前言
虽然已经粗读了几篇关于虚幻5引擎的文章了——实际上自从2021年开始Epic在SIGGRAPH上分享的干货非常多,只是之前确实没有《黑神话:悟空》这样的契机,来激发我把它们都很详细的看一遍(包括当年我个人悟性也还不足)。
可以说在《黑神话:悟空》前,确实没有太多深度使用虚幻5在高质量写实渲染方面特性的产品(勉强可以算一个《堕落之主》,但画面感觉和开发规模其实没法比;其它规模比较大的产品都没那么写实;更多的还是用的虚幻4,管线其实很不同)。
用其它引擎实际达到了极高的(光线追踪全局光照)渲染上限的,我个人认为只有《赛博朋克2077》,但也是通过不断修修补补(以及头铁开发超前于硬件水平的内容)达到的;而近年来实际画面精度特别高的其它游戏,例如《荒野大镖客:救赎2》《战神:诸神黄昏》《地平线:西之绝境》以及育碧的一些产品等,整体来说还属于前光追时代的全局光照产品,它们要考虑向下兼容或者兼容较差硬件的顾虑更多;而其源发的《战争机器》系列,由于其商业路线等原因导致的系列衰落,本来最应该扛起引擎宣传大旗的产品也渐渐起不到这个作用了。
就像之前Nvidia找高清游戏演示显卡,基本只能找《赛博朋克2077》一样,这个意义上确实可以认为《黑神话:悟空》为虚幻5的商业可行性提供了强有力的支持。在Unity引擎在商业上几乎放弃了高清渲染的当下,虚幻5的这一点就显得很可贵——在此之前也确实有很多人对(当前经济状态下)大家的硬件能否带的动那么高清的游戏表示疑虑。所以我才在上个系列文章中说,高清的渲染总得有人做——这个事情是一个第三方商业引擎来做(而不是由第一方开发内部垄断的),对有表达需求的开发者来说算是一件幸运的事。
这次选的是2022年SIG上的一篇分享,原文档是以PPT为主,每页下面搭配了一行左右的解说稿。本文还是以翻译原文PPT页及解说稿为主,打星号的部分则是我个人的补充。由于篇幅原因还是拆分成上下两篇,这是其中的上篇。 由于内容信息量爆炸,中间有些概念没法一一搭配解释,还请谅解。
1 整体概览
*如果看过我其它介绍渲染的文章,可能会感觉写实渲染就是绕不开“间接光照”这四个字了。确实,不仅引擎之间不同,同一个引擎不同版本不同管线的实现也不同。因此一深入细节总是从这里开始。
*这里有大量使用path这个词,除了在“追踪路径”中翻译成路径,其它一律翻译成“方案”,以作明显的区分。

梦想——实时间接光照
我们始终有着对于全实时间接光照的梦想——这能解锁全新的玩家与游戏世界互动的方式(光照上的)。烘焙光照限制很多,即使在很小的事项上——例如开门或摧毁一堵墙。如果这些动态不足的问题能被间接光照解决,可以想象能看到更多复杂的交互方式。
我们也想要一个对光照艺术家更好的工作流程。相比于等待几分钟甚至几小时来等待烘焙的结果,我们希望能立即可见(调整的)结果——想象如果能实时编辑光照能带来多大的光照质量提升。
我们也想要巨大的不经过烘焙的开放世界,同时解决在一个大项目中使用烘焙光照的其它问题——例如上百人每天同时编辑一个场景,而烘焙光照无法保持最新。
只解决户外的高质量间接光照也是不够的,我们希望能达到烘焙光照能达到的所有效果——包括细节光照和阴影。

挑战
而在挑战的方面,我们想匹配的烘焙质量是通过(与实时相比)成百上千倍的处理时间来达成的,即使在很小的地图上也是如此。
Global Illumination is fundamentally incoherent, and it’s a challenge to solve that light transfer efficiently when GPU’s are designed for memory and execution coherency.
全局光照是基本非连贯的(incoherent),要解决光传播计算无法充分利用GPU的内存和执行的连续性的问题也是一个挑战。
这也是一个巨大的问题空间(problem space)——即我们可选的方案很多,因此选择使用哪些方案而不用哪些方案也是巨大的挑战。
留给实时全局光照的性能预算空间(margins)很小,因此很难同时满足性能和质量两方面的要求——就像在山巅行走一样,微小的移动都可能导致性能或质量的下降。
下面我会在最高层做Lumen算法的总览,并在后续的部分中逐步深入细节。

基本问题1:如何追踪射线?
在实时间接光照上首先要解决的问题是:我们要如何在世界中追踪射线。
硬件光线追踪很强大——并且是未来的方向,但我们也需要相对小规模的备选项。在PC市场上仍有很多图形卡(就是显卡 video cards)不支持硬件光线追踪,同时主机提供的硬件光线追踪也不够快。
我们也希望能处理网格高度重叠的场景——这在硬件光线追踪的两层加速结构中运行很慢。
因此我们需要开发一个软件光线追踪方案来突破这些限制。

早期实验:把场景作为高度场来追踪(cards)
When we started working on Software Ray Tracing, one of the first things we tried was to capture the scene using a bunch of orthographic cameras, giving what we call cards. We then ray trace through the card heightfields, and sample the card lighting when the ray hits.
当我们开始软件光线追踪方案的探索时,我们尝试的第一步是:通过一些正交摄像机(orthographic cameras)来抓取场景——抓取的中间结构被我们称为场景卡(cards 后面就保留英文原文)。然后我在card的高度场(heightfields)中追踪,采样射线命中部位的光照信息。
由于这是一种2D表面描述的方式,它提供了较高的空间分辨率——相较于3D描述的例如体素等方案来说。我们可以利用高度场的属性得到很快的软件追踪效果,例如视差遮挡数据(Parallax Occlusion Mapping)。
不过终究来说,高度场无法覆盖整个场景,这样未被覆盖的区域会导致漏光问题。

网格有向距离场追踪
所以作为替代我们选择了网格有向距离场(Mesh Signed Distance Fields)作为我们软件光线追踪的几何描述结构。这能带来可靠的遮挡关系,所有区域都被覆盖了,并且我们仍然能通过球面追踪方式来快速进行射线追踪——跳过了空白的空间(距离场的特性保证的)。
与距离场的相交仅能获知位置和法线信息,因此我们无法查找材质参数或光照。

源自表面缓存的光照
We interpolate the lighting where the ray trace hit from the cards, which we call the Surface Cache. Areas that are missing coverage only result in lost energy, instead of leaking. Ray tracing the card heightfields didn’t work, but using them for lighting does.
我们通过插值的方式从射线命中cards中的位置取光照数据,这被我们称为表面缓存(Surface Cache)。未覆盖的区域会导致结果中能量的损失,而不是漏光(*漏光是更白,损失能量就更黑)。
追踪高度场(作为整体追踪方案)不可行,但使用来作为光照追踪方案是可行的。

表面缓存bonus
表面缓存有一些其它的好处:它能在不同射线之间共享材质公式,使我们能直接控制与更新表面缓存,并解锁更快的使用硬件光线追踪的方案。
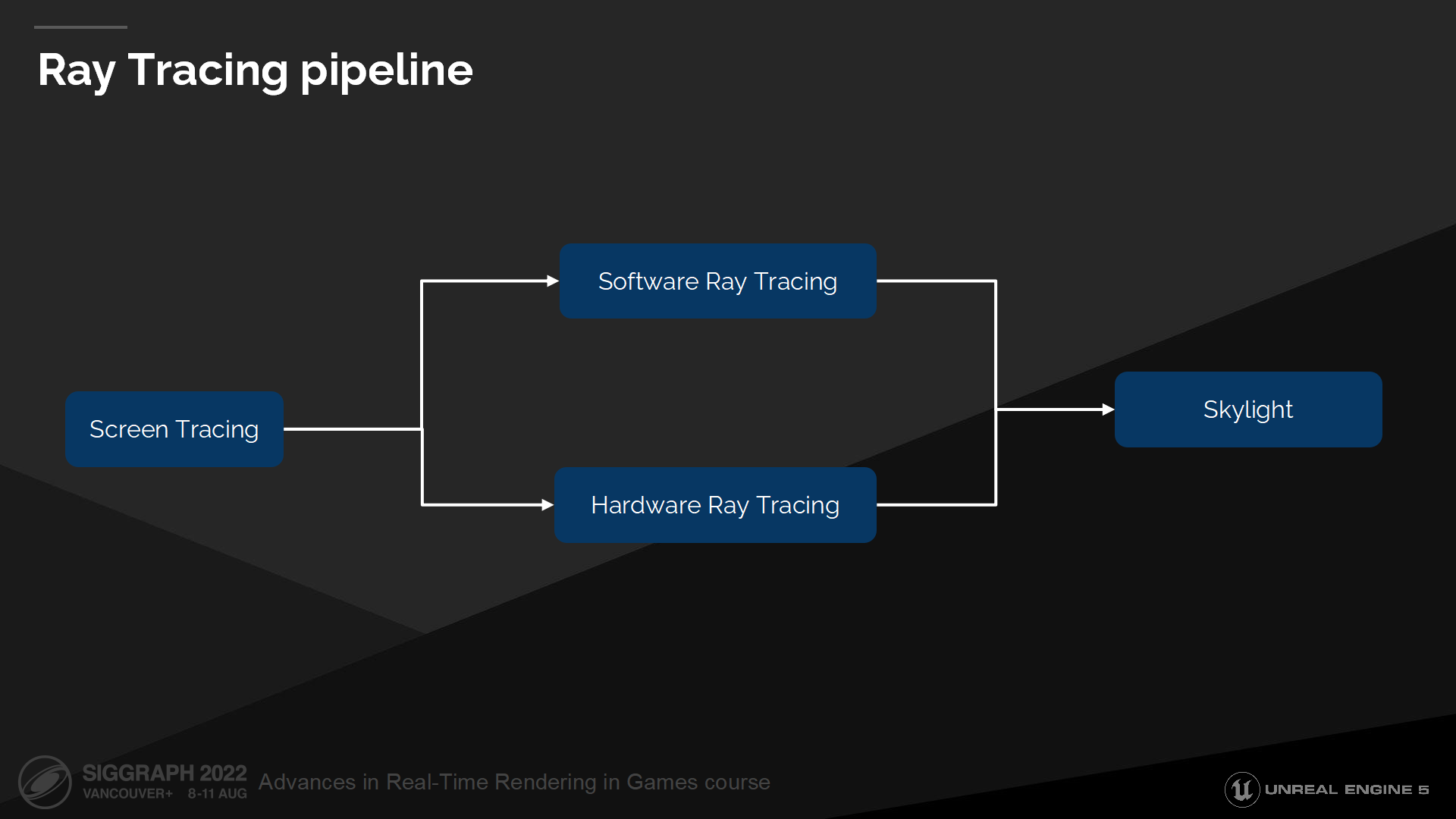
光线追踪管线
*先做屏幕空间追踪,如果需要再做软件或硬件的光线追踪(基于追踪类型配置、硬件等),全部miss时最后追踪天空光照颜色。
*前2步其实之前介绍《战神:诸神黄昏》的文章里面他们也采用了类似的方案,因为通常来说屏幕空间的方案精度往往更高一些。

基本问题2:如果解决整个间接光照的方案?
只提供一次间接光照弹射计算是不够的,我们对于室内场景需要多次弹射的漫反射,以及在反射视图中考虑全局光照。
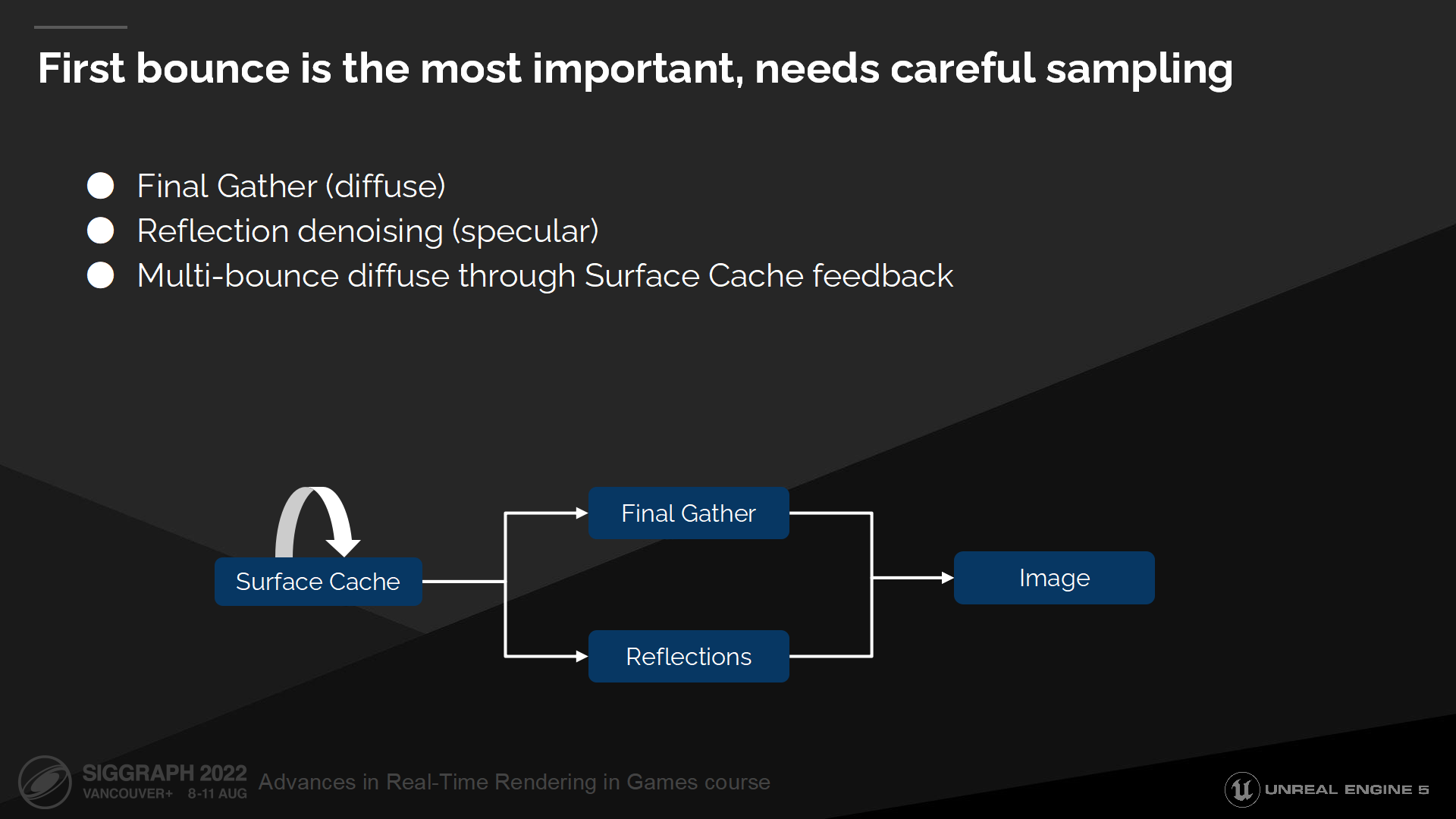
第一次弹射是最重要的,需要细致地采样
首次弹射是最重要的,因此我们将把它拆分出来并用专门的技术方案来解决——对于漫反射部分我们使用被称为Final Gather的方案,对于高光部分我们则使用反射降噪(reflection denoising)。
第一次弹射之后的弹射我们通过表面缓存的反馈来解决。我们将从表面缓存中收集数据——并被它自身读取,每次更新都传播(propagate)并计算其它间接光照中的弹射。
*这里实际上还是有不同层的card之间传播光能量的过程,当传播算完后缓存就稳定住了。原文可能略微有点绕了。

基本问题3:如何解决光传播中的噪声问题
考虑到我们甚至无法负担每帧每像素1射线,但高质量的室内渲染需要(每像素)上百个高效的采样。
*这个问题及其方案探索其实上一个介绍屏幕空间光照缓存的系列中也提到了。总体来说肯定是用各种分时方案来弥补,但细节完全不同。

Final Gather 技术
这些都导向了我们Final Gather技术的提出。我们将使用自适应的降采样方式来追踪尽量少的射线,在空间和时间上尽量重用射线(及其追踪结果),并与重要性采样(Importance Sampling)做乘积以保证射线分配到更合适的方向。
*重用射线、重要性采样等部分其实上个系列中也相对详细的介绍过了,例如基于BRDF做重要性采样等。
*到这里Final Gather这个概念已经塞进了间接光照、追踪降噪等事项要解决。

