前言
之前由于要换工作和换电脑的原因,一段时间没更新。近期搞好了新电脑和科学上网,因此这个系列又可以继续更起来。
由于这周选题的时间不富裕,因此从最新的SIG2024中(顺便一提,之前的文章也是都来自Advances in Real-Time Rendering这个子版块,其实SIGGRAPH不止这部分内容)选择了一个相对不大但我个人觉得有意思的题目,继续做这个粗读系列。

主讲人情况——现在是Visible Threshold这家公司的创始人
对于标题中的两个名词如果不清楚我觉得也不用担心,由于原文配图很多,因此我相信如果感兴趣的多少都能看明白。其实虚幻的Nanite也是一种解决大量微小三角形的方案框架(通过网格划分、自动LOD等配套),可以说以后的游戏渲染这是一个绕不开并且仍有优化空间的话题;而本文介绍的内容直接在像素绘制的层面考虑并尝试优化这个问题,其实非常能打开思路,更能说明硬件和软件算法的相互促进是一件奇妙的事情。
最后还是老样子,本文还是以翻译原文PPT页及解说稿为主,打星号的部分则是我个人的补充。由于篇幅原因还是会拆成上下两篇。
1 可见性与可变着色率——VISIBILITY AND VRS

The key is idea is that our eyes don’t see pixels. Rather, we see gradients. The eye is neural network that assembles these gradients into a hallucinated image.
这个方案的关键思想是,我们的眼睛并不真的看到像素——相对的,我们看到的是“梯度渐变”。人的眼睛是把这些渐变集成到一个“幻视图像”中的神经网络。
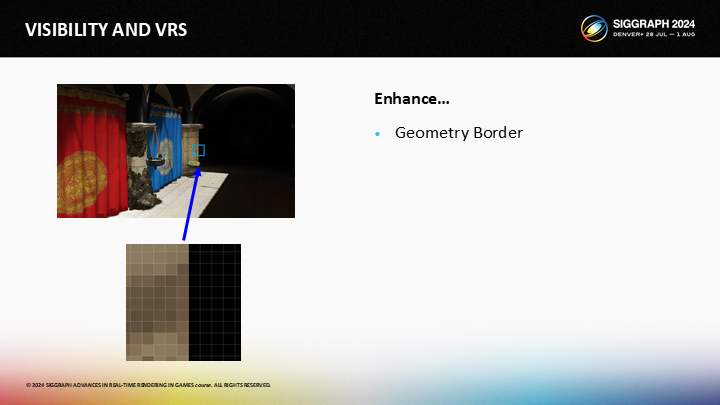
让我们来增强这个图像,并聚焦到其中一个几何体边缘。

对于绿框中选择的2个像素,一个是直接被太阳光照亮的,而后面的一个像素只接收来自间接弹射的光照。作为结果,图像中就有一条锋利的光照边缘。

对于黄框中选择的两个像素,这种渐变虽然也很重要,但就远不如绿框的那种情况重要。

最后,对于红框中的两个像素,两者的颜色差别几乎无法察觉(imperceptible),因此其渐变就更加不重要。

With Variable Rate Shading we can maintain these strong edges in the scene. Then we can reduce the sample rate within geometry edges and it should give us a perceptually similar image in less rendering time.
对于可变着色率方案,我们可以保持场景中比较明显的边缘,之后基于几何体边缘减少采样率能得到视觉上近似的图像,并减少渲染时间。

The goal of this talk is to use a Visibility Buffer to completely separate the geometry rate and the shading rate so that we can use whatever sample pattern we like. Then with an edge-aware reconstruction, we can trade sampling rate for performance, while always preserving the dominant edges in the scene.
这篇分享的目标是使用可见性缓冲来完全分离几何采样率和着色采样率,使我们可以选择任意采样模式。之后通过一个边缘感知的重建过程,我们可以牺牲一定的采样率来换取性能提升,并始终保持场景中主要边缘的正确性。
2 Quad效用——QUAD UTILIZATION
*这里的Quad不是几何体结构,后面马上会提到。
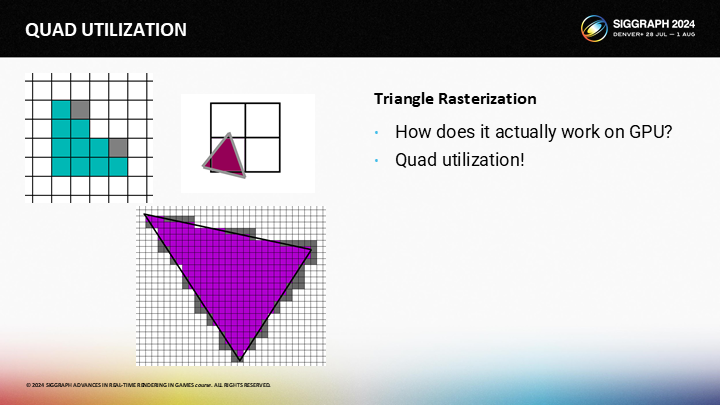
GPU并不是魔法,我们编程使用的像素着色(PixelShader 后面保持原文)接口隐藏了一些不易察觉的细节以及性能上的连带影响(implications)。

其中最重要的一点是,PixelShader始终是一组4个进行调用——被称为一个Quad。尽管你的着色函数一次只处理一个像素,在底层它始终是一次同时执行4个像素。
*涉及到GPU架构但是不复杂,基本思想就是单指令多数据、并行化、数据在显存要连续之类的。
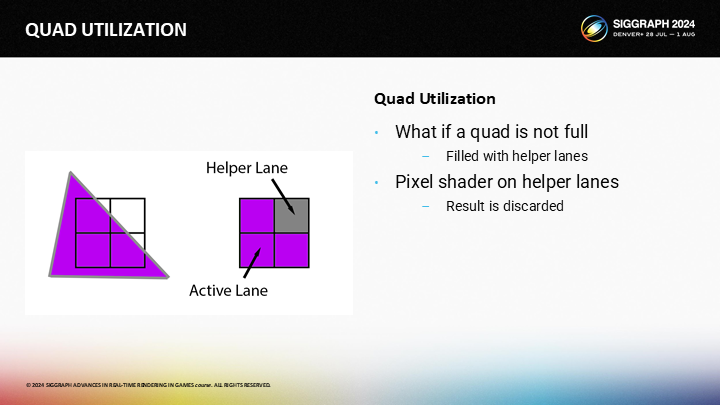
If you render a triangle, and it does not cover the full 2x2 quad, the empty pixel still has to run. Pixels that are being rendered to appear on the screen are called “Active Lanes”, and the soon-to-be discarded pixel shader invocations are called “Helper Lanes”.
如果你渲染一个三角形,并且它没有覆盖全部的2X2的quad,空白的像素仍然需要执行着色。被渲染并出现在屏幕上的像素群体被称为“活动通道”,而即将被丢弃的像素着色调用被称为“辅助通道”。

