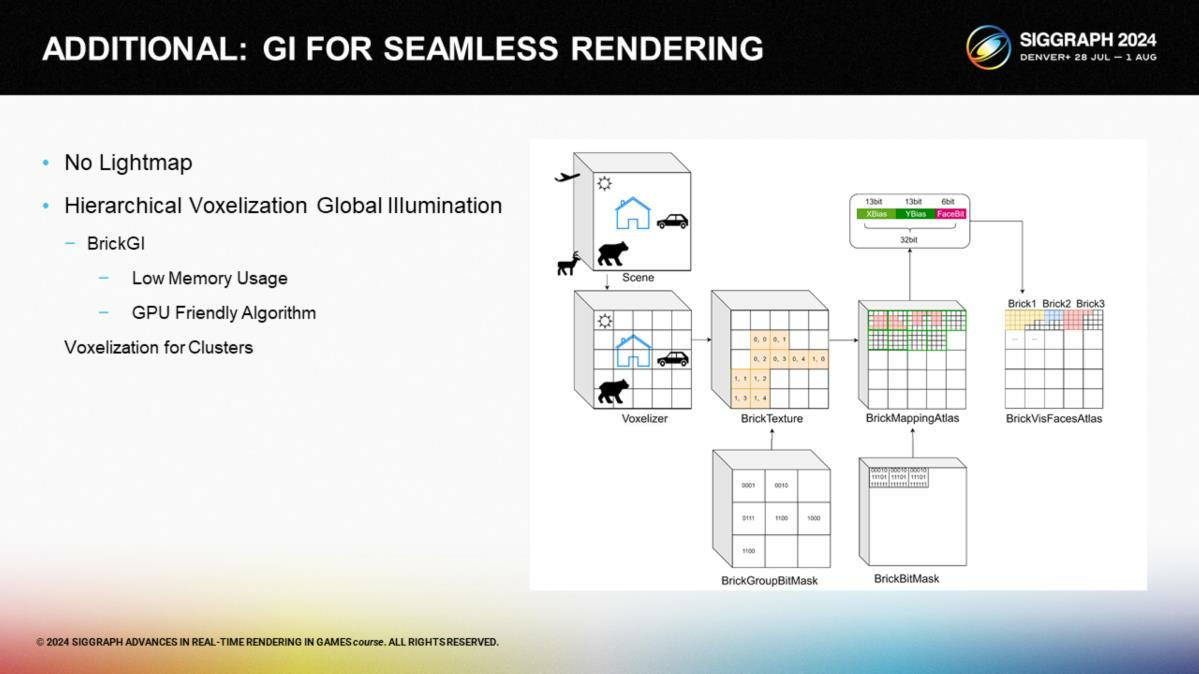
这项GI算法利用了一个多层的基于体积的方案(hierarchical voxel-based approach)。它通过把场景划分成块并体素化,之后利用这些块和提炼出的体素进行快速的raymarching计算。
其中BrickTexture纹理存储BrickData在BrickMappingAtlas中的偏移。BrickMappingAtlas存储体素数据在VisFaceAtlas中的偏移。
*这里设计了一种利用纹理做多层索引的形式,具体组织方式及哪些是三维的,可以从图中看出。核心的GI思想就是体素级别的快速追踪。

*这里展示了默认的配置参数。

这里展示了我们如何从块和visfacelightingatlas中获得光照数据的伪代码。当进行ray tracing时(这里追踪的不是世界空间而是纹理空间,更接近通过数据追踪),第一步需要通过对brickgroupbitmask的快速查询来确定哪一个块所在的组是有效的——这需要一个uint64的采样操作。如果遮罩值不是0,就说明当前的块所在的组包含了有效的块,我们可以通过检测哪些bits被设置过来确定有效的体素块。
After locating the brickindex through the combination of the bitmask and the sampleposition, it is straightforward to convert this index into bricktexcoord, allowing us to query the actual bias stored for the brick in the bricktexture. Subsequently, we utilize both the brickbitmask and the sampleposition to continue with a rapid ray marching process, which identifies the valid voxelcoord within the brick. Then, in the brickmappingatlas, we locate the offset of the voxel within the visfaceatlas, and proceed to read the relevant lightingdata.