Final Gather的域
我们的Final Gather不能只解决不透明(opaque)的情况,也需要能解决半透明(Transparency)和雾(Fog)的情况。
对于不透明物体我们在一个2D域中操作,对于雾我们需要计算摄像机视锥体中的所有点,对于表面缓存我们则从一个纹理空间中收集数据(如图)。
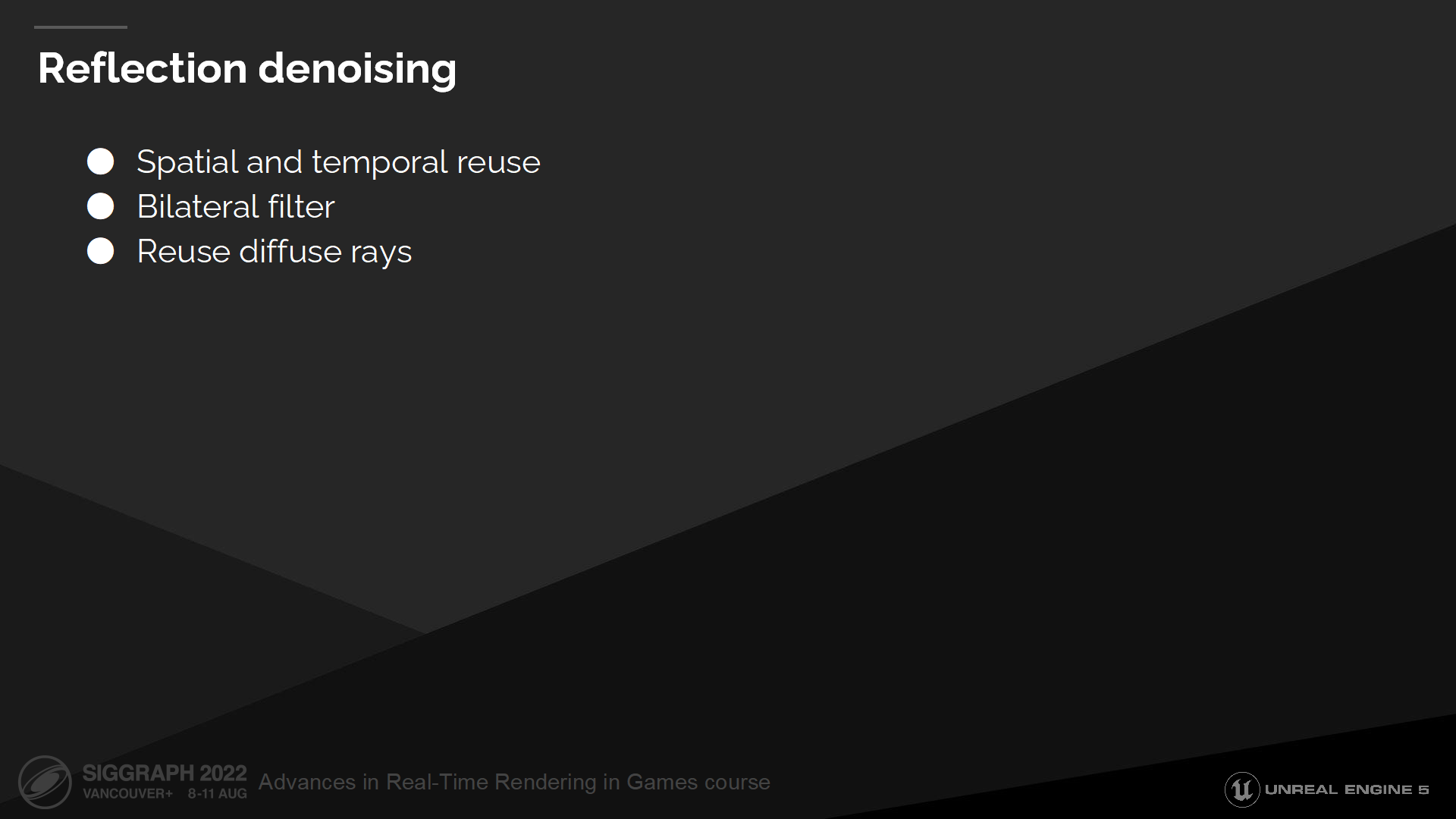
反射降噪
为解决反射噪声问题,我们将以一定方式进行空间和时间上的射线重用,并在可能的位置重用漫反射射线(结合双边过滤器)。

方案概览
*几个部分分别是:光线追踪管线、Final Gather、反射、性能与可扩展性。
*光线追踪需要的几个部分前面都已经引入了。
2 屏幕射线追踪
*在传统的现代渲染管线中,其实屏幕空间追踪就有很多可以聊(之前也介绍过一些)。但到了光追时代,这类技术更像成为了一种“基础建设”。
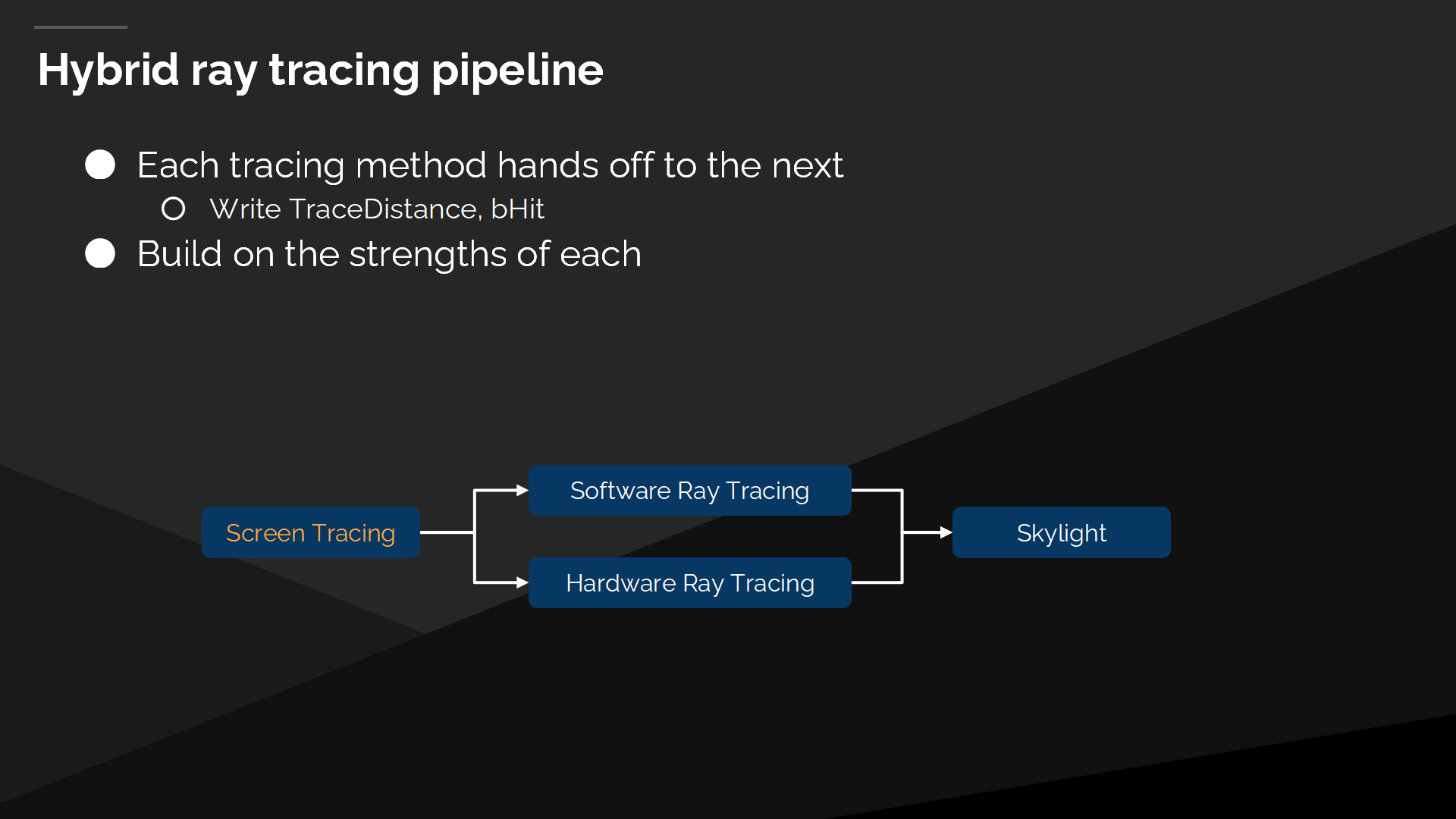
混合的光线追踪管线
Lumen使用了一个混合的(hybrid)光线追踪管线,它允许混合并匹配多种不同的技术。首先考虑的是屏幕空间追踪,然后每个追踪方法都把数据交给下一步,通过输出射线追踪的距离、或是命中的情况。下一个追踪步骤可以重启上一步留下的可用的射线。

屏幕空间追踪的好处
无论软件还是硬件光追,都存在对于光栅化的GBuffer有错配的问题(mismatches 后续会介绍到)。屏幕空间的追踪能很好处理这种错配的情况,包括可能导致“自相交”的故障——从物体内开始追踪(精度问题),或是追踪结果的错配都会导致漏光问题。

屏幕空间追踪的好处
屏幕空间追踪也很善于处理主要追踪方式没有覆盖的几何体定义方式,例如我们的软件光追就不支持蒙皮网格(skinned meshes 动画用),但我们仍然可以通过屏幕空间追踪得到间接光照的阴影。
屏幕空间追踪可以在任何尺寸规模下生效,所以它也是对细节GI有效的——无论你放大到什么程度。

线性步骤跳过细的遮挡物
屏幕空间追踪不能很好的适应线性步骤(指步长)——这会导致跳过细物体,就像图中的栏杆一样,进而导致漏光问题。
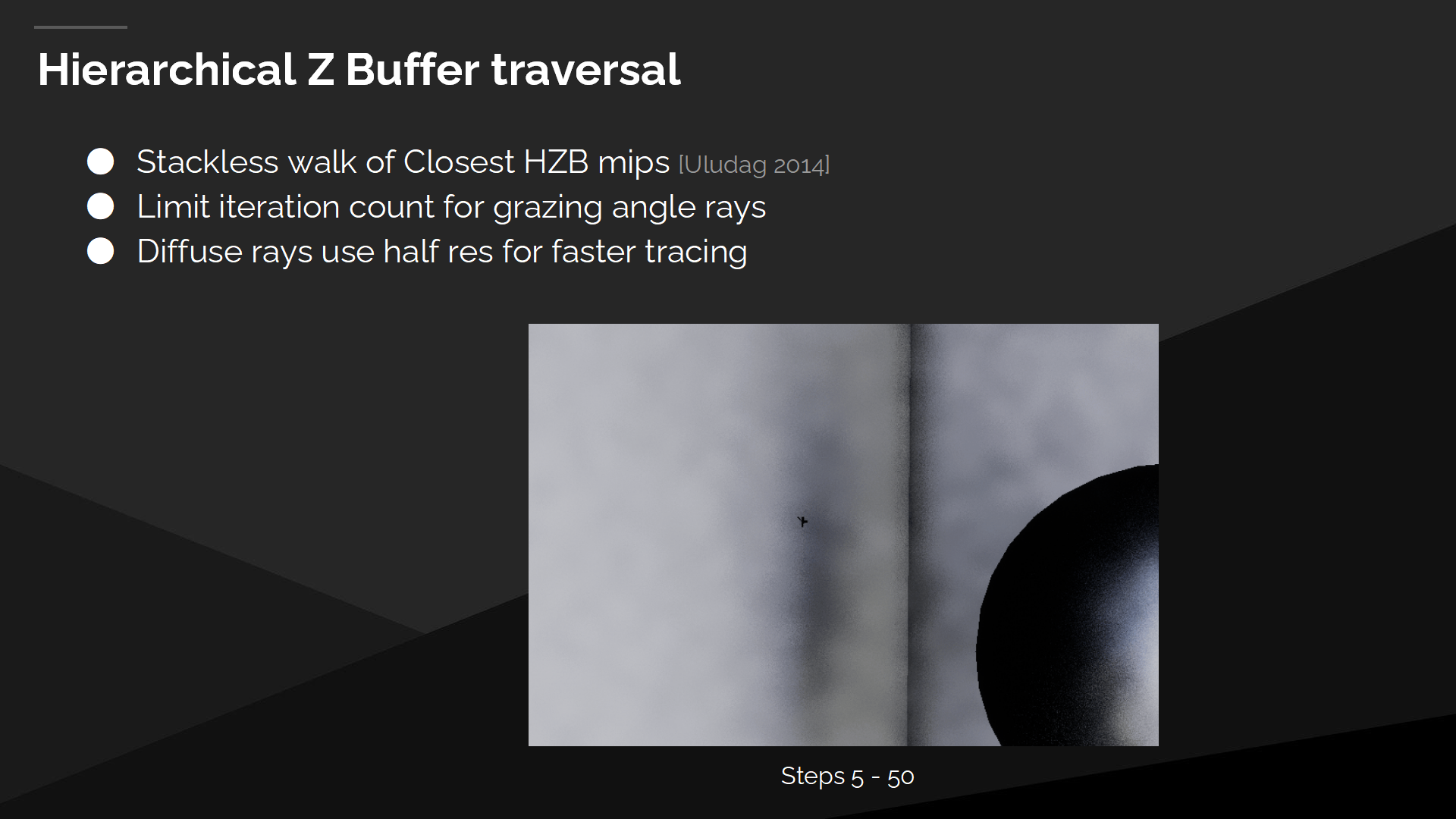
Hi-Z Buffer遍历
作为替代我们采用HZB遍历的方式——它是一种针对最接近的HZB mip的无堆栈查找方式。我们限制了掠射角(grazing angle)射线的迭代次数,例如与墙平行的射线;并且我们的漫反射射线使用半精度以达成更快的追踪速度。

*原文档有一个动画展示了每一步射线追踪执行的过程(长度逐步延伸的)。这里直接截取了执行一定步骤后的追踪情况示意图。
*关于Hi-Z Buffer(缩写HZB)以前介绍过,也可以搜搜网上讲现代渲染管线的文章。

准确地传递给下一个追踪方法
我们必须确保准确的把数据传递给下一步追踪方法,否则就会导致漏光问题。
我们通过(在步进追踪的过程中)回退到最后一个未遮挡的位置以解决这一问题——当射线进入物体表面或离开屏幕范围时。

屏幕空间追踪的结果
总的来说,屏幕空间追踪完全胜在质量上,尽管能实现的质量越高,穿帮时就越能被注意到。
结合硬件光线追踪它也能带来小的性能提升——因为它允许大部分射线脱离复杂的表面集合来运算(屏幕空间的不透明几何已经被深度缓冲处理过了)。
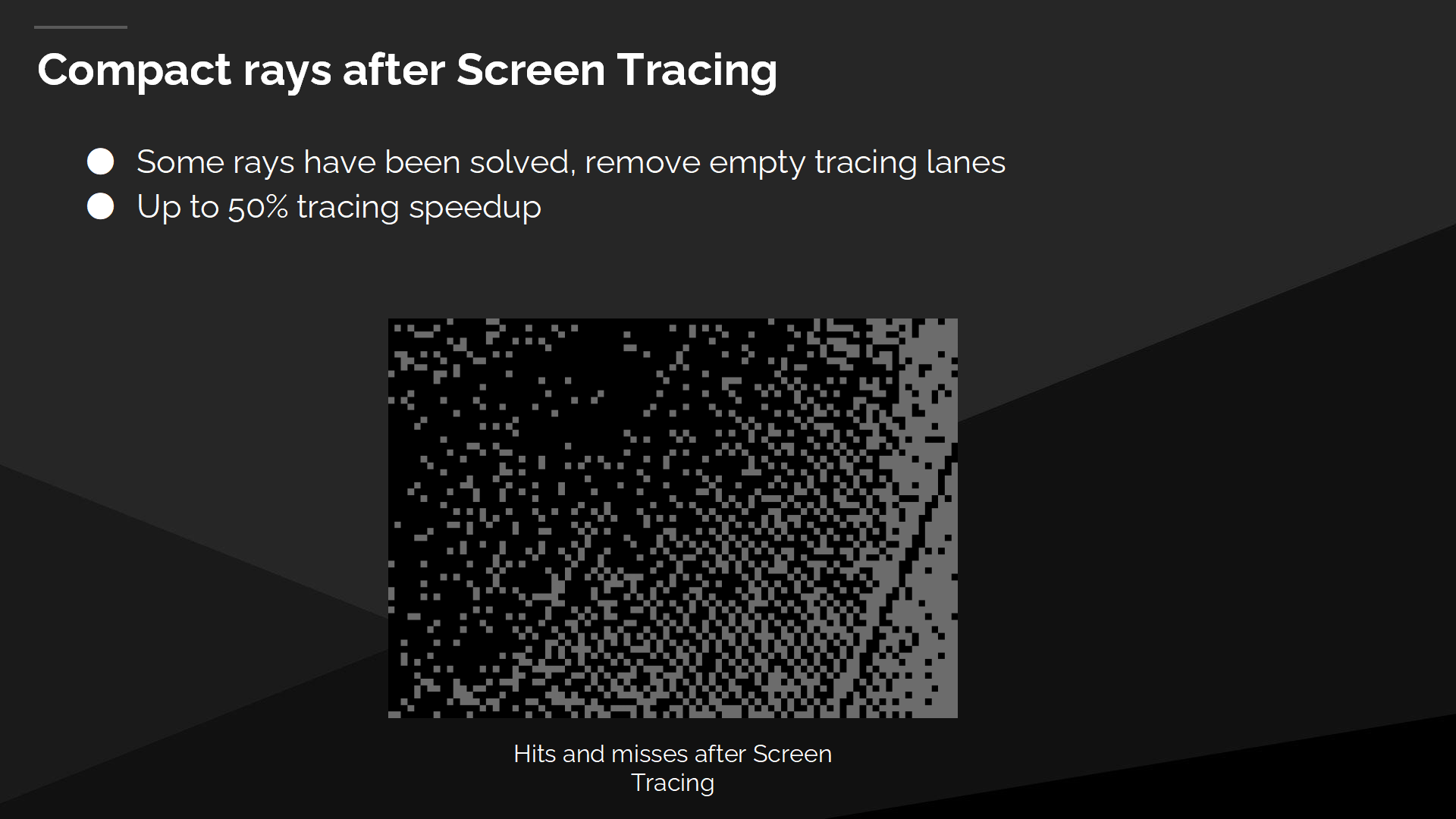
在屏幕空间追踪后,使射线更紧凑
在屏幕空间追踪执行后,部分射线查找已经被屏幕空间的追踪解决了,同时其余射线仍然需要后续的追踪。相比于直接在所有空白的追踪路线上执行下一个追踪步骤,首先我们进行了一个数据压缩过程,这为我们带来显著的速度提升。

The easiest way to do a compaction is to use local atomics to allocate the compacted index. That has the effect of scrambling the rays, which you can see on the left. The red lines are all the different rays within a single wave, and they’re now starting from different positions within the scene.
最早的一种压缩方式使利用局部数据原子(atomics)来分配压缩后的索引。这会导致争夺射线的后果,如左图所示——红色的线代表了单一批次执行的不同射线,它们都从场景中不同的位置发出。
我们采用了一种顺序保持的压缩方式来解决其中的问题,使用一个快速的前缀和(prefix sum)方式,搭配更大的线程组来分配压缩后的索引。
*如果压缩顺序不能保持,那么在多线程执行发生分配资源不够导致“射线争夺”时,结果的不确定性就会更大(包括分帧跳变等问题)。
*关于prefix sum这种处理方式是很值得一看的,它是一种常用的并行计算(索引)管理方式。文末会附资料连接。
3 软件光线追踪
*大段很绕的部分我会保留原文作为参照,不得不说部分名词确实无法很好的和中文对应,实际上还是得结合语境来理解。