让我们看图中的例子,其中三个三角形覆盖了单独的2X2的quad。
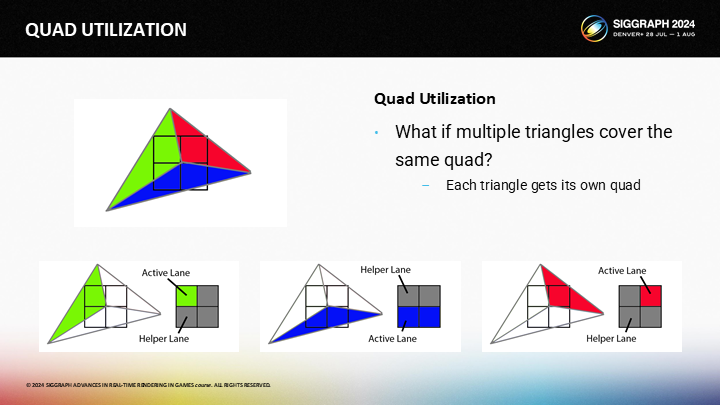
- 绿色的三角形在quad中有一个活动和三个辅助通道
- 蓝色三角形有两个活动和两个辅助通道
- 红色三角形有一个活动和三个辅助通道
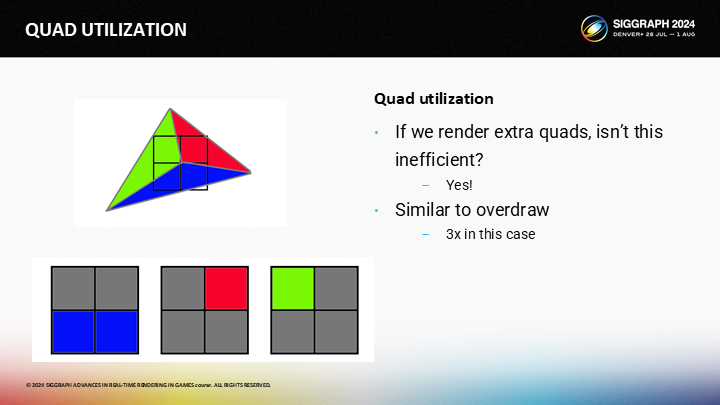
现在你可能想到了:“这并不高效”。确实,答案是“yes”。在我对GPU的心理模型(mental model)中,我把quad理解成像素的重复叠画(overdraw 后面就保持原文),因为GPU会对不可见像素也重复执行像素着色。
*我个人理解,本来对于传统的大三角形,这种硬件架构是一种优化,只是对于微小三角形成了负担。
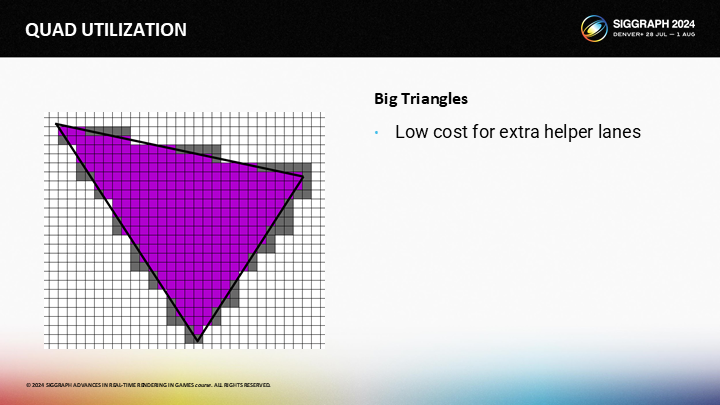
对于较大的三角形,额外的辅助通道不是一个大问题。例如图中,有大量的活动通道和少量的辅助通道,则辅助通道的开销比较些微。

然而,对于微小的三角形,这就成为了一个主要的问题。一个只覆盖单像素的三角形仍然需要一个2X2的quad。
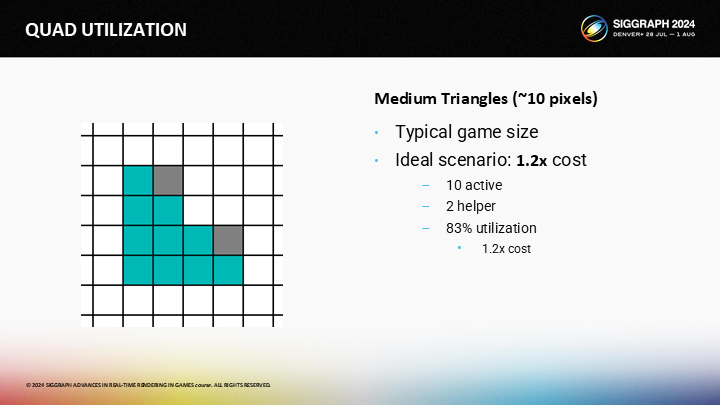
当然,大部分三角形是中等大小的。图中是一个10像素范围的三角形,其中的辅助通道的开销较小。
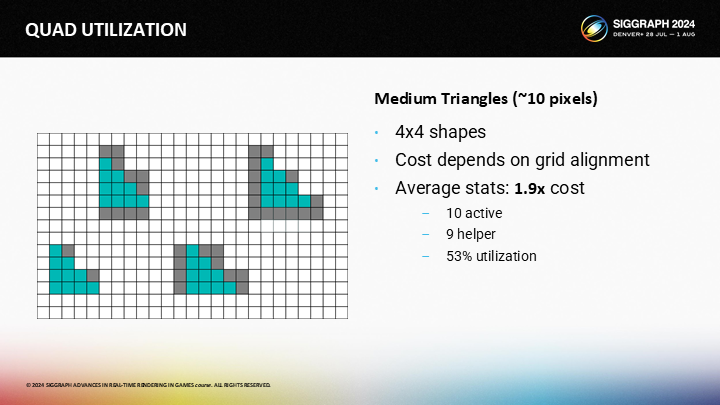
但是辅助通道的数量取决于三角形像素在屏幕分布的方式——在平均情况下,图中的三角形有1.9x的开销。(图中展示了这个比例的意义,除算就是利用率)
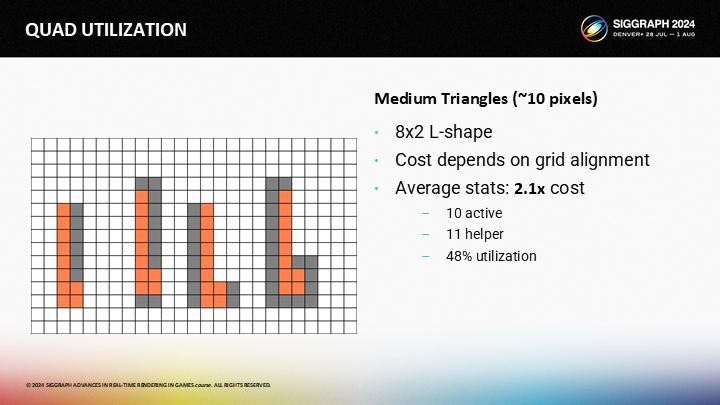
如果三角形是长而细的,情况也会稍微变糟一些。一个L形8x2的三角形有着平均2.1x的quad overdraw。
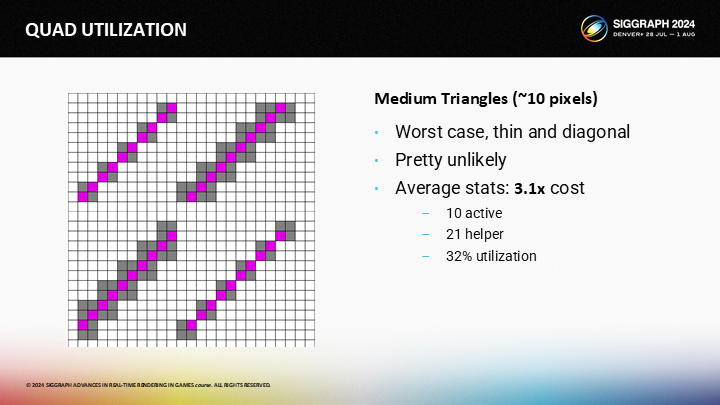
作为参照,这里是最坏的可能情况,虽然几乎很难出现。其中有着3.2x的overdraw开销。
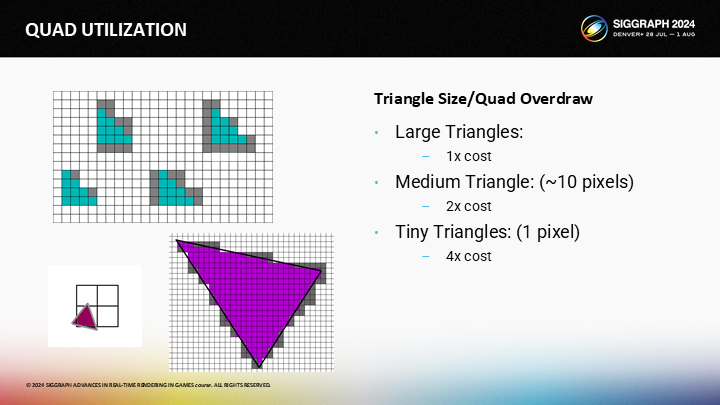
你可能希望控制并把握每一种三角形分布的模式,不过我认为这并不容易。如果是大三角形,那么quad overdraw并不关键;如果是1像素大的三角形,你需要付出4倍的开销;对于传统游戏中的三角形(大约10像素)的,你需要2倍左右的开销。
And really, this is the most important thing that I want you to remember from this talk. When I talk about quad overdraw, most people think about it as something that only matters if you are targeting ultra-dense meshes. But 2x overdraw is still A LOT. If your triangles are 10 pixels in size, then you are paying a significant cost in quad overdraw, today, right now, on the game you are currently shipping.
到此为止,这是我最希望大家记住的事项。当提到quad overdraw时,大部分人会认为这仅在超级紧密的网格体上有影响——但2x左右的overdraw仍然很高。如果三角形是10像素左右,你也会付出在quad overdraw上显著的开销,而这可能正发生在你目前在售的游戏中。

