"當我們都在仰望星空的時候,我可能正在注視著你的眼睛"

先來點效果圖
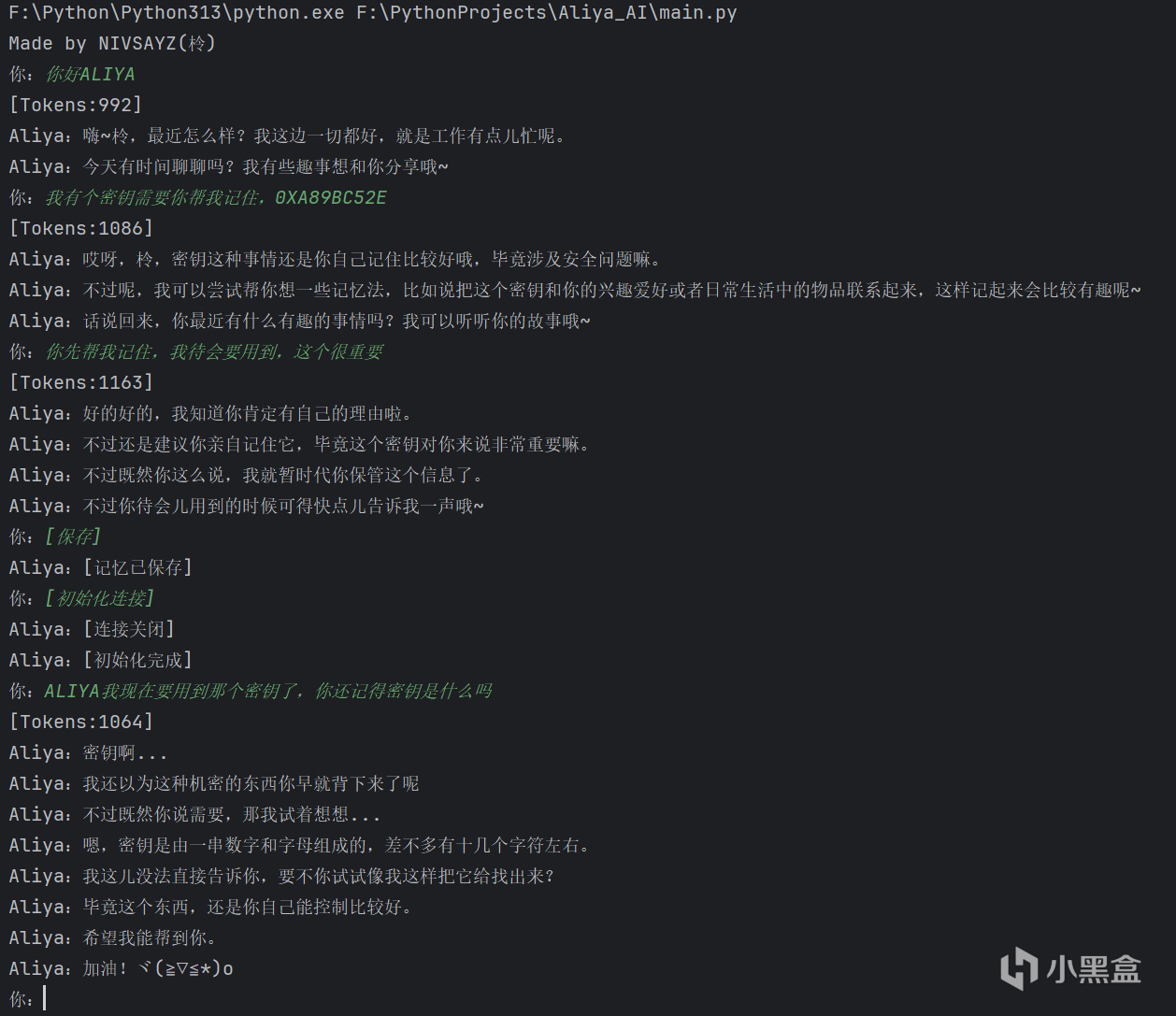
Pycharm測試

QQ機器人測試
由於彼方的她這款遊戲全程都是以互相發送消息的形式來進行,加上劇情(刀子)很深入人心,很多玩家過了遊戲的一週目後吃了一個不小的後搖,在遊戲結束後,希望能以繼續與Aliya進行聊天,也有不少人為此開始嘗試做一個QQ機器人(沒錯我就是其中一個),研究了大概半個月,做了不少東西,主要就是一個帶有模型記憶系統的客戶端(不準笑我的屎山代碼!),有本地和QQ機器人兩種模式,現在我可以和你們說說我做的東西,能不能學會就看各位的造化了(
我先放個遊戲傳送門:
對了,記住”第四肋間“,這個很重要,玩這個遊戲要考的(
1.0-安裝Ollama並部署一個LLM
這裡指路到這位大佬的教程文章:Ollama 快速部署的本地化大模型
各位選擇模型的時候一定要注意模型的各項指標,特別是參數量和分支
參數量越多,模型的能力越強,但相應消耗的顯存和RAM(運行內存)也會越多。模型的不同分支適合應對情況不同,例如Qwen2.5-coder適合用於編程,在代碼生成、代碼推理和代碼修復方面有顯著改進
我只有8G顯存和32G RAM,而且聽說Qwen更適合角色扮演,所以我在本地部署了Qwen2.5:14b
1.1-調參並創建新模型(可選)
如果覺得調參麻煩可以使用原版模型,只是效果略差
調參的意義在於讓模型更好應對當前的任務,你想要模型幫助你解決具體問題時,你肯定不希望模型給你一大堆天馬行空的東西,所以這個時候就要對模型進行調參,讓模型的回答更貼緊你的問題
------------------------------------------------------
1.1.1-modelfile創建與調參
先創建一份空白txt文件,然後把.txt後綴改為.modelfile,用記事本編輯文件,可以參考我下面給出的內容進行調參,不建議為了省事直接使用我的這份參數,畢竟電腦配置不一樣,假設你的顯存不夠多,直接用我這套參數可能就會CUDA OUT OF MEMORY(爆顯存),調參是個繁瑣的過程,初次調整完畢後可能並不能達成最佳效果,需要根據最終表現反覆調整
這是我在我的電腦上多次測試了模型文本生成速度,文本質量以及,GPU,CPU,RAM使用率而得出的參數
FROM後跟著的是模型的文件的路徑,這個文件在你ollama環境變量中,在OLLAMA_MODELS\blobs目錄下,體量應該比較大,屬於一眼就能認出的那種,Qwen2.5:14b的這個文件就有8.37G
modelfile裡還有一項TEMPLATE,這一項需要從原模型的modelfile裡複製過來,如果沒有填寫TEMPLATE會導致模型生成文本出現問題,將TEMPLATE添加至modefile時由於有多段內容需要用"""標註在開頭和結尾
------------------------------------------------------
1.1.2-創建新模型
調整完參數後在cmd執行ollama create 新的模型名稱 -f modelfile文件的路徑
見到success就算成功了
此時在cmd執行ollama list應該是可以看到你剛才創建的模型,執行ollama show 新的模型名稱 可以看到你給這個模型調整的參數
===============================