为什么需要软件光线追踪?
首要的问题是,为什么在硬件光追方案已经有了的现在,还需要软件光追。
虚幻引擎能支持不同平台的不同类型的内容,我们也需要不同的工具以处理这种大范围的用户用例。这是我们引入软件光线追踪的主要动力,我们希望在没有DXR支持的硬件上(以较小的规模)运行光线追踪。
我们并不能完全替换掉硬件光追,但对追踪过程有完整的控制(而不是全交给显卡)能使我们做出不同的tradeoff。例如,重叠的实例在BVH上会是一个问题(不好识别),射线必须与每一个实例做相交计算来判断最近的实例,同时我们也无法改变这种(硬件的)加速结构设计。

概述
在高层设计中我们有两个基本元件——一个逐个网格的距离场、和一个逐个地形原件的高度场。
Those primitives are stored in a two level structure, where on the bottom level we have our primitives and top level is a flat instance descriptor array. This approach allows us to leverage instances for storage and decreases memory usage, which is important for any kind of a volumetric mesh representation.
这些基本元件被储存在一个两层结构中,在底层数据中是我们的元件数据,同时顶层设计中是一个扁平的实例叙词数组。这种方式允许我们利用实例(属性)作数据存储并降低内存使用,这对于任何形式的体积网格描述方式(volumetric mesh representation)都很重要。
距离场(Distance fields)不是UE引擎中的新事物,因此这里会聚焦在Lumen中新开发的特性。(2015年Wright分享的内容,同时他此时还是UE的资深引擎开发人员之一)
*SDF之前也有文章介绍过了,实际操作中主要面对的就是解决精度问题。
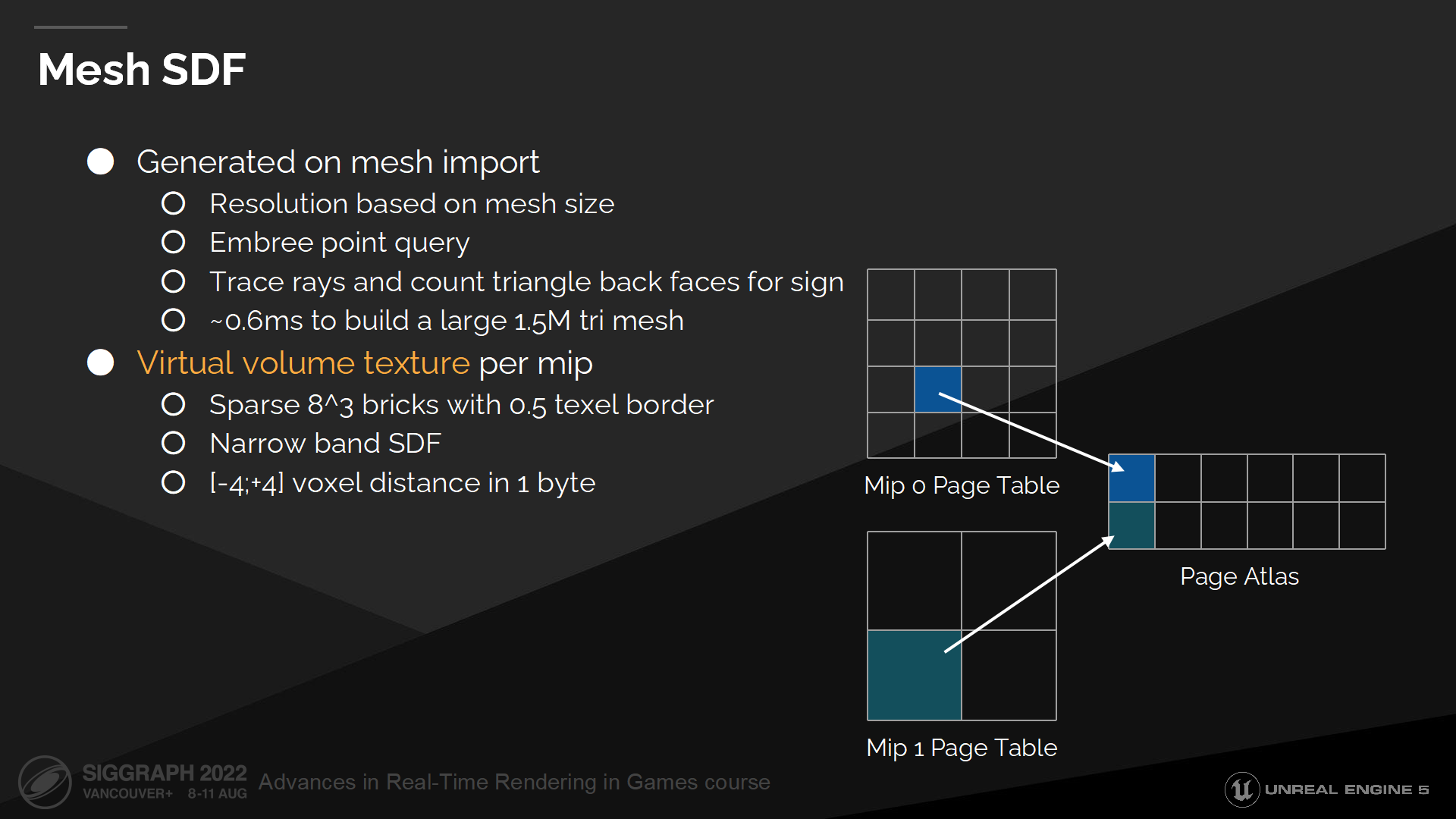
网格SDF
我们在模型网格导入时,就伴随其它必要的网格数据同时存储距离场数据(即离线生成距离场)。
For generation we use Embree point query to efficiently find distance to the nearest triangle. We also cast 64 rays from every voxel and count backface hits to decide whether we are inside or outside the geometry, which determines the distance field sign.
在生成时我们使用Embree点查询(*Embree是Intel提供的一个高性能光线追踪库)来高效查找三角面附近的距离。我们也从每个体素发出64根射线来统计背面命中数,以决定点是在几何体内部还是外部,这决定了距离场的方向(sign 正负)。
Volumetric structures don’t scale well with resolution and are quite memory intensive, so we store only a narrow band distance field inside a mip mapped virtual volume texture.
体积结构不能很好的随分辨率缩放,并且很耗内存,因此我们仅存储了很窄带宽的距离场数据——在一个mip映射结构的虚拟体积纹理中(virtual volume texture)。
Mip0的清晰度(和分辨率是一个词 resolution)是基于网格的尺寸和网格导入设置来决定,然后mip1 半分了精度并加倍了最大物体空间的距离——更多mip层级以此类推。
*页中还对应介绍了一些技术参数(例如导入网格的速度),以及mip和虚拟纹理之间的对应关系。

网格SDF流式加载
每一帧我们都指派一个shader来循环所有实例。它基于和摄像机的距离,计算每个距离场实例需要的mip级别。
之后我们通过CPU发出载入指令,并流式加载需要添加的距离场mip,或是移除那些不再使用的。
Distance field bricks are stored inside a fixed size pool, which is managed by a simple linear allocator. It’s a convenient setup, as we don’t need to deal with any kind of a variable sized 3d allocations or resulting fragmentation.
距离场块(bricks)被存储在固定尺寸的池子中,通过一个线性分配器(allocator)来管理。这是一种便利的设置方式,因为我们不需要处理任何可变长度的3D内存分配或导致碎片问题。

网格SDF追踪
对于网格距离场的追踪,我们使用mipmap来加速光线步进(ray marching)的过程。当接近表面时,我们使用更高的更精确的mip;在距离很远时,我们切换到较低的mip来快速跨国空白的空间。
我们也限制网格距离场ray marching的迭代次数——最大64,基于性能方面的考虑。当达到上限时,我们停止遍历并输出当前命中距离能得到的结果。
最终当追踪命中后,我们使用中部差分(central differencing)方式做6个采样来计算几何体的法线——它会在后续被用来从表面缓存中采样材质和光照。

高度场
地形被划分成不同的部件,并且我们对每一个单独的高度场都在表面缓存中有单独的部件。
在上层结构中,高度场实例的处理与网格距离场域的实例类似,会重用其中的剔除和遍历代码。
Bottom level is different, as per instance instead of a 3d distance field, we raymarch a 2d heightfield and try to find a zero crossing. After finding two samples, where one is above and the other is below heightfield, we linearly interpolate between them to approximate the final hit point.
底层结果则不同,相对于(网格距离场)的实例是3D距离场,对高度场我们raymarch一个2D高度场,并试图找到一个零交叉点(zero crossing)。在找到两个关键样本后——一个位于高度场上方、另一个位于下方,我们对两点线性插值来估计最终命中位置。(*就是page中的LERP函数。零交叉点是一个信号学概念,代表函数中从正转负——或相反的变化点。)
通过命中点我们可以从表面缓存中评估不透明度(opacity),以评估我们是要接受命中结果或是跳过这次命中以继续在高度场中追踪。
在接受命中结果后,我们从表面缓存中估计(采样)位置并计算射线的辐照度(radiance)。
*上个系列也解释过了,radiance后续就保留原词。关于光传播能量计算,详细的理解还是要去看Games101的讲解。

加速结构
At this point we have all the data in the memory and we know how to trace an individual instance. Now we need to figure out how to trace the entire scene as we cannot just loop over all instances in the scene and raymarch each one of them.
此时我们在内存中已经有了所有需要的数据,并且我们已经知道了如何追踪单独的实例。现在我们需要确定如何来追踪整个场景的物体,因为我们不能简单的循环访问所有实例并逐一raymarch。
We tried BVH and grids. Those are really nice acceleration structures as you can build them once per frame and then reuse them in multiple passes. Unfortunately performance of long incoherent rays wasn’t good enough. Software BVH traversal has a quite complex kernel. Grids have complex handling of objects spanning multiple cells. On top of that scenes with overlapping instances require to raymarch each one of them in order to find the closest hit.
我们尝试了BVH以及栅格(grids 有一个翻译是网格,但为与mesh区分后续都翻译成栅格)。它们都是很不错的加速结构,你可以每帧对它们重新构建,并在不同的渲染阶段进行重用。不幸的是对于长距离不连贯的射线的性能不够好。软件BVH遍历有一个很复杂的计算内核(kernel),而栅格对于处理跨格子的物体则较为复杂。而更重要的是,重叠物体较多的场景需要对物体逐一raymarch来识别出最近的命中位置。
最终我们决定简化这个问题,并且只追踪短射线。当追踪的覆盖区需要变得更宽时,我们需要切换到另一种追踪方法。

运行时场景LOD
This was an important realization that we need a precise scene representation only for the first segment of a ray and after that we can switch to a coarse scene representation. This also gave us an opportunity to solve the object overlap issue, as now we can merge entire scene into some simplified global representation.
我们产生了一条重要的认识:只在射线追踪的第一段,我们需要准确的场景表达(representation 可以理解成高度场、SDF、BVH等描述形式的总称),在那之后我们则切换到一个松散的场景表达。这也给我们带来了解决物体重叠问题的机会,因为我们可以将整个场景融合成某种简化的全局表达方式。
我们尝试了几种不同的实现方式:
显然有一种方式是在场景构建时就把整个场景合并成一体,不过这是一个过于严格的工作流程(不适合并行),并且无法支持动态物体。
我们尝试了运行时体素化和锥体追踪(voxel cone tracing),但合并几何体参数的过程中会导致很多漏光问题——尤其是对于较低的mip时。
我们也尝试了体素数据块(voxel bit bricks),这种方式我们在每个体素中存储1比特数据来标记它是否包含几何体。基于数据块的ray marching过程比想象的要缓慢——在我们添加了加速用的邻接纹理(proximity map)后,效果仍不理想,因此最终我们放弃了体素而决定采用全局距离场(Global Distance Field)。
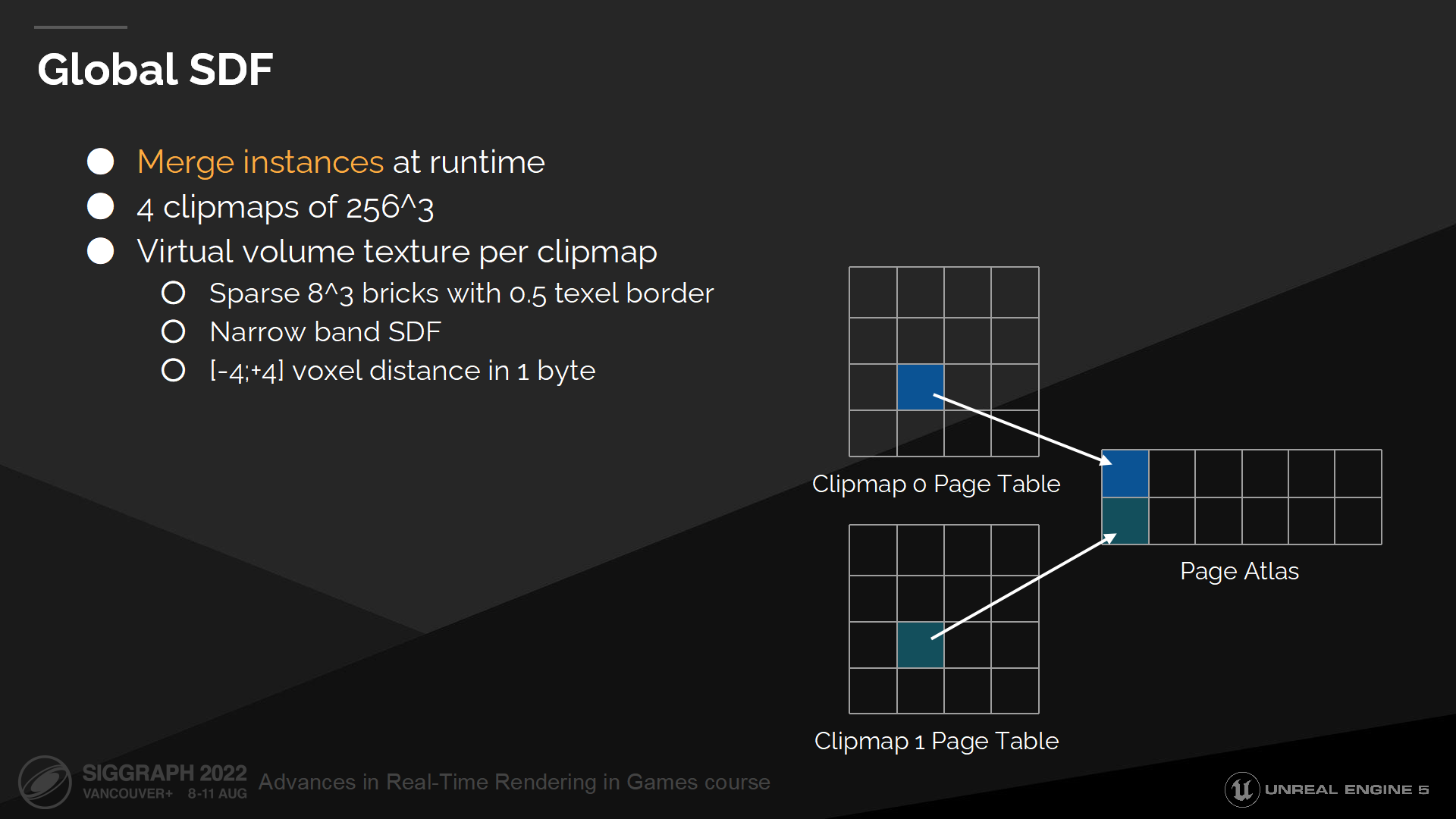
全局SDF
全局距离场合并了所有网格距离场和高度场,并汇入一组以摄像机为中心的裁剪纹理(clipmaps)中。网格距离场和高度场都是完美的网格描述形式,它们都足够简单因而能在运行时进行合并或LOD。
默认情况我们使用4个稀疏的clipmap——由虚拟体积纹理构成。每个clipmap存储距离场块,并且每一块存储一个窄带宽的距离场。
这很类似网格距离场的设置,不过相比于使用一个mipmap层级,我们使用clipmap层级——因为我们想要简化远离摄像机的场景(通过LOD)。

全局SDF缓存
要合并场景所有物体是开销很大的,因此我们需要激进的缓存策略——仅更新那些和上一帧相比变化的物体。
我们也对更新远景的clipmap做了分帧处理,并且我们对于不同的clipmap有不同的LOD设置——这使我们能丢弃远处的小物体。这确实对更新时的性能很有帮助,因为大clipmap也需要更新和合并大量的实例信息。
通常只有少量的场景物体是可动的,大部分剩余物体都是完全静态的。我们利用这一点把缓存划分为动态和静态块,因此当移动一辆汽车时我们不需要重计算静态建筑的缓存数据。
For cached updates we track all scene modifications and build a list of modified bricks on the GPU. Next we cull all the objects in the scene to the current clipmap and then cull resulting list to modified bricks. During the last culling step we sample mesh distance fields for more accurate culling that checking analytical object bounds.
对于缓存更新,我们追踪所有场景的变化,并在GPU构建需要修改的块的列表;然后我们基于当前场景物体计算剔除并汇入当前clipmap,之后基于剔除结果列表修改缓存块的数据。在上一步剔除步骤中我们采样网格距离场用于解析式的物体范围(analytical object bounds)更准确的剔除。(*这里指物体范围是用解析式或公式描述的,而不是点集描述的,就可以带入计算来判断)
此时我们得到了一组待修改的块的列表,以及每个块被剔除的物体列表。这样我们可以对块的数据做分配或接触分配,以执行更新过程了。