目前,一种减轻像素着色开销的选择是硬件VRS——下面让我们看看它如何对quad overdraw产生影响。
*VRS就是可变着色率的缩写。

如前所述,屏幕被划分成了2X2的quad。如果一个三角形覆盖了4个像素的其中任意一个,则2X2的quad需要被调用到。

对于VRS,它虽然应用了同样的概念,但有着更大的quad(例如4X4)。在2x2的VRS的情况中,如果一个三角形覆盖了16个像素的任意一个,则一个2x2的quad会被生成并调用。
*简单说就是2X2的quad只有被活动通道调用,才会向下传递调用里面的实际像素。
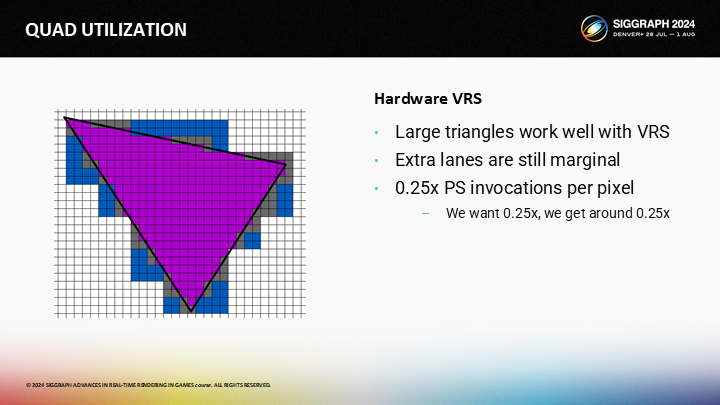
再一次,对于大的三角形,辅助通道的开销是微不足道的——尽管对于这种情况,辅助通道的数量会有所增加。
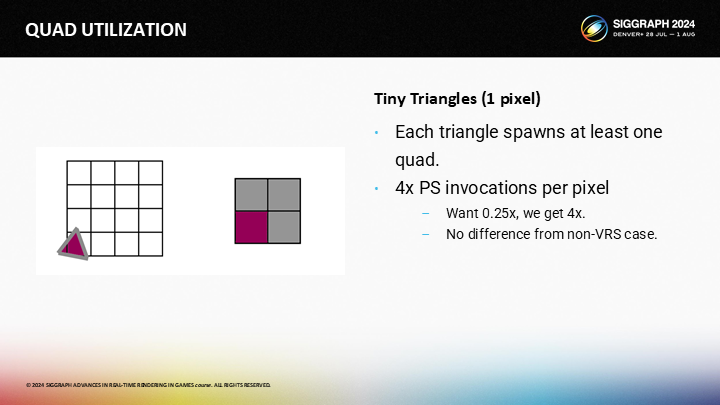
对于1像素的三角形,每一个三角形生成了一个quad。无论VRS是否启用,它都会覆盖一个2X2的quad。

最后,对于10像素左右的三角形,结果是每像素约1次PixelShader调用(预期是0.25)。

回到粗略的结果(如图),大三角形上硬件VRS工作效果最好,但微小三角形仍要付出4倍的开销——10像素左右的三角形开销降低到1x左右,比没有VRS的时候好,但仍然可以改进。

理想状态下我们希望得到如图所示的结果数据。这也是整个这篇演示的重点——如何做到各种情况都是.25x的着色倍率,而与三角形尺寸无关。最终我们能实现这一点,但还是需要付出一些额外的开销。
3 可见性缓冲的细节——VBUFFER DETAILS

为了介绍可见性缓冲渲染(Visibility Buffer rendering),首先我们回顾一下前向渲染(Forward Rendering)。在前向渲染中,我们的像素会从顶点之间插值;之后我们会通过一些材质方程来接收插值结果并计算BRDF数据。我们也通过光照函数来接收材质数据,并计算光照结果。

延迟渲染(Deferred rendering)把这一过程划分到了2个pass中。首先我们通过pixel shader把材质数据写入一个缓冲区;之后在第二个pass中(可能是pixel shader或compute shader)获得材质数据,计算光照并写入结果。
*关于前向渲染、延迟渲染之前我有文章介绍过:链接。Compute shader可以简单理解成不绘制只计算的代码,在GPU中执行。

