前言
雖然已經粗讀了幾篇關於虛幻5引擎的文章了——實際上自從2021年開始Epic在SIGGRAPH上分享的乾貨非常多,只是之前確實沒有《黑神話:悟空》這樣的契機,來激發我把它們都很詳細的看一遍(包括當年我個人悟性也還不足)。
可以說在《黑神話:悟空》前,確實沒有太多深度使用虛幻5在高質量寫實渲染方面特性的產品(勉強可以算一個《墮落之主》,但畫面感覺和開發規模其實沒法比;其它規模比較大的產品都沒那麼寫實;更多的還是用的虛幻4,管線其實很不同)。
用其它引擎實際達到了極高的(光線追蹤全局光照)渲染上限的,我個人認為只有《電馭叛客2077》,但也是通過不斷修修補補(以及頭鐵開發超前於硬件水平的內容)達到的;而近年來實際畫面精度特別高的其它遊戲,例如《荒野大鏢客:救贖2》《戰神:諸神黃昏》《地平線:西域禁地》以及育碧的一些產品等,整體來說還屬於前光追時代的全局光照產品,它們要考慮向下兼容或者兼容較差硬件的顧慮更多;而其源發的《戰爭機器》系列,由於其商業路線等原因導致的系列衰落,本來最應該扛起引擎宣傳大旗的產品也漸漸起不到這個作用了。
就像之前Nvidia找高清遊戲演示顯卡,基本只能找《電馭叛客2077》一樣,這個意義上確實可以認為《黑神話:悟空》為虛幻5的商業可行性提供了強有力的支持。在Unity引擎在商業上幾乎放棄了高清渲染的當下,虛幻5的這一點就顯得很可貴——在此之前也確實有很多人對(當前經濟狀態下)大家的硬件能否帶的動那麼高清的遊戲表示疑慮。所以我才在上個系列文章中說,高清的渲染總得有人做——這個事情是一個第三方商業引擎來做(而不是由第一方開發內部壟斷的),對有表達需求的開發者來說算是一件幸運的事。
這次選的是2022年SIG上的一篇分享,原文檔是以PPT為主,每頁下面搭配了一行左右的解說稿。本文還是以翻譯原文PPT頁及解說稿為主,打星號的部分則是我個人的補充。由於篇幅原因還是拆分成上下兩篇,這是其中的上篇。 由於內容信息量爆炸,中間有些概念沒法一一搭配解釋,還請諒解。
1 整體概覽
*如果看過我其它介紹渲染的文章,可能會感覺寫實渲染就是繞不開“間接光照”這四個字了。確實,不僅引擎之間不同,同一個引擎不同版本不同管線的實現也不同。因此一深入細節總是從這裡開始。
*這裡有大量使用path這個詞,除了在“追蹤路徑”中翻譯成路徑,其它一律翻譯成“方案”,以作明顯的區分。

夢想——實時間接光照
我們始終有著對於全實時間接光照的夢想——這能解鎖全新的玩家與遊戲世界互動的方式(光照上的)。烘焙光照限制很多,即使在很小的事項上——例如開門或摧毀一堵牆。如果這些動態不足的問題能被間接光照解決,可以想象能看到更多複雜的交互方式。
我們也想要一個對光照藝術家更好的工作流程。相比於等待幾分鐘甚至幾小時來等待烘焙的結果,我們希望能立即可見(調整的)結果——想象如果能實時編輯光照能帶來多大的光照質量提升。
我們也想要巨大的不經過烘焙的開放世界,同時解決在一個大項目中使用烘焙光照的其它問題——例如上百人每天同時編輯一個場景,而烘焙光照無法保持最新。
只解決戶外的高質量間接光照也是不夠的,我們希望能達到烘焙光照能達到的所有效果——包括細節光照和陰影。

挑戰
而在挑戰的方面,我們想匹配的烘焙質量是通過(與實時相比)成百上千倍的處理時間來達成的,即使在很小的地圖上也是如此。
Global Illumination is fundamentally incoherent, and it’s a challenge to solve that light transfer efficiently when GPU’s are designed for memory and execution coherency.
全局光照是基本非連貫的(incoherent),要解決光傳播計算無法充分利用GPU的內存和執行的連續性的問題也是一個挑戰。
這也是一個巨大的問題空間(problem space)——即我們可選的方案很多,因此選擇使用哪些方案而不用哪些方案也是巨大的挑戰。
留給實時全局光照的性能預算空間(margins)很小,因此很難同時滿足性能和質量兩方面的要求——就像在山巔行走一樣,微小的移動都可能導致性能或質量的下降。
下面我會在最高層做Lumen算法的總覽,並在後續的部分中逐步深入細節。

基本問題1:如何追蹤射線?
在實時間接光照上首先要解決的問題是:我們要如何在世界中追蹤射線。
硬件光線追蹤很強大——並且是未來的方向,但我們也需要相對小規模的備選項。在PC市場上仍有很多圖形卡(就是顯卡 video cards)不支持硬件光線追蹤,同時主機提供的硬件光線追蹤也不夠快。
我們也希望能處理網格高度重疊的場景——這在硬件光線追蹤的兩層加速結構中運行很慢。
因此我們需要開發一個軟件光線追蹤方案來突破這些限制。

早期實驗:把場景作為高度場來追蹤(cards)
When we started working on Software Ray Tracing, one of the first things we tried was to capture the scene using a bunch of orthographic cameras, giving what we call cards. We then ray trace through the card heightfields, and sample the card lighting when the ray hits.
當我們開始軟件光線追蹤方案的探索時,我們嘗試的第一步是:通過一些正交攝像機(orthographic cameras)來抓取場景——抓取的中間結構被我們稱為場景卡(cards 後面就保留英文原文)。然後我在card的高度場(heightfields)中追蹤,採樣射線命中部位的光照信息。
由於這是一種2D表面描述的方式,它提供了較高的空間分辨率——相較於3D描述的例如體素等方案來說。我們可以利用高度場的屬性得到很快的軟件追蹤效果,例如視差遮擋數據(Parallax Occlusion Mapping)。
不過終究來說,高度場無法覆蓋整個場景,這樣未被覆蓋的區域會導致漏光問題。

網格有向距離場追蹤
所以作為替代我們選擇了網格有向距離場(Mesh Signed Distance Fields)作為我們軟件光線追蹤的幾何描述結構。這能帶來可靠的遮擋關係,所有區域都被覆蓋了,並且我們仍然能通過球面追蹤方式來快速進行射線追蹤——跳過了空白的空間(距離場的特性保證的)。
與距離場的相交僅能獲知位置和法線信息,因此我們無法查找材質參數或光照。

源自表面緩存的光照
We interpolate the lighting where the ray trace hit from the cards, which we call the Surface Cache. Areas that are missing coverage only result in lost energy, instead of leaking. Ray tracing the card heightfields didn’t work, but using them for lighting does.
我們通過插值的方式從射線命中cards中的位置取光照數據,這被我們稱為表面緩存(Surface Cache)。未覆蓋的區域會導致結果中能量的損失,而不是漏光(*漏光是更白,損失能量就更黑)。
追蹤高度場(作為整體追蹤方案)不可行,但使用來作為光照追蹤方案是可行的。

表面緩存bonus
表面緩存有一些其它的好處:它能在不同射線之間共享材質公式,使我們能直接控制與更新表面緩存,並解鎖更快的使用硬件光線追蹤的方案。
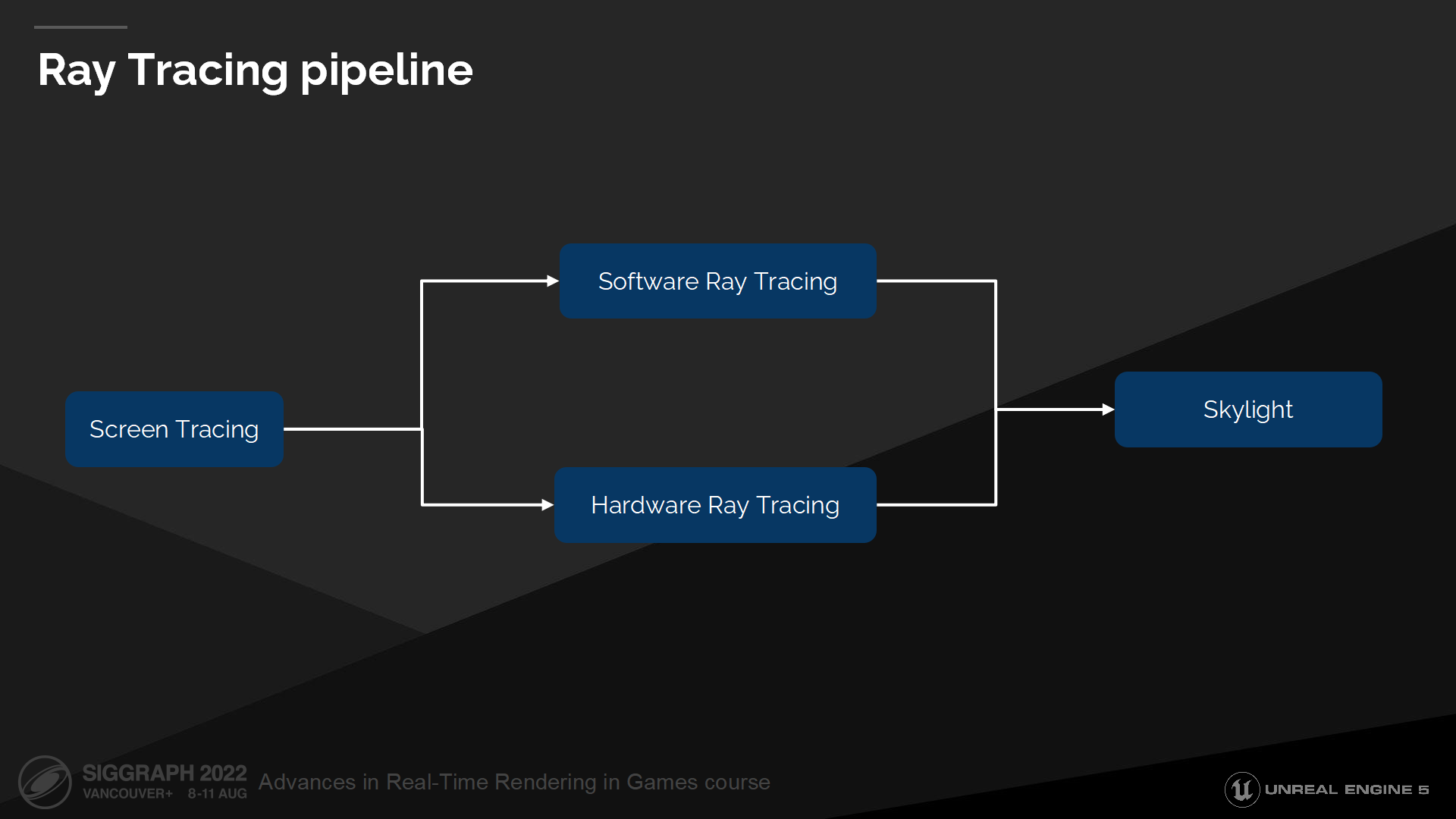
光線追蹤管線
*先做屏幕空間追蹤,如果需要再做軟件或硬件的光線追蹤(基於追蹤類型配置、硬件等),全部miss時最後追蹤天空光照顏色。
*前2步其實之前介紹《戰神:諸神黃昏》的文章裡面他們也採用了類似的方案,因為通常來說屏幕空間的方案精度往往更高一些。

基本問題2:如果解決整個間接光照的方案?
只提供一次間接光照彈射計算是不夠的,我們對於室內場景需要多次彈射的漫反射,以及在反射視圖中考慮全局光照。
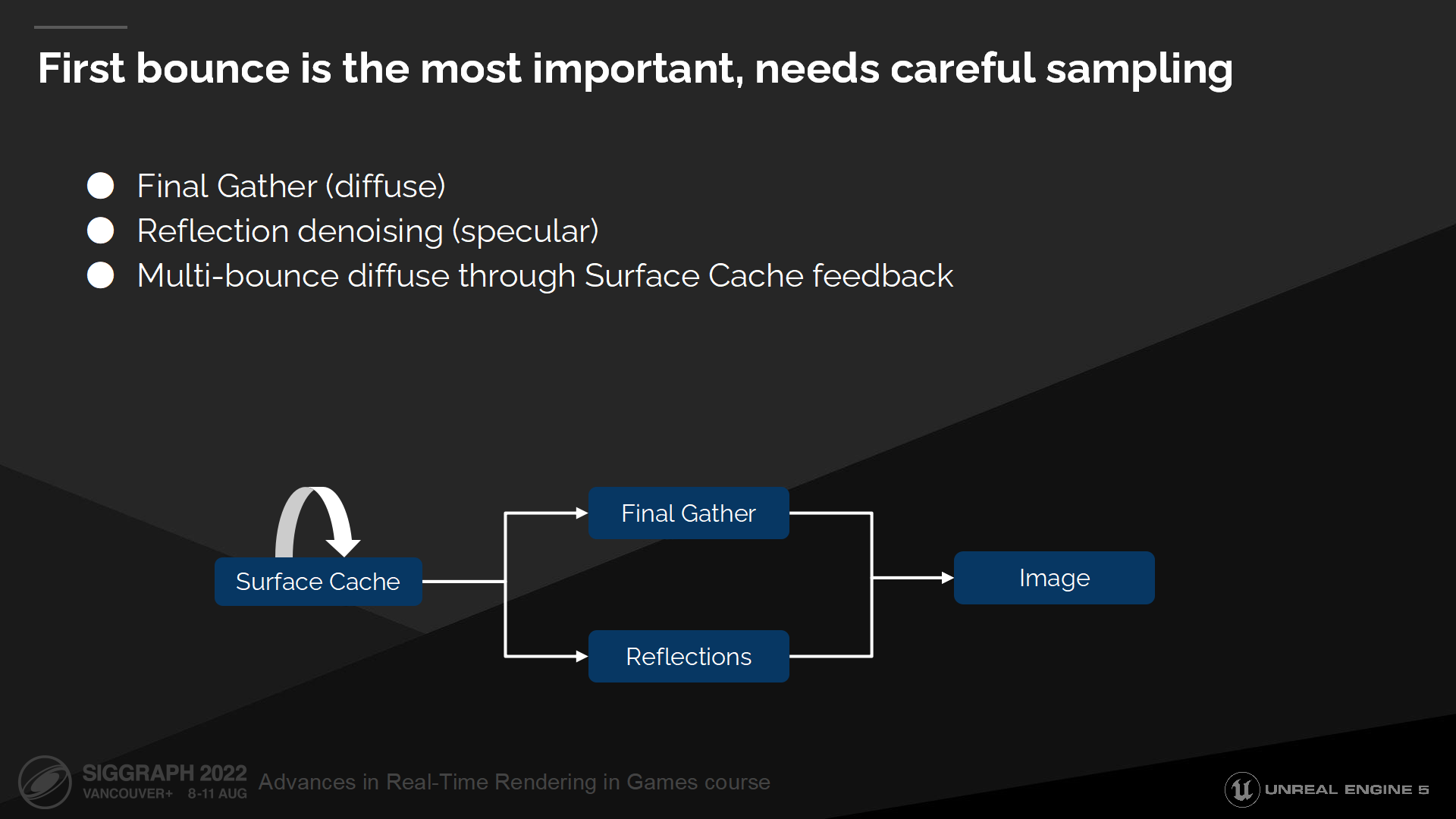
第一次彈射是最重要的,需要細緻地採樣
首次彈射是最重要的,因此我們將把它拆分出來並用專門的技術方案來解決——對於漫反射部分我們使用被稱為Final Gather的方案,對於高光部分我們則使用反射降噪(reflection denoising)。
第一次彈射之後的彈射我們通過表面緩存的反饋來解決。我們將從表面緩存中收集數據——並被它自身讀取,每次更新都傳播(propagate)並計算其它間接光照中的彈射。
*這裡實際上還是有不同層的card之間傳播光能量的過程,當傳播算完後緩存就穩定住了。原文可能略微有點繞了。

基本問題3:如何解決光傳播中的噪聲問題
考慮到我們甚至無法負擔每幀每像素1射線,但高質量的室內渲染需要(每像素)上百個高效的採樣。
*這個問題及其方案探索其實上一個介紹屏幕空間光照緩存的系列中也提到了。總體來說肯定是用各種分時方案來彌補,但細節完全不同。

Final Gather 技術
這些都導向了我們Final Gather技術的提出。我們將使用自適應的降採樣方式來追蹤儘量少的射線,在空間和時間上儘量重用射線(及其追蹤結果),並與重要性採樣(Importance Sampling)做乘積以保證射線分配到更合適的方向。
*重用射線、重要性採樣等部分其實上個系列中也相對詳細的介紹過了,例如基於BRDF做重要性採樣等。
*到這裡Final Gather這個概念已經塞進了間接光照、追蹤降噪等事項要解決。

