前言
之前由於要換工作和換電腦的原因,一段時間沒更新。近期搞好了新電腦和科學上網,因此這個系列又可以繼續更起來。
由於這周選題的時間不富裕,因此從最新的SIG2024中(順便一提,之前的文章也是都來自Advances in Real-Time Rendering這個子版塊,其實SIGGRAPH不止這部分內容)選擇了一個相對不大但我個人覺得有意思的題目,繼續做這個粗讀系列。

主講人情況——現在是Visible Threshold這家公司的創始人
對於標題中的兩個名詞如果不清楚我覺得也不用擔心,由於原文配圖很多,因此我相信如果感興趣的多少都能看明白。其實虛幻的Nanite也是一種解決大量微小三角形的方案框架(通過網格劃分、自動LOD等配套),可以說以後的遊戲渲染這是一個繞不開並且仍有優化空間的話題;而本文介紹的內容直接在像素繪製的層面考慮並嘗試優化這個問題,其實非常能打開思路,更能說明硬件和軟件算法的相互促進是一件奇妙的事情。
最後還是老樣子,本文還是以翻譯原文PPT頁及解說稿為主,打星號的部分則是我個人的補充。由於篇幅原因還是會拆成上下兩篇。
1 可見性與可變著色率——VISIBILITY AND VRS

The key is idea is that our eyes don’t see pixels. Rather, we see gradients. The eye is neural network that assembles these gradients into a hallucinated image.
這個方案的關鍵思想是,我們的眼睛並不真的看到像素——相對的,我們看到的是“梯度漸變”。人的眼睛是把這些漸變集成到一個“幻視圖像”中的神經網絡。
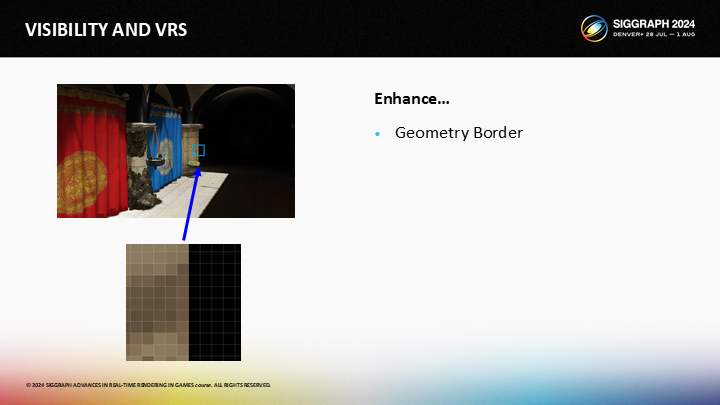
讓我們來增強這個圖像,並聚焦到其中一個幾何體邊緣。

對於綠框中選擇的2個像素,一個是直接被太陽光照亮的,而後面的一個像素只接收來自間接彈射的光照。作為結果,圖像中就有一條鋒利的光照邊緣。

對於黃框中選擇的兩個像素,這種漸變雖然也很重要,但就遠不如綠框的那種情況重要。

最後,對於紅框中的兩個像素,兩者的顏色差別幾乎無法察覺(imperceptible),因此其漸變就更加不重要。

With Variable Rate Shading we can maintain these strong edges in the scene. Then we can reduce the sample rate within geometry edges and it should give us a perceptually similar image in less rendering time.
對於可變著色率方案,我們可以保持場景中比較明顯的邊緣,之後基於幾何體邊緣減少採樣率能得到視覺上近似的圖像,並減少渲染時間。

The goal of this talk is to use a Visibility Buffer to completely separate the geometry rate and the shading rate so that we can use whatever sample pattern we like. Then with an edge-aware reconstruction, we can trade sampling rate for performance, while always preserving the dominant edges in the scene.
這篇分享的目標是使用可見性緩衝來完全分離幾何採樣率和著色採樣率,使我們可以選擇任意採樣模式。之後通過一個邊緣感知的重建過程,我們可以犧牲一定的採樣率來換取性能提升,並始終保持場景中主要邊緣的正確性。
2 Quad效用——QUAD UTILIZATION
*這裡的Quad不是幾何體結構,後面馬上會提到。
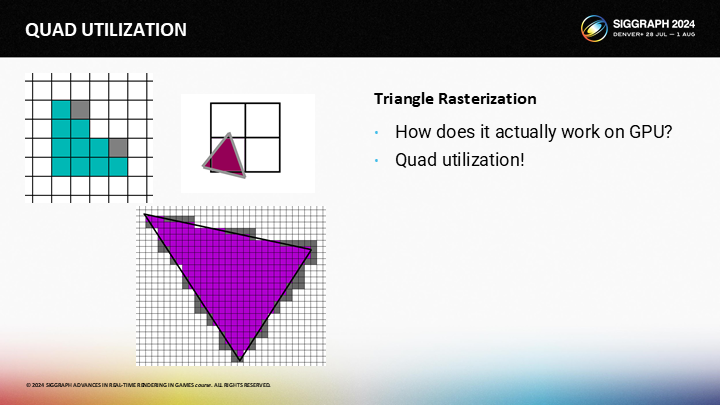
GPU並不是魔法,我們編程使用的像素著色(PixelShader 後面保持原文)接口隱藏了一些不易察覺的細節以及性能上的連帶影響(implications)。

其中最重要的一點是,PixelShader始終是一組4個進行調用——被稱為一個Quad。儘管你的著色函數一次只處理一個像素,在底層它始終是一次同時執行4個像素。
*涉及到GPU架構但是不復雜,基本思想就是單指令多數據、並行化、數據在顯存要連續之類的。
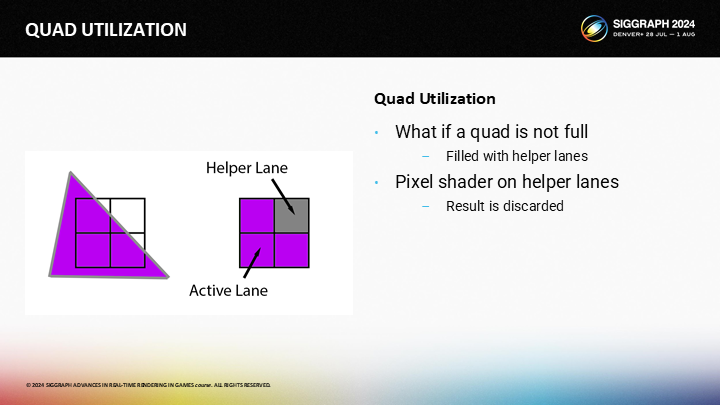
If you render a triangle, and it does not cover the full 2x2 quad, the empty pixel still has to run. Pixels that are being rendered to appear on the screen are called “Active Lanes”, and the soon-to-be discarded pixel shader invocations are called “Helper Lanes”.
如果你渲染一個三角形,並且它沒有覆蓋全部的2X2的quad,空白的像素仍然需要執行著色。被渲染並出現在屏幕上的像素群體被稱為“活動通道”,而即將被丟棄的像素著色調用被稱為“輔助通道”。

