谷歌的DeepMind研究者們最近推出了一種新的AI訓練方法,該方法顯著減少了完成任務所需的計算資源和時間。據最新研究報告,這種通常耗能巨大的過程通過新方法得以加快和降低成本,這對環境可能是個好消息。

研究指出,這種名為多模態對比學習與聯合示例選擇(JEST)的方法“在迭代次數上超越了現有最先進的模型,減少了多達13倍,計算需求減少了10倍。”
AI行業以其高能耗而聞名。例如,大規模AI系統如ChatGPT需要大量的處理能力,這反過來又需要大量的能源和水來冷卻這些系統。由於AI計算需求增加,微軟的水資源消耗在2021年至2022年間據報增加了34%,ChatGPT被指控每處理5到50個提示就消耗近半升水。
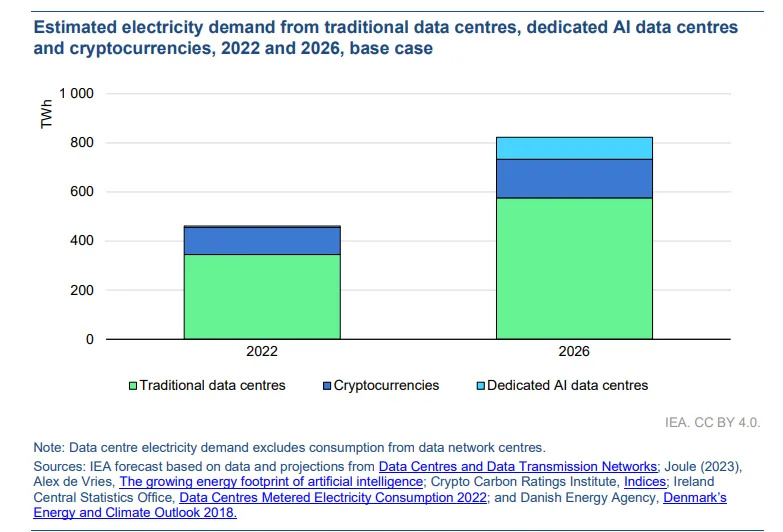
國際能源署(IEA)預計,從2022年到2026年,數據中心的電力消耗將翻倍,這使得AI的功率需求與常受批評的加密貨幣挖礦行業的能源概況相媲美。
然而,如JEST這樣的方法可能提供了一種解決方案。谷歌表示,通過優化AI訓練的數據選擇,JEST能顯著減少迭代次數和計算力需求,這可能會降低總體能源消耗。這種方法符合提高AI技術效率和減輕其環境影響的努力。
如果這種技術在大規模應用中證明是有效的,AI培訓者將只需使用一小部分目前用於訓練模型的功率。這意味著他們可以用現有資源創建更強大的AI工具,或者用更少的資源開發新模型。
JEST的工作方式
JEST通過選擇互補的數據批次來最大化AI模型的可學習性。與選擇單個示例的傳統方法不同,該算法考慮了整個集合的組成。
例如,假設你正在學習多種語言。你可能會發現,不是分別按難易程度學習英語、德語和挪威語,而是將它們一起學習,在一種語言的知識支持另一種語言的學習過程中更有效。
谷歌採取了類似的方法,並證明它是成功的。
研究人員在論文中指出:“我們證明,聯合選擇數據批次對於學習比獨立選擇示例更有效。”
為此,谷歌研究人員使用了“多模態對比學習”,其中JEST過程識別了數據點之間的依賴關係。這種方法提高了AI訓練的速度和效率,同時大大減少了計算能力的需求。
該方法的關鍵是從預訓練的參考模型開始,以指導數據選擇過程,谷歌指出。這種技術讓模型專注於高質量、精選的數據集,進一步優化了訓練效率。
論文解釋說:“一批次的質量還取決於其組成,而不僅僅是獨立考慮其數據點的總和質量。”
研究的實驗顯示,在各種基準測試上都取得了穩固的性能提升。例如,使用JEST在常見的WebLI數據集上進行訓練,顯示了學習速度和資源效率的顯著改善。
研究人員還發現,該算法很快就發現了高度可學習的子批次,通過專注於“匹配”在一起的特定數據片段,加速了訓練過程。這種被稱為“數據質量自舉”的技術,重視質量而不是數量,並已證明對AI訓練更有利。
論文中指出:“在一個小型精選數據集上訓練的參考模型可以有效指導更大數據集的策劃,使得訓練出的模型在許多下游任務上的質量大大超過參考模型。”