全局SDF更新
为更新单个块,我们循环所有影响它的物体,并为每个体素计算最小距离。
有一个问题是实例可能有非统一化(non-uniform)的尺寸,但存储在距离场中的距离仅对标准化尺寸的实例有效。
We tried finding the nearest point through an analytical gradient and then recomputing distance from it, but it didn’t work well in practice due to the limited distance field resolution. In the end what worked for us is simply to bound the distance field using distance to analytical object bounds. Most of the non-uniformly scaled objects are also simple shapes like walls so it works really well in practice.
我们尝试通过一种解析梯度(analytical gradient)的方式来找到最近的点,并为其重计算距离——但在实践中这不太可行,因为距离场的精度是有限的。最终对我们有效的方案是,简单地使用到物体的(解析)边界的距离作为距离场的边界。大部分非统一化尺寸的物体有着简单的形体——例如墙壁,因此这个方案在实践中是运作良好的。
当更新动态块时,我们需要和重叠的静态块组合,以合并两者的缓存数据更新到最终的距离场中。
最终我们更新粗粒度的mip——它是一个四分之一精度的非稀疏距离场容器(non sparse distance field volume),用于加速空白空间的跳过过程。我们在执行步进时使用粗粒度的mip替代clipmap层级——因为我们的clipmap有着不同的LOD层级,在最大的层级中可能会丢失一些物体。
粗粒度的mip有着很低的分辨率,所以我们始终更新整个volume——通过采样全局距离场数据,并通过一些Eikonal传播算法迭代来拓展它。
*图中列出了Eikonal传播的出处。
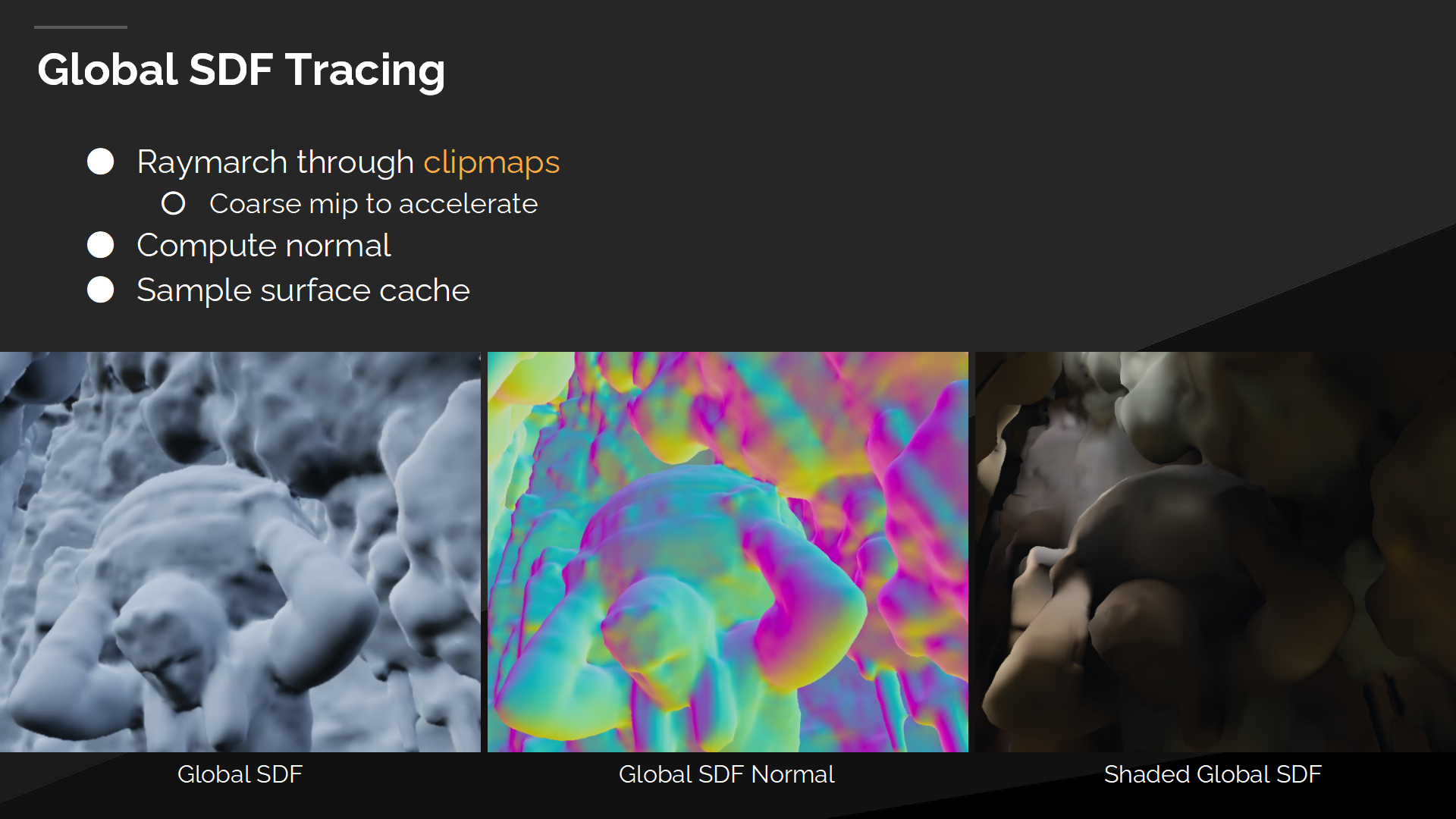
全局SDF追踪
在追踪全局距离场时,我们从最小的clipmap开始循环,逐一做raymarch直到命中一个位置。
Every step we first sample the continuous coarse mipmap and if we are close to the surface then we also sample sparse bricks.
每当我们第一次采样连续粗粒度的mipmap时,如果很接近物体表面,则我们同时采样稀疏块的数据。
最终当我们得出命中点时,我们通过6个采样点来采样表面缓存,以计算表面渐变并获得光照信息。
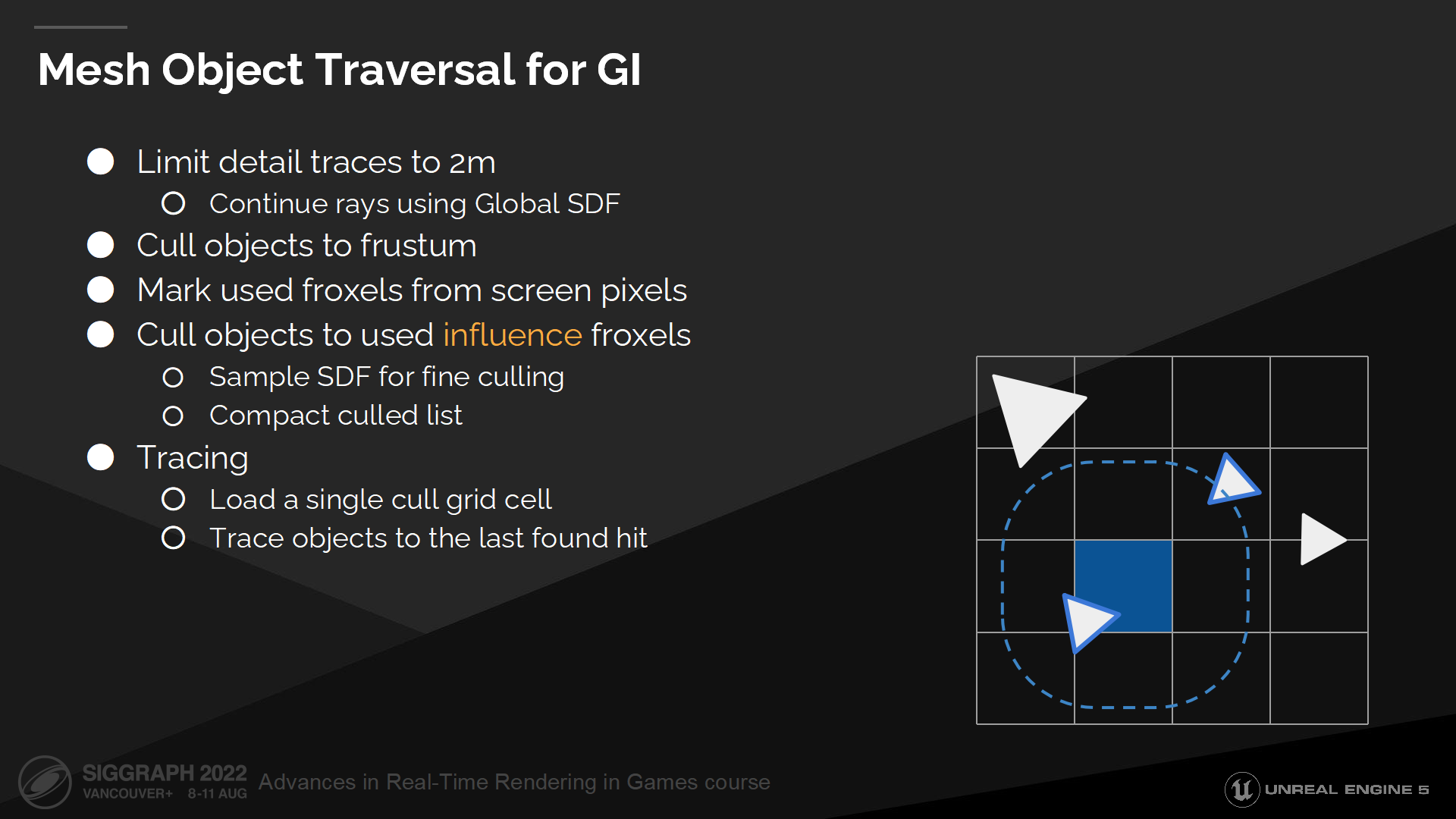
GI中的网格物体遍历
现在我们已经有了一个远场追踪的备选方案(fallback),可以回到网格距离场追踪了。(*指近距离使用的方案,图中提到是2m距离内的)
With the assumption of tracing only short rays we don’t need BVH or world space grids anymore. Instead we can cull objects to an influence froxel grid, where every cell contains a list of all objects which need to be intersected if a ray starts from that cell.
基于近距离只追踪短射线的假设,我们不再需要BVH或者世界空间栅格(而直接计算物体相交)。作为替代我们可以筛选剔除物体并汇入一个可变的视锥栅格中(influence froxel grid),其中每个单元格包含了(当射线从该格发出时)需要判断相交的物体列表。
为产生这个列表,我们首先基于视锥(frustum)剔除场景物体。之后我们标记出包含几何体的视锥栅格单元(froxel 这个应该是组合frustum和voxel的生造词),以避免浪费追踪时间在完全不被使用的froxel上。
下一步我们剔除物体(这一步是遮挡剔除)以标记froxel单元格。第一步物体的剔除测试是粗略的包围盒检测,第二步则是一个精确的距离场采样。
最终我们把剔除结果列表压缩进一个连续的物体列表中。
当从像素中追踪GI或反射信息时,我们会加载一个合适的单元格,循环其中所有物体并ray march直到命中一个位置。这样得出的结果非常简单且有着连贯的追踪核(kernel)。

网格物体遍历用于计算直接阴影
Directional shadow rays are parallel and we cannot depend on a cone footprint getting wider here. Which means that we need to trace full length rays.
直接阴影需要的射线是平行的,因此我们不能依靠锥体追踪的范围变得更宽来解决——这意味着我们需要追踪全距离的射线。
为实现这一点我们把物体剔除并划分入一组光源空间的2D栅格中,每一个单元格包含了可能相交的物体数组。
Next to fill this grid we scatter objects by rasterizing their object oriented bounds. Inside the pixel shader we do extra fine culling by sampling the mesh distance field.
下一步为了填充这组栅格,我们通过光栅化它们物体朝向上的包围盒来把物体打散,之后在像素shader中我们基于采样网格距离场做更好的剔除。
最终我们的剔除列表是经过压缩的。
之后再追踪阴影射线时,我们将加载一个合适的单元格,循环其中的物体并逐一ray march直到命中一个位置。

软件光线追踪管线
现在我们就有了所有软件光追管线的部件:
- 我们从屏幕空间追踪开始
- 之后我们在未得出结果的射线位置执行(短距离)网格距离场追踪
- 下一步我们使用全局距离场追踪剩余射线位置
- 最终仍未得出结果的射线会采样天空颜色