讓我們看圖中的例子,其中三個三角形覆蓋了單獨的2X2的quad。
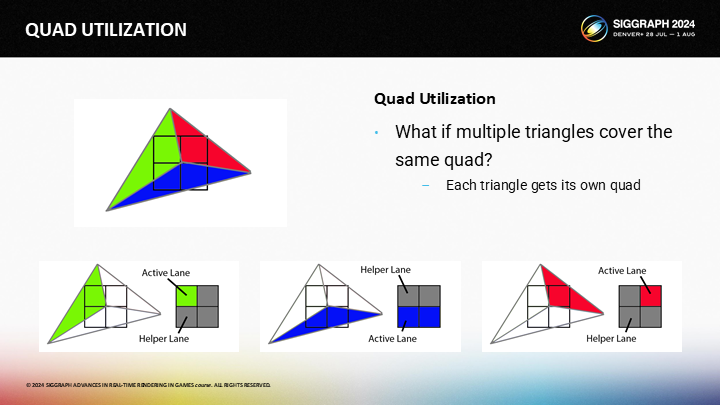
- 綠色的三角形在quad中有一個活動和三個輔助通道
- 藍色三角形有兩個活動和兩個輔助通道
- 紅色三角形有一個活動和三個輔助通道
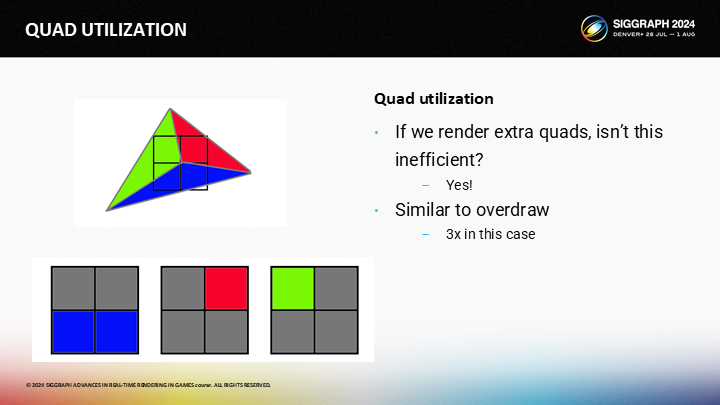
現在你可能想到了:“這並不高效”。確實,答案是“yes”。在我對GPU的心理模型(mental model)中,我把quad理解成像素的重複疊畫(overdraw 後面就保持原文),因為GPU會對不可見像素也重複執行像素著色。
*我個人理解,本來對於傳統的大三角形,這種硬件架構是一種優化,只是對於微小三角形成了負擔。
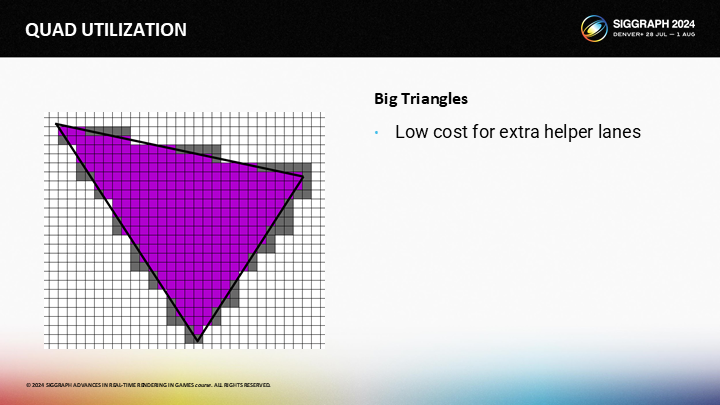
對於較大的三角形,額外的輔助通道不是一個大問題。例如圖中,有大量的活動通道和少量的輔助通道,則輔助通道的開銷比較些微。

然而,對於微小的三角形,這就成為了一個主要的問題。一個只覆蓋單像素的三角形仍然需要一個2X2的quad。
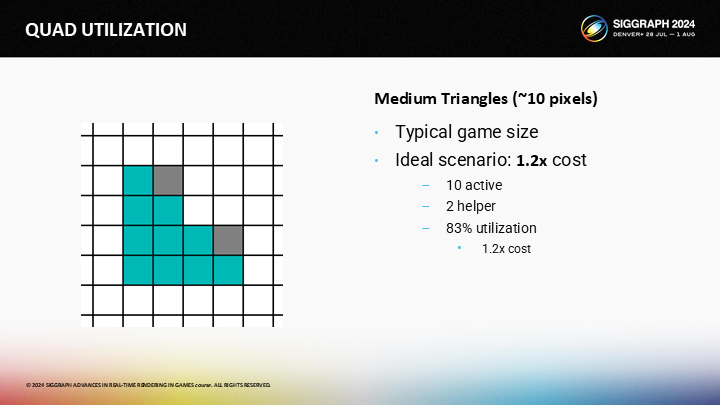
當然,大部分三角形是中等大小的。圖中是一個10像素範圍的三角形,其中的輔助通道的開銷較小。
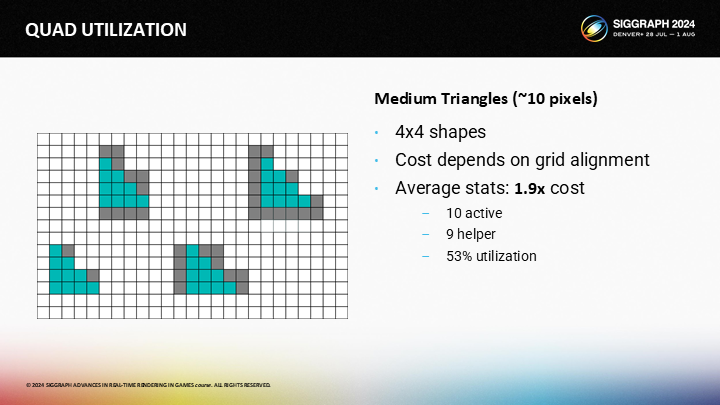
但是輔助通道的數量取決於三角形像素在屏幕分佈的方式——在平均情況下,圖中的三角形有1.9x的開銷。(圖中展示了這個比例的意義,除算就是利用率)
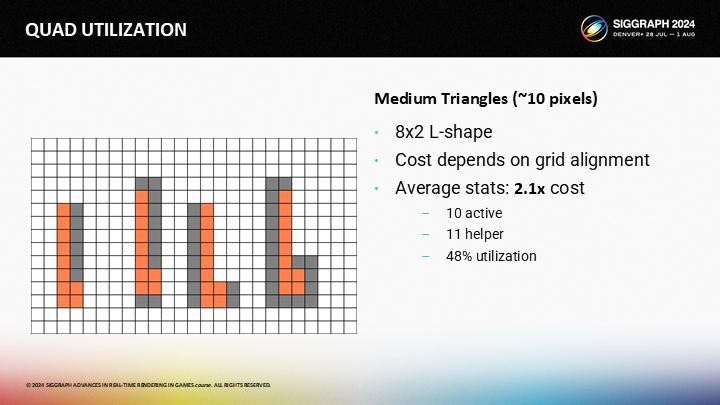
如果三角形是長而細的,情況也會稍微變糟一些。一個L形8x2的三角形有著平均2.1x的quad overdraw。
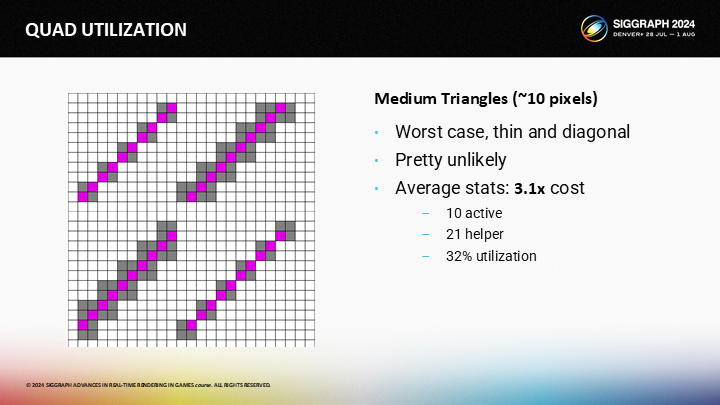
作為參照,這裡是最壞的可能情況,雖然幾乎很難出現。其中有著3.2x的overdraw開銷。
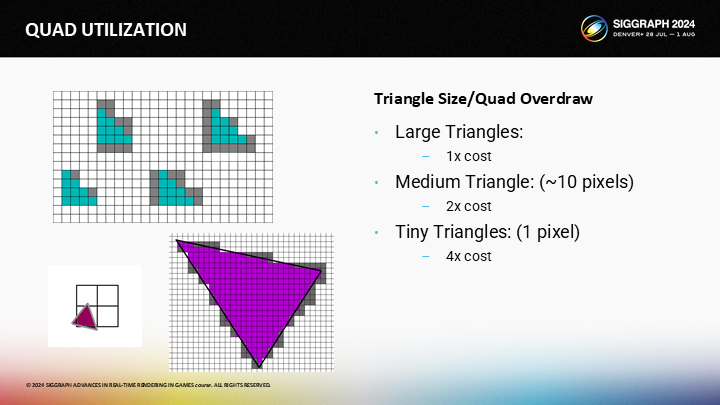
你可能希望控制並把握每一種三角形分佈的模式,不過我認為這並不容易。如果是大三角形,那麼quad overdraw並不關鍵;如果是1像素大的三角形,你需要付出4倍的開銷;對於傳統遊戲中的三角形(大約10像素)的,你需要2倍左右的開銷。
And really, this is the most important thing that I want you to remember from this talk. When I talk about quad overdraw, most people think about it as something that only matters if you are targeting ultra-dense meshes. But 2x overdraw is still A LOT. If your triangles are 10 pixels in size, then you are paying a significant cost in quad overdraw, today, right now, on the game you are currently shipping.
到此為止,這是我最希望大家記住的事項。當提到quad overdraw時,大部分人會認為這僅在超級緊密的網格體上有影響——但2x左右的overdraw仍然很高。如果三角形是10像素左右,你也會付出在quad overdraw上顯著的開銷,而這可能正發生在你目前在售的遊戲中。