Final Gather的域
我們的Final Gather不能只解決不透明(opaque)的情況,也需要能解決半透明(Transparency)和霧(Fog)的情況。
對於不透明物體我們在一個2D域中操作,對於霧我們需要計算攝像機視錐體中的所有點,對於表面緩存我們則從一個紋理空間中收集數據(如圖)。
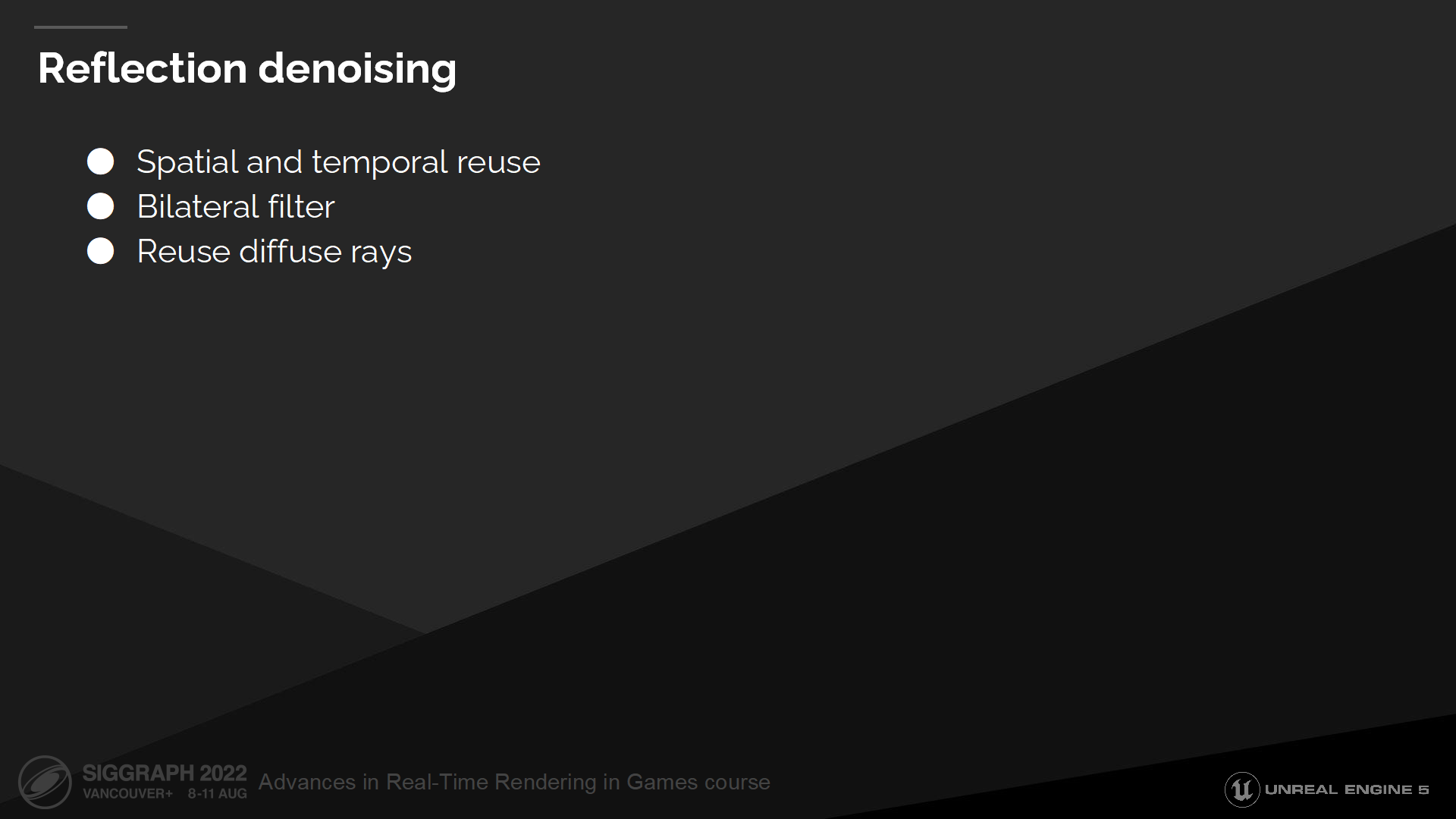
反射降噪
為解決反射噪聲問題,我們將以一定方式進行空間和時間上的射線重用,並在可能的位置重用漫反射射線(結合雙邊過濾器)。

方案概覽
*幾個部分分別是:光線追蹤管線、Final Gather、反射、性能與可擴展性。
*光線追蹤需要的幾個部分前面都已經引入了。
2 屏幕射線追蹤
*在傳統的現代渲染管線中,其實屏幕空間追蹤就有很多可以聊(之前也介紹過一些)。但到了光追時代,這類技術更像成為了一種“基礎建設”。
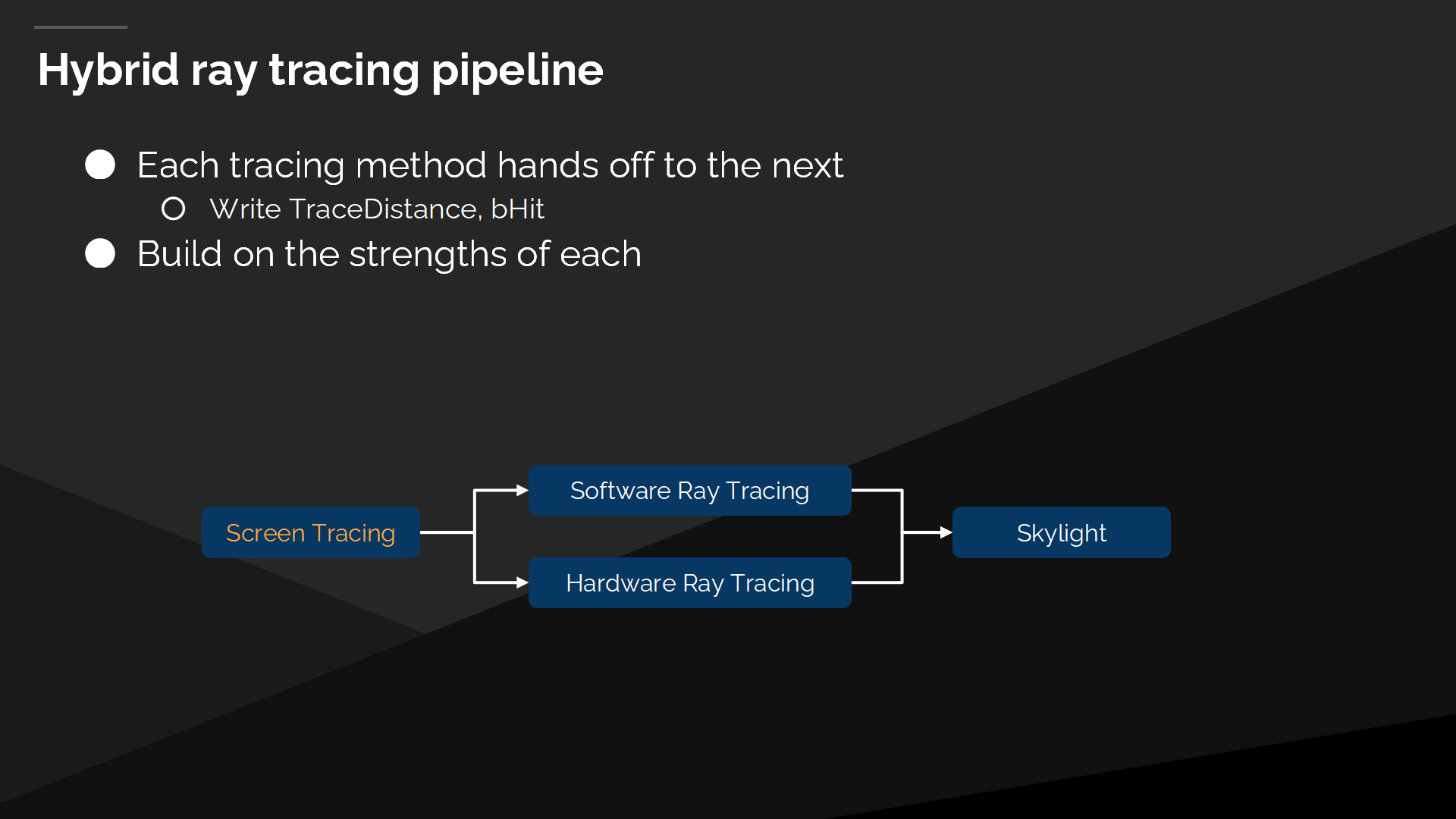
混合的光線追蹤管線
Lumen使用了一個混合的(hybrid)光線追蹤管線,它允許混合並匹配多種不同的技術。首先考慮的是屏幕空間追蹤,然後每個追蹤方法都把數據交給下一步,通過輸出射線追蹤的距離、或是命中的情況。下一個追蹤步驟可以重啟上一步留下的可用的射線。

屏幕空間追蹤的好處
無論軟件還是硬件光追,都存在對於光柵化的GBuffer有錯配的問題(mismatches 後續會介紹到)。屏幕空間的追蹤能很好處理這種錯配的情況,包括可能導致“自相交”的故障——從物體內開始追蹤(精度問題),或是追蹤結果的錯配都會導致漏光問題。

屏幕空間追蹤的好處
屏幕空間追蹤也很善於處理主要追蹤方式沒有覆蓋的幾何體定義方式,例如我們的軟件光追就不支持蒙皮網格(skinned meshes 動畫用),但我們仍然可以通過屏幕空間追蹤得到間接光照的陰影。
屏幕空間追蹤可以在任何尺寸規模下生效,所以它也是對細節GI有效的——無論你放大到什麼程度。

線性步驟跳過細的遮擋物
屏幕空間追蹤不能很好的適應線性步驟(指步長)——這會導致跳過細物體,就像圖中的欄杆一樣,進而導致漏光問題。
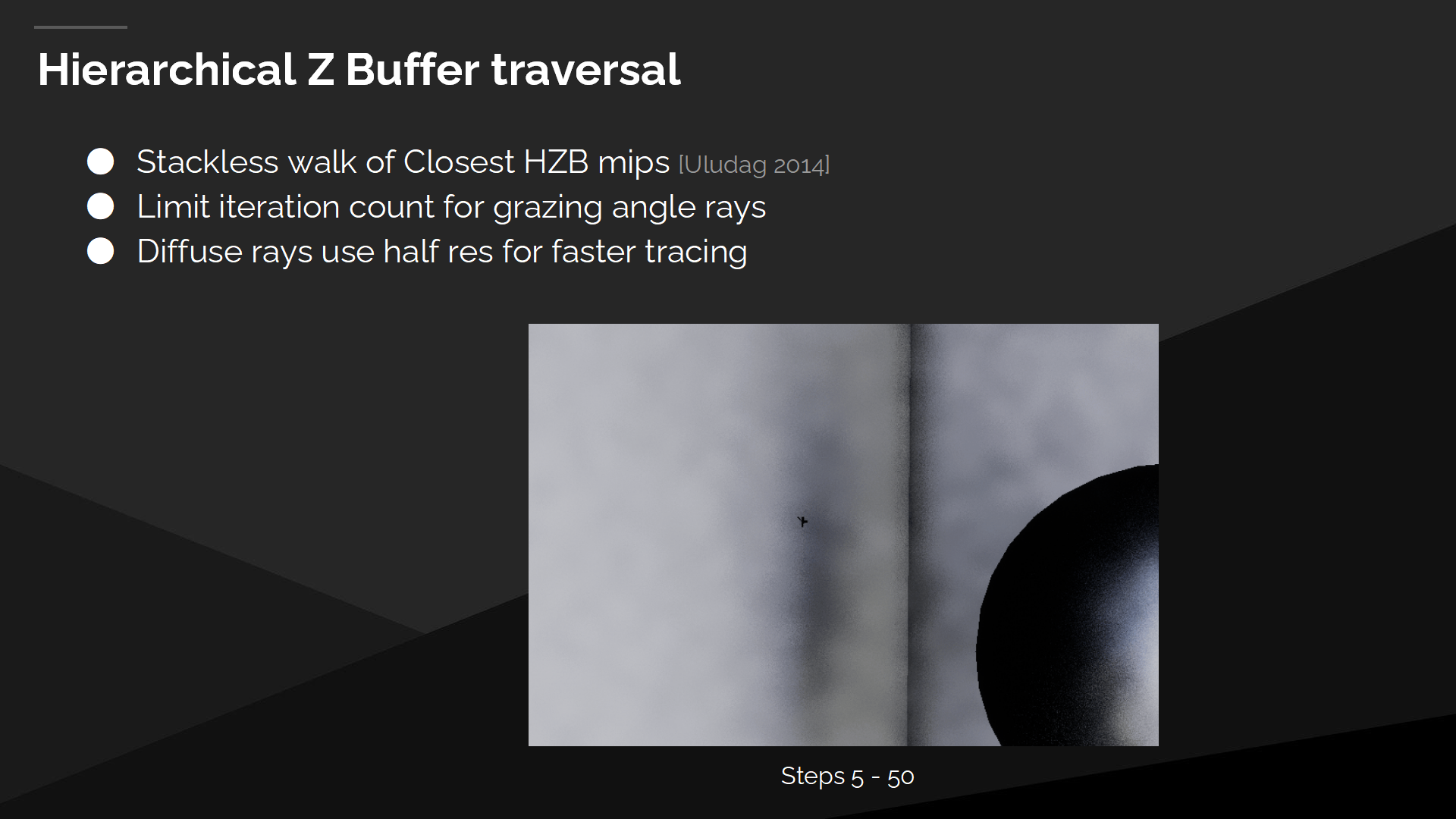
Hi-Z Buffer遍歷
作為替代我們採用HZB遍歷的方式——它是一種針對最接近的HZB mip的無堆棧查找方式。我們限制了掠射角(grazing angle)射線的迭代次數,例如與牆平行的射線;並且我們的漫反射射線使用半精度以達成更快的追蹤速度。

*原文檔有一個動畫展示了每一步射線追蹤執行的過程(長度逐步延伸的)。這裡直接截取了執行一定步驟後的追蹤情況示意圖。
*關於Hi-Z Buffer(縮寫HZB)以前介紹過,也可以搜搜網上講現代渲染管線的文章。

準確地傳遞給下一個追蹤方法
我們必須確保準確的把數據傳遞給下一步追蹤方法,否則就會導致漏光問題。
我們通過(在步進追蹤的過程中)回退到最後一個未遮擋的位置以解決這一問題——當射線進入物體表面或離開屏幕範圍時。

屏幕空間追蹤的結果
總的來說,屏幕空間追蹤完全勝在質量上,儘管能實現的質量越高,穿幫時就越能被注意到。
結合硬件光線追蹤它也能帶來小的性能提升——因為它允許大部分射線脫離複雜的表面集合來運算(屏幕空間的不透明幾何已經被深度緩衝處理過了)。
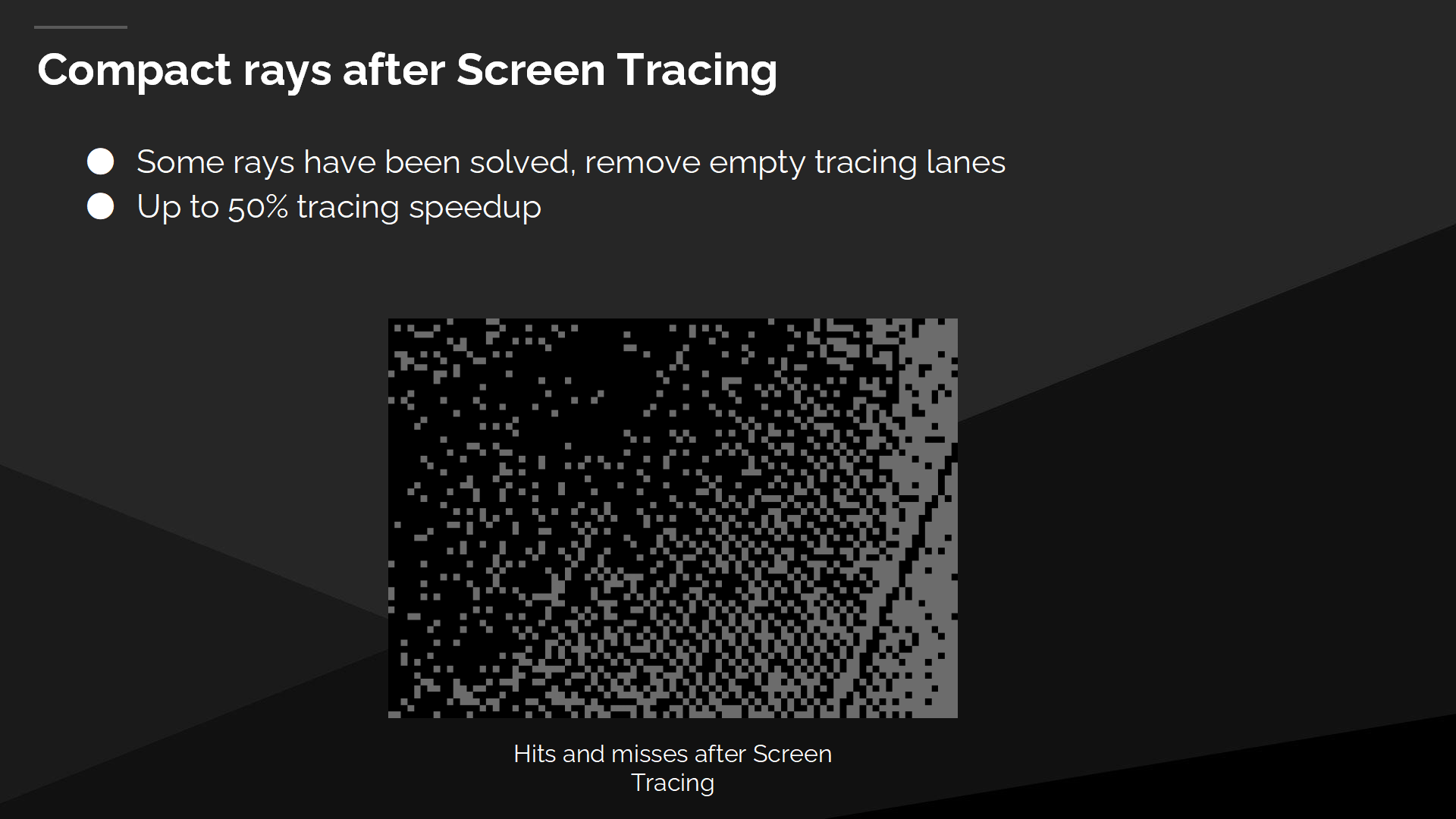
在屏幕空間追蹤後,使射線更緊湊
在屏幕空間追蹤執行後,部分射線查找已經被屏幕空間的追蹤解決了,同時其餘射線仍然需要後續的追蹤。相比於直接在所有空白的追蹤路線上執行下一個追蹤步驟,首先我們進行了一個數據壓縮過程,這為我們帶來顯著的速度提升。

The easiest way to do a compaction is to use local atomics to allocate the compacted index. That has the effect of scrambling the rays, which you can see on the left. The red lines are all the different rays within a single wave, and they’re now starting from different positions within the scene.
最早的一種壓縮方式使利用局部數據原子(atomics)來分配壓縮後的索引。這會導致爭奪射線的後果,如左圖所示——紅色的線代表了單一批次執行的不同射線,它們都從場景中不同的位置發出。
我們採用了一種順序保持的壓縮方式來解決其中的問題,使用一個快速的前綴和(prefix sum)方式,搭配更大的線程組來分配壓縮後的索引。
*如果壓縮順序不能保持,那麼在多線程執行發生分配資源不夠導致“射線爭奪”時,結果的不確定性就會更大(包括分幀跳變等問題)。
*關於prefix sum這種處理方式是很值得一看的,它是一種常用的並行計算(索引)管理方式。文末會附資料連接。
3 軟件光線追蹤
*大段很繞的部分我會保留原文作為參照,不得不說部分名詞確實無法很好的和中文對應,實際上還是得結合語境來理解。