通过组合bitmask和采样位置,可以定位到块的索引——之后就能直接转换成块的纹理坐标,这允许我们直接查询实际在bricktexture存储的块的偏移。这之后,我们同时利用brickbitmask和采样位置来继续执行一次快速的ray marching过程,以确定块的内部有效的体素纹理坐标。然后,在brickmappingatlas内部,我们定位体素在visfaceatlas中的偏移值,并读取相关的光照数据。
*这里可能有点绕,但最终实际上就是逐层定位到一个体素的光照数据。对于光照数据的结构,后面有具体展示。

*这里展示了如何从brickmask得到有效的块的伪代码。核心思路就是按位计算索引。

让我们比较brickgi和lightmap方案在移动端的性能。在这个测试中,我们添加了超过100个物体,每个包含一个1024x1024精度的lightmap,在一个512x512米的大场景中。实验结果表明lightmap需要至少160MB的内存开销,而brickgi只需要30MB。
另外,brickgi的GPU时间轻微的高于lightmap方案,3ms在大部分移动设备上仍被视为一个可接受的指标。

图表展示了30MB内存具体是如何分配以覆盖512米的场景的。此外,高精度的三角形集群不需要体素化计算,这使整体的体素化开销较低。
*可以看到具体的体素存了Albedo、Normal、Lighting、Emissive这4个通道的光照用数据。另外,“高精度的三角形集群不需要体素化计算”这个结论不那么容易得出,虽然我也有一些自己的猜想,不过还是感觉作者缺少了相应的铺垫。

低精度的集群在光栅化过程中则能更容易地体素化。

对于直接光照计算,我们的测试过程表明在生成阴影深度时高精度集群是非必须的。使用粗粒度的估计对视觉质量的影响较小,但却能显著提升性能。
*右侧图片展示了阴影绘制时使用LOD0和2之间的drawcall差距。