目前,一種減輕像素著色開銷的選擇是硬件VRS——下面讓我們看看它如何對quad overdraw產生影響。
*VRS就是可變著色率的縮寫。

如前所述,屏幕被劃分成了2X2的quad。如果一個三角形覆蓋了4個像素的其中任意一個,則2X2的quad需要被調用到。

對於VRS,它雖然應用了同樣的概念,但有著更大的quad(例如4X4)。在2x2的VRS的情況中,如果一個三角形覆蓋了16個像素的任意一個,則一個2x2的quad會被生成並調用。
*簡單說就是2X2的quad只有被活動通道調用,才會向下傳遞調用裡面的實際像素。
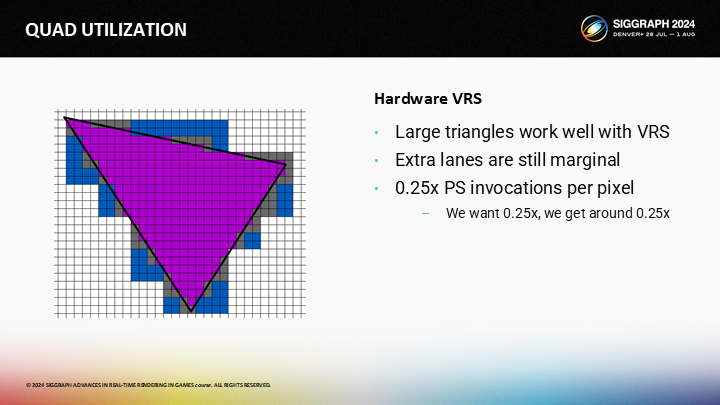
再一次,對於大的三角形,輔助通道的開銷是微不足道的——儘管對於這種情況,輔助通道的數量會有所增加。
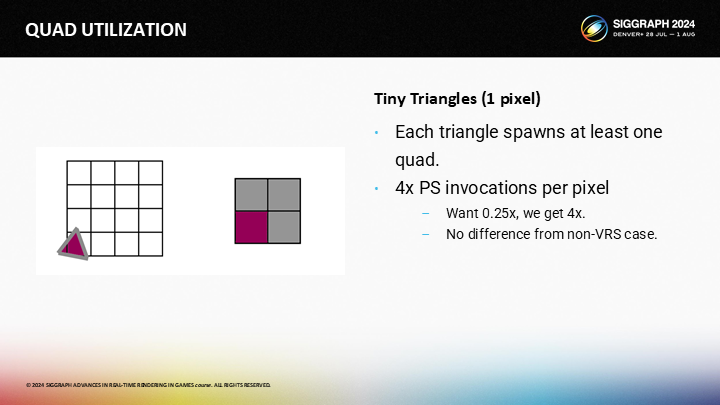
對於1像素的三角形,每一個三角形生成了一個quad。無論VRS是否啟用,它都會覆蓋一個2X2的quad。

最後,對於10像素左右的三角形,結果是每像素約1次PixelShader調用(預期是0.25)。

回到粗略的結果(如圖),大三角形上硬件VRS工作效果最好,但微小三角形仍要付出4倍的開銷——10像素左右的三角形開銷降低到1x左右,比沒有VRS的時候好,但仍然可以改進。

理想狀態下我們希望得到如圖所示的結果數據。這也是整個這篇演示的重點——如何做到各種情況都是.25x的著色倍率,而與三角形尺寸無關。最終我們能實現這一點,但還是需要付出一些額外的開銷。
3 可見性緩衝的細節——VBUFFER DETAILS

為了介紹可見性緩衝渲染(Visibility Buffer rendering),首先我們回顧一下前向渲染(Forward Rendering)。在前向渲染中,我們的像素會從頂點之間插值;之後我們會通過一些材質方程來接收插值結果並計算BRDF數據。我們也通過光照函數來接收材質數據,並計算光照結果。

延遲渲染(Deferred rendering)把這一過程劃分到了2個pass中。首先我們通過pixel shader把材質數據寫入一個緩衝區;之後在第二個pass中(可能是pixel shader或compute shader)獲得材質數據,計算光照並寫入結果。
*關於前向渲染、延遲渲染之前我有文章介紹過:鏈接。Compute shader可以簡單理解成不繪製只計算的代碼,在GPU中執行。

可見性緩衝渲染則又分出一個步驟,在第一個pass中寫入三角形ID——而關鍵就在這(原文是That’s it)。之後材質pass需要獲得三角形ID,計算插值,計算材質數據並寫入GBuffer。最後的光照步驟和前面一樣。