為什麼需要軟件光線追蹤?
首要的問題是,為什麼在硬件光追方案已經有了的現在,還需要軟件光追。
虛幻引擎能支持不同平臺的不同類型的內容,我們也需要不同的工具以處理這種大範圍的用戶用例。這是我們引入軟件光線追蹤的主要動力,我們希望在沒有DXR支持的硬件上(以較小的規模)運行光線追蹤。
我們並不能完全替換掉硬件光追,但對追蹤過程有完整的控制(而不是全交給顯卡)能使我們做出不同的tradeoff。例如,重疊的實例在BVH上會是一個問題(不好識別),射線必須與每一個實例做相交計算來判斷最近的實例,同時我們也無法改變這種(硬件的)加速結構設計。

概述
在高層設計中我們有兩個基本元件——一個逐個網格的距離場、和一個逐個地形原件的高度場。
Those primitives are stored in a two level structure, where on the bottom level we have our primitives and top level is a flat instance descriptor array. This approach allows us to leverage instances for storage and decreases memory usage, which is important for any kind of a volumetric mesh representation.
這些基本元件被儲存在一個兩層結構中,在底層數據中是我們的元件數據,同時頂層設計中是一個扁平的實例敘詞數組。這種方式允許我們利用實例(屬性)作數據存儲並降低內存使用,這對於任何形式的體積網格描述方式(volumetric mesh representation)都很重要。
距離場(Distance fields)不是UE引擎中的新事物,因此這裡會聚焦在Lumen中新開發的特性。(2015年Wright分享的內容,同時他此時還是UE的資深引擎開發人員之一)
*SDF之前也有文章介紹過了,實際操作中主要面對的就是解決精度問題。
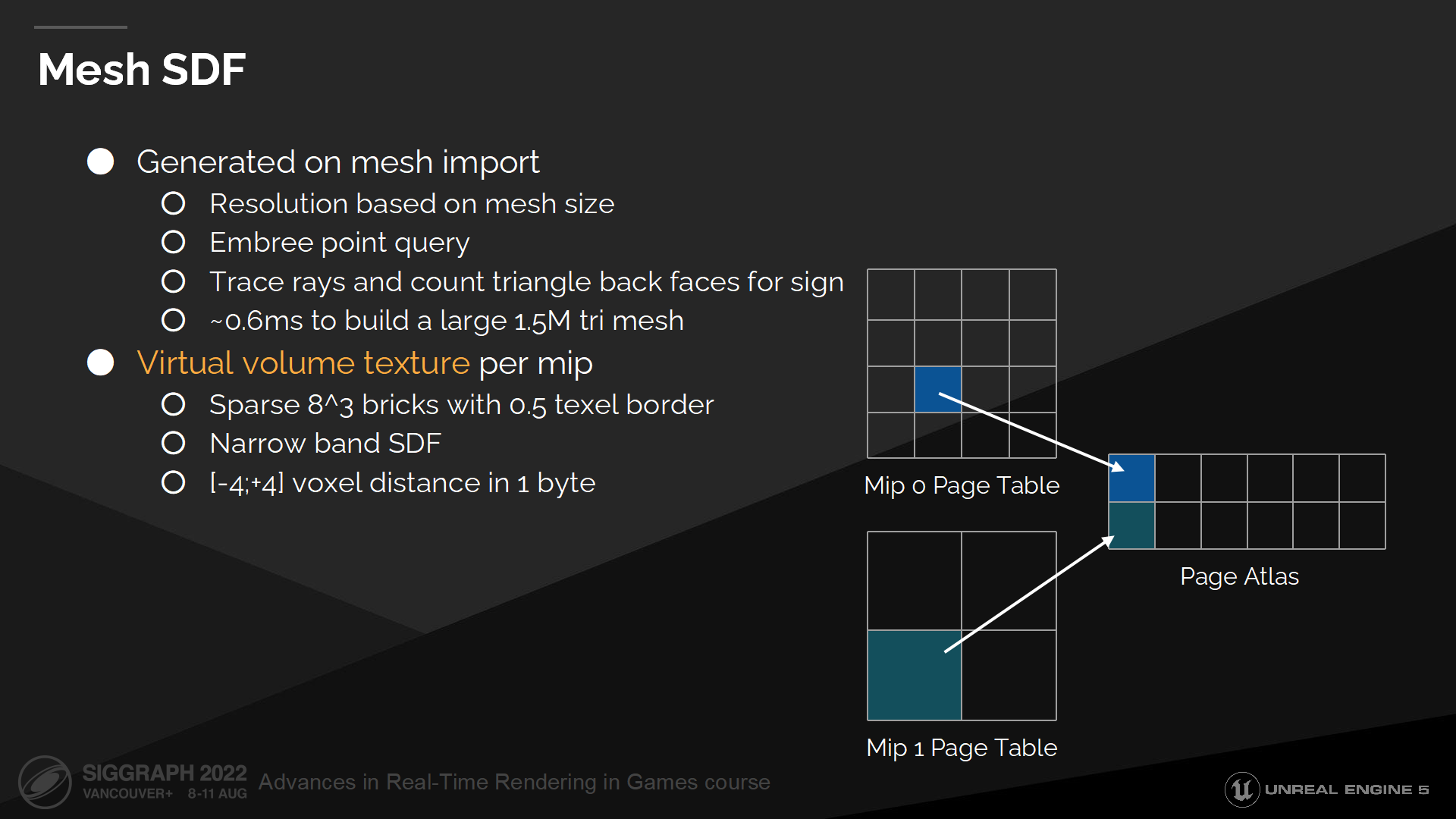
網格SDF
我們在模型網格導入時,就伴隨其它必要的網格數據同時存儲距離場數據(即離線生成距離場)。
For generation we use Embree point query to efficiently find distance to the nearest triangle. We also cast 64 rays from every voxel and count backface hits to decide whether we are inside or outside the geometry, which determines the distance field sign.
在生成時我們使用Embree點查詢(*Embree是Intel提供的一個高性能光線追蹤庫)來高效查找三角面附近的距離。我們也從每個體素髮出64根射線來統計背面命中數,以決定點是在幾何體內部還是外部,這決定了距離場的方向(sign 正負)。
Volumetric structures don’t scale well with resolution and are quite memory intensive, so we store only a narrow band distance field inside a mip mapped virtual volume texture.
體積結構不能很好的隨分辨率縮放,並且很耗內存,因此我們僅存儲了很窄帶寬的距離場數據——在一個mip映射結構的虛擬體積紋理中(virtual volume texture)。
Mip0的清晰度(和分辨率是一個詞 resolution)是基於網格的尺寸和網格導入設置來決定,然後mip1 半分了精度並加倍了最大物體空間的距離——更多mip層級以此類推。
*頁中還對應介紹了一些技術參數(例如導入網格的速度),以及mip和虛擬紋理之間的對應關係。

網格SDF流式加載
每一幀我們都指派一個shader來循環所有實例。它基於和攝像機的距離,計算每個距離場實例需要的mip級別。
之後我們通過CPU發出載入指令,並流式加載需要添加的距離場mip,或是移除那些不再使用的。
Distance field bricks are stored inside a fixed size pool, which is managed by a simple linear allocator. It’s a convenient setup, as we don’t need to deal with any kind of a variable sized 3d allocations or resulting fragmentation.
距離場塊(bricks)被存儲在固定尺寸的池子中,通過一個線性分配器(allocator)來管理。這是一種便利的設置方式,因為我們不需要處理任何可變長度的3D內存分配或導致碎片問題。

網格SDF追蹤
對於網格距離場的追蹤,我們使用mipmap來加速光線步進(ray marching)的過程。當接近表面時,我們使用更高的更精確的mip;在距離很遠時,我們切換到較低的mip來快速跨國空白的空間。
我們也限制網格距離場ray marching的迭代次數——最大64,基於性能方面的考慮。當達到上限時,我們停止遍歷並輸出當前命中距離能得到的結果。
最終當追蹤命中後,我們使用中部差分(central differencing)方式做6個採樣來計算幾何體的法線——它會在後續被用來從表面緩存中採樣材質和光照。

高度場
地形被劃分成不同的部件,並且我們對每一個單獨的高度場都在表面緩存中有單獨的部件。
在上層結構中,高度場實例的處理與網格距離場域的實例類似,會重用其中的剔除和遍歷代碼。
Bottom level is different, as per instance instead of a 3d distance field, we raymarch a 2d heightfield and try to find a zero crossing. After finding two samples, where one is above and the other is below heightfield, we linearly interpolate between them to approximate the final hit point.
底層結果則不同,相對於(網格距離場)的實例是3D距離場,對高度場我們raymarch一個2D高度場,並試圖找到一個零交叉點(zero crossing)。在找到兩個關鍵樣本後——一個位於高度場上方、另一個位於下方,我們對兩點線性插值來估計最終命中位置。(*就是page中的LERP函數。零交叉點是一個信號學概念,代表函數中從正轉負——或相反的變化點。)
通過命中點我們可以從表面緩存中評估不透明度(opacity),以評估我們是要接受命中結果或是跳過這次命中以繼續在高度場中追蹤。
在接受命中結果後,我們從表面緩存中估計(採樣)位置並計算射線的輻照度(radiance)。
*上個系列也解釋過了,radiance後續就保留原詞。關於光傳播能量計算,詳細的理解還是要去看Games101的講解。

加速結構
At this point we have all the data in the memory and we know how to trace an individual instance. Now we need to figure out how to trace the entire scene as we cannot just loop over all instances in the scene and raymarch each one of them.
此時我們在內存中已經有了所有需要的數據,並且我們已經知道了如何追蹤單獨的實例。現在我們需要確定如何來追蹤整個場景的物體,因為我們不能簡單的循環訪問所有實例並逐一raymarch。
We tried BVH and grids. Those are really nice acceleration structures as you can build them once per frame and then reuse them in multiple passes. Unfortunately performance of long incoherent rays wasn’t good enough. Software BVH traversal has a quite complex kernel. Grids have complex handling of objects spanning multiple cells. On top of that scenes with overlapping instances require to raymarch each one of them in order to find the closest hit.
我們嘗試了BVH以及柵格(grids 有一個翻譯是網格,但為與mesh區分後續都翻譯成柵格)。它們都是很不錯的加速結構,你可以每幀對它們重新構建,並在不同的渲染階段進行重用。不幸的是對於長距離不連貫的射線的性能不夠好。軟件BVH遍歷有一個很複雜的計算內核(kernel),而柵格對於處理跨格子的物體則較為複雜。而更重要的是,重疊物體較多的場景需要對物體逐一raymarch來識別出最近的命中位置。
最終我們決定簡化這個問題,並且只追蹤短射線。當追蹤的覆蓋區需要變得更寬時,我們需要切換到另一種追蹤方法。

運行時場景LOD
This was an important realization that we need a precise scene representation only for the first segment of a ray and after that we can switch to a coarse scene representation. This also gave us an opportunity to solve the object overlap issue, as now we can merge entire scene into some simplified global representation.
我們產生了一條重要的認識:只在射線追蹤的第一段,我們需要準確的場景表達(representation 可以理解成高度場、SDF、BVH等描述形式的總稱),在那之後我們則切換到一個鬆散的場景表達。這也給我們帶來了解決物體重疊問題的機會,因為我們可以將整個場景融合成某種簡化的全局表達方式。
我們嘗試了幾種不同的實現方式:
顯然有一種方式是在場景構建時就把整個場景合併成一體,不過這是一個過於嚴格的工作流程(不適合並行),並且無法支持動態物體。
我們嘗試了運行時體素化和錐體追蹤(voxel cone tracing),但合併幾何體參數的過程中會導致很多漏光問題——尤其是對於較低的mip時。
我們也嘗試了體素數據塊(voxel bit bricks),這種方式我們在每個體素中存儲1比特數據來標記它是否包含幾何體。基於數據塊的ray marching過程比想象的要緩慢——在我們添加了加速用的鄰接紋理(proximity map)後,效果仍不理想,因此最終我們放棄了體素而決定採用全局距離場(Global Distance Field)。
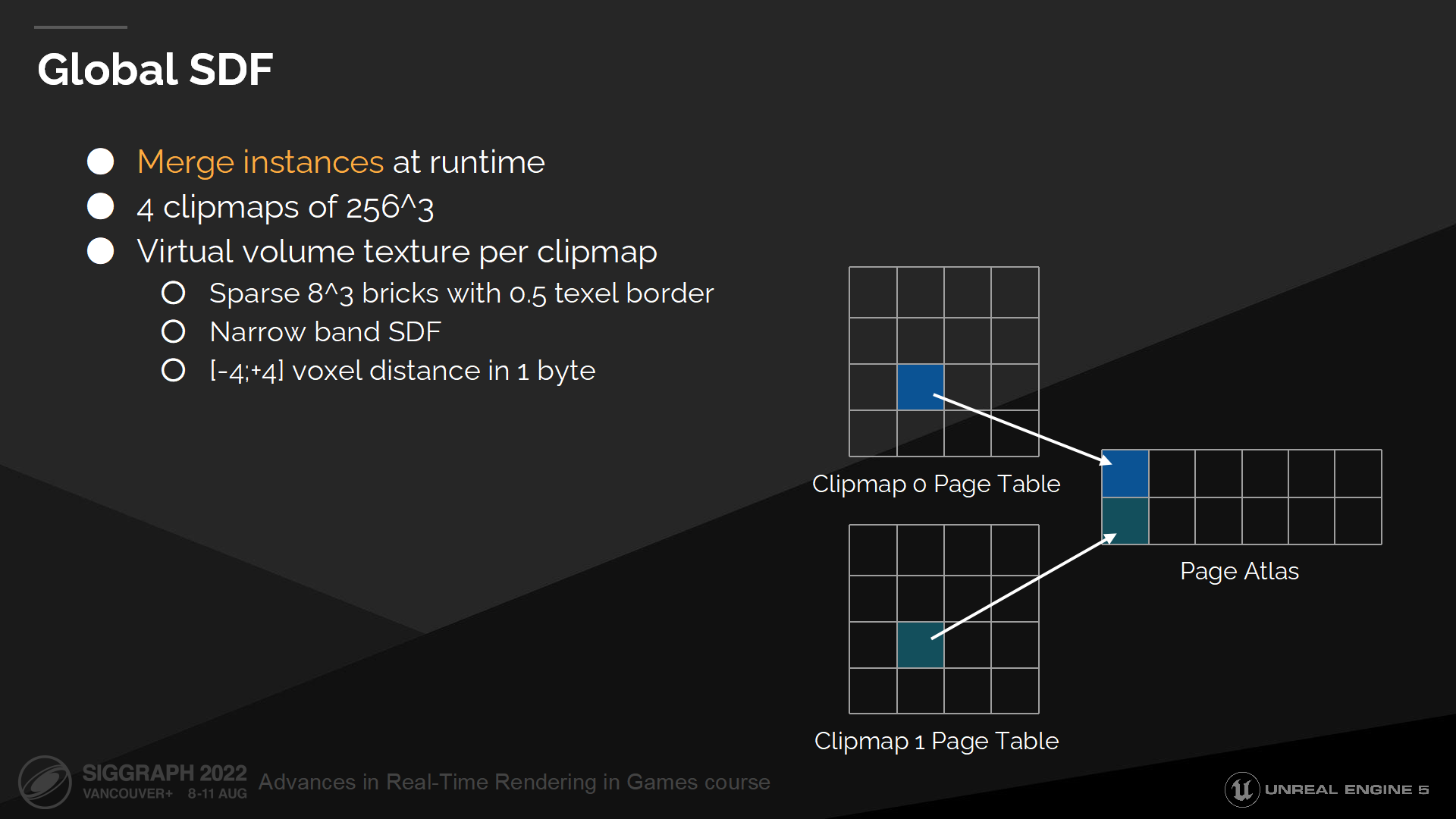
全局SDF
全局距離場合並了所有網格距離場和高度場,並匯入一組以攝像機為中心的裁剪紋理(clipmaps)中。網格距離場和高度場都是完美的網格描述形式,它們都足夠簡單因而能在運行時進行合併或LOD。
默認情況我們使用4個稀疏的clipmap——由虛擬體積紋理構成。每個clipmap存儲距離場塊,並且每一塊存儲一個窄帶寬的距離場。
這很類似網格距離場的設置,不過相比於使用一個mipmap層級,我們使用clipmap層級——因為我們想要簡化遠離攝像機的場景(通過LOD)。

全局SDF緩存
要合併場景所有物體是開銷很大的,因此我們需要激進的緩存策略——僅更新那些和上一幀相比變化的物體。
我們也對更新遠景的clipmap做了分幀處理,並且我們對於不同的clipmap有不同的LOD設置——這使我們能丟棄遠處的小物體。這確實對更新時的性能很有幫助,因為大clipmap也需要更新和合並大量的實例信息。
通常只有少量的場景物體是可動的,大部分剩餘物體都是完全靜態的。我們利用這一點把緩存劃分為動態和靜態塊,因此當移動一輛汽車時我們不需要重計算靜態建築的緩存數據。
For cached updates we track all scene modifications and build a list of modified bricks on the GPU. Next we cull all the objects in the scene to the current clipmap and then cull resulting list to modified bricks. During the last culling step we sample mesh distance fields for more accurate culling that checking analytical object bounds.
對於緩存更新,我們追蹤所有場景的變化,並在GPU構建需要修改的塊的列表;然後我們基於當前場景物體計算剔除並匯入當前clipmap,之後基於剔除結果列表修改緩存塊的數據。在上一步剔除步驟中我們採樣網格距離場用於解析式的物體範圍(analytical object bounds)更準確的剔除。(*這裡指物體範圍是用解析式或公式描述的,而不是點集描述的,就可以帶入計算來判斷)
此時我們得到了一組待修改的塊的列表,以及每個塊被剔除的物體列表。這樣我們可以對塊的數據做分配或接觸分配,以執行更新過程了。