上方的图片展示了200个drawcall时的阴影纹理,而下方则是100个drawcall的。它们的区别是微乎其微的。另外,使用shadow caching也是最高效的的方法之一。
*shadow caching是一种shadowmap的分帧缓存复用方案。现代引擎的shadowmap一定程度上都会做缓存。

*作者未来的优化方向与特性开发方向。可以看到截至发分享的时候,针对高端设备例如PC的管线开发还没有(软件VRS、光追、MeshShader、Bindless之类)。
三、优势与性能表现
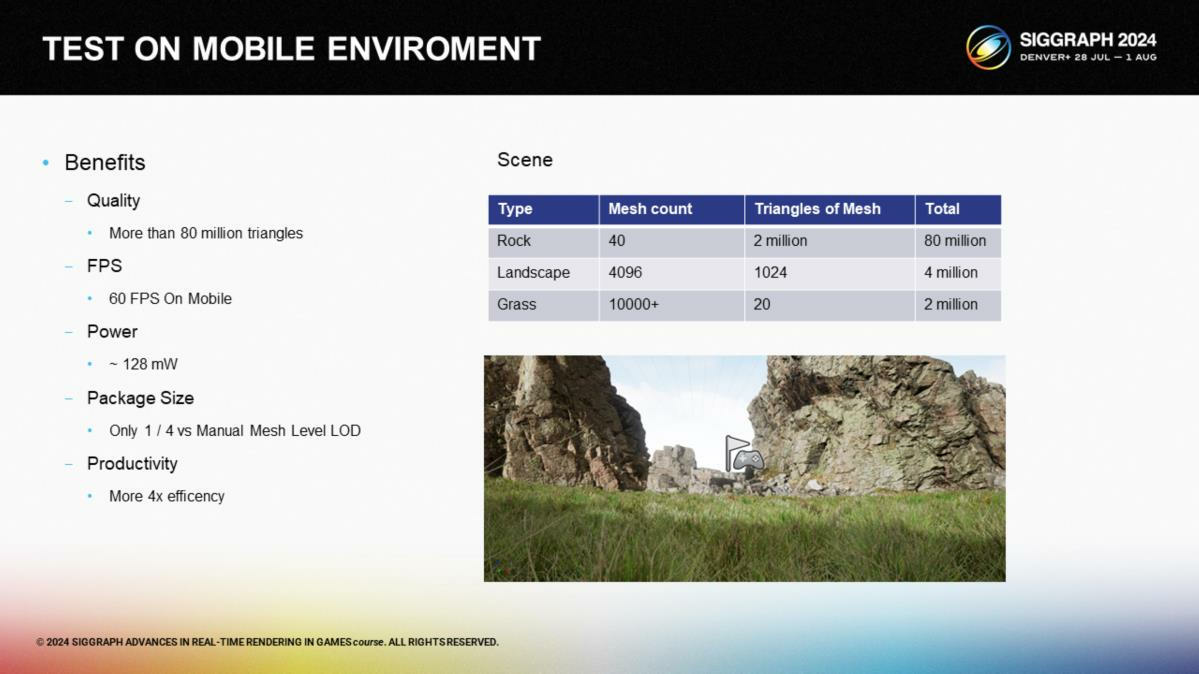
*图中展示了一些性能上的优势,例如比起手动LOD方案只占用1/4的存储空间,以及比起不定制的传统管线有极大性能提升。
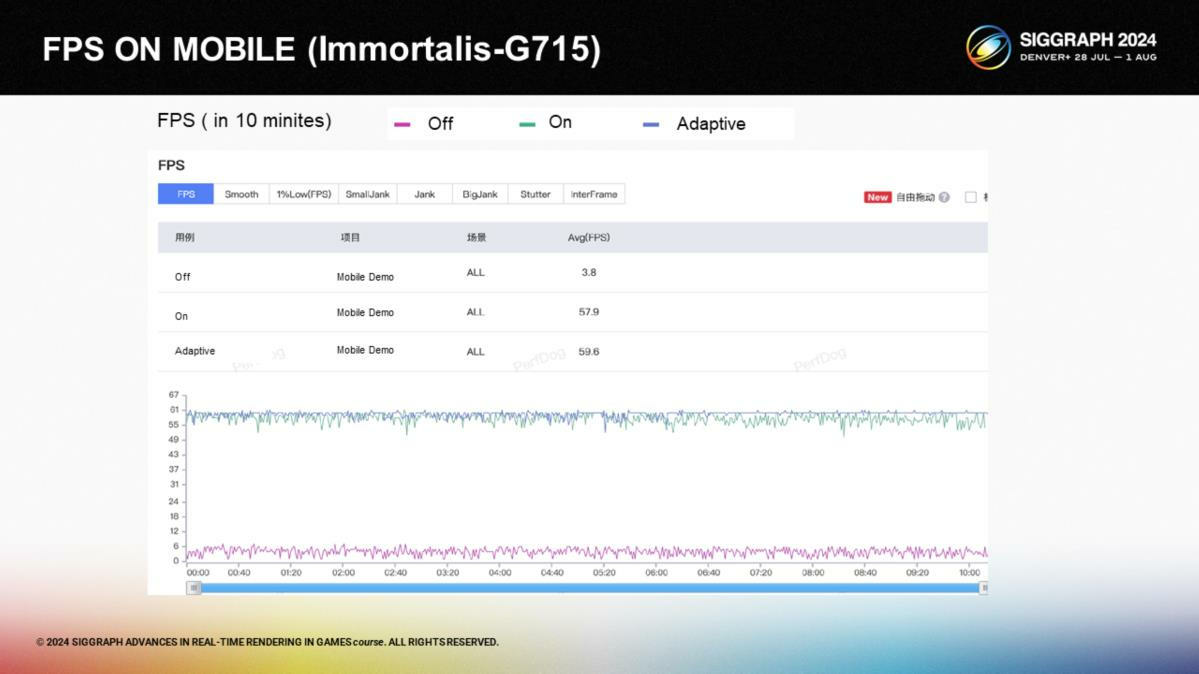
*图中展示了用固有管线和改装后管线的帧率对比。
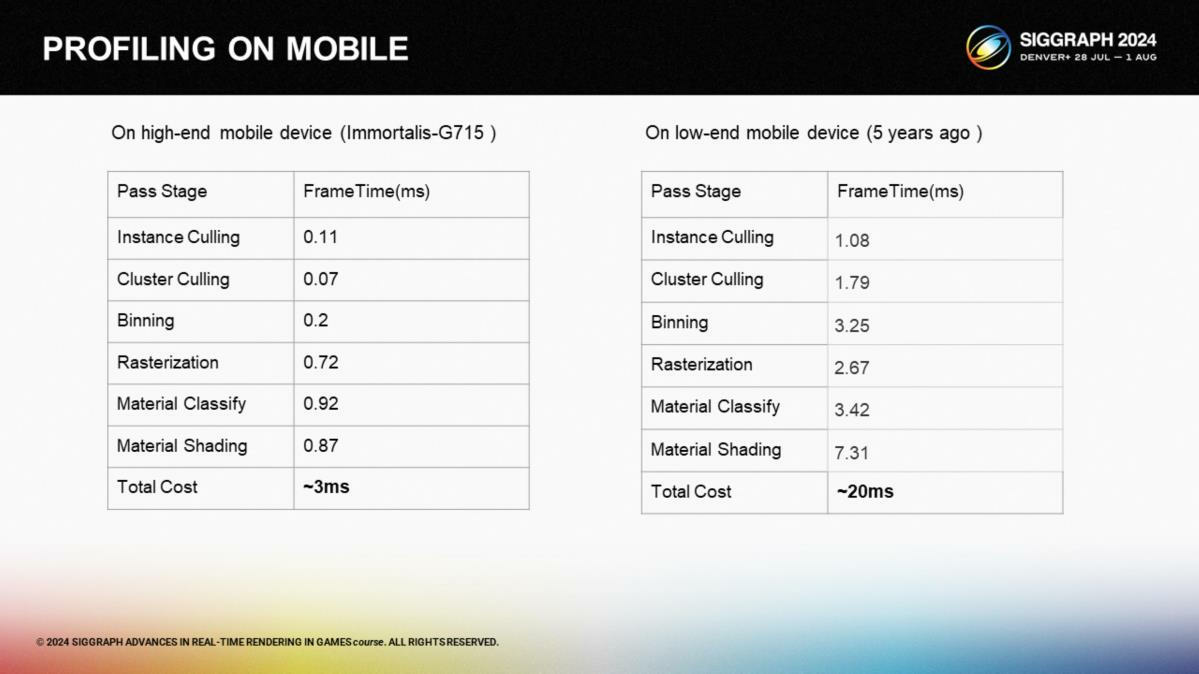
*帧时间对比,主流机型3ms,5年前的机型20ms。