SDF中的单面表面
在我们结束这个章节前,仍有一些在实践中需要解决的使用距离场时的问题。
First one is that many meshes aren’t closed. This often happens with scanned meshes or simply meshes which aren’t supposed to be seen from the opposite side. It’s not an issue for rasterizer, but in case of a distance field it produces a negative region which will stick out from the geometry and break tracing.
首先,许多网格是不闭合的。这通常发生在网格是扫描产生的,或者网格背面不需要被看见的情况。这在光栅化管线中不是一个问题,但在距离场的情况下它回产生一个从几何体中突出的负值域,从而打破追踪过程。
To solve this problem, during the distance field generation we insert a virtual surface after 4 voxels. Or in other words we wrap negative distance after 4 voxels.
要解决这个问题,在距离场生成时我们每4个体素插入一个虚拟表面——换句话说我们每4个体素之间都将负距离值包住了。
这不是一个完美的方案,并且仍然会导致光栅和ray marching之间的错配问题,不过总好过有一大片负值区域。
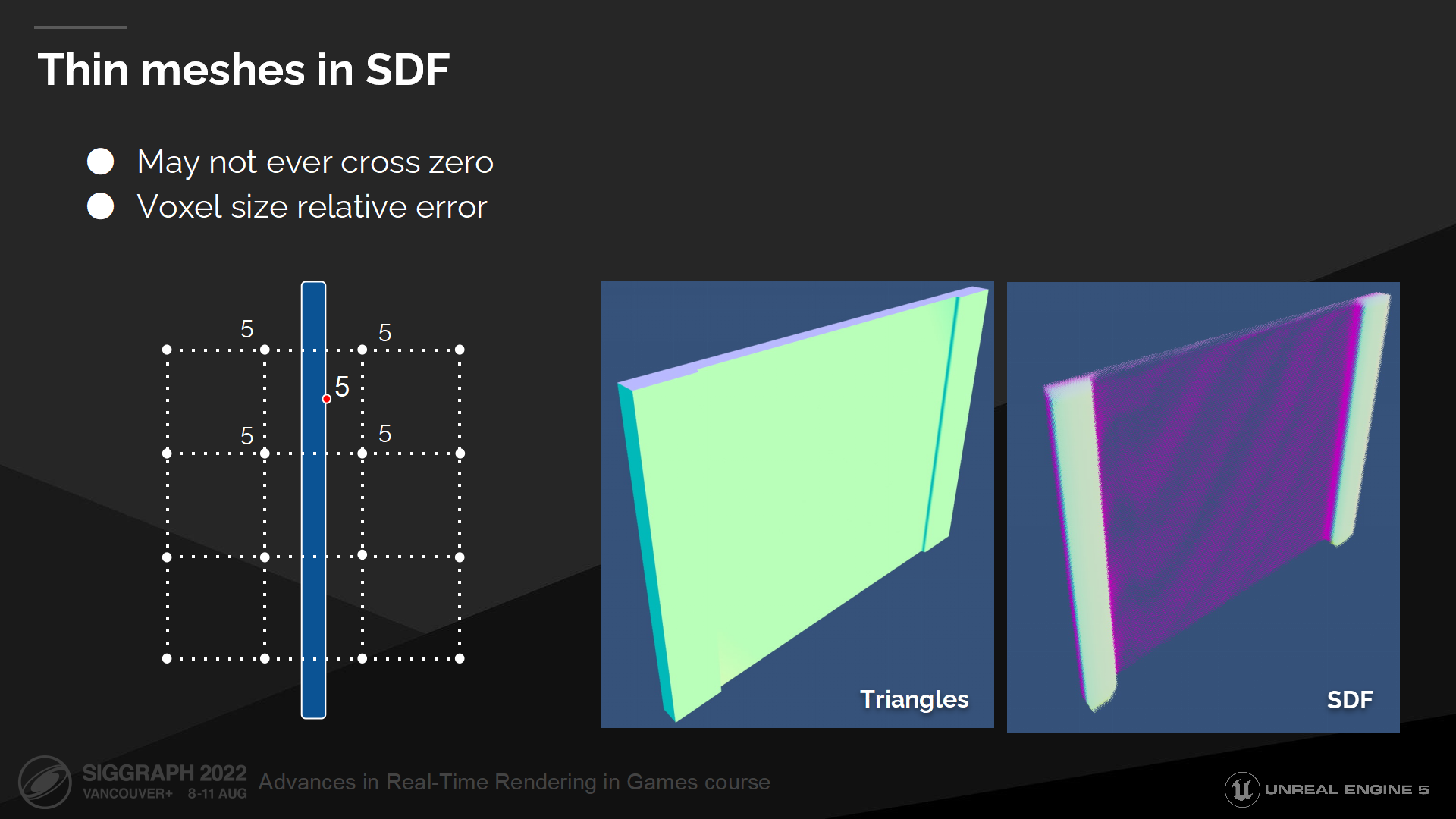
SDF中的细网格
另一类问题是细网格导致的。
离散的距离场表达方式是受限于分辨率的(有最小点间隔限制),因而无法表示出距离小于两个体素间距的细节。
In this diagram you can see an example of a thin wall, which is placed between the sampling points. Evaluating such distance field won’t ever result in a zero or negative distance and ray marcher won’t ever register a hit. Gradient computation will be also incorrect as gradient around this wall will be zero.
在图中你可以看到一个细墙面的例子,它位于采样点之间。评估这种距离场中的情况将无法得出零或负距离,以至于光线步进中不会视为一次命中结果。梯度计算的结果也将是错误的,因为这个墙面被记为了零值。
这在很多普遍的使用场景中会是灾难性的问题——当室内较暗而室外明亮时,即使有一根射线穿过了这种墙,都会导致大量漏光问题。
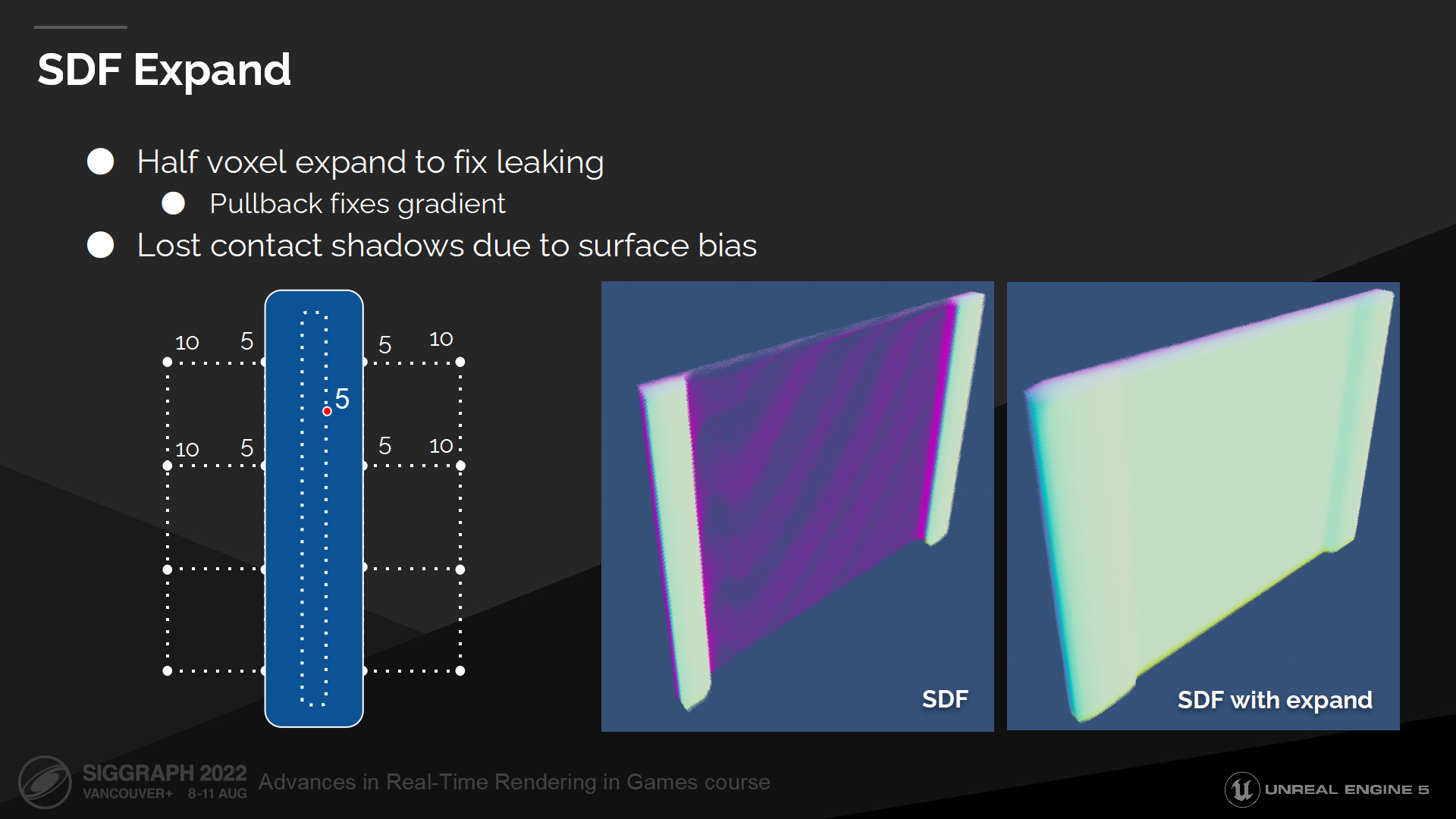
SDF延展
要克服这一问题,我们需要把距离场以体素对角线长度的一半做延展。
This expand fixes leaking and now we can reliably hit any thin surface. Gradient also will be fixed, as we will be computing it further away from the surface where we have reliable distance field values.
这种延展能修复漏光问题,使我们能可靠地命中细表面。梯度计算也被修复了,由于我们有了可靠的距离场参数,计算距离这一表面更远的位置也能正确实现。
延展操作是运行时进行的,这使我们能保存原始的距离场数据。
这种延展的缺点是会导致过度剔除,同时我们也需要更大的表面偏移量来判断离开表面的位置(to escape the surface)——这会导致破坏邻接阴影的问题。(*就是说bias要额外把延展出的这一段考虑进去,对算阴影来说就偏差更大了)
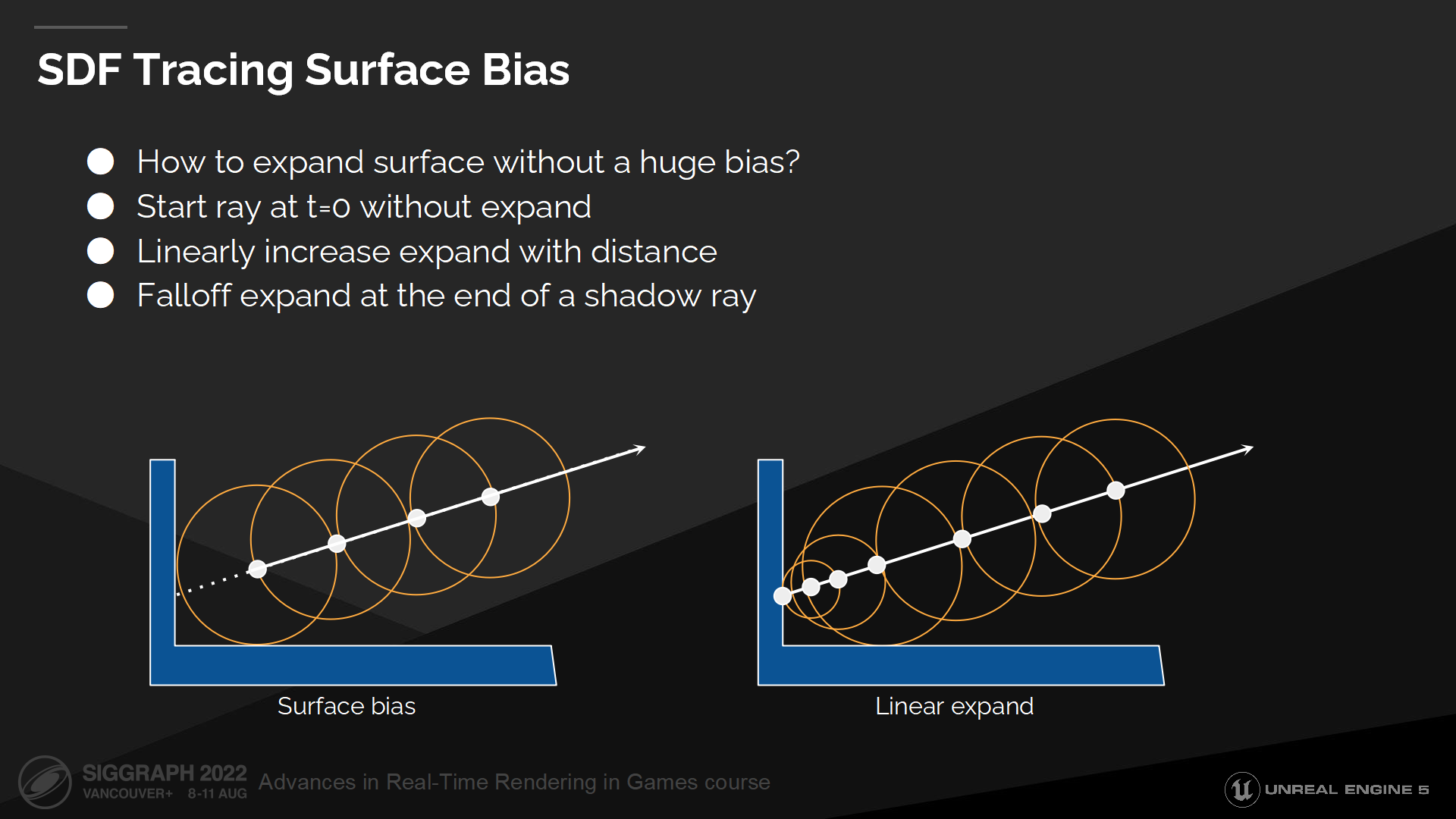
SDF追踪表面偏移量
让我们看看如何改进表面bias的问题。
We preserve the original distance field data and expand surfaces at runtime, which allows us to start at the surface and then linearly increase expand as we move further away from it. This way we can trace that initial ray segment instead of just skipping it and losing all contact shadows.
我们保存了原始的距离场数据,并在运行时做延展——这使我们能从表面开始以线性的方式做延展,直到远离表面。这使我们能追踪到初始的射线段,而不是全部跳过它们而丢失了所有邻接阴影需要的数据。(*图中右侧展示了这种方式,在达到最大步长前,每次增加的步长是线性的)
而在阴影射线追踪结束后,我们需要把延展值退回到零,这样这条射线就不会(错误地)命中光源所在的表面。
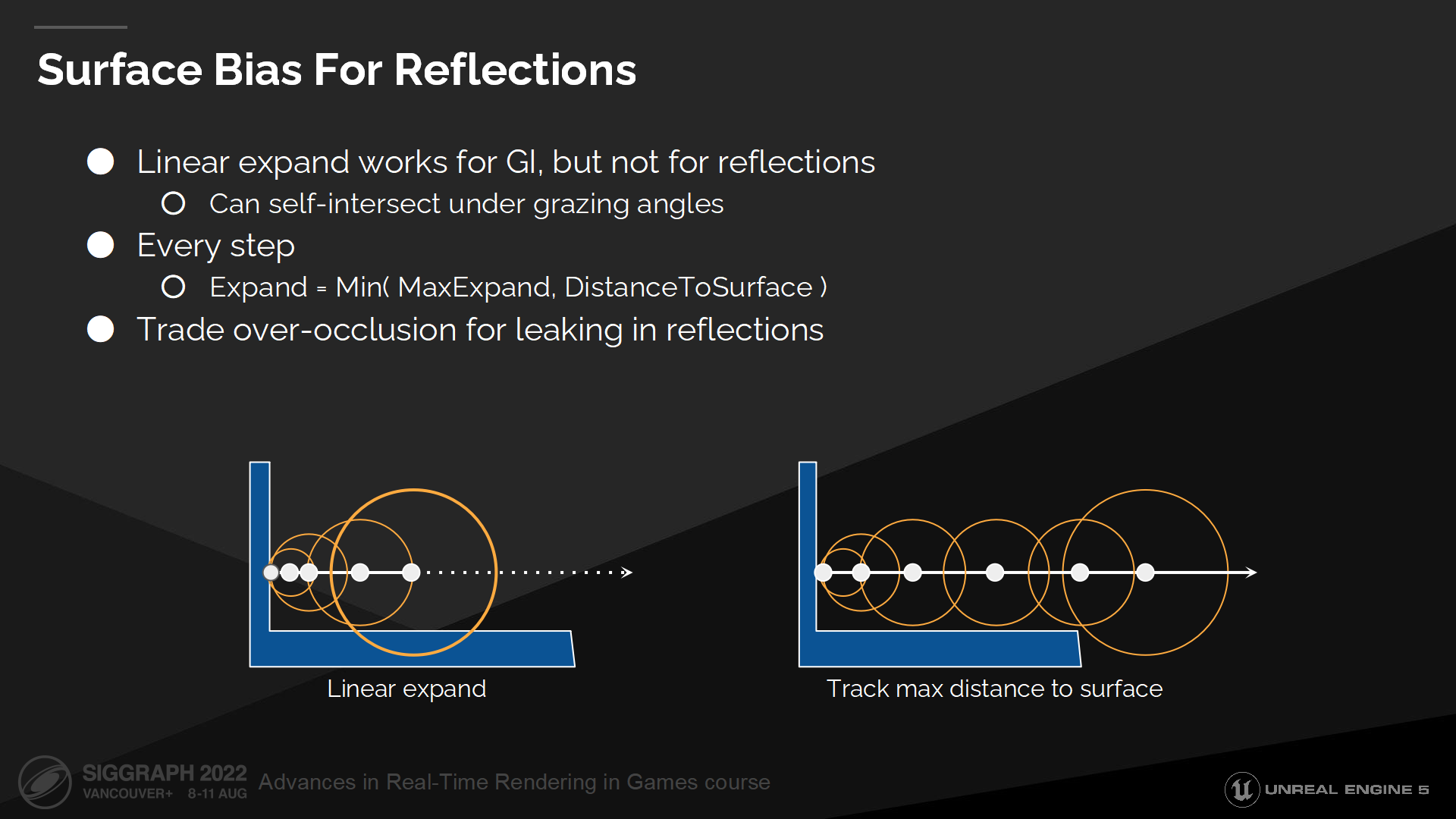
反射相关的表面偏移量
不幸的是这种启发式方案不适用于掠射角(几乎平行)的情况,因为延展过程会过于快以至于部分点上射线会有自相交问题(*图中就是与另一个细表面有了相交上的错判)。
这对于GI和漫反射的射线是能接收的,但对于镜面反射则效果不好——因而这种情况下,相比于过度剔除,我们能接收一点漏光。
我们通过第二种启发式方案来解决反射问题,每一步我们延展的步长基于当前点到表面的距离。这样能保证射线能始终从初始表面离开(*而不是错判为相交)。
*点到表面的距离是距离场中的点自身可以查询到的属性。

SDF延展解决漏光
*图中展示了细网格相关的邻接阴影及漏光解决。

叶子的效果如何?
距离场延展对于固定几何体例如墙面的效果不错,但对于树叶的效果不好,因为这会导致完全遮蔽树叶中应该透过的光照。
为解决这个问题我们需要引入另一个方案——它被称为覆盖率(coverage)。
We mark distance field instances based on the two-sided material and then resample this data into a separate global distance field channel. Coverage allows us to distinguish solid thin surfaces which should block all the light, from surfaces with partial transparency, which should let some light pass through.
我们标记出距离场中那些双面的材质,并将它们重采样至一个单独的全局距离场通道中。覆盖率能帮助区分应完全阻挡光源的固定细表面,与应透过部分光照的半透明的表面。
During ray marching every step we sample the coverage and based on it we increase raymarching step size and decrease expand. Additionally we use coverage for stochastic transparency on every hit to decide whether we should accept this hit or we should continue tracing.
在ray marching的每一步,我们都采样覆盖率,并基于它的值增加raymarching的步长,同时降低延展值。作为补充,我们使用覆盖率来计算每次命中的随机透明度(stochastic transparency),以决定是否视为命中或是需要继续追踪。(*stochastic transparency之前介绍过,是通过像素之间的间隔,来以一定策略实现用不透明模拟半透明的效果)
关于树叶的另一个问题是,它们通常是动态的,而预计算的距离场不支持动画。这通常会导致自阴影问题,因为我们通过对树叶做了额外的表面偏移来解决这一问题。

SDF覆盖率
*图中是解决叶子透光问题之后的结果,右侧相对看起来正常了很多。不过总归这还是一种trick,以现在能达到的精度来说还做不出真实的叶子透光。

软件光追的优势
虽然距离场方案对于镜面反射来说不是完美方案,但对于GI或粗糙表面都有着不错的效果。图中右侧的场景几乎都是被间接光照照亮的,可以看到距离场在其中起到了很好的效果,也能解决微小细节中的光照——例如台灯以及电视的间接阴影。
它也不需要特定的硬件,能支持所有平台。
它在引擎里有着多样的效用,被例如Lumen以及其它使用场合——例如物理碰撞所共用。
最后距离场允许我们缩小场景,并支持有大量重叠实例的场景——通过在运行时把整个场景合并至全局距离场来实现。
*至此简单总结一下,远距离软件光追的核心数据结构是全局距离场,它是把物体的距离场汇入多层clipmap得到的中间层数据结构。基于这种数据的采样在计算光照和阴影时面临的挑战不同,在一些极值情况也会有问题,文中也给出了一些基于实践的解决方案,虽然很多是启发式的甚至是trick。
4 表面缓存
*如概述部分介绍的,表面缓存主要用来补充SDF中不具备的光照计算参数。
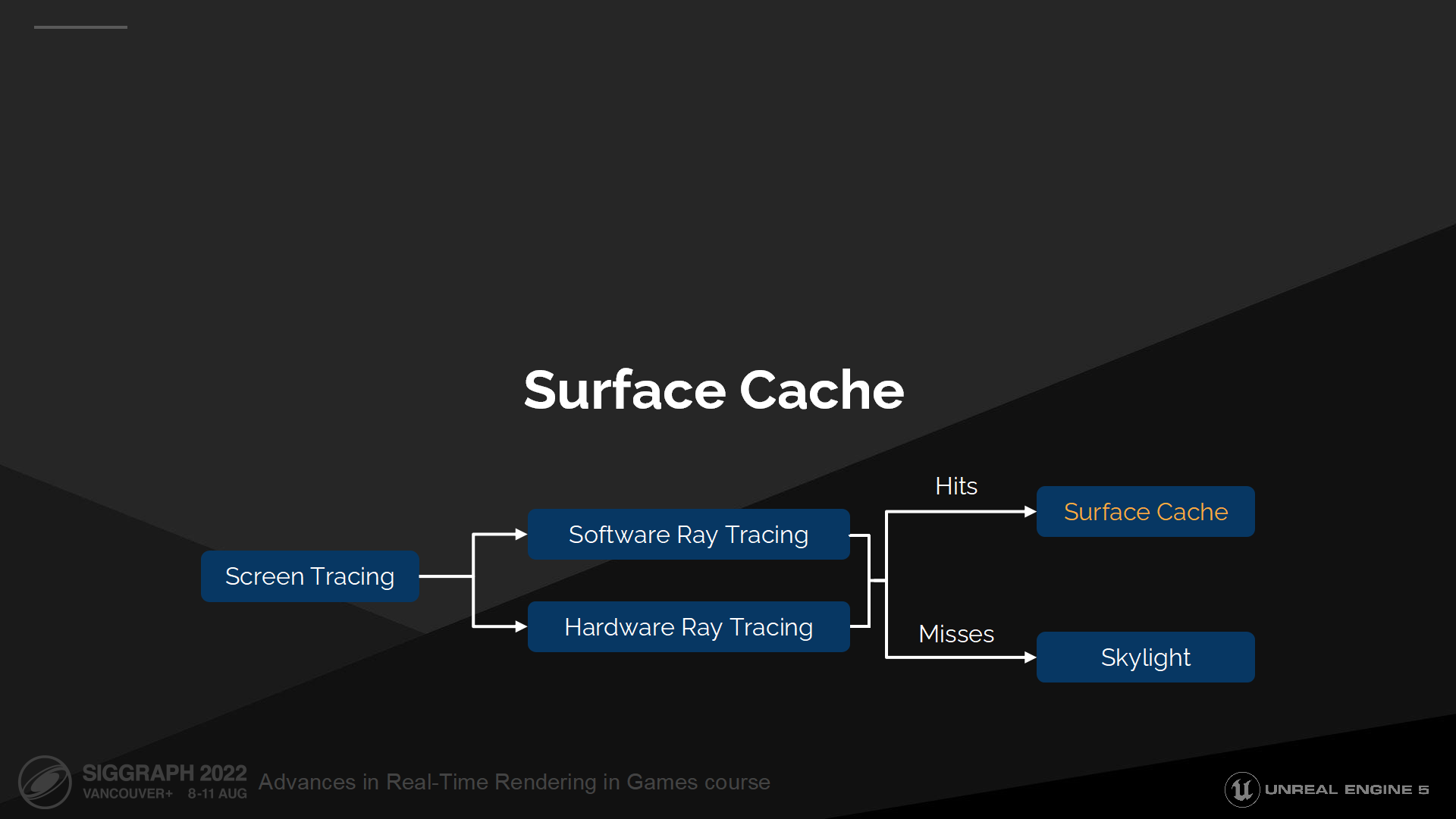
如前文所述,只有SDF数据还不足以计算物体表面的材质光照。