全局SDF更新
為更新單個塊,我們循環所有影響它的物體,併為每個體素計算最小距離。
有一個問題是實例可能有非統一化(non-uniform)的尺寸,但存儲在距離場中的距離僅對標準化尺寸的實例有效。
We tried finding the nearest point through an analytical gradient and then recomputing distance from it, but it didn’t work well in practice due to the limited distance field resolution. In the end what worked for us is simply to bound the distance field using distance to analytical object bounds. Most of the non-uniformly scaled objects are also simple shapes like walls so it works really well in practice.
我們嘗試通過一種解析梯度(analytical gradient)的方式來找到最近的點,併為其重計算距離——但在實踐中這不太可行,因為距離場的精度是有限的。最終對我們有效的方案是,簡單地使用到物體的(解析)邊界的距離作為距離場的邊界。大部分非統一化尺寸的物體有著簡單的形體——例如牆壁,因此這個方案在實踐中是運作良好的。
當更新動態塊時,我們需要和重疊的靜態塊組合,以合併兩者的緩存數據更新到最終的距離場中。
最終我們更新粗粒度的mip——它是一個四分之一精度的非稀疏距離場容器(non sparse distance field volume),用於加速空白空間的跳過過程。我們在執行步進時使用粗粒度的mip替代clipmap層級——因為我們的clipmap有著不同的LOD層級,在最大的層級中可能會丟失一些物體。
粗粒度的mip有著很低的分辨率,所以我們始終更新整個volume——通過採樣全局距離場數據,並通過一些Eikonal傳播算法迭代來拓展它。
*圖中列出了Eikonal傳播的出處。
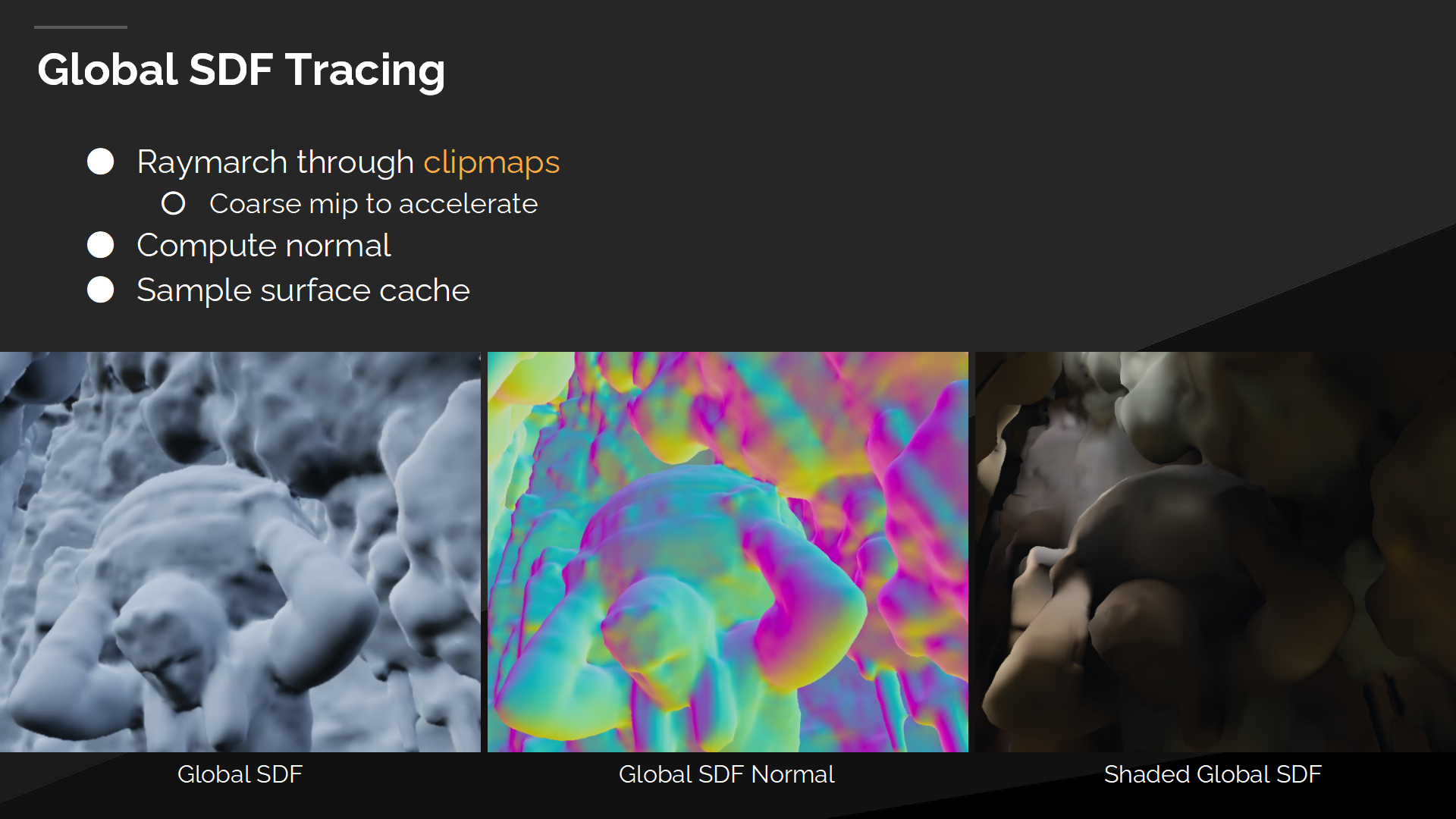
全局SDF追蹤
在追蹤全局距離場時,我們從最小的clipmap開始循環,逐一做raymarch直到命中一個位置。
Every step we first sample the continuous coarse mipmap and if we are close to the surface then we also sample sparse bricks.
每當我們第一次採樣連續粗粒度的mipmap時,如果很接近物體表面,則我們同時採樣稀疏塊的數據。
最終當我們得出命中點時,我們通過6個採樣點來採樣表面緩存,以計算表面漸變並獲得光照信息。
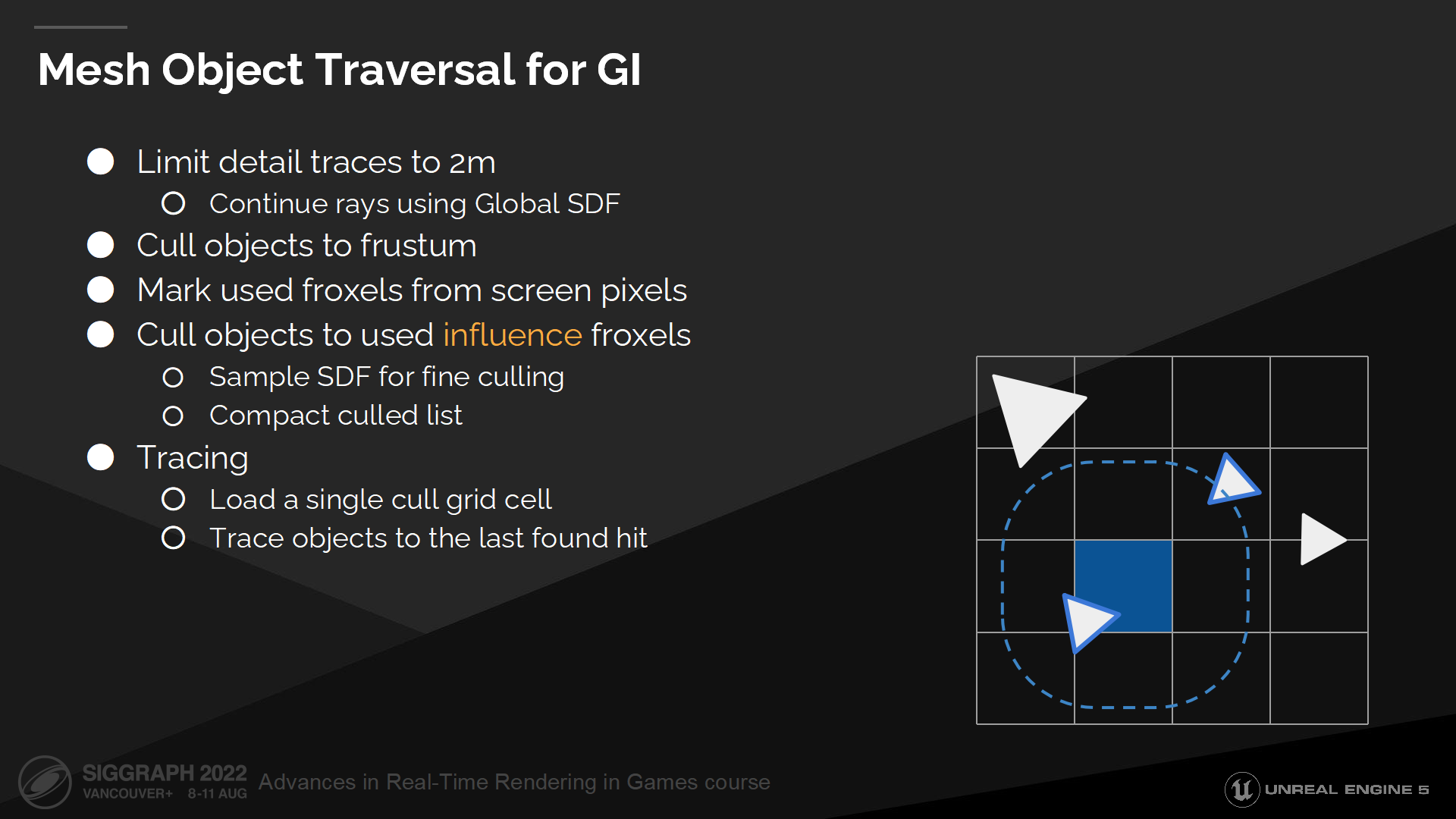
GI中的網格物體遍歷
現在我們已經有了一個遠場追蹤的備選方案(fallback),可以回到網格距離場追蹤了。(*指近距離使用的方案,圖中提到是2m距離內的)
With the assumption of tracing only short rays we don’t need BVH or world space grids anymore. Instead we can cull objects to an influence froxel grid, where every cell contains a list of all objects which need to be intersected if a ray starts from that cell.
基於近距離只追蹤短射線的假設,我們不再需要BVH或者世界空間柵格(而直接計算物體相交)。作為替代我們可以篩選剔除物體並匯入一個可變的視錐柵格中(influence froxel grid),其中每個單元格包含了(當射線從該格發出時)需要判斷相交的物體列表。
為產生這個列表,我們首先基於視錐(frustum)剔除場景物體。之後我們標記出包含幾何體的視錐柵格單元(froxel 這個應該是組合frustum和voxel的生造詞),以避免浪費追蹤時間在完全不被使用的froxel上。
下一步我們剔除物體(這一步是遮擋剔除)以標記froxel單元格。第一步物體的剔除測試是粗略的包圍盒檢測,第二步則是一個精確的距離場採樣。
最終我們把剔除結果列表壓縮進一個連續的物體列表中。
當從像素中追蹤GI或反射信息時,我們會加載一個合適的單元格,循環其中所有物體並ray march直到命中一個位置。這樣得出的結果非常簡單且有著連貫的追蹤核(kernel)。

網格物體遍歷用於計算直接陰影
Directional shadow rays are parallel and we cannot depend on a cone footprint getting wider here. Which means that we need to trace full length rays.
直接陰影需要的射線是平行的,因此我們不能依靠錐體追蹤的範圍變得更寬來解決——這意味著我們需要追蹤全距離的射線。
為實現這一點我們把物體剔除並劃分入一組光源空間的2D柵格中,每一個單元格包含了可能相交的物體數組。
Next to fill this grid we scatter objects by rasterizing their object oriented bounds. Inside the pixel shader we do extra fine culling by sampling the mesh distance field.
下一步為了填充這組柵格,我們通過光柵化它們物體朝向上的包圍盒來把物體打散,之後在像素shader中我們基於採樣網格距離場做更好的剔除。
最終我們的剔除列表是經過壓縮的。
之後再追蹤陰影射線時,我們將加載一個合適的單元格,循環其中的物體並逐一ray march直到命中一個位置。

軟件光線追蹤管線
現在我們就有了所有軟件光追管線的部件:
- 我們從屏幕空間追蹤開始
- 之後我們在未得出結果的射線位置執行(短距離)網格距離場追蹤
- 下一步我們使用全局距離場追蹤剩餘射線位置
- 最終仍未得出結果的射線會採樣天空顏色