那麼,對於1像素三角形,三種方式的實際開銷如何?在前向渲染中,只有一個pass,因此材質和光照在pixel shader中有著4x的overdraw;在延遲渲染中,只有材質pass需要負擔4x的overdraw,而光照則是1x;結合VBuffer,則材質和光照的計算每像素都只用執行一次——但缺點是我們需要引入額外的開銷來保證這一點。

看看我們的VBuffer渲染概述,其實其中有一些值得注意的細節。(理論相對簡單,但是實現中有一定複雜度)

首先,我們如何獲得待寫入VBuffer的三角形ID?
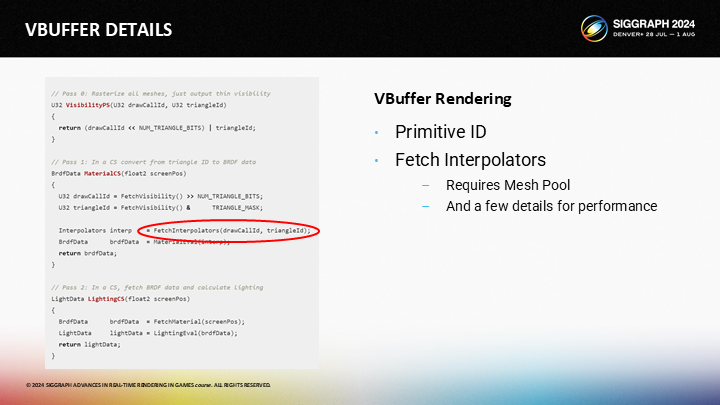
其次,我們該如何計算插值?硬件插值器在這個方案中不再可用。
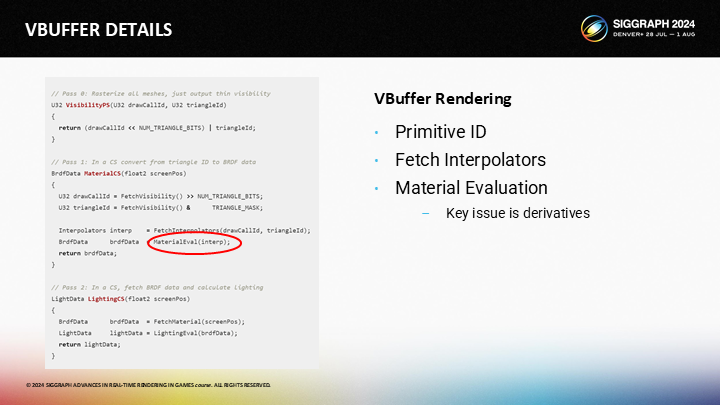
第三,儘管材質計算過程是不變的,但我們需要確認該如何計算mipmap的派生層級。

最後,我們需要分離這些像素、將它們排序,並整合到最終的圖像裡。
*這一段VBuffer的介紹比較初步,可能不好理解。簡單來說就是設計了一套人為干預三角形光柵化至像素的方案,並提出了其中一些待攻克的問題。後面的部分(包括下篇)主要就是在逐一解答這些問題。
4 元ID——PRIMITIVE ID
*Primitive其實一直沒有合適的翻譯,這裡可以主要理解成頂點和三角形。

首要問題是我們如何將三角形ID渲染到一個紋理中。我們希望得出一個在各主流平臺都沒有性能問題的方案。
*之所以是ID渲染到一個紋理中,其實是便於在計算中訪問連續的大段內存。實際上現在很多虛擬紋理都會對應一個虛擬ID紋理。

這裡列出了很多可選項,讓我們一一來討論。

第一個選項是使用SV_Primitive ID語義,或glsl中的gl_PrimitiveId(這裡指不同的圖形語言)。這寫起來很容易——僅需要一行代碼,但它不支持所有平臺,並且也有一些性能上的懲罰。

第二個方案是無索引方式(NonIndexed)。假設我們想渲染圖中的立方體——對於第一個三角形,我們需要渲染它的3個頂點,並且我們想要整個三角形分配圖中粉色的ID——我們可以分別渲染3個頂點並把粉色存入其中。(*這裡顏色可以理解成一種ID數值可視化的結果)
缺點是當渲染下一個三角形時,我們需要以不同的顏色再次渲染這3個頂點。儘管這一方案很簡單,但我們會失去頂點複用的便利——對於每個三角形都需要3個唯一的頂點。
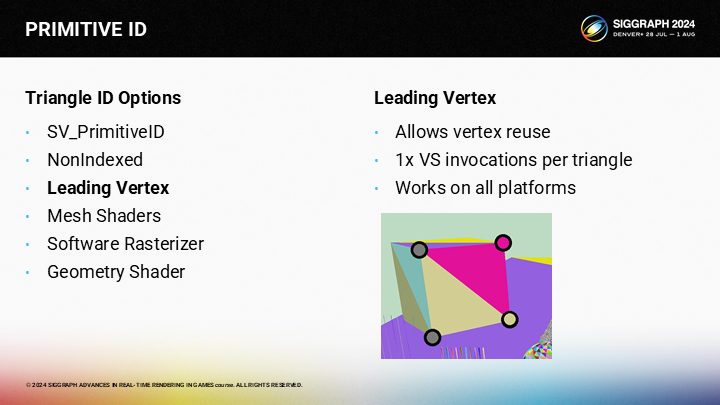
But there is a trick. When we use nointerpolate or flat shading, the interpolator will simply use one vertex for the color, and the other two vertices are ignored. This vertex is called the “provoking” vertex, hence the name.
不過其中也有一個trick。當我們使用無插值或平面著色時,插值器會直接使用一個頂點的顏色,而忽略另外兩個頂點。這個頂點就被稱為“激發”頂點——如其名字一樣產生影響。
在圖中的情況中,對於粉色的三角形,頂部右側的頂點就是激發頂點——因此我們可以不關注這個三角形的另兩個頂點的顏色。
對於微黃色的三角形,我們可以使用底部右側的頂點作為激發頂點。
Since both triangles have a different provoking vertex, they can reuse the same vertices across the edges. With this approach, we can get 1 vertex invocation per triangle. It’s not as good as the theoretical ideal of half a vertex per triangle, it’s still much better than the 3 VS invocations per triangle of NonIndexed.
因為兩個三角形有著不同的激發頂點,它們可以公用有著相同頂點的邊。通過這一方案,我們可以實現每個三角形調用一個頂點——雖然不如平均一個三角形半個頂點調用的理論最佳狀態,但也好於3倍調用的情況。

下一個選項是mesh shader。如果能接收在最小規格範圍支持三角形ID,那它就是最好的選擇——但距離全平臺支持還有很大距離。
*Mesh shader主要是PC和主機上較新的一套著色方式,已經跳出了光柵化、頂點、像素著色的模式,能更靈活地在GPU中編程。

軟件光柵化是部分平臺上最快的選擇。但它需要64位元(的系統),通常來說對於大三角形也需要替代方案,並且在移動端會有耗電的問題。

Geometry shader雖然也可用,但在不同平臺硬件上的性能表現有著相當不可確定的方面。

最終我們剩餘了3個備選方案:SV_PrimitiveID、無索引方式、以及激發頂點(後續都稱為Leading Vertex)是相對可用的方案;Mesh shader和軟件光柵化是後續優化(針對平臺)時的候選方案,不過第一步我們只實現了左邊列出的3個方案。