可见性缓冲渲染则又分出一个步骤,在第一个pass中写入三角形ID——而关键就在这(原文是That’s it)。之后材质pass需要获得三角形ID,计算插值,计算材质数据并写入GBuffer。最后的光照步骤和前面一样。

那么,对于1像素三角形,三种方式的实际开销如何?在前向渲染中,只有一个pass,因此材质和光照在pixel shader中有着4x的overdraw;在延迟渲染中,只有材质pass需要负担4x的overdraw,而光照则是1x;结合VBuffer,则材质和光照的计算每像素都只用执行一次——但缺点是我们需要引入额外的开销来保证这一点。

看看我们的VBuffer渲染概述,其实其中有一些值得注意的细节。(理论相对简单,但是实现中有一定复杂度)

首先,我们如何获得待写入VBuffer的三角形ID?
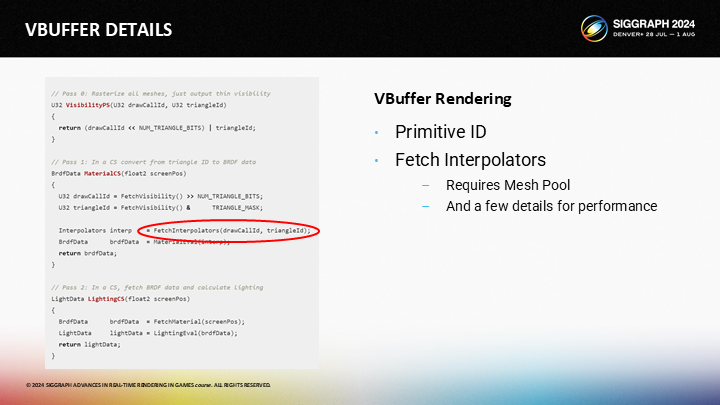
其次,我们该如何计算插值?硬件插值器在这个方案中不再可用。
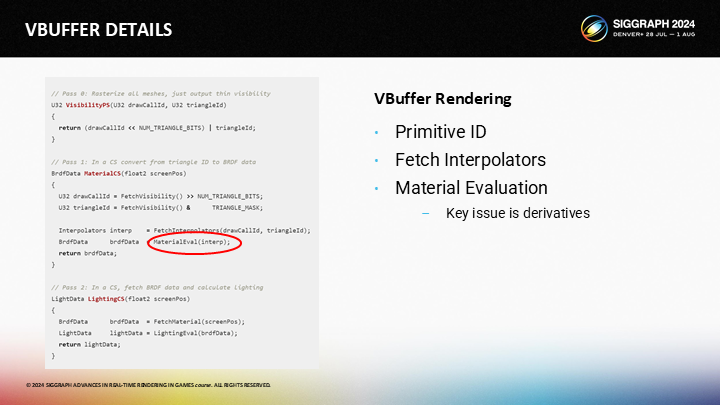
第三,尽管材质计算过程是不变的,但我们需要确认该如何计算mipmap的派生层级。

最后,我们需要分离这些像素、将它们排序,并整合到最终的图像里。
*这一段VBuffer的介绍比较初步,可能不好理解。简单来说就是设计了一套人为干预三角形光栅化至像素的方案,并提出了其中一些待攻克的问题。后面的部分(包括下篇)主要就是在逐一解答这些问题。
4 元ID——PRIMITIVE ID
*Primitive其实一直没有合适的翻译,这里可以主要理解成顶点和三角形。

首要问题是我们如何将三角形ID渲染到一个纹理中。我们希望得出一个在各主流平台都没有性能问题的方案。
*之所以是ID渲染到一个纹理中,其实是便于在计算中访问连续的大段内存。实际上现在很多虚拟纹理都会对应一个虚拟ID纹理。

这里列出了很多可选项,让我们一一来讨论。

第一个选项是使用SV_Primitive ID语义,或glsl中的gl_PrimitiveId(这里指不同的图形语言)。这写起来很容易——仅需要一行代码,但它不支持所有平台,并且也有一些性能上的惩罚。

第二个方案是无索引方式(NonIndexed)。假设我们想渲染图中的立方体——对于第一个三角形,我们需要渲染它的3个顶点,并且我们想要整个三角形分配图中粉色的ID——我们可以分别渲染3个顶点并把粉色存入其中。(*这里颜色可以理解成一种ID数值可视化的结果)
缺点是当渲染下一个三角形时,我们需要以不同的颜色再次渲染这3个顶点。尽管这一方案很简单,但我们会失去顶点复用的便利——对于每个三角形都需要3个唯一的顶点。
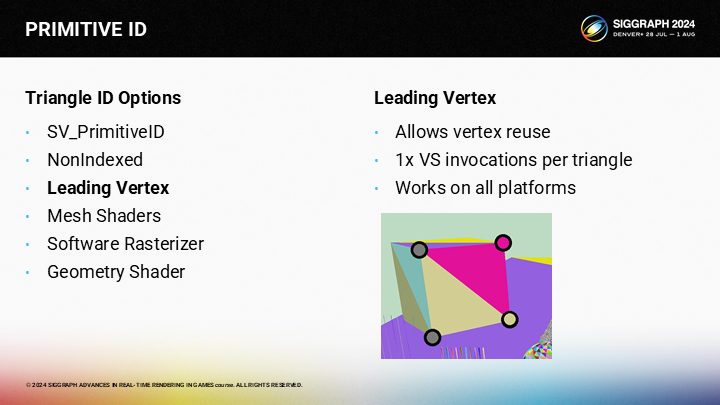
But there is a trick. When we use nointerpolate or flat shading, the interpolator will simply use one vertex for the color, and the other two vertices are ignored. This vertex is called the “provoking” vertex, hence the name.
不过其中也有一个trick。当我们使用无插值或平面着色时,插值器会直接使用一个顶点的颜色,而忽略另外两个顶点。这个顶点就被称为“激发”顶点——如其名字一样产生影响。
在图中的情况中,对于粉色的三角形,顶部右侧的顶点就是激发顶点——因此我们可以不关注这个三角形的另两个顶点的颜色。
对于微黄色的三角形,我们可以使用底部右侧的顶点作为激发顶点。
Since both triangles have a different provoking vertex, they can reuse the same vertices across the edges. With this approach, we can get 1 vertex invocation per triangle. It’s not as good as the theoretical ideal of half a vertex per triangle, it’s still much better than the 3 VS invocations per triangle of NonIndexed.
因为两个三角形有着不同的激发顶点,它们可以公用有着相同顶点的边。通过这一方案,我们可以实现每个三角形调用一个顶点——虽然不如平均一个三角形半个顶点调用的理论最佳状态,但也好于3倍调用的情况。

下一个选项是mesh shader。如果能接收在最小规格范围支持三角形ID,那它就是最好的选择——但距离全平台支持还有很大距离。
*Mesh shader主要是PC和主机上较新的一套着色方式,已经跳出了光栅化、顶点、像素着色的模式,能更灵活地在GPU中编程。