SDF中的單面表面
在我們結束這個章節前,仍有一些在實踐中需要解決的使用距離場時的問題。
First one is that many meshes aren’t closed. This often happens with scanned meshes or simply meshes which aren’t supposed to be seen from the opposite side. It’s not an issue for rasterizer, but in case of a distance field it produces a negative region which will stick out from the geometry and break tracing.
首先,許多網格是不閉合的。這通常發生在網格是掃描產生的,或者網格背面不需要被看見的情況。這在光柵化管線中不是一個問題,但在距離場的情況下它回產生一個從幾何體中突出的負值域,從而打破追蹤過程。
To solve this problem, during the distance field generation we insert a virtual surface after 4 voxels. Or in other words we wrap negative distance after 4 voxels.
要解決這個問題,在距離場生成時我們每4個體素插入一個虛擬表面——換句話說我們每4個體素之間都將負距離值包住了。
這不是一個完美的方案,並且仍然會導致光柵和ray marching之間的錯配問題,不過總好過有一大片負值區域。
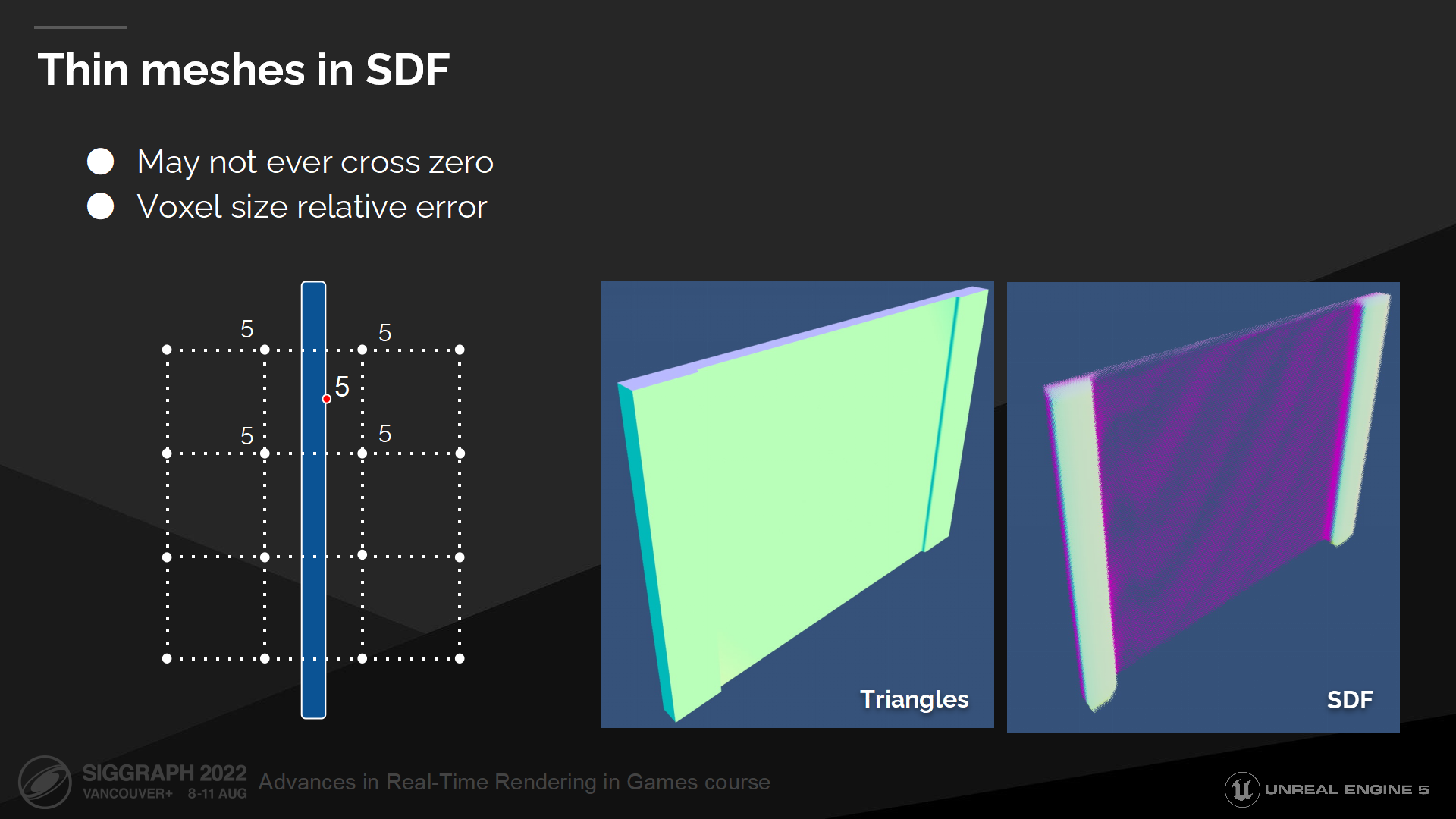
SDF中的細網格
另一類問題是細網格導致的。
離散的距離場表達方式是受限於分辨率的(有最小點間隔限制),因而無法表示出距離小於兩個體素間距的細節。
In this diagram you can see an example of a thin wall, which is placed between the sampling points. Evaluating such distance field won’t ever result in a zero or negative distance and ray marcher won’t ever register a hit. Gradient computation will be also incorrect as gradient around this wall will be zero.
在圖中你可以看到一個細牆面的例子,它位於採樣點之間。評估這種距離場中的情況將無法得出零或負距離,以至於光線步進中不會視為一次命中結果。梯度計算的結果也將是錯誤的,因為這個牆面被記為了零值。
這在很多普遍的使用場景中會是災難性的問題——當室內較暗而室外明亮時,即使有一根射線穿過了這種牆,都會導致大量漏光問題。
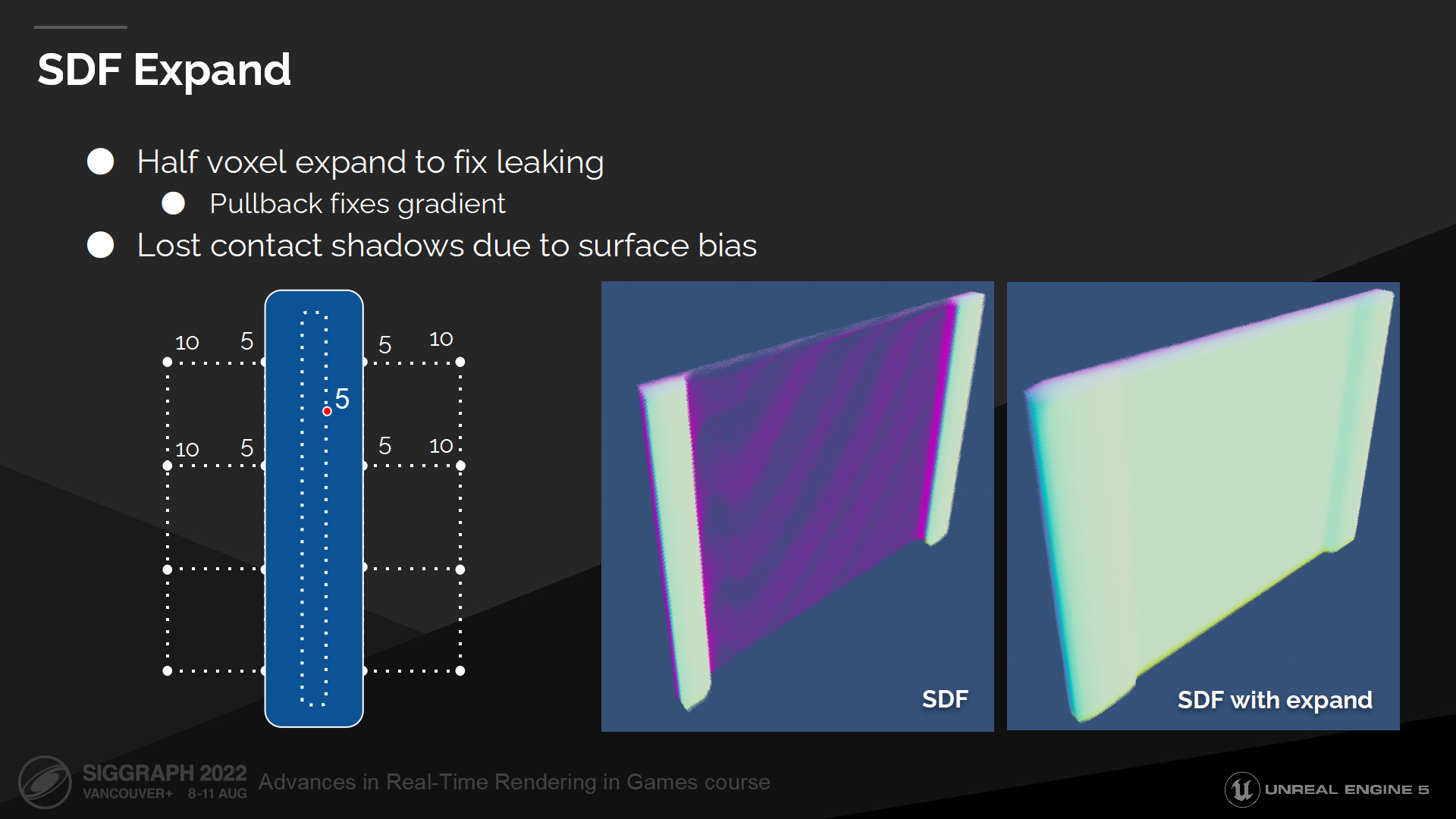
SDF延展
要克服這一問題,我們需要把距離場以體素對角線長度的一半做延展。
This expand fixes leaking and now we can reliably hit any thin surface. Gradient also will be fixed, as we will be computing it further away from the surface where we have reliable distance field values.
這種延展能修復漏光問題,使我們能可靠地命中細表面。梯度計算也被修復了,由於我們有了可靠的距離場參數,計算距離這一表面更遠的位置也能正確實現。
延展操作是運行時進行的,這使我們能保存原始的距離場數據。
這種延展的缺點是會導致過度剔除,同時我們也需要更大的表面偏移量來判斷離開表面的位置(to escape the surface)——這會導致破壞鄰接陰影的問題。(*就是說bias要額外把延展出的這一段考慮進去,對算陰影來說就偏差更大了)
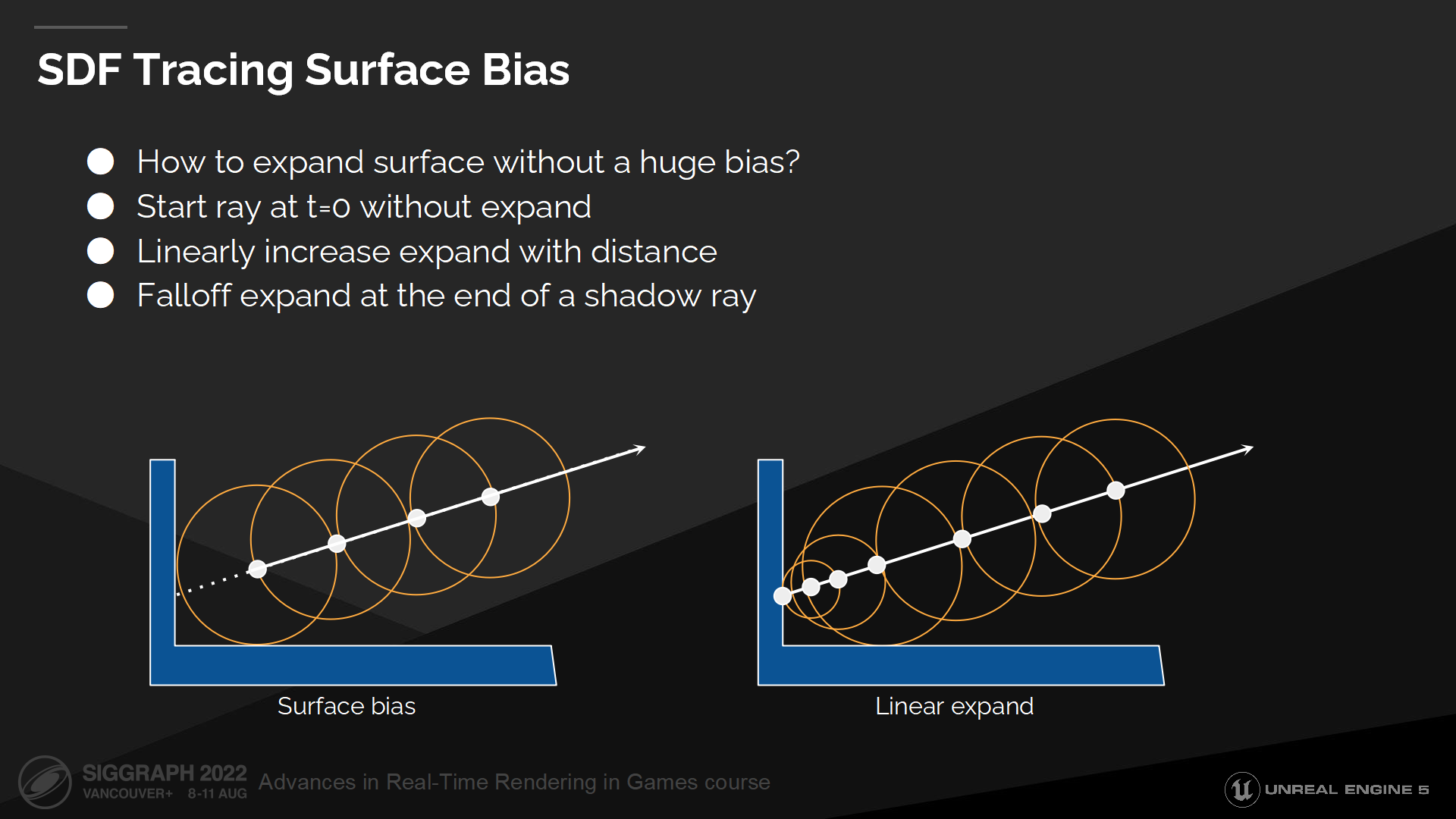
SDF追蹤表面偏移量
讓我們看看如何改進表面bias的問題。
We preserve the original distance field data and expand surfaces at runtime, which allows us to start at the surface and then linearly increase expand as we move further away from it. This way we can trace that initial ray segment instead of just skipping it and losing all contact shadows.
我們保存了原始的距離場數據,並在運行時做延展——這使我們能從表面開始以線性的方式做延展,直到遠離表面。這使我們能追蹤到初始的射線段,而不是全部跳過它們而丟失了所有鄰接陰影需要的數據。(*圖中右側展示了這種方式,在達到最大步長前,每次增加的步長是線性的)
而在陰影射線追蹤結束後,我們需要把延展值退回到零,這樣這條射線就不會(錯誤地)命中光源所在的表面。
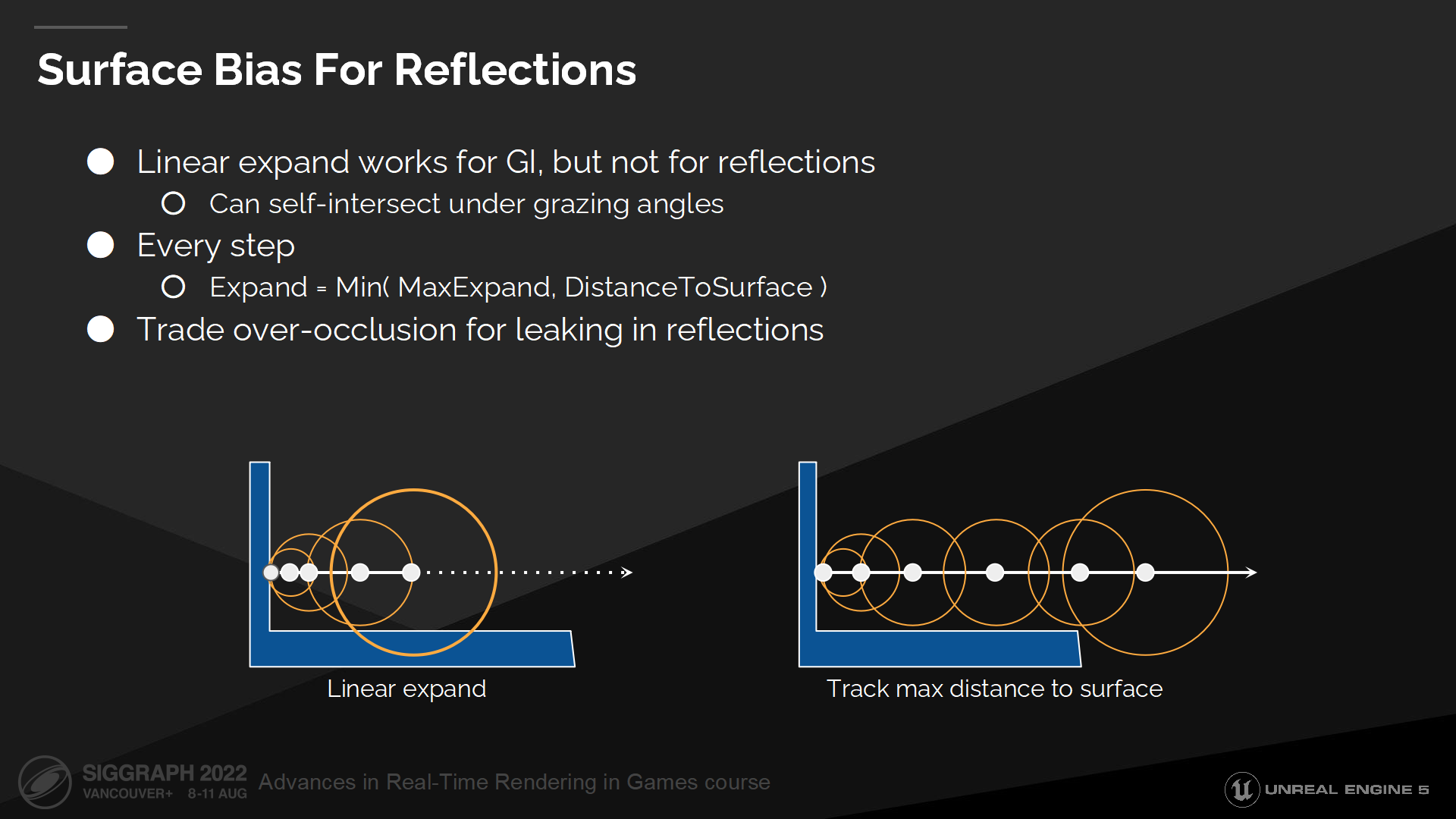
反射相關的表面偏移量
不幸的是這種啟發式方案不適用於掠射角(幾乎平行)的情況,因為延展過程會過於快以至於部分點上射線會有自相交問題(*圖中就是與另一個細表面有了相交上的錯判)。
這對於GI和漫反射的射線是能接收的,但對於鏡面反射則效果不好——因而這種情況下,相比於過度剔除,我們能接收一點漏光。
我們通過第二種啟發式方案來解決反射問題,每一步我們延展的步長基於當前點到表面的距離。這樣能保證射線能始終從初始表面離開(*而不是錯判為相交)。
*點到表面的距離是距離場中的點自身可以查詢到的屬性。

SDF延展解決漏光
*圖中展示了細網格相關的鄰接陰影及漏光解決。

葉子的效果如何?
距離場延展對於固定幾何體例如牆面的效果不錯,但對於樹葉的效果不好,因為這會導致完全遮蔽樹葉中應該透過的光照。
為解決這個問題我們需要引入另一個方案——它被稱為覆蓋率(coverage)。
We mark distance field instances based on the two-sided material and then resample this data into a separate global distance field channel. Coverage allows us to distinguish solid thin surfaces which should block all the light, from surfaces with partial transparency, which should let some light pass through.
我們標記出距離場中那些雙面的材質,並將它們重採樣至一個單獨的全局距離場通道中。覆蓋率能幫助區分應完全阻擋光源的固定細表面,與應透過部分光照的半透明的表面。
During ray marching every step we sample the coverage and based on it we increase raymarching step size and decrease expand. Additionally we use coverage for stochastic transparency on every hit to decide whether we should accept this hit or we should continue tracing.
在ray marching的每一步,我們都採樣覆蓋率,並基於它的值增加raymarching的步長,同時降低延展值。作為補充,我們使用覆蓋率來計算每次命中的隨機透明度(stochastic transparency),以決定是否視為命中或是需要繼續追蹤。(*stochastic transparency之前介紹過,是通過像素之間的間隔,來以一定策略實現用不透明模擬半透明的效果)
關於樹葉的另一個問題是,它們通常是動態的,而預計算的距離場不支持動畫。這通常會導致自陰影問題,因為我們通過對樹葉做了額外的表面偏移來解決這一問題。

SDF覆蓋率
*圖中是解決葉子透光問題之後的結果,右側相對看起來正常了很多。不過總歸這還是一種trick,以現在能達到的精度來說還做不出真實的葉子透光。

軟件光追的優勢
雖然距離場方案對於鏡面反射來說不是完美方案,但對於GI或粗糙表面都有著不錯的效果。圖中右側的場景幾乎都是被間接光照照亮的,可以看到距離場在其中起到了很好的效果,也能解決微小細節中的光照——例如檯燈以及電視的間接陰影。
它也不需要特定的硬件,能支持所有平臺。
它在引擎裡有著多樣的效用,被例如Lumen以及其它使用場合——例如物理碰撞所共用。
最後距離場允許我們縮小場景,並支持有大量重疊實例的場景——通過在運行時把整個場景合併至全局距離場來實現。
*至此簡單總結一下,遠距離軟件光追的核心數據結構是全局距離場,它是把物體的距離場匯入多層clipmap得到的中間層數據結構。基於這種數據的採樣在計算光照和陰影時面臨的挑戰不同,在一些極值情況也會有問題,文中也給出了一些基於實踐的解決方案,雖然很多是啟發式的甚至是trick。
4 表面緩存
*如概述部分介紹的,表面緩存主要用來補充SDF中不具備的光照計算參數。
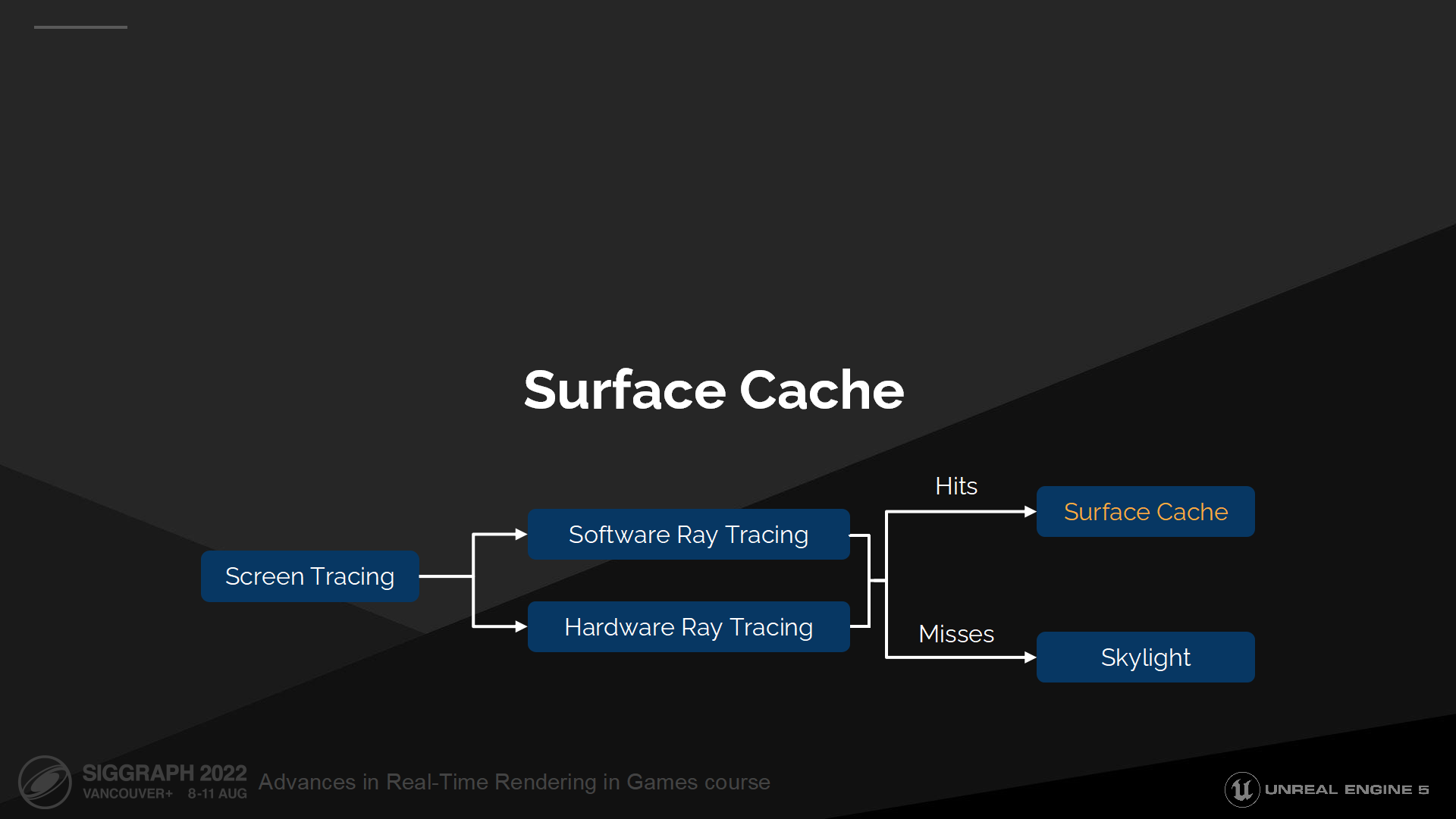
如前文所述,只有SDF數據還不足以計算物體表面的材質光照。

