
大语言模型的热潮带来了一波又一波的ai应用,仿佛一夜之间不会用大语言模型就已经落伍了。相较于一开始大语言模型对硬件的极致消耗,现在的大语言模型在推理阶段已经不需要再消耗那么高的显存和性能了,部署平台也从云服务器逐渐走向了边缘计算。而我们一般玩家现在已经拥有了可以用来跑语言模型的显卡,却囿于不熟悉深度学习平台,导致有力无处使
上一次我比较详细地做了一个AMD平台显卡的ROCm深度学习计算部署的教程,但是毕竟是在命令行下运行,涉及到很多软件的安装以及环境配置,对于一般玩家来说还是太麻烦了。所以这次,我就出一个简单的完全不需要配置环境的大语言模型部署教程,来教大家怎么利用性能过剩的显卡(bushi)在本地部署大语言模型
简介
首先来简单介绍一下AMD的ai计算目前对大语言模型(以下简称LLM)的支持状况,除开cDNA这种专门用来训练LLM的计算卡,专业卡和一般的游戏显卡的6000系以及7000系,还有目前已经配备了NPU的8000 APU,都能支持ROCm加速。而Meta公司的Llama以及其他优化后的LLM,也支持了ROCm平台
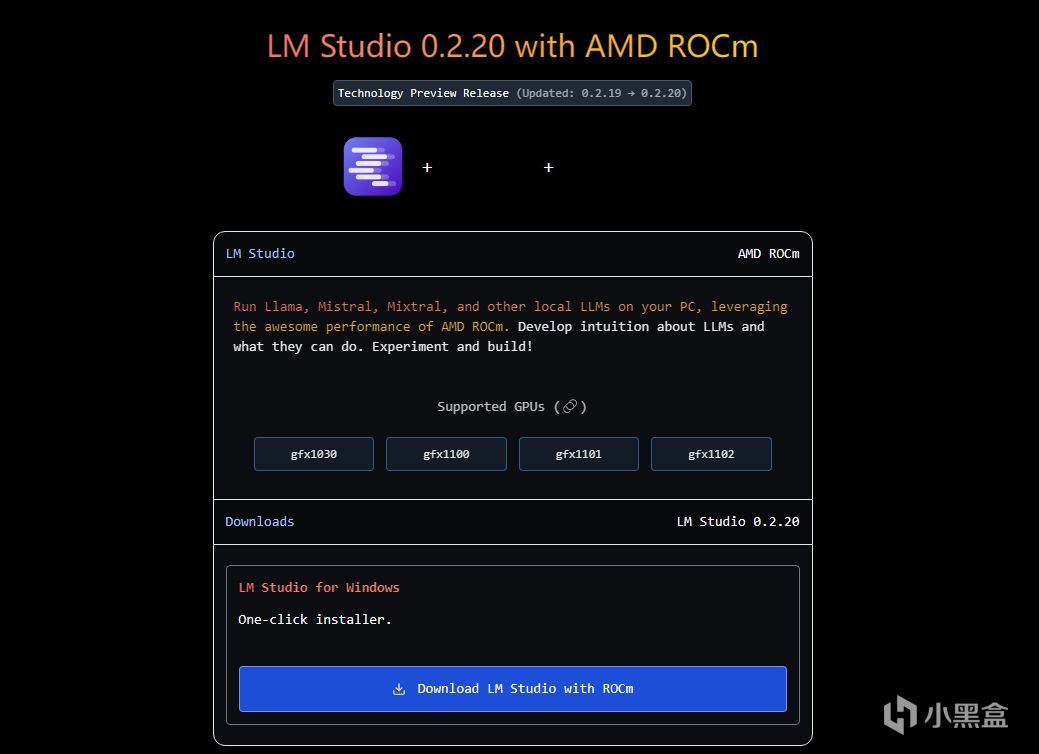
本次要用到的软件,就是一个专门为LLM所设计的部署工具,名叫LM Studio,可以在这个链接进行下载:LMSTUDIO。这个软件已经支持了ROCm加速,而且GUI做得非常好
使用的平台为AMD的7900X+RX7900XT,内存为金士顿的Renegade 6400 48Gx2。这个配置也是上次用于ai绘画的教程中的硬件配置,性能非常充裕,可以灵活地适配各种应用
部署Llama3 8B大语言模型+测试性能
下载好LM studio with ROCm之后就能直接打开,安装过程我就不多说了,和一般软件没有区别。打开之后可以看到一个总览页面,里面有各种来源和规模的LLM可供部署
然后我们搜索一下Llama,下载Llama3 8B,这时候大家就会发现下不动,因为这些模型开发者为了图省事,是直接用的huggingface的来源。这个来源下载速度本身就很慢,很容易就会出现失败。但是不用担心,因为点开正在进行的下载任务,下载链接就在下方的下载详情中,直接复制即可
下面放入浏览器里面,直接回车就能用浏览器的下载器进行下载,因为浏览器的下载器一般只会进行原网页的下载,所以这样依旧很慢,如果不嫌慢的话一晚上应该能下好
所以我们叫出某不知名P2P下载器,某雷可以利用多个来源进行加速,直接从国内下好的地址转过来,速度直接提升无数倍。下好的模型当然也是没有办法直接用的,需要放入指定的位置软件才能读取到
软件边栏里面有一个文件夹图标,打开这一项,上方有一个show in file explorer,点击即可进入模型的文件夹
