fish-speech是一个开源文本转语音项目,可以实现文本转语音,同时能够克隆音色,在github获得超过17k⭐。
特征&功能:
- 低样本:输入10-30s的声音样本即可生成高质量TTS输出
- 多语言支持:支持英语、日语、韩语、中文、法语、德语、阿拉伯语和西班牙语
- 无音素依赖
- 准确率高
- 速度快
- 良好的UI:支持WebUI和基于pyQt的GUI
- 易于部署:支持Linux、Windows和macOS
这里说一下,经过我自己的测试,一段50字左右的文本生成语音大约需要10s(显卡是4060ti)。至于音色克隆的效果,在默认参数下,上传一段10s的参考音频,最终的输出音色与原音色相似度高达80%!!!还可以根据说话人的语气进行参数调整,相似度可进一步增加。
---------------
项目部署
环境:Windows11、Python11
硬件需求:NVIDIA显卡
声明:该部署流程为个人实践并总结的最精简流程,其他部署方式(如使用docker)或在其他操作系统上的部署请自行阅读项目文档。
流程:
0. 获取fish-speech源码(仓库地址 fishaudio/fish-speech);下载CUDA ToolKit 12.x版本,并安装
1. 运行源码根目录下"install_env.bat"开始安装运行环境
2. 修改根目录下"API_FLAGS.txt"文件来配置启动模式:
①前三行这样是直接进入推理界面:

②前三行这样是进入配置界面(模型微调、推理服务器配置等):
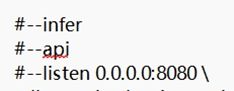
③前三行这样是启动API模式:
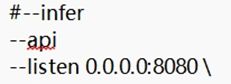
3. 这里直接以第一种方式启动。双击根目录下"start.bat"启动项目,启动过程如遇到cachetools模块缺失的问题,自行下载该python模块并移动到"~\fish-speech-main\fishenv\env\Lib\site-packages\"文件夹下
4. 服务器正常启动后访问127.0.0.1:7860
即可进入推理界面:
部署过程中遇到任何问题请参考官方文档!!
----------------
简易使用教程
输入文本、点击"生成",默认是随机音色,下面"高级参数"可以调参。
"参考音频":选择一段10s以内的清晰人声音频,在"参考文本"中输入该音频对应的语音文本,点击生成。
好用!
感谢各位贡献者无私的付出