为什么使用表面缓存
Distance fields don’t have any vertex attributes and we can’t run material shaders on them. We have access only to position, normal and mesh instance data. This means that we need some kind of a UV-less surface representation to be able to shade those hits.
距离场数据不包含任何顶点参数,因而我们无法在其上执行材质shader的计算。我们能得出的只有位置、法线和网格实例数据。这意味这我们需要一种纹理坐标无关的表面(UV-less surface)描述方式来为命中点着色。
我们也需要将这一描述数据用于缓存并复用于其它各种计算与光路径,因为我们无法负担递归的多次弹射射线追踪。
- 自定义的材质图(graphs 是另一种编辑shader的方式)可能非常复杂,并在每次计算射线命中时有较高开销。
- 有多个需要投影的直接光照光源也会开销较大。
- 多次弹射的开销则更大,因为对每一个射线命中我们都需要递归地追踪多个射线并逐一计算材质光照。
表面参数
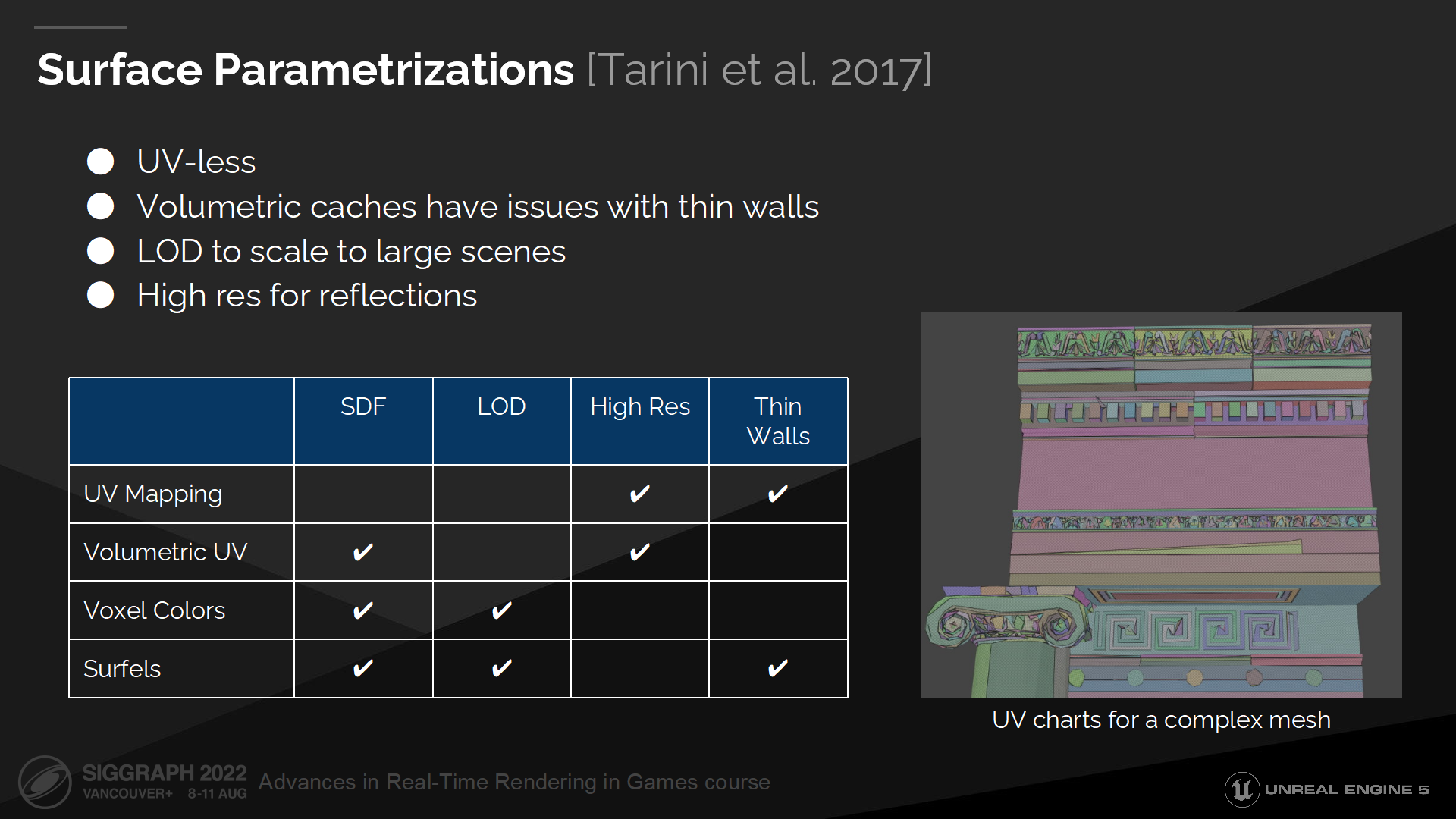
在能计算距离场命中结果以外,我们对表面参数也有额外的需求。我们希望它是基于表面空间的——因为体块方式在描述细墙时会导致漏光。我们需要一种规模可变(scalable)的方案,既可以覆盖复杂场景的巨量实例,也可以在精度上放大以支持镜面反射。(*图中就列出了不同使用场合的参数组合)
虽然有很多的表面参数化方式,但多数我们都不会用到。
纹理映射(UV)对于复杂网格来说不能很好的适配,因为它们会产生很多琐碎且不利于合并的UV图。并且它们也需要顶点参数,而我们的结构中并不能访问到。
体积UV也不能描述细墙壁,而且它也无法很清晰的基于距离来计算LOD。
体素颜色和微表面则有着精度上的限制,因而不能用于反射。

*Cards这个概念是由后文的解释来填充的,就不翻译了
For Lumen we decided to use projected cards, which can be also described as uniform rectangular clusters of surfels.
在Lumen中我们决定使用投影的cards,它也可以被描述为统一的微表面的矩形集群。(*从page中可以看出,策略是逐网格投影)
它们是易于快速查找的——基于它们的矩形结构。
Cards可以在运行时生成,并能缩放至任何分辨率——在不需要烘焙任何数据的情况下。
它们也可以用来表述两面的细墙体。
*Cards可以简单理解成把网格“拍平”了的一种结构,其实看到是使用的这样一种结构我还挺意外的。
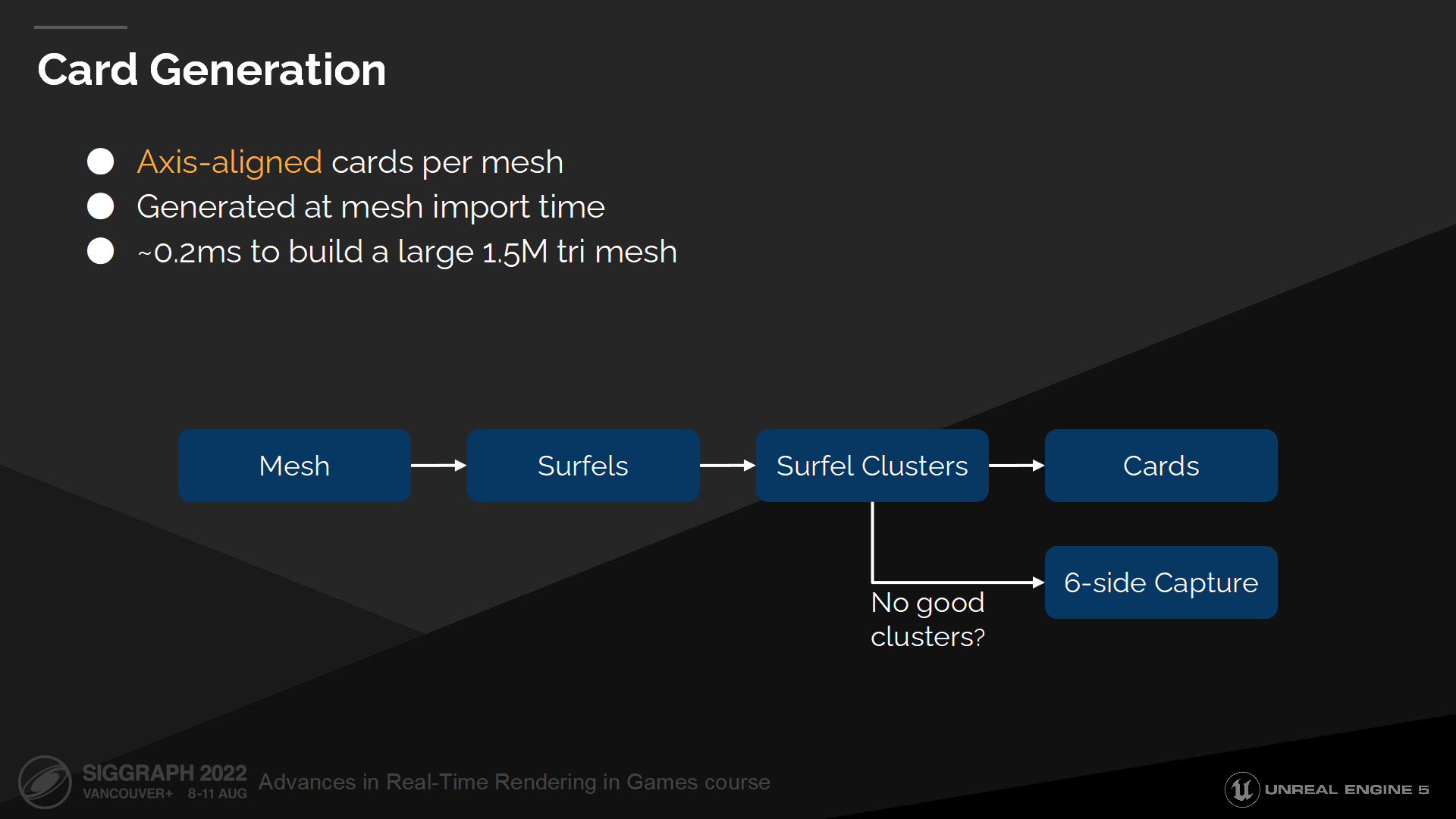
Card生成
在网格导入时我们执行了预计算过程来生成并放置cards。
所有cards都是轴向(axis-aligned)的,这能使其易于生成和查找(*减少计算过程的矩阵乘除)。我们也尝试过支持任意朝向,但结果来说它们不易于放置,提供的额外灵活度也不值得为之付出相应的开销。
生成始于对三角面的简化——它们会被体素化并汇入一组轴向的微表面。
之后我们使用Kmeans聚类算法(K-means inspired clustering algorithm)划分集群,并将集群数据写入cards。
如果生成中产生了任何问题——例如网格太难以解开折叠(unwrap)或太小,我们就用一个6面cubemap的投影方式作为后备。
*Kmeans聚类算法是一个重复移动类中心点的过程——通过把类的中心点,也称重心(centroids),移动到其包含成员的平均位置,然后重新划分其内部成员。详细的案例这里不展开了。

Card生成——微表面
在生成的第一步转化三角面至轴向微表面时,为了简化网格其中小的细节都被移除了。
我们在体素化网格时对每个2d单元格发出64根对物体追踪的射线。之后我们对每一个3D单元格加总射线命中的数据,并基于一定的阈值生成微表面。
射线命中数被作为微表面的覆盖率存储下来,并将被用来评估一个集群的有用程度。额外地我们也存储了射线命中的位置,它将被用来决定微表面在集群近平面上的可见性。
Next for every surfel we trace 64 rays and count the number of triangle back face hits. If most of those hits are back faces then given surfel is inside geometry and we can discard it. We also compute surfel’s occlusion based on the average distance to hits. Occlusion will be used to determine how important it is to cluster a given surfel.
下一步,对于每个微表面我们追踪64个射线以统计命中的三角面背面的数量。如果大部分命中位置都在背面,我们可以认为当前的微表面位于几何体内部,并可以丢弃掉。我们也基于平均命中距离来计算微表面的遮挡程度,它将被用于决定一个微表面在集群中的重要性。

Card生成——初始集群
下一步我们生成初始集群。
我们选择一个未使用的微表面,并迭代地产生集群:
- 首先我们对所有未分配的微表面,按到集群边界的距离计算权重以选择那些更接近的;
- 微表面的遮挡程度也被列入考虑,优先选择那些更重要的;
- 集群的比率系数(ratio)也影响权重,以提高方形集群的倾向。并且最终我们需要检测微表面从集群的近平面处是否可见。
下一步我们持续的添加最优的微表面,直到我们达到足够有效的候选数量。此时我们重新计算集群的重心位置,并开始从它从重新生成集群。
在进行有限次的重生成后,得到的集群就不再变化。此时我们将集群添加到列表中,并查找下一个未使用的微表面(*回到迭代的开始)。
在递归执行这一步后,最终我们的网格会完全被集群覆盖,不过这些集群可能还不是全局最优(globally optimal)的。

Card生成——集群优化
Final step is a global optimization, where we re-grow all clusters in parallel from their current centroids. Again we do a few iterations of parallel growing until we hit a limit or clusters don’t change anymore.
最终步骤是全局优化,我们将所有集群按当前的重心位置平行地重新生成。在进行数次平行生成的迭代后,停止于达到上限或是集群不再变化时。
平行的生成过程可能导致过小的集群或是空白空间,所以每次迭代后我们都需要移除过小的集群,并在空白空间插入新的集群。
最后我们按覆盖率排序集群,并按指定的数量选择最重要的一些集群汇入cards。

Card管理
现在我们有了每个网格的card,需要以一定方式来管理。
其中有两个冲突需要解决:
- 一方面,我们有很多很小的card用于处理多次GI弹射。我们不需要很高的精度,因为GI是很低频(指光照信号变化的频率)的,但作为持存地覆盖所有物体又有其重要性。
- 另一方面,我们也有少量高精度的card用于特定表面的反射。这时我们需要很高的分辨率,例如用于镜面反射,card需要匹配屏幕像素密度。
极端情况是我们Matrix Awakens的DEMO中演示的,其中需要覆盖大量的实例,以围绕摄像机处理建筑间的光线弹射;同时我们也需要多个高精度card的反射表面。

虚拟表面缓存
这两项需求将我们导向了虚拟表面缓存方案。
对于GI我们使用低分辨率的常驻页(pages)。这些页是围绕摄像机基于距离来分配的,我们也有一套LOD方案以移除特小的card。
对于反射我们使用稀疏的按需分配的页。它们基于反射射线命中位置来分配,在不需要时被取消分配。

表面缓存GPU反馈
每次射线命中时我们写入表面缓存反馈,因此我们可以有选择地指定每一页的精度并与更新频率。
射线命中采样并混合了多页的数据,因此我们需要推测地(stochastically )选择一些最重要的页。下一步我们更新它的上次使用时间,并将请求的mip层级写入一个反馈缓冲中。
我们在GPU上压缩这个反馈缓冲——通过将所有请求插入一个GPU哈希表并压缩。最终的请求队列包含需要的页及每页的命中数量。
请求队列之后会被加载到GPU,之后我们就可以对其进行排序,并对页数据做映射和解除映射。

物理页图集
大于页尺寸的数据会被拆分成独立的物理页,并单独分配空间。
小于页尺寸的card是被作为子集分配的——这意味着我们映射一个单独的物理页,并使用一个2D分配器为其分配多个小的card。(*2D分配器指需要一定的图集排布方式以提高页利用率)
这很重要,因为这允许我们在有很大的页的同时不在边界处浪费太多内存,同时我们也能支持小的分配而不需要把每页都向上取整至物理页尺寸。(*例如小于128尺寸的可以拆成多个64尺寸使用)
我们精简了查找过程,因而如果我们请求了一个不存在的高精度页,页表会自动指向一个低分辨率的持存的页。这允许我们在采样表面缓存是只做一次查找,而不需要递归地查询备选页。
*详细的参数可以看PPT页中的内容。