软件光栅化是部分平台上最快的选择。但它需要64位元(的系统),通常来说对于大三角形也需要替代方案,并且在移动端会有耗电的问题。

Geometry shader虽然也可用,但在不同平台硬件上的性能表现有着相当不可确定的方面。

最终我们剩余了3个备选方案:SV_PrimitiveID、无索引方式、以及激发顶点(后续都称为Leading Vertex)是相对可用的方案;Mesh shader和软件光栅化是后续优化(针对平台)时的候选方案,不过第一步我们只实现了左边列出的3个方案。

为了决定最终选择,我们需要测试它们的性能表现——而这是一项艰巨的任务。幸运的是,Sebastian Aaltonen在多年以前就做过彻底的研究并把结果发到了twitter。他测试了一台NVIDIA、一台AMD和一台Intel内核的机器。
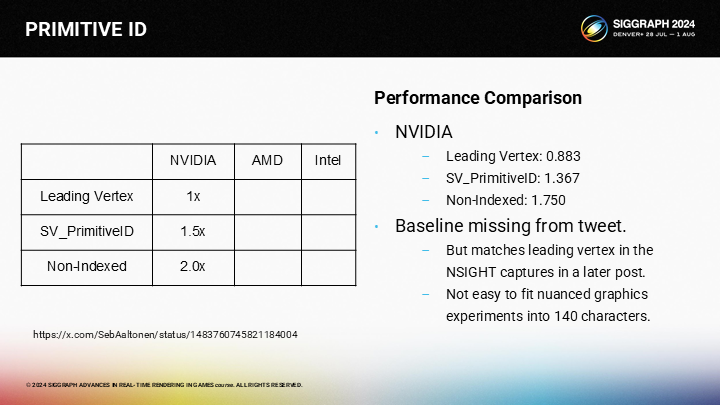
在NVIDIA,Leading Vertex是最快的选项。SV_PrimitiveID大约慢50%,而无索引方式大约慢一倍。

AMD的情况和NVIDIA类似。(具体如图中所示)
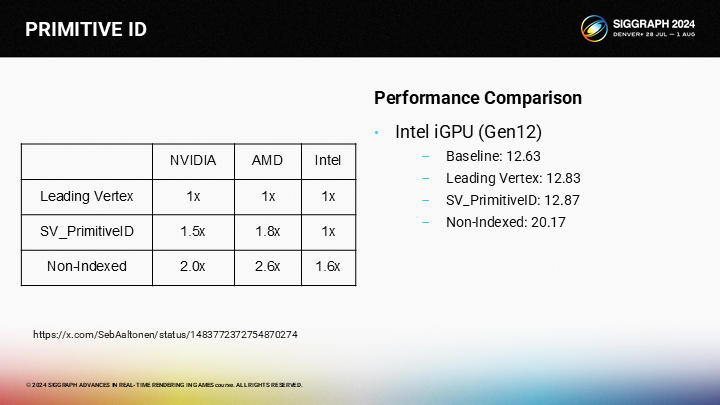
Intel的情况很有趣。它有着一个非常快的SV_PrimitiveID的实现,几乎没有额外开销。而无索引方式仍有显著的性能惩罚。
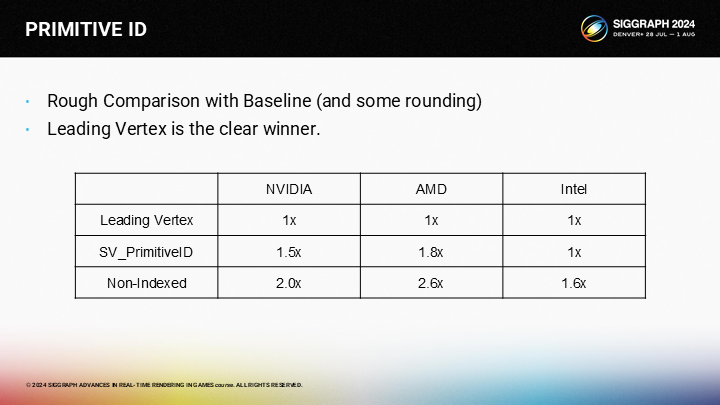
将它们汇总到一起并表示为基于基线的倍数,Leading Vertex是明显胜出的方案。另外2个方案都有不同的性能惩罚,而Leading Vertex仅有轻微的额外开销。
*下面的部分是一个算法推导,但结合图示来说不算复杂。
因此,让我们用一个例子来演示如何在一个三角形集群来实现leading vertex渲染。
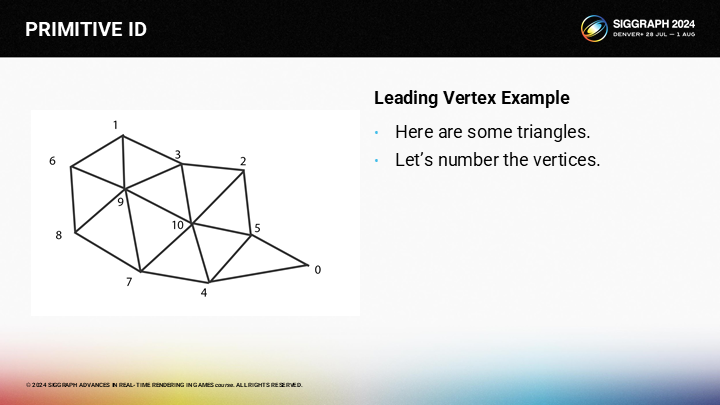
为了展示算法的概念,让我们如图所示将顶点编号。
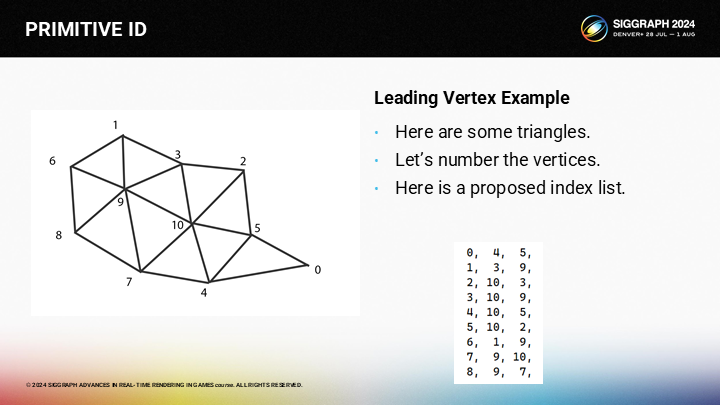
预期得到的索引列表如图所示(每行一个三角形的3顶点,递增)。
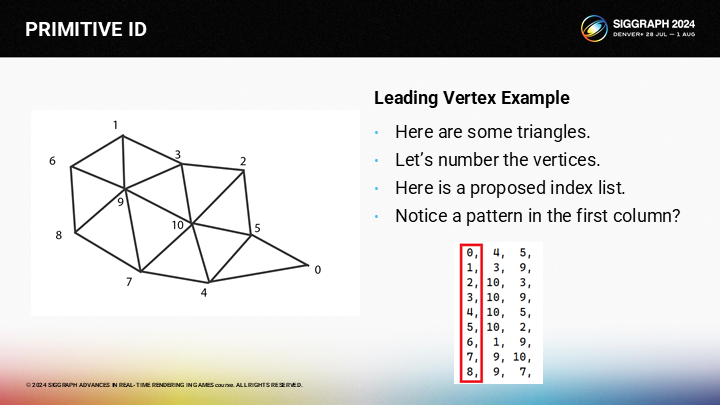
按照列表中的顺序,我们已经把数据设置成元ID匹配leading vertex的方式。