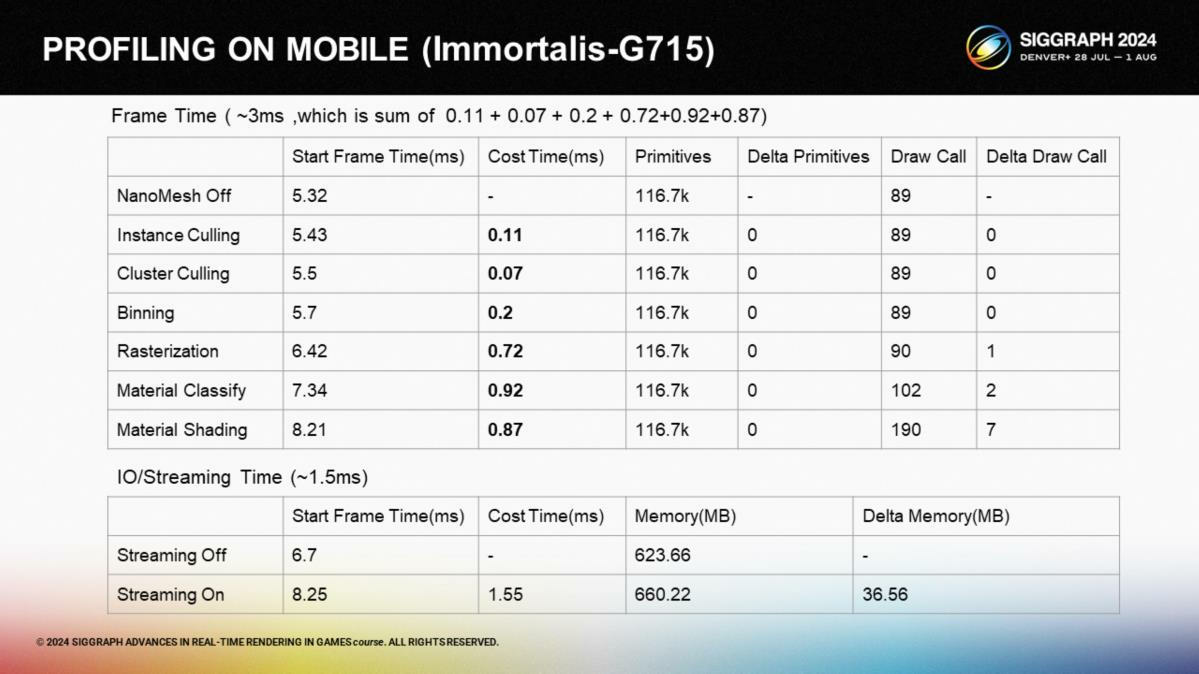
*主流机型上的性能开销阶段拆分。其中光栅化和材质着色相对耗时更多。
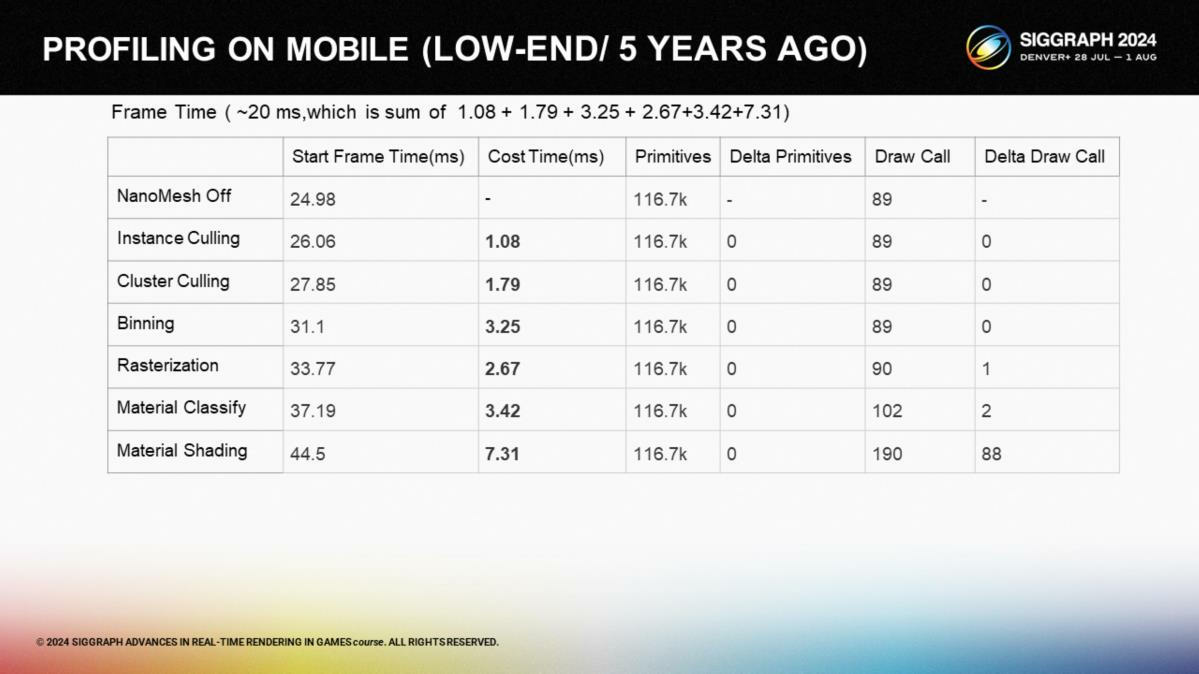
*旧机型上的性能开销阶段拆分。其中材质着色显著耗时更长。
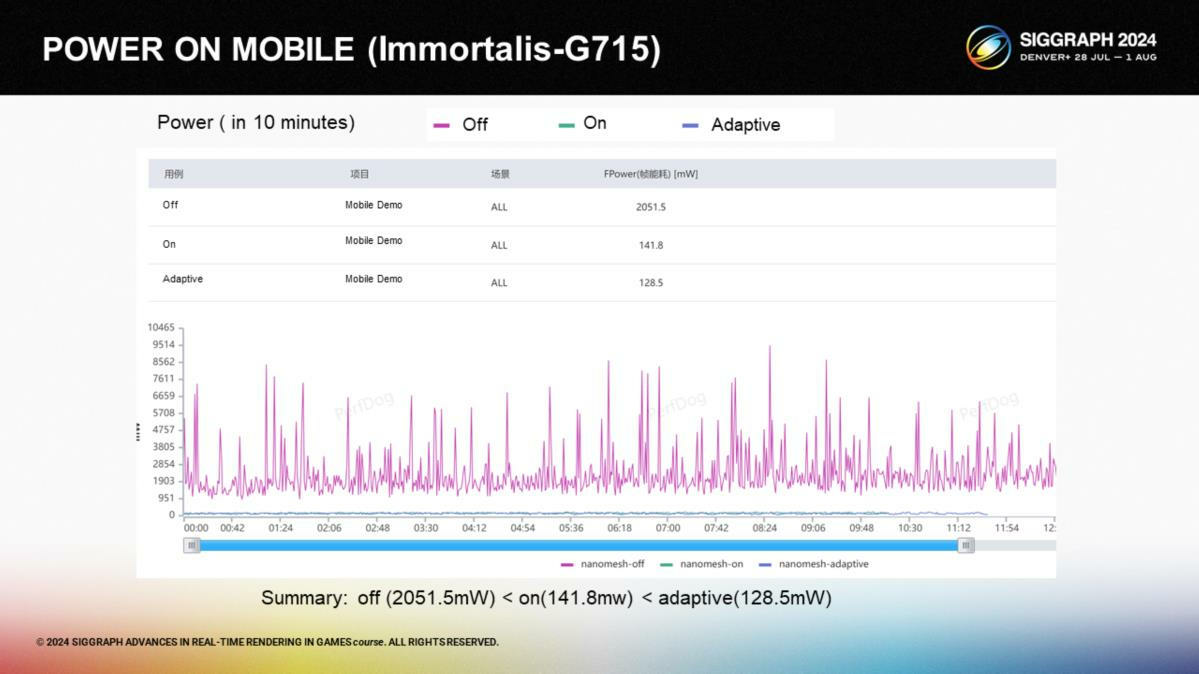
*10分钟耗电量统计。按作者的说法这套管线会比传统的网格渲染方式略微省电一些。
结语
总结一下,整个技术方案的动态网格技术属于Nanite技术栈的衍生版,而全动态的GI则是基于体素追踪,在材质着色上则设计了一套方案以利用GPU的tile架构。
整个技术方案还有不少指标处于研究阶段和实际商品化游戏的临界值上——例如真实的游戏还会有更多角色、UI、特效和复杂逻辑。不过在世界范围内,把主机级的渲染技术逐步下沉到移动端,这个可以说是我国游戏行业弯道超车世界的一个方向了。
无论是腾讯、网易还是其它大厂,其在移动端的开发能力无疑是领先世界的,其合作方的很多手游项目也都是联合开发完成的——大一点的例如《使命召唤 手游版》《暗黑破坏神 不朽》等。
人们通常会诟病这些产品中的一些商业化配套设计——虽然我也认为目前手游的商业模式已经到了比较危险的边缘,但单从技术实现角度来看,这些大IP的移动端作品确实是最大限度还原了所属IP游戏的视觉要素。而且其实稍微主流的移动端设备其实是有着不输于NS的性能的,很多时候没法比较的其实是屏幕大小、游玩场合、操作模式、耗电量等等外在的要素。
无论如何,腾讯的大世界项目明年就要出来了,人们到底是否需要在移动端有那么高的画质,以及之后多端的大型网游中的移动端到底是利好还是拖累,我觉得后面一年的一些项目就是一个分水岭——让我们拭目以待。
最后是资料链接:
Seamless Rendering on Mobile: The Magic of Adaptive LOD Pipeline的PDF