為什麼使用表面緩存
Distance fields don’t have any vertex attributes and we can’t run material shaders on them. We have access only to position, normal and mesh instance data. This means that we need some kind of a UV-less surface representation to be able to shade those hits.
距離場數據不包含任何頂點參數,因而我們無法在其上執行材質shader的計算。我們能得出的只有位置、法線和網格實例數據。這意味這我們需要一種紋理座標無關的表面(UV-less surface)描述方式來為命中點著色。
我們也需要將這一描述數據用於緩存並複用於其它各種計算與光路徑,因為我們無法負擔遞歸的多次彈射射線追蹤。
- 自定義的材質圖(graphs 是另一種編輯shader的方式)可能非常複雜,並在每次計算射線命中時有較高開銷。
- 有多個需要投影的直接光照光源也會開銷較大。
- 多次彈射的開銷則更大,因為對每一個射線命中我們都需要遞歸地追蹤多個射線並逐一計算材質光照。
表面參數
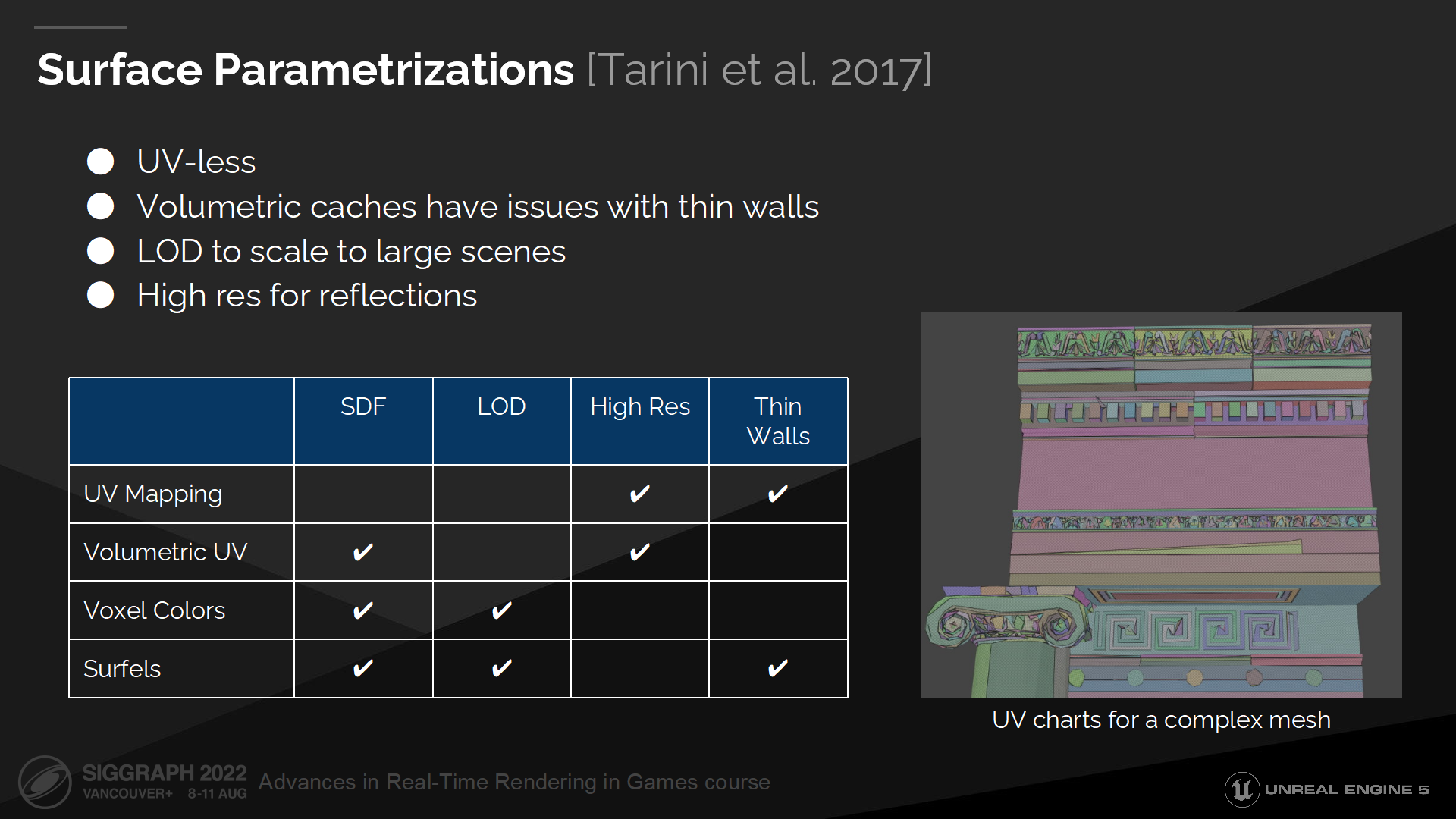
在能計算距離場命中結果以外,我們對錶面參數也有額外的需求。我們希望它是基於表面空間的——因為體塊方式在描述細牆時會導致漏光。我們需要一種規模可變(scalable)的方案,既可以覆蓋複雜場景的巨量實例,也可以在精度上放大以支持鏡面反射。(*圖中就列出了不同使用場合的參數組合)
雖然有很多的表面參數化方式,但多數我們都不會用到。
紋理映射(UV)對於複雜網格來說不能很好的適配,因為它們會產生很多瑣碎且不利於合併的UV圖。並且它們也需要頂點參數,而我們的結構中並不能訪問到。
體積UV也不能描述細牆壁,而且它也無法很清晰的基於距離來計算LOD。
體素顏色和微表面則有著精度上的限制,因而不能用於反射。

*Cards這個概念是由後文的解釋來填充的,就不翻譯了
For Lumen we decided to use projected cards, which can be also described as uniform rectangular clusters of surfels.
在Lumen中我們決定使用投影的cards,它也可以被描述為統一的微表面的矩形集群。(*從page中可以看出,策略是逐網格投影)
它們是易於快速查找的——基於它們的矩形結構。
Cards可以在運行時生成,並能縮放至任何分辨率——在不需要烘焙任何數據的情況下。
它們也可以用來表述兩面的細牆體。
*Cards可以簡單理解成把網格“拍平”了的一種結構,其實看到是使用的這樣一種結構我還挺意外的。
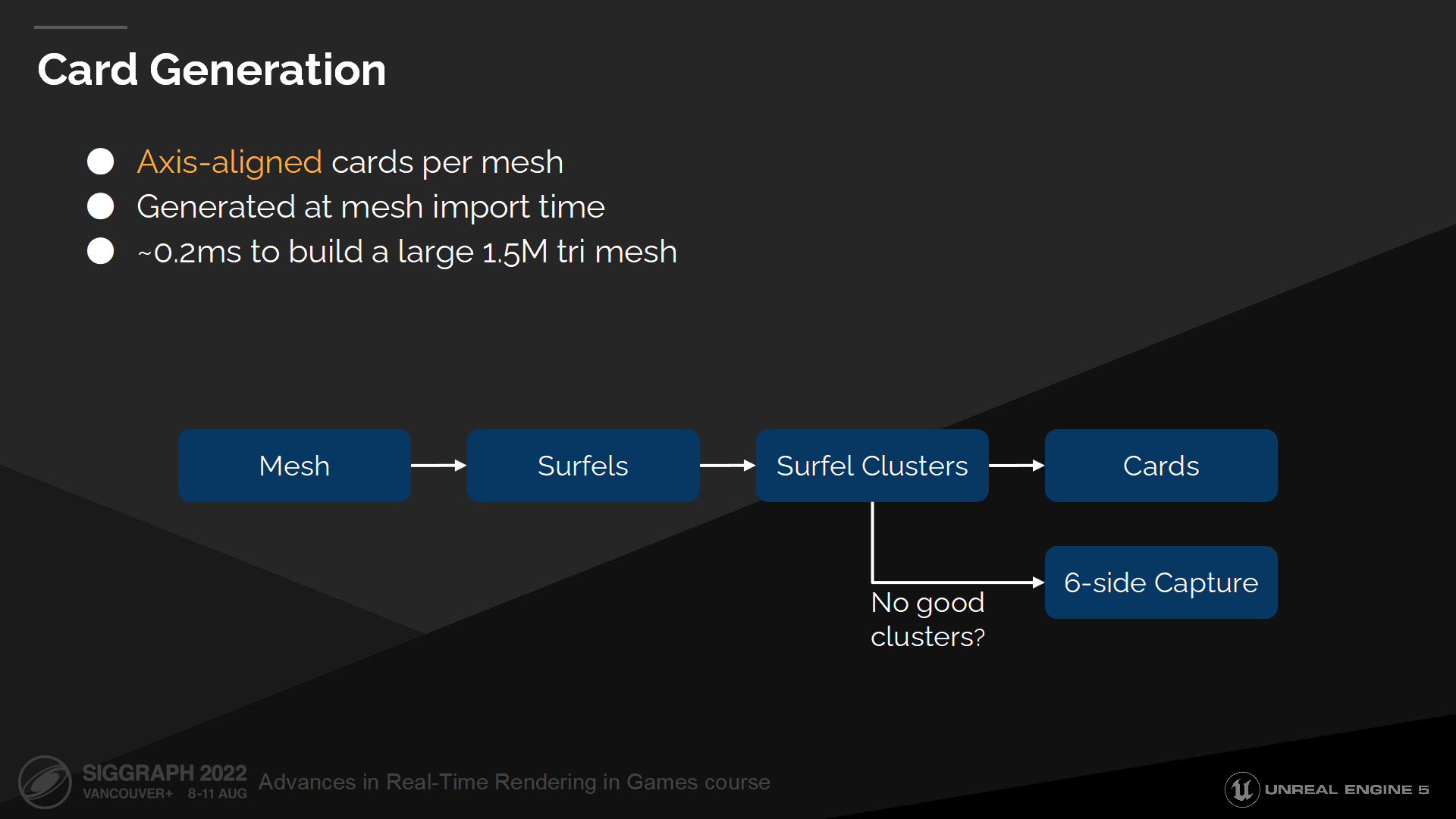
Card生成
在網格導入時我們執行了預計算過程來生成並放置cards。
所有cards都是軸向(axis-aligned)的,這能使其易於生成和查找(*減少計算過程的矩陣乘除)。我們也嘗試過支持任意朝向,但結果來說它們不易於放置,提供的額外靈活度也不值得為之付出相應的開銷。
生成始於對三角面的簡化——它們會被體素化並匯入一組軸向的微表面。
之後我們使用Kmeans聚類算法(K-means inspired clustering algorithm)劃分集群,並將集群數據寫入cards。
如果生成中產生了任何問題——例如網格太難以解開摺疊(unwrap)或太小,我們就用一個6面cubemap的投影方式作為後備。
*Kmeans聚類算法是一個重複移動類中心點的過程——通過把類的中心點,也稱重心(centroids),移動到其包含成員的平均位置,然後重新劃分其內部成員。詳細的案例這裡不展開了。

Card生成——微表面
在生成的第一步轉化三角面至軸向微表面時,為了簡化網格其中小的細節都被移除了。
我們在體素化網格時對每個2d單元格發出64根對物體追蹤的射線。之後我們對每一個3D單元格加總射線命中的數據,並基於一定的閾值生成微表面。
射線命中數被作為微表面的覆蓋率存儲下來,並將被用來評估一個集群的有用程度。額外地我們也存儲了射線命中的位置,它將被用來決定微表面在集群近平面上的可見性。
Next for every surfel we trace 64 rays and count the number of triangle back face hits. If most of those hits are back faces then given surfel is inside geometry and we can discard it. We also compute surfel’s occlusion based on the average distance to hits. Occlusion will be used to determine how important it is to cluster a given surfel.
下一步,對於每個微表面我們追蹤64個射線以統計命中的三角面背面的數量。如果大部分命中位置都在背面,我們可以認為當前的微表面位於幾何體內部,並可以丟棄掉。我們也基於平均命中距離來計算微表面的遮擋程度,它將被用於決定一個微表面在集群中的重要性。

Card生成——初始集群
下一步我們生成初始集群。
我們選擇一個未使用的微表面,並迭代地產生集群:
- 首先我們對所有未分配的微表面,按到集群邊界的距離計算權重以選擇那些更接近的;
- 微表面的遮擋程度也被列入考慮,優先選擇那些更重要的;
- 集群的比率係數(ratio)也影響權重,以提高方形集群的傾向。並且最終我們需要檢測微表面從集群的近平面處是否可見。
下一步我們持續的添加最優的微表面,直到我們達到足夠有效的候選數量。此時我們重新計算集群的重心位置,並開始從它從重新生成集群。
在進行有限次的重生成後,得到的集群就不再變化。此時我們將集群添加到列表中,並查找下一個未使用的微表面(*回到迭代的開始)。
在遞歸執行這一步後,最終我們的網格會完全被集群覆蓋,不過這些集群可能還不是全局最優(globally optimal)的。

Card生成——集群優化
Final step is a global optimization, where we re-grow all clusters in parallel from their current centroids. Again we do a few iterations of parallel growing until we hit a limit or clusters don’t change anymore.
最終步驟是全局優化,我們將所有集群按當前的重心位置平行地重新生成。在進行數次平行生成的迭代後,停止於達到上限或是集群不再變化時。
平行的生成過程可能導致過小的集群或是空白空間,所以每次迭代後我們都需要移除過小的集群,並在空白空間插入新的集群。
最後我們按覆蓋率排序集群,並按指定的數量選擇最重要的一些集群匯入cards。

Card管理
現在我們有了每個網格的card,需要以一定方式來管理。
其中有兩個衝突需要解決:
- 一方面,我們有很多很小的card用於處理多次GI彈射。我們不需要很高的精度,因為GI是很低頻(指光照信號變化的頻率)的,但作為持存地覆蓋所有物體又有其重要性。
- 另一方面,我們也有少量高精度的card用於特定表面的反射。這時我們需要很高的分辨率,例如用於鏡面反射,card需要匹配屏幕像素密度。
極端情況是我們Matrix Awakens的DEMO中演示的,其中需要覆蓋大量的實例,以圍繞攝像機處理建築間的光線彈射;同時我們也需要多個高精度card的反射表面。

虛擬表面緩存
這兩項需求將我們導向了虛擬表面緩存方案。
對於GI我們使用低分辨率的常駐頁(pages)。這些頁是圍繞攝像機基於距離來分配的,我們也有一套LOD方案以移除特小的card。
對於反射我們使用稀疏的按需分配的頁。它們基於反射射線命中位置來分配,在不需要時被取消分配。

表面緩存GPU反饋
每次射線命中時我們寫入表面緩存反饋,因此我們可以有選擇地指定每一頁的精度並與更新頻率。
射線命中採樣並混合了多頁的數據,因此我們需要推測地(stochastically )選擇一些最重要的頁。下一步我們更新它的上次使用時間,並將請求的mip層級寫入一個反饋緩衝中。
我們在GPU上壓縮這個反饋緩衝——通過將所有請求插入一個GPU哈希表並壓縮。最終的請求隊列包含需要的頁及每頁的命中數量。
請求隊列之後會被加載到GPU,之後我們就可以對其進行排序,並對頁數據做映射和解除映射。

物理頁圖集
大於頁尺寸的數據會被拆分成獨立的物理頁,並單獨分配空間。
小於頁尺寸的card是被作為子集分配的——這意味著我們映射一個單獨的物理頁,並使用一個2D分配器為其分配多個小的card。(*2D分配器指需要一定的圖集排布方式以提高頁利用率)
這很重要,因為這允許我們在有很大的頁的同時不在邊界處浪費太多內存,同時我們也能支持小的分配而不需要把每頁都向上取整至物理頁尺寸。(*例如小於128尺寸的可以拆成多個64尺寸使用)
我們精簡了查找過程,因而如果我們請求了一個不存在的高精度頁,頁表會自動指向一個低分辨率的持存的頁。這允許我們在採樣表面緩存是隻做一次查找,而不需要遞歸地查詢備選頁。
*詳細的參數可以看PPT頁中的內容。

