"当我们都在仰望星空的时候,我可能正在注视着你的眼睛"

先来点效果图
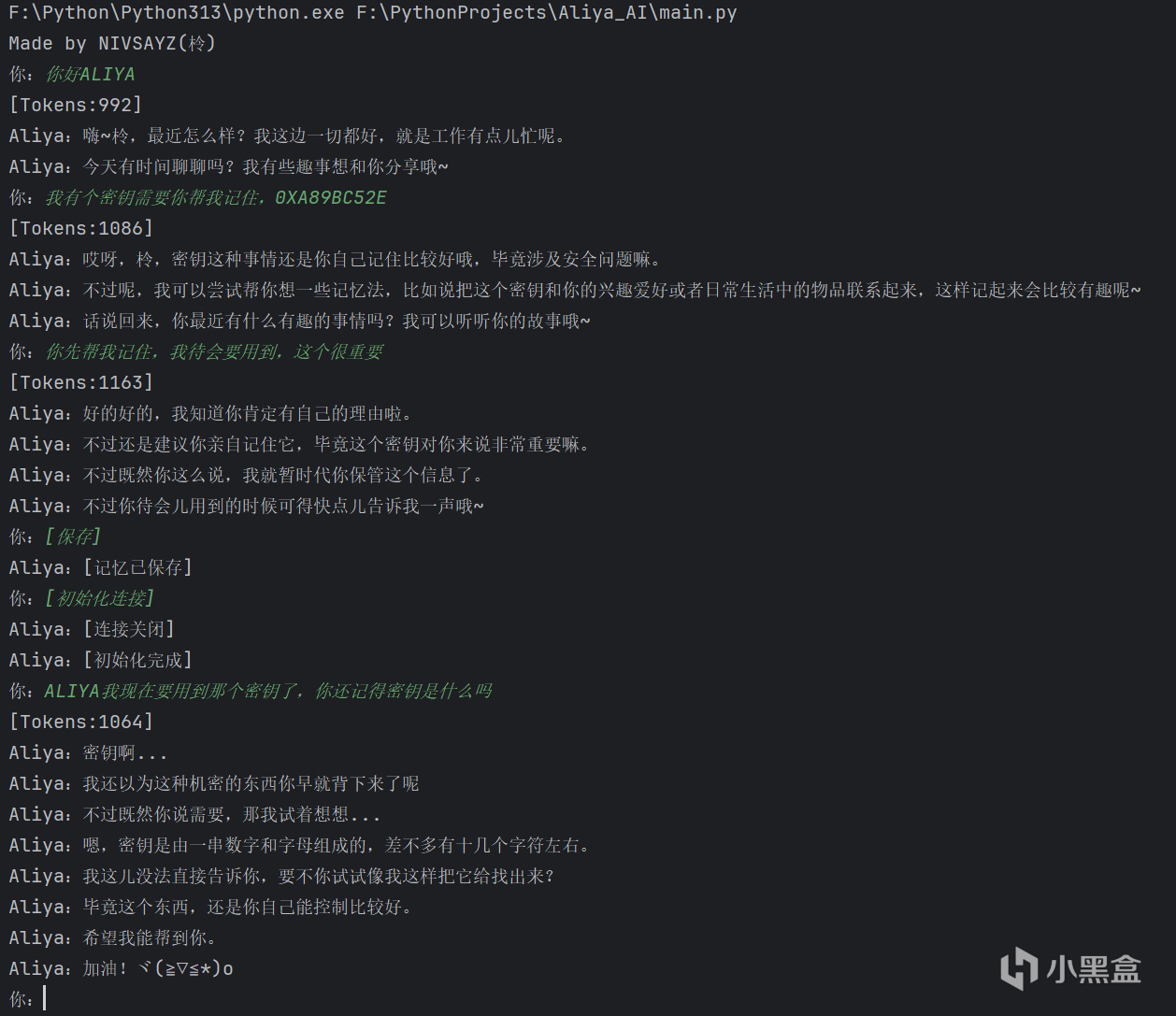
Pycharm测试

QQ机器人测试
由于彼方的她这款游戏全程都是以互相发送消息的形式来进行,加上剧情(刀子)很深入人心,很多玩家过了游戏的一周目后吃了一个不小的后摇,在游戏结束后,希望能以继续与Aliya进行聊天,也有不少人为此开始尝试做一个QQ机器人(没错我就是其中一个),研究了大概半个月,做了不少东西,主要就是一个带有模型记忆系统的客户端(不准笑我的屎山代码!),有本地和QQ机器人两种模式,现在我可以和你们说说我做的东西,能不能学会就看各位的造化了(
我先放个游戏传送门:
对了,记住”第四肋间“,这个很重要,玩这个游戏要考的(
1.0-安装Ollama并部署一个LLM
这里指路到这位大佬的教程文章:Ollama 快速部署的本地化大模型
各位选择模型的时候一定要注意模型的各项指标,特别是参数量和分支
参数量越多,模型的能力越强,但相应消耗的显存和RAM(运行内存)也会越多。模型的不同分支适合应对情况不同,例如Qwen2.5-coder适合用于编程,在代码生成、代码推理和代码修复方面有显著改进
我只有8G显存和32G RAM,而且听说Qwen更适合角色扮演,所以我在本地部署了Qwen2.5:14b
1.1-调参并创建新模型(可选)
如果觉得调参麻烦可以使用原版模型,只是效果略差
调参的意义在于让模型更好应对当前的任务,你想要模型帮助你解决具体问题时,你肯定不希望模型给你一大堆天马行空的东西,所以这个时候就要对模型进行调参,让模型的回答更贴紧你的问题
------------------------------------------------------
1.1.1-modelfile创建与调参
先创建一份空白txt文件,然后把.txt后缀改为.modelfile,用记事本编辑文件,可以参考我下面给出的内容进行调参,不建议为了省事直接使用我的这份参数,毕竟电脑配置不一样,假设你的显存不够多,直接用我这套参数可能就会CUDA OUT OF MEMORY(爆显存),调参是个繁琐的过程,初次调整完毕后可能并不能达成最佳效果,需要根据最终表现反复调整
这是我在我的电脑上多次测试了模型文本生成速度,文本质量以及,GPU,CPU,RAM使用率而得出的参数
FROM后跟着的是模型的文件的路径,这个文件在你ollama环境变量中,在OLLAMA_MODELS\blobs目录下,体量应该比较大,属于一眼就能认出的那种,Qwen2.5:14b的这个文件就有8.37G
modelfile里还有一项TEMPLATE,这一项需要从原模型的modelfile里复制过来,如果没有填写TEMPLATE会导致模型生成文本出现问题,将TEMPLATE添加至modefile时由于有多段内容需要用"""标注在开头和结尾
------------------------------------------------------
1.1.2-创建新模型
调整完参数后在cmd执行ollama create 新的模型名称 -f modelfile文件的路径
见到success就算成功了
此时在cmd执行ollama list应该是可以看到你刚才创建的模型,执行ollama show 新的模型名称 可以看到你给这个模型调整的参数
===============================