為了決定最終選擇,我們需要測試它們的性能表現——而這是一項艱鉅的任務。幸運的是,Sebastian Aaltonen在多年以前就做過徹底的研究並把結果發到了twitter。他測試了一臺NVIDIA、一臺AMD和一臺Intel內核的機器。
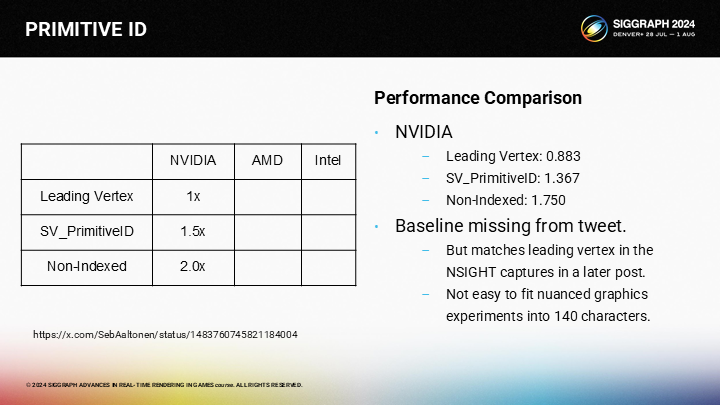
在NVIDIA,Leading Vertex是最快的選項。SV_PrimitiveID大約慢50%,而無索引方式大約慢一倍。

AMD的情況和NVIDIA類似。(具體如圖中所示)
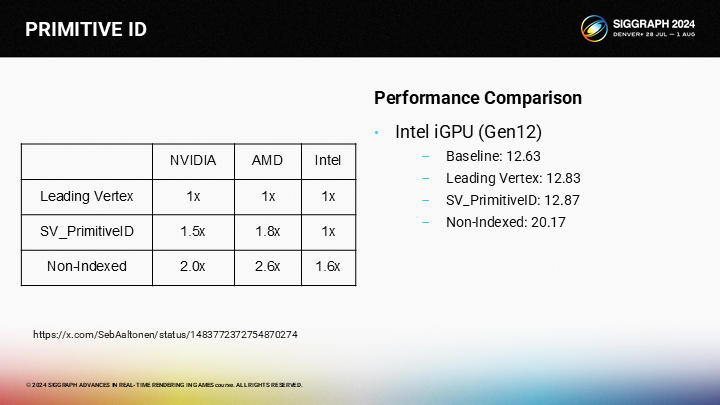
Intel的情況很有趣。它有著一個非常快的SV_PrimitiveID的實現,幾乎沒有額外開銷。而無索引方式仍有顯著的性能懲罰。
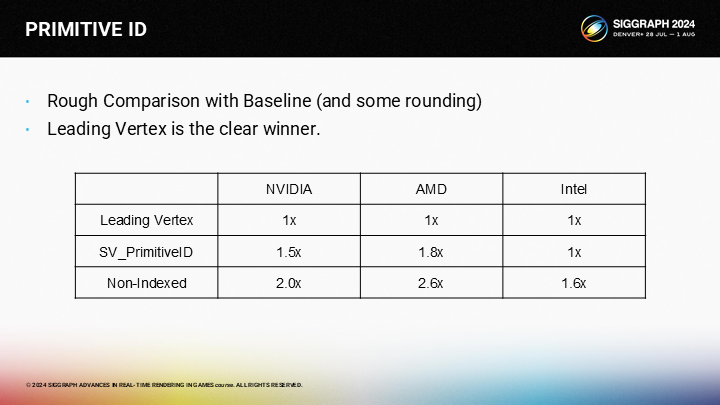
將它們彙總到一起並表示為基於基線的倍數,Leading Vertex是明顯勝出的方案。另外2個方案都有不同的性能懲罰,而Leading Vertex僅有輕微的額外開銷。
*下面的部分是一個算法推導,但結合圖示來說不算複雜。
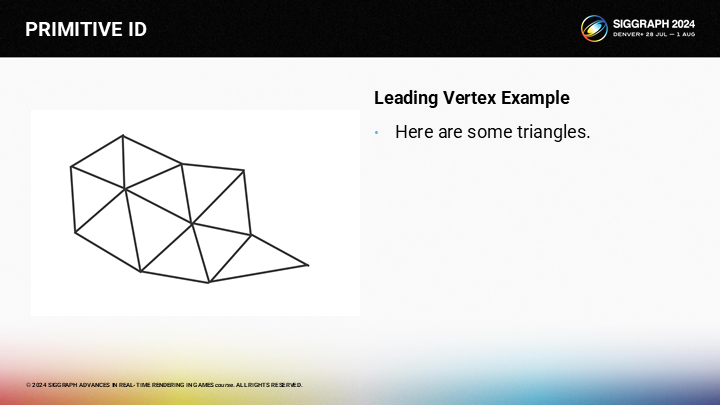
因此,讓我們用一個例子來演示如何在一個三角形集群來實現leading vertex渲染。
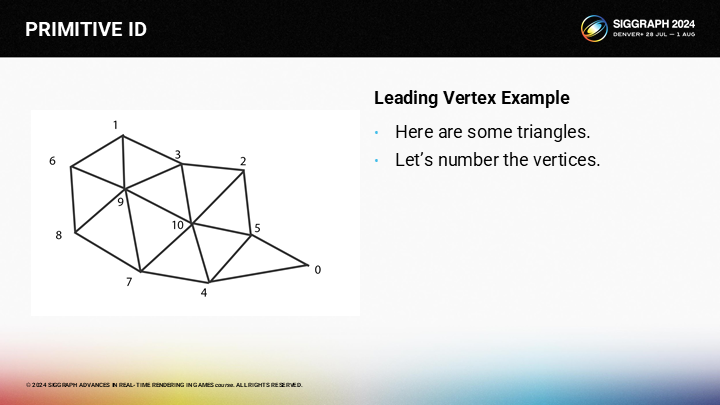
為了展示算法的概念,讓我們如圖所示將頂點編號。
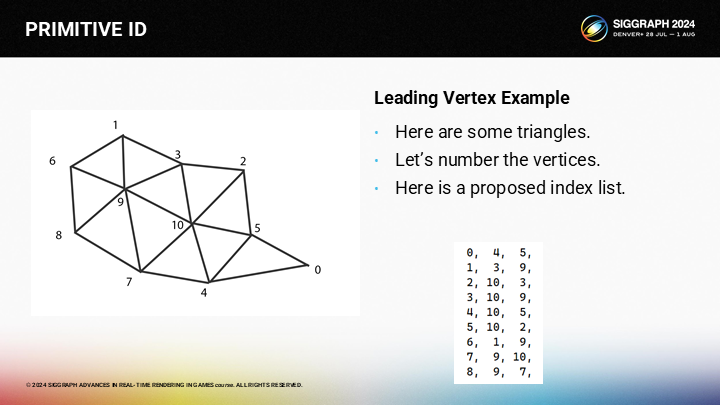
預期得到的索引列表如圖所示(每行一個三角形的3頂點,遞增)。
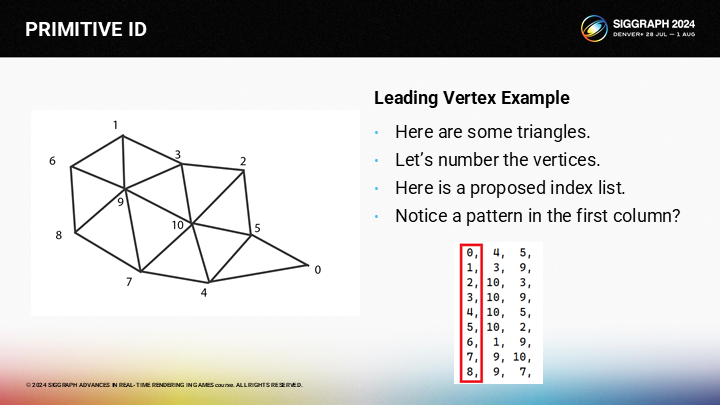
按照列表中的順序,我們已經把數據設置成元ID匹配leading vertex的方式。

