fish-speech是一個開源文本轉語音項目,可以實現文本轉語音,同時能夠克隆音色,在github獲得超過17k⭐。
特徵&功能:
- 低樣本:輸入10-30s的聲音樣本即可生成高質量TTS輸出
- 多語言支持:支持英語、日語、韓語、中文、法語、德語、阿拉伯語和西班牙語
- 無音素依賴
- 準確率高
- 速度快
- 良好的UI:支持WebUI和基於pyQt的GUI
- 易於部署:支持Linux、Windows和macOS
這裡說一下,經過我自己的測試,一段50字左右的文本生成語音大約需要10s(顯卡是4060ti)。至於音色克隆的效果,在默認參數下,上傳一段10s的參考音頻,最終的輸出音色與原音色相似度高達80%!!!還可以根據說話人的語氣進行參數調整,相似度可進一步增加。
---------------
項目部署
環境:Windows11、Python11
硬件需求:NVIDIA顯卡
聲明:該部署流程為個人實踐並總結的最精簡流程,其他部署方式(如使用docker)或在其他操作系統上的部署請自行閱讀項目文檔。
流程:
0. 獲取fish-speech源碼(倉庫地址 fishaudio/fish-speech);下載CUDA ToolKit 12.x版本,並安裝
1. 運行源碼根目錄下"install_env.bat"開始安裝運行環境
2. 修改根目錄下"API_FLAGS.txt"文件來配置啟動模式:
①前三行這樣是直接進入推理界面:

②前三行這樣是進入配置界面(模型微調、推理服務器配置等):
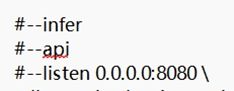
③前三行這樣是啟動API模式:
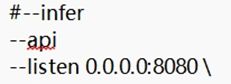
3. 這裡直接以第一種方式啟動。雙擊根目錄下"start.bat"啟動項目,啟動過程如遇到cachetools模塊缺失的問題,自行下載該python模塊並移動到"~\fish-speech-main\fishenv\env\Lib\site-packages\"文件夾下
4. 服務器正常啟動後訪問127.0.0.1:7860
即可進入推理界面:
部署過程中遇到任何問題請參考官方文檔!!
----------------
簡易使用教程
輸入文本、點擊"生成",默認是隨機音色,下面"高級參數"可以調參。
"參考音頻":選擇一段10s以內的清晰人聲音頻,在"參考文本"中輸入該音頻對應的語音文本,點擊生成。
好用!
感謝各位貢獻者無私的付出