If we have the indices laid out in this way, the vertex shader is quite simple. The primitive id is simply the incoming vertex id. And we need a single indirection to convert the incoming index into the actual vertex buffer index.
当我们使索引以这种方式排列时,顶点shader就会很简单——(三角形的)元ID就和输入的顶点ID相同。之后我们需要一个单次的重定向,将输入的索引转换成实际的顶点缓冲区中的索引。
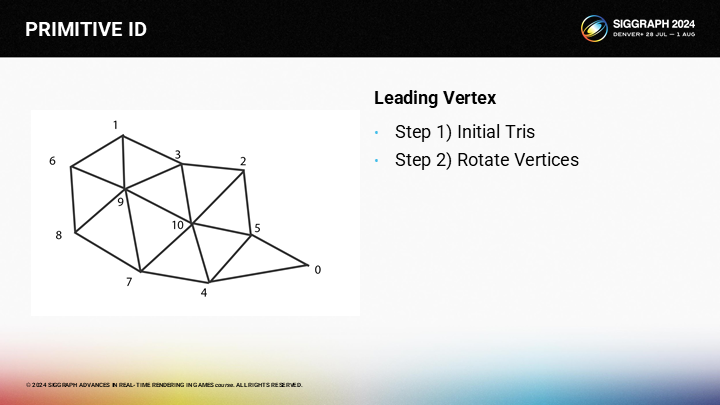
我们可以通过2个步骤将一个三角形集群优化成这种形式:
- 第一步,用贪婪算法尝试尽量分配更多的包含激发顶点的三角形
- 第二步,通过旋转顶点来填充步骤一剩余的三角形
*后面实际上说的是如何编号得到上述顶点ID分布的一套算法。
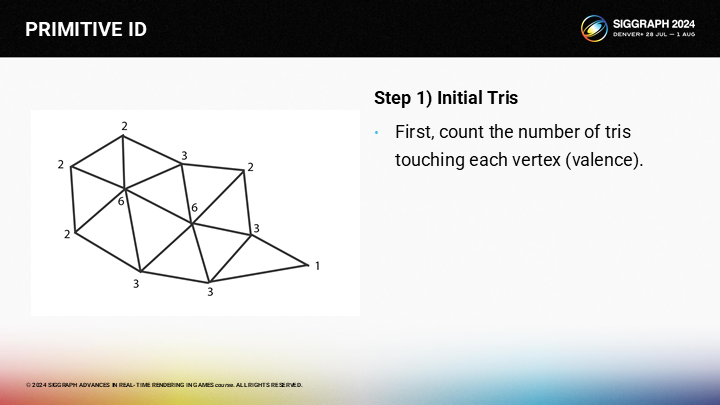
在步骤一中,首先需要计算每个顶点邻接的三角形数量。(这里用了类似化学的价的概念valence)
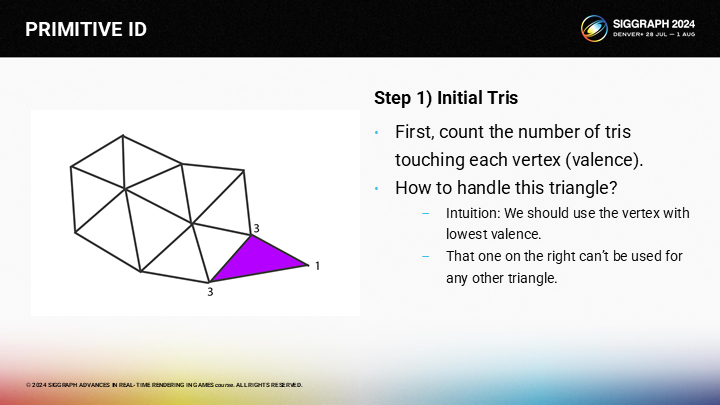
在这个步骤中,循环上是采用的贪婪策略为每个三角形选择最好的前向顶点。从直觉上(Intuitively),最“好”的选择就是有着最低价的顶点,而更高价的顶点则更可能被其它三角形公用。同时,这一策略也倾向于从边缘处的顶点开始计算。
*贪婪策略指每一步都使用局部数值上的最优解。
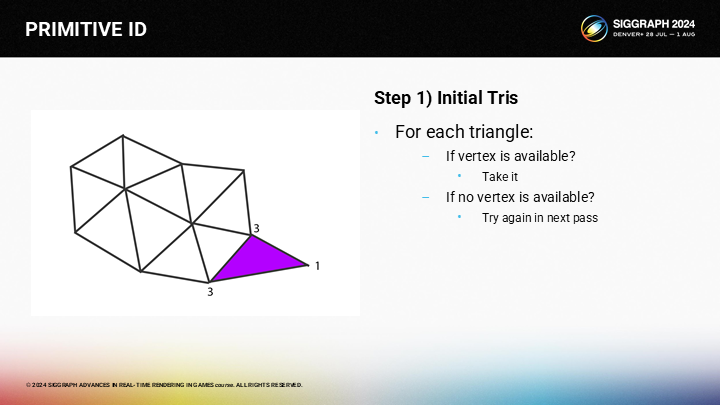
因此这个算法很简单——迭代每个三角形,选择最好的可用的激发顶点;如果没有可用顶点,则等待后一个步骤来处理。