Card抓取
我們也需要把網格和材質數據輸入card,它們在之後會被投影到表面上。
我們在運行時執行這一步,通過一個正交攝像機(ortho camera)將網格渲染到card上,並寫入表面屬性——例如漫反射係數(albedo)和法線(normals)。在運行時執行能使我們方便地處理精度縮放,並在不用管理預計算數據的情況下支持材質改變。
Card抓取是以給定的幀間隔來更新並緩存的。每一幀我們收集頁更新的請求,並在它們每次使用時基於和攝像機的距離進行排序。之後我們選取指定數量的最重要的頁進行數據抓取並更新。作為補充,為支持動態材質,有少量的頁我們需要每幀更新。
通常來說渲染很多小網格會非常慢,基於LOD以及很多小的繪製指令(draw calls)。但通過Nanite我們可以在一個draw call中渲染所有幾何體,並且我們也有一個連續的LOD層級以簡化網格並渲染到小的目標上(*這裡指card)。這是極大的渲染提速,使我們能更頻繁地抓取card數據。
*Nanite的網格管線的文章之前我也做過一篇粗讀(鏈接)。
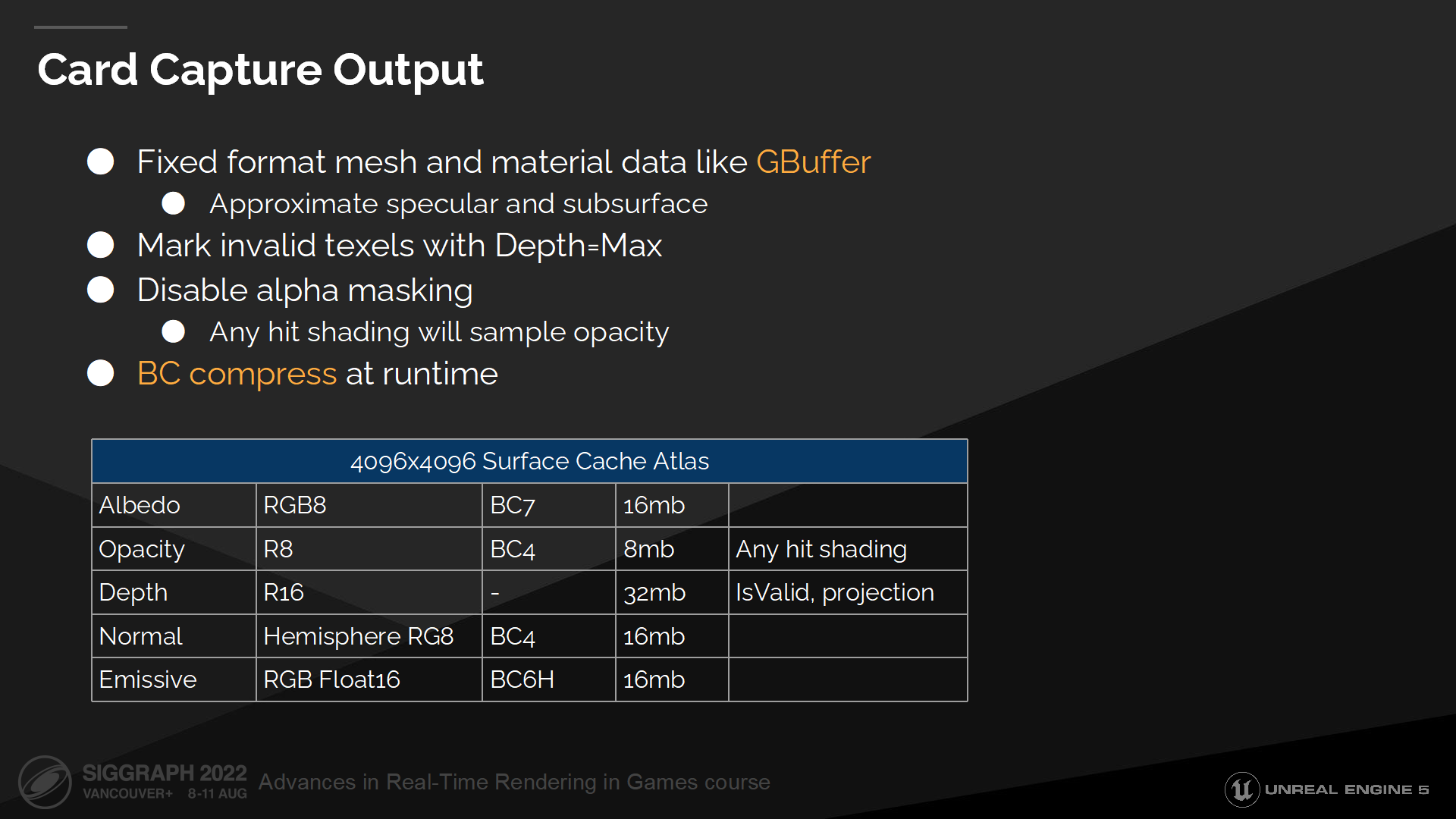
Card抓取輸出
Card抓取重新採樣材質和網格數據,並寫入一個指定的與視點無關(view independent)的類似GBuffer的結構中。
我們通過修改漫反射係數來解釋(原文是to account for)能量的損失,以估算高光或次表面射出的光照。
我們也標記出無效的紋素(texels,可以理解成緩衝紋理中的一塊區域),在後續我們就可以直到哪些texel不包含有效數據因而無法被採樣。
在抓取時我們關閉透明遮罩(alpha masking),因為我們需要從一個透明遮罩的表面點來識別缺少的表面緩存數據。這在後續會很有幫助,因為可以在運行命中檢測的shader時不需要處理材質shader。(*這裡主要是對透明遮罩材質的處理)
最後抓取的數據在運行時被BC壓縮(全稱 Block Compression),以最小化內存佔用。
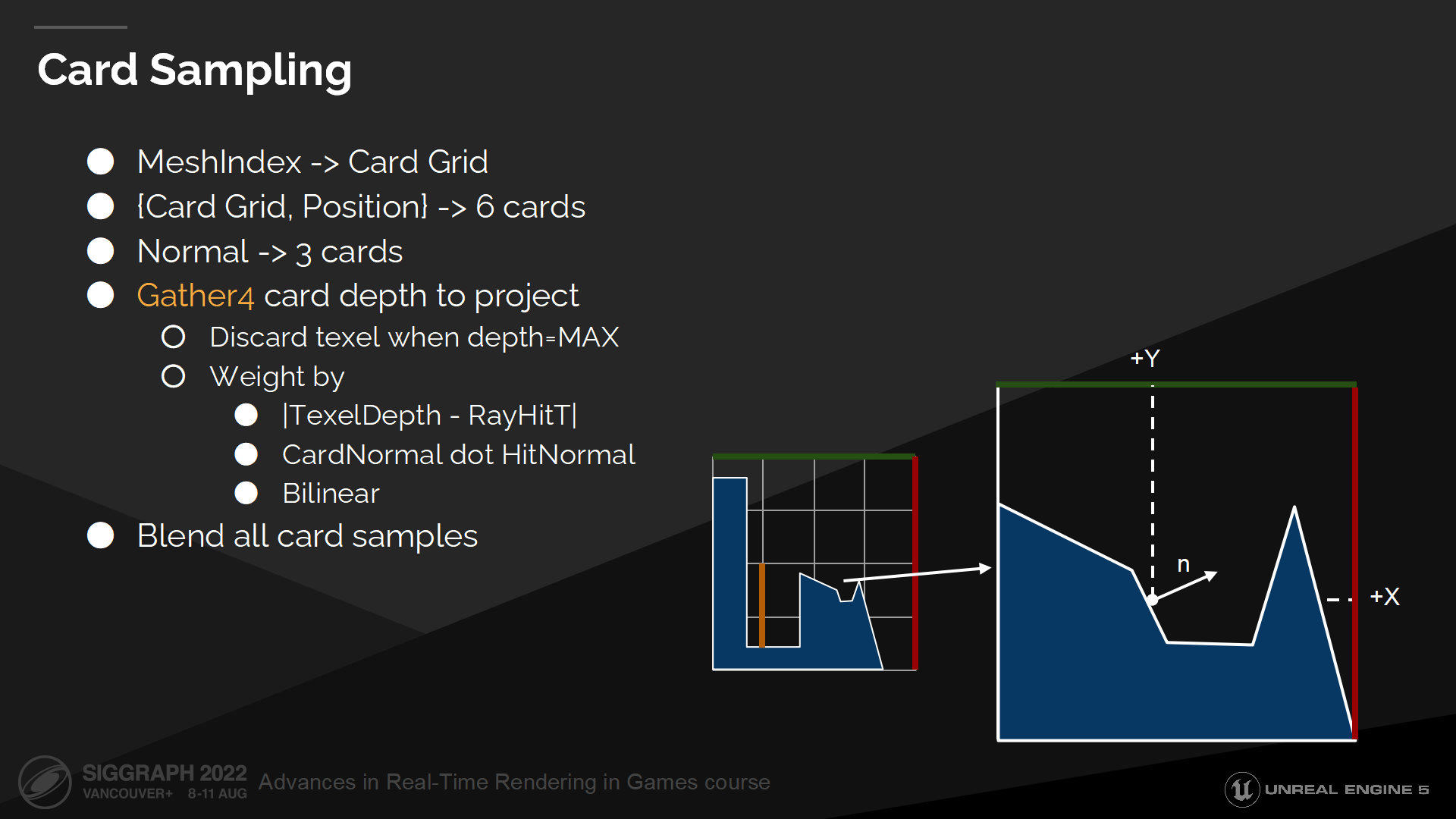
Card採樣
現在我們準備好了所有數據,可以採樣表面緩存了。
我們開始於按網格索引查找card柵格。之後我們查找柵格中的一個單元以得到6個card。基於表面法線我們找到需要投影的3個card。
之後我們採樣這3個card。對每一個card我們收集4個深度信息,用於手動執行雙線性過濾(bilinear filtering)。
We weight each texel by delta between stored depth in surface cache and ray hit depth to discard occluded samples. We also weight texels by card projection normal to prevent projection from stretching. Then we discard texels marked as invalid.
我們基於深度緩衝中的差值、以及射線命中的深度來計算texel的權重,並丟棄被遮擋的樣本;我們也把card投影法線方向作為權重,以避免從過度拉伸的方向投影。之後我們把丟棄的texel標記為無效。
最後所有的採樣被混合到一起,以計算命中位置的最終表面緩存屬性。

Card合併
某些情況下,我們會面臨card能縮放到什麼程度的問題。這在很多小實例合併成一個大物體時會是一個問題——例如圖中的大樓,我們不得不產生大量的小card、或是放棄整個物體的card(因為數量太多了)。
我們的解決方案是運行時合併card。
我們的實現方式是自動找到小的重疊組,或基於用戶提供的tag來分組。
每個組包含從6方向抓取的6個card,類似cubemap。這在觀察者在集合組的外部時是一種好的近似——而這是通常會有的情況。
感謝Nanite,最終抓取整個組並渲染到各個card的過程也非常快。

光照的情況如何?
現在我們在表面緩存中有了材質數據,但仍需要用它來計算光照。
圖中展示了(光照)多次彈射的重要性,沒有多次彈射時近一半的場景都是黑的,並且反射也消失了。
需要多重陰影射線的直接光照,或需要遞歸追蹤的間接光照開銷都很大。在大部分情況我們都無法負擔額外的射線,因此理想狀態下光照都應該來自表面緩存。

表面緩存光照
表面緩存中包含了計算光照需要的所有網格和材質數據。
這和(烘焙的)光照紋理方式類似,也會遇到類似的問題。
When tracing from texels, we need an appropriate bias based on the surface normal and ray direction to escape surfaces.
當從texel中追蹤時,我們需要基於表面法線和射線方向有一個合適的偏移值,以確保射線能正確離開表面。
Texel也可能在幾何體內部,並由於雙線性過濾而導致穿牆漏光等問題(*算插值時不知道牆壁位置)。我們通過丟棄命中三角形背面的射線來解決這一問題,使幾何體內部的texel正確顯示成黑色。