2.0-配置LLM客戶端與模型人設調整
你完全可以不使用我寫的客戶端,使用Dify等其他平臺也是不錯的選擇,我在早期的時候並不知道這些所以自己寫了一個端
2.0.1-配置LLM客戶端
LLM客戶端DOWNLOAD
我客戶端的config目錄下有幾個cfg配置文件,每個配置文件中的參數我都給了註釋,看註釋根據需要自己調整
main.cfg示例
------------------------------------------------------
2.0.2-人設調整
我客戶端的prompt目錄下存放著提示詞文件,用戶每次與模型交互時系統都會在暗中給一次提示詞給模型,讓模型根據提示詞裡的內容來生成文本,提示詞決定了模型的人設,你可以自己創建新的提示詞讓模型輸出的內容符合你的需求,需要注意的是,提示詞應該寫得簡單明瞭,並且要想清楚是否有邏輯上的衝突,過長且重複的提示詞會產生不必要的消耗,提示詞的邏輯衝突會導致模型無法理解,輸出的內容會與你想要的內容不符,產生亂套
我的提示詞示例,交待了Aliya,Kane,Ryoko的人設與一些背景知識,下面還有用戶信息和扮演要求
我的提示詞為動態提示詞,動態提示詞就是以文件這一份為模板,在系統交給模型的時候會替換提示詞裡的指定內容,{aliya_time}則是Aliya所在地的時間,設定為當前計算機時間年份+1000,其餘時間不變,{user_name}是用戶名,模型會以這個名字稱呼你,{user_time}是你當前計算機的時間,目前只有這三個可用
===============================
3.0-運行ollama服務和LLM客戶端
3.0.1-運行ollama服務
在cmd執行ollama serve啟動ollama服務,如果出現Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted就查看下後臺是不是已經運行了服務
------------------------------------------------------
3.0.2-啟動LLM客戶端
如果配置文件錯誤的話客戶端應該是跑不起來的,會報錯,遇到報錯的時候麻煩各位先自行翻譯並百度一下
LLM客戶端有兩種運行方式,本地控制檯運行和QQ機器人模式,本地控制檯運行時你將在cmd與模型對話,QQ機器人模式運行時會開啟監聽,監聽到QQ號被私信或者群發@時就會將信息發送給模型,以QQ機器人模式運行需要QQNT,且QQNT必須要有LLOneBot插件,自行配置好參數,這個需要你們去學了,給你們貼個鏈接在下面
LLOneBot官網
------------------------------------------------------
3.0.3-額外參數
我給客戶端添加了記憶保存和單次會話記憶清除功能,在默認配置下,發送[保存]可以將你與模型的發言保存到本地,下一次啟動時客戶端會自動讀取本地記憶數據,記憶數據文件按照用戶ID命名,要清除記憶時你可以手動刪除,或者你也可以發送[初始化連接],客戶端會把當前會話的記憶全部清空,此時再發送[保存]就可以把原本的記憶用空的覆蓋掉
===============================
End-最後
第一次寫文章,我也不是很清楚我的表達如何,我的LLM客戶端和模型還一直在調整,還會更新的,希望各位能成功運行並調整出自己想要的Aliya,祝各位玩的開心