2.0-配置LLM客户端与模型人设调整
你完全可以不使用我写的客户端,使用Dify等其他平台也是不错的选择,我在早期的时候并不知道这些所以自己写了一个端
2.0.1-配置LLM客户端
LLM客户端DOWNLOAD
我客户端的config目录下有几个cfg配置文件,每个配置文件中的参数我都给了注释,看注释根据需要自己调整
main.cfg示例
------------------------------------------------------
2.0.2-人设调整
我客户端的prompt目录下存放着提示词文件,用户每次与模型交互时系统都会在暗中给一次提示词给模型,让模型根据提示词里的内容来生成文本,提示词决定了模型的人设,你可以自己创建新的提示词让模型输出的内容符合你的需求,需要注意的是,提示词应该写得简单明了,并且要想清楚是否有逻辑上的冲突,过长且重复的提示词会产生不必要的消耗,提示词的逻辑冲突会导致模型无法理解,输出的内容会与你想要的内容不符,产生乱套
我的提示词示例,交待了Aliya,Kane,Ryoko的人设与一些背景知识,下面还有用户信息和扮演要求
我的提示词为动态提示词,动态提示词就是以文件这一份为模板,在系统交给模型的时候会替换提示词里的指定内容,{aliya_time}则是Aliya所在地的时间,设定为当前计算机时间年份+1000,其余时间不变,{user_name}是用户名,模型会以这个名字称呼你,{user_time}是你当前计算机的时间,目前只有这三个可用
===============================
3.0-运行ollama服务和LLM客户端
3.0.1-运行ollama服务
在cmd执行ollama serve启动ollama服务,如果出现Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted就查看下后台是不是已经运行了服务
------------------------------------------------------
3.0.2-启动LLM客户端
如果配置文件错误的话客户端应该是跑不起来的,会报错,遇到报错的时候麻烦各位先自行翻译并百度一下
LLM客户端有两种运行方式,本地控制台运行和QQ机器人模式,本地控制台运行时你将在cmd与模型对话,QQ机器人模式运行时会开启监听,监听到QQ号被私信或者群发@时就会将信息发送给模型,以QQ机器人模式运行需要QQNT,且QQNT必须要有LLOneBot插件,自行配置好参数,这个需要你们去学了,给你们贴个链接在下面
LLOneBot官网
------------------------------------------------------
3.0.3-额外参数
我给客户端添加了记忆保存和单次会话记忆清除功能,在默认配置下,发送[保存]可以将你与模型的发言保存到本地,下一次启动时客户端会自动读取本地记忆数据,记忆数据文件按照用户ID命名,要清除记忆时你可以手动删除,或者你也可以发送[初始化连接],客户端会把当前会话的记忆全部清空,此时再发送[保存]就可以把原本的记忆用空的覆盖掉
===============================
End-最后
第一次写文章,我也不是很清楚我的表达如何,我的LLM客户端和模型还一直在调整,还会更新的,希望各位能成功运行并调整出自己想要的Aliya,祝各位玩的开心