If we have the indices laid out in this way, the vertex shader is quite simple. The primitive id is simply the incoming vertex id. And we need a single indirection to convert the incoming index into the actual vertex buffer index.
當我們使索引以這種方式排列時,頂點shader就會很簡單——(三角形的)元ID就和輸入的頂點ID相同。之後我們需要一個單次的重定向,將輸入的索引轉換成實際的頂點緩衝區中的索引。
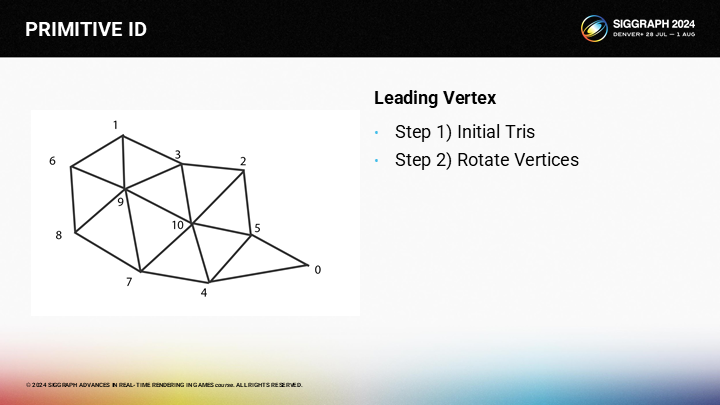
我們可以通過2個步驟將一個三角形集群優化成這種形式:
- 第一步,用貪婪算法嘗試儘量分配更多的包含激發頂點的三角形
- 第二步,通過旋轉頂點來填充步驟一剩餘的三角形
*後面實際上說的是如何編號得到上述頂點ID分佈的一套算法。
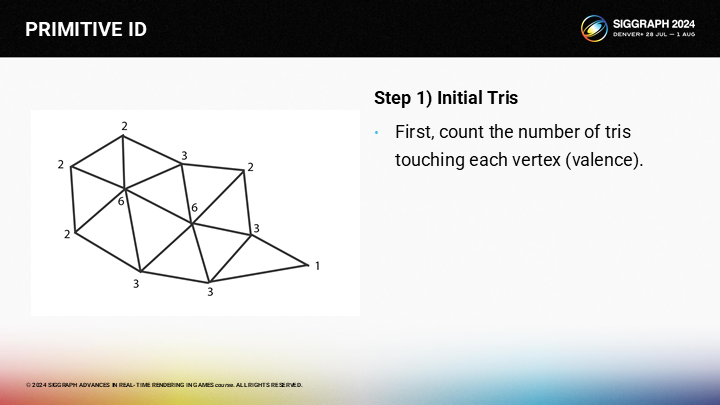
在步驟一中,首先需要計算每個頂點鄰接的三角形數量。(這裡用了類似化學的價的概念valence)
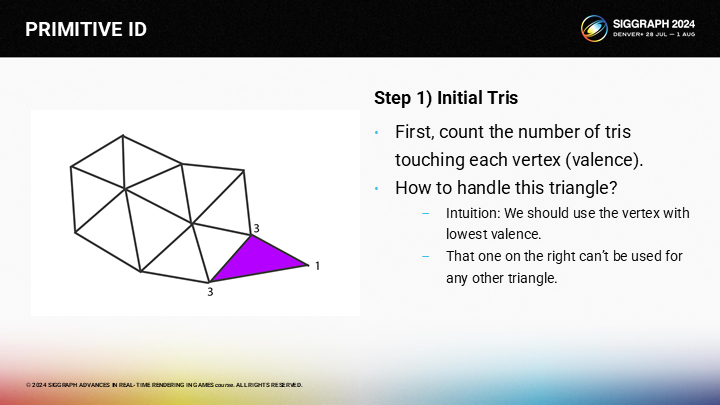
在這個步驟中,循環上是採用的貪婪策略為每個三角形選擇最好的前向頂點。從直覺上(Intuitively),最“好”的選擇就是有著最低價的頂點,而更高價的頂點則更可能被其它三角形公用。同時,這一策略也傾向於從邊緣處的頂點開始計算。
*貪婪策略指每一步都使用局部數值上的最優解。
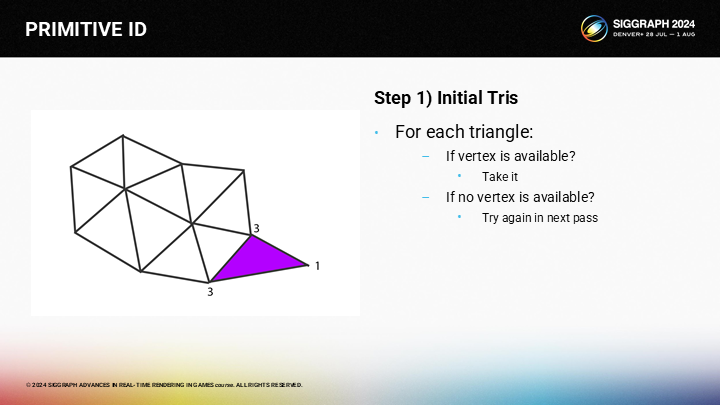
因此這個算法很簡單——迭代每個三角形,選擇最好的可用的激發頂點;如果沒有可用頂點,則等待後一個步驟來處理。