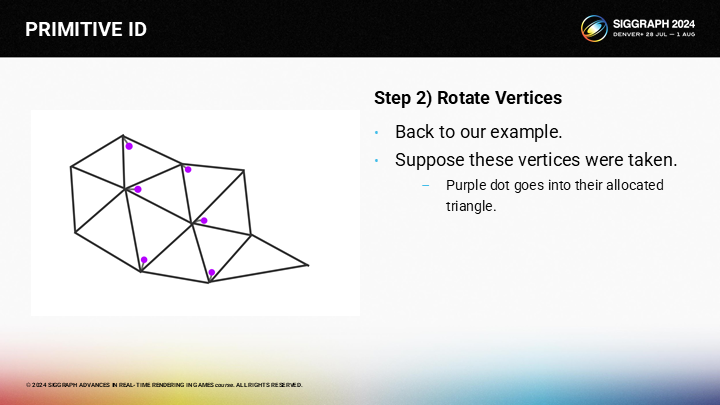
在执行完第一步后,部分三角形已经选择了激发顶点。在图中,紫色的小点标示出了这些三角形的激发顶点。
*这里我反复推演了一下如何得出如图的紫色点分布,但按我的理解这里作者应该只是大致标了一下用于演示,或者还遗漏了一些执行中的规则,否则按之前的规则并不能经过合理的循环得出如图的顶点分配。
*虽然这里的例子可能有瑕疵,但并不影响理解算法的思想。如果有觉得能正常推导出来这些点,欢迎在评论区留言。
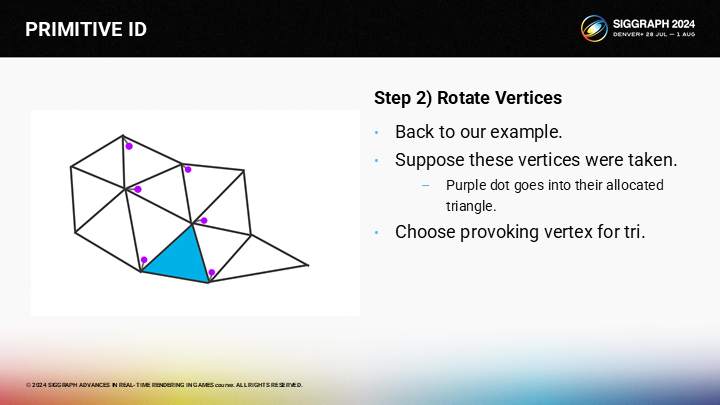
现在我们希望为蓝色的三角形选择激发顶点。
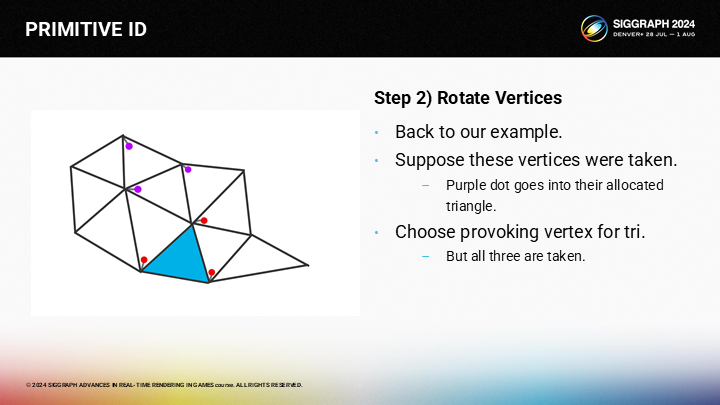
然而,它的所有顶点都被其它三角形选择过了。
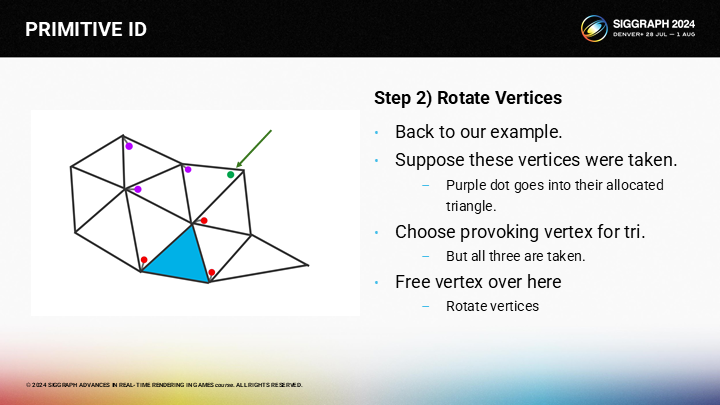
所幸的是,我们可以(从蓝色三角形的顶点)通过一轮深度优先搜索来查找到未选择的顶点(绿色)。
*深度优先是相对于广度优先的,在这里就是倾向于沿着一条边的路径一直查找下去;而广度优先就更倾向于每次处理完一个三角形的多条边。
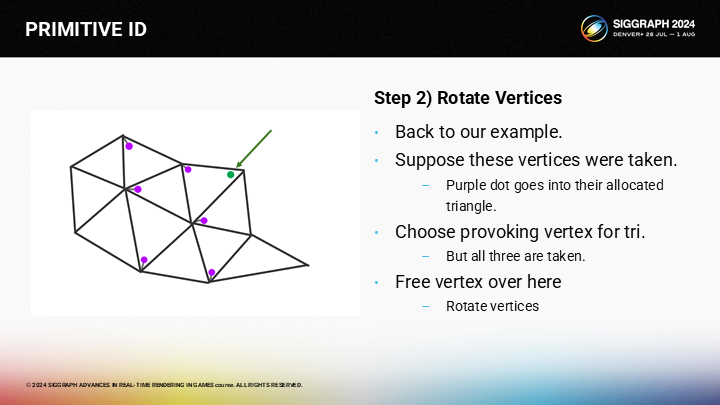
一旦我们找到一条路径(到空顶点),我们可以通过旋转激发顶点的方式来释放一个本来选中的顶点。
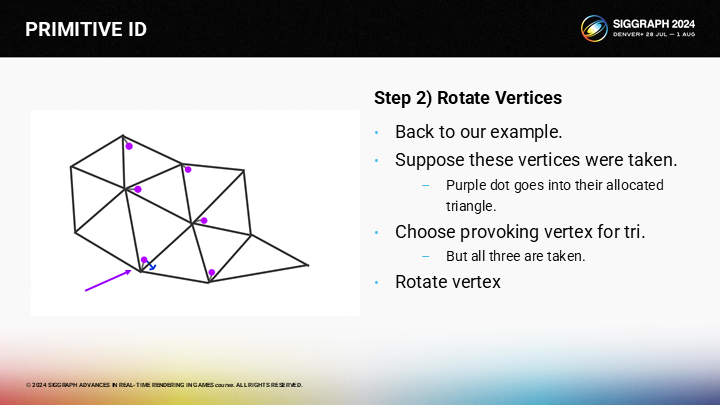
首先,我们旋转相邻三角形的激发顶点。
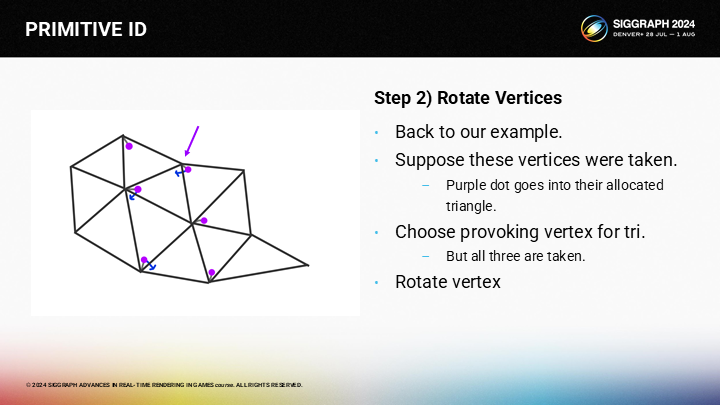
然后逐次递进至目标三角形。
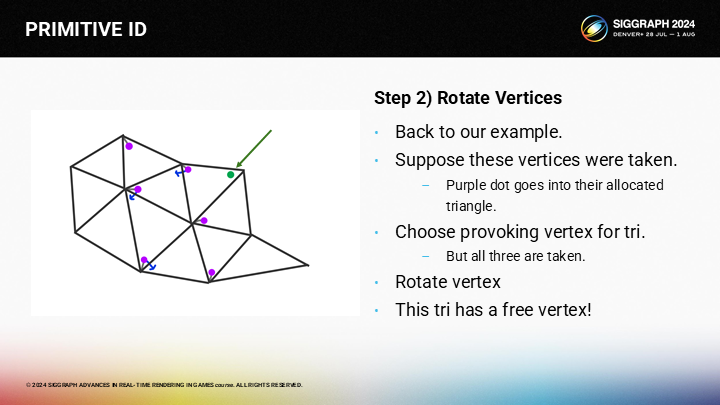
达到目标三角形后,之前的空闲顶点就可以被选择为激发顶点。
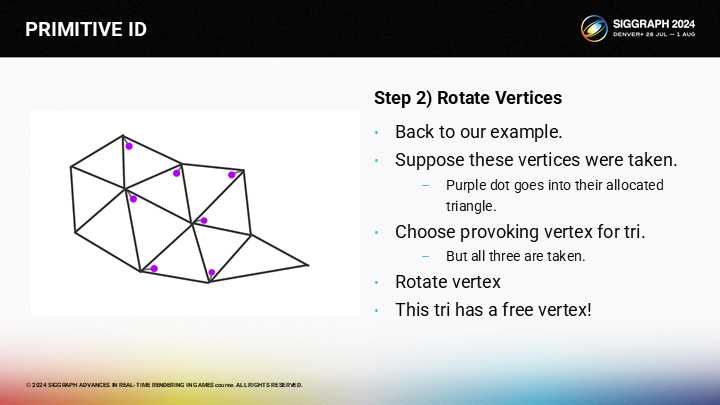
这样,我们就为已处理的三角形都分配了激发顶点。