Card抓取
我们也需要把网格和材质数据输入card,它们在之后会被投影到表面上。
我们在运行时执行这一步,通过一个正交摄像机(ortho camera)将网格渲染到card上,并写入表面属性——例如漫反射系数(albedo)和法线(normals)。在运行时执行能使我们方便地处理精度缩放,并在不用管理预计算数据的情况下支持材质改变。
Card抓取是以给定的帧间隔来更新并缓存的。每一帧我们收集页更新的请求,并在它们每次使用时基于和摄像机的距离进行排序。之后我们选取指定数量的最重要的页进行数据抓取并更新。作为补充,为支持动态材质,有少量的页我们需要每帧更新。
通常来说渲染很多小网格会非常慢,基于LOD以及很多小的绘制指令(draw calls)。但通过Nanite我们可以在一个draw call中渲染所有几何体,并且我们也有一个连续的LOD层级以简化网格并渲染到小的目标上(*这里指card)。这是极大的渲染提速,使我们能更频繁地抓取card数据。
*Nanite的网格管线的文章之前我也做过一篇粗读(链接)。
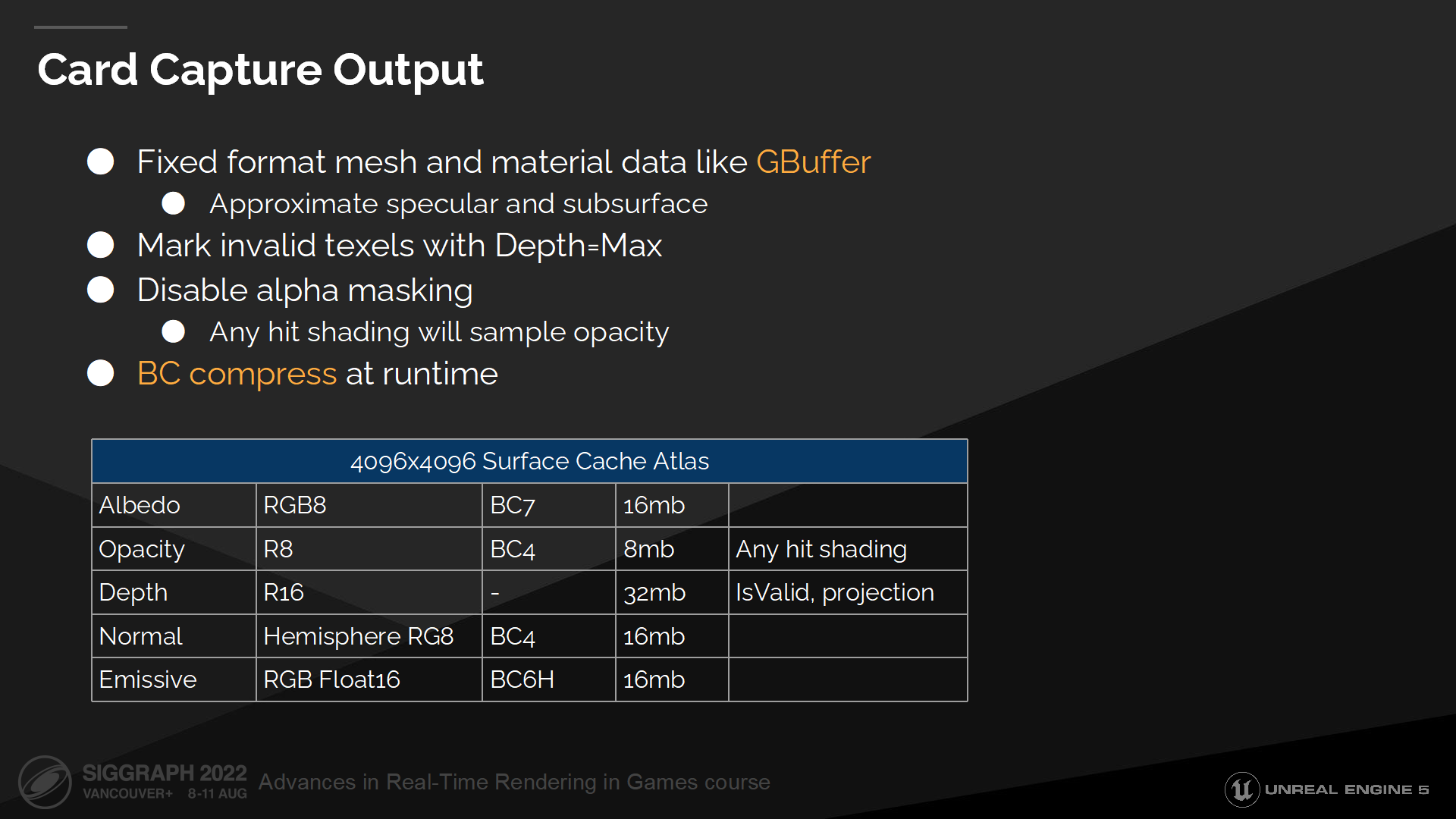
Card抓取输出
Card抓取重新采样材质和网格数据,并写入一个指定的与视点无关(view independent)的类似GBuffer的结构中。
我们通过修改漫反射系数来解释(原文是to account for)能量的损失,以估算高光或次表面射出的光照。
我们也标记出无效的纹素(texels,可以理解成缓冲纹理中的一块区域),在后续我们就可以直到哪些texel不包含有效数据因而无法被采样。
在抓取时我们关闭透明遮罩(alpha masking),因为我们需要从一个透明遮罩的表面点来识别缺少的表面缓存数据。这在后续会很有帮助,因为可以在运行命中检测的shader时不需要处理材质shader。(*这里主要是对透明遮罩材质的处理)
最后抓取的数据在运行时被BC压缩(全称 Block Compression),以最小化内存占用。
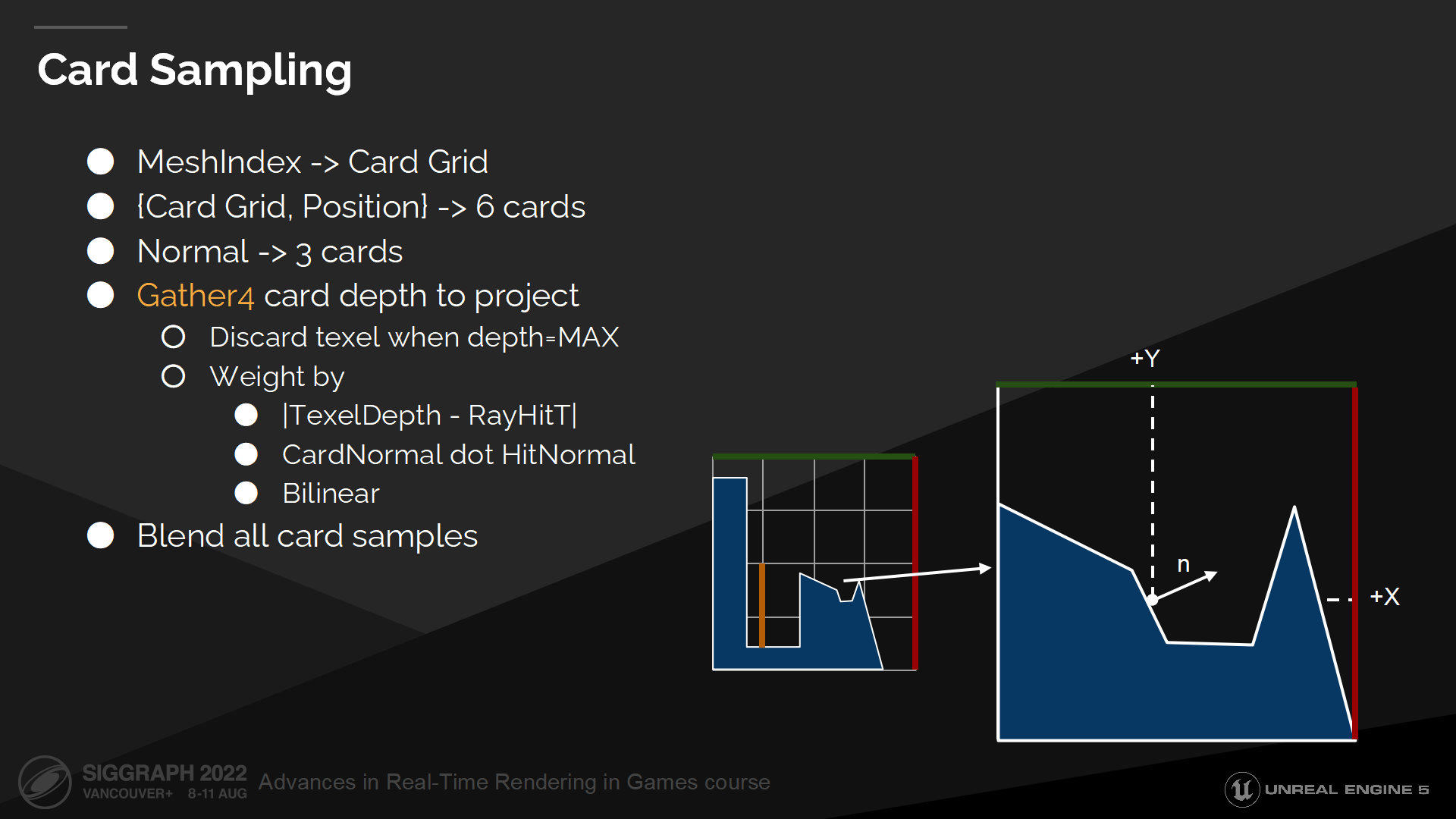
Card采样
现在我们准备好了所有数据,可以采样表面缓存了。
我们开始于按网格索引查找card栅格。之后我们查找栅格中的一个单元以得到6个card。基于表面法线我们找到需要投影的3个card。
之后我们采样这3个card。对每一个card我们收集4个深度信息,用于手动执行双线性过滤(bilinear filtering)。
We weight each texel by delta between stored depth in surface cache and ray hit depth to discard occluded samples. We also weight texels by card projection normal to prevent projection from stretching. Then we discard texels marked as invalid.
我们基于深度缓冲中的差值、以及射线命中的深度来计算texel的权重,并丢弃被遮挡的样本;我们也把card投影法线方向作为权重,以避免从过度拉伸的方向投影。之后我们把丢弃的texel标记为无效。
最后所有的采样被混合到一起,以计算命中位置的最终表面缓存属性。

Card合并
某些情况下,我们会面临card能缩放到什么程度的问题。这在很多小实例合并成一个大物体时会是一个问题——例如图中的大楼,我们不得不产生大量的小card、或是放弃整个物体的card(因为数量太多了)。
我们的解决方案是运行时合并card。
我们的实现方式是自动找到小的重叠组,或基于用户提供的tag来分组。
每个组包含从6方向抓取的6个card,类似cubemap。这在观察者在集合组的外部时是一种好的近似——而这是通常会有的情况。
感谢Nanite,最终抓取整个组并渲染到各个card的过程也非常快。

光照的情况如何?
现在我们在表面缓存中有了材质数据,但仍需要用它来计算光照。
图中展示了(光照)多次弹射的重要性,没有多次弹射时近一半的场景都是黑的,并且反射也消失了。
需要多重阴影射线的直接光照,或需要递归追踪的间接光照开销都很大。在大部分情况我们都无法负担额外的射线,因此理想状态下光照都应该来自表面缓存。

表面缓存光照
表面缓存中包含了计算光照需要的所有网格和材质数据。
这和(烘焙的)光照纹理方式类似,也会遇到类似的问题。
When tracing from texels, we need an appropriate bias based on the surface normal and ray direction to escape surfaces.
当从texel中追踪时,我们需要基于表面法线和射线方向有一个合适的偏移值,以确保射线能正确离开表面。
Texel也可能在几何体内部,并由于双线性过滤而导致穿墙漏光等问题(*算插值时不知道墙壁位置)。我们通过丢弃命中三角形背面的射线来解决这一问题,使几何体内部的texel正确显示成黑色。