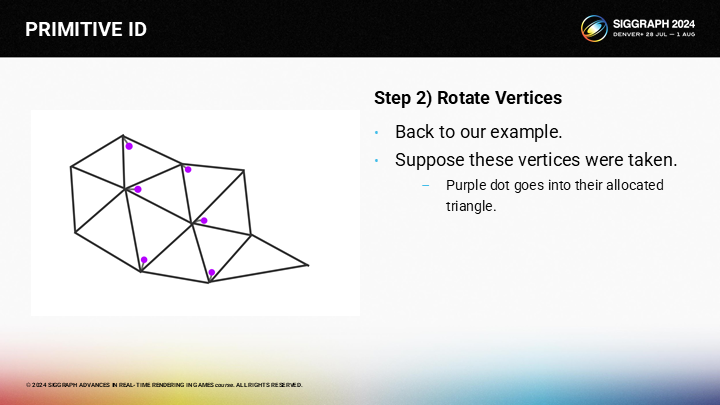
在執行完第一步後,部分三角形已經選擇了激發頂點。在圖中,紫色的小點標示出了這些三角形的激發頂點。
*這裡我反覆推演了一下如何得出如圖的紫色點分佈,但按我的理解這裡作者應該只是大致標了一下用於演示,或者還遺漏了一些執行中的規則,否則按之前的規則並不能經過合理的循環得出如圖的頂點分配。
*雖然這裡的例子可能有瑕疵,但並不影響理解算法的思想。如果有覺得能正常推導出來這些點,歡迎在評論區留言。
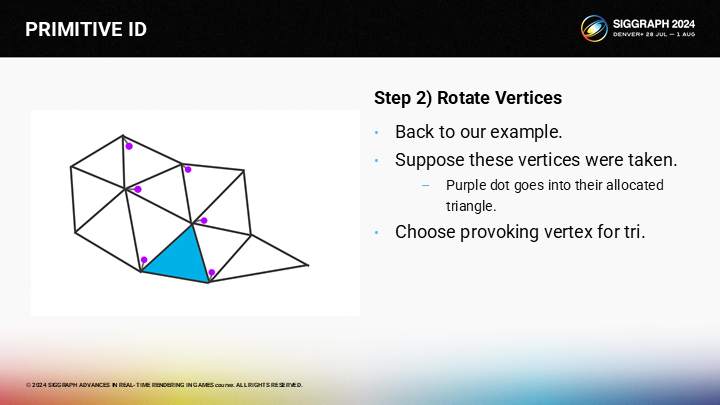
現在我們希望為藍色的三角形選擇激發頂點。
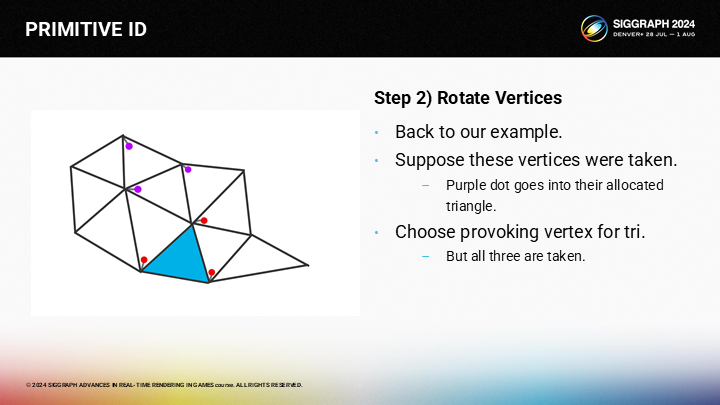
然而,它的所有頂點都被其它三角形選擇過了。
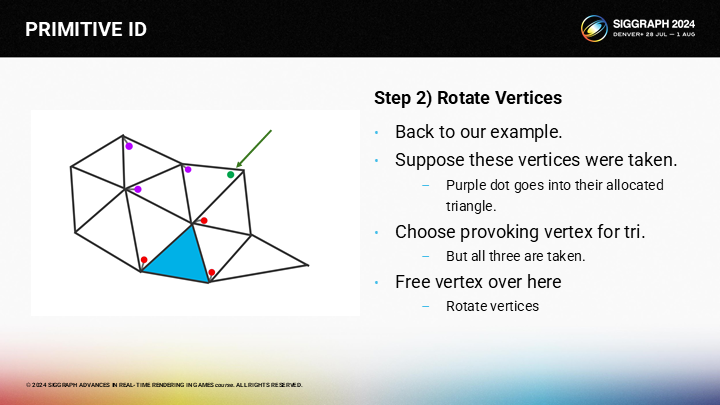
所幸的是,我們可以(從藍色三角形的頂點)通過一輪深度優先搜索來查找到未選擇的頂點(綠色)。
*深度優先是相對於廣度優先的,在這裡就是傾向於沿著一條邊的路徑一直查找下去;而廣度優先就更傾向於每次處理完一個三角形的多條邊。
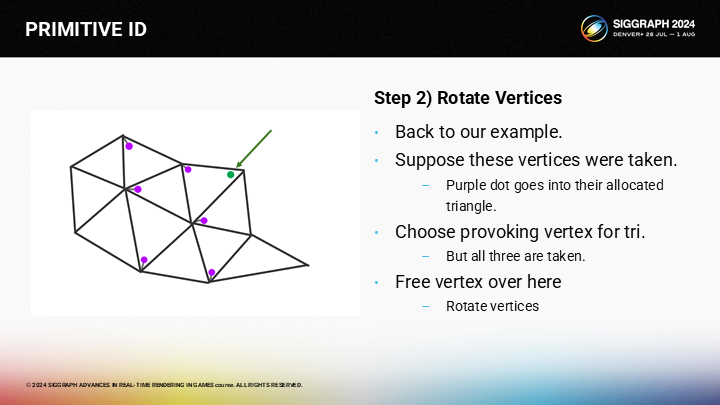
一旦我們找到一條路徑(到空頂點),我們可以通過旋轉激發頂點的方式來釋放一個本來選中的頂點。
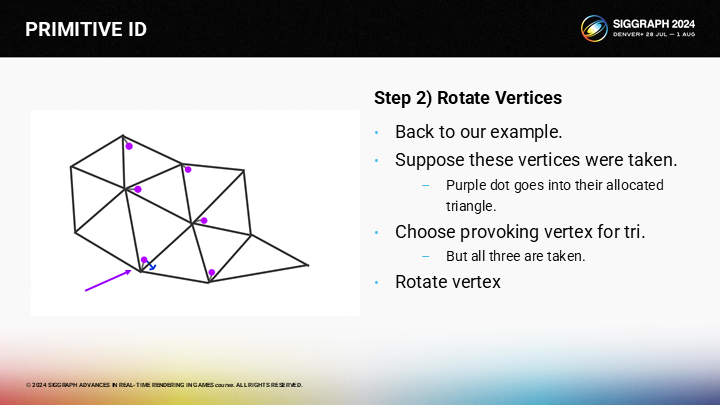
首先,我們旋轉相鄰三角形的激發頂點。
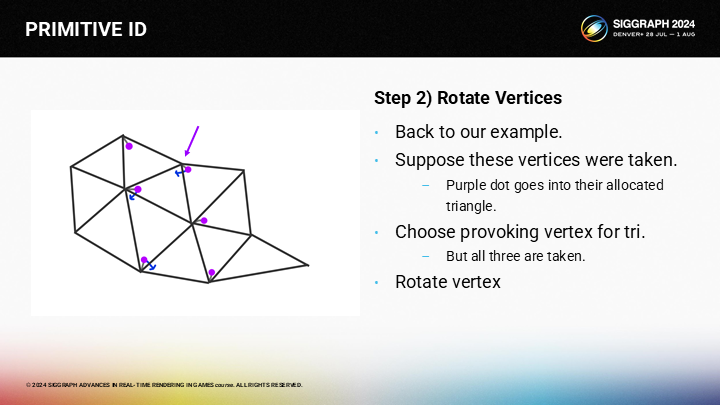
然後逐次遞進至目標三角形。
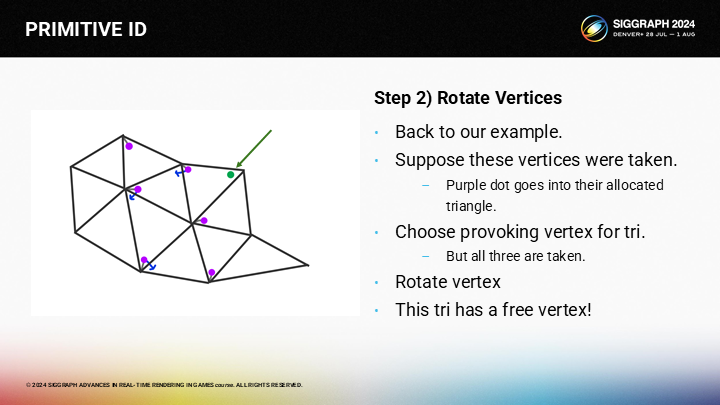
達到目標三角形後,之前的空閒頂點就可以被選擇為激發頂點。
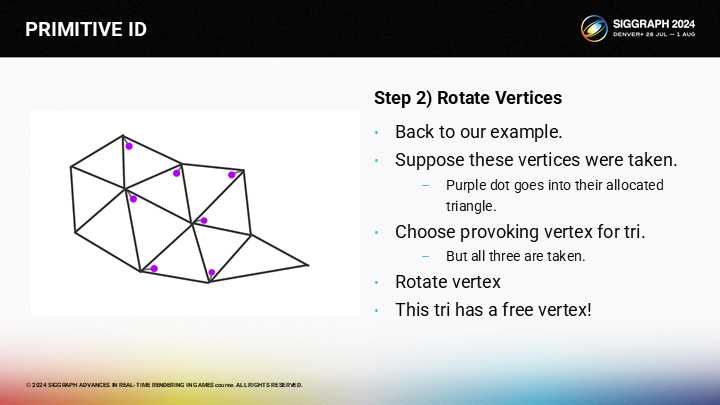
這樣,我們就為已處理的三角形都分配了激發頂點。

