谷歌的DeepMind研究者们最近推出了一种新的AI训练方法,该方法显著减少了完成任务所需的计算资源和时间。据最新研究报告,这种通常耗能巨大的过程通过新方法得以加快和降低成本,这对环境可能是个好消息。

研究指出,这种名为多模态对比学习与联合示例选择(JEST)的方法“在迭代次数上超越了现有最先进的模型,减少了多达13倍,计算需求减少了10倍。”
AI行业以其高能耗而闻名。例如,大规模AI系统如ChatGPT需要大量的处理能力,这反过来又需要大量的能源和水来冷却这些系统。由于AI计算需求增加,微软的水资源消耗在2021年至2022年间据报增加了34%,ChatGPT被指控每处理5到50个提示就消耗近半升水。
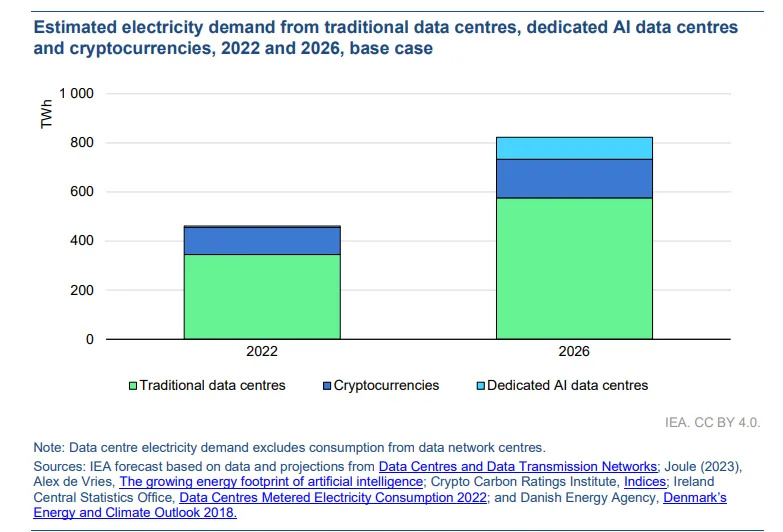
国际能源署(IEA)预计,从2022年到2026年,数据中心的电力消耗将翻倍,这使得AI的功率需求与常受批评的加密货币挖矿行业的能源概况相媲美。
然而,如JEST这样的方法可能提供了一种解决方案。谷歌表示,通过优化AI训练的数据选择,JEST能显著减少迭代次数和计算力需求,这可能会降低总体能源消耗。这种方法符合提高AI技术效率和减轻其环境影响的努力。
如果这种技术在大规模应用中证明是有效的,AI培训者将只需使用一小部分目前用于训练模型的功率。这意味着他们可以用现有资源创建更强大的AI工具,或者用更少的资源开发新模型。
JEST的工作方式
JEST通过选择互补的数据批次来最大化AI模型的可学习性。与选择单个示例的传统方法不同,该算法考虑了整个集合的组成。
例如,假设你正在学习多种语言。你可能会发现,不是分别按难易程度学习英语、德语和挪威语,而是将它们一起学习,在一种语言的知识支持另一种语言的学习过程中更有效。
谷歌采取了类似的方法,并证明它是成功的。
研究人员在论文中指出:“我们证明,联合选择数据批次对于学习比独立选择示例更有效。”
为此,谷歌研究人员使用了“多模态对比学习”,其中JEST过程识别了数据点之间的依赖关系。这种方法提高了AI训练的速度和效率,同时大大减少了计算能力的需求。
该方法的关键是从预训练的参考模型开始,以指导数据选择过程,谷歌指出。这种技术让模型专注于高质量、精选的数据集,进一步优化了训练效率。
论文解释说:“一批次的质量还取决于其组成,而不仅仅是独立考虑其数据点的总和质量。”
研究的实验显示,在各种基准测试上都取得了稳固的性能提升。例如,使用JEST在常见的WebLI数据集上进行训练,显示了学习速度和资源效率的显著改善。
研究人员还发现,该算法很快就发现了高度可学习的子批次,通过专注于“匹配”在一起的特定数据片段,加速了训练过程。这种被称为“数据质量自举”的技术,重视质量而不是数量,并已证明对AI训练更有利。
论文中指出:“在一个小型精选数据集上训练的参考模型可以有效指导更大数据集的策划,使得训练出的模型在许多下游任务上的质量大大超过参考模型。”