更新策略
光照信息每一帧都重新计算是开销很大的,因此我们每帧只缓存并更新表面缓存的一个子集。
我们基于缓存页上次使用以及被更新的时间,来选择一帧中要更新的页。
上次使用时间是基于每一个命中的射线上,GPU反馈写入的帧序号;上次更新时间则随每次页更新递增。
这两个属性在直接和间接光照中被分别追踪,并且它们都有不同的更新频率。具体地说,我们更新简单的直接光照的频率远快于间接光照。
为了指定一定数量的最重要的页,我们构建了一个直方图(histogram),从连续的容器(原文是buckets,直译是桶容器)中选择直到我们达到预期的数量。
有时我们需要改变一个card的尺寸,或映射一个新页。此时我们尝试重新采样之前的光照信息(如果可行),这样我们就不至于丢弃之前所有昂贵计算的结果。
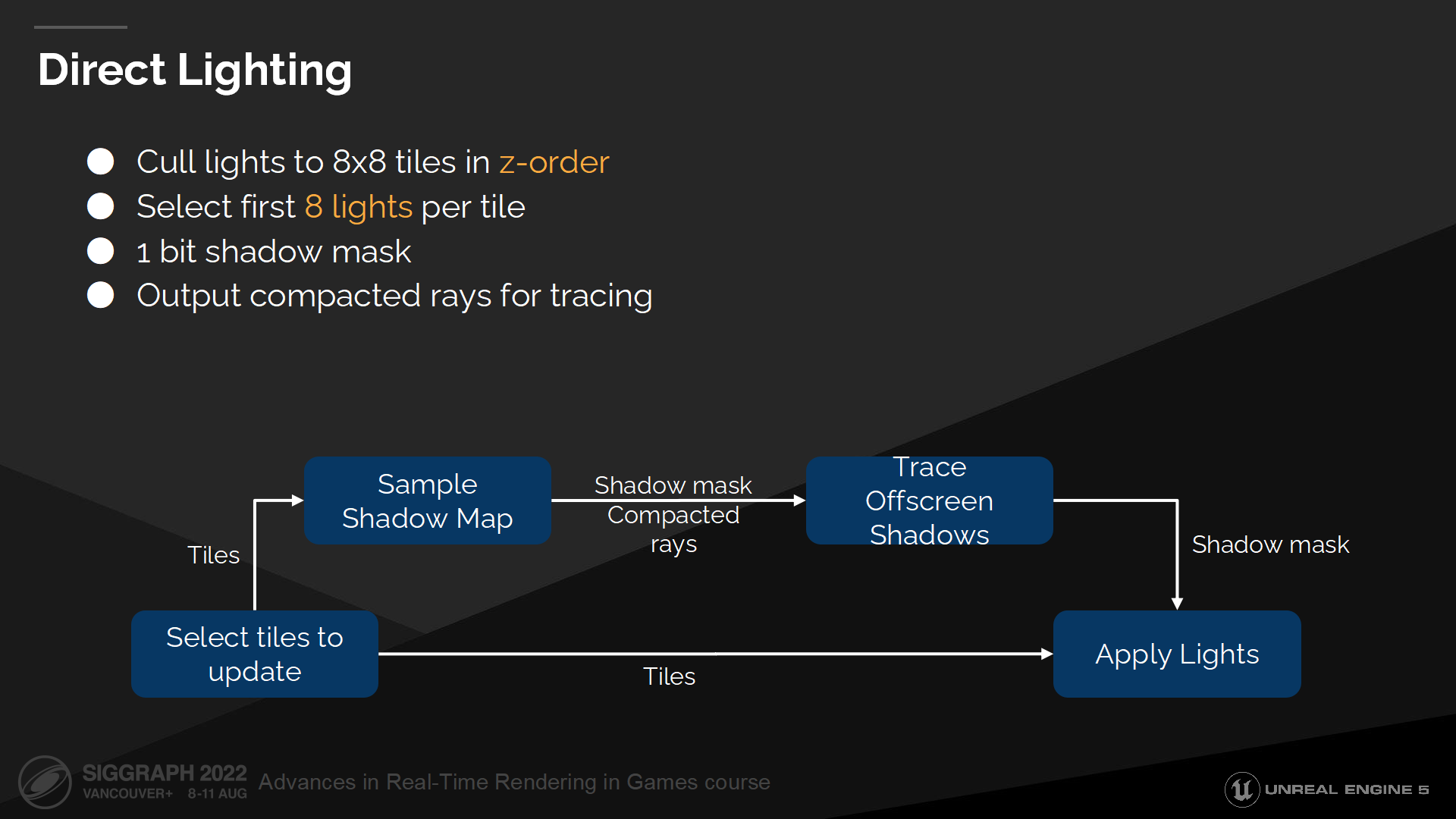
直接光照
当选中待更新的页,我们将它切分成8x8的块(tile),并输出到一个z排序(z-order)序列中以最大程度保持一致性。
然后,对于这些tile我们选择最多8个光源。目前我们仅选择最先的8个光源,并且它在我们的使用场合运作良好——但在未来我们希望采用更只能的光源选择策略。
对于每个光源我们有1 bit的shadow mask,以用于混合多种阴影计算方法。我们首先通过采样可用的阴影纹理(shadow maps)来输入shadow mask。在这个pass中我们也构建了一个阴影射线的压缩列表,以用来解决阴影纹理无法覆盖而需要射线追踪的位置——通常这类texel都在摄像机背面。下一步我们追踪阴影射线来完成shadow mask。
最终我们执行光照pass并使用shadow mask来计算光照值。
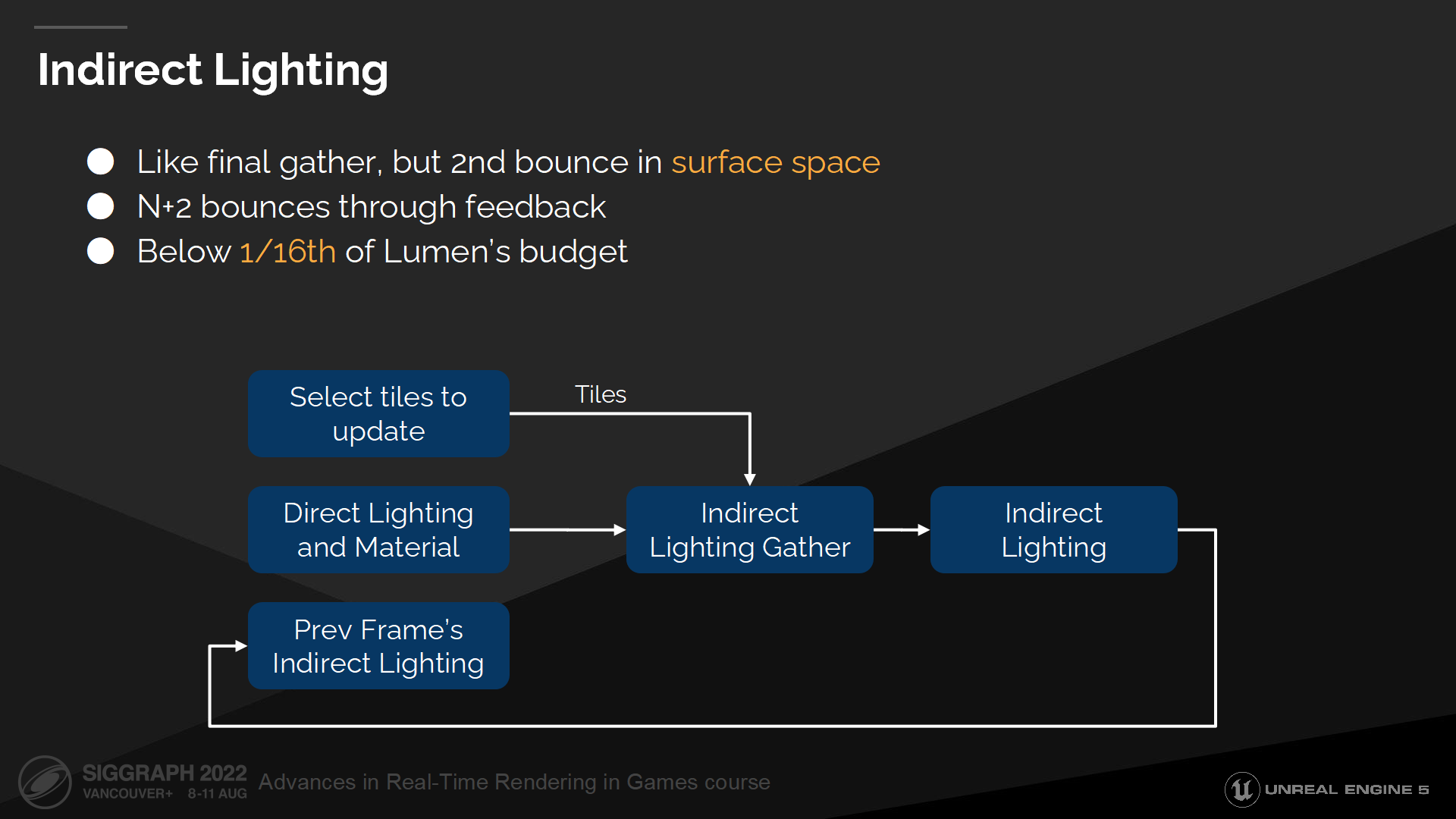
间接光照
间接光照则有更多挑战,因为这里我们基本上需要在表面空间中执行final gather以计算第二次弹射。(*final gather在上个系列介绍屏幕光照缓存中有详细介绍,类似card这也是有很详细内涵的一个概念)
In order to support multiple bounces for every indirect ray hit we sample current frame’s direct lighting and last frame’s indirect lighting. So for every frame we compute the first two bounces and the following bounces are then feedback based.
为了至此间接光照射线的多次弹射,我们采样当前帧的直接光照和上一帧的间接光照。因此我们每一帧都计算前2次弹射,并且后续的弹射次数是基于回馈机制来计算的。
很重要的需要指出的一点是——我们的性能预算很有限,因此只能以牺牲效果的方式来换性能。这意味着不仅每帧能更新的页数量很低,新射线的预算页很少。
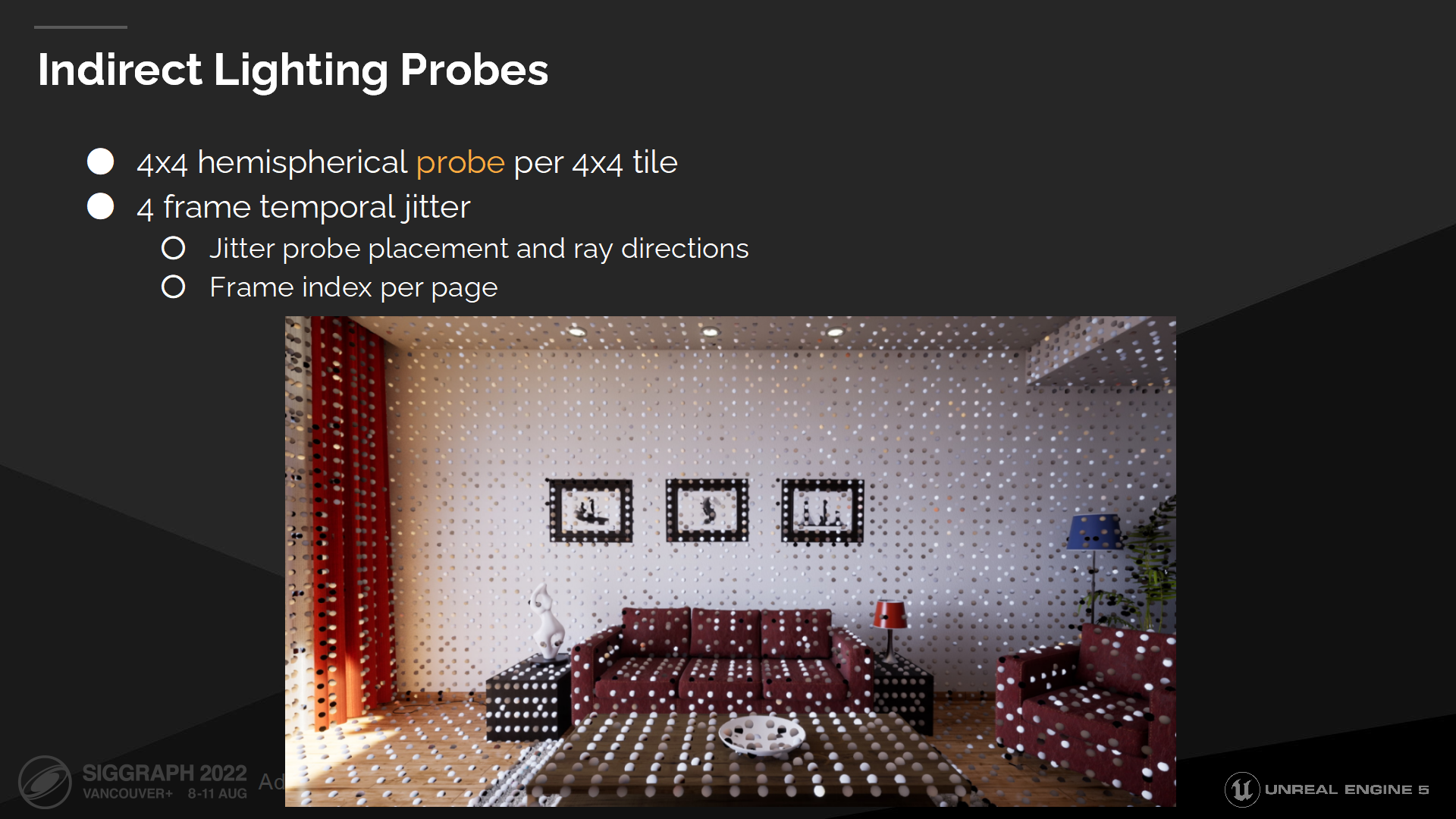
间接光照探针
理想状况下我们将从每个texel追踪64根射线,但这太昂贵了。作为替代我们在每4x4的tile都放置一个半球形的探针,并且只从探针的texel进行追踪。这使得降采样的追踪能生效,同时还保持了表面法线的细节。
我们每帧抖动探针位置和探针方向(基于帧索引),并存储在每个表面缓存页中。
由于追踪数较少,得出的探针采样结果是有很多噪声的,因此我们需要一些空间和时间上的重用来消除误差。
*这部分其实和上个系列介绍的内容是呼应的。篇幅原因确实也没办法再展开探针和final gather的细节了。
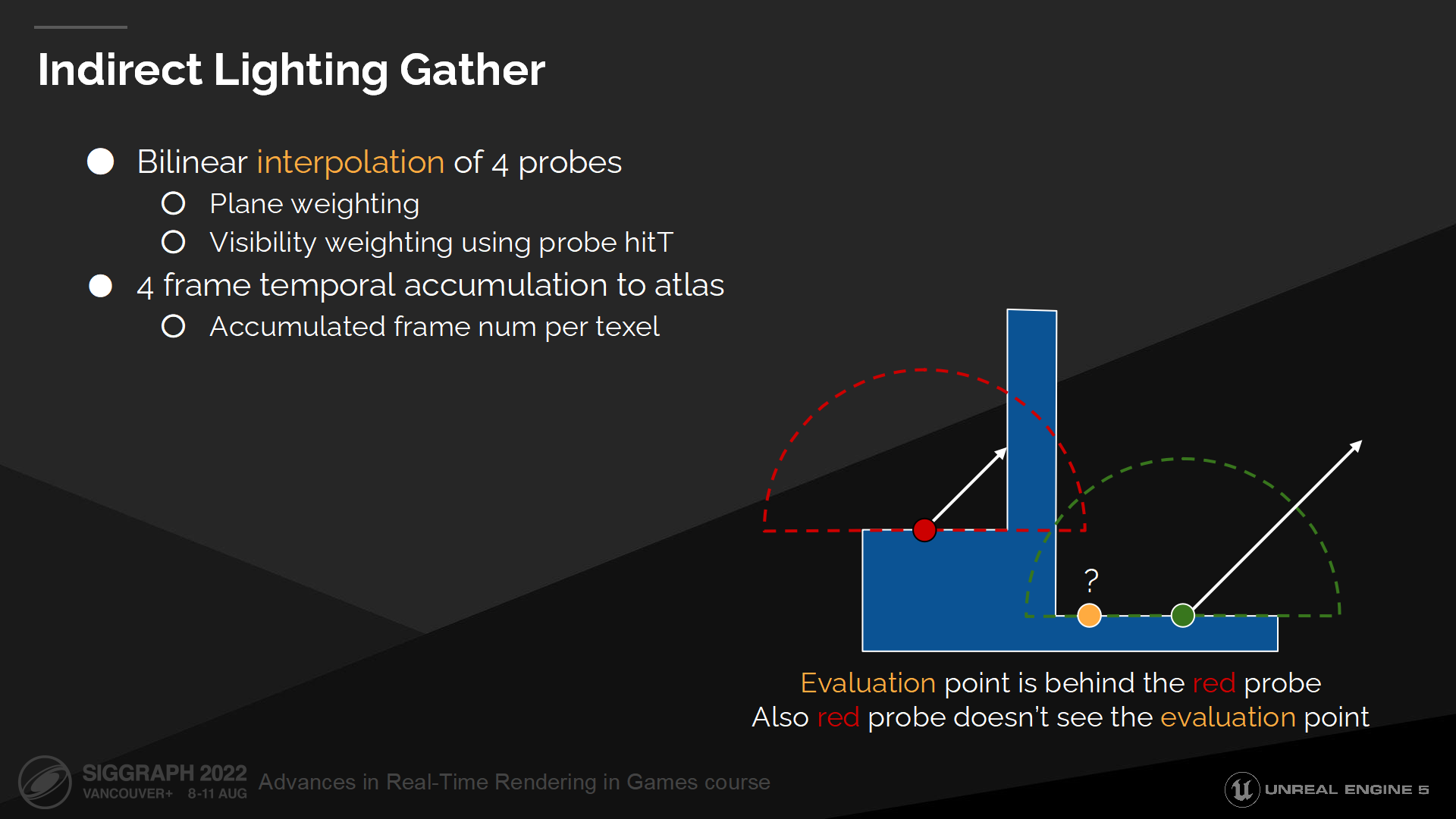
间接光照收集
对每个texel我们选取4个最近的探针,并在它们之间做插值以计算间接光照。
在插值过程中我们有2个探索策略以减少漏光——由于有些探针可能在墙后。第一个策略是对每个半球探针按其所在平面分配权重,以跳过在其之后的texel;第二个策略是使用探针的深度缓冲来检测可见性,以评估可用的texel。
Finally interpolated results are temporarily blended into the indirect lighting atlas. Alongside this atlas we keep a current number of accumulated frames. Indirect lighting update rate is quite low and we need to limit the total number of accumulated frames to 4 in order to minimize ghosting.
最终我们得出插值的结果,并分帧(temporarily)混合入间接光照图集中。搭配这个图集,我们还保存了一定数量的累积帧。间接光照的更新频率是很低的,因而我们需要把可累积的帧数设置为4,以最小化鬼影问题。

体素光照
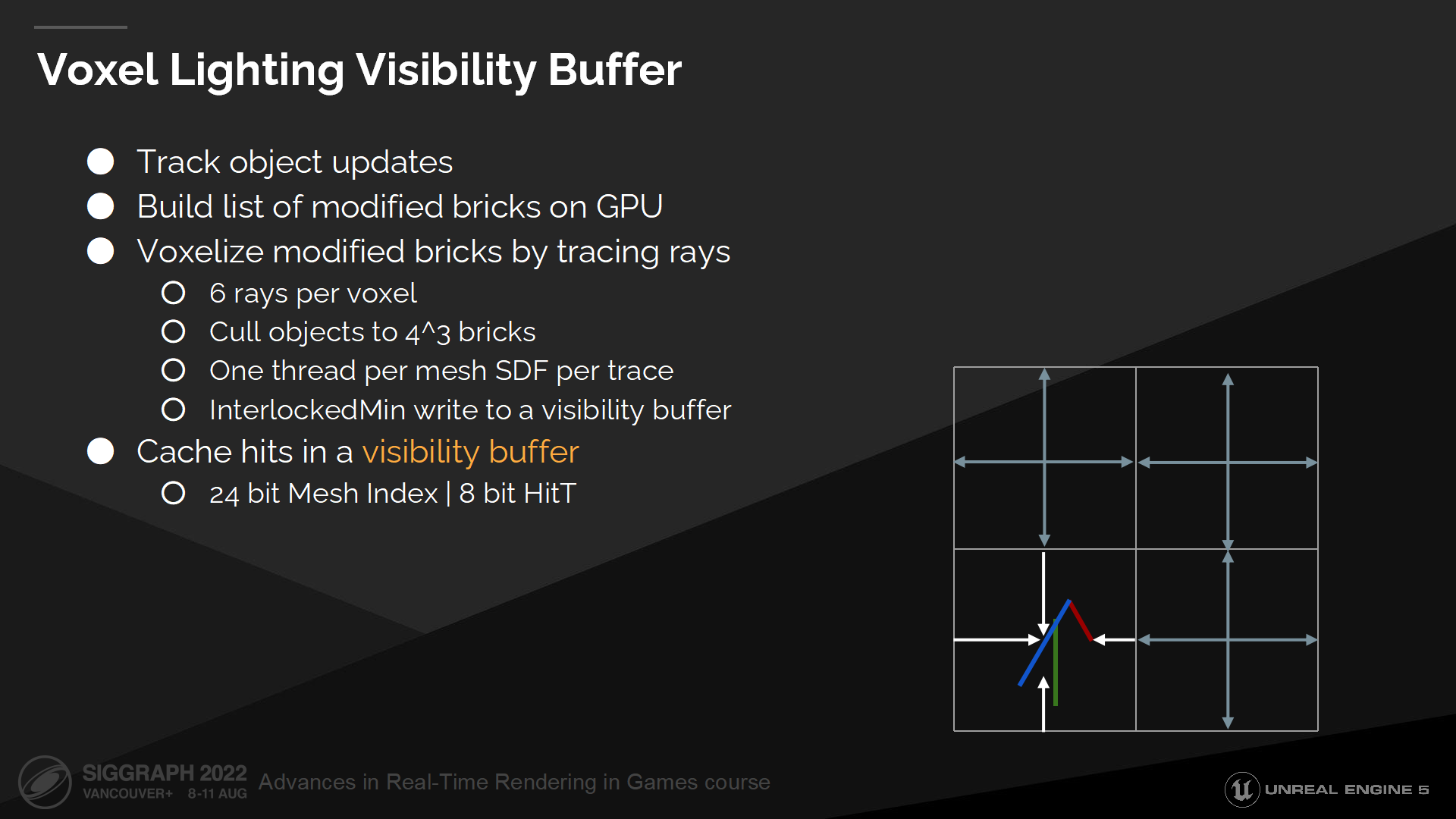
最后一个问题是,我们无法从全局距离场中直接采样表面缓存。全局距离场是一个合并的结构,我们无法从中得知命中了哪个网格实例。
为此我们也把card合并成一组全局的以摄像机为中心的clipmap。
每个体素中存储了每个轴向的radiance,我们在采样时在不同方向以及相邻体素之间做插值。
We weight every sample by weight stored in the alpha channel. This weight allows us to account for the missing cards and for card re-projection onto a fixed world space axis.
我们使用存储在alpha通道中的权重来选择采样的优先级。这项权重允许我们考虑丢失的card,以及重投射到指定的世界空间的轴上的card。(*生成方式下一段会提到。使用细节原文没有介绍,这段大概的意思是card合并之后的采样准确性通过权重值来描述了)

体素光照更新
下一步我们每帧对整个可见性缓冲进行着色。
首先我们需要对其压缩,因为它过于稀疏了。(*这里还是指把不连续的数据压缩成连续的)
在压缩后,我们为每个有效的可见性缓冲采样表面缓存,以计算最终的光照。
在这一步中我们也计算了投影权重,并将保存在体素光照容器的alpha通道中。

表面缓存的局限
关于表面缓存的局限性,最主要的问题是体素光照的质量不高(由于过于稀疏)。这是一个我们将再未来改进的点。
Card是网格导入时生成的,因此不支持网格动画。对于树叶,我们通过增加深度的权重bias来缓解这一问题,这对于小的形变是可行的,但对角色类动画则不是。
某些网格——例如树,有着太多的层级,因而不能被展开成一个合理数量的层级。这在计算反射时是一个会被注意到的问题,不过对于漫反射射线则问题不大——因为它只会导致少量能量的丢失。

总结
表面缓存的最大好处是它使距离场追踪变得可行。
它也在缓存各类昂贵的计算结果方面有很好的功效。这不仅对于距离场追踪有用,对于硬件光追它也有利于跳过(射线命中后)昂贵的材质和光照计算。
最后它还激活了高质量的多次弹射计算,这对渲染可信的GI和反射效果非常关键。
*总的来说,前沿的渲染引擎对于多次弹射的间接光照支持是越来越好了,但是对于极限情况例如树叶等还是需要一些trick。
结语
我个人感觉这篇分享其中的内容,对比之前2021年的2篇来说有了一定的推进,一些细节设计已经不一样了。不过作为一款有较大革新的复杂的商业引擎来说,这种程度的探索迭代也正常——更何况其中的很多参数设计、数据结构以及trick,到现在以及几年后可能又会发生不少改变,例如处理室内场景的方案就在不断改进的过程中,针对树叶的方案也还谈不上特别靠谱。
由于是一种总括性质但又干货很多的分享,因此这篇文章其实page和解说稿都包含了不少信息——例如要看具体实用的参数规格还是要看page。但总的来说,只看解说稿作为了解方案的脉络已经够了。尽管如此,也已经是信息量爆炸的一篇内容了。
对照概述部分来说,本篇中覆盖到了软件光追和表面缓存的部分;下周会更新下篇,从硬件光追的部分开始,并覆盖后面几节。
最后是一些资料链接:
Prefix Sum的Wiki
Parallel Prefix Sum (Scan) with CUDA (CUDA不关键 算法可以用ComputeShader实现)
Lumen: Real-time Global Illumination in Unreal Engine 5 的PTTX