回顧一下,這個算法在2個層面上執行。第一個步驟簡單地選取最優的頂點——基於最低的價;第二個步驟執行一個深度優先搜索,並旋轉所需的頂點。
實際上在多數情況中,第二步甚至不需要執行,因為第一步就已經為每個三角形找到了有效的激發頂點。

然而,這一方式在某些情況也會失效。在我的使用場合,集群始終包含64個三角形和64個頂點。
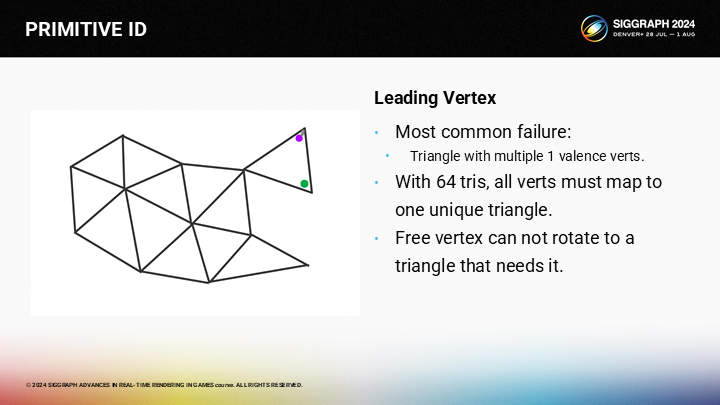
多數的失效情況是,其中一個三角形是以鬆散的方式與其它部分相連——通過一個單獨的頂點。當它選擇紫色的頂點作為激發頂點時,綠色的頂點並不能通過旋轉進入集群中,因而就會出現集群中有三角形未分配激發頂點的情況。

這一算法已經併入了我的MeshOptimizer工具中,通常也用於LOD生成——因為它非常快速。MeshOptimzer基於一個貪婪算法,一次添加一個三角形到buffer中;一旦buffer超過你限制的值——在我的使用場合是64個三角形和頂點,則從buffer發出一個三角形集群,並開始一個新集群。
其中我在集群發出的部分做出了修改,基於激發頂點的考慮重排了三角形順序。如果一個三角形無法找到一個激發頂點,則它會被放回buffer中用於下一個集群的生成。在實踐中,通常所有三角形都是能匹配上的,但偶爾會有一兩個三角形丟失的情況。

實際的數據在磁盤上是非常緊湊的。對於每一個集群,我們需要64個索引用於源頂點buffer,之後它們會被複制一份。
Also, we don’t need to store two of the three indices, as the first vertex is implied. If we pack them into 6 bits per index, 32bit index meshes end up as 5.5 bytes per triangle, which is a nice win for disk space over storing uncompressed indices.
並且,我們不需要存儲三個頂點索引中的另外2個,因為第一個頂點已經指明瞭(它們的對應關係)。
*圖中還列出了32bit和16bit索引的一些空間佔用情況。

在實踐中還會遇到另一個問題。假設我們想支持不同平臺的不同網格實現,該如何做?例如,在交新的GPU使用mesh shader,在舊的GPU退回到leading vertex或傳統的GBuffer渲染模式。
此時,我們並不想在磁盤上存儲三份不同版本的網格數據。
幸運的是,將數據從leading vertex轉換成其它數據描述方式的開銷是很輕微的。在磁盤上你只需要保留緊密壓縮的數據形式,之後你可以在運行時按需展開索引列表。當前的遊戲在存儲空間上都非常緊張,因此在我看來這項壓縮對於傳統的未排序索引列表或是傳統GBuffer渲染都是有提升的。
*回顧一下,這裡整個在做的都是實現頂點、三角形、頂點顏色數據1比1比1存儲,以及有序訪問。
結語
由於斷更了一段時間,想簡單談談我對我在機核更新的文章的思考。
首先我這些技術文章肯定也可以發在知乎,雖然我只是一個普通開發者不是什麼大神,但是我也在知乎讀到過翻譯和解釋得不如我的文章,比較起來這沒什麼心理負擔——另外要說把一個複雜事情解釋得相對好懂一些,我覺得自己還是努力做到了的。
在這個基礎上,我的個人文章的另一部分,就是那些遊玩感受、行業觀察之類的,知乎是無處安放的——這就是我最初就選擇投在機核的一個重要原因吧。並且,機核的網頁編輯器使用起來也比較順手,我不需要額外的網頁編輯方式就能方便地排版和保存文章。最後,定期寫點東西確實在我看來是很好的一種習慣,畢竟當前社會人多少都要做點自我表達,而這也是有一個慢慢熟練的過程的。
另外順便聊聊我今天看到的一個遊戲論壇討論,主要是說光追技術這麼耗費硬件,是否值得的問題——目前看來它帶來的光影質量其實和遊玩確實關係不大,反而會拖慢幀數。我認可這種現狀,但也要說其實會這麼想,還是因為現在的遊戲都是兼容了傳統的全局光照管線和光追管線,在兩者並行的情況下光追的性價比不算高;另外就是自然光源的遊戲相對不如科幻題材的遊戲光追效果明顯,這個也是事實;還有一個不可忽視的問題,是基於摩爾定律提升的硬件性能,在單核上已經快到頭了,而針對多核的優化門檻就非常高了。
但是長期看來,光追和AI同步發展,一定會有一個量變到質變的過程——這也是我長期看技術文章的一個感受,因為圖形學算起來也是有半個多世紀(算上數學基礎的話上百年)的積累,這部分前沿的慢慢推進始終是有意義的。
下週繼續更這篇文章的後半部分。最後是資料鏈接(其中有原作者提供的一些,可以下載了PPTX文件去找對應鏈接):
可見性緩衝的資料
可變著色率的資料
Variable Rate Shading with Visibility Buffer Rendering的PPTX地址
微軟的 Variable Rate Shading 介紹
AMD的 AMD FidelityFX Variable Shading 介紹