回顾一下,这个算法在2个层面上执行。第一个步骤简单地选取最优的顶点——基于最低的价;第二个步骤执行一个深度优先搜索,并旋转所需的顶点。
实际上在多数情况中,第二步甚至不需要执行,因为第一步就已经为每个三角形找到了有效的激发顶点。

然而,这一方式在某些情况也会失效。在我的使用场合,集群始终包含64个三角形和64个顶点。
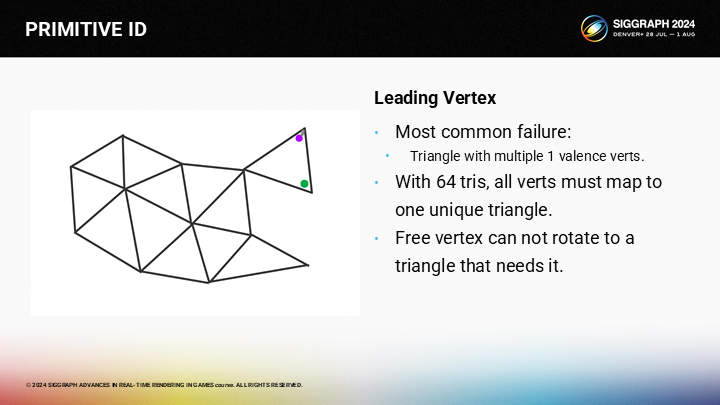
多数的失效情况是,其中一个三角形是以松散的方式与其它部分相连——通过一个单独的顶点。当它选择紫色的顶点作为激发顶点时,绿色的顶点并不能通过旋转进入集群中,因而就会出现集群中有三角形未分配激发顶点的情况。

这一算法已经并入了我的MeshOptimizer工具中,通常也用于LOD生成——因为它非常快速。MeshOptimzer基于一个贪婪算法,一次添加一个三角形到buffer中;一旦buffer超过你限制的值——在我的使用场合是64个三角形和顶点,则从buffer发出一个三角形集群,并开始一个新集群。
其中我在集群发出的部分做出了修改,基于激发顶点的考虑重排了三角形顺序。如果一个三角形无法找到一个激发顶点,则它会被放回buffer中用于下一个集群的生成。在实践中,通常所有三角形都是能匹配上的,但偶尔会有一两个三角形丢失的情况。

实际的数据在磁盘上是非常紧凑的。对于每一个集群,我们需要64个索引用于源顶点buffer,之后它们会被复制一份。
Also, we don’t need to store two of the three indices, as the first vertex is implied. If we pack them into 6 bits per index, 32bit index meshes end up as 5.5 bytes per triangle, which is a nice win for disk space over storing uncompressed indices.
并且,我们不需要存储三个顶点索引中的另外2个,因为第一个顶点已经指明了(它们的对应关系)。
*图中还列出了32bit和16bit索引的一些空间占用情况。

在实践中还会遇到另一个问题。假设我们想支持不同平台的不同网格实现,该如何做?例如,在交新的GPU使用mesh shader,在旧的GPU退回到leading vertex或传统的GBuffer渲染模式。
此时,我们并不想在磁盘上存储三份不同版本的网格数据。
幸运的是,将数据从leading vertex转换成其它数据描述方式的开销是很轻微的。在磁盘上你只需要保留紧密压缩的数据形式,之后你可以在运行时按需展开索引列表。当前的游戏在存储空间上都非常紧张,因此在我看来这项压缩对于传统的未排序索引列表或是传统GBuffer渲染都是有提升的。
*回顾一下,这里整个在做的都是实现顶点、三角形、顶点颜色数据1比1比1存储,以及有序访问。
结语
由于断更了一段时间,想简单谈谈我对我在机核更新的文章的思考。
首先我这些技术文章肯定也可以发在知乎,虽然我只是一个普通开发者不是什么大神,但是我也在知乎读到过翻译和解释得不如我的文章,比较起来这没什么心理负担——另外要说把一个复杂事情解释得相对好懂一些,我觉得自己还是努力做到了的。
在这个基础上,我的个人文章的另一部分,就是那些游玩感受、行业观察之类的,知乎是无处安放的——这就是我最初就选择投在机核的一个重要原因吧。并且,机核的网页编辑器使用起来也比较顺手,我不需要额外的网页编辑方式就能方便地排版和保存文章。最后,定期写点东西确实在我看来是很好的一种习惯,毕竟当前社会人多少都要做点自我表达,而这也是有一个慢慢熟练的过程的。
另外顺便聊聊我今天看到的一个游戏论坛讨论,主要是说光追技术这么耗费硬件,是否值得的问题——目前看来它带来的光影质量其实和游玩确实关系不大,反而会拖慢帧数。我认可这种现状,但也要说其实会这么想,还是因为现在的游戏都是兼容了传统的全局光照管线和光追管线,在两者并行的情况下光追的性价比不算高;另外就是自然光源的游戏相对不如科幻题材的游戏光追效果明显,这个也是事实;还有一个不可忽视的问题,是基于摩尔定律提升的硬件性能,在单核上已经快到头了,而针对多核的优化门槛就非常高了。
但是长期看来,光追和AI同步发展,一定会有一个量变到质变的过程——这也是我长期看技术文章的一个感受,因为图形学算起来也是有半个多世纪(算上数学基础的话上百年)的积累,这部分前沿的慢慢推进始终是有意义的。
下周继续更这篇文章的后半部分。最后是资料链接(其中有原作者提供的一些,可以下载了PPTX文件去找对应链接):
可见性缓冲的资料
可变着色率的资料
Variable Rate Shading with Visibility Buffer Rendering的PPTX地址
微软的 Variable Rate Shading 介绍
AMD的 AMD FidelityFX Variable Shading 介绍