更新策略
光照信息每一幀都重新計算是開銷很大的,因此我們每幀只緩存並更新表面緩存的一個子集。
我們基於緩存頁上次使用以及被更新的時間,來選擇一幀中要更新的頁。
上次使用時間是基於每一個命中的射線上,GPU反饋寫入的幀序號;上次更新時間則隨每次頁更新遞增。
這兩個屬性在直接和間接光照中被分別追蹤,並且它們都有不同的更新頻率。具體地說,我們更新簡單的直接光照的頻率遠快於間接光照。
為了指定一定數量的最重要的頁,我們構建了一個直方圖(histogram),從連續的容器(原文是buckets,直譯是桶容器)中選擇直到我們達到預期的數量。
有時我們需要改變一個card的尺寸,或映射一個新頁。此時我們嘗試重新採樣之前的光照信息(如果可行),這樣我們就不至於丟棄之前所有昂貴計算的結果。
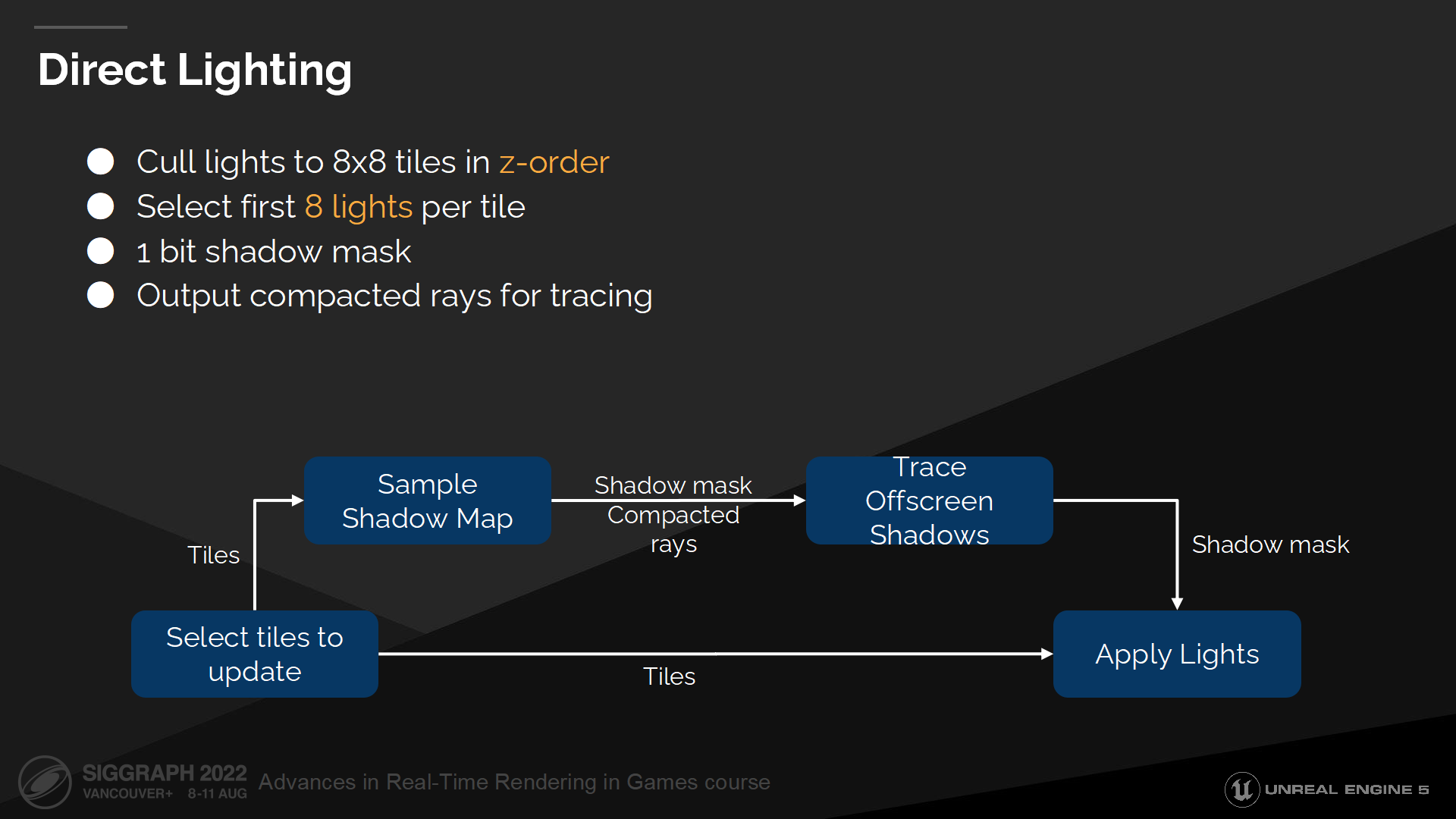
直接光照
當選中待更新的頁,我們將它切分成8x8的塊(tile),並輸出到一個z排序(z-order)序列中以最大程度保持一致性。
然後,對於這些tile我們選擇最多8個光源。目前我們僅選擇最先的8個光源,並且它在我們的使用場合運作良好——但在未來我們希望採用更只能的光源選擇策略。
對於每個光源我們有1 bit的shadow mask,以用於混合多種陰影計算方法。我們首先通過採樣可用的陰影紋理(shadow maps)來輸入shadow mask。在這個pass中我們也構建了一個陰影射線的壓縮列表,以用來解決陰影紋理無法覆蓋而需要射線追蹤的位置——通常這類texel都在攝像機背面。下一步我們追蹤陰影射線來完成shadow mask。
最終我們執行光照pass並使用shadow mask來計算光照值。
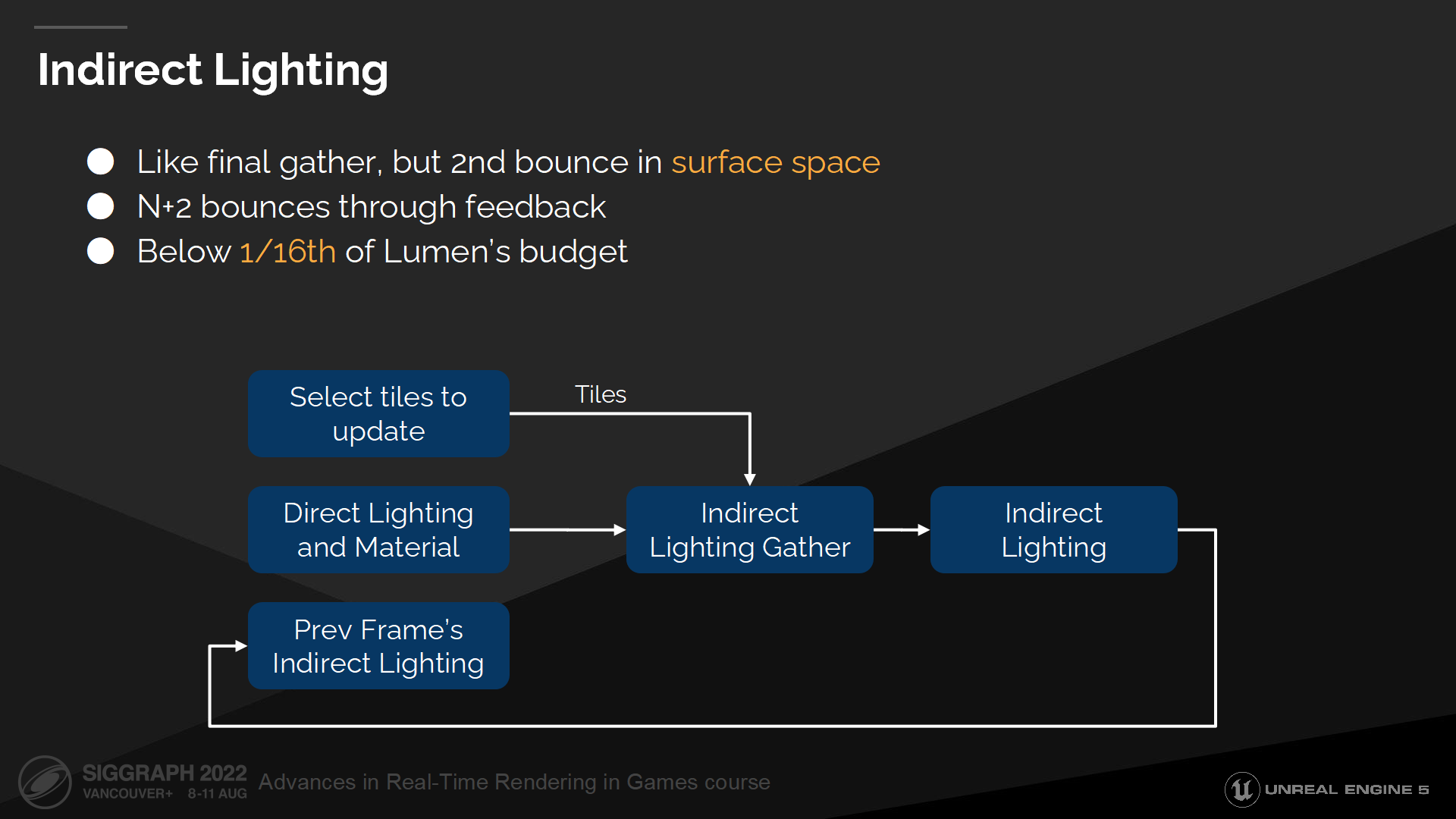
間接光照
間接光照則有更多挑戰,因為這裡我們基本上需要在表面空間中執行final gather以計算第二次彈射。(*final gather在上個系列介紹屏幕光照緩存中有詳細介紹,類似card這也是有很詳細內涵的一個概念)
In order to support multiple bounces for every indirect ray hit we sample current frame’s direct lighting and last frame’s indirect lighting. So for every frame we compute the first two bounces and the following bounces are then feedback based.
為了至此間接光照射線的多次彈射,我們採樣當前幀的直接光照和上一幀的間接光照。因此我們每一幀都計算前2次彈射,並且後續的彈射次數是基於回饋機制來計算的。
很重要的需要指出的一點是——我們的性能預算很有限,因此只能以犧牲效果的方式來換性能。這意味著不僅每幀能更新的頁數量很低,新射線的預算頁很少。
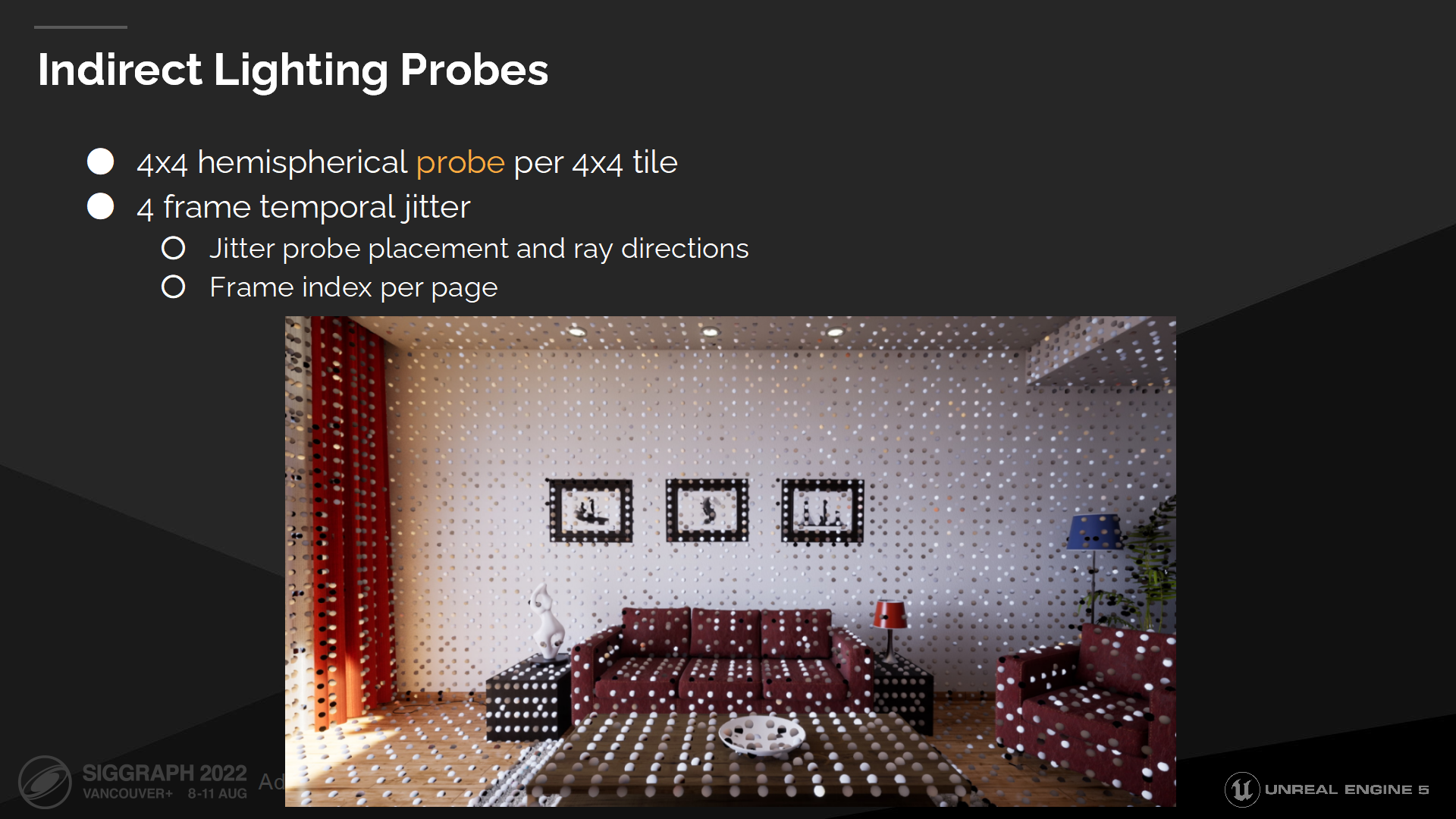
間接光照探針
理想狀況下我們將從每個texel追蹤64根射線,但這太昂貴了。作為替代我們在每4x4的tile都放置一個半球形的探針,並且只從探針的texel進行追蹤。這使得降採樣的追蹤能生效,同時還保持了表面法線的細節。
我們每幀抖動探針位置和探針方向(基於幀索引),並存儲在每個表面緩存頁中。
由於追蹤數較少,得出的探針採樣結果是有很多噪聲的,因此我們需要一些空間和時間上的重用來消除誤差。
*這部分其實和上個系列介紹的內容是呼應的。篇幅原因確實也沒辦法再展開探針和final gather的細節了。
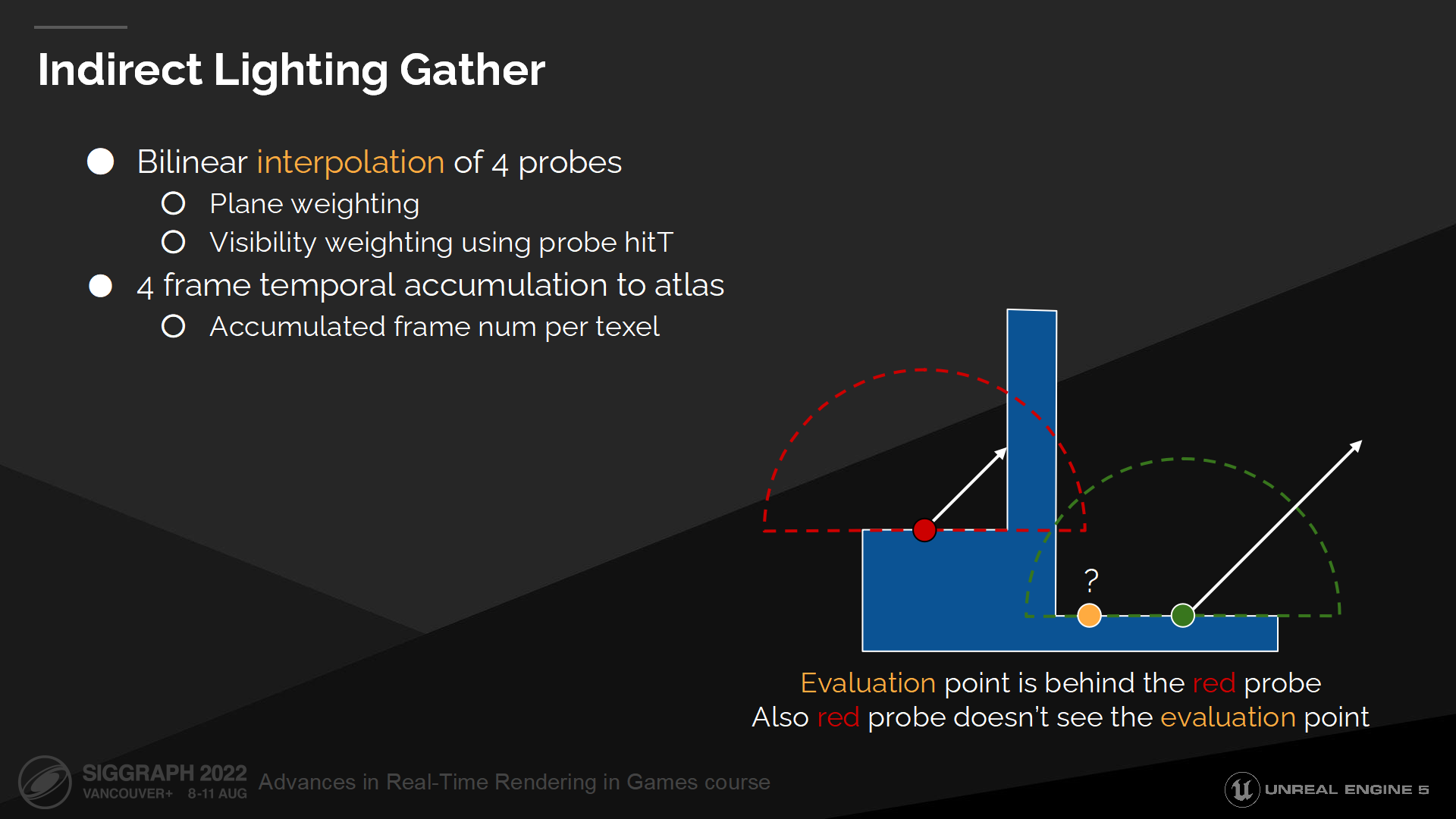
間接光照收集
對每個texel我們選取4個最近的探針,並在它們之間做插值以計算間接光照。
在插值過程中我們有2個探索策略以減少漏光——由於有些探針可能在牆後。第一個策略是對每個半球探針按其所在平面分配權重,以跳過在其之後的texel;第二個策略是使用探針的深度緩衝來檢測可見性,以評估可用的texel。
Finally interpolated results are temporarily blended into the indirect lighting atlas. Alongside this atlas we keep a current number of accumulated frames. Indirect lighting update rate is quite low and we need to limit the total number of accumulated frames to 4 in order to minimize ghosting.
最終我們得出插值的結果,並分幀(temporarily)混合入間接光照圖集中。搭配這個圖集,我們還保存了一定數量的累積幀。間接光照的更新頻率是很低的,因而我們需要把可累積的幀數設置為4,以最小化鬼影問題。

體素光照
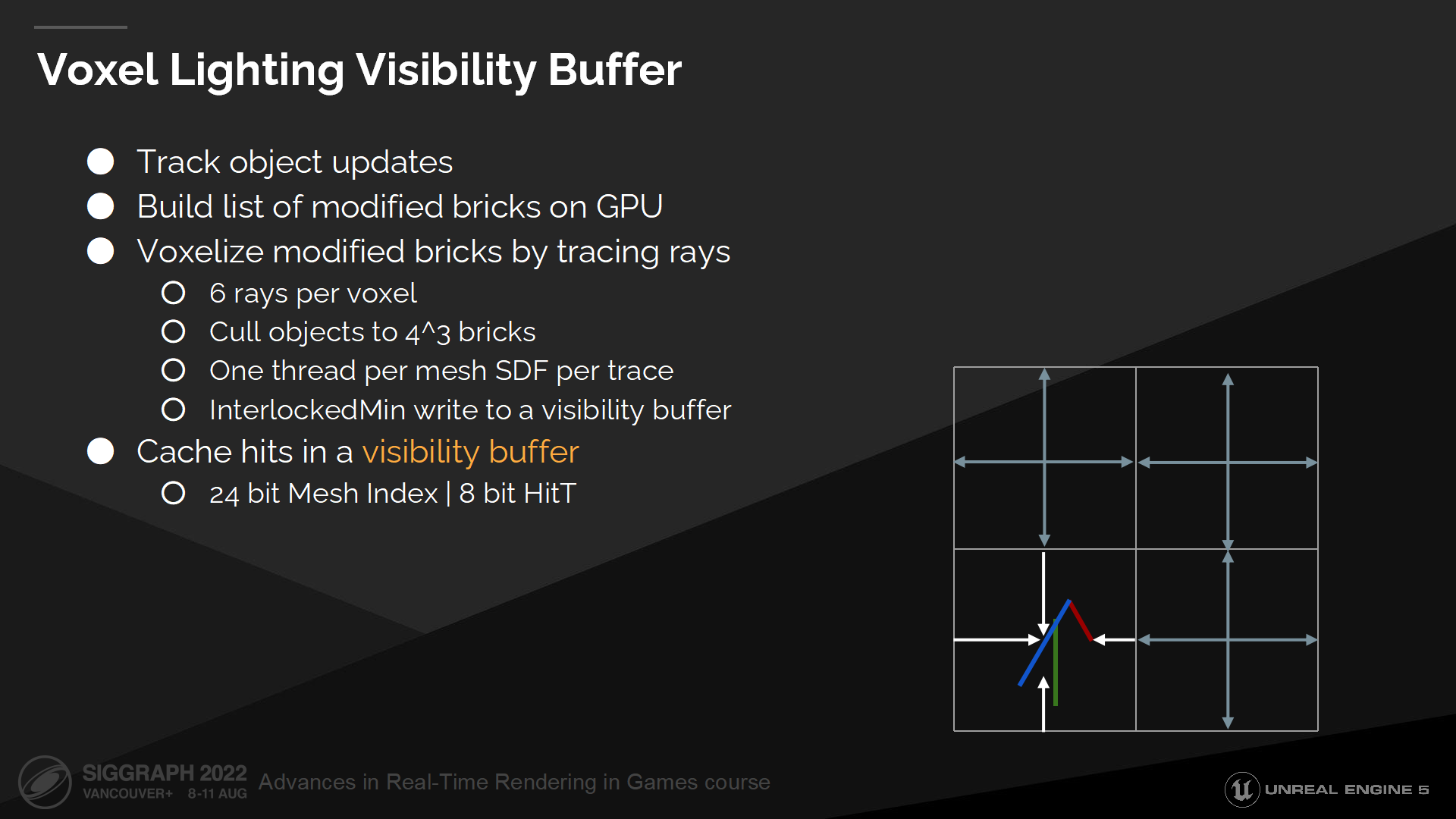
最後一個問題是,我們無法從全局距離場中直接採樣表面緩存。全局距離場是一個合併的結構,我們無法從中得知命中了哪個網格實例。
為此我們也把card合併成一組全局的以攝像機為中心的clipmap。
每個體素中存儲了每個軸向的radiance,我們在採樣時在不同方向以及相鄰體素之間做插值。
We weight every sample by weight stored in the alpha channel. This weight allows us to account for the missing cards and for card re-projection onto a fixed world space axis.
我們使用存儲在alpha通道中的權重來選擇採樣的優先級。這項權重允許我們考慮丟失的card,以及重投射到指定的世界空間的軸上的card。(*生成方式下一段會提到。使用細節原文沒有介紹,這段大概的意思是card合併之後的採樣準確性通過權重值來描述了)

體素光照更新
下一步我們每幀對整個可見性緩衝進行著色。
首先我們需要對其壓縮,因為它過於稀疏了。(*這裡還是指把不連續的數據壓縮成連續的)
在壓縮後,我們為每個有效的可見性緩衝採樣表面緩存,以計算最終的光照。
在這一步中我們也計算了投影權重,並將保存在體素光照容器的alpha通道中。

表面緩存的侷限
關於表面緩存的侷限性,最主要的問題是體素光照的質量不高(由於過於稀疏)。這是一個我們將再未來改進的點。
Card是網格導入時生成的,因此不支持網格動畫。對於樹葉,我們通過增加深度的權重bias來緩解這一問題,這對於小的形變是可行的,但對角色類動畫則不是。
某些網格——例如樹,有著太多的層級,因而不能被展開成一個合理數量的層級。這在計算反射時是一個會被注意到的問題,不過對於漫反射射線則問題不大——因為它只會導致少量能量的丟失。

總結
表面緩存的最大好處是它使距離場追蹤變得可行。
它也在緩存各類昂貴的計算結果方面有很好的功效。這不僅對於距離場追蹤有用,對於硬件光追它也有利於跳過(射線命中後)昂貴的材質和光照計算。
最後它還激活了高質量的多次彈射計算,這對渲染可信的GI和反射效果非常關鍵。
*總的來說,前沿的渲染引擎對於多次彈射的間接光照支持是越來越好了,但是對於極限情況例如樹葉等還是需要一些trick。
結語
我個人感覺這篇分享其中的內容,對比之前2021年的2篇來說有了一定的推進,一些細節設計已經不一樣了。不過作為一款有較大革新的複雜的商業引擎來說,這種程度的探索迭代也正常——更何況其中的很多參數設計、數據結構以及trick,到現在以及幾年後可能又會發生不少改變,例如處理室內場景的方案就在不斷改進的過程中,針對樹葉的方案也還談不上特別靠譜。
由於是一種總括性質但又幹貨很多的分享,因此這篇文章其實page和解說稿都包含了不少信息——例如要看具體實用的參數規格還是要看page。但總的來說,只看解說稿作為了解方案的脈絡已經夠了。儘管如此,也已經是信息量爆炸的一篇內容了。
對照概述部分來說,本篇中覆蓋到了軟件光追和表面緩存的部分;下週會更新下篇,從硬件光追的部分開始,並覆蓋後面幾節。
最後是一些資料鏈接:
Prefix Sum的Wiki
Parallel Prefix Sum (Scan) with CUDA (CUDA不關鍵 算法可以用ComputeShader實現)
Lumen: Real-time Global Illumination in Unreal Engine 5 的PTTX