因为模型从属于不同来源的不同分支,所以在这个文件夹下还需要单独为Meta/Llama创建文件夹,然后把模型按照./Meta/Llama/下载好的模型放入,这样软件就能读取到模型的信息了
然后我们打开边栏的对话图标,最上方的选项里就能插入这个已经下好的模型,那么话不多说,赶紧加载一下尝尝味道吧
对于一般的8000系APU和ZEN4的Ryzen CPU而言这样基本就结束了,但是如果有一张规模比较大的显卡的话,就要把右边边栏中的Hardware Setting的GPU Offload打开到max,这样才能使用全部的GPU核心
打开之后需要重新加载一次模型让模型从内存中转移到显存里面,然后我们来问模型一些简单问题,就能看到模型的性能消耗明显从核显+独显(第一个峰值)转变为了纯独显(第二个峰值)这样的模式
为了让大家直观的感受到显卡带来的加速,我测试了各个档位下的推理速度,从max到无dGPU
可以看到在8layer以及16layer下,GPU的加速并不算明显,但是开到max之后,就能得到质的飞跃。而就算不开dGPU加速,Ryzen本身的推理能力就不差,而且也算是ROCm设备,同样可以实现简单的加速,有一个不错的基础速度
Llama经过重新训练之后的8B模型确实非常快,一张显卡生成速度直接起飞,比云端上的API接口反应迅速很多,而且没有明显的道德和政治倾向。而且因为是独立的本地模型,不会存在数据泄露的风险,所以就安全性而言比云端的服务要好很多
本地API接口
如果有进阶的应用需求,那就需要用到API接口,而LM Studio也有对应的功能,在边栏中有一项就是打开本地接口。但是在运用上并不简单,接口需要搭配前端使用,会玩的朋友可以自己试试,我就不单独讲解了,一般玩家也确实用不上这个
总结
大语言模型的革新浪潮不可避免,因为它的工具属性实在是太强了,和一般的AI应用相比泛用性强太多,而且可塑性也非常不错,现在我都已经见到不少大语言模型用作剧本杀和跑团bot 的情景了。而大语言模型也能给我们平时带来不少便利,语言模型最强的功能就是Summarization,也就是从各种来源的信息中搜罗总结出凝练的结论,对于查资料和查方法来说非常好用
而本地部署的大语言模型在下载完成后就能完全离线使用,不用担心数据泄露以及隐私暴露问题。而且下载好的语言模型不具有记忆性不具有学习行为,虽然没什么长进,但是也避免了越用越歪的情况,毕竟想要更新的模型随时都可以从LM Studio里找到,用歪了重下对本地使用还是会有影响的。AMD的ROCm在大语言模型推理上已经经过了优化,仅使用CPU就已经能有不错的基础性能,在GPU加速之后对话生成非常流畅,尤其是7900XT完全加速之后可以用畅爽来形容,所以大家赶紧利用好手里的显卡,也来试试大语言模型能不能给你带来帮助吧
硬件介绍
下面是部署时用的硬件